Agent Memory 与个性化长期记忆:从向量库到可治理记忆系统
Agent Memory 与个性化长期记忆:从向量库到可治理记忆系统
系列:AI 论文盘点 / 技术趋势,第二轮「2026 AI 系统与 Agent 基础设施」
日期:2026-07-02
适合读者:研究生、科研读者、AI 工程师、AI 产品/平台架构师
摘要
Agent Memory 正在从「把聊天记录塞进向量库」变成一套独立的系统工程:它要决定什么值得记、怎么抽取、如何合并冲突、何时遗忘、如何检索、如何向用户解释,以及如何在隐私、审计和删除权之间取得平衡。2025-2026 年的新论文显示,长期记忆已经不再只是 RAG 的一个小插件,而是 agent 基础设施中的核心资源层:Zep/Graphiti 走向时序知识图谱,Mem0 和 Memoria 强调可生产化的事实抽取与个性化,A-MEM、AgeMem、EverMemOS 试图让 agent 自己管理记忆生命周期,MemOS 把记忆抽象成类似操作系统资源,LongMemEval-V2、PersonaMem-v2、MemoryDocDataSet 则把评测从「能否回忆一句话」推进到环境经验、隐式偏好和跨源推理。与此同时,ChatGPT Memory、LangGraph Memory、Letta、Mem0 等产品与框架已经把长期记忆带入真实应用。下一阶段的关键问题不是「要不要记忆」,而是:哪些记忆有证据、谁有权修改、如何避免记忆投毒和隐私泄露、以及记忆系统能否被评测和治理。
目录
- 研究背景:为什么长期记忆突然变成 agent 基础设施
- 近一年路线图:从向量库到记忆操作系统
- 代表论文分组解读
- 方法对比表
- 关键技术趋势
- 工程落地启发
- 局限与争议
- 接下来值得关注的问题
- 总结
- 参考资料
研究背景:为什么长期记忆突然变成 agent 基础设施
LLM 的「记忆」至少有三层含义。第一层是参数记忆,即模型权重中固化的知识;第二层是工作记忆,即当前上下文窗口;第三层是外部长期记忆,即跨会话保存、检索和更新的用户事实、经验轨迹、任务偏好、工具使用策略和环境知识。过去很多应用把第三层简化为「聊天记录 + embedding + top-k 检索」,但真正的 agent 场景很快会撞到边界。
边界来自三个方面。首先,个性化不是简单相似度检索。用户可能在不同时间表达过相互冲突的偏好,过去事实可能已经过期,隐式偏好也不一定应该被系统自动保存。其次,agent 的记忆不只关于用户,还关于任务和环境:某个代码仓库的构建坑、某个网页后台的操作路径、某个科研项目的实验失败记录,都需要长期保留。第三,记忆天然涉及治理。一个能跨月、跨应用、跨设备记住你的系统,也可能错误推断你的心理状态、泄露敏感信息、被攻击者写入恶意记忆,或者在用户要求删除后仍通过摘要和派生事实残留。
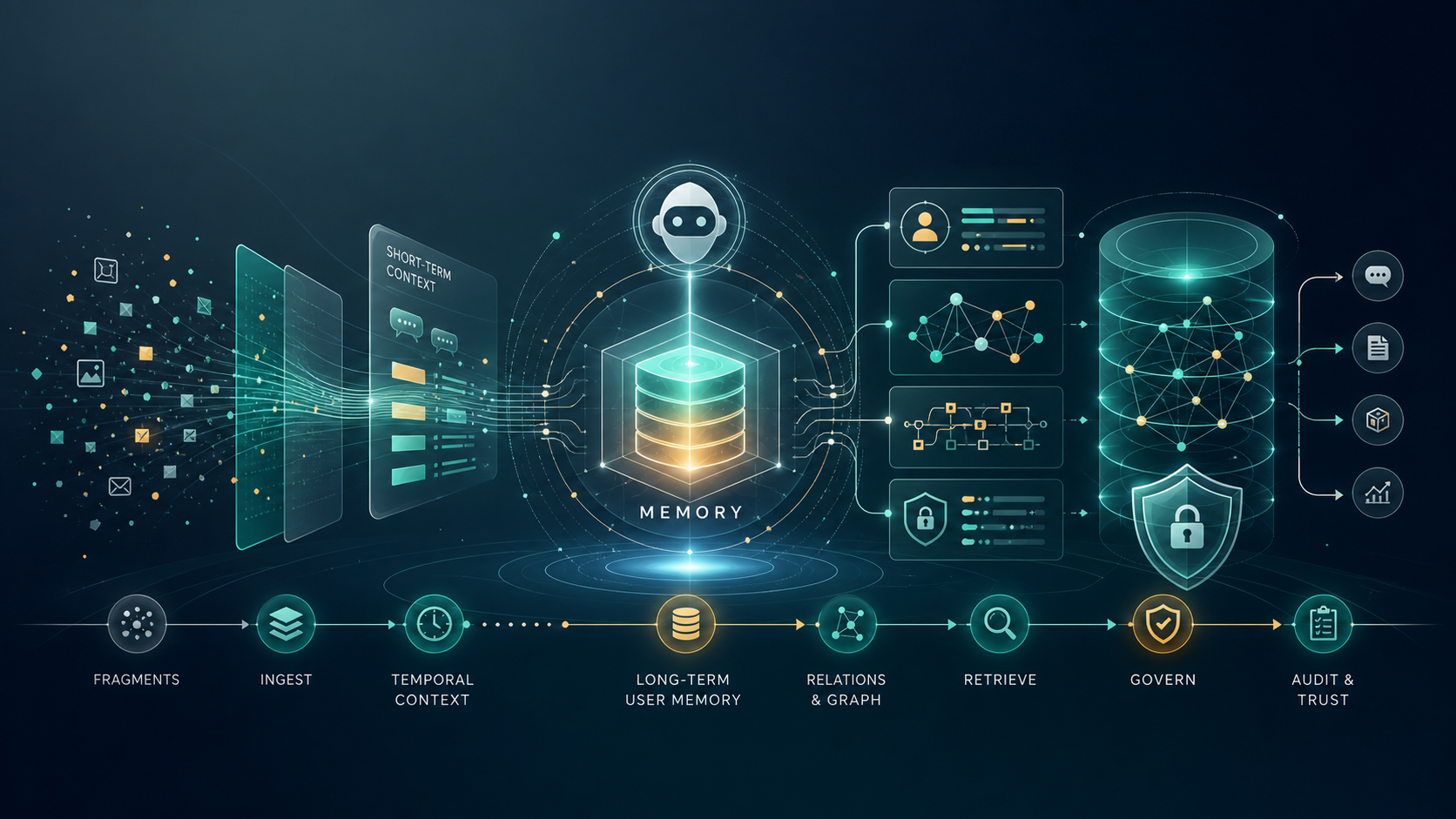
