【必收藏】2025年多模态大模型前沿研究:10篇论文带你掌握大模型核心技术
多模态大模型研究进展综述 近期10篇多模态大模型研究论文取得重要突破,主要聚焦三大方向:1)架构创新,如Uni-X提出的"两端分离、中间共享"结构有效缓解模态冲突;2)感知增强,VTPerception-R1通过显式视觉文本锚定提升推理能力;3)高效优化,Vision Function Layer发现视觉功能层级规律,实现精准微调。这些研究在图像生成、视频理解等任务中表现优异,
本文汇总了10篇最新多模态大模型研究论文,涵盖Uni-X、VTPerception-R1、视觉功能层等创新方向,解决模态冲突、推理能力不足等问题。研究提出高效架构、感知锚定、视觉令牌压缩等方案,在图像生成、视频理解、3D认知等任务表现优异,为多模态大模型发展提供新思路,是程序员学习大模型技术的优质资源。
更多多模态基础模型、文生图、视觉问答、视频理解、视频生成、Image Captioning论文和涨点idea,
1.Uni-X: Mitigating Modality Conflict with a Two-End-Separated Architecture for Unified Multimodal Models
- 论文下载地址:https://arxiv.org/pdf/2509.24365
- 开源代码:https://github.com/CURRENTF/Uni-X
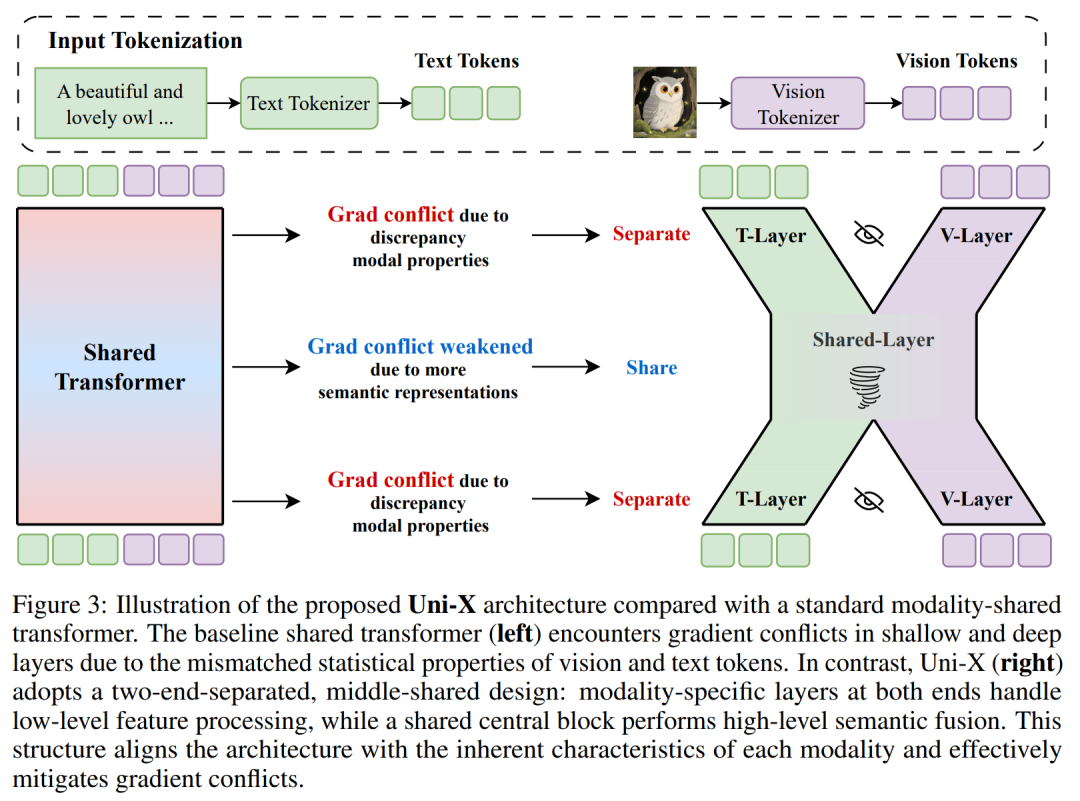
论文聚焦统一多模态模型(UMMs)的模态冲突问题。现有基于共享自回归(AR)Transformer 的 UMMs 存在缺陷:浅、深层因图文低阶统计特性差异大,出现严重梯度冲突,仅中层因语义抽象化冲突较弱。
