Agent 场景下,谁才是真正好用的 Flash 模型
最近一个月,国产大模型不断推出新模型,Step 3.7 Flash、MiniMax M3、GLM-5.2、Kimi K2.7 Code几乎都是前后脚发布。
我仔细研究了一下这几个新的模型,它们的路子还有点不一样,Step 3.7 Flash主攻性价比和低延迟,MiniMax M3死磕超长上下文和Agentic Workflow,GLM-5.2走通用开源路线,Kimi K2.7 Code 则专门服务编程场景。
目前来看,模型发展有个趋势非常明显:大模型竞争已经不单是拼谁性能最好,推理能力最强,现在都在往Agent方向发力,在高频使用场景里,看谁家的模型好用、稳定,性价比更高。
以前我们在聊Flash模型,都觉得它是Pro版的廉价替代品,没有什么用。复杂的交给Pro,简单不重要的扔给Flash,Flash就是个省钱选项。
现在来看,情况有些不一样了。Flash模型已经不再是我们常说的备胎了,它已经是一个单独的品类,而且各个模型厂商都在推出这类模型。
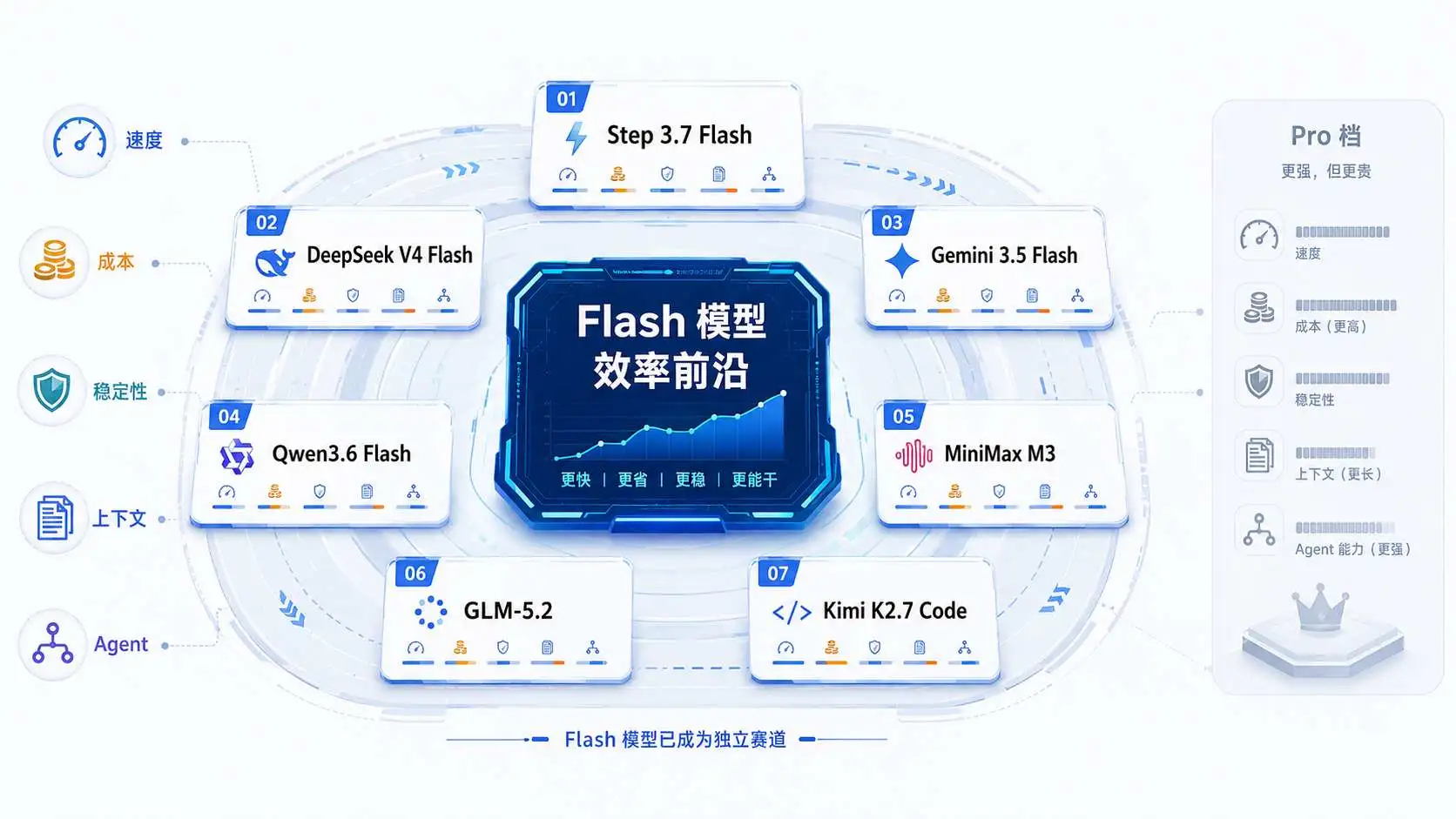
目前我们可以简单地把模型分成二档。
第一种是Pro档。主打一个极限推理、复杂编程和长链条Agent任务,像Claude Opus 4.8和GPT-5.5就属于这类。它们在高难度评测集上得分都很高,但是它的价格也是很高,稍微搞一些高频任务,账单就有点受不了。