因此,Agent Memory 的研究重心正在从「提升召回率」转向「生命周期管理」。一个成熟记忆系统至少包含写入、抽取、归并、版本化、检索、重排序、引用、删除、遗忘、审计和权限控制。它更像数据库、搜索引擎、日志系统和隐私平台的组合,而不是一个普通向量库。
近一年路线图:从向量库到记忆操作系统
2023 年的 Generative Agents、MemoryBank 和 MemGPT 奠定了三条基础路线。Generative Agents 把观察、反思和规划结合起来,让 agent 从自然语言经验中形成高层反思;MemoryBank 面向长期陪伴和个性化,尝试用遗忘曲线、用户画像和记忆强化来模拟人类式记忆;MemGPT 则明确借鉴操作系统的层级存储,把有限上下文窗口看成「虚拟上下文管理」问题。
2025 年开始,路线明显分化。Zep 提出面向企业 agent 记忆的时序知识图谱架构,强调动态整合对话和业务数据;A-MEM 借鉴 Zettelkasten,用 agentic 写入、链接和更新组织记忆网络;Mem0 把生产环境中的长期会话记忆做成可评测框架,并加入图记忆;MemOS 和 MemoryOS 则把记忆上升为操作系统式资源,讨论表示、调度、迁移、融合和治理。到 2025 年底,MIRIX、Memoria、PersonaMem-v2 等工作进一步覆盖多模态、知识图谱用户画像和隐式个性化。
2026 年的新变化是评测和治理开始补课。LongMemEval-V2 不再只问「用户过去说过什么」,而是评测 web agent 是否记住环境状态、工作流、动态变化和踩坑经验;MemoryDocDataSet 把多会话记忆与长文档推理合在一起,暴露出会话检索和文档检索之间的断裂;Algorithmic Self-Portrait 对真实 ChatGPT 记忆条目做审计,指出系统自动生成记忆会带来用户代理权和敏感推断问题;MemX、SuperLocalMemory、MemPrivacy 等工作则转向本地优先、记忆投毒防御和边云隐私保护。
代表论文分组解读
1. 经典基础:从反思记忆到虚拟上下文
Generative Agents 的核心不是「角色扮演」,而是把 agent 行为拆成 observation、memory stream、retrieval、reflection、planning。它说明长期行为一致性需要经验记录和高层反思共同作用。对今天的 agent 平台来说,这仍是一个重要启发:原始事件日志不等于可用记忆,系统需要把低层事件压缩成可复用经验。
MemoryBank 则把长期陪伴作为应用场景,强调用户画像、情感互动和选择性遗忘。虽然它的实验环境与今天生产系统仍有距离,但它提出的「记忆会随时间强化或衰减」非常现实。不是所有对话内容都应该永久保留;记忆价值应随新证据、任务频率和用户反馈变化。
MemGPT 的影响更偏系统结构。它把上下文窗口视作有限快速存储,把外部存储视作慢速长期层,通过模型主动管理内外存交换来扩展有效上下文。这个类比在 2025-2026 年被 MemOS、MemoryOS、EverMemOS 等工作继续放大:记忆不再是 prompt 附件,而是被调度、压缩、迁移和审计的资源。
