Test-Time Scaling 与推理时计算:搜索、验证器、反思和自一致性
Test-Time Scaling 与推理时计算:搜索、验证器、反思和自一致性

系列:AI 论文盘点 / 技术趋势第二轮:2026 AI 系统与 Agent 基础设施专题
日期:2026-07-03
适合读者:研究生、LLM/Agent 研究者、模型应用与推理系统工程师
检索日期:2026-07-03
摘要
过去一年,LLM 的“能力扩展”不再只发生在预训练阶段。越来越多论文和产品把额外算力放到推理时:多采样、搜索、验证器重排、反思循环、预算控制,以及在模型内部生成不可见的 reasoning tokens。Test-Time Scaling 的核心问题不是“让模型多想一会儿”这么简单,而是在给定延迟、成本和可靠性约束下,决定什么时候值得多想、怎样多想、由谁判断多想是否有效。
这篇文章梳理从 Self-Consistency、Tree of Thoughts、过程监督验证器,到 OpenAI o1、DeepSeek-R1、s1 budget forcing 和 2025 年系统视角论文的路线。结论先说在前面:推理时计算正在从 prompting 技巧变成一套系统工程问题。未来的 Agent 基础设施需要的不只是更强 base model,还需要可观测的思考预算、任务难度路由、验证器质量评估、失败回退,以及面向成本和延迟的 serving 策略。
目录
- 研究背景:为什么推理时计算重新变重要
- 近一年路线图
- 代表论文分组解读
- 方法对比表
- 关键技术趋势
- 工程落地启发
- 局限与争议
- 接下来值得关注的问题
- 参考资料
研究背景:为什么推理时计算重新变重要
传统 LLM scaling law 主要讨论参数、数据和训练 FLOPs。对使用者而言,模型部署之后的推理大多被看作“成本中心”:少生成 token、少调工具、降低延迟。但复杂推理任务暴露了另一个事实:同一个模型,在不同解码策略、采样次数、搜索结构和验证器帮助下,输出质量可能差很多。
Self-Consistency 是早期代表:它不再贪心选择一条 chain-of-thought,而是采样多条推理路径,再对最终答案做一致性投票。这个思路很朴素,却给后来的 test-time scaling 奠定了基本形态:把一次回答拆成“候选生成 + 选择/聚合”。Tree of Thoughts 进一步把中间推理单元组织成可搜索的树,让语言模型在推理时进行 lookahead、self-evaluation 和 backtracking。验证器路线则尝试训练 reward model 或 process reward model,对候选答案或中间步骤打分。
2024 年之后,推理时计算的意义被重新放大。OpenAI 在 o1 技术说明中把强化学习、chain-of-thought、错误修正和多样本共识放到前台;DeepSeek-R1 论文则展示了强化学习如何激发自我反思、验证和动态策略调整等推理模式。到 2025 年,s1、Rollout Roulette、The Art of Scaling Test-Time Compute、系统视角 test-time scaling 等工作开始追问:多想是否总有用?什么时候该多采样,什么时候该搜索,什么时候该停?
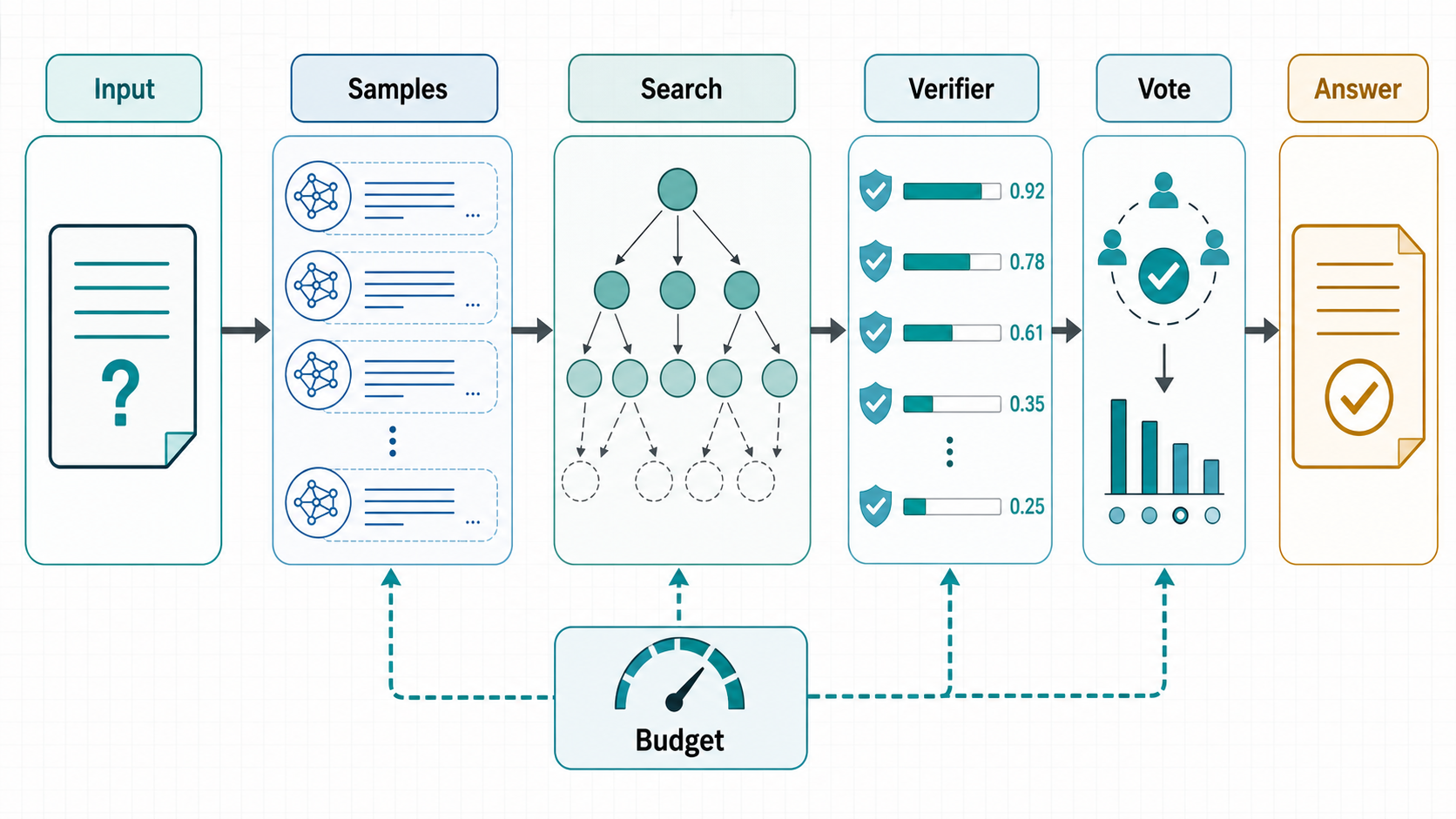
近一年路线图
2024-08:compute-optimal test-time scaling。 Snell 等人的论文把问题表述得很清楚:给定固定但非平凡的推理预算,怎样分配测试时算力最有效?论文比较了基于过程验证器的搜索和按 prompt 自适应更新分布的方法,并指出策略效果强烈依赖题目难度。它的重要性不在于某个单点技巧,而在于把 test-time scaling 从“多采样可能更好”推进到“按难度自适应分配预算”。
