DeepSeekOCR2的理解1——摘要和引言
文章目录
一、前言
仅供参考,未经实验验证。
二、DeepSeek-OCR 2
论文标题: DeepSeek-OCR 2: Visual Causal Flow(DeepSeek-OCR 2:视觉因果流)
(DeepSeekMath-V2:迈向自我验证的数学推理)
作者: Haoran Wei, Yaofeng Sun, Yukun Li
机构: DeepSeek-AI
发表时间: 2026年1月28日
GitHub: https://github.com/deepseek-ai/DeepSeek-OCR-2
论文地址: https://arxiv.org/pdf/2601.20552
核心动机
传统视觉语言模型(VLM)将图像 patch 按固定的栅格扫描顺序(左上到右下)展平为1D序列输入LLM,并配以固定的位置编码。但这与人类视觉感知矛盾——人类阅读文档时遵循语义驱动的灵活扫描模式,例如先看标题、再浏览图表、最后处理正文。论文提出:2D图像理解是否可以通过两个级联的1D因果推理结构有效实现?
核心创新:DeepEncoder V2
DeepEncoder V2 是 DeepSeek-OCR 编码器的重大升级,核心是用 LLM 架构替代 CLIP ViT,引入**视觉因果流(Visual Causal Flow)**机制:
| 组件 | 说明 |
|---|---|
| Vision Tokenizer | 80M参数的SAM-base + 两层卷积,实现16× token压缩,输出维度896 |
| LM as Vision Encoder | 用 Qwen2-0.5B(500M参数)替代CLIP ViT(300M),参数规模相当 |
| Causal Flow Queries | 可学习的因果流查询token,数量与视觉token相等(256–1120个) |
| Attention Mask | 双流注意力:视觉token用双向注意力(ViT式),因果查询用因果注意力(LLM式) |
关键设计:视觉token作为前缀,因果查询作为后缀。每个查询可以attend到所有视觉token和前面的查询,从而逐步对视觉信息进行语义重排序。最终只有因果查询的输出传给LLM解码器,形成"编码器因果重排 → 解码器自回归生成"的两级级联因果推理。
架构细节
Token数量策略(多裁剪):
- 全局视图:1024×1024 → 256 tokens
- 局部视图:768×768 → 144 tokens/个,最多6个
- 总token数范围:256–1120,上限与 Gemini-3 Pro 的最大视觉token预算对齐
解码器:沿用 DeepSeek-OCR 的 DeepSeek-3B MoE 结构(约500M活跃参数),确保性能提升主要来自编码器侧而非解码器暴力扩容。
注意力掩码结构(如图5所示):
M = [ 1_{m×m} 0_{m×n} ]
[ 1_{n×m} LowerTri(n) ]
其中 m 为视觉token数,n 为因果查询数(n=m),LowerTri 为下三角矩阵。
实验与性能
OmniDocBench v1.5 评测:
- 综合得分 91.09%,相比 DeepSeek-OCR 基线提升 3.73%
- 在表格结构识别、版式还原保真度等复杂布局任务上进步显著
效率优势:
- 视觉token压缩比高(16×),激活内存低
- 支持动态分辨率(0–6个局部裁剪自适应)
- 可用消费级显卡(如RTX 4090)本地部署,支持vLLM加速
主要贡献总结
- DeepEncoder V2:首次在视觉编码器中引入因果推理能力,实现视觉token的动态语义重排,打破固定栅格扫描的归纳偏置。
- DeepSeek-OCR 2:在保持高压缩比和解码效率的同时,文档理解性能显著提升,是文档OCR领域的新SOTA开源模型。
- 统一多模态编码的初步验证:证明LLM架构可直接作为VLM编码器,天然继承MoE、高效注意力等LLM社区优化,为图像、音频、文本的统一编码提供新路径。
局限与未来方向
- 手写体识别:在极端手写体场景上仍有提升空间
- 通用视觉理解:当前以文档OCR为主实验场景,未来需扩展到更广泛的视觉任务
- 真正的2D推理:论文提出这是向"genuine 2D reasoning"迈进的一步,但级联1D结构是否能完全替代2D注意力仍需探索
问题1:通俗解释
一句话总结
DeepSeek-OCR 2 做了一件很简单但很重要的事:它让 AI 看图片不再像"扫描仪"死板地逐行扫描,而是像人一样"有逻辑地跳读"。
传统 AI 是怎么看图片的?
