AI具身交互:实现一个会说话的3D虚拟伴侣
引言
传统的 3D 虚拟人更多停留在“形象展示”和“内容播报”阶段,交互能力有限。如果给这些3D虚拟人注入大模型的理解与生成能力,就可以它们从“呆头呆脑的形象”变成“拥有智慧的AI伴侣”。
设想一下,如果在网页、手机、大屏等任意终端屏幕上,我们可以随时召唤一个具备大模型能力的 3D
虚拟交互伙伴,它能听懂你的问题,实时给出回应,并通过语音、表情和动作完成自然表达,是不是一件非常有趣的事情?
本篇文章将结合 Trae 与魔珐星云 SDK,带大家快速实现一个会说话、可打断、能交流的 智能AI 伴侣。
AI 伴侣效果展示
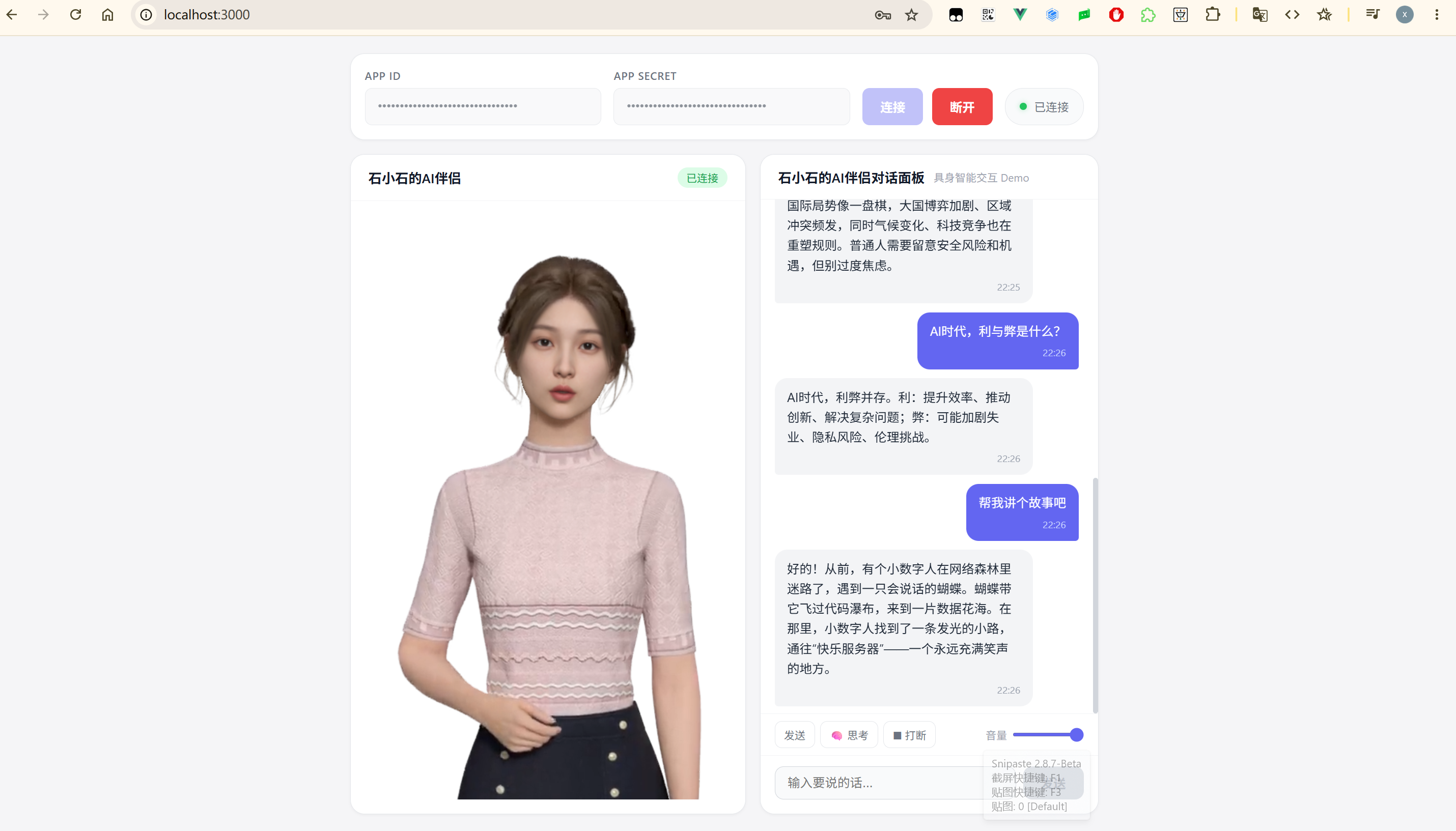
参考下面的图片和视频,运行前端服务后,只需在页面中输入App ID 和 App Secret,点击“连接”按钮,即可加载并创建一个 3D 虚拟人。连接成功后,我们就可以在右侧对话面板中输入问题与其交流了。
Demo 效果视频地址:https://www.bilibili.com/video/BV1rtjo6MEJe
从最终视频效果来看,Demo 中的 3D 虚拟人已经具备了很强的交互性。借助大模型的理解与生成能力,它能够理解用户提问,并给出自然、连贯的回答;同时通过语音、表情和动作完成具身表达,让交互不再停留在单纯的文本层面。
更重要的是,3D 虚拟人的响应速度也非常快,基本可以做到约 500ms 的低延迟响应,整体交互体验比较流畅。而实现这样一个能听懂问题、实时回应、并完成自然表达的网页 AI 伴侣,实际成本并不高。
下文将介绍如何借助 Trae 和魔珐星云具身驱动 SDK,快速搭建这个最小可运行 Demo。
核心技术:魔珐星云具身驱动SDK
从零实现一个 3D 虚拟人交互并不容易,背后需要打通一整套复杂链路:
- 3D 形象加载和端侧渲染;
- 文本转语音 TTS;
- 口型、表情、肢体动作同步;
- AI 回复流式输出后的播报拼接;
- 用户打断、思考、倾听、待机状态切换;
- 低延迟和多终端兼容
好在,这些复杂能力已经有了成熟方案:魔珐星云具身驱动
SDK。魔珐星云是魔珐科技打造的「AI
具身交互智能体开放平台」,提供 AI 形象生成、多模态感知、大模型 Agent 认知、实时 3D 具象表达、机器人运控等端到端能力。
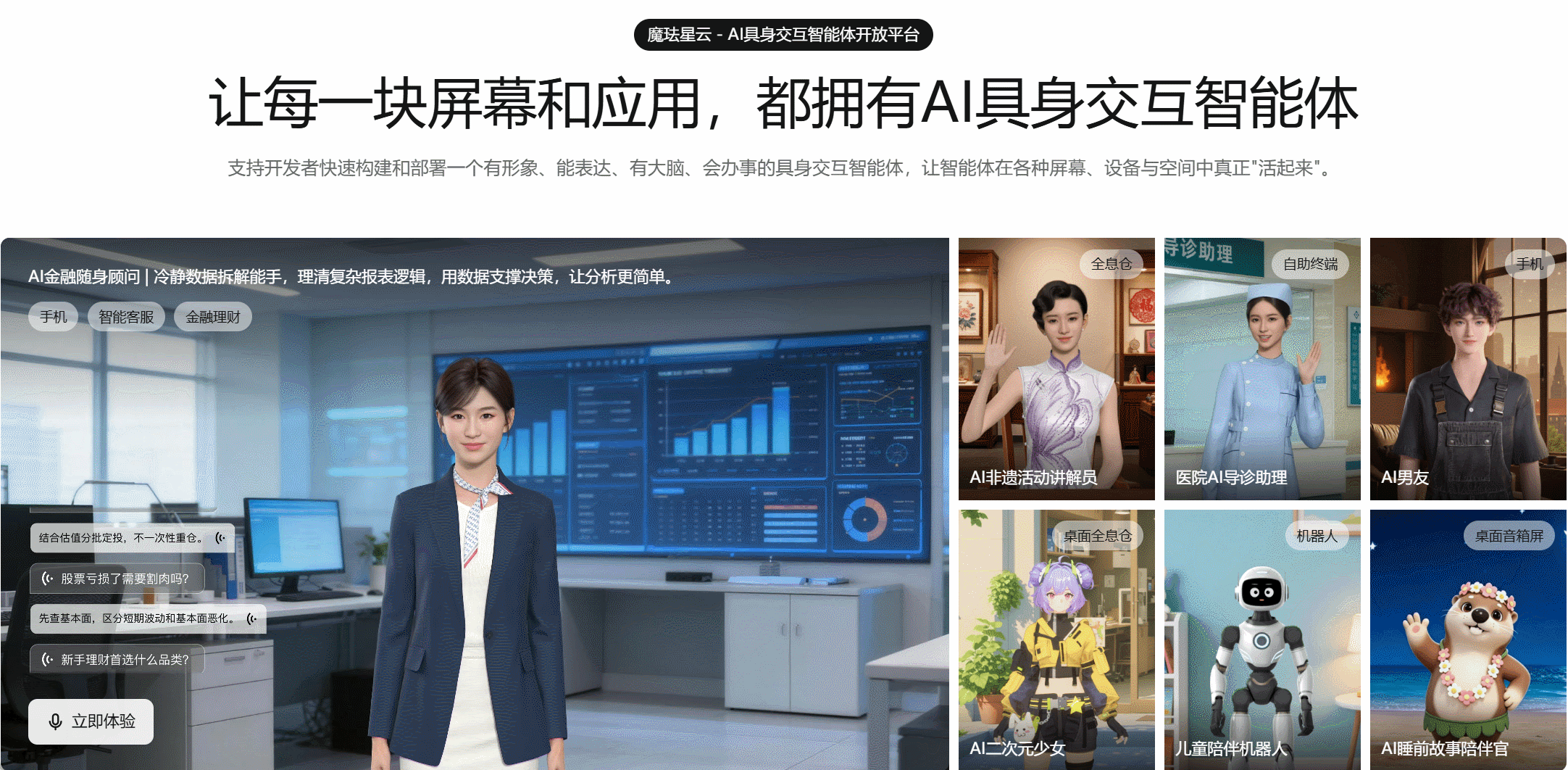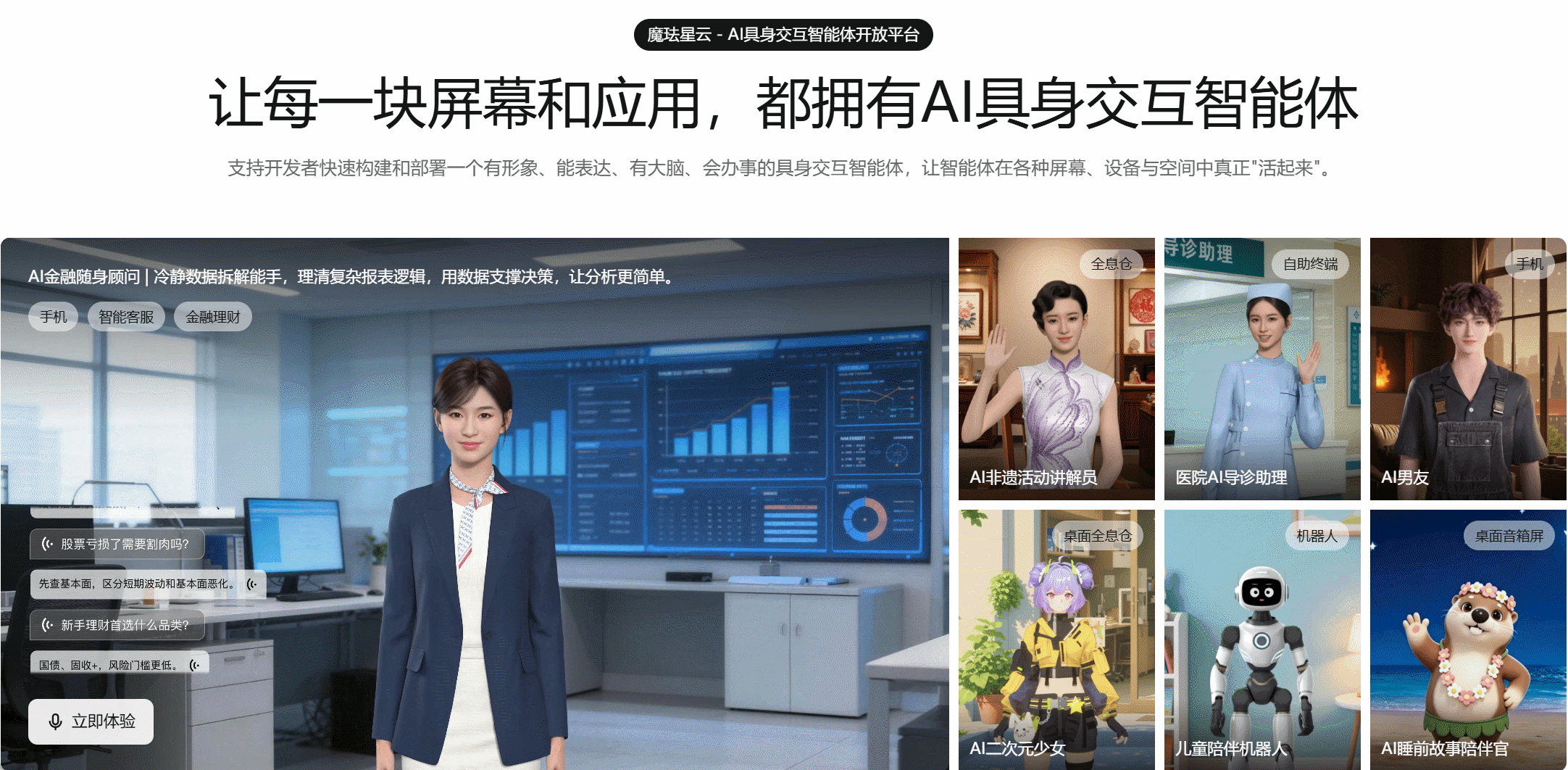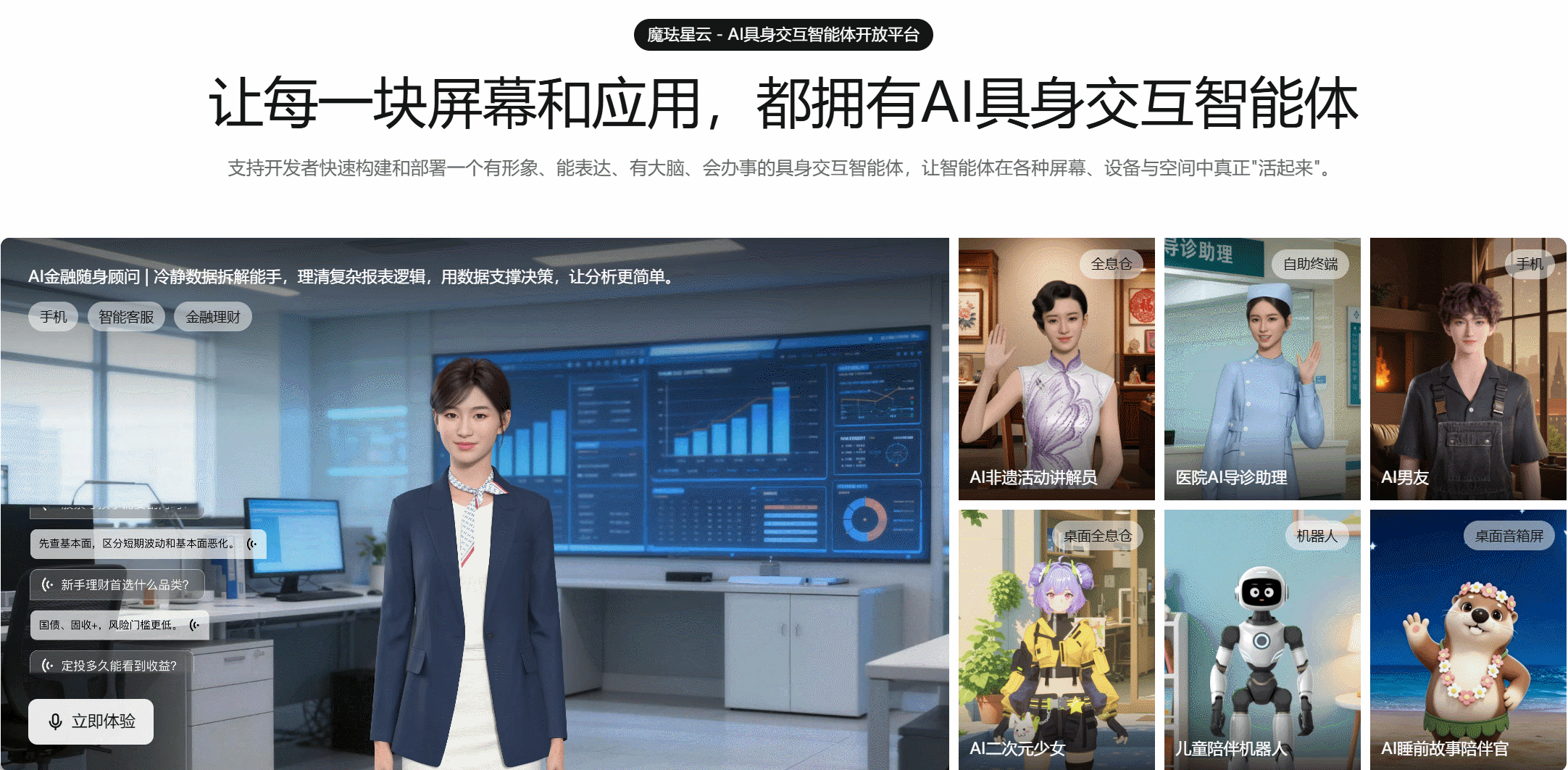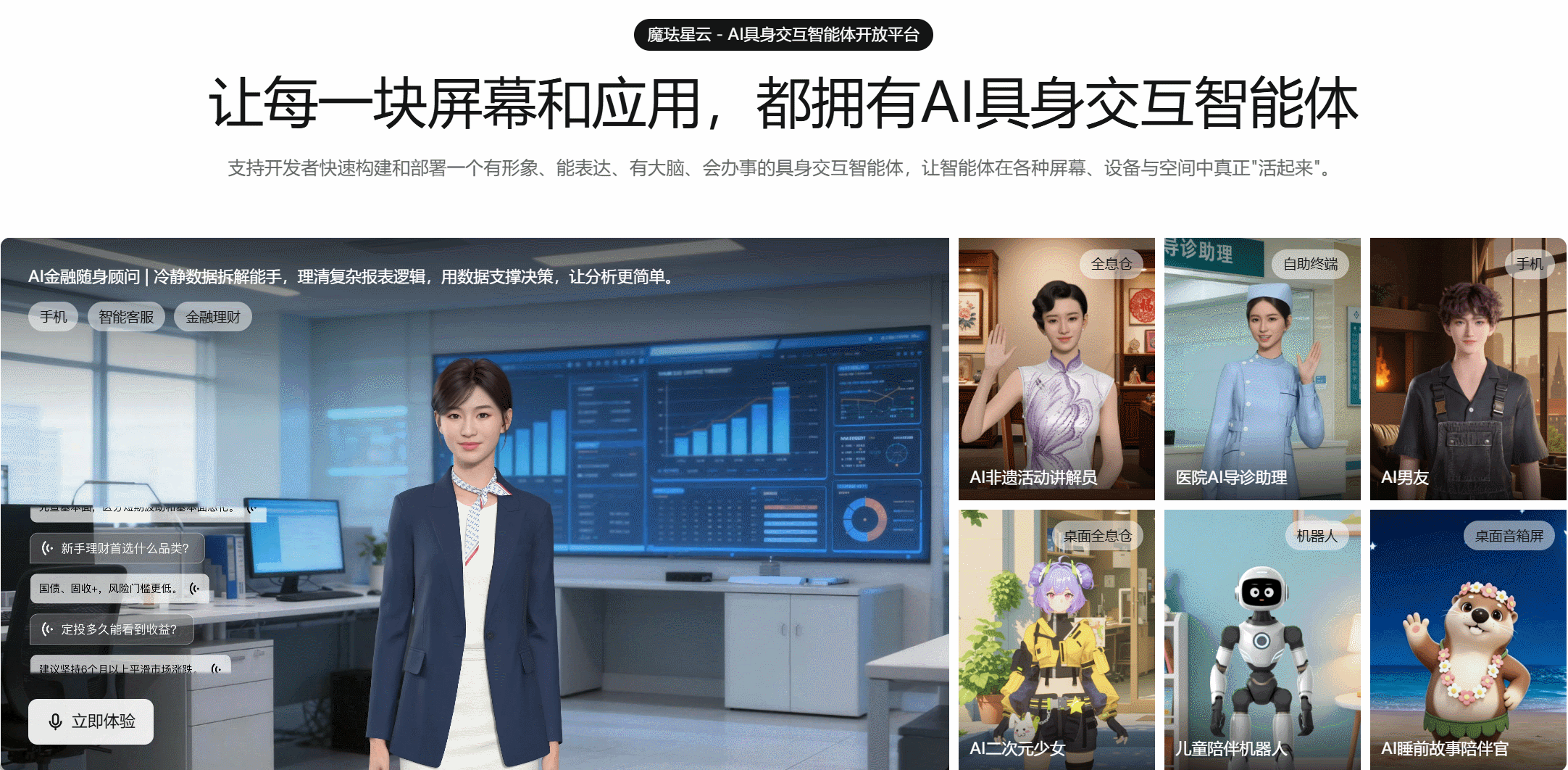
借助其具身驱动 SDK,我们可以把 AI 的表达方式从“文本回复”升级为“3D 多模态交互”:基于文本输入,实时生成语音、表情与动作,驱动 3D 数字人完成自然表达。