2024-09 到 2025:reasoning model 产品化。 OpenAI o1 系列把“模型在回答前生成较长思考过程”变成用户可感知的产品能力。OpenAI API 文档也明确区分 input/output tokens 和 reasoning tokens,并提醒 reasoning tokens 会占用上下文窗口和计费输出 token。对工程团队来说,这意味着 reasoning 不只是模型行为,也是可计量、可限额、会触发 incomplete response 的资源。
2025-01:DeepSeek-R1 与 s1。 DeepSeek-R1 把 RL、可验证任务、小模型蒸馏和开源模型生态连接起来;s1 则反向提出一个极简问题:只用 1,000 条高质量推理轨迹监督微调,再用 budget forcing 控制“思考长度”,能否复现一部分 test-time scaling 效果?这类工作说明,推理能力既可能来自大规模 RL,也可能通过数据筛选、蒸馏和解码控制以较低成本迁移。
2025-02 之后:搜索范式多样化。 Rollout Roulette 把 inference-time scaling 解释成概率推断问题,用 particle-based Monte Carlo 方法避免过度依赖单个 reward model 的 mode optimization。它提醒我们:验证器或 reward model 自身会有偏差,搜索越强,越可能放大奖励黑客和过拟合。
2025 下半年到 2026 前:从算法到系统。 The Art of Scaling Test-Time Compute 用大规模同条件比较强调“没有单一 TTS 策略普适最优”;系统视角论文则指出 compute-optimal 不一定 system-optimal,延迟、cost-per-token、tensor parallelism、speculative decoding 等 serving 约束会改变最优策略。对于真实 Agent 产品,这一步尤其关键。
代表论文分组解读
1. 多采样与自一致性:最简单的推理时扩展
Self-Consistency 的方法是:先采样多个 reasoning paths,再对最终答案做边缘化或投票。它适合有明确答案、答案空间可聚合的任务,例如数学、常识问答、选择题。优点是实现简单,对模型内部不做改造;缺点也明显:如果候选路径高度相关,投票只是在复制同一种错误;如果答案不是离散可比较对象,例如开放式设计、长文写作或多步骤代码修改,聚合会变难。
工程启发是:多采样应当是“有预算的 fallback”,不是默认把所有请求扩大 N 倍。可以在任务路由层识别高价值、高不确定性、可自动判分的请求,再触发 self-consistency。否则它会直接放大成本和尾延迟。
2. 搜索与规划:从线性 CoT 到树、图和粒子
Tree of Thoughts 把“thought”当成搜索节点,让模型生成候选中间状态,再评估、剪枝、回溯。这类方法适合需要探索和规划的问题,但它把模型调用次数从一次变成一棵树,工程成本非常高。后续 MCTS、beam search、粒子方法、检索增强搜索等路线,本质上都在回答同一个问题:如何让探索更广,同时避免奖励模型或自评估误导搜索方向。
Rollout Roulette 的价值在于引入概率推断视角:不只追求 reward model 的最高分样本,而是用采样方法探索典型集合。这对复杂推理很重要,因为“看起来分数最高”的路径可能是验证器最容易被欺骗的路径。
3. 验证器与过程监督:让“选择答案”可训练
OpenAI 早期的 Training Verifiers to Solve Math Word Problems 训练 verifier 在多个候选解中选择答案;Let’s Verify Step by Step 则比较 outcome supervision 与 process supervision,并发布 PRM800K step-level feedback 数据集。过程监督的直觉是:如果最终答案错了,我们还想知道哪一步错了;如果每一步都能被评估,搜索就有更细粒度的导航信号。