2. 生产化记忆层:事实抽取、图结构与企业上下文
Zep 的重点是 temporal knowledge graph。它指出企业 agent 面对的不只是静态文档,而是持续变化的对话、客户、项目和业务实体。Graphiti 这类时序图试图保存「关系何时成立、何时变化、来自哪里」。论文报告其在 DMR 和 LongMemEval 相关评测上优于若干基线,但这些数字仍应按预印本和特定实现条件理解,落地前需要在自有数据上复测。
Mem0 更像一条工程化路线:把会话中的关键信息抽取成可检索事实,并在检索时只返回最相关记忆。论文报告 Mem0 在 LOCOMO 上相对 OpenAI 记忆方案提升了 LLM-as-a-Judge 指标,并显著降低 p95 延迟和 token 成本。这里的关键启发不是某个百分比,而是:长期记忆的收益必须同时看准确率、延迟、token 成本和可维护性。全量上下文也许简单,但在多会话、多用户、多 agent 情况下通常不可持续。
Letta 和 LangGraph 的文档则体现了框架层共识。LangGraph 把短期记忆定义为 thread-scoped state,把长期记忆放入跨线程 namespace/store,并区分 semantic、episodic、procedural memory;Letta 强调 stateful agents,使用 memory blocks、messages、tools 和持久化数据库管理 agent 状态。这些产品化接口说明,长期记忆正在成为开发框架的一等公民。
3. Agentic Memory:让 agent 参与写入、链接和遗忘
A-MEM 的思路是把记忆组织交给 agent,而不是固定 pipeline。新记忆加入时,系统生成带上下文、关键词、标签等属性的 note,并让 agent 分析历史记忆、建立连接、更新旧记忆表示。它借鉴 Zettelkasten 的核心思想:知识不是孤立卡片,而是不断链接和演化的网络。
AgeMem 在 2026 年进一步提出把长短期记忆管理作为 agent policy 的一部分:存储、检索、更新、总结、丢弃都可以作为工具动作,并用逐步强化学习训练何时执行这些动作。这个方向很重要,因为真实 agent 的记忆决策高度依赖任务阶段。客服 agent、代码 agent、科研 agent、个人助理对「值得记住」的判断完全不同,固定规则很难通吃。
EverMemOS 则强调自组织生命周期:从 episodic trace 形成 MemCells,到 semantic consolidation 形成 MemScenes,再通过 reconstructive recollection 组合下游推理所需上下文。它的概念价值在于把记忆从「写入一次、检索多次」改成「持续巩固、修正、重构」。但这类 agentic 记忆也带来新风险:系统自动改写旧记忆时,必须保留原始证据、版本和可回滚能力,否则很难审计错误是何时引入的。
4. 个性化与隐式偏好:记住用户,还是过度推断用户?