为此,团队提出 “两端分离、中间共享” 的 Uni-X 架构:浅、深层用模态专属参数处理图文低阶差异,中层共享参数实现高阶语义融合。
实验显示,相同训练条件下,Uni-X 训练效率更优;3B 参数规模(配更大训练数据)时,GenEval 图像生成得分达 82,文本与视觉理解任务表现比肩甚至超越 7B 参数 AR 类 UMMs,为高效、可扩展的多模态建模提供新基础。
2.VTPerception-R1: Enhancing Multimodal Reasoning via Explicit Visual and Textual Perceptual Grounding
- 论文下载地址:https://arxiv.org/pdf/2509.24776
- 开源代码(即将开源):https://github.com/yizhuoDi/VTPerceprion-R1
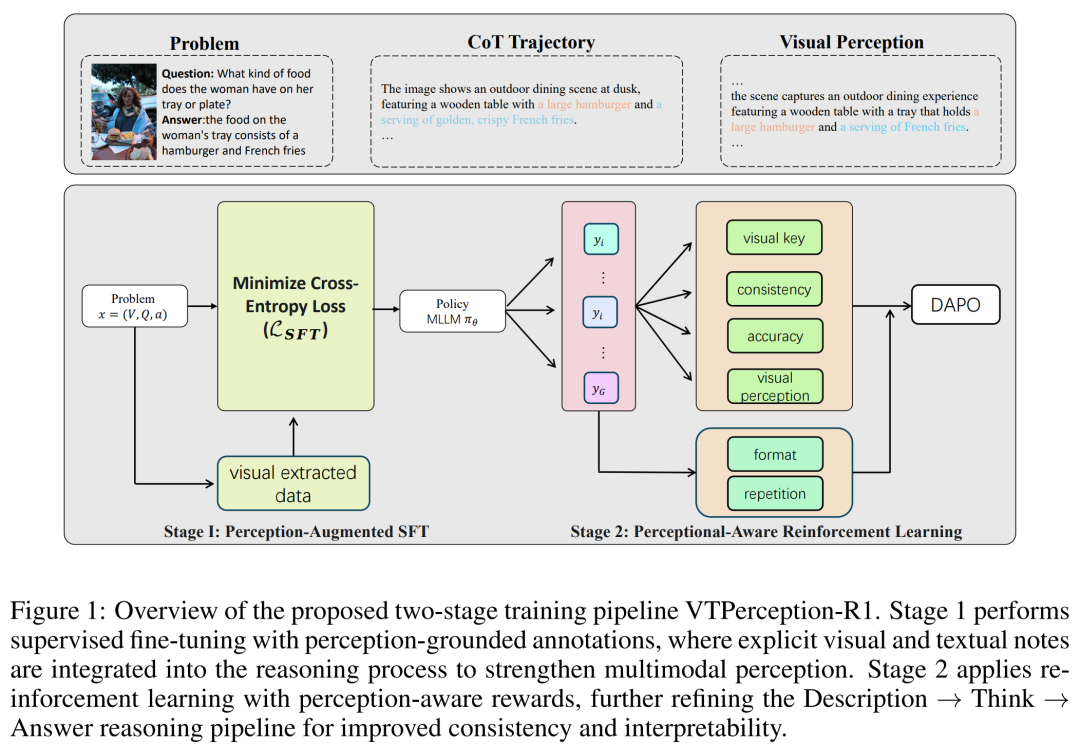
论文聚焦多模态大语言模型(MLLMs)推理难以锚定感知证据的问题。研究通过在 4 个基准数据集(MMMU、MathVista 等)、2 个模型(Qwen2.5-VL-32B/7B)上的系统实验,发现显式感知(尤其结合文本线索)能持续提升推理性能,对小模型效果更显著。
据此提出两阶段 VTPerception-R1 框架:第一阶段通过感知增强监督微调,让模型生成任务相关的感知描述后再推理;第二阶段基于 DAPO 算法,引入视觉关键信息、文本关键信息及一致性奖励的感知感知强化学习。
实验显示,该框架在多任务上显著提升推理精度与鲁棒性,3B 规模模型性能可媲美部分 7B 模型,为感知锚定的多模态推理提供有效方案。
3.(NeurIPS2025)Vision Function Layer in Multimodal LLMs