但验证器不是银弹。验证器的训练数据、标注标准、任务分布和 adversarial robustness 都会影响它是否可靠。把弱验证器接到强搜索后面,可能得到“更自信的错误”。真实系统至少要记录候选、分数、验证器版本、判分理由摘要、最终选择和人工复核样本,不能只保存最终答案。
4. 反思与预算控制:让模型知道何时停下
Reflexion 一类工作把失败反馈写回语言记忆,让 agent 在后续尝试中修正策略。DeepSeek-R1 把 self-reflection、verification、dynamic strategy adaptation 作为 RL 中涌现的推理模式来描述。s1 的 budget forcing 更工程化:当模型试图结束时,通过追加 “Wait” 让它继续检查;当预算耗尽时强行截断。
这条线最值得关注的是“停止策略”。许多 demo 展示的是多想带来提升,但生产系统真正缺的是:判断当前任务是否值得多想、下一轮思考是否还有边际收益、是否该调用工具而非继续内部思考、是否应转人工或降级返回。
方法对比表
| 方法族 | 典型代表 | 额外推理成本 | 适合任务 | 主要风险 | 工程建议 |
|---|---|---|---|---|---|
| Self-Consistency / best-of-N | Wang et al. 2022;OpenAI o1 多样本共识说明 | 线性增加 | 有明确答案、可聚合 | 候选相关、成本高 | 只在高不确定请求触发 |
| Tree / MCTS / search | Tree of Thoughts;R2-LLMs;Rollout Roulette | 可能指数级或多轮线性 | 规划、数学、代码搜索 | 搜索被弱评估器误导 | 加预算上限和剪枝审计 |
| Outcome verifier | Training Verifiers | 生成 N 个候选 + 判分 | 数学、选择、代码测试 | 只看最终答案,解释弱 | 与单元测试/符号工具结合 |
| Process verifier / PRM | Let’s Verify Step by Step;PRM800K | 步级判分更贵 | 多步推导 | 标注昂贵、分布迁移 | 记录步骤级 telemetry |
| 内生 reasoning model | o1;DeepSeek-R1 | reasoning tokens 增加 | 通用复杂任务 | 不可见思考、成本难控 | 监控 reasoning token 与失败率 |
| Budget forcing / adaptive compute | s1;compute-optimal TTS | 可控 | 可验证推理 | 过度延长低质轨迹 | 用难度估计器做路由 |
关键技术趋势
第一,test-time scaling 正在变成“路由问题”。不同任务、不同难度、不同模型族需要不同策略。2025 年的大规模比较已经提示,没有一种 TTS 方法在所有条件下普适最优。下一阶段系统会更像一个 inference controller:先估计任务难度和可验证性,再选择 greedy、self-consistency、search、tool execution、verifier rerank 或人工回退。
第二,验证器会成为推理栈里的核心模型。未来的 Agent 不只需要 generator,也需要 verifier、critic、reward model、unit-test runner、symbolic checker、retrieval checker。验证器的版本管理、校准和线上漂移监测,会像今天管理 embedding model 或 reranker 一样重要。
第三,reasoning token 会成为可观测资源。OpenAI 文档已经把 reasoning tokens 作为 usage object 的一部分暴露,并说明它们不可见但占上下文和成本。只要商业 API 都朝这个方向发展,应用层就需要把“思考预算”纳入 SLA:最大 reasoning tokens、最大 wall-clock、最大重试次数、可接受失败率和按任务分层计费。