PersonaMem-v2 把个性化评测推向隐式偏好。现实中用户很少说「请记住我偏好 X」,更多是在长期对话中间接暴露目标、约束、风格和禁忌。该数据集用大量模拟用户交互和偏好来评测模型是否能理解隐式 persona,并报告 frontier LLM 在隐式个性化上仍然困难。这里的工程启发是:个性化记忆不能只靠显式 facts,还要处理 preference inference;但推断越强,治理要求越高。
Algorithmic Self-Portrait 直接审计真实 ChatGPT 记忆条目。论文分析 80 名用户的 2,050 条记忆,报告多数记忆由系统单方面生成,并包含个人数据和心理推断。这个结果对所有长期记忆产品都是警示:用户可能并不知道系统把哪些句子转化成了长期画像。记忆界面不应只提供「删除所有记忆」,还应提供来源、置信度、敏感类型、最近使用记录和可编辑解释。
MemPrivacy 则从边云架构切入,尝试在端侧识别隐私敏感 span,用类型化占位符参与云侧记忆处理,再在本地恢复原值。这个方向适合移动端、企业桌面 agent 和医疗/法律/金融等场景:记忆的语义结构可以参与检索,但原始敏感值不必暴露给云端。相关实验数字仍需人工核验和复现,但问题定义本身已经很清楚。
5. 评测:从聊天回忆到环境经验与跨源推理
LongMemEval 是长期聊天记忆评测的重要基准,覆盖信息抽取、多会话推理、时间推理、知识更新和拒答等能力。它提醒我们,长期记忆不是单一检索任务。一个系统既要找得到旧事实,也要知道事实是否过期,还要在没有相关记忆时拒绝胡编。
LongMemEval-V2 把对象换成 specialized web environments。它评测 agent 是否能从多达 500 条轨迹、上亿 token 的历史中提取静态状态、动态状态、工作流、环境坑点和 premise awareness。论文报告基于 coding agent 的 AgentRunbook-C 表现强,但延迟成本高。这说明下一代记忆系统可能不只是向量检索,而是「文件化经验库 + 可执行证据收集 agent + 检索摘要」的混合架构。
MemoryDocDataSet 进一步指出,真实任务往往要求先从对话记忆中找出相关文档,再在长文档中做精读。单独优化 conversation memory 或 document RAG 都不够,系统需要联合检索和跨源证据链。对科研、法律、客服和企业知识库来说,这可能是非常常见的失败模式。
方法对比表
| 路线 | 代表工作/系统 | 记忆形态 | 适合场景 | 主要风险 |
|---|---|---|---|---|
| 全量历史上下文 | 长上下文模型、简单聊天归档 | 原始消息序列 | 小规模、低频会话、审计回放 | 成本高、干扰强、隐私暴露面大 |
| 向量库/RAG | 传统 memory RAG、部分 LangGraph store 实现 | chunk、事实、摘要 | 低成本召回、文档或会话检索 | 时间关系弱、冲突处理弱、误召回 |