想象你拿到一张报纸,上面有大标题、小标题、图片、表格和正文。
传统 AI 的做法:它像一台扫描仪,从左上角开始,一行一行、一列一列,死板地"扫"完整张纸。然后把扫到的所有内容,按这个固定顺序塞给大脑(LLM)去处理。
问题在哪? 如果标题在右下角,表格在中间,正文在左边,传统 AI 会先读一堆正文,中间突然插入一个表格,最后才看到标题——这完全不符合人类的阅读习惯。
人是怎么看图片的?
人的做法:你的眼睛会"跳来跳去"。
- 先看大标题(知道主题)
- 再扫图片/图表(获取关键信息)
- 然后看正文(读细节)
- 遇到表格会专门盯着看
而且,你的下一步看哪里,取决于你刚才看到了什么。比如看到"见图3",你的眼睛就会跳到图3的位置。这就是**“因果流”**——每一步的视觉焦点都"因果依赖"于之前的理解。
DeepSeek-OCR 2 的聪明之处
论文的核心就是让 AI 也能像人一样"因果跳读"。
它做了两个关键改造:
1. 把"扫描仪"换成"侦探"
- 传统模型用 CLIP(一个专门看图的模型)来提取图片特征,就像用扫描仪。
- DeepSeek-OCR 2 换成了一个小型语言模型(Qwen2-0.5B)来当"眼睛"。
- 为什么用语言模型?因为语言模型天生擅长**“下一步该看什么”**的推理——它读句子时就是因果依赖的。
2. 发明了一套"双流注意力"机制
想象图片被切成了很多小方块(token),模型处理时有两种角色:
| 角色 | 作用 | 通俗比喻 |
|---|---|---|
| 视觉 token | 保留图片的全局信息,每个小方块都能看到整张图 | 像一张完整的地图,摊在桌上 |
| 因果流查询 | 可学习的"阅读顺序标记",按因果顺序逐步重排信息 | 像侦探的手指,在地图上按逻辑顺序指点 |
关键设计:地图(视觉token)是双向的——每个点都知道其他所有点的存在;但侦探的手指(因果查询)是单向的——手指下一步指哪里,只能依赖之前指过的位置。
最后,只有侦探的手指轨迹(因果查询的输出)被传给大脑(LLM),而不是整张地图的原始扫描顺序。
效果怎么样?
在文档 OCR 上:
- 传统模型读复杂论文、发票、表格时,经常把左右栏搞混、把表格内容读错行。
- DeepSeek-OCR 2 在权威测试集 OmniDocBench 上拿了 91.09% 的高分,比上一代提升了 3.73%。
在效率上:
- 它能把一张图压缩成 256~1120 个"信息块",既省算力又省显存。
- 普通显卡(比如 RTX 4090)就能跑,还能用 vLLM 加速。
一个形象的比喻
想象你在餐厅看菜单:
- 传统 AI:从菜单左上角第一个字开始,逐字逐句读到右下角,不管标题、价格、图片在哪。
- DeepSeek-OCR 2:先看"今日推荐"大标题 → 扫一眼图片 → 看价格 → 再看具体菜名。而且,看到"套餐详见背面"时,它会"翻过去"继续看。
它让 AI 第一次拥有了"阅读策略"——知道什么该先看,什么该后看,下一步该跳到哪。
为什么这事重要?
这篇论文其实在探索一个更大的问题:AI 能不能真正理解"二维空间"?
现在的 LLM 本质上是一维的——它只能从左到右读一串文字。把图片硬塞成一维序列,就像把一幅画撕成纸条再拼起来读,总会丢失空间关系。
DeepSeek-OCR 2 的思路是:也许不需要让 LLM 直接变成2D的,而是让"眼睛"(编码器)先把2D图片按语义逻辑重排成1D的因果流,再交给1D的 LLM 去理解。
这就像给 LLM 配了一个会翻译的向导——向导先按人类逻辑把图片"讲成故事",LLM 再听故事。这比让 LLM 直接看图要自然得多。
总结:DeepSeek-OCR 2 不是让 AI 看得更"多",而是让 AI 看得更"聪明"——学会了像人一样,按语义因果去"跳读"图片。
摘要
We present DeepSeek-OCR 2 to investigate the feasibility of a novel encoder—DeepEncoder V2—capable of dynamically reordering visual tokens upon image semantics. Conventional vision-language models (VLMs) invariably process visual tokens in a rigid raster-scan order (top-left to bottom-right) with fixed positional encoding when fed into LLMs.