其核心功能包括:
- 实时 3D 数字人渲染与驱动:支持在网页中加载并驱动 3D 数字人形象;
- 语音合成与口型同步:支持文本/SSML 播报,并自动完成语音、口型、表情同步;
- 多状态行为控制:支持待机、互动待机、播报等状态切换;
- Widget 组件展示:支持字幕、图片、视频等内容展示;
- 事件回调与日志调试:支持自定义事件回调,方便接入业务逻辑和排查问题。
具身驱动SDK对浏览器的要求
目前,具身驱动 SDK 已提供 JS 版本。也就是说,只要终端支持浏览器内核,就可以接入具备 AI 交互能力的 3D 虚拟人,适用于网页、PC 客户端、车机、大屏等多种场景。其 SDK 支持的浏览器版本要求如下:

实战教程:用Trae快速搭建3D虚拟人项目
获取App ID、App Secret
要使用具身驱动 SDK 快速创建一个可交互的 AI 虚拟形象,首先需要登录魔珐星云控制台,在应用中心创建一个驱动应用,并完成角色、音色、场景和表演风格配置,同时获取后续接入 SDK 所需的 App ID 和App Secret。
参考下面的动图,登录控制台后,进入「应用管理」中的「驱动应用」Tab,点击「开始创建」,填写应用名称并确认。随后会进入形象选择页面,可以根据业务场景选择合适的 3D 数字人形象。
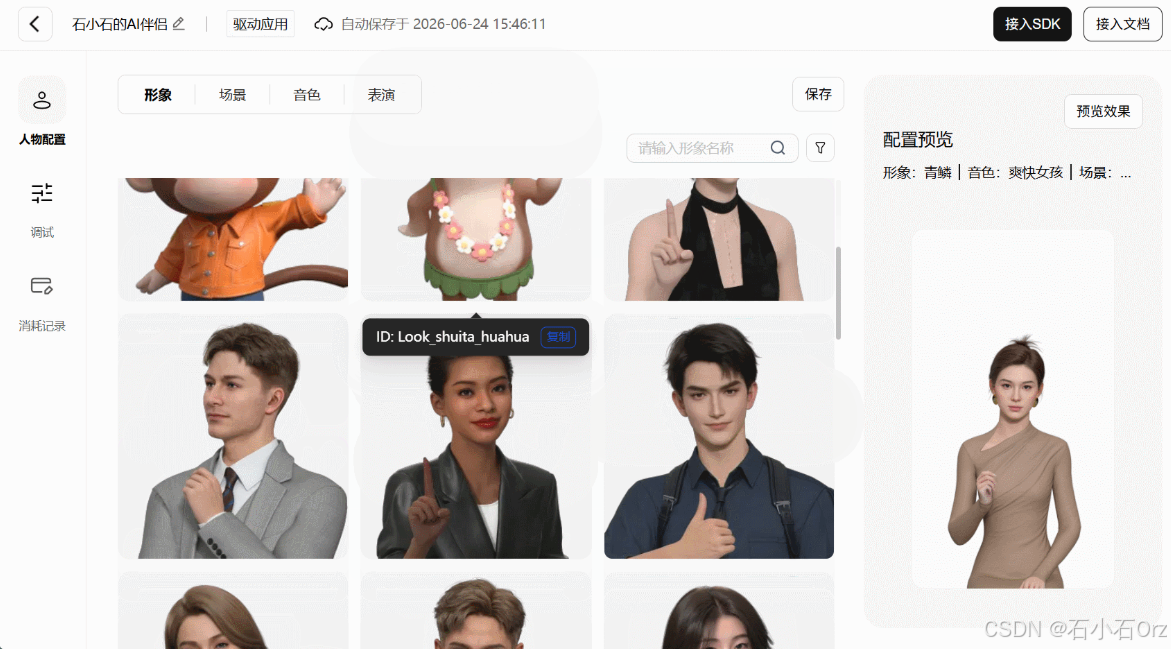
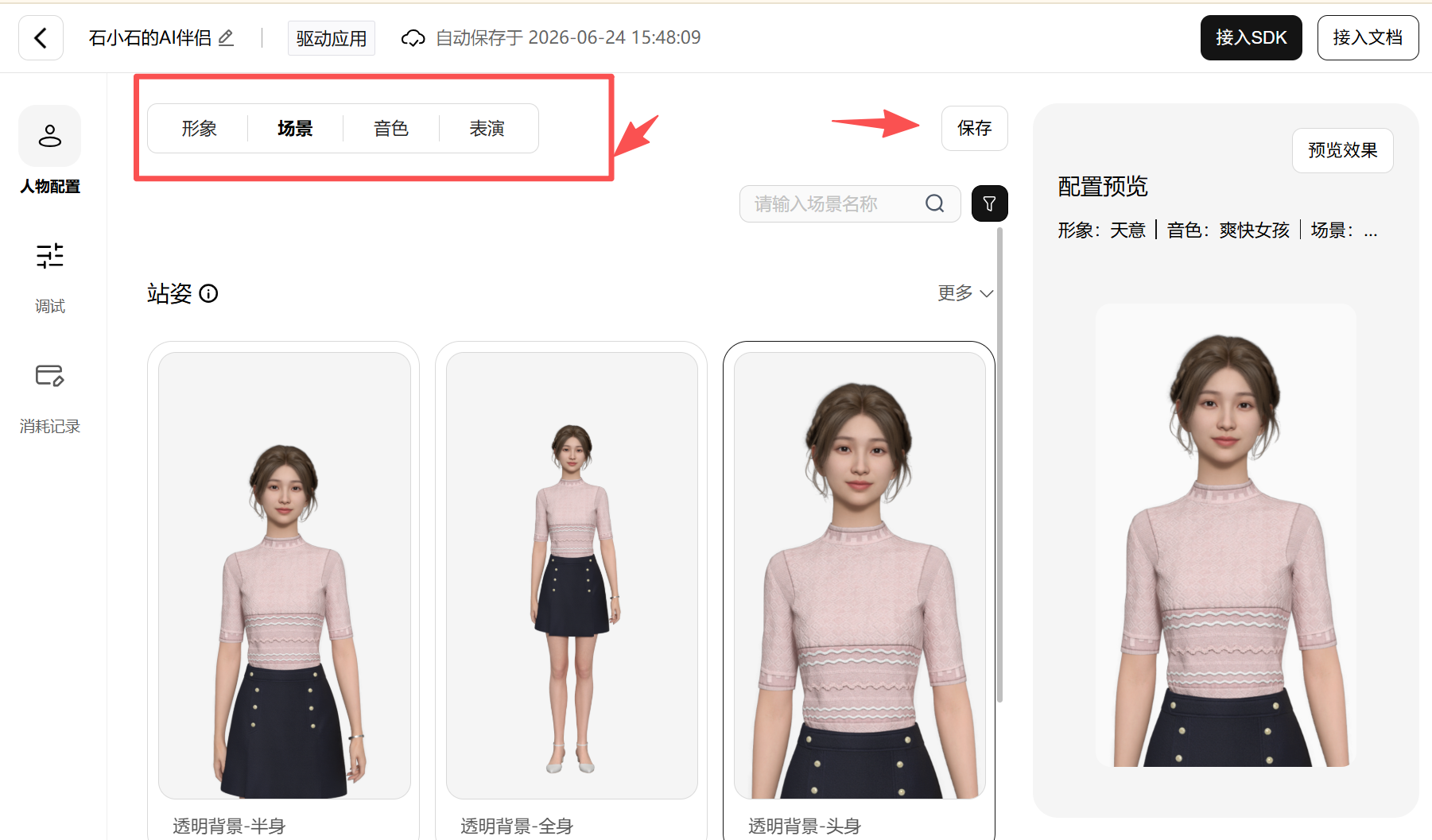
选择形象后,还可以继续配置场景、音色和表演风格。确认配置无误后,点击「保存」,系统就会自动完成驱动应用创建。
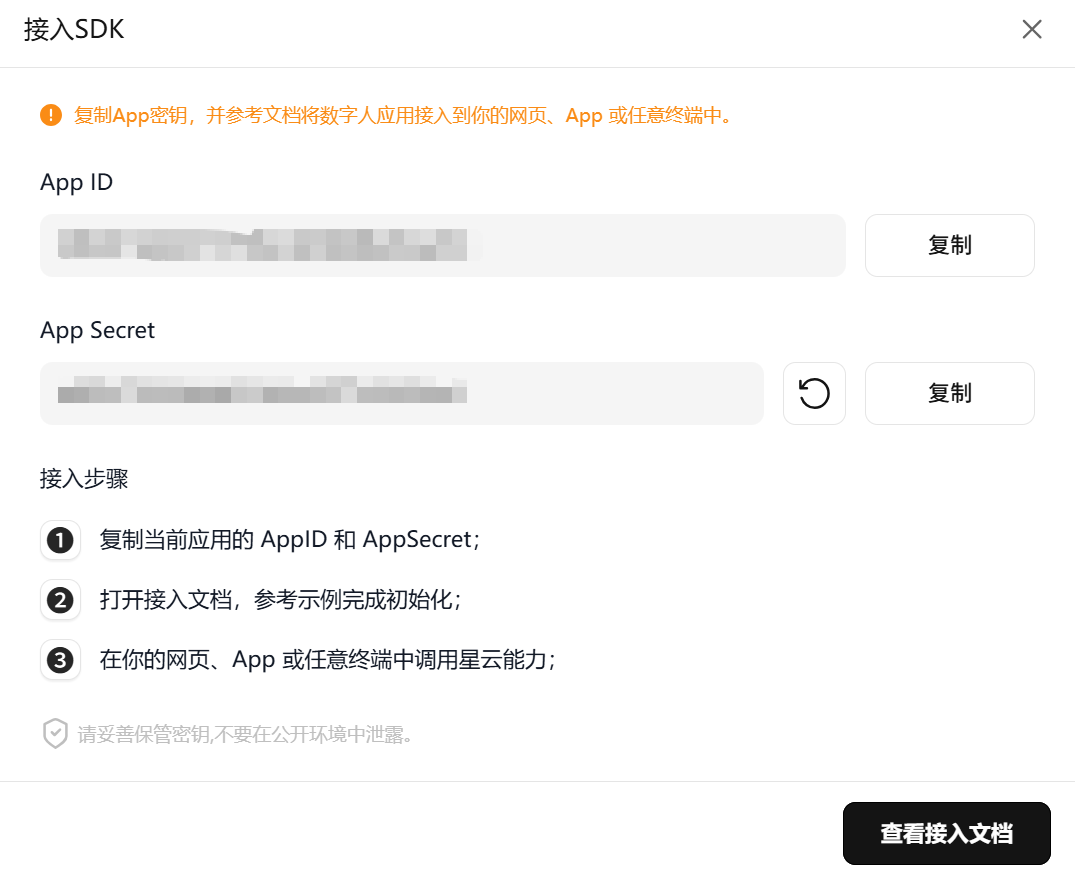
现在,点击「接入SDK」按钮即可查看并复制 App ID和 App Secret,用于后续网页 Demo 接入。
核心代码实现
具身驱动 SDK 的接入方式非常简单,整体流程可以分为三步:引入 SDK、初始化实例、调用播报方法。
首先,在页面中引入 SDK:
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
然后创建 SDK 实例,并完成初始化。这里需要将 appId 和 appSecret 替换为刚才在魔珐星云控制台中复制的内容:
const sdk = new XmovAvatar({
containerId: "#sdk", // 必填:数字人挂载容器
appId: "your_appid", // 必填:应用 AppID
appSecret: "your_appsecret", // 必填:应用 AppSecret
gatewayServer: "https://nebula-agent.xingyun3d.com/user/v1/ttsa/session", // 必填:服务接口地址
// SDK 事件回调,方便调试
onMessage(message) {