| 结构化画像 | MemoryBank、Memoria、PersonaMem-v2 | 用户 profile、偏好、属性 | 个性化助手、CRM、教育陪伴 | 过度推断、画像陈旧、用户代理权不足 |
| 时序/图记忆 | Zep/Graphiti、Mem0 graph、MemoTime | 实体、关系、时间戳、证据 | 企业上下文、多实体多跳推理 | 图构建错误会长期传播 |
| Agentic memory | A-MEM、AgeMem、EverMemOS | agent 写入、链接、更新、遗忘 | 长周期任务、研究/代码/web agent | 自动改写难审计,训练和评测复杂 |
| 记忆操作系统 | MemGPT、MemOS、MemoryOS | 层级存储、MemCube、资源调度 | 平台级 agent runtime | 抽象宏大,标准和互操作仍未稳定 |
| 本地/隐私优先 | MemX、SuperLocalMemory、MemPrivacy | 本地数据库、FTS、隐私占位符 | 桌面 agent、企业内网、敏感行业 | 多端同步、可用性和模型能力受限 |
关键技术趋势
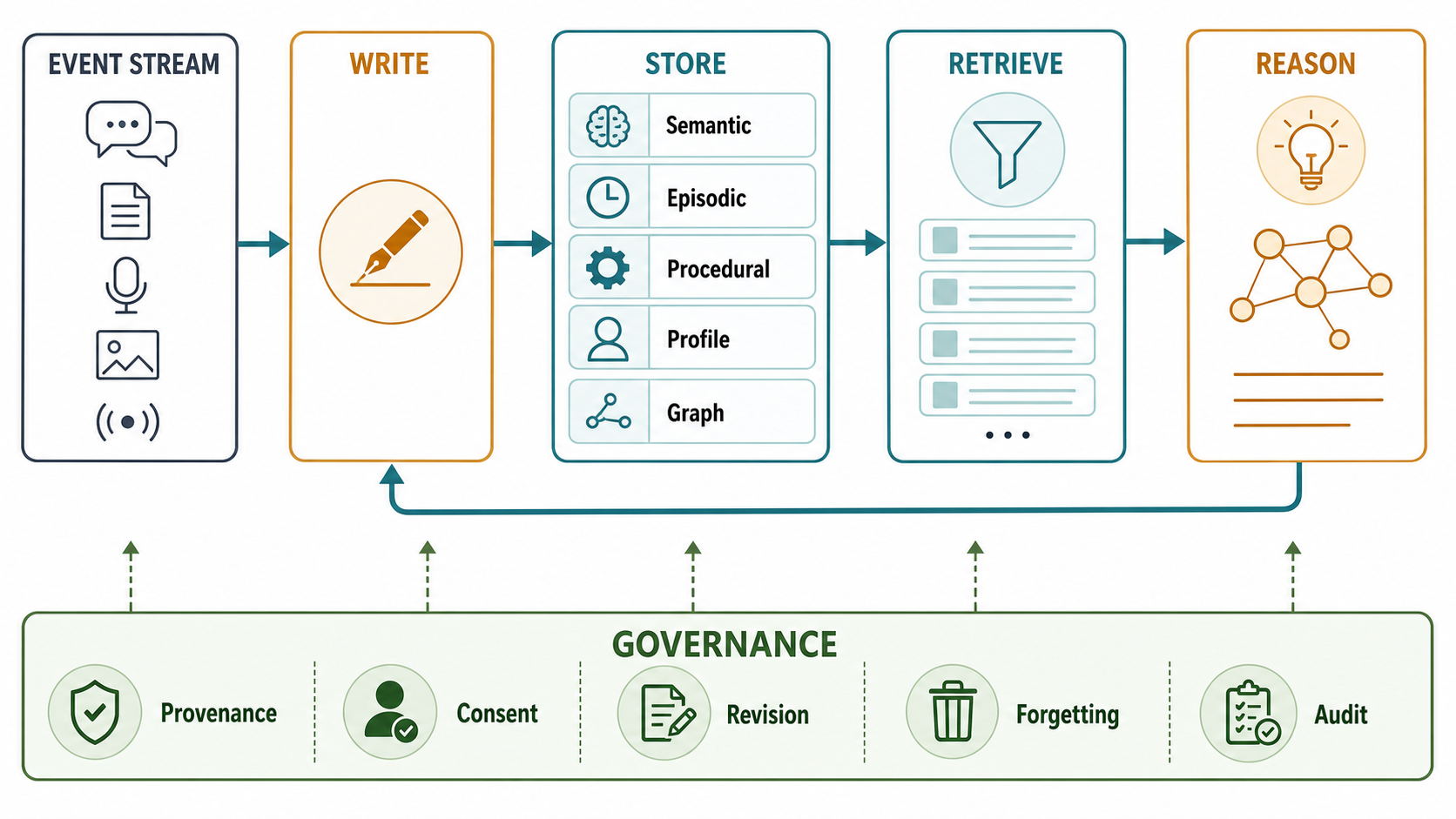
第一,记忆写入正在从同步工具调用走向异步后台服务。LangGraph 文档把写入分成 hot path 和 background:前者即时可用但增加延迟,后者更易批处理和去重,但可能让其他线程短期拿不到新记忆。生产系统通常需要两者结合:显式用户指令、偏好修改和安全相关记忆走热路径;普通对话摘要、去重和巩固走后台任务。
第二,记忆粒度正在从 chunk 走向 evidence-backed fact。长会话中直接存 chunk 容易召回无关上下文;只存抽取事实又容易丢失证据和语气。较稳妥的设计是同时保存原始 episode、抽取事实、来源 span、时间戳、置信度和更新历史。回答时返回的是紧凑事实,但审计时能回放原文。
第三,图和时间成为长期记忆的核心结构。个性化最难的地方往往不是「用户喜欢咖啡」,而是「用户过去喜欢咖啡,但最近因为睡眠问题改喝茶」「这个偏好只适用于工作日」「这个结论来自一次玩笑还是明确指令」。没有时间、实体和关系,很多记忆会在跨月交互中变成误导。
第四,记忆评测正在多维化。只看 QA accuracy 不够,还要看拒答、过期事实更新、冲突消解、敏感信息处理、删除后残留、延迟、token 成本、写入噪声、误召回率和用户可控性。记忆系统会有自己的 eval harness,而不是附属于通用 LLM benchmark。
第五,治理层会成为差异化能力。产品层的记忆开关只是第一步。真正可用的长期记忆需要 memory diff、memory provenance、用户确认策略、敏感类型策略、租户隔离、审计日志、TTL、删除传播、导出格式和数据保留策略。
工程落地启发
