go 数字人Coze智能体
1. 项目概述
本项目旨在构建一个具备实时交互能力的 AI 数字人智能体系统,结合 Coze 智能体平台与 Live2D 数字人渲染项目,实现自然语言理解、知识问答、情绪响应与视觉化数字人展示。
本文围绕工单“全栈开发-网约车-数字人Coze智能体任务工单”的实战内容,重点记录三个核心键路:OpenClaw 中的人物切换、Coze 智能体对接,以及音色配置与情感调优。
1.1 技术栈概览
|
层面 |
技术选型 |
|
智能体平台 |
Coze(插件 + 工作流 + 知识库) |
|
后端服务 |
Go (net/http) 作为 Coze 转发层,不暴露 Token |
|
前端框架 |
Next.js + React + TypeScript + Vite |
|
3D 动画渲染 |
Live2D Cubism SDK + WebGL |
|
语音模块 |
Coze TTS API + Web Speech API 降级 |
|
通信协议 |
WebSocket + SSE + RESTful API |
|
状态管理 |
Zustand (persist) |
1.2 系统架构
整体链路为:浏览器前端 → Go 后端 → Coze 发布 API。其中 Go 后端作为安全中间层,负责保管 Coze Token、转发流式响应、提供 TTS/ASR 服务。前端通过 SSE 流式接收智能体回复,并将文本分句后通过 Coze TTS 转为音频,再驱动 Live2D 模型的口型同步与表情变化。
