2025别再瞎存数据!VLA训练三大神格式终极对决:HDF5、LeRobot、RLDS谁才是你的真命天子?
HDF5如本地硬盘,切片快、小数据友好;LeRobot云原生Parquet,边下边训,大模型预训练首选;RLDS/TFDS序列强,离线RL神器,TF生态无缝。按场景挑格式,别再全量下载!
·
1、HDF5
HDF5 文件可以被视为一个容器,其内部结构类似于文件系统,包含两种主要对象:
- 数据集 (Dataset):本质上是多维数组,用于存储实际的数据,例如图像像素、传感器读数等。
- 组 (Group):用于组织文件中的对象,可以包含其他组或数据集,形成一个层次化的结构,类似于文件系统中的文件夹。
- 结构:

- 使用侧重:
- 高性能 I/O: 支持并行 I/O 操作,能够高效地读写大规模数据集,这对于动辄 TB 级的 VLA 数据集至关重要。它还支持数据切片(slicing),允许程序只读取所需的数据子集到内存中,而不是一次性加载整个庞大的文件
- 可扩展性: 单个 HDF5 文件的大小理论上只受文件系统的限制,能够轻松存储海量数据
- 通用性: 作为一种跨平台、多语言支持的标准格式,HDF5 在不同系统和编程环境(Python, C++, Java 等)中都有着良好的兼容性
2、Lerobot
Lerobot 由 Hugging Face 团队于 2024 年发起并主导开发。Lerobot 的诞生正是为了解决机器人学习领域数据集格式不统一、模型难以复现、社区贡献门槛高等痛点- 结构:
通常是以 Parquet 文件为核心,并结合 Zarr 等云原生格式,整体被封装在一个易于访问和操作的目录结构中
- 数据集目录结构: 一个 Lerobot 数据集通常是一个文件夹,其中包含了多个 Parquet 文件(用于存储表格化的数据,如动作、奖励等)、一个
info.json文件(包含数据集的元数据,如特征描述、统计信息等)和一个dataset_info.json文件(描述数据集的配置和版本) - 分片与流式处理: 数据通常被分割成多个小的 Parquet 文件(shards)。这种设计天然支持流式处理(streaming)。与 HDF5 需要一次性下载整个大文件不同,Lerobot 可以边下载边处理数据,极大地降低了本地存储的需求和数据加载的启动时间,非常适合在云端或资源受限的环境中进行训练
- 与 Hugging Face
datasets库深度集成: Lerobot 数据集可以被datasets库直接加载和处理,用户可以利用map,filter,shuffle等丰富的 API 对数据进行高效的预处理。 - 结构图
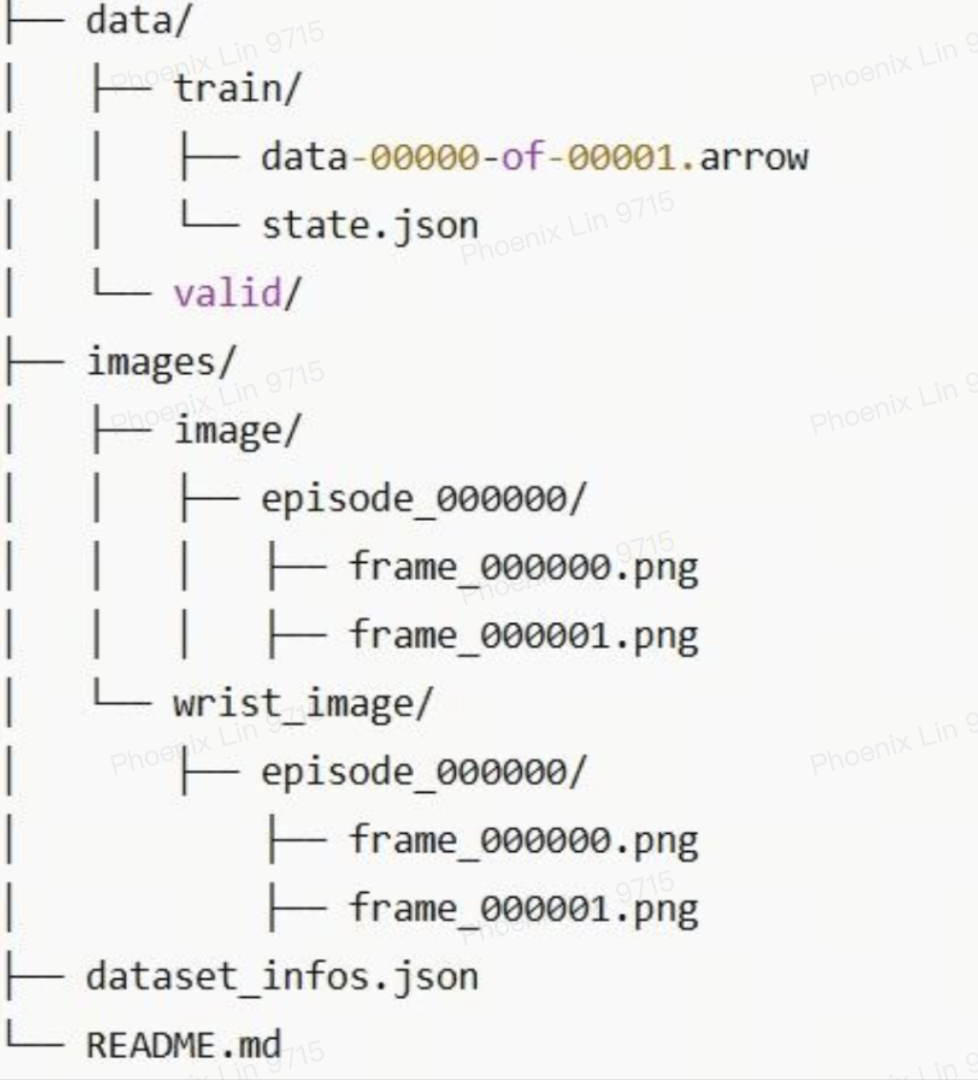
- 侧重点:
- Lerobot 的核心侧重点在于易用性、标准化和社区协作。Lerobot 能够在下载数据的同时对其进行处理,显著降低了本地存储需求以及数据加载的启动时间,尤其适用于在云端或资源受限环境中开展训练工作。 SmolVLA 和 π0_fast是当前明确使用 LeRobot 数据格式训练的 VLA 模型。
