ComfyUI × Qwen-Image-Edit Plus :本地部署教程,让大家自由创作,无限灵感随心掌控!
阿里巴巴近日推出Qwen-Image-Edit-2509图像编辑模型,支持本地8G显存部署。文章详解了在ComfyUI中配置该模型的完整流程:需加载UNet、LoRA、VAE和CLIP四个核心组件,通过多图输入和文本提示实现姿态调整、服装替换等编辑功能。实测显示8G显存下生成时间约2分钟,并提供了人物换装、动物场景融合等案例展示。该方案突破平台限制,支持本地自由创作,读者可获取官方工作流进一步探索
前两天阿里巴巴放出了一系列的大招,推出了将近7款模型。对于图像生成编辑模型Qwen-image-edit也进行更新。自从8月份的qwen-iamge 到现在Qwen-image-Edit-2509,目前图像编辑领域还是比较火热。至于相关的模型,我前面的文章也有给大家介绍,这里就不过多赘述。
今天主要跟大家分享下,采用个人私有电脑(8G)显存,将Qwen-iamge-edit2509模型结合本地的 ComfyUI进行私有化部署, 通过设置ComfyUI工作流,结合模型的‘多图编辑’、‘增强一致性’、‘高级文本编辑’、‘ControlNet 集成’等特点,进行任意图像编辑生成。大白话,都已经部署到本地,不受平台以及模型的限制,想怎么玩都可以!!!