第二种可以叫Flash档,或者效率前沿。Step 3.7 Flash、DeepSeek V4 Flash、Gemini 3.5 Flash、Qwen3.6 Flash都在这个阵营,这类模型不追求单项能力很强,而是在高频、多轮、低延迟、大规模使用的的场景里,在速度、成本、上下文长度和稳定性之间找到一个平衡。
尤其是在 Agent 场景里,Flash 模型承担的角色越来越像执行层模型,它不一定是负责最极限的推理模型,但要负责大量实际任务的拆解、工具调用、代码生成、错误修复和结果整理。
所以判断一个 Flash 模型好不好,不能只看 benchmark 测评,也不能简单的看单次问答,而要看它在真实任务里是否稳定、少犯错误少返工、是否能把任务一次性跑完。
今天我们就先拿Step 3.7 Flash来试试,把它和其他几款Flash模型放在一起,用真实项目从代码生成效率、响应速度与成本、工具调用稳定性三个角度挨个跑一遍,看看到底谁更好用。
测试方法
我们这边使用Claude code 来测试,测试的模型比较多,我们可以安装cc switch,配置好各个模型厂商后可以一键切换,非常方便。
也可以通过修改json配置文件来切换模型 ~/.claude/settings.json,例如 Step 3.7 Flash 的配置
export ANTHROPIC_BASE_URL="https://api.stepfun.com/step_plan"
export ANTHROPIC_AUTH_TOKEN="你的 key"
export ANTHROPIC_MODEL="step-3.7-flash"