2. OpenClaw 人物切换
OpenClaw 提供了 persona-switch 技能,支持在预设人设与自定义人设之间自由切换。在数字人场景中,人物切换可以让同一个数字人展现不同的“人格”——例如从品牌代言人切换到虚拟讲解员。
2.1 人设文件结构
OpenClaw 的人设存储在 SOUL.md 文件中,通过 persona-switch 技能可以定义多套预设人设:
# 预设人设一:品牌代言人 - 风格:专业、亲切、品牌化 - 角色:某品牌官方虚拟代言人 - 语言:正式但不死板,可加入 emoji # 预设人设二:虚拟讲解员 - 风格:知识型、引导性、教育性 - 角色:景区智能导览 - 语言:简洁、信息密度高
2.2 人物切换与 Live2D 联动
在数字人场景中,人物切换不仅是文本风格的变化,还可以联动 Live2D 模型切换。前端存储了当前所有可用的 Live2D 角色,用户在“设置 → 角色”面板中切换后,系统会重新加载对应的 .model3.json,并重置聊天记录。
切换时的关键代码逻辑: 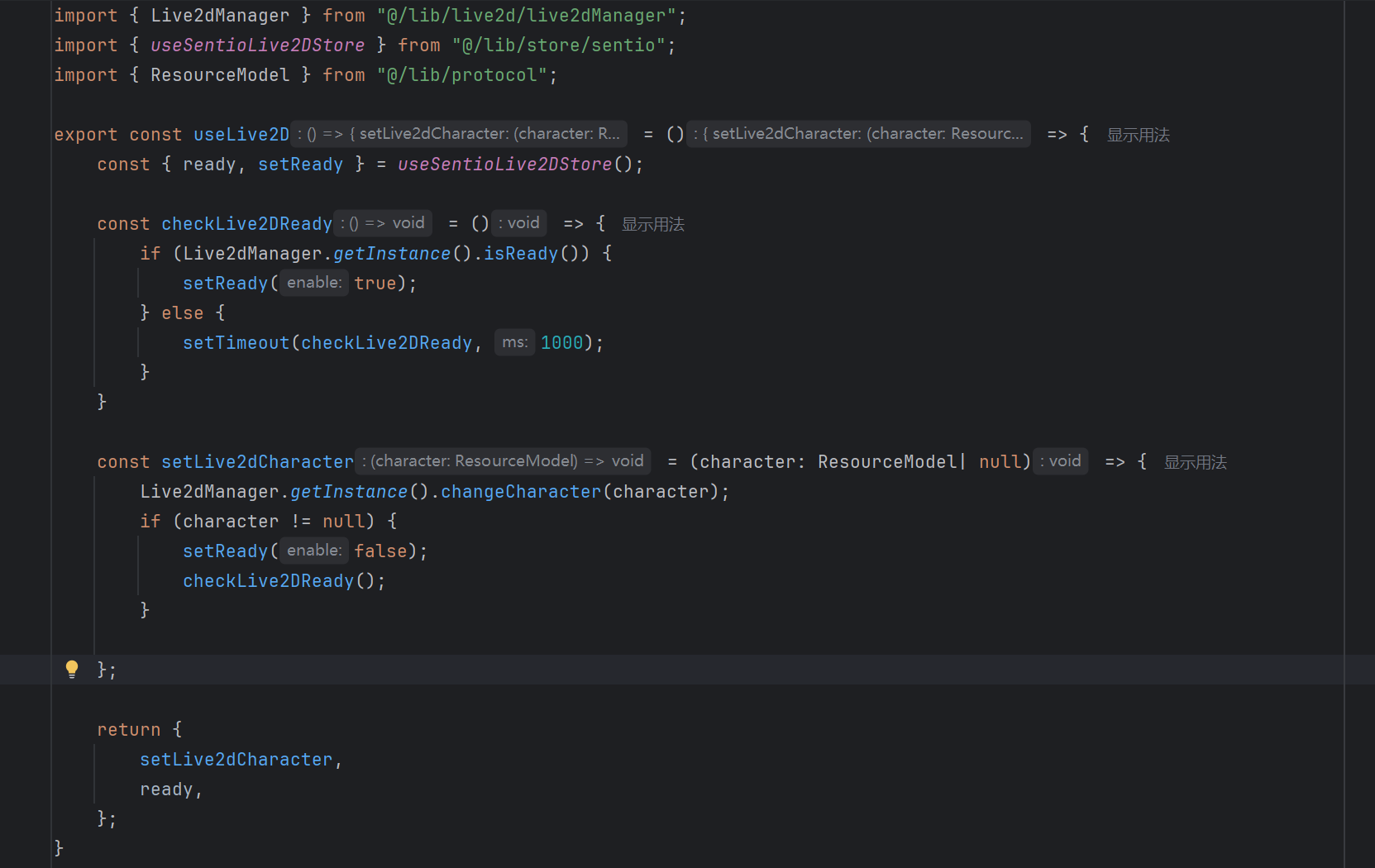
建议在 Coze 智能体层面配合人设设置:不同的角色可以对应不同的知识库和提示词,使得切换人物后整体交互体验一致。
3. Coze 智能体对接实战
3.1 架构设计:为什么需要 Go 转发层
直接从前端调用 Coze API 会暴露 Token,存在安全风险。因此我们引入了 Go 后端作为中间转发层:
- Token 安全:仅从环境变量读取,不落盘到任何源码文件
- 协议透明:前端发送标准 JSON,Go 转换为 Coze 格式后转发
- 音色统一:TTS 由 Go 后端调用 Coze 音频接口,确保数字人声音一致
- 降级策略:TTS 失败时自动降级到浏览器 Web Speech API
3.2 Go 后端核心实现
环境配置
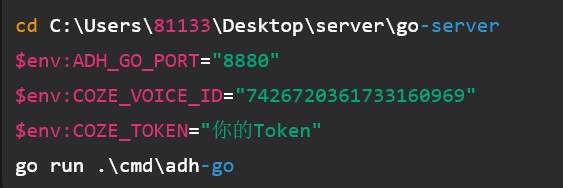

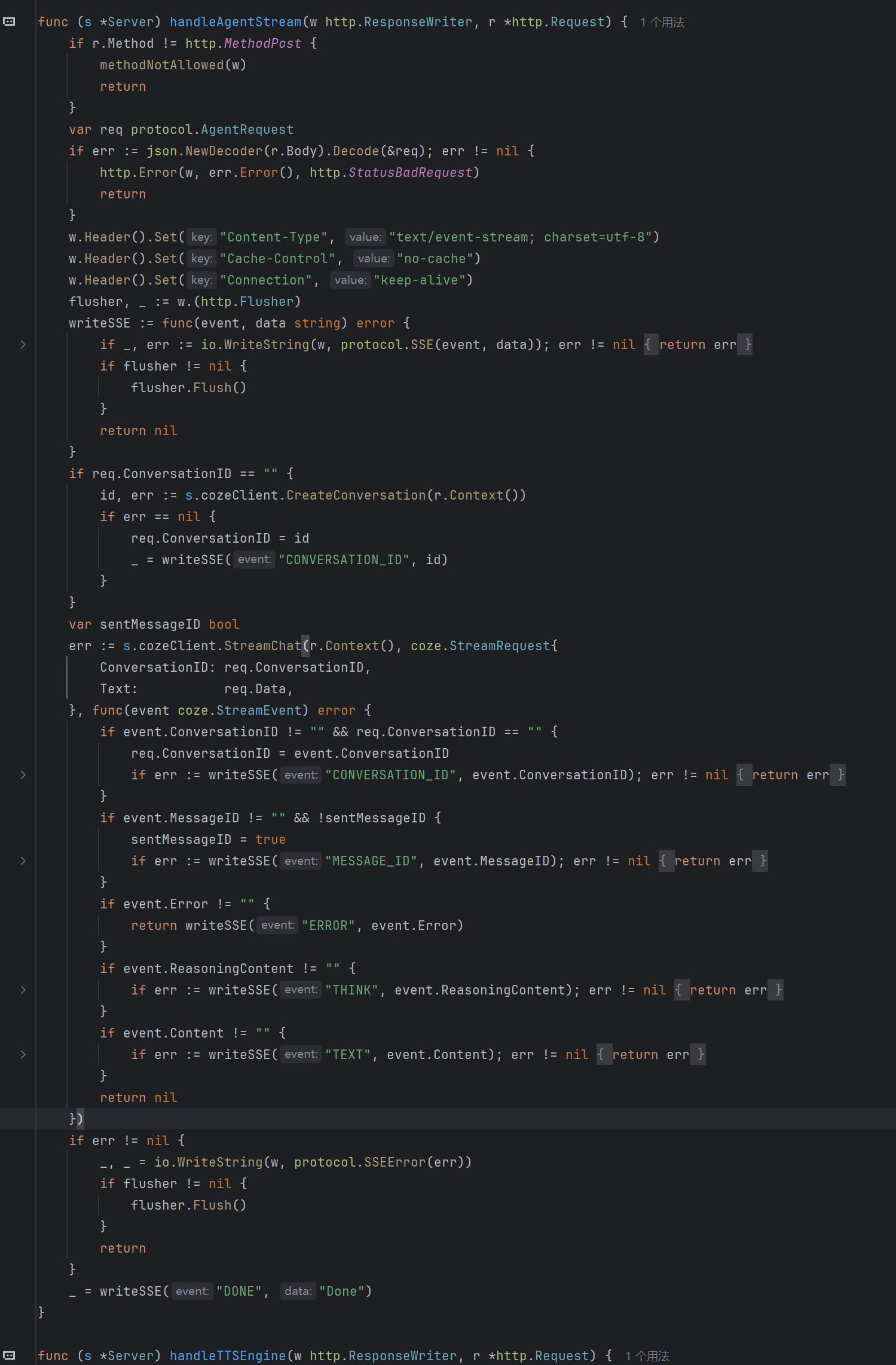
SSE 流式对话转发
前端通过 fetchEventSource 发起 POST 请求,Go 后端接收后调用 Coze 对话 API,并将 SSE 事件流转发给前端:
Coze 发布页 stream_run 兼容
当通过 Coze 发布页部署时,请求体格式与 API 直调不同,需要包装为 stream_run 格式:
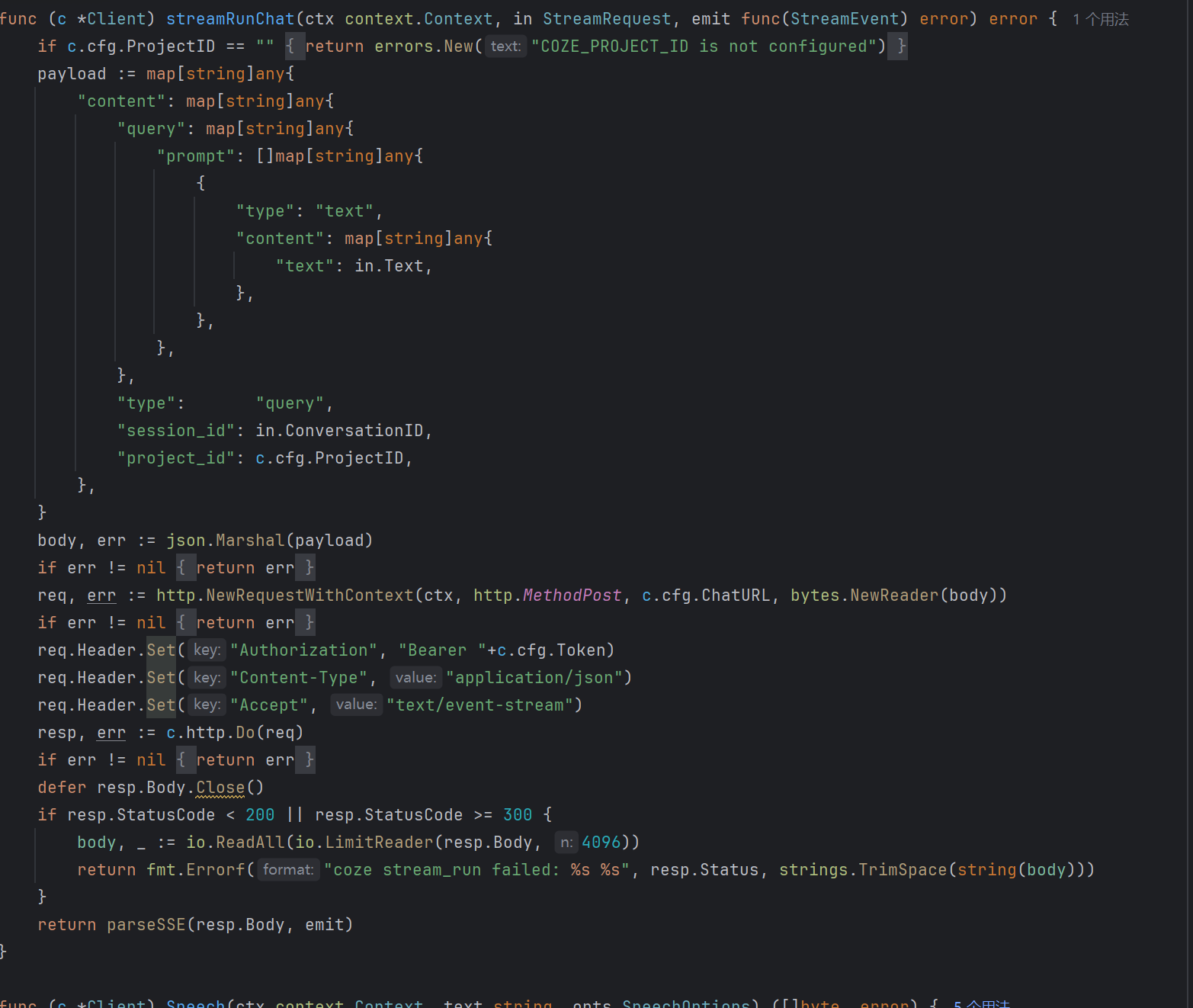
判断逻辑:如果 COZE_CHAT_URL 中包含 /stream_run 或 .coze.site,则自动使用 stream_run 模式;否则使用 API v3 直调模式。
3.3 前端对接实现
Agent 流式调用
前端通过 api_agent_stream 函数发起 SSE 请求,并在回调中处理不同类型的事件:
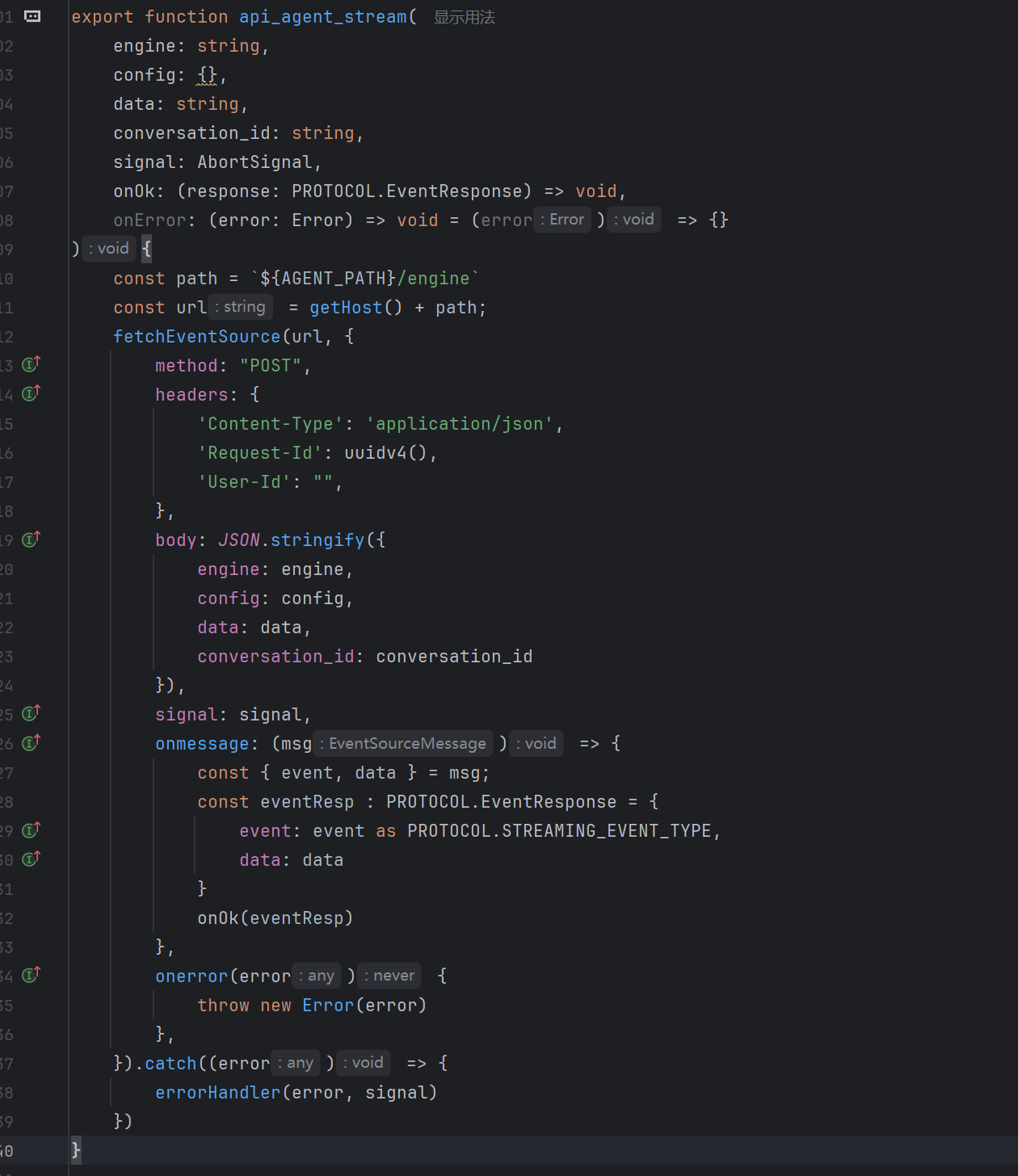