console.log("SDK message:", message);
},
});
// 初始化 SDK,加载数字人资源
await sdk.init({
onDownloadProgress(progress) {
console.log(`资源加载进度:${progress}%`);
},
});
初始化完成后,调用 speak 方法即可让数字人开口说话:
sdk.speak("你好,石小石,我是你的 AI 伴侣~", true, true);
如果只是播报一句完整的话,后两个参数通常都传
true
接下来,我们可以把以上接入逻辑粘贴到 Trae 的 AI 对话框中,让它帮我们快速生成一个基于 Vue 3 的最小 Demo。
下面是Trae 生成的一个最小使用Demo:
<template>
<!-- 数字人挂载容器 -->
<div id="sdk"></div>
</template>
<script setup>
import { onMounted, onBeforeUnmount } from "vue";
// 保存 SDK 实例
let sdk = null;
onMounted(async () => {
// 创建 SDK 实例
sdk = new window.XmovAvatar({
containerId: "#sdk", // 数字人挂载容器
appId: "你的 AppID", // 替换为控制台中的 AppID
appSecret: "你的 AppSecret", // 替换为控制台中的 AppSecret
gatewayServer: "https://nebula-agent.xingyun3d.com/user/v1/ttsa/session",
// SDK 事件回调,方便查看运行状态
onMessage(message) {
console.log("SDK message:", message);
},
});
// 初始化 SDK,加载数字人资源
await sdk.init({
onDownloadProgress(progress) {
console.log(`资源加载进度:${progress}%`);
},
});
// 初始化完成后,让数字人播报一句话
sdk.speak("你好,我是你的网页 AI 伴侣,很高兴见到你。", true, true);
});
onBeforeUnmount(() => {
// 页面卸载时销毁 SDK,释放资源
if (sdk) {
sdk.destroy();
}
});
</script>
<style scoped>
#sdk {
width: 800px;
height: 450px;
background: #000;
border-radius: 12px;
overflow: hidden;
}
</style>