这里也提前说明一下,这篇不是特别严谨的 benchmark,更像是我自己拿几个真实任务跑了一圈,看看模型真实干活的时表现如何。
因为实际测试的时候,不同模型能用的工具链并不完全一样。Step 3.7 Flash、DeepSeek V4 Flash、Qwen3.6 Flash,我主要是在 Claude Code 里跑, Gemini 3.5 Flash,我这边只能放到 Google Antigravity 里面测试。
所以后面看到时间、Token、报错次数这些数据,大家不要直接理解成排行榜。我们不是要证明谁是第一,而是想看看,在真实 Agent 任务里,谁更稳定、少犯错、最后交出来的东西是一个能用的成品。
案例测试
案例一:从零搭建开发者日志站
这个案例我们主要对比下 Step 3.7 Flash 和 DeepSeek V4 Flash 这个两个模型
我直接把下面这段 prompt 丢给 Claude Code,两个模型各跑一次:

这个任务不算特别难,模型需要理解技术栈要求,搭 Next.js 项目结构,配置 Markdown 解析,写列表页和详情页,加标签筛选和语法高亮,还要生成 5 篇像样的示例日志。
中间任何一个步骤出错,就可能导致项目跑不起来、页面功能不完整,或者前端显示不太好
我们先来看下 deepseek-v4-flash的效果
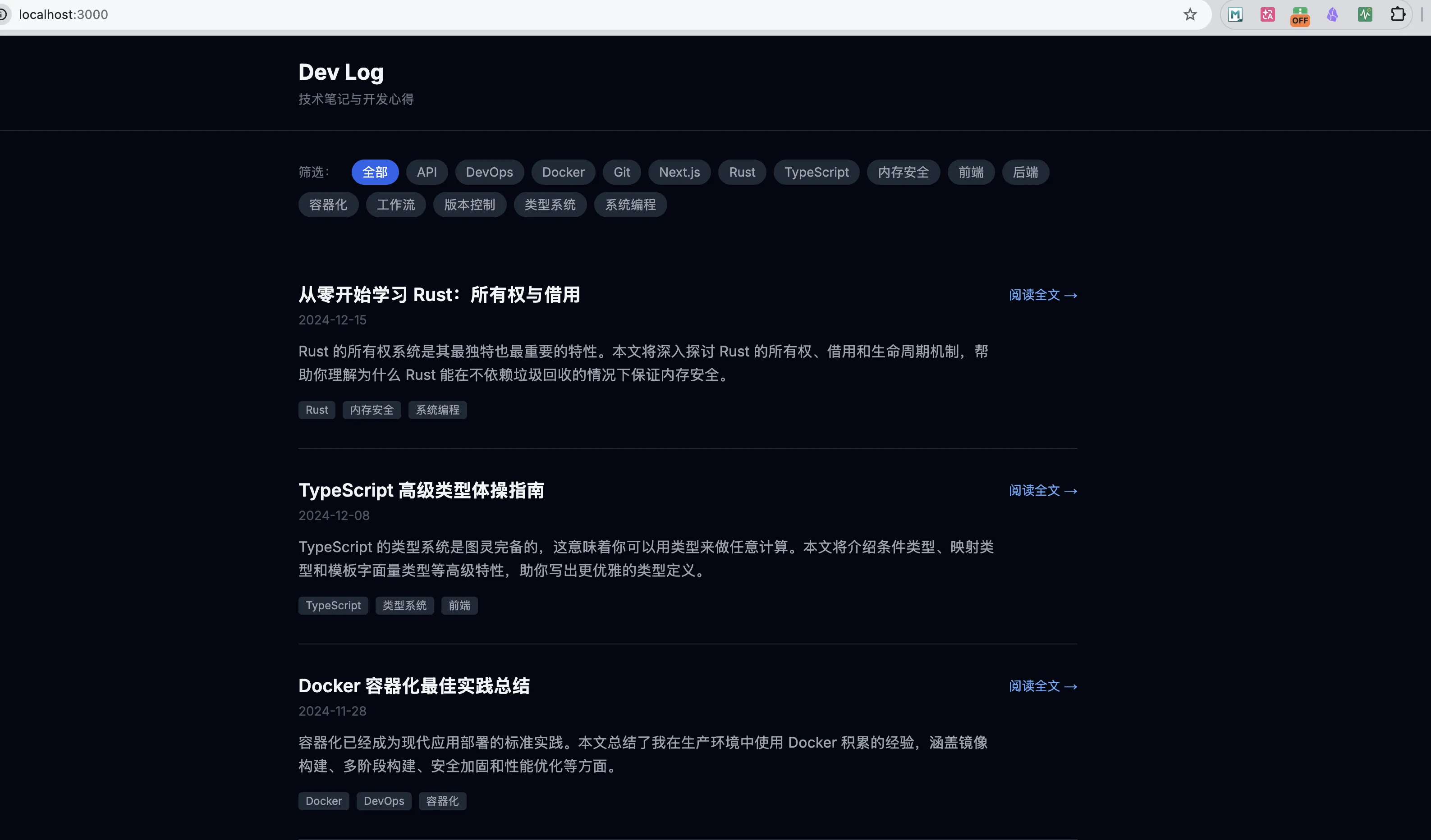
页面上总体功能都符合需求,模型一轮就给出了结果,没有让我们多次提示,中间执行过程中,模型在编译的时候遇到了3次错误,都是自己修复,最后给出的是一个可用的网页成品。