- 论文下载地址:https://arxiv.org/pdf/2509.24791
- 开源代码:https://github.com/ChengShiest/Vision-Function-Layer
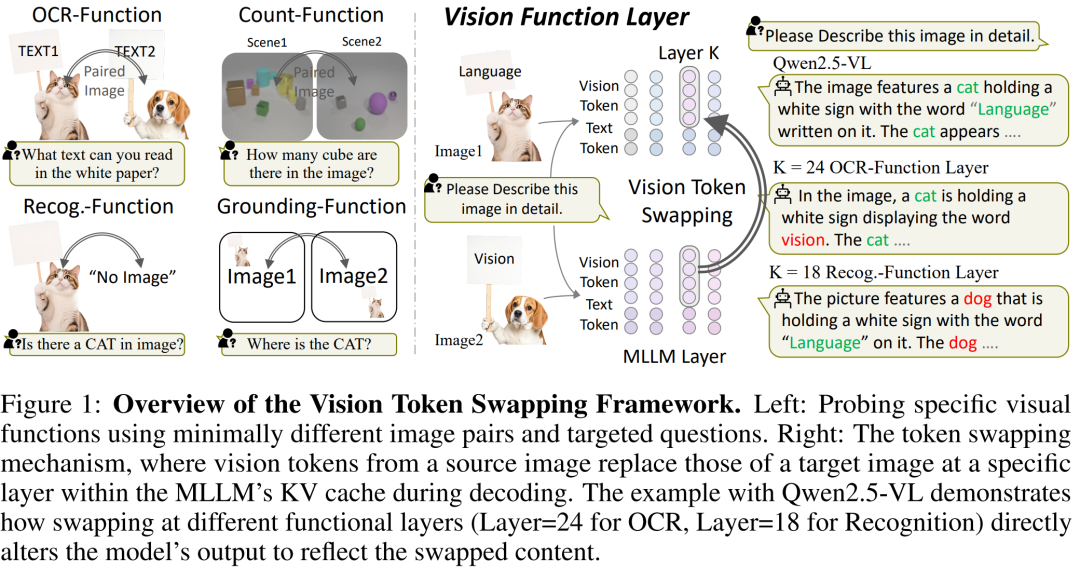
论文聚焦多模态大语言模型(MLLMs)视觉功能的层间分布规律。研究提出 “视觉功能层(VFL)” 概念,发现计数、定位、OCR 等视觉功能集中于 2-3 个特定解码器层,且不同 VFL 的深度顺序在不同 MLLMs 中高度一致(如识别层最早、OCR 层最晚),与人类认知逻辑契合。
为验证该发现,团队设计 “视觉令牌交换” 与 “令牌丢弃” 分析框架,精准定位各功能对应的层级。基于此,提出 VFL-LoRA 微调策略,仅针对目标功能对应的 VFL 层微调,参数量减半仍保持性能;VFL-Select 数据选择方法凭 20% 数据实现 98% 全量数据性能,且优于人类专家筛选结果,为 MLLMs 的高效优化与可解释性提升提供新方向。
4.(NeurIPS2025)VT-FSL: Bridging Vision and Text with LLMs for Few-Shot Learning
- 论文下载地址:https://arxiv.org/pdf/2509.25033
- 开源代码:https://github.com/peacelwh/VT-FSL
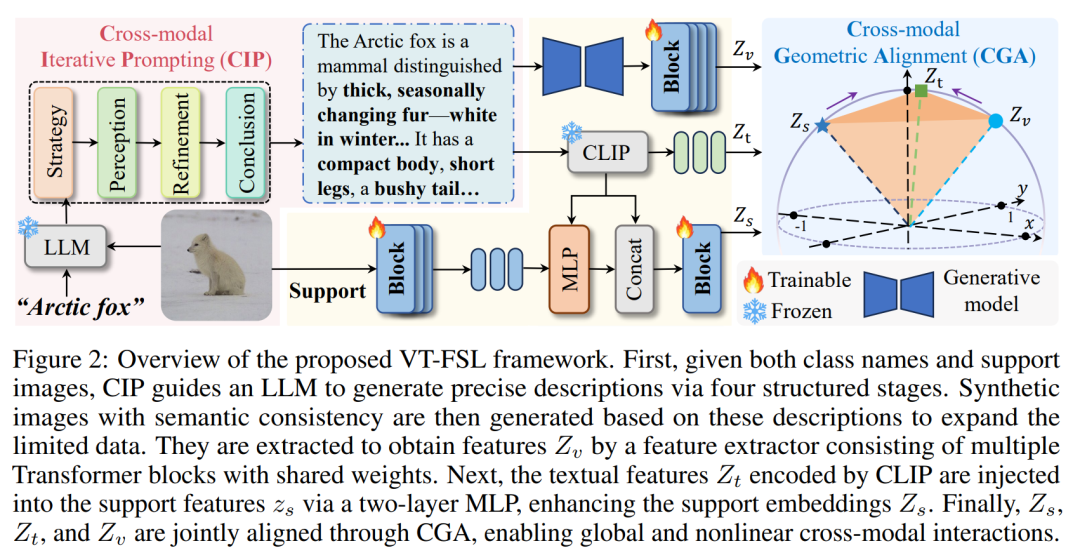
论文聚焦少样本学习(FSL)中标签样本有限导致的语义偏差与泛化能力弱问题。现有方法常因缺乏视觉证据锚定产生语义幻觉,VT-FSL 通过大语言模型(LLMs)构建精准跨模态提示并几何对齐,有效解决此问题。