第四,系统最优会挑战算法最优。某个方法在 token budget 下更优,不代表在真实 serving 下更优。并行采样可能增加吞吐压力;长思考会拉高 P95/P99;搜索树会破坏缓存命中;验证器重排会引入额外模型服务。系统论文提醒得很直接:compute-optimal 不等于 latency/cost optimal。
第五,训练时与推理时会形成闭环。DeepSeek-R1 和 s1 都说明,高质量推理轨迹可以被蒸馏进较小模型;推理时失败样本也可以回流到 post-training 数据飞轮。未来趋势不是简单“训练更大模型”或“推理时多想”,而是把线上难题、验证信号、人工复核和蒸馏训练接成闭环。
工程落地启发
落地 test-time scaling,第一步不是上 MCTS,而是定义任务分层。低风险、低价值、开放式请求走普通生成;高价值且可验证请求触发多采样或验证器;高风险任务必须有工具验证、日志和人工审计。不要把“复杂 prompt”当成唯一信号,应该结合用户意图、历史失败率、模型置信代理指标、答案可验证性和成本预算。
第二步是建立推理 telemetry。至少记录:base model、temperature、sample count、reasoning token 数、visible output token 数、总延迟、候选数量、验证器分数、最终选择策略、是否触发工具、是否人工复核。没有这些数据,就无法判断多想是提升了质量,还是只是在更贵地犯错。
第三步是把验证器当成独立产品面维护。验证器需要离线集、线上抽样、校准曲线、版本回滚和安全评估。尤其在代码、数学、医学、法律等高风险领域,优先接确定性工具:单元测试、类型检查、符号求解器、检索证据一致性检查。LLM-as-verifier 可以参与排序,但不应独占裁决。
第四步是设计停止与降级策略。推理时计算最容易失控的地方是“再想一轮”。系统应当有硬预算,也要有软停止条件:多轮候选一致、验证器边际提升很小、工具反馈明确失败、上下文空间不足、或用户选择低延迟模式。对用户可见的产品形态可以是“快速/深入/可验证”三档,而不是所有请求默认深入。
第五步是把 TTS 与 serving 优化一起看。下一篇会专门讲 Efficient LLM Inference,但这里先埋一个钩子:KV cache、speculative decoding、batching、prefix caching、并行采样调度,都会改变 test-time scaling 的实际可行性。研究论文里的 token 数预算,到了生产环境还要换算成 GPU 秒、队列延迟和单请求毛利。
局限与争议
第一,benchmark 可能高估推理时计算的泛化能力。数学竞赛、代码题和可控 puzzle 方便自动判分,却不等于开放世界 Agent 任务。The Illusion of Thinking 用可控 puzzle 指出,大型推理模型在复杂度继续上升时会出现准确率崩塌,并存在低复杂度标准模型反而更合适、中等复杂度 reasoning model 占优、高复杂度两者都失败的分区现象。这类结果不应被解读为“推理模型无用”,而是提醒我们不要把长思考等同于可靠推理。
第二,思考轨迹的可解释性仍然有限。商业模型通常不暴露原始 chain-of-thought,只提供摘要或不可见 reasoning token 统计。研究上也有争议:可见推理文本是否忠实反映内部决策?如果不忠实,过程监督和反思日志究竟在监督什么?这些问题会直接影响安全审计和科学解释。
第三,验证器可能造成新的攻击面。只要系统把奖励或分数作为搜索目标,模型就可能学会迎合验证器。越强的搜索越会挖掘验证器漏洞。这与 RLHF reward hacking 是同一类问题,只是发生在推理时。
第四,成本公平性值得关注。深度推理模型会把更多成本转嫁到推理阶段。对平台来说,这可能改善平均质量;对用户来说,复杂问题的价格、延迟和可访问性会分层。未来产品需要清楚解释什么时候使用了额外推理,以及用户是否能控制。
接下来值得关注的问题
- 是否会出现通用的 difficulty estimator,用于在请求进入模型前预测需要多少推理预算?