3、RLDS
RLDS (Reinforcement Learning Datasets) 诞生于解决大规模强化学习研究中数据处理复杂性的需求,用于处理来自不同环境(模拟器、真实机器人)和不同任务的大量序列数据,并与 TensorFlow Datasets (TFDS) 紧密集成
- 结构
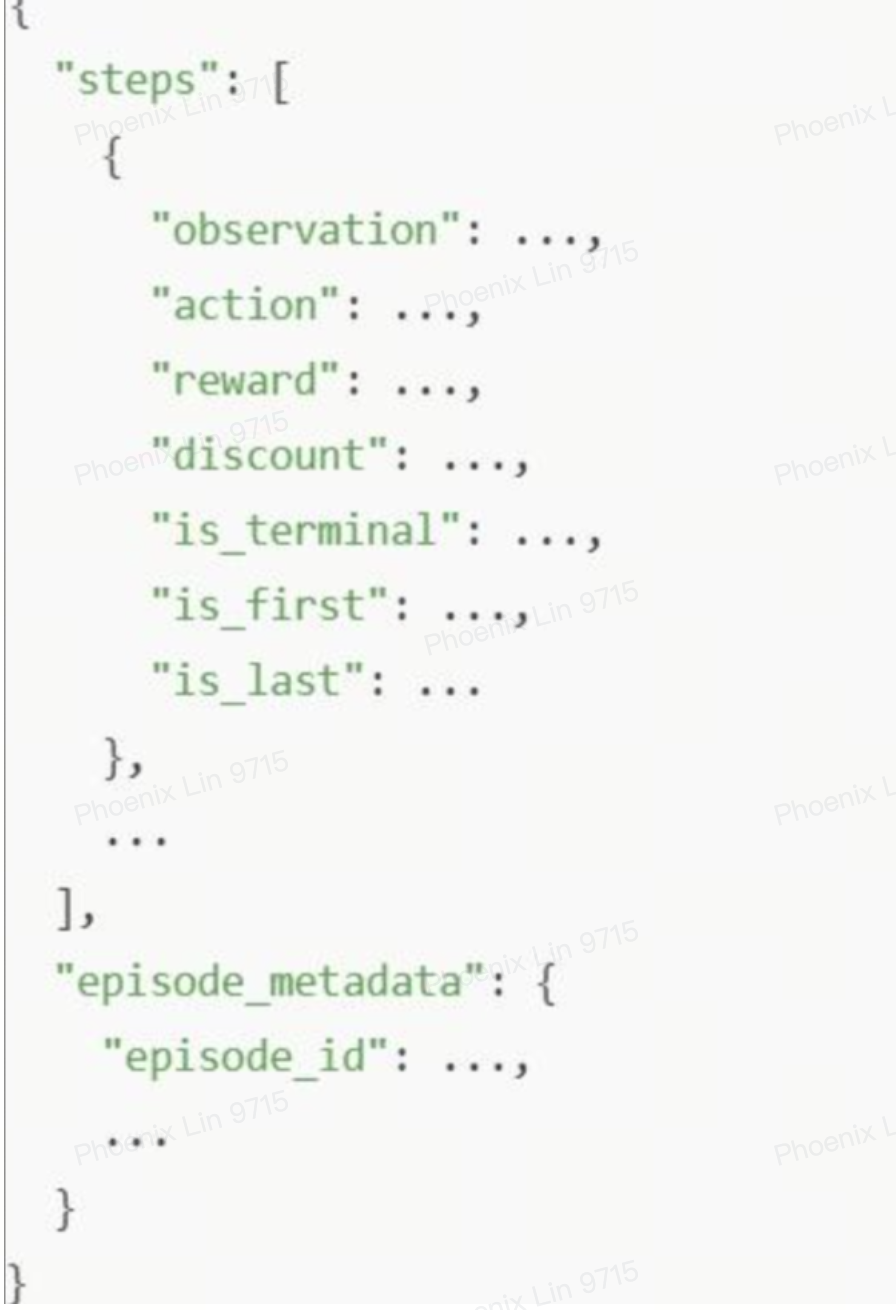
- 核心抽象:Episode 和 Step: RLDS 将所有数据都组织成序列 (episodes),每个序列由一系列的步骤 (steps) 组成
- 一个 step 通常是一个字典,包含在该时间点上的所有信息,如 observation(又可以是一个包含多个传感器数据的字典,如 image, state)、action、reward、is_first、is_last、is_terminal 等
- 一个 episode 就是这些 step 字典的序列
- TFDS集成:RLDS 通常与 TFDS 协同工作。TFDS 负责底层的数据存储和加载(其后端可以是 TFRecord 等格式),而 RLDS 在其上层提供强大的 API,用于将加载的数据转换为上述的 episode 和 step 结构,并支持复杂的序列转换操作,如 N-step 转换、窗口化(windowing)、轨迹重组(trajectory transforms)等