框架含两大核心模块:跨模态迭代提示(CIP)结合类别名与支持图像,经策略、感知等四阶段生成精准类描述,驱动语义一致图像零样本合成;跨模态几何对齐(CGA)通过最小化核化平行六面体体积,对齐文本、支持图像与合成图像特征,捕捉全局非线性关系。
实验显示,VT-FSL 在 10 个基准数据集(含标准、跨域、细粒度场景)上达 SOTA,平均准确率提升 4.2%,20% 数据即可实现 98% 全量数据性能。
5.Visual Jigsaw Post-Training Improves MLLMs
- 论文下载地址:https://arxiv.org/pdf/2509.25190
- 工程主页:https://penghao-wu.github.io/visual_jigsaw
- 开源代码:https://github.com/penghao-wu/visual_jigsaw
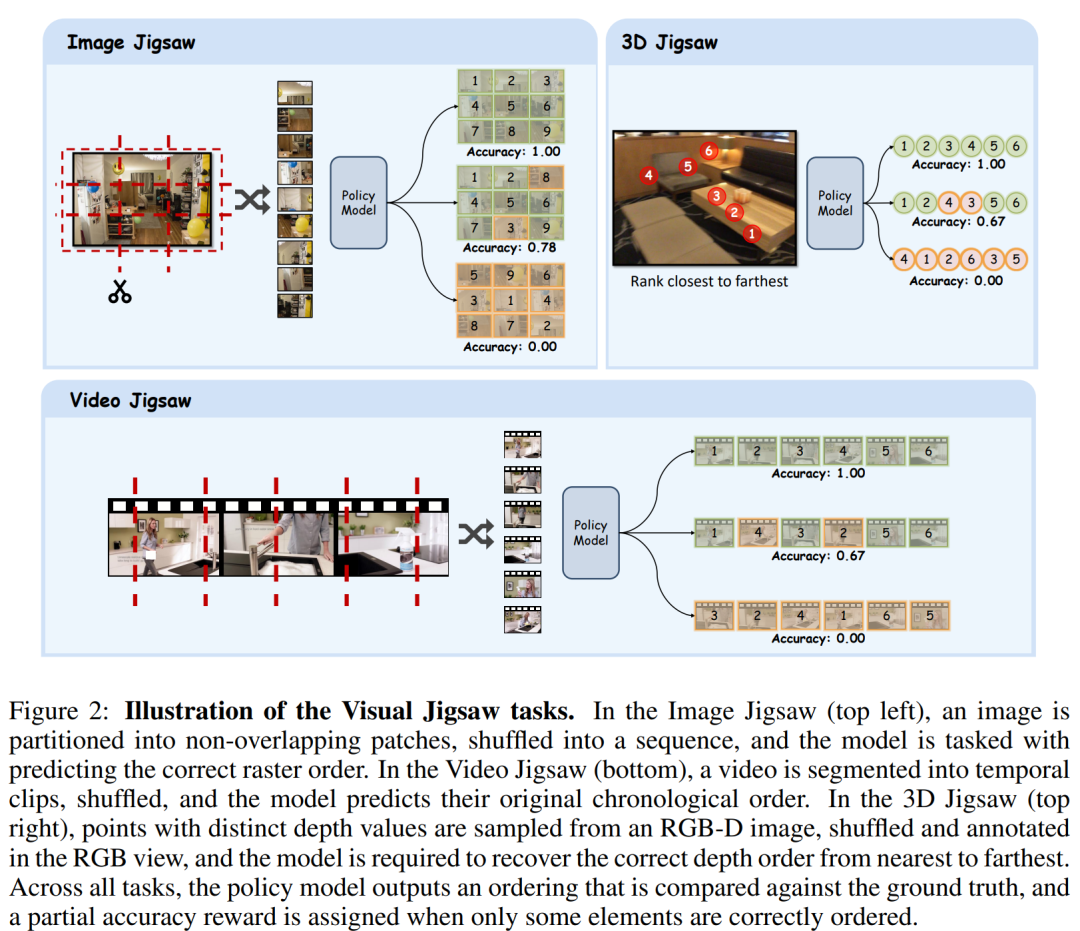
论文针对多模态大语言模型(MLLMs)现有后训练多为文本中心、视觉理解不足的问题,设计了自监督的 Visual Jigsaw 框架。
其核心是将视觉理解转化为排序任务:对图像、视频、3D 数据等视觉输入进行分割、打乱,让模型用自然语言输出正确排列顺序。该框架无需额外视觉生成组件,监督信号自动获取,且适配可验证奖励强化学习(RLVR)。
实验以 Qwen2.5-VL-7B 为基础模型,经 GRPO 算法训练后,在图像细粒度感知、视频时序推理、3D 空间理解任务上均获显著提升,如 3D 任务中 DA-2K 数据集准确率提高 17.11%。同时,该框架还能在增强视觉能力的同时,保留模型原有推理能力,为 MLLMs 视觉能力优化提供新路径。
