DeepSeek联合北大最新文章DSpark: 如何让大模型推理速度提升 85%?
一篇来自 DeepSeek-AI 与北京大学的联合研究,彻底重新定义了 LLM 高并发推理的效率天花板。
论文标题:DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation
机构:DeepSeek-AI + 北京大学
arXiv:待发布(论文内引用 DeepSeek-V4 为 arXiv:2606.19348)
你每天用的 AI 助手,背后在拼命"抢时间"
每次你向 AI 输入一个问题,背后的服务器都在和时间赛跑。
大语言模型(LLM)生成文本的方式天生很"慢"——它必须一个词一个词地蹦出来,每个词都要过一遍整个模型。用户越多,服务器越挤,响应就越慢。
为了解决这个问题,研究者们发明了推测解码(Speculative Decoding):先用一个小模型快速"猜"好几个词,再让大模型一次性验证。如果猜对了,就相当于大模型一次生成了多个词,速度自然快了很多。
但问题来了:
- 猜太多:后面的词越来越不准,大量验证资源被浪费
- 高并发时:每个请求都多验证几个词,整体吞吐量反而崩掉
- 自回归小模型:逐词生成太慢,块很小;并行小模型:一次全猜,但词之间互相不依赖,后几个词质量急剧下降
DeepSeek-AI 联合北京大学给出了一个优雅的答案——DSpark。
DSpark 是什么?
DSpark 全称 Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation,是一个统一了高吞吐草稿生成与自适应验证调度的推测解码框架。
它的核心思路可以用一句话概括:
“用半自回归架构草稿得更准,用置信度调度器验证得更聪明。”
两大核心创新
创新一:半自回归生成(Semi-Autoregressive Generation)
先看一个经典的并行解码错误案例:
假设 AI 要补全句子 “当然可以,没问题”。并行模型同时预测每个词,但因为不知道前一个词是"没",可能输出"当然问题"——词义混乱,典型的"多模态碰撞"。
DSpark 的解法是两阶段设计:
第一阶段:并行主干(Parallel Backbone)
- 继承 DFlash 架构,一次前向传播生成整个草稿块的隐藏状态和基础 logits
- 速度快,推理延迟几乎不随块长增加
- 可以堆更深的层数,第一个词的预测精度远高于浅层自回归模型
第二阶段:轻量顺序头(Sequential Head)
- 在并行主干之上,附加一个极轻量的逐步修正模块
- 每一步采样后,将前一个词的信息注入下一个词的概率分布
- 两种实现:Markov Head(只看前一个词,低秩矩阵实现)和 RNN Head(维护递归状态,捕获更长依赖)
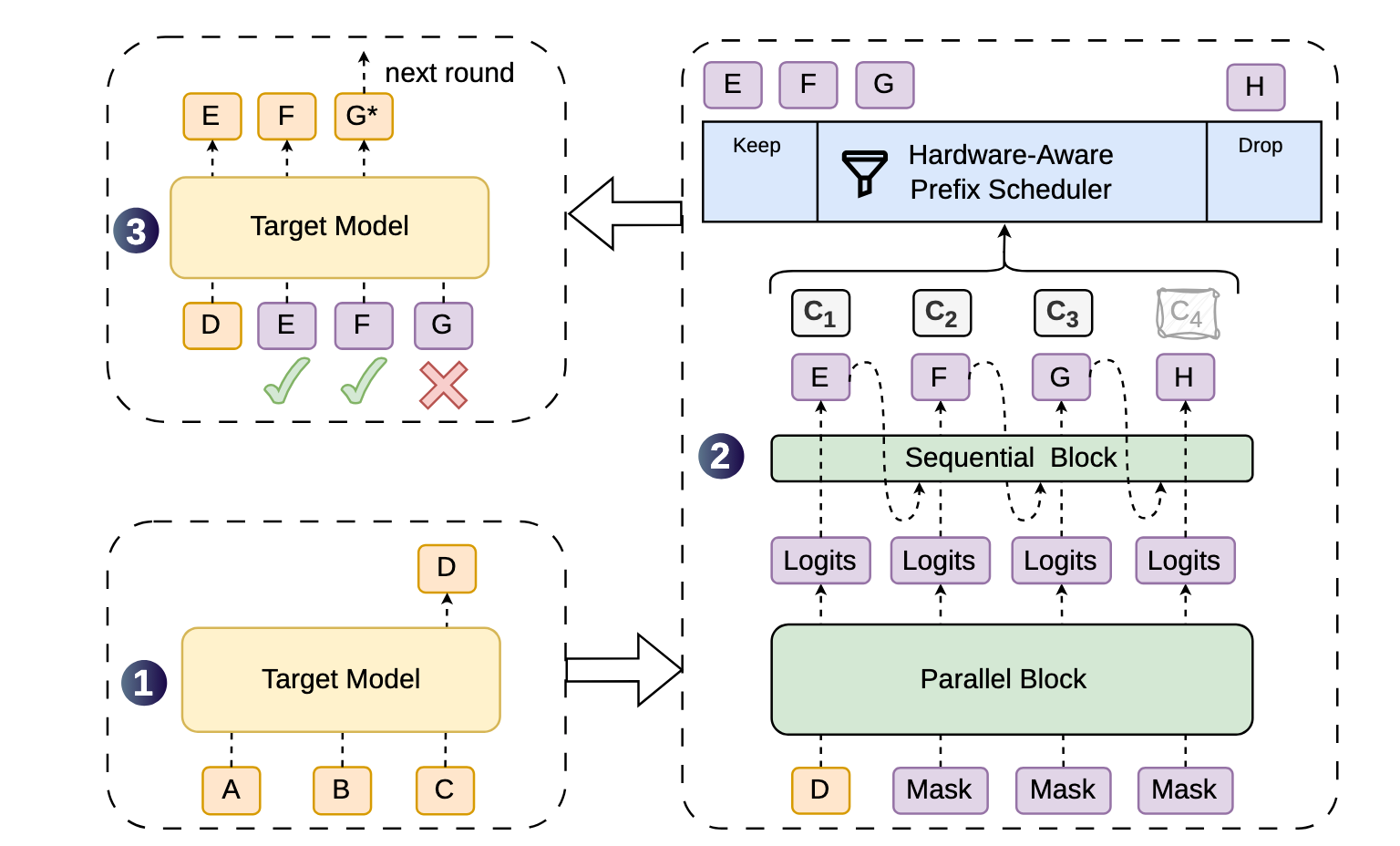
图1:DSpark 的架构与解码流程。给定提示词 ABC,目标模型先生成锚定词 D,DSpark 用并行主干+轻量顺序头生成草稿词 EFGH 及对应置信分数 c₁–c₄,调度器保留前缀 EFG、丢弃低置信词 H,目标模型并行验证,E/F 被接受、G 被拒绝并重生成 G。*
这个设计的精妙之处在于:顺序头极轻,延迟几乎可以忽略不计。实测中,将草稿长度从 4 扩展到 16,顺序头仅带来额外 0.2%~1.3% 的延迟,却换来高达 30% 的接受长度提升。
创新二:置信度调度验证(Confidence-Scheduled Verification)