目前8G现存,出图的效率基本在2分钟左右,速度还是可以的!
这里写目录标题
流程图如下
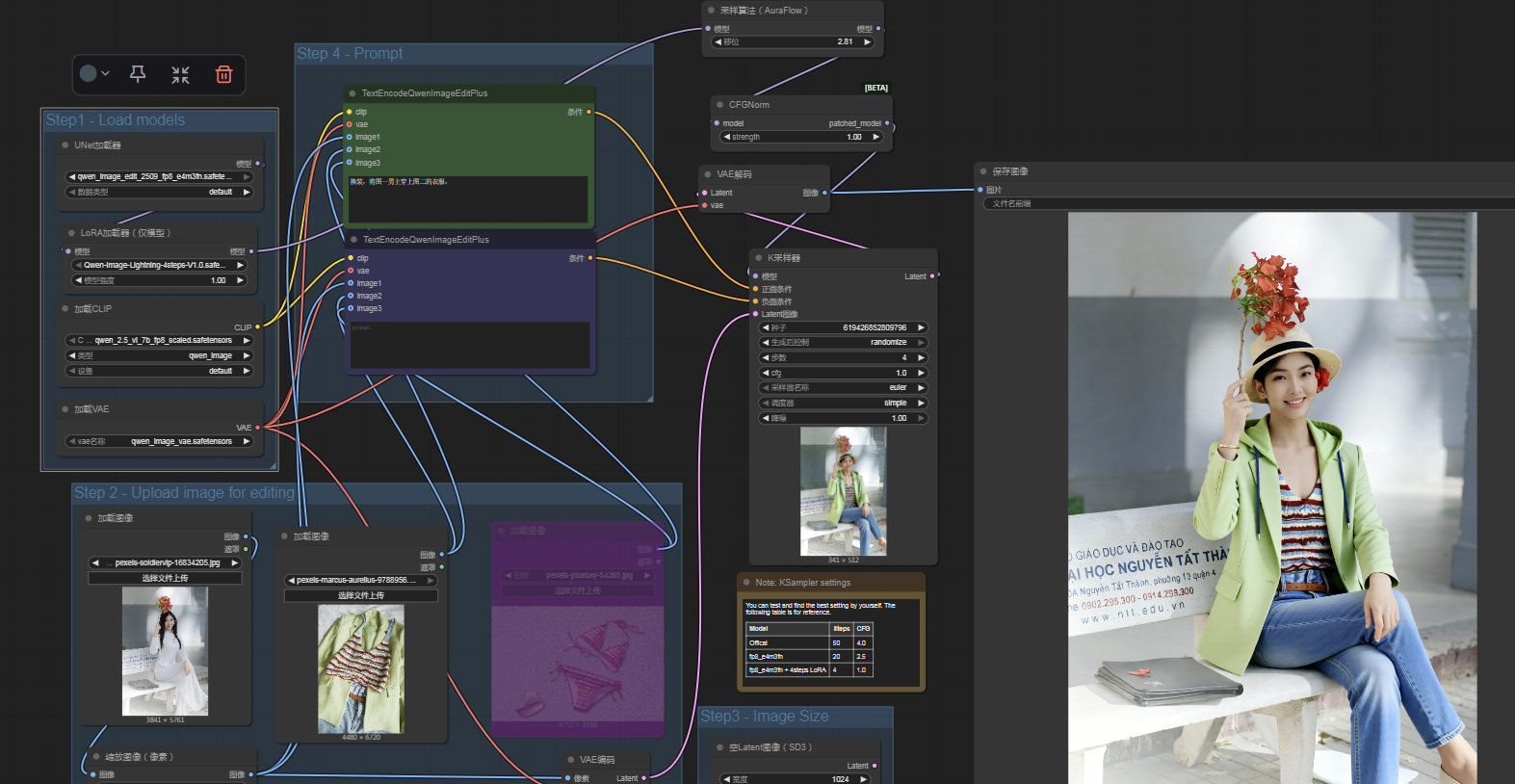
一、第一步模型加载
主要用的模型有四个,不过前面如果有用过qwen-image的小伙伴应该都有 看LoRA、CLIP以及VAE模型。没有也没关系,根据实际情况下载即可。
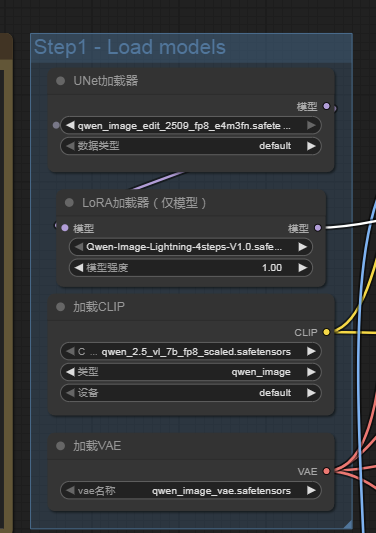
- Unet 加载器:主要是加载最新
qwen_image_edit_2509_fp8_e4m3fn.safetensors模型进行去噪处理。
Huggingface 下载地址:qwen_image_edit_2509_fp8_e4m3fn.safetensors
ModelScope下载地址:qwen_image_edit_2509_fp8_e4m3fn.safetensors
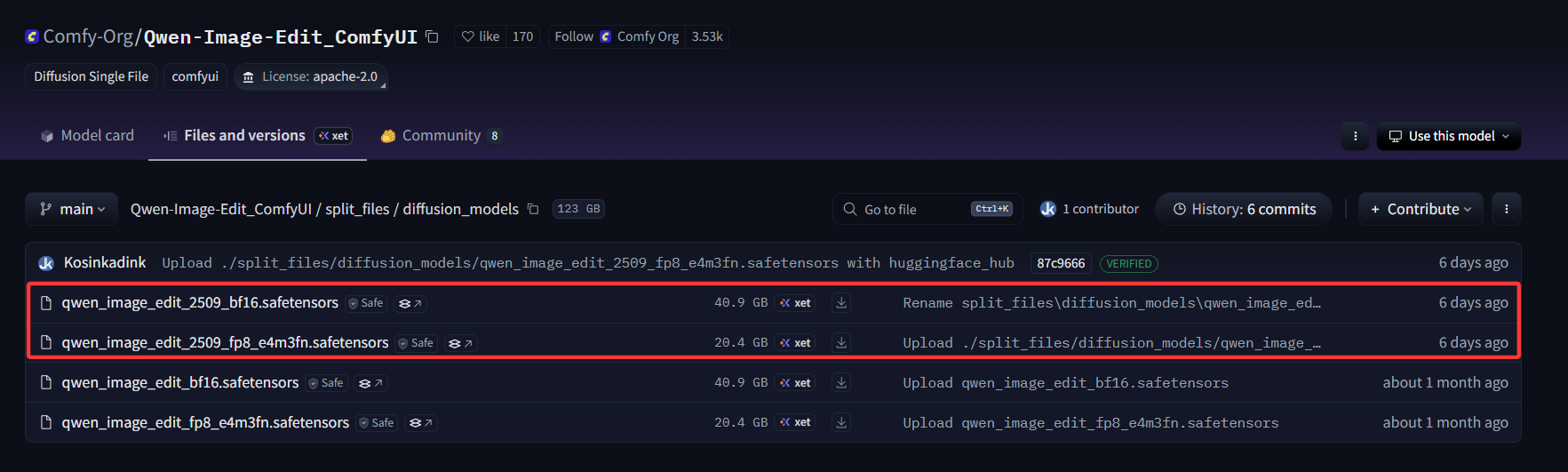
根据实际情况下载模型,目前博主使用的是FP8精度的,有条件的小伙伴可以选择BF16,效果会更好!