6.UniVid: Unifying Vision Tasks with Pre-trained Video Generation Models
- 论文下载地址:https://arxiv.org/pdf/2509.21760
- 开源代码(即将开源):https://github.com/CUC-MIPG/UniVid
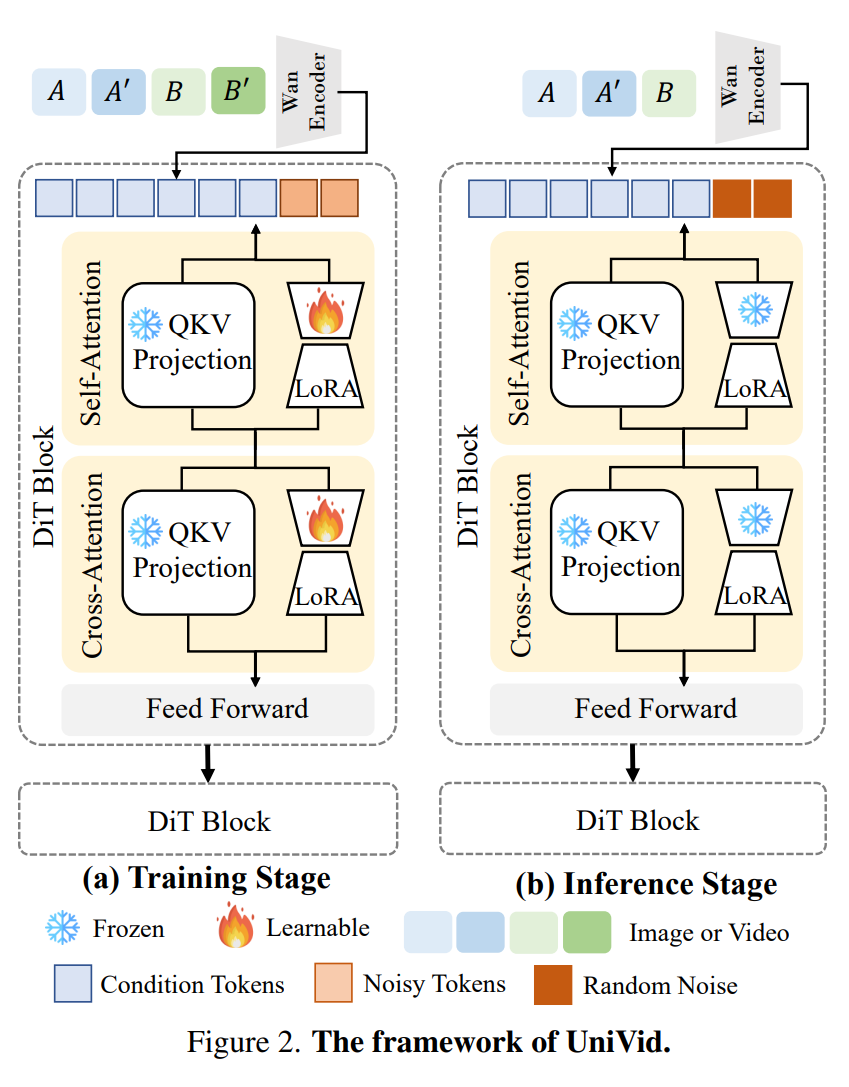
论文旨在解决现有大型视觉模型(LVM)需任务 / 模态专属预训练、成本高且扩展性弱的问题,探索预训练视频生成模型适配多视觉任务的可能性。
框架以视频扩散 Transformer(Wan 模型)为基础,通过轻量级监督微调(SFT)与 LoRA 模块,无需任务专属架构修改,将图像、视频任务统一为 “视觉句子”:以示例对 (A,A’) 和查询 B 构成上下文,预测输出 B’。
实验显示,仅经自然视频预训练的 UniVid,能高效适配跨模态(图像 - 视频混合上下文)与跨数据源(自然数据到标注数据)任务,且反转视觉句子顺序即可切换理解与生成任务。在风格迁移、深度估计等 6 类任务上,其性能优于 LVM,验证了预训练视频生成模型作为通用视觉基础模型的潜力。
7.ERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models
- 论文下载地址:https://arxiv.org/pdf/2509.21991
- 开源代码:https://github.com/nota-github/ERGO
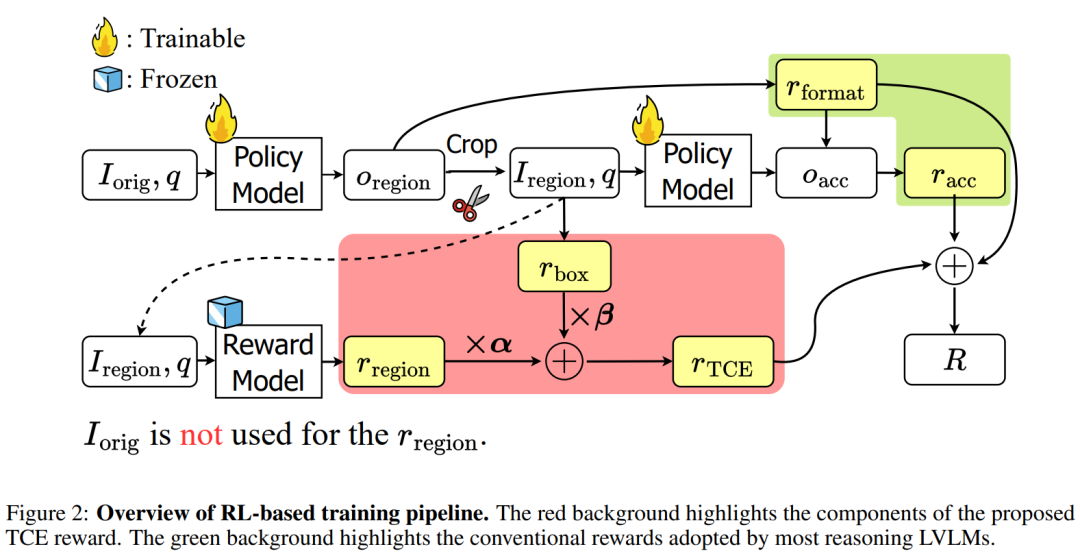
论文针对现有视觉语言模型(LVLMs)处理高分辨率图像时视觉令牌多、计算成本高,且低分辨率输入下易丢失细节的问题,设计了 ERGO 框架。