再来看看 Step 3.7 Flash 的效果
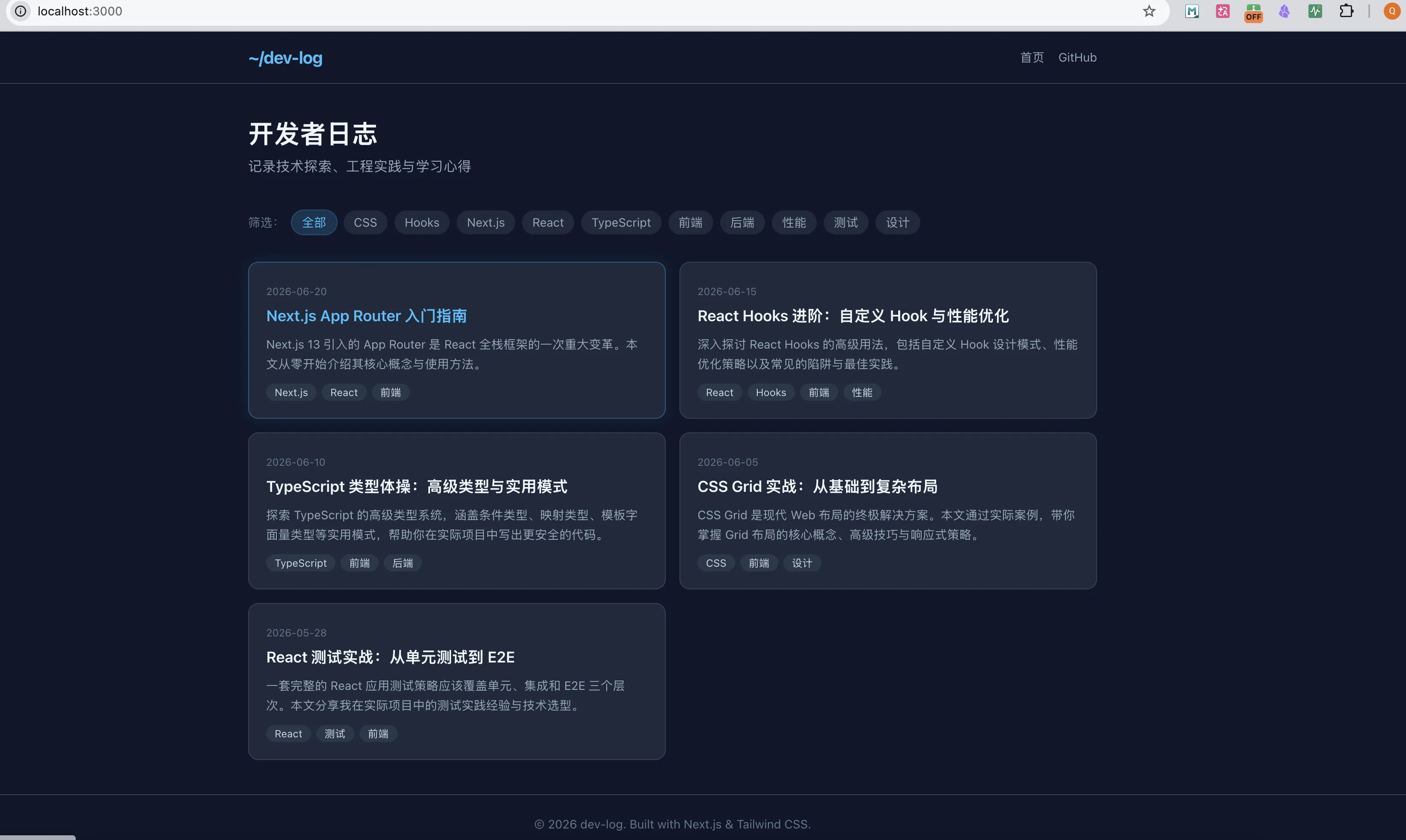
这个页面同样是一轮生成,布局上采用了卡片式网格结构,每篇文章以标题、描述和标签组合展示,点击卡片进入详情页。相比DeepSeek V4 Flash偏列表化的信息陈列,Step 3.7 Flash生成的页面更强调视觉层级,导航栏固定了分类筛选,交互上更贴近成熟的博客系统,整体观感更加规整。
这两个网页,你们更喜欢那种风格,我是更加倾向 step-3.7-flash这种。
看完效果,我们来看下,时间,成本的消耗,我做了个对比图
| 项目 | deepseek-v4-flash | step-3.7-flash |
|---|---|---|
| 总 Input | 726.6k | 747.4k |
| 总 Output | 14.0k | 25.7k |
| API 时间 | 2m 1s | 2m 30s |
| 估算人民币成本 | ¥0.72 | ¥1.22 |
从图中可以看出,两个模型的输入token基本上差不多,Step 3.7 Flash 的模型输出要多很多,难道是这个原因,导致效果要好一点吗,API消耗的时间也没有多大的差距,成本上deepseek确实更加便宜,从API定价来看,国内外 好像也没那个模型能够和deepseek比。
案例二:GitHub 项目雷达
我们来看看 Step 3.7 Flash 和 Gemini 3.5 Flash 对比表现如何