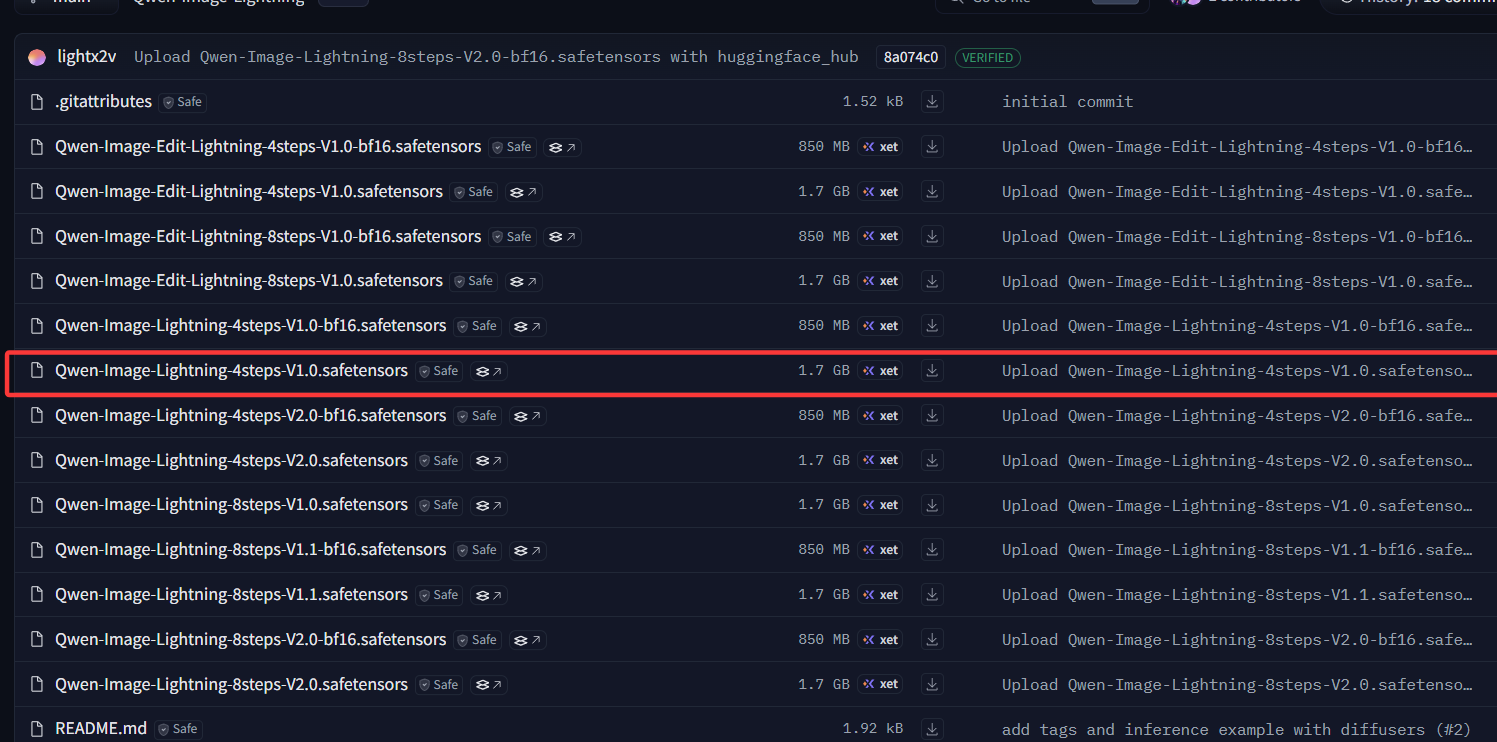
- LORA模型:还是选用的
Qwen-Image-Lightning-4steps-V1.0.safetensors模型进行微调
Huggingface 下载地址:Qwen-Image-Lightning-4steps-V1.0.safetensors
ModelScope下载地址:Qwen-Image-Lightning-4steps-V1.0.safetensors’
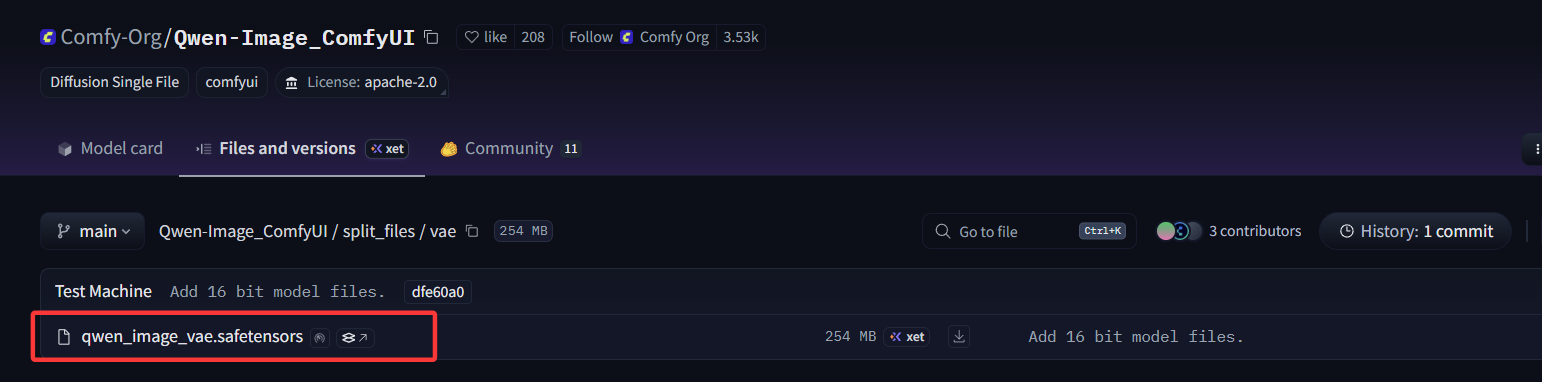
- VAE解码器:采用的是
qwen_image_vae.safetensors模型。
Huggingface 下载地址:qwen_image_vae.safetensors
ModelScope下载地址:qwen_image_vae.safetensors
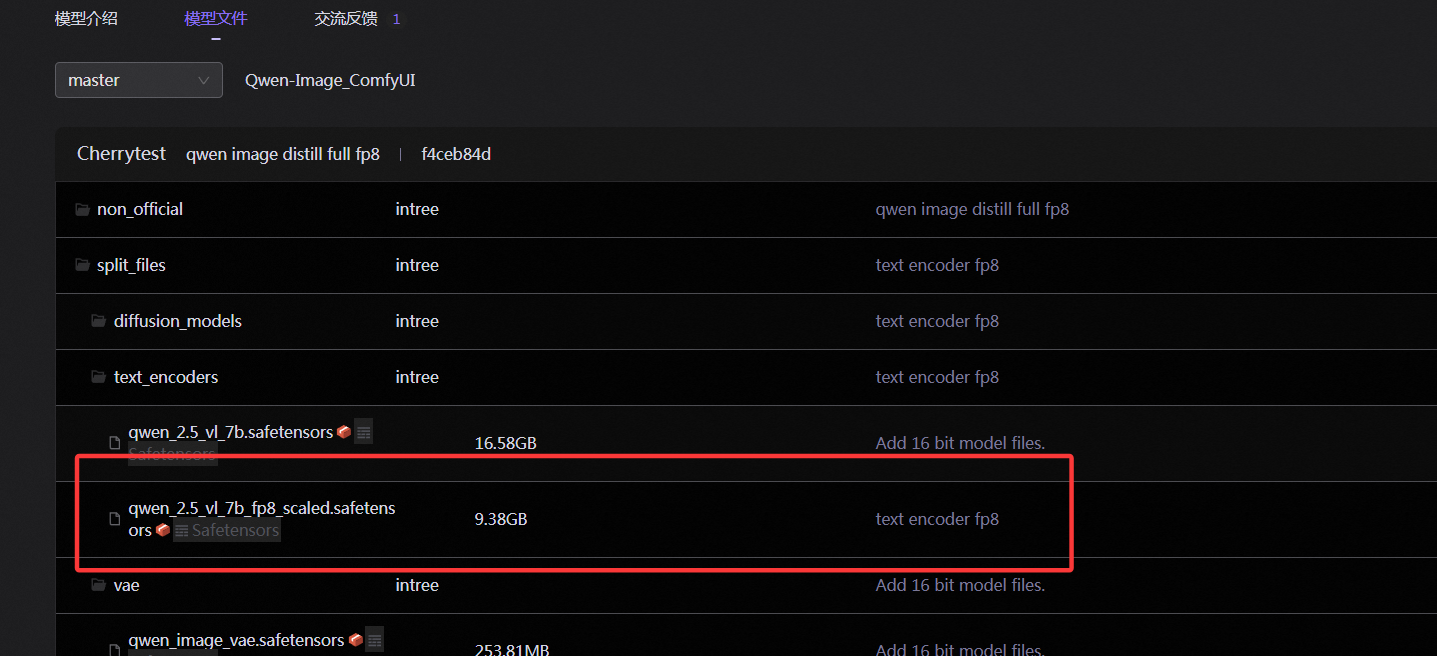
- Text Encoder采用的是
qwen_2.5_vl_7b_fp8_scaled.safetensors模型,将提示词转换为浅空间的向量。