ERGO 采用 “粗到细” 两阶段推理流程:先分析低分辨率图像定位任务相关区域,再对这些区域进行全分辨率裁剪和后续推理。其核心是强化学习框架下的奖励设计,包括区域验证奖励(仅用裁剪区域和查询评估任务性能)、框调整奖励( penalize 过大裁剪区域),二者结合形成任务驱动上下文探索(TCE)奖励,还融入准确性和格式奖励优化最终性能。
实验以 Qwen2.5-VL-7B 为基础模型,在 V等基准测试中,用 23% 视觉令牌实现 3 倍推理加速,V基准得分超 Qwen2.5-VL-7B 4.7 分,兼顾高效性与准确性。
8.(NeurIPS2025)Unveiling Chain of Step Reasoning for Vision-Language Models with Fine-grained Rewards
- 论文下载地址:https://arxiv.org/pdf/2509.19003
- 开源代码:https://github.com/baaivision/CoS
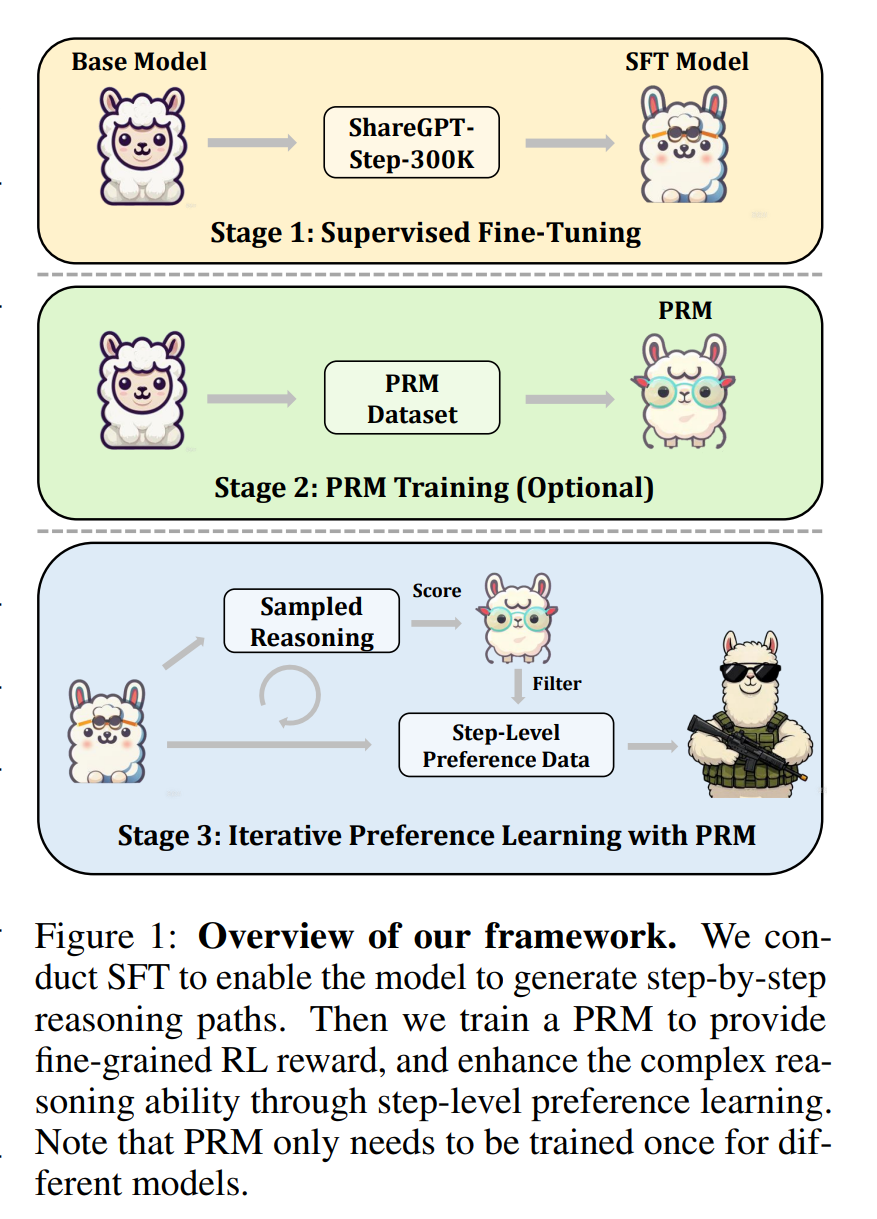
论文针对现有视觉语言模型(VLMs)思维链推理粗粒度、中间步骤难评估的问题,提出 “分步推理(CoS)” 框架,实现对推理步骤质量的精准评估与强化学习优化。
框架核心包括:设计含 “名称 - 思考 - 反思” 三组件的结构化推理模板,构建 30 万条多任务分步推理数据集 ShareGPT-Step-300K;通过蒙特卡洛估计与 LLM-as-Judge 生成步骤级标注数据,训练过程奖励模型(PRM)以提供细粒度奖励;基于 PRM 进行迭代直接偏好优化(DPO),提升模型推理能力。
