别再按固定间隔截帧了:claude-real-video 让任意大模型真正“看懂”视频
前言
把一段视频丢给大模型,让它帮你总结内容、回答画面里的问题,听起来很美好。但你真去试就会撞上一堵墙:
- 把 YouTube 链接贴进 ChatGPT,它读的是字幕文本,根本没看画面。
- Claude 压根不接受视频文件。
- 即便是原生支持视频的 Gemini,默认也是按「每秒 1 帧」固定采样,还得先把视频上传到谷歌云端,快速切换的镜头很容易漏掉。
换句话说,大多数 AI 工具并不真正“看”视频。最近 GitHub 上一个叫 claude-real-video(缩写 crv)的开源项目给出了一个更聪明的本地方案:它不按固定间隔截帧,而是只在场景发生切换时才提取关键帧,再用滑动窗口去掉近乎重复的画面,最后用 Whisper 把音频转成文字——全部在你自己电脑上跑完,数据不传云端。
这篇文章就来拆解它到底聪明在哪、怎么用,以及关键参数怎么调。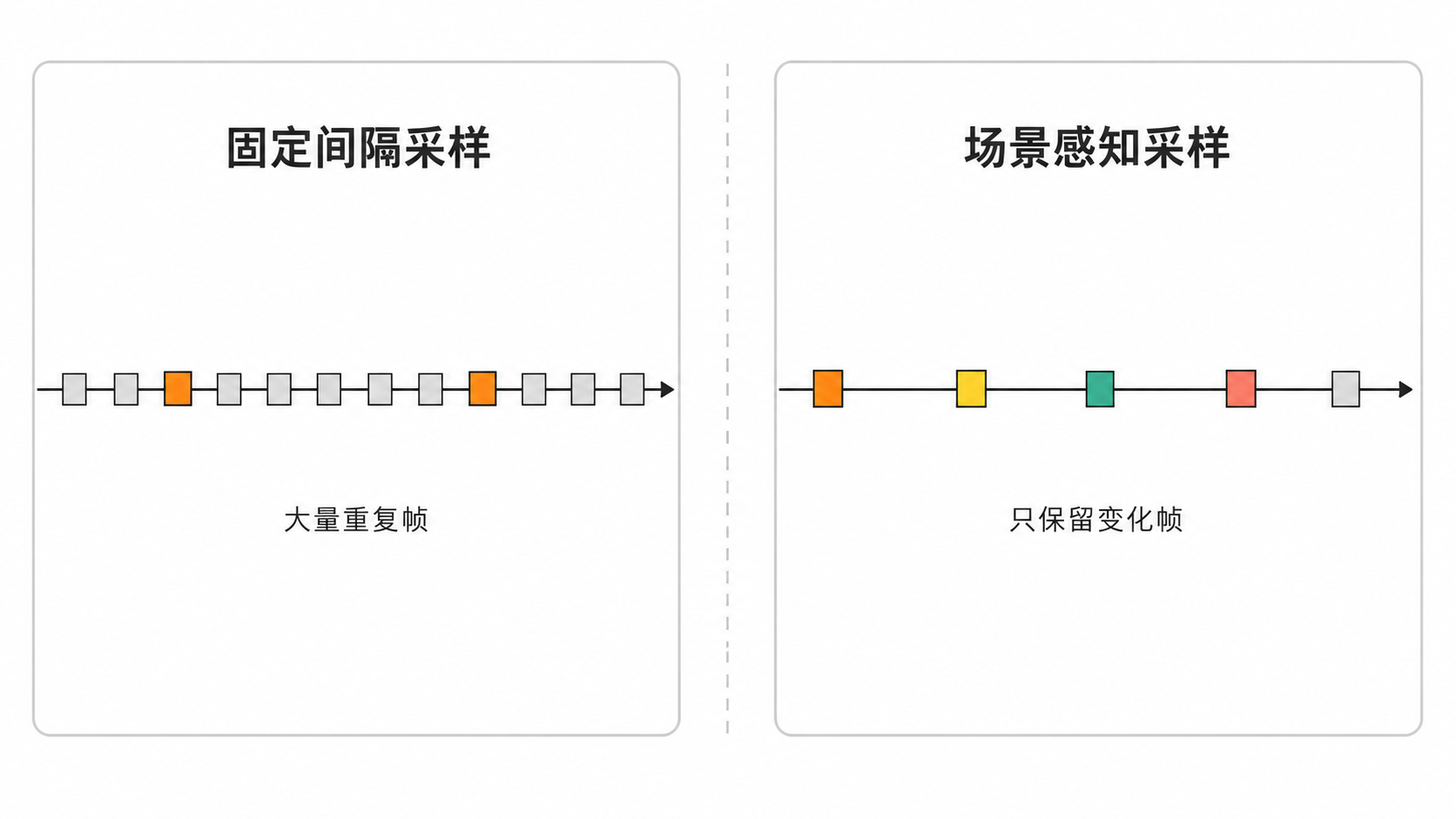
背景或问题:固定间隔采样为什么不行?