提示词如下:
帮我从零搭建一个 GitHub 项目雷达:
- 用 Python 脚本抓取 GitHub Trending 本周热门 AI 项目
- 对每个项目提取:名称、Star 数、语言、简介、最近更新时间
- 自动分类(Agent 框架 / 模型推理 / RAG / 多模态 / 工具链 / 其他)
- 生成一个 HTML 报告页面:分类卡片 + 统计小结 + 原始数据表
- 项目能直接跑起来,输出 `report.html`
我们先看下Gemini 3.5 Flash的效果,直接把提示词给到 google Antigravity
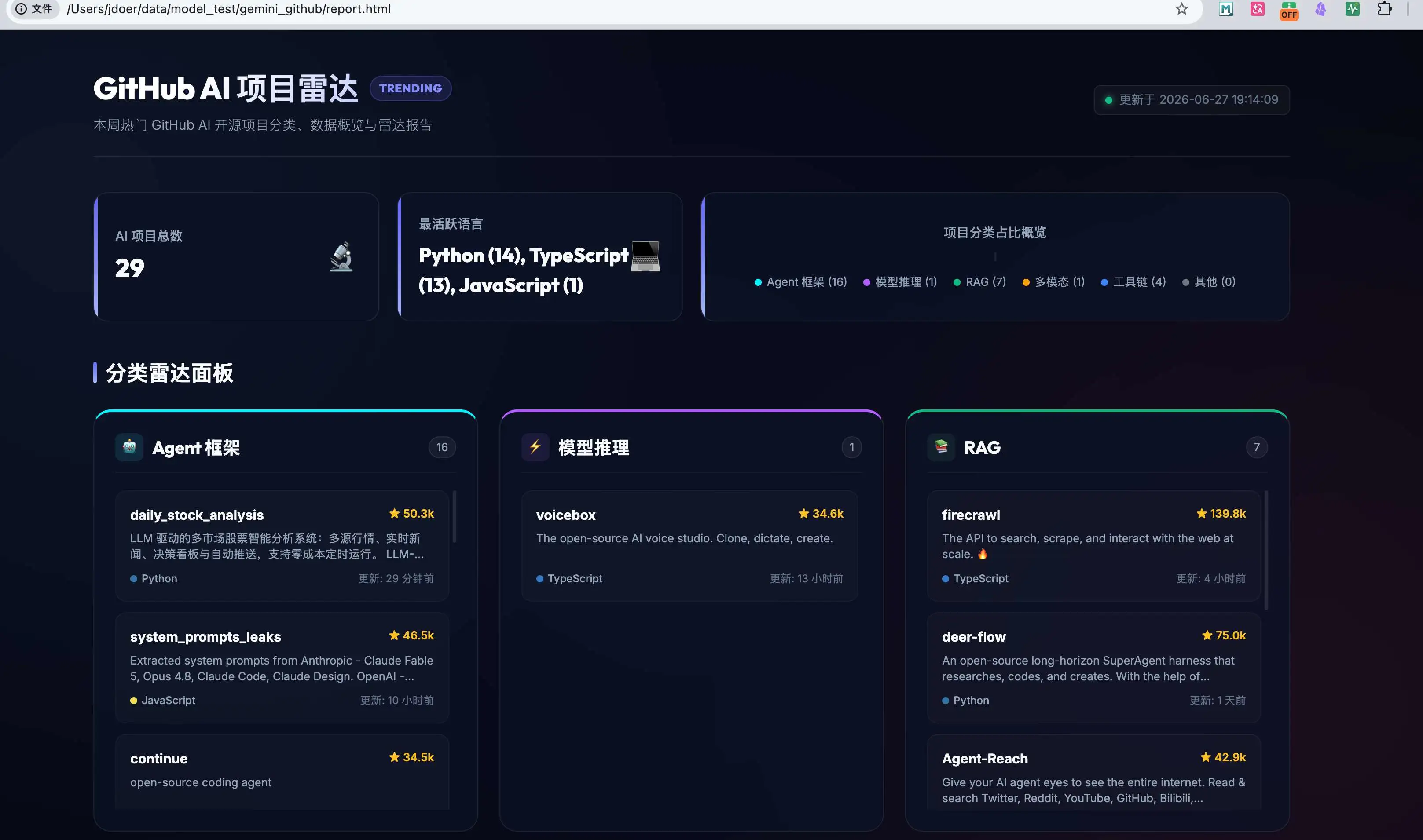
任务是一次性完成,虽然说中间有2个工具报错,都是模型自动修复,没有人工介入,最后给出了一个完整可运行的脚本和页面。
Gemini 这次任务完成度没有问题,但页面组织比较松散,信息密度和视觉层级不太友好。
我们在来看 Step 3.7 Flash 的效果,把相同的提示词给到claude code

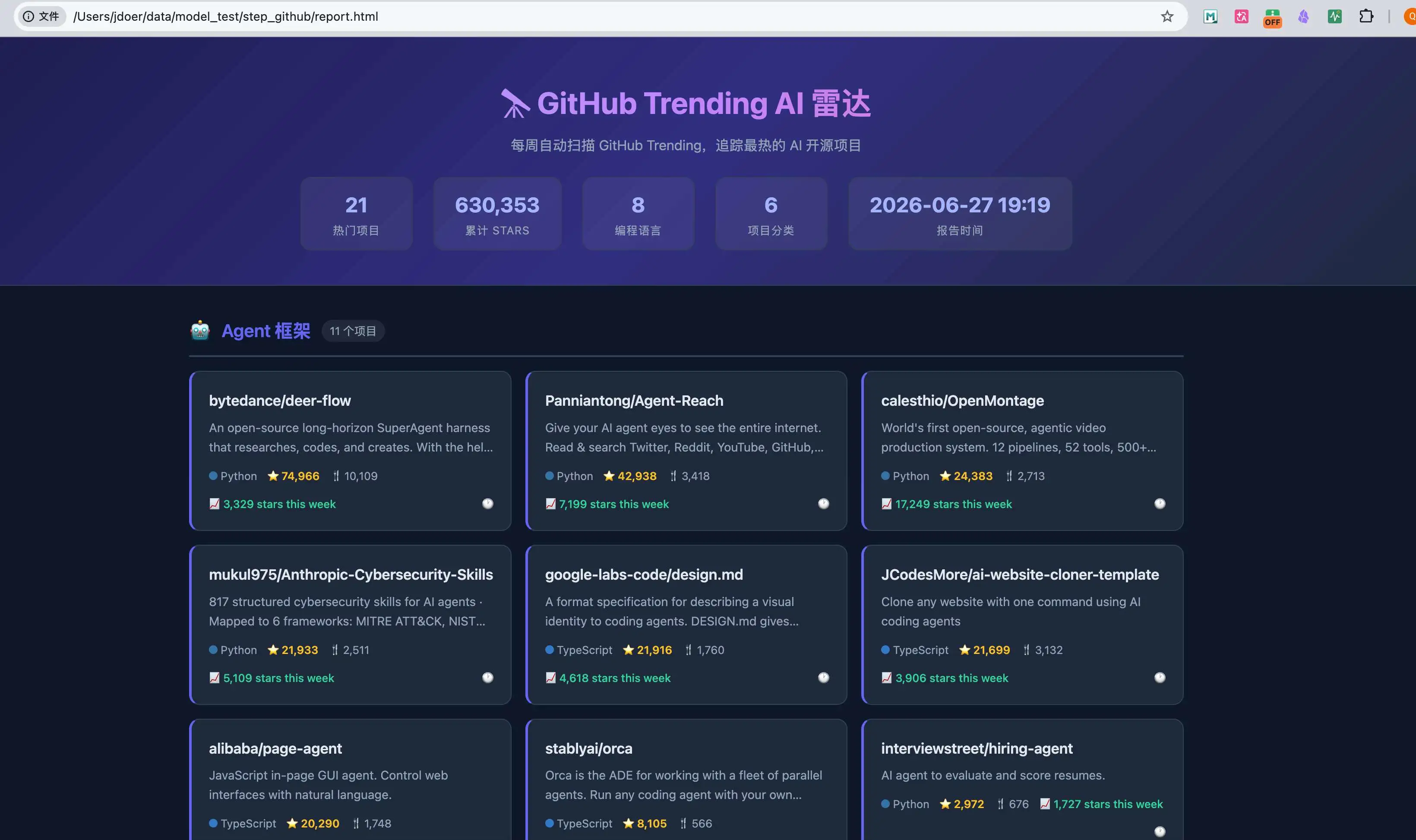
任务页是一次性完成,中间没有发生任何错误,给出了一个完整可运行的脚本和页面。
页面采用了卡片式的布局,每个卡片清晰呈现项目名称、简短描述、编程语言、Star总数及本周增量。信息密度适中,视觉层次分明。稍显不足的是分类导航没有固定在顶部,需要滚动到对应区域才能看到其他分类。但整体排版、字体和间距控制都比较舒适,Step 3.7 Flash 更接近一个可交付的看板页面。
