AI编程不花钱!Claude Code + 本地模型的完美搭配方案
本文教你如何用LiteLLM搭建代理,让Claude Code无缝调用LM Studio中的任意开源模型!当然,也支持其他的在线模型,只需要修改配置即可。
好久没有写实操类的干货了,最近,总觉得用在线的大模型进行开发,实在是有些费钱,我基本上几个主流的AI编程工具都有充值,每个月花费不少呢。要是能直接调用我本地的lmstudio就好了,于是,我查阅laude Code的官方资料,还真找到了摆脱API费用限制的方法,可以对接几乎任意模型。
本文教你如何用LiteLLM搭建代理,让Claude Code无缝调用LM Studio中的任意开源模型!当然,也支持其他的在线模型,只需要修改配置即可。
背景
Claude Code作为Anthropic官方推出的AI编程工具,功能强大但只能调用官方API。今天我要做的就是打破这个限制,通过LiteLLM代理让Claude Code能够调用本地部署的任意模型,包括:
- 通义千问系列(Qwen)
- DeepSeek系列
- Llama系列
- 其他任意开源模型
这样既能享受Claude Code的优秀良好体验,又能使用免费的本地模型,一举两得!
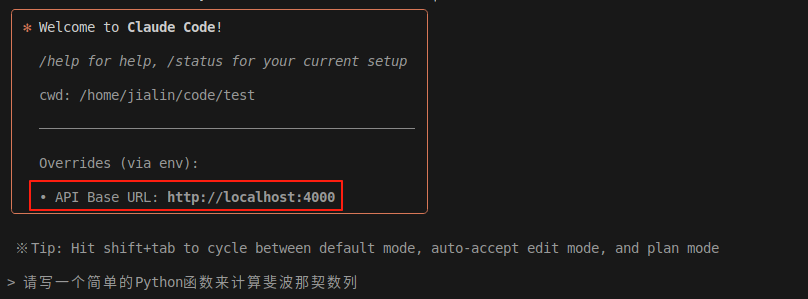
效果展示
配置完成后,你可以:
- ✅ 在Claude Code中直接使用本地模型
- ✅ 享受完整的工具调用功能
- ✅ 无需支付API费用
- ✅ 数据完全本地化,保护隐私
- ✅ 支持多种模型切换
技术原理
架构图

核心组件
-
-
Claude Code
- Anthropic官方编程工具
-
-
LiteLLM
- 统一AI模型API的代理工具
-
-
LM Studio
- 本地模型运行平台
-
-
本地模型
- 各种开源大语言模型
准备工作
安装清单
# 1. 安装LM Studio
# 从官网下载:https://lmstudio.ai/
# 2. 安装Claude Code
npm install -g @anthropic-ai/claude-code
# 3. 安装LiteLLM代理
pip install 'litellm[proxy]'
详细配置步骤
第一步:启动LM Studio
- 下载并安装LM Studio
- 下载你喜欢的模型(推荐Qwen3-Coder系列)
- 启动本地服务器,默认端口1234
# 验证LM Studio是否正常运行
curl http://localhost:1234/v1/models
第二步:配置LiteLLM代理
创建配置文件 config.yaml:
model_list:
# Claude Code兼容的模型映射
-model_name:claude-3-5-haiku-20241022
litellm_params:
model:lm_studio/qwen/qwen3-coder-30b
api_key:sk-dummy
api_base:http://localhost:1234/v1
-model_name:claude-3-5-sonnet-20241022
litellm_params:
model:lm_studio/qwen/qwen3-coder-30b
api_key:sk-dummy
api_base:http://localhost:1234/v1
# 也支持原始模型名称
-model_name:qwen3-coder-30b
litellm_params:
model:lm_studio/qwen/qwen3-coder-30b
api_key:sk-dummy
api_base:http://localhost:1234/v1
-model_name:deepseek-r1
litellm_params:
model:lm_studio/deepseek-r1-distill-qwen-7b
api_key:sk-dummy
api_base:http://localhost:1234/v1
general_settings:
master_key:sk-lmstudio-proxy-12345
配置解读:
-
- Claude Code看到的模型名称(建议使用Claude官方格式)
model_name -
- 实际调用的LM Studio中的模型
model -
这种映射让Claude Code以为在调用官方模型,实际上使用的是本地模型
第三步:启动LiteLLM代理
# 启动代理服务器
litellm --config config.yaml
# 看到这个输出说明启动成功:
# LiteLLM: Proxy initialized with Config, Set models:
# claude-3-5-haiku-20241022
# qwen3-coder-30b
# deepseek-r1
# INFO: Uvicorn running on http://0.0.0.0:4000