市面上很多“让大模型看视频”的脚本,做法出奇地一致:用 ffmpeg 按「每 N 秒一帧」把视频切成图片,再一股脑塞给模型。这种固定间隔采样有三个硬伤。
1. 静态内容被过度采样。 一段 10 分钟的屏幕录制(讲 PPT),画面几乎不动,按每秒 1 帧算就是约 600 张近乎一模一样的图。把这些全喂给模型,除了烧 token、撑爆上下文窗口,没有任何信息增量。
2. 快速剪辑被采样不足。 一段节奏很快的混剪,两个关键镜头之间的切换可能只有 0.2 秒,而你的采样间隔是 1 秒——恰好完美错过每一个镜头切换点,模型拿到的全是“中间过渡帧”,根本看不懂发生了什么。
3. A-B-A 切回镜头被重复发送。 视频里常见这种剪辑:先给全景 A,切到特写 B,再切回全景 A。固定采样会把同一个全景 A 截下来重复发两遍,模型被迫“看”两次已经看过的画面,又浪费一轮上下文。
把这三个问题叠加起来,结果就是:你喂给模型的帧很多,但有效的很少;上下文成本很高,理解效果却很差。 这正是 claude-real-video 要解决的矛盾。
| 对比维度 | 固定间隔采样 | claude-real-video |
|---|---|---|
| 帧选择 | 每 N 秒一帧 | 场景变化检测 + 密度下限 |
| 重复镜头(A-B-A 剪切) | 每次都重复发送 | 滑动窗口去重,每个镜头只发一次 |
| 静态幻灯片(10 分钟) | 约 600 张近乎相同的帧 | 压缩为 1 帧(去重) |
| 快速切换剪辑 | 漏掉采样间隔之间的帧 | 捕捉每一次视觉变化 |
| 音频 | 通常被忽略 | 字幕优先 + Whisper 回退转录 |
| 视频去向 | 通常上传到云端 | 留在你的机器上 |
| 输入方式 | 通常仅支持本地文件 | 支持 URL(yt-dlp)或本地文件 |
核心思路:场景感知 + 去重 + 本地转录
claude-real-video 的设计可以浓缩成一句话:只把“画面真正发生变化”的关键帧喂给模型,顺便把音频也变成模型能读的文字。
它把整个流程拆成六步,全部在本地完成:
- 获取(Fetch):用 yt-dlp 处理 URL(支持 cookie 登录态),或直接复制本地文件。
- 提取(Extract):通过 ffmpeg 的时序选择通道,捕获每一个场景切换点,同时保证密度下限(每
--fps-floor秒至少一帧),从而同时覆盖快速剪辑和慢速录屏。 - 去重(Dedup):基于真实像素差异,与最近保留的若干帧做滑动窗口比较,丢掉重复镜头。
- 文本(Text):如果视频自带字幕(.srt/.vtt 或内嵌字幕轨道)就直接用,比重新转录更快更准;没有字幕才回退到 Whisper。
