涨价预警!DeepSeek V4 正式版 7 月中旬上线,高峰时段 API 价格翻倍
DeepSeek 高峰时段涨价
昨天下文收到邮件:
-
DeepSeek V4 正式版计划于 7 月中旬正式上线(还有十几天),现在的是4月24日发布的预览版
-
正式版发布后,DeepSeek API 高峰时段价格翻倍(每日 9:00~12:00 和 14:00~18:00)。
调整后的价格:
- deepseek-v4-pro
| 计费项 | 平时价格 | 高峰时段价格 |
|---|---|---|
| 百万tokens输入(缓存命中) | 0.025 元 | 0.05 元 |
| 百万tokens输入(缓存未命中) | 3 元 | 6 元 |
| 百万tokens输出 | 6 元 | 12 元 |
- deepseek-v4-flash
| 计费项 | 平时价格 | 高峰时段价格 |
|---|---|---|
| 百万tokens输入(缓存命中) | 0.02 元 | 0.04 元 |
| 百万tokens输入(缓存未命中) | 1 元 | 2 元 |
| 百万tokens输出 | 2 元 | 4 元 |
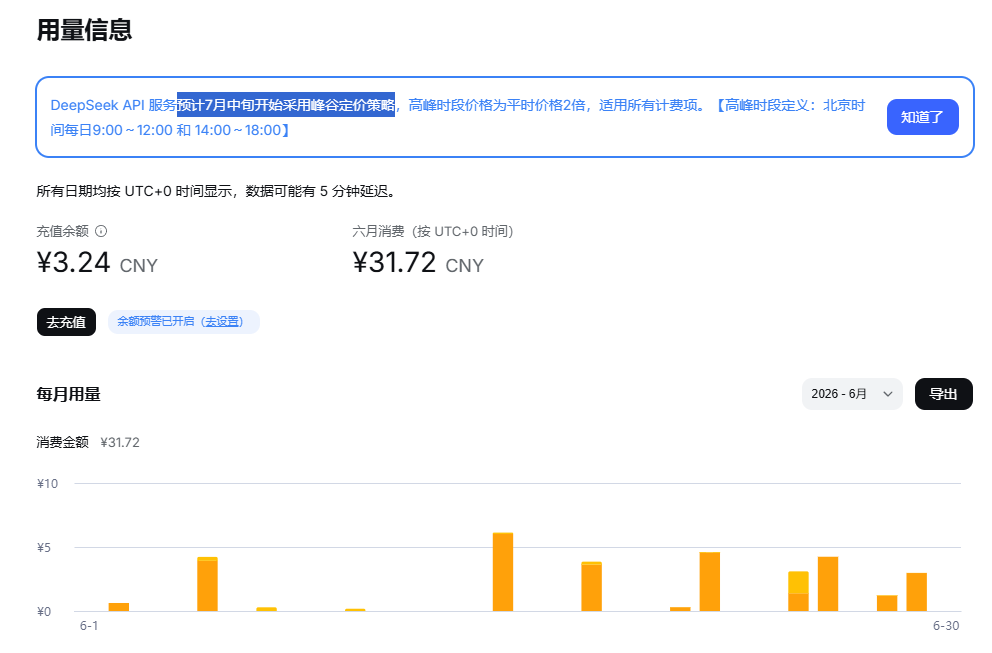
是7月中旬正式版发布后价格才变,目前价格还没有变,还没有采用峰谷定价策略。
我6月没咋用DeepSeek,只花了30:
DeepSpec 和 DSpark
6月27日,DeepSeek联合北京大学开源推理加速框架DSpark,通过半自回归生成与置信度调度两项创新,在不增加硬件、不牺牲生成质量的前提下,将单用户生成速度提升60%–85%、整体吞吐量最高提升4倍,并已部署于DeepSeek-V4系列线上服务。
随DSpark一同开源的DeepSpec是一个全栈代码库。它专门用于训练和评估推测解码(Speculative Decoding)算法中的草稿模型(Draft Models)。
DeepSpec 为这项技术提供了一套完整的工程流水线,主要包括以下三个核心模块:
- 数据准备 (Data Preparation):提供下载训练数据、调用目标模型重新生成答案,以及构建目标缓存(Target Cache)的脚本。
- 模型训练 (Training):支持多 GPU 并行,利用准备好的缓存数据来训练特定的草稿模型。
- 模型评估 (Evaluation):提供在各类主流基准测试(如 GSM8k, Math500, HumanEval 等)上衡量推测解码接受率(Acceptance Rate)的评估工具。
目前,该仓库已支持三种草稿模型算法(DSpark、DFlash 和 Eagle3),并且主要针对 Qwen 系列(如 Qwen3)和 Gemma 模型提供了丰富的预训练权重和默认配置。