如果你今天要给 agent 产品加长期记忆,不建议从「买一个向量库」开始,而应先定义记忆契约。
第一,定义 memory schema。至少区分事实、偏好、任务状态、环境经验、程序性规则和原始事件;每条记忆要有 subject、source、timestamp、confidence、scope、ttl、sensitivity、last_used_at、superseded_by 等字段。没有 schema 的自然语言记忆很快会失控。
第二,写入前先设计权限。哪些内容必须用户显式同意?哪些内容可以自动保存但必须可见?哪些内容只能在本地保存?哪些内容默认不保存,例如健康、财务、未成年人、身份认证、亲密关系和心理状态?这些策略应在系统层实现,而不是靠 prompt 提醒模型「请谨慎」。
第三,检索要有 abstention。长期记忆最危险的失败之一是把错误记忆自信地带入回答。MemX、LongMemEval 等工作都提醒我们,低置信拒绝和「没有找到相关记忆」同样重要。工程上可使用混合检索、RRF、时间过滤、实体过滤、重排序和证据阈值,但必须记录为什么召回某条记忆。
第四,给用户一个 memory inbox。所有新写入或高敏推断的记忆都进入可审核列表,用户可以确认、编辑、降级为短期、设置过期或删除。对企业场景,还要支持管理员策略和租户级审计,但不能让管理员随意查看个人敏感记忆。
第五,把删除当成系统功能,而不是 UI 功能。删除一条记忆后,派生摘要、图边、缓存、prompt profile、离线训练样本和跨设备副本都要处理。否则「删除」只是在前端隐藏。
第六,评测要使用你自己的长周期轨迹。公开基准能提供方向,但每个产品的记忆语义都不同。客服要测 ticket continuity,代码 agent 要测仓库经验和构建坑,科研 agent 要测实验参数演化,个人助理要测偏好更新和隐私控制。
局限与争议
第一,很多 2025-2026 年记忆论文仍是 arXiv 预印本,评测数据、实现细节和对照条件需要人工复核。尤其是带有「SOTA」「大幅降低成本」的声明,最好在同一模型、同一数据、同一延迟预算下复测。
第二,长期记忆与长上下文模型不是替代关系。长上下文适合一次性读入大材料,长期记忆适合跨会话、跨任务、跨时间的状态维护。未来系统大概率同时使用两者:长上下文做深读,长期记忆做持续状态。
第三,个性化和操控之间边界模糊。当模型长期记住用户目标、弱点、风格和情绪反应时,推荐、说服和依赖关系都会更强。记忆系统的安全评估不能只看隐私泄露,还要看行为影响。
第四,自动记忆会改变人机关系。一个助手如果主动记住用户未明确要求保存的内容,短期会更贴心,长期可能让用户失去控制感。Algorithmic Self-Portrait 的结果说明,记忆透明度本身就是产品体验的一部分。
接下来值得关注的问题
- 是否会出现通用 memory schema 或 memory interchange format,让用户能在不同 agent 产品之间迁移记忆?