- 音频(可选):用
--keep-audio保留完整原始音轨,让支持听力的模型(如 GPT-4o、Gemini)能听到音乐和语调。 - 清单文件(Manifest):生成
MANIFEST.txt汇总所有信息,供模型一次性读取。
最终输出的是一个干净的本地文件夹:关键帧图片 + 转录文本 + 清单。你把这个文件夹拖进任意大模型(Claude / ChatGPT / Gemini),就能基于画面提问了。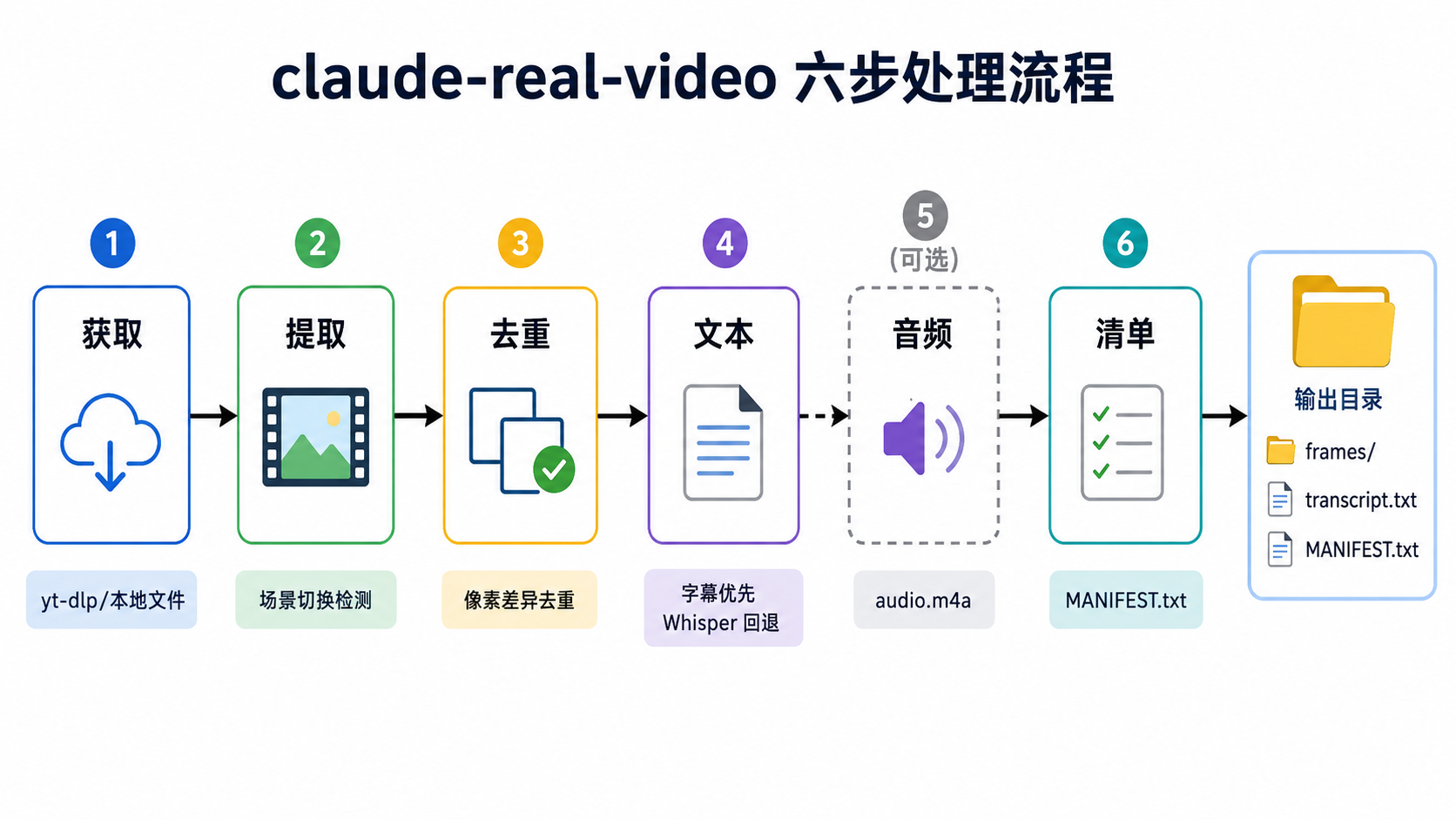
实现步骤
第一步:安装 ffmpeg(系统依赖)
claude-real-video 用 ffmpeg / ffprobe 做帧提取和音频处理,但 ffmpeg 不能通过 pip 安装,需要先单独装一次。
| 操作系统 | 命令 |
|---|---|
| macOS | brew install ffmpeg |
| Linux | sudo apt install ffmpeg(或你的发行版包管理器) |
| Windows | winget install Gyan.FFmpeg 或 choco install ffmpeg,并把 bin\ 加入 PATH |
装完验证一下:
ffmpeg -version
第二步:安装 claude-real-video
# 只装核心(帧提取 + 去重)
pip install claude-real-video
# 想要音频转录,加上 whisper 扩展
pip install "claude-real-video[whisper]"
[whisper] 会顺带装上 openai-whisper,它同样依赖 ffmpeg。要求 Python 3.10 以上。
第三步:跑一个最简单的例子
支持 YouTube、Instagram、TikTok 等链接,也支持本地文件:
# 处理一个 YouTube 链接
crv "https://www.youtube.com/watch?v=XXXXXXX"
# 处理本地文件,指定输出目录和转录语言
crv lecture.mp4 -o out --lang zh
# 只提取帧,不要转录
crv clip.mp4 --no-transcribe
crv 是 python -m claude_real_video 的简写。跑完后输出目录长这样:
crv-out/
├── frames/
│ ├── frame-001.jpg
│ ├── frame-002.jpg
│ └── ...
├── transcript.txt # 音频/字幕转录的纯文本