这轮任务中,Step 3.7 Flash 一共消耗 406.5k input tokens 和 18.7k output tokens,没有缓存命中。执行时间上,API 时间为 2 分 25 秒,完整 Wall 时间为 4 分 45 秒。按 Step 3.7 Flash 官方价格估算,这次任务成本约 0.7 元人民币。
Gemini 3.5 Flash 的消耗不好查看,没有记录可以查看的地方,时间消耗两边都差不多,在3分钟左右,这边只显示了额度被消耗了28%,无法查看token的一个具体消耗。
案例三:源码解读
写代码只是 Coding Agent 的一部分。
另外一个高频的场景是读代码,这个是我们经常遇到的事情,接手一个陌生项目、理解一个开源库、分析一个框架的核心链路,然后把它转成团队能读懂的文档。
所以第三个案例我选了一个源码解读,让它阶段源码,给出输出一个html的页面,这个源码解读,需要多轮工具调用,我们可以看看它们在多轮工具调用上的表现如何。
提示词如下
请你分析当前这个 GitHub 开源项目的源码,并生成一份静态 HTML 架构分析报告。
要求你不要只看 README,要结合源码目录、核心模块、类和函数调用关系来分析。
分析目标:
1. 这个项目是做什么的?
2. 它解决了什么问题?
3. 核心架构是什么?
4. 主要模块如何协作?
5. 一次 memory 写入流程是怎么走的?
6. 一次 memory 检索流程是怎么走的?
