【实战】 深入理解 Qwen3-VL 多模态大模型微调:从原理到代码实现
[实战] 深入理解 Qwen3-VL 多模态大模型微调:从原理到代码实现
前言
随着多模态大模型(LMM)的爆发,Qwen-VL 系列凭借其强大的图像理解和 OCR 能力,成为了开源界的佼佼者。官方提供的 qwen-vl-finetune 目录展示了如何利用自定义数据对模型进行下游任务适配。
本文将基于 Qwen-VL 的官方微调逻辑,分步骤拆解其训练流程,绘制架构图,并详细说明数据处理、模型加载及 LoRA 训练的核心代码实现。
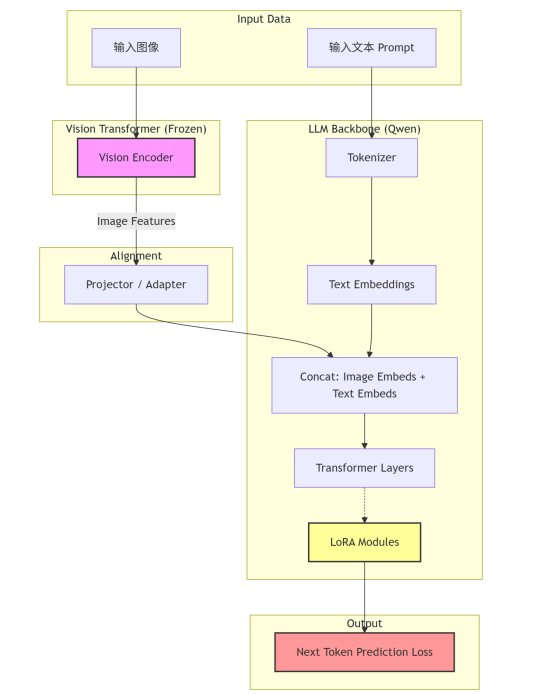
1. 整体架构与训练逻辑
在进行代码实战前,我们需要理解 Qwen-VL 系列的架构。它主要由三个部分组成:
- Vision Encoder (Vision Tower): 通常基于 ViT (Vision Transformer),用于提取图像特征。
- Projector (Adapter): 对齐层(如 C-Abstractor 或 MLP),将图像特征映射到文本嵌入空间。
- LLM Backbone: 大语言模型基座(Qwen),用于生成文本。
在微调(SFT)阶段,我们通常保持 Vision Encoder 冻结(Freeze),主要利用 LoRA (Low-Rank Adaptation) 技术微调 LLM 基座的线性层,有时也会微调 Projector。
架构流程图
2. 环境准备
微调 Qwen3-VL 需要依赖最新的 transformers、peft 和 deepspeed。
pip install torch torchvision
pip install transformers>=4.37.0
pip install peft
pip install deepspeed
pip install qwen_vl_utils # 处理Qwen特有的图像预处理
3. 核心步骤详解
步骤一:数据准备 (Data Formatting)
Qwen-VL 的微调数据通常遵循 JSON/JSONL 格式。每条数据包含图像路径和多轮对话。
数据示例 (train_data.json):
[
{
"messages": [
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/image.jpg"},
{"type": "text", "text": "这张图片里有什么?"}
]
},
{
"role": "assistant",
"content": [{"type": "text", "text": "这是一只在草地上奔跑的金毛犬。"}]
}
]
}
]
步骤二:数据预处理 (Data Collator)
这是微调代码中最复杂的部分。模型不能直接理解 JPG 图片,需要经过 process_vision_info 处理。
核心逻辑实现:
from qwen_vl_utils import process_vision_info
def preprocess_function(examples, processor):
"""
将原始数据转换为模型输入的 Tensor
"""
texts = []
images = []
for example in examples:
# 1. 提取图像和文本
image_inputs, video_inputs = process_vision_info(example['messages'])
# 2. 应用 Chat Template (构建 Prompt)
# Qwen3-VL 会将图片占位符转换为特定的 token,如 <|image_pad|>
text = processor.apply_chat_template(
example['messages'],
tokenize=False,
add_generation_prompt=False
)
texts.append(text)
images.append(image_inputs)
# 3. 使用 Processor 进行批量处理
# 这步会自动进行 Tokenize 和 Image Resize/Normalize
inputs = processor(
text=texts,
images=images,
padding=True,
return_tensors="pt"
)
# 4. 构造 Label (用于计算 Loss)
# 只有 Assistant 的回答部分需要计算 Loss,User 的输入部分设为 -100 (Ignore Index)
labels = inputs["input_ids"].clone()
# (此处省略具体的 mask 逻辑,通常需要根据 mask_token 将 user 部分过滤)
return inputs
步骤三:加载模型与配置 LoRA
为了显存优化,我们使用 LoRA 技术。
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
from peft import LoraConfig, get_peft_model, TaskType
# 1. 加载模型
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-7B-Instruct", # 假设的模型路径
torch_dtype="auto",
device_map="auto"