启动项目后,页面会渲染出 3D 数字人,并在初始化完成后自动播报一句欢迎语。
对接DeepSeek,让AI伴侣具备智慧
接入 DeepSeek:获取 AI 回复
前面的 Demo 已经可以让数字人播报固定文本。接下来我们单独接入 DeepSeek,让页面具备 AI 回复能力。这里先不考虑复杂的流式输出,只用最简单的非流式接口:用户输入一句话,前端请求 DeepSeek,拿到完整回复后再交给数字人播报。
首先准备一个 DeepSeek API Key,然后在代码中定义:
// DeepSeek API Key,Demo 为了方便直接写在前端
const DEEPSEEK_API_KEY = "你的 DeepSeek API Key";
然后封装一个最简单的请求方法:
async function askDeepSeek(question) {
const response = await fetch("https://api.deepseek.com/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${DEEPSEEK_API_KEY}`,
},
body: JSON.stringify({
model: "deepseek-chat",
messages: [
{
role: "system",
content:
"你是一个网页 AI 伴侣,请用简洁、自然、口语化的中文回答用户问题。",
},
{
role: "user",
content: question,
},
],
stream: false,
}),
});
const data = await response.json();
// 取出 DeepSeek 返回的回答内容
return data.choices?.[0]?.message?.content || "抱歉,我暂时没有想好怎么回答。";
}
这个方法只做一件事:把用户的问题发送给 DeepSeek,并返回 AI 的文本回复。
可以先用一段简单代码验证接口是否正常:
async function testDeepSeek() {
const answer = await askDeepSeek("请用一句话介绍你自己");
console.log("DeepSeek 回复:", answer);
}
如果控制台能正常打印回复,说明 DeepSeek 已经接通了。
将 DeepSeek 回复交给数字人播报
DeepSeek 接通后,我们只需要把它返回的 answer 传给 sdk.speak(),数字人就可以把 AI 回复说出来。
核心逻辑如下:
async function askAndSpeak() {
if (!sdk) {
alert("请先初始化数字人");
return;
}
const question = inputText.value.trim();