我们提出了DeepSeek-OCR 2,以研究一种新颖编码器—DeepEncoder V2—的可行性,该编码器能够根据图像语义动态地重新排序视觉标记。传统的视觉语言模型(VLM)在输入大型语言模型(LLM)时,总是以固定的位置编码,采用僵化的光栅扫描顺序(从左上到右下)来处理视觉标记。
However, this contradicts human visual perception, which follows flexible yet semantically coherent scanning patterns driven by inherent logical structures. Particularly for images with complex layouts, human vision exhibits causally-informed sequential processing. Inspired by this cognitive mechanism, DeepEncoder V2 is designed to endow the encoder with causal reasoning capabilities, enabling it to intelligently reorder visual tokens prior to LLM-based content interpretation.
然而,这与人类的视觉感知相悖——人类的视觉遵循由内在逻辑结构驱动的、灵活且语义连贯的扫描模式。特别是在面对版式复杂的图像时,人类的视觉系统会表现出因果驱动的序列化处理特征。受这一认知机制的启发,DeepEncoder V2 旨在赋予编码器以因果推理能力,使其能够在基于 LLM 的内容理解之前,智能地对视觉 token 进行重新排序。
This work explores a novel paradigm: whether 2D image understanding can be effectively achieved through two-cascaded 1D causal reasoning structures, thereby offering a new architectural approach with the potential to achieve genuine 2D reasoning. Codes and model weights are publicly accessible at http://github.com/deepseek-ai/DeepSeek-OCR-2.
本研究探索了一种新范式:是否可以通过两个级联的一维因果推理结构有效地实现二维图像理解,从而提供一种具有实现真正二维推理潜力的新架构方法。代码和模型权重可在 http://github.com/deepseek-ai/DeepSeek-OCR-2 公开获取。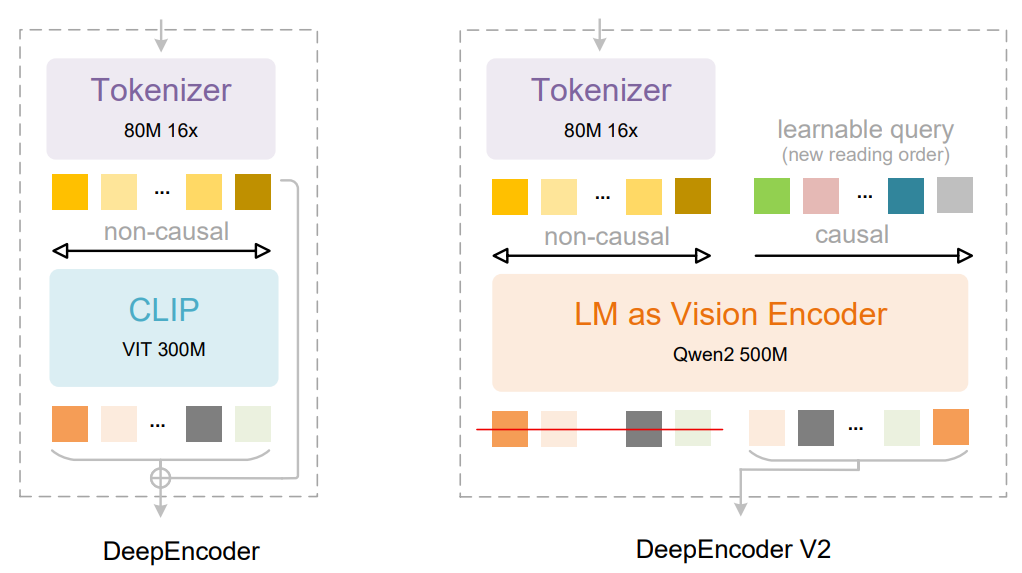
Figure 1 | We substitute the CLIP component in DeepEncoder with an LLM-style architecture. By customizing the attention mask, visual tokens utilize bidirectional attention while learnable queries adopt causal attention. Each query token can thus attend to all visual tokens and preceding queries, allowing progressive causal reordering over visual information.
图 1 | 我们用 LLM 风格的架构替换了 DeepEncoder 中的 CLIP 组件。通过自定义注意力掩码,视觉标记利用双向注意力,而可学习的查询采用因果注意力。因此,每个查询标记都可以关注所有视觉标记和前面的查询,从而允许对视觉信息进行渐进的因果重排序。
1. 引言
The human visual system closely mirrors transformer-based vision encoders [14, 16]: foveal fixations function as visual tokens, locally sharp yet globally aware. However, unlike existing encoders that rigidly scan tokens from top-left to bottom-right, human vision follows a causallydriven flow guided by semantic understanding.