实验显示,CoS 在 MathVista、MMMU 等 6 个基准测试中表现优异, InternVL-2.5-MPO 结合 CoS 后平均得分达 73.4%。同时发现,VLMs 推理质量比长度更重要,平衡步骤与答案评估更利于性能提升,为多模态复杂推理提供新方向。
9.Reading Images Like Texts: Sequential Image Understanding in Vision-Language Models
- 论文下载地址:https://arxiv.org/pdf/2509.19191
- 开源代码:https://github.com/Siriuslala/vlm_interp
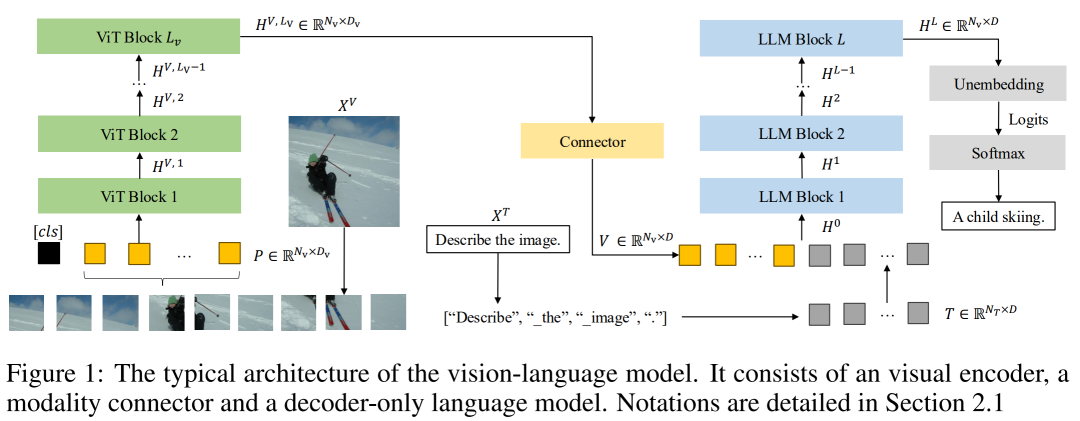
论文针对现有视觉语言模型(VLMs)以序列化方式处理图像、与人类视觉并行处理特性差异大,且内部机制不透明的问题,受人类视觉双通路假说启发,从目标识别(“是什么” 通路)与空间感知(“在哪里” 通路)两方面解析 VLMs 视觉处理机制。
研究发现,目标识别中,模型将图像转为文本令牌图,视觉编码器从浅层到深层呈 “属性识别 - 语义消歧” 两阶段处理;空间感知上,理论推导并验证了位置表示的几何结构,2D RoPE 通过正交子空间编码水平 / 垂直方向关系。
基于此,提出指令无关令牌压缩算法(通过视觉解码器与游程编码减少推理 tokens)和 RoPE 缩放技术(增强低频区域位置信息)。实验显示,令牌压缩使推理速度提升,RoPE 缩放增强空间推理,为 VLMs 视觉理解机制解析与性能优化提供新方向。
10.Visual Instruction Pretraining for Domain-Specific Foundation Models