if (!question) {
alert("请先输入问题");
return;
}
try {
// 用户提问后,让数字人进入思考状态
sdk.think();
// 请求 DeepSeek 获取回答
const answer = await askDeepSeek(question);
// 将 AI 回复交给数字人播报
sdk.speak(answer, true, true);
} catch (error) {
console.error("DeepSeek 请求失败:", error);
// 出错时也可以让数字人播报错误提示
sdk.speak("抱歉,AI 服务暂时不可用,请稍后再试。", true, true);
}
}
这里为了让 Demo 更容易理解,直接把 DeepSeek API Key 写在了前端。实际开发中不建议这样做,正式项目应通过后端接口转发请求,避免密钥泄露。
进阶 API:状态控制、流式播报与事件监听
完成最小 Demo 后,如果要把它升级成一个真正可交互的 AI 伴侣,就需要用到一些进阶 API。这里重点介绍几个最常用的能力:状态切换、流式播报、打断、音量控制和事件监听。
数字人状态切换
在真实交互中,数字人不应该一直处于同一个状态,而是要根据用户行为和 AI 响应过程切换状态。例如:用户没说话时待机,用户提问时进入思考,AI 回复时开始播报,用户打断时回到互动待机。
常用状态 API 如下:
// 普通待机状态
sdk.idle();
// 互动待机状态,常用于打断当前播报
sdk.interactiveidle();
// 进入离线模式,此状态下不消耗积分
sdk.offlineMode();
// 从离线模式切回在线模式
sdk.onlineMode();
在 Demo 中,最常用的是 idle() 和 interactiveidle():
// 初始化完成后,让数字人进入待机状态
await sdk.init();
sdk.idle();
// 用户点击“打断”按钮时,打断当前播报
function interrupt() {
sdk.interactiveidle();
}
其中,interactiveidle() 很适合用来处理“打断”场景。比如数字人正在播报一段长文本,用户想重新提问,就可以先调用它让数字人回到互动待机状态,再开始下一轮对话。
对接大模型流式输出
如果只是播报一句固定文本,可以这样调用:
sdk.speak("欢迎使用魔珐星云", true, true);
但在 AI 伴侣场景里,大模型通常是流式返回内容的。此时可以多次调用 speak(),通过 is_start 和 is_end 标识告诉 SDK 当前文本处于哪一段。
// 第一段:is_start 为 true,is_end 为 false
sdk.speak("你好,我是你的 AI 伴侣,", true, false);