DSpark已全面部署在DeepSeek-V4-Flash和V4-Pro的预览版线上服务中,替代原MTP-1生产基线,并经过真实用户流量验证。
DSpark论文原文:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
DSPark解决了什么问题:
大型语言模型(LLM)在推理时往往速度较慢且资源利用率低。现有的“投机解码”加速技术在生成长序列草稿时面临两大瓶颈:一是并行生成的草稿在后半段质量会迅速衰减;二是在高并发场景下,盲目验证所有草稿词元会严重浪费系统的核心算力。
原理简述:
- 半自回归生成:采用“重并行主干 + 轻串行头部”的架构。绝大部分计算由并行网络瞬间完成以保证速度,而轻量级的串行头部则为词元注入局部上下文依赖,从而在几乎不增加延迟的情况下,大幅缓解了草稿后半段质量衰减的问题。
- 基于置信度调度的验证:引入置信度预测头,预估每个草稿词元最终存活的概率。配合感知硬件负载的调度器,系统会动态地为每个请求裁剪出最优的验证长度,果断丢弃极有可能被拒绝的尾部词元,确保好钢用在刀刃上。
投机解码:
一种大模型推理加速框架,其原理是让轻量级的草稿模型(Draft Model)快速生成一批候选词元,然后交由全尺寸的目标模型(Target Model)在一次前向传播中进行验证,以此在不损失生成质量的前提下提升速度。
原理图示:
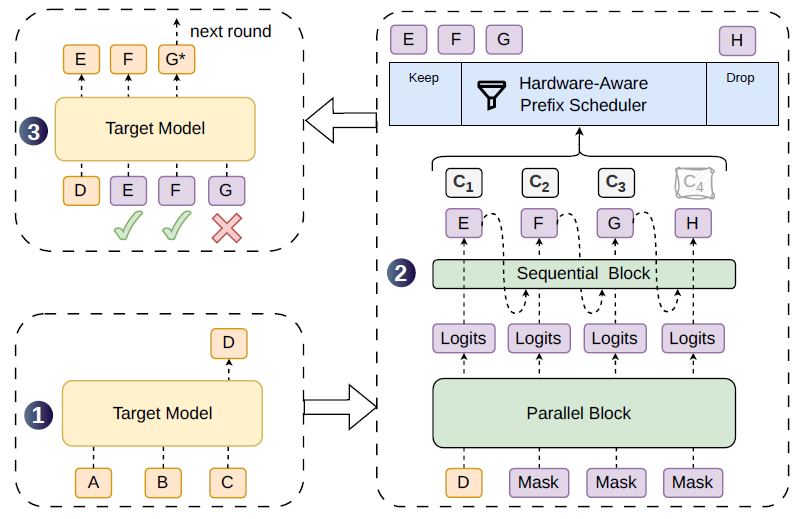
该图通过一个具体的词元生成示例,直观地展示了 DSpark 的完整解码循环(Decoding Cycle)流程,具体分为三个主要阶段 :
- 主模型生成锚点给定提示词元(Tokens)
A、B、C,目标大模型(Target Model)首先执行一步前向传播,生成下一个词元D。这个D将作为后续草稿阶段的“锚定词元”(Anchor Token)。 - 半自回归草稿生成与动态裁剪 以
D作为输入,DSpark 结合了一个重型的并行块(Parallel Block)和一个轻量级的顺序块(Sequential Block),共同生成草稿词元E、F、G、H,并为它们计算出对应的置信度分数 C 1 C_1 C1 至 C 4 C_4 C4 。随后,“硬件感知前缀调度器”(Hardware-Aware Prefix Scheduler)对这些分数进行评估,动态决定保留高置信度的前缀E、F、G(Keep),并果断丢弃(Drop)低置信度的尾部词元H。 - 并行验证与修正 目标大模型对调度器保留下来的前缀
E、F、G进行单次并行验证 。在此示例中,E和F被成功接受,而G被拒绝,大模型会当场生成一个修正后的词元G*来补救,从而完成本轮循环并进入下一轮 。
性能提升数据:

往期内容:

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)