└── MANIFEST.txt # 清单:帧列表 + 元信息
把 frames/ 整个文件夹加上 MANIFEST.txt 和 transcript.txt 一起拖进 Claude / ChatGPT / Gemini,然后随便提问即可。
代码示例
命令行常用选项一览
| 标志 | 默认值 | 含义 |
|---|---|---|
-o, --out |
crv-out |
输出目录 |
--scene |
0.30 |
场景切换敏感度,值越低提取的帧越多 |
--fps-floor |
1.0 |
每 N 秒至少提取一帧(密度下限) |
--max-frames |
150 |
总帧数的硬上限 |
--lang |
auto |
Whisper 语言(en, zh, auto, …) |
--dedup-threshold |
8 |
像素变化比例,超过才视为新帧;值越高帧越少 |
--dedup-window |
4 |
与最近 N 个保留帧比较,避免 A-B-A 重复 |
--report |
off | 生成 report.html,可视化每一帧的保留/丢弃决策 |
--no-transcribe |
off | 跳过音频转录 |
--keep-audio |
off | 同时保存完整音轨 audio.m4a |
--cookies |
– | 用于登录受限源的 Netscape cookie 文件 |
Python API 调用
如果你想在脚本或后端服务里集成,直接调 process 函数:
from claude_real_video import process
# 处理一个视频,输出到 ./out,转录语言设为中文
r = process(
"https://youtu.be/XXXXXXX",
"out",
lang="zh",
scene=0.30, # 场景切换敏感度
dedup_threshold=8, # 像素变化阈值
dedup_window=4, # 滑动窗口大小
)
print(f"提取的关键帧数量: {r.frame_count}")
print(f"转录文本路径: {r.transcript_path}")
返回对象 r 包含帧数和转录文本路径,方便你接着把图片和文本灌进自己的 RAG 或 Agent 流水线。
一个完整的“视频问答”串联示例
下面演示如何把 claude-real-video 的输出接入一个本地多模态问答流程(伪代码,示意思路):
import os
from claude_real_video import process