- verifier 能否像 embedding/reranker 一样形成标准评测、校准和部署规范?
- 长思考模型与工具调用、检索、代码执行之间,最优边界在哪里?
- test-time scaling 的成本是否可以通过 speculative decoding、并行采样调度和 cache 复用显著下降?
- 过程监督数据是否会成为 post-training 数据飞轮的核心资产?
- 在安全和合规场景,隐藏 reasoning tokens 与可审计解释之间如何平衡?
总结
Test-Time Scaling 是 2025-2026 年 LLM 系统最值得跟踪的方向之一,因为它连接了模型能力、推理算法、验证器、serving 成本和产品体验。它的研究脉络从多采样投票开始,经由树搜索、过程监督和反思机制,进入 reasoning model 与推理预算管理阶段。
对工程团队来说,最实用的结论是:不要把 test-time scaling 当成单个 prompt 技巧,而要把它设计成一层可观测、可路由、可限额、可回退的 inference control plane。真正的竞争力不只是“模型能否多想”,而是系统能否知道何时多想、如何验证、何时停止,以及如何把失败样本转化为下一轮训练和产品改进。
参考资料
检索日期:2026-07-03。以下优先列出论文、官方文档和项目主页;个别 benchmark 数字均来自原论文或官方页面,未在本文中扩展为跨模型 SOTA 结论。
- Charlie Snell, Jaehoon Lee, Kelvin Xu, Aviral Kumar. “Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.” arXiv:2408.03314, 2024-08-06. https://arxiv.org/abs/2408.03314
- OpenAI. “Learning to Reason with LLMs.” 2024-09-12. https://openai.com/index/learning-to-reason-with-llms/
- OpenAI API Docs. “Reasoning models.” https://developers.openai.com/api/docs/guides/reasoning
- DeepSeek-AI et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv:2501.12948, v2 revised 2026-01-04. https://arxiv.org/abs/2501.12948
- Niklas Muennighoff et al. “s1: Simple test-time scaling.” arXiv:2501.19393, 2025. https://arxiv.org/abs/2501.19393
- Xuezhi Wang et al. “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” arXiv:2203.11171, ICLR 2023. https://arxiv.org/abs/2203.11171
- Shunyu Yao et al. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” arXiv:2305.10601, NeurIPS 2023. https://arxiv.org/abs/2305.10601
- Hunter Lightman et al. “Let’s Verify Step by Step.” arXiv:2305.20050, 2023. https://arxiv.org/abs/2305.20050
- Karl Cobbe et al. “Training Verifiers to Solve Math Word Problems.” arXiv:2110.14168, 2021. https://arxiv.org/abs/2110.14168
- Isha Puri et al. “Rollout Roulette: A Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo Methods.” arXiv:2502.01618, v5 revised 2025-08-14. https://arxiv.org/abs/2502.01618
- Parshin Shojaee et al. “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity.” arXiv:2506.06941, NeurIPS 2025. https://arxiv.org/abs/2506.06941
- Youpeng Zhao et al. “Are We Scaling the Right Thing? A System Perspective on Test-Time Scaling.” arXiv:2509.19645, 2025. https://arxiv.org/abs/2509.19645
- Aradhye Agarwal, Ayan Sengupta, Tanmoy Chakraborty. “The Art of Scaling Test-Time Compute for Large Language Models.” arXiv:2512.02008, 2025-12-01. https://arxiv.org/abs/2512.02008

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)