Huggingface 下载地址:qwen_2.5_vl_7b_fp8_scaled.safetensors
ModelScope下载地址:qwen_2.5_vl_7b_fp8_scaled.safetensors
二、图像加载以及Prompt配置
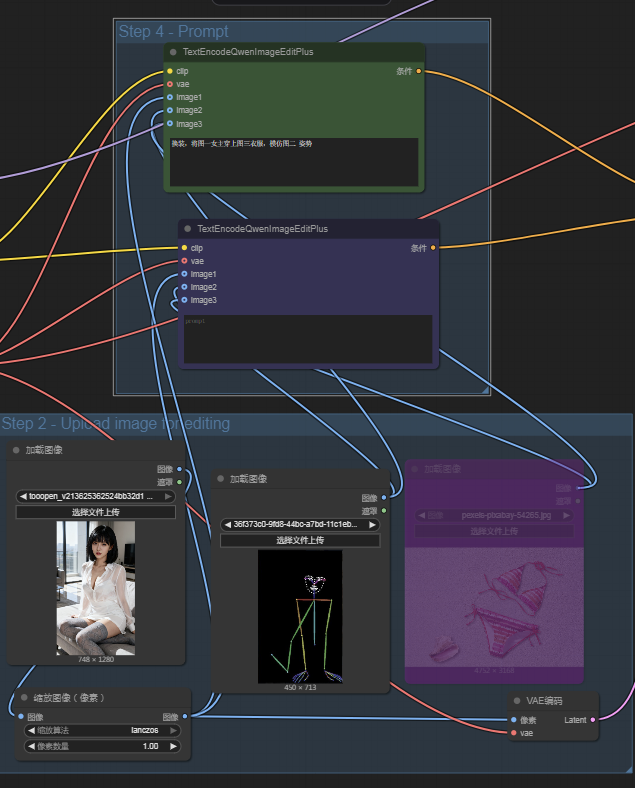
其实,这两个部分都是相辅相成的,我们如果需要多图进行编辑或者图像组合,就可以设置多个Load Image节点,然后再CLIP的提示环节,就可以添加多个图像输入入口。
🔹 整体流程(对应图里的 Step 2 和 Step 4)
1. 主图输入(Step 2)
- 上传一张“主图”(例如左边的女生照片)。
- 这张图会通过 VAE 编码器 转换成潜空间(Latent),这样模型才能在压缩空间里进行编辑。
2. 参考图 / 条件输入
-
上传额外的参考条件,例如:
- 人体姿态(Pose 图)
- 其他辅助图片
-
这些作为条件约束输入,告诉模型要按照这些参考来修改或生成图像。
3. 提示词 + CLIP 编码(Step 4)
- 在 TextEncodeQwenImageEditPlus 节点中输入提示词(例如:“教堂…女孩子…”)。