事件类型包括:CONVERSATION_ID、MESSAGE_ID、THINK、TEXT、DONE、ERROR。其中 THINK 事件对应 Coze 的推理过程,TEXT 事件对应最终回复内容。
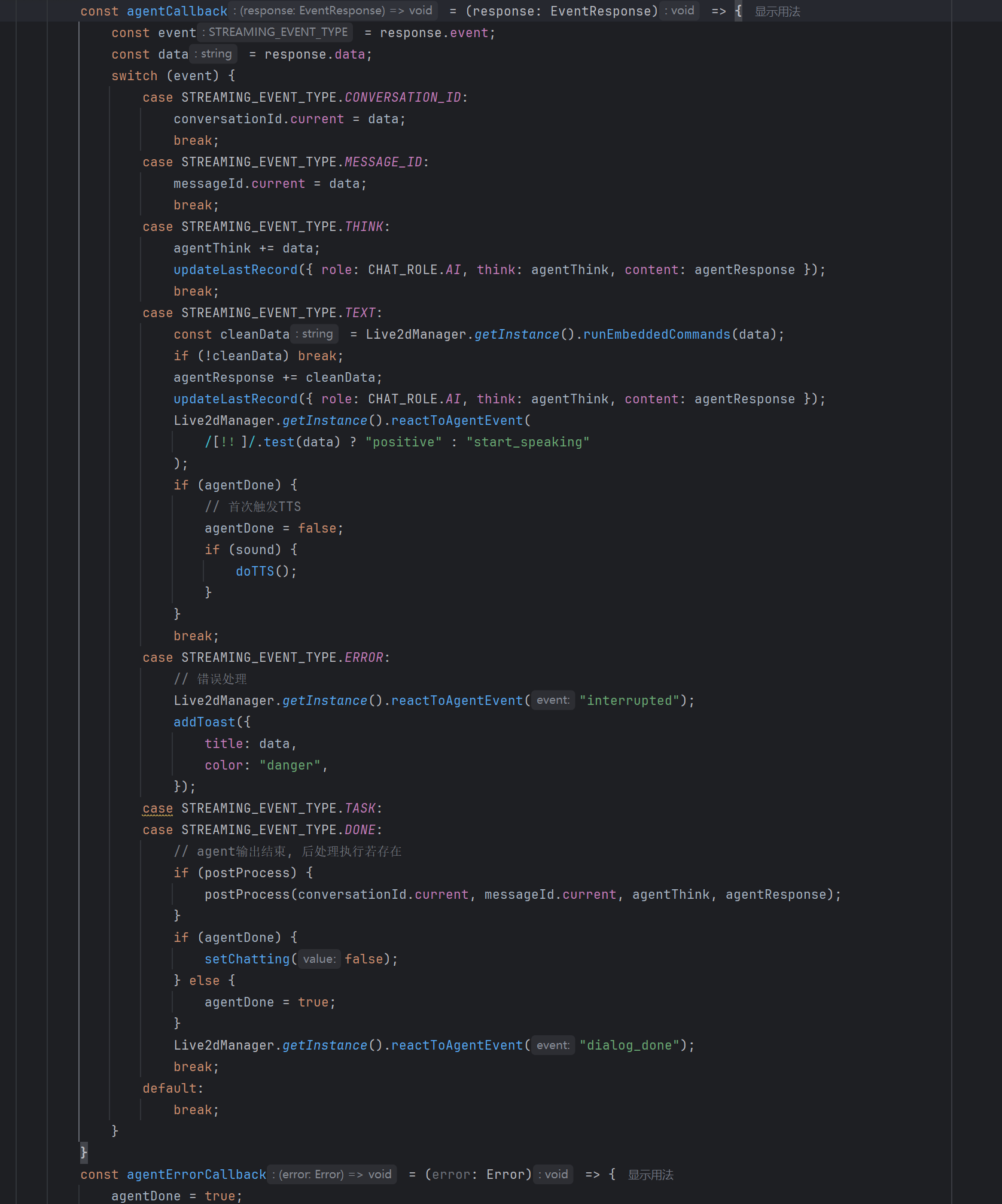
流式事件处理与 TTS 联动
3.4 OpenClaw 中配置 Coze 代理
在 OpenClaw 中配置 Coze 智能体代理时,“代理功能描述”应包含以下关键信息:
智能体名称:内部HR问答助手 智能体ID:7655620274246926388 智能体平台:Coze(插件 + 工作流 + 知识库) 通信协议:SSE流式响应,通过 Go 服务端转发 能力范围:自然语言理解、多轮对话、 知识检索、情绪响应、动作指令下发 安全策略:Token仅存储在Go服务端环境变量, 前端不保存任何密钥
4. 音色配置与情感调优
数字人的语音是用户体验的核心。本项目采用 Coze TTS API 作为主要语音引擎,支持自定义音色和情感参数。
4.1 音色自动解析策略
Go 后端实现了智能音色解析链:
- 前端显式指定:用户在设置面板输入 voice_id,优先级最高
- 环境变量 COZE_VOICE_ID:服务端默认音色
- 智能体音色查询:调用 GET /v1/bots/{bot_id} 获取智能体配置的音色
- 账号音色查询:调用 GET /v1/audio/voices ,优先选择非系统音色
- 降级:所有方式都失败时,前端自动使用浏览器 Web Speech API
4.2 音色解析代码