7. 它依赖哪些外部组件,比如 LLM、Embedding、Vector Store、Graph Store、数据库等?
8. 如果我要自己实现一个简化版,最小核心链路是什么?
9. 这个项目的优点、复杂点和潜在局限是什么?
请完成以下任务:
1. 扫描项目目录
- 找出核心源码目录
- 找出主要入口文件
- 找出核心类、核心函数和关键配置文件
2. 分析源码结构
- 说明每个核心模块的职责
- 说明模块之间的调用关系
- 不要泛泛而谈,要尽量指出具体文件路径
3. 生成架构报告
- 创建 `mem0_architecture_report.html`
- 使用纯 HTML + CSS,不依赖外部 CDN
- 页面需要包含以下章节:
- 项目概览
- 目录结构解读
- 核心模块说明
- Memory 写入流程
- Memory 检索流程
- 关键类与函数表
- 架构流程图,使用 HTML/CSS 或 Mermaid 代码块均可
- 简化版实现思路
- 优点与局限
- 适合参考的源码文件清单
4. 报告要求
- 内容要适合工程师阅读
- 不要只写概念,要结合源码文件路径
- 每个核心结论尽量标注来自哪个文件或目录
- HTML 页面要有清晰排版
- 代码路径用等宽字体展示
- 表格清晰可读
5. 验收要求
- 最终必须生成 `mem0_architecture_report.html`
- 报告打开后能直接阅读
- 如果你发现源码结构和 README 描述不一致,以源码为准
我们先来看下Qwen3.6 Flash的效果
在执行过程中,发生了多次工具调用失败的场景,不过Agent最后都做了修复,一次对话就完成了任务


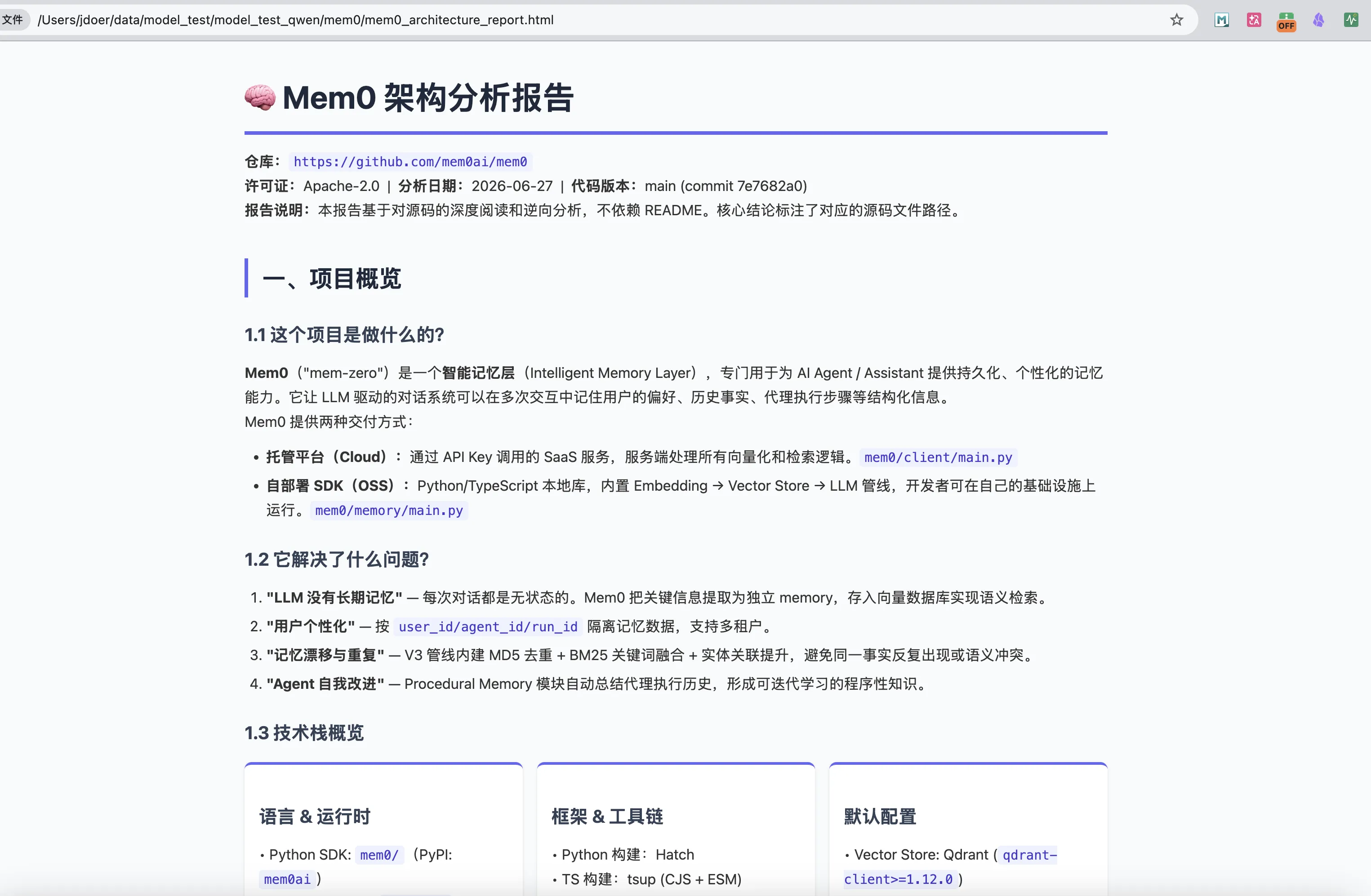
总体来说效果还是可以的,按照我们给的需求完成了任务,对memo0这个记忆架构框架的源码总结也比较到位
再来看看 Step 3.7 Flash 的效果如何


在执行过程中,没有发生工具调用错误,一次性完成了所有任务,和Qwen3.6 Flash 相比,差异不是很大,就是左边多了一个导航菜单,可以直接点击快速定位到想看的目录。
看完效果,我们来看下,时间,成本的消耗,我简单做了个对比的表格,大家可以自己看下。
| 项目 | Qwen3.6 Flash | Step-3.7-Flash |
|---|---|---|
| 总 Input | 1.38M | 1.2M |
| 总 Output | 40.8k | 20.6k |
| API 时间 | 6m 17s | 4m 08s |
| 估算人民币成本 | 约 ¥2.07 | 约 ¥1.79 |
几轮测试后的横向对比
| 维度 | Step 3.7 Flash | DeepSeek V4 Flash | Gemini 3.5 Flash | Qwen3.6 Flash |
|---|---|---|---|---|