# 1. 本地处理视频,得到关键帧 + 转录
result = process(
"meeting.mp4",
"out",
lang="zh",
keep_audio=False, # 不需要听音乐/语调可关掉
max_frames=60, # 控制上下文成本
)
frames_dir = os.path.join("out", "frames")
transcript_path = result.transcript_path
# 2. 读取转录文本
with open(transcript_path, "r", encoding="utf-8") as f:
transcript = f.read()
# 3. 把关键帧 + 转录交给多模态大模型(以 OpenAI 兼容接口为例)
import base64
def encode_image(path):
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode()
frame_files = sorted(
os.path.join(frames_dir, f)
for f in os.listdir(frames_dir)
if f.endswith(".jpg")
)[: result.frame_count]
# 构造多模态消息:先给文字上下文,再逐帧给图
content = [{"type": "text", "text": f"视频转录文本:\n{transcript}\n\n下面是关键帧,请基于画面和文本回答问题。"}]
for fp in frame_files:
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{encode_image(fp)}"},
})
messages = [
{"role": "system", "content": "你是一个视频内容分析助手,基于关键帧和转录回答用户问题。"},
{"role": "user", "content": content},
{"role": "user", "content": "请总结这段视频讲了什么,重点在哪里?"},
]
# from openai import OpenAI
# client = OpenAI(api_key="...", base_url="...")
# resp = client.chat.completions.create(model="gpt-4o", messages=messages, max_tokens=800)
# print(resp.choices[0].message.content)
这个例子展示了 claude-real-video 在工程里的定位:它是视频到多模态模型之间那座“聪明的桥”,负责把原始视频压缩成模型能高效消化的关键帧 + 文字,而真正理解和回答的活儿仍交给大模型。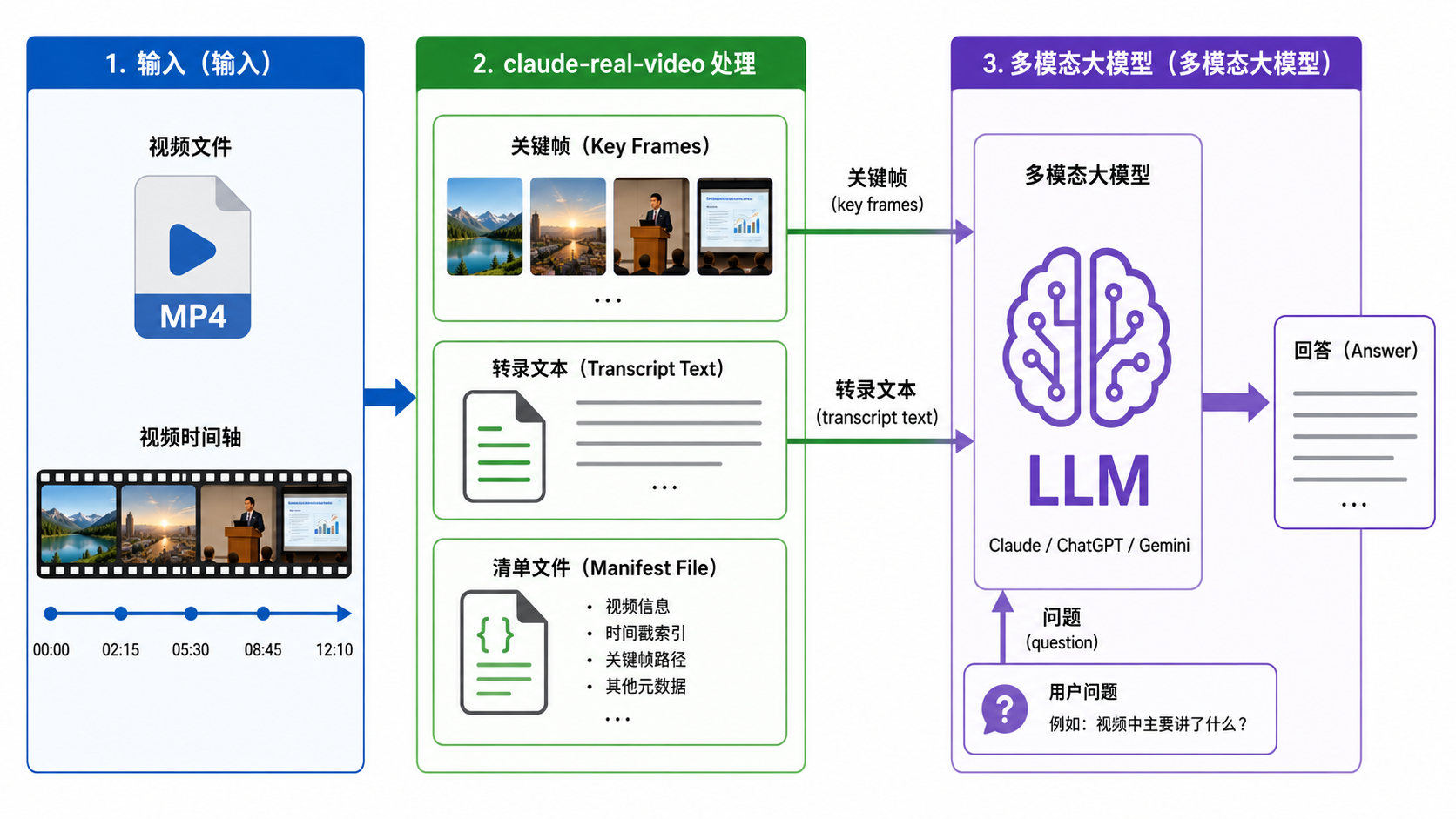