- 论文下载地址:https://arxiv.org/pdf/2509.17562
- 开源代码:https://github.com/zcablii/ViTP
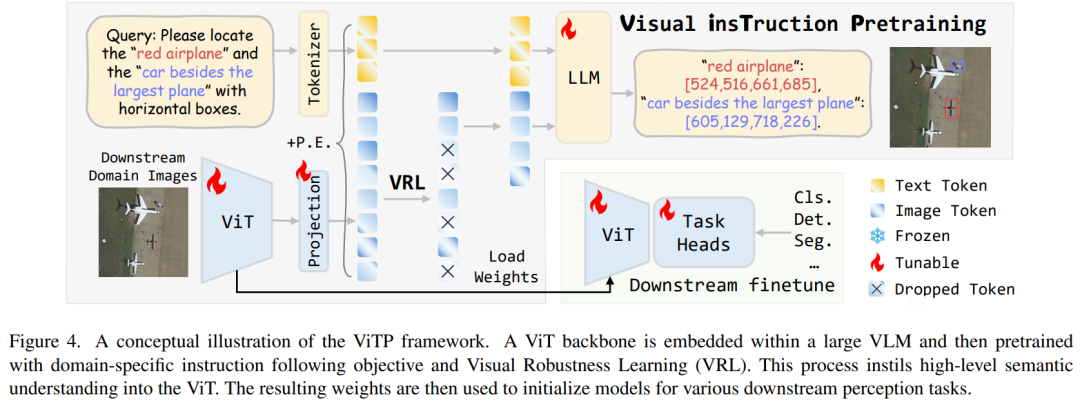
论文针对现有视觉基础模型预训练多为 “自下而上”、缺乏高层推理对低层感知的指导,且在遥感、医疗等专用领域泛化差的问题,提出视觉指令预训练(ViTP)范式。
ViTP 将 ViT 骨干网络嵌入视觉语言模型(VLM),基于目标领域的视觉指令数据进行端到端预训练,通过 LLM 生成响应作为监督信号,引导 ViT 学习领域相关特征。同时提出视觉鲁棒性学习(VRL),随机丢弃大量视觉令牌,迫使 ViT 在稀疏令牌中编码更全面信息。
实验在 16 个遥感与医疗影像基准测试中,ViTP 均创 SOTA,如遥感 SAR 目标检测 mAP 达 59.7,医疗 AMOS2022 分割 mDice 达 90.6。其预训练仅需 8 张 A40 GPU 训练 1 天,且低数据量下仍表现优异,为领域专用视觉基础模型提供高效解决方案。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
完整的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
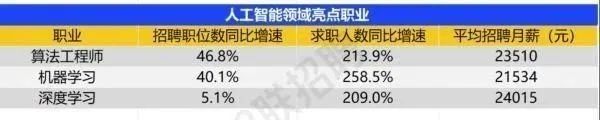
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程⑤⑥
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献666条内容
已为社区贡献666条内容

所有评论(0)