人类的视觉系统与基于 Transformer 的视觉编码器[14, 16]非常相似:中央凹注视(foveal fixations)充当视觉 token,局部清晰锐利,同时具备全局感知能力。然而,与现有编码器死板地按从左上到右下的顺序扫描 token 不同,人类视觉遵循一种由语义理解引导的因果驱动流。
Consider tracing a spiral—our eye movements follow inherent logic where each subsequent fixation causally depends on previous ones. By analogy, visual tokens in models should be selectively processed with ordering highly contingent on visual semantics rather than spatial coordinates.
试想你在追踪一条螺旋线——我们的眼球运动遵循某种内在逻辑,其中每一次后续的注视都因果地依赖于先前的注视。以此类推,模型中的视觉 token 也应当被选择性地处理,其排序应高度取决于视觉语义,而非空间坐标。
This insight motivates us to fundamentally reconsider the architectural design of visionlanguage models (VLMs), particularly the encoder component. LLMs are inherently trained on 1D sequential data, while images are 2D structures. Directly flattening image patches in a predefined raster-scan order introduces unwarranted inductive bias that ignores semantic relationships.
这一洞见促使我们从根本上重新思考视觉语言模型(VLMs)的架构设计,特别是编码器组件。LLMs 本质上是在一维序列数据上训练的,而图像是二维结构。直接以预定义的栅格扫描顺序展平图像块会引入不必要的归纳偏置,忽略了语义关系。
To address this, we present DeepSeek-OCR 2 with a novel encoder design—DeepEncoder V2—to advance toward more human-like visual encoding. Following DeepSeek-OCR [54], we adopt document reading as our primary experimental testbed. Documents present rich challenges including complex layout orders, intricate formulas, and tables.
为了解决这个问题,我们提出了DeepSeek-OCR 2,它采用了一种新颖的编码器设计——DeepEncoder V2,以实现更接近人类的视觉编码。继DeepSeek-OCR [54]之后,我们将文档阅读作为主要的实验测试平台。文档呈现出丰富的挑战,包括复杂的布局顺序、精细的公式和表格。
These structured elements inherently carry causal visual logic, demanding sophisticated reasoning capabilities that make document OCR an ideal platform for validating our approach.
这些结构化元素本身就带有因果视觉逻辑,需要复杂的推理能力,这使得文档 OCR 成为验证我们方法的理想平台。
Our main contributions are threefold:
我们的主要贡献有三方面:
First, we present DeepEncoder V2, featuring several key innovations:
(1) we replace the CLIP [37] component in DeepEncoder [54] with a compact LLM [48] architecture, as illustrated in Figure 1, to achieve visual causal flow;
(2) to enable parallelized processing, we introduce learnable queries [10], termed causal flow tokens, with visual tokens prepended as a prefix—through a customized attention mask, visual tokens maintain global receptive fields, while causal flow tokens can obtain visual token reordering ability;
(3) we maintain equal cardinality between causal and visual tokens (with redundancy such as padding and borders) to provide sufficient capacity for re-fixation;
(4) only the causal flow tokens—the latter half of the encoder outputs—are fed to the LLM [24] decoder, enabling cascade causal-aware visual understanding.
首先,我们提出了DeepEncoder V2,它具有几个关键创新点:
(1)我们用一个紧凑的LLM [48]架构取代了DeepEncoder [54]中的CLIP [37]组件,如图1所示,以实现视觉因果流;(2)为了实现并行处理,我们引入了可学习的查询[10],称为因果流tokens,并将视觉tokens作为前缀预先添加——通过定制的注意力掩码,视觉tokens保持全局感受野,而因果流tokens可以获得视觉token重排序能力;
(3)我们保持因果tokens和视觉tokens之间相等的基数(具有诸如填充和边界之类的冗余),以便为重新注视提供足够的容量;
(4)只有因果流tokens——编码器输出的后半部分——被馈送到LLM [24]解码器,从而实现级联的、具有因果意识的视觉理解。
Second, leveraging DeepEncoder V2, we present DeepSeek-OCR 2, which preserves the image compression ratio and decoding efficiency of DeepSeek-OCR while achieving substantial performance improvements. We constrain visual tokens fed to the LLM between 256 and 1120. The lower bound (256) corresponds to DeepSeek-OCR’s tokenization of 1024×1024 images, while the upper bound (1120) matches Gemini-3 pro’s [44] maximum visual token budget.
其次,我们利用DeepEncoder V2提出了DeepSeek-OCR 2,它在保持DeepSeek-OCR的图像压缩比和解码效率的同时,实现了显著的性能提升。我们将输入到LLM的视觉令牌限制在256到1120之间。下界(256)对应于DeepSeek-OCR对1024×1024图像的标记化,而上界(1120)则匹配Gemini-3 pro的[44]最大视觉令牌预算。
This design positions DeepSeek-OCR 2 as both a novel VLM architecture for research exploration and a practical tool for generating high-quality training data for LLM pretraining.