运行结果与效果说明
用一个 10 分钟的技术演讲视频做对比测试,能直观看出差异:
- 固定间隔采样(每秒 1 帧):约 600 帧,其中 500 多帧是讲者站在同一张幻灯片前几乎不动,模型上下文被无效图片占满,回答时容易“Lost in the Middle”。
- claude-real-video(默认参数):通常压缩到 20~50 帧左右,每一帧都对应一次真正的画面变化(幻灯片切换、代码演示、图表出现),外加一份转录文本。模型拿到的信息密度高、上下文成本低。
如果你想直观看到它到底“丢掉了哪些帧、保留了哪些帧”,加上 --report:
crv lecture.mp4 --report
它会在 dropped/ 目录里保存被丢弃的帧,并生成一个 report.html,用可视化方式展示每一帧的保留/丢弃决策和差异百分比——这是调参时最实用的调试工具。
深入:关键参数怎么调
理解了原理,调参就有方向了。
--scene:场景切换敏感度(默认 0.30)
这是 ffmpeg 场景检测的阈值。值越低,越“敏感”,稍微一点变化就判定为场景切换,提取的帧越多;值越高,只有大幅度画面变化才被捕获,帧越少。
- 演讲/教学视频(画面变化慢):可适当调低到 0.20,避免漏掉幻灯片切换。
- 快速混剪/游戏录屏(画面变化剧烈):默认 0.30 通常够用,太高会丢镜头。
--dedup-threshold:像素变化比例(默认 8)
去重时,两帧降采样后的像素差异比例超过这个值,才认为是“新帧”。值越高,过滤越狠,帧越少。
- 想保留更多细节:调低到 4~6。
- 想极致压缩上下文成本:调高到 12~15。
--dedup-window:滑动窗口大小(默认 4)
这是 claude-real-video 解决 A-B-A 切回镜头的关键。它不只和「前一帧」比,而是和最近保留的 N 帧比。
1:只和前一帧比较,遇到 A-B-A 会把第二个 A 当新帧重复发。4(默认):和最近 4 个保留帧比较,镜头切回时认出“这个画面模型已经看过”,直接丢弃,避免重复发送。
对于访谈、对话类视频(频繁正反打镜头),建议保持默认 4 甚至调高到 6;对于线性教程(画面单向推进),调到 2 也够。
为什么用降采样 RGB 而不是感知哈希(pHash)?