| 工具调用稳定性 | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★☆☆ |
| 错误自修复能力 | 高 | 高 | 高 | 高 |
| UI/前端审美 | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ |
| 单次Token成本 | 中等 | 低 | 中高 | 中等 |
| 隐性返工成本 | 低 | 中 | 中 | 中 |
从这张表里可以看出,Flash 模型的成本不能只看单次 Token 单价。
DeepSeek V4 Flash 的单次 Token 成本确实更低,这一点很有优势。但放到 Agent 场景里,真正影响成本的还有另一个变量:失败后的重试成本。比如工具调用失败、代码错误反复修改、页面结构不符合预期、报告需要人工二次整理,这些都会变成隐性成本。
我们把Agent的成本拆成两部分来看:
总成本 = Token 成本 + 失败重试成本 + 人工介入成本。
从这几轮测试看,Step 3.7 Flash 不是单次调用最便宜的模型,但它的工具调用稳定性更好,返工更少,最终交付物完成度也更高。因此,如果任务是高频、多轮、需要持续调用工具的 Agent 执行场景,Step 3.7 Flash 的综合成本未必会更高,反而可能是更加省心的选择。
什么时候选 Step 3.7 Flash
经过上面的案例测试下来,大家对Step 3.7 Flash 应该有一个直观的感觉, 如果要我给Step 3.7 Flash给一个定位,我对它看法是:
它的价格确实比DeepSeek更贵一点,上下文比不过 DeepSeek 和 Gemini,但它的工具调用稳定性,接口响应速度,前端界面审美还是非常不错的。
它不是再某一个方面表现最强的模型,也没有明显的短板,它是在当前 Flash 模型档里,在速度、成本、稳定性这几个维度综合评估下来,在真实Agent执行层优先选择的模型之一。
适合选 Step 3.7 Flash 的场景:
-
需要高频、多轮、低延迟的 Agent 任务
-
生产级 coding-agent 工作流,对速度和稳定性都有要求
-
需要多模态理解,比如截图转代码、图表转结论
-
预算敏感,但又不想牺牲太多稳定性
Step 3.7 Flash 也有一个比较明显的短板,就是它的上下文只有256k。
如果要一次性处理大量代码库、长文档,或者需要把很多资料全部塞进上下文里,那这个窗口可能不太够。这种场景下,DeepSeek V4 Flash 会更合适。
模型没有绝对的最优解,还是要看场景。
最后总结
真实项目里,我们不只是追求模型回答得多聪明,而是希望它在一轮又一轮任务里,稳定、可控的执行任务,不要在哪里不停的犯错和返工。
我们做的案例只能给大家一个参考,真正适合你自己的模型,还是要放到你自己的项目里跑一遍。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)