// 中间段:is_start 和 is_end 都为 false
sdk.speak("我可以陪你聊天、讲故事,", false, false);
// 最后一段:is_start 为 false,is_end 为 true
sdk.speak("也可以帮你解答问题。", false, true);
参数说明:
sdk.speak(ssml, is_start, is_end);
ssml:播报文本,也可以是 SSML;is_start:是否为本轮播报的第一段;is_end:是否为本轮播报的最后一段。
需要注意的是,流式播报时建议先积攒一小段文本再开始调用 speak(),避免文本太短导致数字人频繁等待。同时,前一轮 speak(..., true) 结束后,不建议马上连续开启下一轮播报,最好先通过 interactiveidle() 做一次状态切换。
使用 SSML 触发动作
speak() 不仅可以传普通文本,也可以传 SSML。通过 SSML 可以让数字人在播报时执行指定动作,比如欢迎、挥手、跳舞等。
例如,让数字人说欢迎语时触发一个 Hello 动作:
const ssml = `
<speak>
<ue4event>
<type>ka</type>
<data><action_semantic>Hello</action_semantic></data>
</ue4event>
欢迎来到星云具身 3D 数字人平台,很高兴见到你。
</speak>
`;
sdk.speak(ssml, true, true);
如果需要根据语义触发动作,也可以使用 ka_intent:
const ssml = `
<speak>
热烈
<ue4event>
<type>ka_intent</type>
<data><ka_intent>Welcome</ka_intent></data>
</ue4event>
欢迎各位来到今天的分享。
</speak>
`;
sdk.speak(ssml, true, true);
这类能力很适合用于虚拟主持人、欢迎页、导览讲解等场景,让数字人不只是“说话”,而是能配合语义做动作表达。
监听播报状态
在真实项目中,我们经常需要知道数字人什么时候开始说话、什么时候说完。可以通过 onVoiceStateChange 监听音频播放状态。
const sdk = new XmovAvatar({
containerId: "#sdk",
appId: "your_appid",
appSecret: "your_appsecret",
gatewayServer: "https://nebula-agent.xingyun3d.com/user/v1/ttsa/session",
// 监听数字人播报状态
onVoiceStateChange(status) {
console.log("数字人语音状态:", status);