- 结构图
- 侧重点
- 强大的序列变换: 它提供了丰富的工具来处理时序依赖关系,这对于需要从离线数据中构建训练样本的离线强化学习(Offline RL)和模仿学习至关重要。例如,可以轻松地从一个完整的 episode 中,提取出固定长度的动作-观察窗口作为模型的输入
- 生态整合: 作为 TensorFlow 生态的一部分,RLDS 能够与 tf.data 无缝衔接,构建出高效、可扩展的输入管道,并能很好地支持 TPU 等硬件进行大规模训练
4、个人使用经验
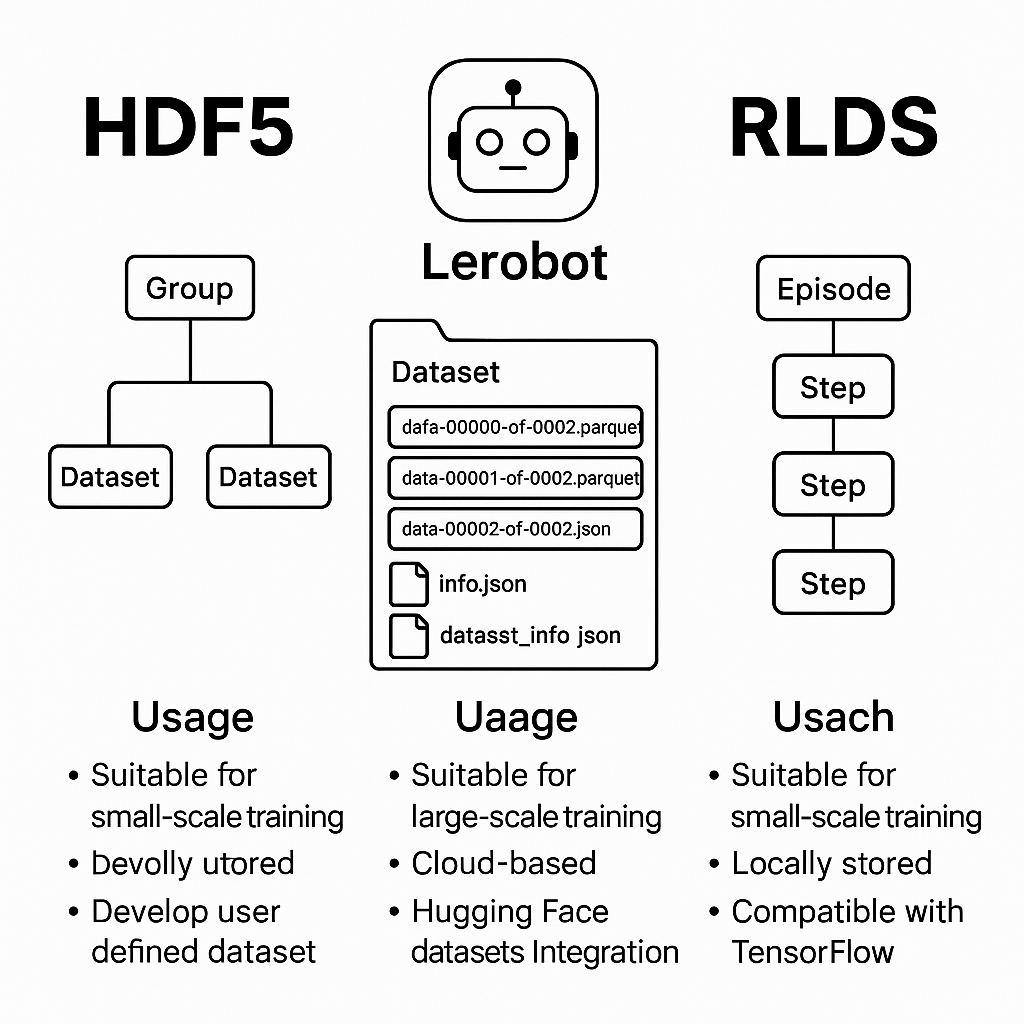
| 数据格式 | HDF5 | Lerobot | RLDS |
| 适用范围 | 适合少量数据训练,例如post-training阶段 需要自己开发相应dataset 可扩展性较高 |
适合大规模数据训练,例如pre-training阶段 高度配适Hugging Face dataset |
适合少量数据训练,例如post-training阶段 高度配适TensorFlow 架构 |
| 存储方式 | 少量数据本地存储 | 云端,缓解本地存储压力 (数据规模较大) | 少量数据本地存储 |
| 读取速度 | 较快 可进行slicing操作 | 较快,边下载边处理 | 很少使用tensor flow架构 未进行测试 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)