这是一个容易被忽略但很重要的设计选择。很多去重工具用感知哈希(pHash / aHash),但 claude-real-video 故意不用,原因是:
- 感知哈希在纯色背景和等亮度的色相变化场景下会失效——两张颜色完全不同但亮度结构相似的图可能算出相同的哈希值,被误判为重复。
- 降采样 RGB 直接计算像素差异,对纯色、色相变化更鲁棒,误判更少。
代价是计算量略大,但因为已经降采样到很小尺寸,这点开销可以忽略。
常见问题与避坑
1. 报错 ffmpeg: command not found
ffmpeg 没装或没加入 PATH。Whisper 也依赖 ffmpeg,所以这是最常见的前置问题。装完用 ffmpeg -version 确认能调用。
2. 处理 YouTube 链接失败 / 报 age-restricted / 地区限制
yt-dlp 偶尔会因为网站策略变动失效,先升级 yt-dlp:pip install -U yt-dlp。如果是登录受限内容(你自己有权访问的),用 --cookies cookies.txt 传入 Netscape 格式的 cookie 文件。注意:切勿把 cookie 凭证提交到公开仓库。
3. 转录文本为空或质量差
claude-real-video 的策略是「字幕优先」:如果视频自带 .srt/.vtt 或内嵌字幕轨道,直接用,比重新转录更快更准。只有没有字幕时才回退到 Whisper。如果转录为空,检查:
- 视频是否真的有音轨(无声轨会干净跳过,不报错)。
--lang是否设对(中文视频传zh,不要让它 auto 错判)。- Whisper 模型大小:长视频默认小模型可能漏字,可考虑用更大模型(需自行配置 whisper)。
4. 帧太多撑爆上下文窗口
加 --max-frames 60 设置硬上限,或调高 --dedup-threshold 和 --scene 来压缩帧数。原则:喂给模型的帧不在多,在于每帧都代表一次真正的视觉变化。
5. --keep-audio 和转录的区别
--keep-audio 保存的是完整原始音轨(audio.m4a,含音乐、音效、语调),给支持听力的模型(如 Gemini、GPT-4o)实际“听”。而 transcript.txt 只有文字。两者互补:文字任何模型都能读,音频文件则让模型感知到情绪、节奏和音乐——对于音乐 MV、演讲语气分析很有用。
6. 本地处理的隐私优势
把视频上传云端处理(如 Gemini 原生流程)意味着你的视频内容离开本地。对于企业内部会议录像、含敏感信息的演示视频,claude-real-video 的“全部本地”特性是一个硬需求:关键帧、音轨、转录都留在你机器上,不外传。
总结
让大模型“看”视频,难点不在模型本身,而在怎么把视频变成模型能高效消化的输入。固定间隔采样是最直觉的做法,但也是最浪费的做法——它不分场景地轰炸上下文窗口,真正有信息量的帧反而被稀释。
claude-real-video 的核心价值就三句话:
- 场景感知提取:只在画面真正变化时取帧,静态内容不浪费、快速剪辑不漏帧。
- 滑动窗口去重:用真实像素差异对抗 A-B-A 重复,每帧都算数。
- 本地全流程:字幕优先 + Whisper 回退转录,数据不出机器,隐私可控。
它不替代任何大模型,而是做好“视频 → 关键帧 + 文字”这层脏活累活,让 Claude、ChatGPT、Gemini 这些模型能把精力花在理解上,而不是在海量重复帧里挣扎。如果你在做视频内容分析、会议纪要、教学视频问答这类场景,值得一试。
项目地址(MIT 协议、Python 100%):github.com/HUANGCHIHHUNGLeo/claude-real-video

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)