// 开始说话
if (status === "voice_start" || status === "start") {
console.log("数字人开始播报");
}
// 播报结束
if (status === "voice_end" || status === "end") {
console.log("数字人播报结束");
}
},
});
监听 SDK 消息和错误
onMessage 是调试时非常重要的回调。SDK 的错误信息、运行消息都可以通过它输出。
const sdk = new XmovAvatar({
containerId: "#sdk",
appId: "your_appid",
appSecret: "your_appsecret",
gatewayServer: "https://nebula-agent.xingyun3d.com/user/v1/ttsa/session",
onMessage(message) {
console.log("SDK message:", message);
// message 中通常包含 code、message、timestamp 等字段
if (message.code) {
console.warn("SDK 错误码:", message.code);
console.warn("SDK 错误信息:", message.message);
}
},
});
常见错误可以简单理解为几类:
10001:容器不存在,通常是containerId写错或 DOM 还没渲染;10002:Socket 连接异常,可能是网络或服务连接问题;10003:会话创建失败,优先检查appId、appSecret、应用配置;30001:背景图片加载失败;40001:音频解码失败;50001 / 50002:离线/在线状态变化;50003 / 50004:网络重试或网络断开。
在开发阶段,建议始终保留 onMessage 日志,这样排查问题会快很多。
音量与调试信息
最后还有几个开发调试时比较实用的方法。
控制音量:
// 静音
sdk.setVolume(0);
// 一半音量
sdk.setVolume(0.5);
// 最大音量
sdk.setVolume(1);
显示或隐藏调试信息:
// 显示调试信息
sdk.showDebugInfo();
// 隐藏调试信息
sdk.hideDebugInfo();
在联调阶段,可以临时打开调试信息;上线前再关闭,保持页面干净。
使用 Trae 完善交互体验
到这里,我们的 Demo 已经具备了基础能力:页面可以加载 3D 虚拟人,并通过 DeepSeek 获取 AI 回复,再交给数字人进行播报。接下来,我继续结合具身驱动 SDK 的常用 API,让 Trae 帮我做多轮代码迭代,逐步完善页面交互体验。
这一步主要补充了几个能力:
- 支持在页面中输入