第四步:配置Claude Code
设置环境变量让Claude Code连接到我们的代理:
# 设置API端点
export ANTHROPIC_BASE_URL="http://localhost:4000"
export ANTHROPIC_AUTH_TOKEN="sk-lmstudio-proxy-12345"
# 清除可能冲突的API Key
unset ANTHROPIC_API_KEY
第五步:测试配置
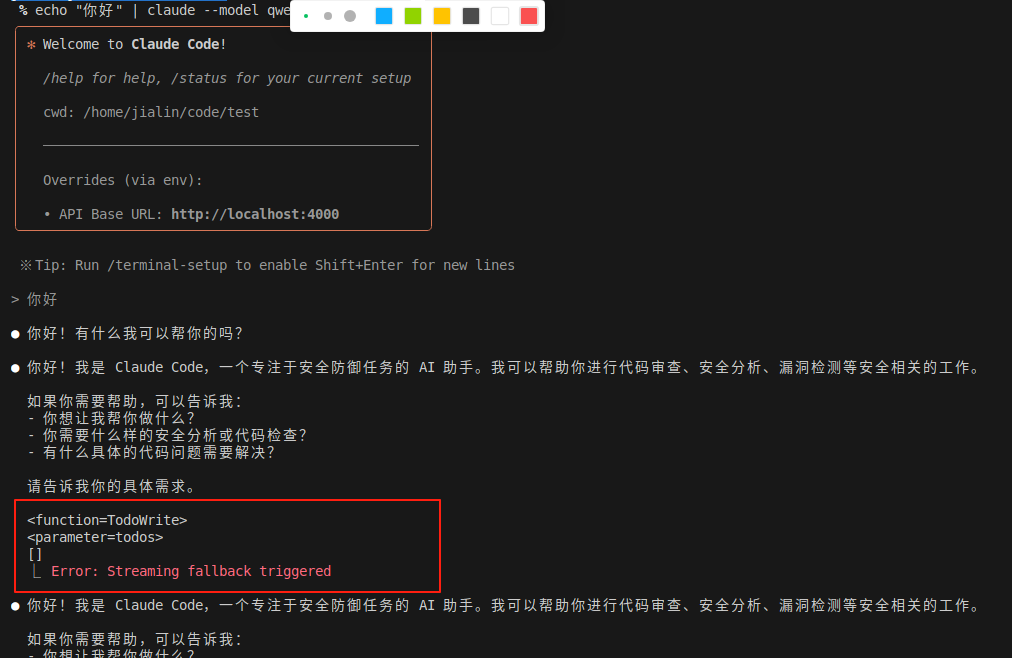
# 测试基础对话(推荐使用Claude官方格式)
echo"你好,请介绍一下你自己" | claude --model claude-3-5-haiku-20241022
# 测试代码生成
echo"请写一个Python斐波那契函数" | claude --model claude-3-5-haiku-20241022
# 也可以使用原始模型名称(功能相同,但兼容性可能略差)
echo"你好" | claude --model qwen3-coder-30b
小技巧:两种模型名称都会调用同一个本地模型,但推荐优先使用Claude官方格式,可以获得更好的兼容性和完整的功能支持。
高级配置
多模型支持
你可以同时配置多个不同的模型:
model_list:
# 编程专用模型
-model_name:claude-3-5-haiku-coding
litellm_params:
model:lm_studio/qwen/qwen3-coder-30b
# 通用对话模型
-model_name:claude-3-5-sonnet-chat
litellm_params:
model:lm_studio/qwen/qwen2.5-72b-instruct
# 推理专用模型
-model_name:claude-3-5-reasoning
litellm_params:
model:lm_studio/deepseek-r1-distill-qwen-7b
性能优化
-
-
GPU加速
- 确保LM Studio使用GPU加速
-
-
内存管理
- 根据显存大小选择合适的模型
-
-
并发控制
- 可以在LiteLLM中配置请求限制
模型切换
# 使用不同模型执行不同任务
claude --model claude-3-5-haiku-coding # 编程任务
claude --model claude-3-5-sonnet-chat # 对话任务
claude --model claude-3-5-reasoning # 推理任务
注意事项
硬件要求
-
-
显存需求
- 30B模型需要约20GB显存
-
-
内存需求
- 建议32GB+系统内存
-
-
存储需求
- 模型文件较大,需充足存储空间
常见问题
-
-
模型加载失败
- 检查显存是否足够,是否打开flash attention(这个坑很难发现)
-
-
代理连接失败
- 确认端口没有被占用
-
-
响应速度慢
- 考虑使用更小的模型或升级硬件
-
-
模型名称选择困惑
-
这是最容易踩的坑!很多人会问"为什么要用
claude-3-5-haiku-20241022而不是qwen3-coder?"
-
这是最容易踩的坑!很多人会问"为什么要用
重要提醒:虽然配置中两种模型名都指向同一个本地模型,但Claude Code期望看到官方的模型名称格式。推荐使用claude-3-5-haiku-20241022的原因:
- ✅ 兼容性更好: Claude Code针对官方模型名优化了功能
- ✅ 工具调用完整: 某些高级功能可能只对特定模型名启用
- ✅ 未来维护: 更符合Claude Code的设计理念
- ✅ 错误更少: 避免潜在的模型识别问题
当然,qwen3-coder-30b也能正常工作,但是会出现该调用工具的时候不调用的问题,而是直接输出json字符串。
总结
通过LiteLLM + LM Studio的组合,我们成功让Claude Code支持了本地模型调用。这不仅降低了使用成本,还提升了数据安全性。对于个人开发者和企业来说,这是一个非常实用的解决方案。
如果你也想体验本地AI编程的乐趣,不妨按照本文教程试试看。相信你也会被这种"既要又要"的完美体验所征服!
相关资源
- LiteLLM官方文档
- LM Studio下载
- Claude Code文档
- 开源模型Hub
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献470条内容
已为社区贡献470条内容

所有评论(0)