- CLIP 会将提示词编码成“语义向量”,提供给模型。
- 节点还能接收图像输入,把 文本 + 图像 一起作为条件。
4. 整合 → 送入 UNet 去噪模型
-
输入内容包括:
- VAE 编码的“主图潜空间”
- CLIP 编码的提示词向量
- 参考图像输入
-
这些会一起送入 UNet。
-
UNet 根据提示词和参考图,把原图潜空间逐步修改,生成符合要求的新潜空间。
5. VAE 解码
- 修改完成的潜空间通过 VAE 解码器 转换成最终可视化的图像。
三、K采样器设置
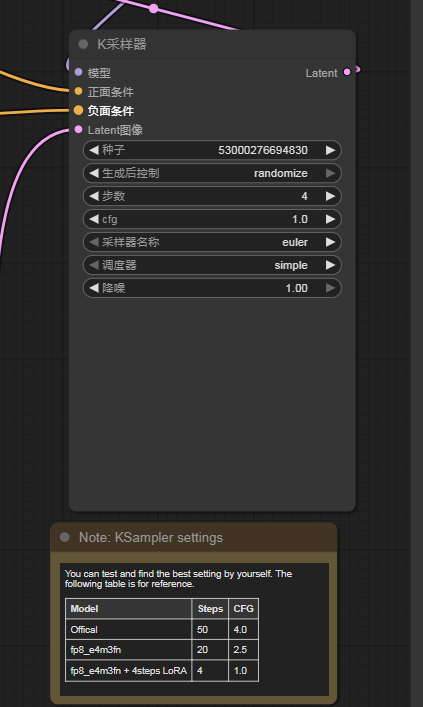
🔹 采样环节的作用
在 Stable Diffusion 里,采样器(Sampler)负责 逐步把“随机噪声的潜空间”去噪成最终图像。
📥 输入
-
噪声潜空间(Latent)
-
条件输入:
- CLIP 编码的提示词
- 参考图像
- VAE 编码的主图
⚙️ 过程
- 根据设定好的 迭代步数 和 采样算法,逐步减少噪声。
- 每一步迭代,潜空间都会变得更有结构,更接近目标图像。
📤 输出
- 得到一个已经成型的潜空间表示。