App ID和App Secret,无需手动修改代码; - 增加连接状态展示,方便判断 SDK 是否初始化成功;
- 增加对话面板,用于和 AI 虚拟伴侣对话;
- 在请求 DeepSeek 时,让数字人进入“思考”状态;
- AI 回复后,调用
speak方法驱动数字人播报; - 增加“打断”能力,用户可以中断当前播报;
经过与 Trae 的多轮对话、调试和修复后,最终交互效果界面如下:
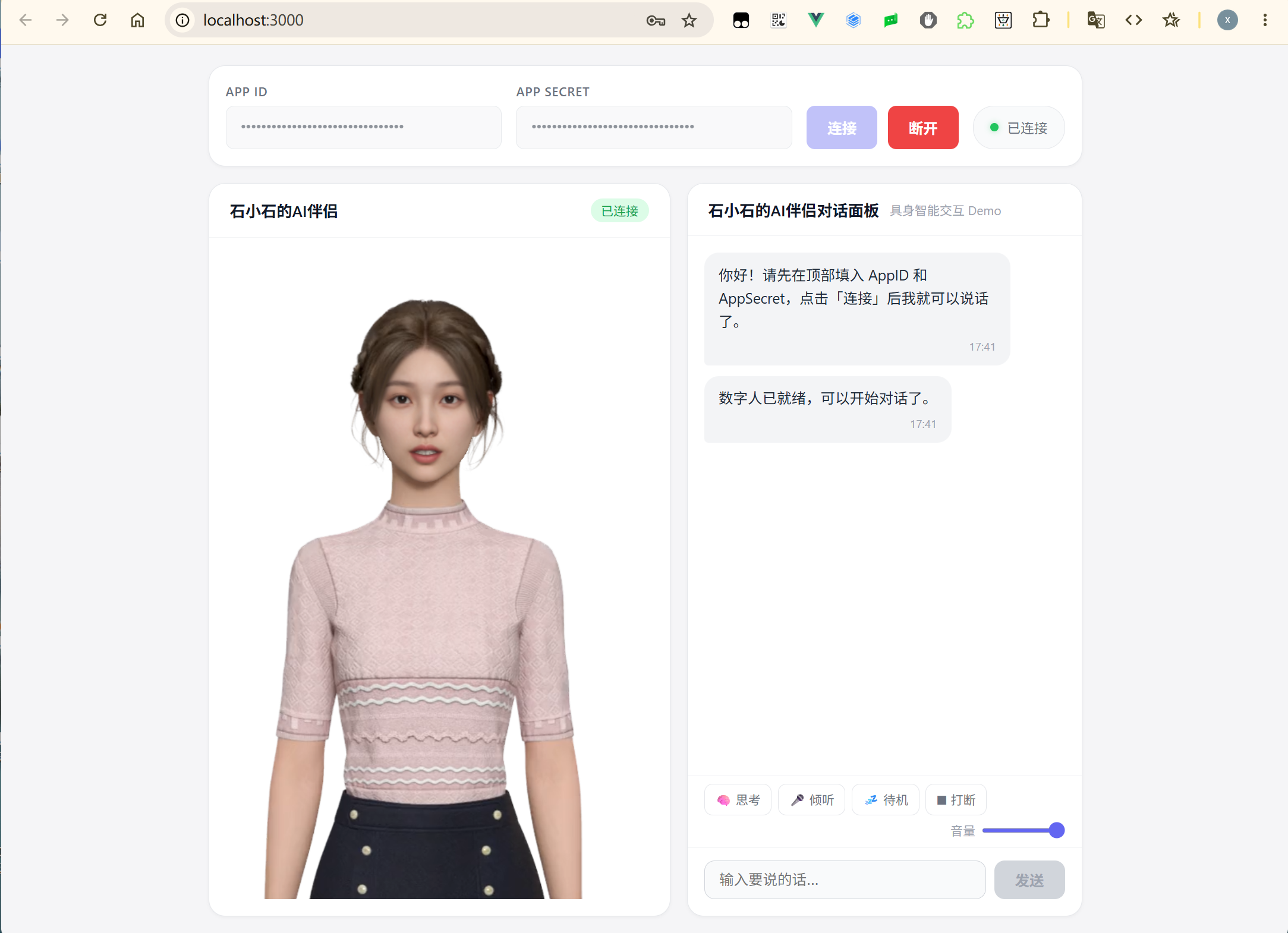
实际使用时,只需要在页面顶部输入 App ID 和 App Secret,点击“连接”完成初始化。连接成功后,在输入框中输入问题,虚拟助手就会调用 DeepSeek 获取回答,并通过 3D 数字人形象进行语音播报。
具体交互可以参考下面的视频:
Demo 效果视频地址:https://www.bilibili.com/video/BV1rtjo6MEJe
可以看到,虚拟人的响应几乎没有延迟,神情、动作都比较自然。如果你对当前的形象不满意,在魔珐星云控制台创建新的形象,更换App ID 和 App Secret即可。
增加语音对话功能
在上面的示例中,我们已经完成了基本的文本输入、AI 回复和数字人播报能力。但在很多真实场景中,比如车载大屏、商场导览屏、智能客服终端等,语音对话往往才是更自然的交互方式。
要实现语音对话能力其实并不复杂:前端可以调用浏览器麦克风权限,实时采集用户语音,再通过语音识别服务将语音转换为文本;随后把识别结果发送给大模型获取回复,最后再交给魔珐星云 SDK 驱动 3D 虚拟人播报。这样就可以形成完整的语音交互闭环:
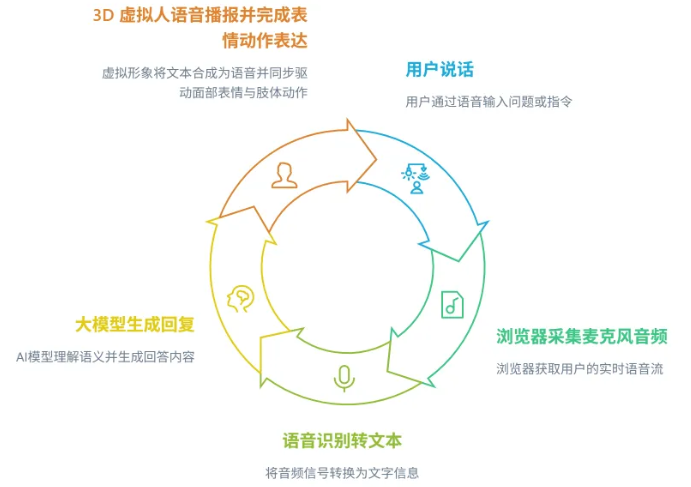
由于篇幅原因,本文不展开语音识别和实时音频采集的具体实现,后续我会单独写一篇文章拆解这一部分。
如果你对 3D 虚拟人、AI 伴侣、具身智能交互、语音对话等方向感兴趣,可以关注我的专栏,后续会继续分享更多相关实践。
总结
借助本文可以看到,通过魔珐星云具身驱动 SDK,实现一个能说话、可互动的 3D 虚拟人物成本非常低。基于浏览器和安卓 SDK 的支持,让它具备很强的终端兼容性,让网页、移动端、大屏、车机等多种屏幕和应用,都有机会接入 AI 具身交互智能体。
这也意味着,AI 不再只能停留在文本对话中,而是可以通过 3D 形象、语音、表情和动作完成更自然的表达,带来更接近真实陪伴的交互体验。
当然,本文只是一个最小可运行 Demo,主要用于验证从 3D 数字人加载、语音播报到大模型回复的完整链路。后续还可以继续扩展流式回复、语音输入、自定义字幕、动作控制等能力,让这个 AI 伴侣更加自然、智能和好用。
本文中的 Demo 已经开源,评论任意内容即可获得。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)