- 记忆写入是否会从 prompt 规则走向经过训练的 policy,例如 AgeMem 这类 RL 路线?
- 图记忆和向量记忆如何结合,才能同时支持事实召回、关系推理、时间推理和低延迟?
- 记忆投毒、跨会话 prompt injection 和恶意偏好写入会不会成为 agent 安全的新主战场?
- 删除权、解释权和可携带权如何在长期记忆系统中实现,而不只是合规文档中的承诺?
- 本地优先记忆能否在移动端和桌面端形成主流架构,尤其是在个人助理和企业 agent 场景?
总结
Agent Memory 的下一阶段不会只是「更大的上下文」或「更好的向量检索」。真正有价值的长期记忆系统必须同时解决四件事:记得准、用得对、改得动、删得干净。2025-2026 年的研究已经把问题从算法技巧推进到系统架构:记忆有类型、有生命周期、有证据、有权限、有评测,也有风险。对工程团队而言,最务实的路线是先把记忆当作受治理的数据资产,而不是当作 prompt 的附属品。只有这样,个性化 agent 才可能从短期演示走向长期可信协作。
参考资料
检索日期:2026-07-02。以下优先列出 arXiv、官方文档和项目文档;2025-2026 年预印本的实验结论均建议在引用前再次人工核验。
- Joon Sung Park et al., Generative Agents: Interactive Simulacra of Human Behavior, arXiv, 2023. https://arxiv.org/abs/2304.03442
- Wanjun Zhong et al., MemoryBank: Enhancing Large Language Models with Long-Term Memory, arXiv, 2023. https://arxiv.org/abs/2305.10250
- Charles Packer et al., MemGPT: Towards LLMs as Operating Systems, arXiv, 2023. https://arxiv.org/abs/2310.08560
- Di Wu et al., LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, arXiv, 2024. https://arxiv.org/abs/2410.10813
- Preston Rasmussen et al., Zep: A Temporal Knowledge Graph Architecture for Agent Memory, arXiv, 2025. https://arxiv.org/abs/2501.13956
- Wujiang Xu et al., A-MEM: Agentic Memory for LLM Agents, arXiv, 2025. https://arxiv.org/abs/2502.12110
- Prateek Chhikara et al., Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, arXiv, 2025. https://arxiv.org/abs/2504.19413
- Zhiyu Li et al., MemOS: An Operating System for Memory-Augmented Generation in Large Language Models, arXiv, 2025. https://arxiv.org/abs/2505.22101
- Yu Wang and Xi Chen, MIRIX: Multi-Agent Memory System for LLM-Based Agents, arXiv, 2025. https://arxiv.org/abs/2507.07957
- Bowen Jiang et al., PersonaMem-v2: Towards Personalized Intelligence via Learning Implicit User Personas and Agentic Memory, arXiv, 2025. https://arxiv.org/abs/2512.06688
- Yi Yu et al., Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents, arXiv, 2026. https://arxiv.org/abs/2601.01885
- Chuanrui Hu et al., EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning, arXiv, 2026. https://arxiv.org/abs/2601.02163
- Abhisek Dash et al., The Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT, arXiv, 2026. https://arxiv.org/abs/2602.01450
- Lizheng Sun, MemX: A Local-First Long-Term Memory System for AI Assistants, arXiv, 2026. https://arxiv.org/abs/2603.16171
- Di Wu et al., LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues, arXiv, 2026. https://arxiv.org/abs/2605.12493
- Qiyang Xie et al., MemoryDocDataSet: A Benchmark for Joint Conversational Memory and Long Document Reasoning, arXiv, 2026. https://arxiv.org/abs/2606.04442
- LangChain Docs, Memory overview, accessed 2026-07-02. https://docs.langchain.com/oss/python/concepts/memory
- Letta Docs, Introduction to Stateful Agents, accessed 2026-07-02. https://docs.letta.com/guides/core-concepts/stateful-agents
- Mem0 Docs, Overview, accessed 2026-07-02. https://docs.mem0.ai/platform/overview
- OpenAI Help Center, Memory FAQ, accessed 2026-07-02. https://help.openai.com/en/articles/8590148-memory-faq

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)