func (c *Client) resolveVoiceID(ctx, overrideVoiceID) (string, error) { // 1. 前端 override 优先 if overrideVoiceID != "" { return overrideVoiceID, nil } // 2. 环境变量 if c.cfg.VoiceID != "" { return c.cfg.VoiceID, nil } // 3. 查询 Bot 音色 if c.cfg.BotID != "" { voiceID, err := c.lookupBotVoiceID(ctx) if err == nil { return voiceID, nil } } // 4. 查询账号可用音色,优先非系统 return c.lookupAvailableVoiceID(ctx) }
4.3 情感参数配置
Coze TTS API 支持多种情感语调:
|
情感 |
参数值 |
适用场景 |
|
开心 |
happy |
欢迎语、正面反馈 |
|
悲伤 |
sad |
逗乐、遗憾回复 |
|
生气 |
angry |
投诉场景、严肃提醒 |
|
惊讶 |
surprised |
意外情况、惊喜回复 |
|
恐惧 |
fear |
风险提示 |
|
讨厌 |
hate |
负面事件关怀 |
|
兴奋 |
excited |
活动宣传、促销 |
|
冷漠 |
coldness |
正式通知、官方声明 |
|
中性 |
neutral |
普通对话、日常交流 |
4.4 前端音色设置界面
用户可以在“设置 → TTS”面板中手动调整音色参数,包括 voice_id、emotion、emotion_scale。前端配置优先于后端环境变量,留空则使用后端默认值。
// TTS 参数定义 parameters: [ { name: "voice_id", type: "string", default: "7468518753626767397" }, { name: "emotion", type: "string", choices: ["happy","sad","angry","surprised", "fear","hate","excited","coldness","neutral"], default: "angry" }, { name: "emotion_scale", type: "float", range: [0, 5], default: 0 }, ]
5. Live2D 动作与表情系统
5.1 指令体系设计
数字人支持两种指令方式:
- 纯控制指令:/motion nod 或 /expression smile,仅触发动作,不发送给智能体
- 嵌入指令:[motion:bow_light]欢迎回来!会触发鞠躬动作,并将“欢迎回来!”发送给智能体
这意味着 Coze 智能体可以主动控制数字人动作:在回复中输出 [motion:bow_light]欢迎回来,前端会自动执行鞠躬动作并移除标记。
5.2 指令解析实现
// 嵌入指令解析:匹配 [motion:xxx] 或 [expression:xxx] runEmbeddedCommands(text: string): string { return text.replace( /[([motion|动作|expression|表情):([a-zA-Z0-9_-]+)]/g, (_match, type, command) => { if (type === 'motion' || type === '动作') { this.applyCommand(command); } else { this.applyCommand(`expression:${command}`); } return ""; // 从展示文本中移除 } ); }
5.3 事件驱动表情
当智能体开始回复时,前端自动触发随机表情,让数字人更自然:
reactToAgentEvent(event: string): void { switch (event) { case 'start_speaking': case 'positive': manager.playRandomExpression(); break; case 'interrupted': this.stopAudio(); manager.playRandomExpression(); break; } }

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)