该设计将 DeepSeek-OCR 2 定位为用于研究探索的新型视觉语言模型(VLM)架构,以及用于为大型语言模型(LLM)预训练生成高质量训练数据的实用工具。
Finally, we provide preliminary validation for employing language model architectures as VLM encoders—a promising pathway toward unified omni-modal encoding. This framework enables feature extraction and token compression across diverse modalities (images, audio, text [28]) by simply configuring modality-specific learnable queries. Crucially, it naturally succeeds to advanced infrastructure optimizations from the LLM community, including Mixtureof-Experts (MoE) architectures, efficient attention mechanisms [26], and so on.
最后,我们为采用语言模型架构作为VLM编码器提供了初步验证——这是实现统一全模态编码的一个有希望的途径。该框架通过简单地配置特定于模态的可学习查询,能够跨多种模态(图像、音频、文本 [28])进行特征提取和令牌压缩。至关重要的是,它自然地继承了来自LLM社区的先进基础设施优化,包括专家混合(MoE)架构、高效注意力机制 [26] 等。
In summary, we propose DeepEncoder V2 for DeepSeek-OCR 2, employing specialized attention mechanisms to effectively model the causal visual flow of document reading. Compared to the DeepSeek-OCR baseline, DeepSeek-OCR 2 achieves 3.73% performance gains on OmniDocBench v1.5 [34] and yields considerable advances in visual reading logic.
总而言之,我们提出了用于DeepSeek-OCR 2的DeepEncoder V2,它采用专门的注意力机制来有效地建模文档阅读的因果视觉流。与DeepSeek-OCR基线相比,DeepSeek-OCR 2在OmniDocBench v1.5 [34]上实现了3.73%的性能提升,并在视觉阅读逻辑方面取得了显著进展。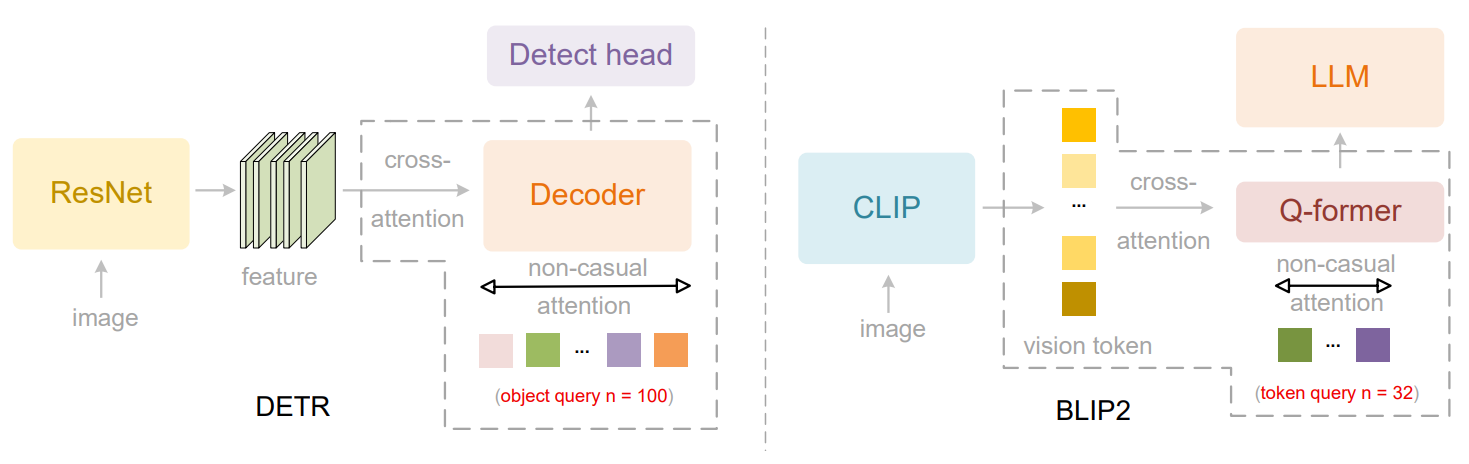
Figure 2 | This figure shows two computer vision models with parallelized queries: DETR’s decoder [10] for object detection and BLIP2’s Q-former [22] for visual token compression. Both employ bidirectional self-attention among queries.
图 2 | 此图展示了两个具有并行化查询的计算机视觉模型:用于目标检测的 DETR 解码器 [10] 和用于视觉令牌压缩的 BLIP2 的 Q-former [22]。两者都在查询之间采用双向自注意力机制。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 2
2 0
0- 0


 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)