)
# 2. 加载处理器
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-7B-Instruct")
# 3. 配置 LoRA
# target_modules 非常关键,对于 Qwen 系列,通常微调 Attention 的投影层
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=16, # LoRA 秩
lora_alpha=32, # LoRA 缩放系数
lora_dropout=0.05,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]
# 注意:通常不微调 vision tower,除非任务极度依赖视觉特征的改变
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters() # 打印可训练参数量
步骤四:初始化 Trainer
使用 Hugging Face 的 Trainer 结合 DeepSpeed 进行分布式训练。
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./output_qwen3_vl_lora",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
num_train_epochs=3,
bf16=True, # 推荐使用 BF16 防止溢出
logging_steps=10,
save_strategy="epoch",
deepspeed="./ds_config_zero2.json", # DeepSpeed 配置文件
remove_unused_columns=False # 多模态数据列名可能不匹配,需设为 False
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=formatted_train_dataset, # 经过预处理的数据集
data_collator=data_collator,
)
trainer.train()
4. 关键技术点解析
在阅读 finetune.py 源码时,有几个 Qwen-VL 特有的细节需要注意:
1. 动态分辨率 (Dynamic Resolution)
Qwen3-VL (继承自 Qwen2-VL) 支持任意分辨率输入。它通过 Naive Dynamic Resolution 机制,将图片切分为多个 14 × 14 14 \times 14 14×14 的 patch。
- 代码体现:在
processor处理图片时,输出的pixel_values形状是变长的,不再是固定的 224 × 224 224 \times 224 224×224 或 336 × 336 336 \times 336 336×336。 - 训练影响:这要求
DataCollator在堆叠(stack)tensor 时必须处理 padding,或者使用 Flash Attention 的varlen模式。
2. 多模态 Token 混合
在输入到 LLM 之前,Embedding 层发生了什么?
- 文本:Token ID → \rightarrow → Text Embeddings
- 图片:Pixel Values → \rightarrow → ViT → \rightarrow → Image Embeddings
- 融合:在输入序列中,
<|image_pad|>的位置被替换为计算好的 Image Embeddings。
3. 梯度检查点 (Gradient Checkpointing)
由于视觉部分产生的 token 数量巨大(尤其是高分辨率图片),显存压力很大。开启 gradient_checkpointing=True 是微调 Qwen-VL 的标配,它通过以时间换空间的方式显著降低显存占用。
5. 启动训练
通常我们编写一个 shell 脚本来启动 DeepSpeed 训练:
#!/bin/bash
# 设置可见 GPU
export CUDA_VISIBLE_DEVICES=0,1,2,3
deepspeed --num_gpus 4 finetune.py \
--model_name_or_path Qwen/Qwen3-VL-7B-Instruct \
--data_path ./data/train.json \
--output_dir ./output_checkpoints \
--bf16 True \
--fix_vit True \
--use_lora True
6. 总结
Qwen3-VL 的微调逻辑本质上是一个 “冻结视觉塔 + LoRA 微调语言模型” 的过程。其核心难点不在于模型架构的修改,而在于:
- 数据的正确格式化:确保图像和文本对应的 Token 位置正确。
- 动态分辨率的处理:理解 Processor 是如何处理不同尺寸图片的。
- 显存优化:合理使用 DeepSpeed Zero2/3 和 Gradient Checkpointing。
希望这篇博客能帮您理清 Qwen-VL 微调的代码脉络。如果您手头有特定的垂直领域数据(如医疗影像、工业质检),按照上述流程即可快速训练出专属的多模态模型。
参考资料:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)