DeepSeek V4 正式版定档 7 月中旬,API 计费全面引入“峰谷定价”机制
大模型赛道的竞争已迈入“极致性价比”与“精细化运营”的下半场。今日,DeepSeek 正式发布官方公告:备受期待的 DeepSeek V4 正式版计划于 7 月中旬正式上线。除了带来万众瞩目的功能优化与核心性能跃升外,DeepSeek 同步宣布将对 API 定价策略进行结构性调整,正式引入“峰谷定价”机制,致力于以更科学的资源配置,为开发者提供更稳定的服务体验与更具弹性的成本控制方案。
以下是本次公告的详细解读:
一、 性能跃迁:DeepSeek V4 正式版强势来袭
根据官方预告,DeepSeek V4 正式版将于 7 月中旬正式向广大用户开放。相较于前代模型,本次版本更新的核心看点在于:
-
深度功能优化:在理解能力、逻辑推理及多模态(如有)等方面迎来实质性突破。
-
性能全面提升:响应速度、并发处理能力以及复杂任务的稳定性将得到显著增强。
对于长期依赖 DeepSeek API 构建应用的开发者和企业而言,这无疑是一次值得期待的产品力重装升级。
二、 策略革新:开启“峰谷定价”新时代
伴随新版上线,DeepSeek 敏锐地洞察到 API 调用在时间分布上的巨大差异。为缓解高峰时段算力挤兑、提升整体服务鲁棒性,DeepSeek 官方决定正式施行“峰谷定价”机制。
-
高峰时段定义为:每日 9:00 ~ 12:00 及 14:00 ~ 18:00(北京时间)。
-
计费逻辑:在高峰期调用 API 将执行高峰价格,而在非高峰期(闲时)调用则享受更低的平时价格。
这一举措不仅是商业策略的调整,更是对开发者的一种“柔性引导”,旨在将非紧急且体量庞大的推理任务平滑转移至非高峰时段,从而最大化整体算力利用效率,最终让利给遵循调度规律的开发者。
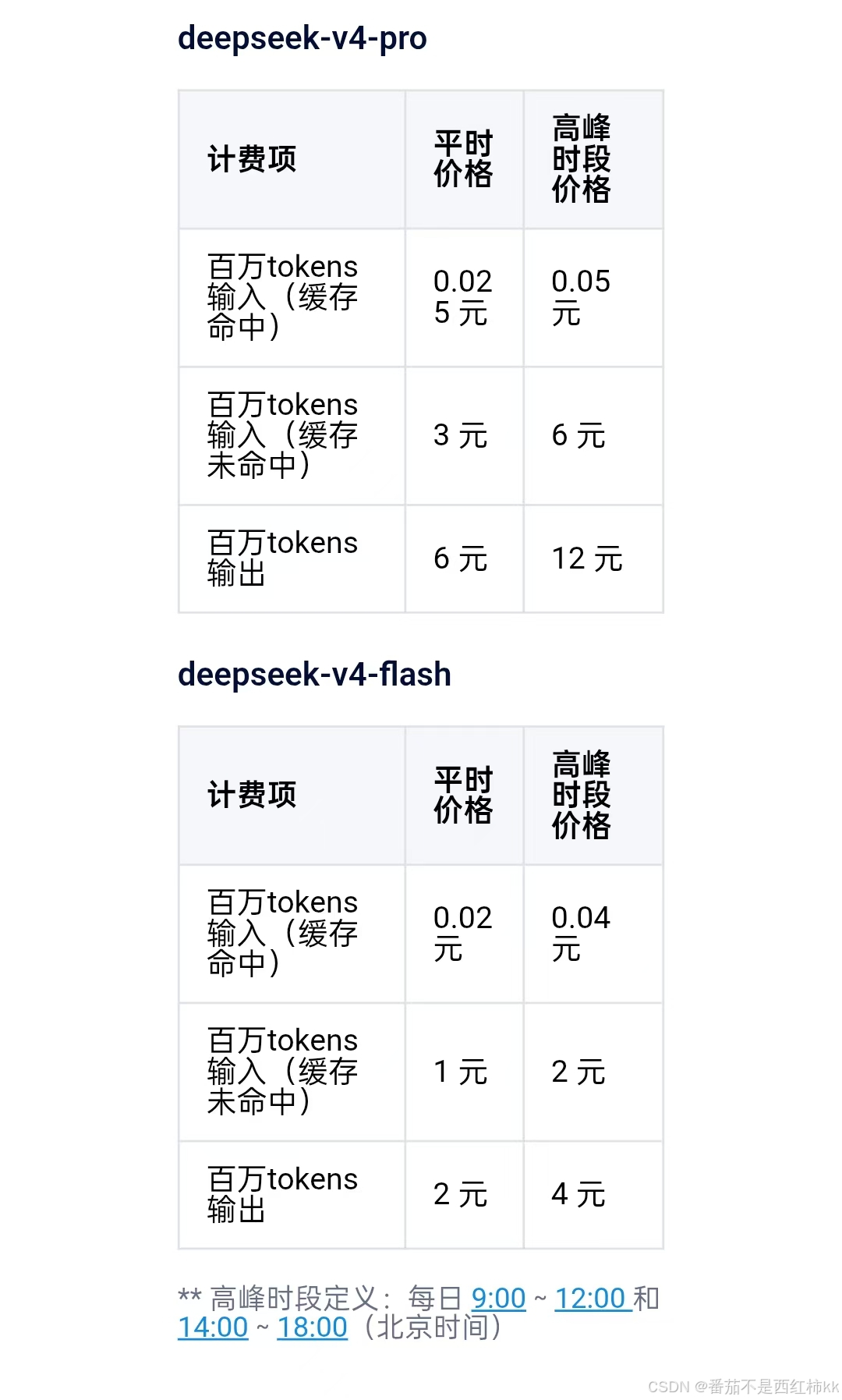
三、 定价详情:Pro 与 Flash 双模型差异化布局
本次公布的定价细则重点覆盖了两款核心模型:deepseek-v4-pro(高性能版) 与 deepseek-v4-flash(极速响应版)。最大的亮点在于“缓存命中”的输入成本大幅降低,体现了 DeepSeek 在显存管理与上下文缓存技术上的深厚积累。
以下为百万 tokens 计费细则及对比:
1. deepseek-v4-pro 定价
Pro 版本主打最强逻辑与极致智能,适合处理复杂任务。
| 计费项 | 平时价格 (元/百万tokens) | 高峰时段价格 (元/百万tokens) | 备注 |
|---|---|---|---|
| 输入 (缓存命中) | 0.025元 | 0.05元 | 成本极低,开发者的福音 |
| 输入 (缓存未命中) | 3元 | 6元 | 标准输入定价 |
| 输出 | 6元 | 12元 | 高性能输出的成本 |
2. deepseek-v4-flash 定价
Flash 版本主打轻量级、高并发、低延迟,适合高频实时交互。
| 计费项 | 平时价格 (元/百万tokens) | 高峰时段价格 (元/百万tokens) | 备注 |
|---|---|---|---|
| 输入 (缓存命中) | 0.02元 | 0.04元 | 门槛级极低定价 |
| 输入 (缓存未命中) | 1元 | 2元 | 性价比之王 |
| 输出 | 2元 | 4元 | 极具竞争力的输出成本 |
注:由于输入缓存命中价格极低,强烈建议开发者在实现长上下文(如 RAG 或多轮对话)时,合理复用缓存上下文,以最大程度节省成本。
四、 开发者指南:如何把握新定价时代的红利?
-
合理规划任务队列:针对非实时性的大型批量推理任务,利用晚间 18:00 至次日 9:00 的“平时”时段运行,最高可节省 50% 的成本。
-
最大化缓存命中率:充分利用 DeepSeek 提供的上下文缓存机制。通过保持会话上下文或复用高频知识库前缀,将输入(缓存命中)成本控制在 0.02~0.05 元/百万tokens 的极低水位。
-
按需择模型:对于追求极速响应的实时聊天或简单指令,优先选择
flash模型;对复杂推理、代码生成和深度分析则采用pro模型,实现效果与成本的最佳平衡。
结语
DeepSeek V4 的 7 月中旬官宣,不仅预示着又一次模型能力的集中爆发,其创新的“峰谷定价+缓存优惠”策略也成为了行业定价体系的一个新标杆。这不仅是技术实力的体现,更是对 AI 应用落地生态的深度赋能。让我们拭目以待 7 月中旬的到来!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)