- 最终交由 VAE 解码,生成可视化的最终图片。
具体采用的步骤吗,根据实际资源配置进行设置,官方给出的建议设置如下:
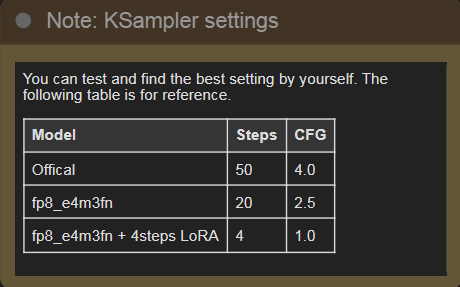
四、实例展示
🔹 人物+姿态
提示词:将图一女主穿上图二的衣服。

🔹 人物+姿势+服装
提示词:换装,将图一女主穿上图三衣服,模仿图二 姿势

🔹 人物+动物+场景

五、结论
是不是很令人兴奋?所有模型和框架都可在本地运行,我们可以免费体验最新技术,尽情发挥创意。本文仅是一个简单示例,在实际流程中我们还能进一步优化,比如VAE、CLIP和Text Encoder等组件已有更强大的模型可供选择,有兴趣的朋友不妨尝试一下。
六、补充
工作流程以及ComfyUI的配置问题
- ComfyUI配置:要下载最新版本的ComfyUI,目前官方已经更新过并集成了Qwen-Iamge-Edit2509的插件。
- 工作流:可以私信获取或者通过官网领取。
✨ 都已经看到这里,赶紧体验上手吧,与此同时也顺便点个赞+关注哦!!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)