并行模型生成了一个长草稿块,但不能所有词都送去验证——高并发时,这会把目标模型的 batch 容量全占满。
DSpark 通过两步解决这个问题:
2.1 置信度头(Confidence Head)
对每个草稿位置 k k k,输出一个标量 c k ∈ ( 0 , 1 ) c_k \in (0,1) ck∈(0,1),估计"在前面所有词都被接受的条件下,第 k k k 个词被接受的概率":
c k = σ ( w ⊤ [ h k ; W 1 [ x k − 1 ] ] ) c_k = \sigma\big(w^\top [h_k;\, W_1[x_{k-1}]]\big) ck=σ(w⊤[hk;W1[xk−1]])
其中 h k h_k hk 是主干的隐藏状态, W 1 [ x k − 1 ] W_1[x_{k-1}] W1[xk−1] 是 Markov 嵌入(前一个词的信息)。
训练时用总变差距离作为监督信号,直接对齐真实接受率:
c k ∗ = 1 − 1 2 ∥ p k d − p k t ∥ 1 c_k^* = 1 - \tfrac{1}{2}\|p_k^d - p_k^t\|_1 ck∗=1−21∥pkd−pkt∥1
后验温度缩放(Sequential Temperature Scaling):原始置信分通常过度自信,导致联合生存概率被高估。DSpark 从左到右逐位置校准温度,将预期校准误差(ECE)从 3%~8% 降至约 1%,为调度器提供可靠的概率估计。
2.2 硬件感知前缀调度器(Hardware-Aware Prefix Scheduler)
调度问题被建模为全局吞吐量最大化:
max ℓ 1 , … , ℓ R Θ = τ ⋅ SPS ( B ) \max_{\ell_1,\ldots,\ell_R} \Theta = \tau \cdot \text{SPS}(B) ℓ1,…,ℓRmaxΘ=τ⋅SPS(B)
其中 B = ∑ r ( 1 + ℓ r ) B = \sum_r (1 + \ell_r) B=∑r(1+ℓr) 是验证批次大小, τ = ∑ r ∑ j = 1 ℓ r a r , j \tau = \sum_r \sum_{j=1}^{\ell_r} a_{r,j} τ=∑r∑j=1ℓrar,j 是期望接受词数, SPS ( B ) \text{SPS}(B) SPS(B) 是硬件吞吐曲线(引擎初始化时预先 profiling,存为轻量查找表)。
求解策略:贪心排序 + 早停。将所有请求的所有候选词按生存概率降序排列,逐一加入验证批次,一旦吞吐量开始下降立即停止。这保证了:
- 算法复杂度低,O(γR log γR)
- 严格因果性(不会用未来信息做决策,保证无损解码)
实验结果:数字说话
离线基准:草稿质量碾压 SOTA
在 Qwen3-4B/8B/14B 和 Gemma4-12B 四个目标模型上,横跨数学推理、代码生成、日常对话三大领域:
| 模型 | vs. Eagle3(自回归) | vs. DFlash(并行) |
|---|---|---|
| Qwen3-4B | +30.9% | +16.3% |
| Qwen3-8B | +26.7% | +18.4% |
| Qwen3-14B | +30.0% | +18.3% |
DSpark 同时超越了最强自回归基线(Eagle3)和最强并行基线(DFlash)。
位置级分析:为什么并行模型反而赢了自回归?
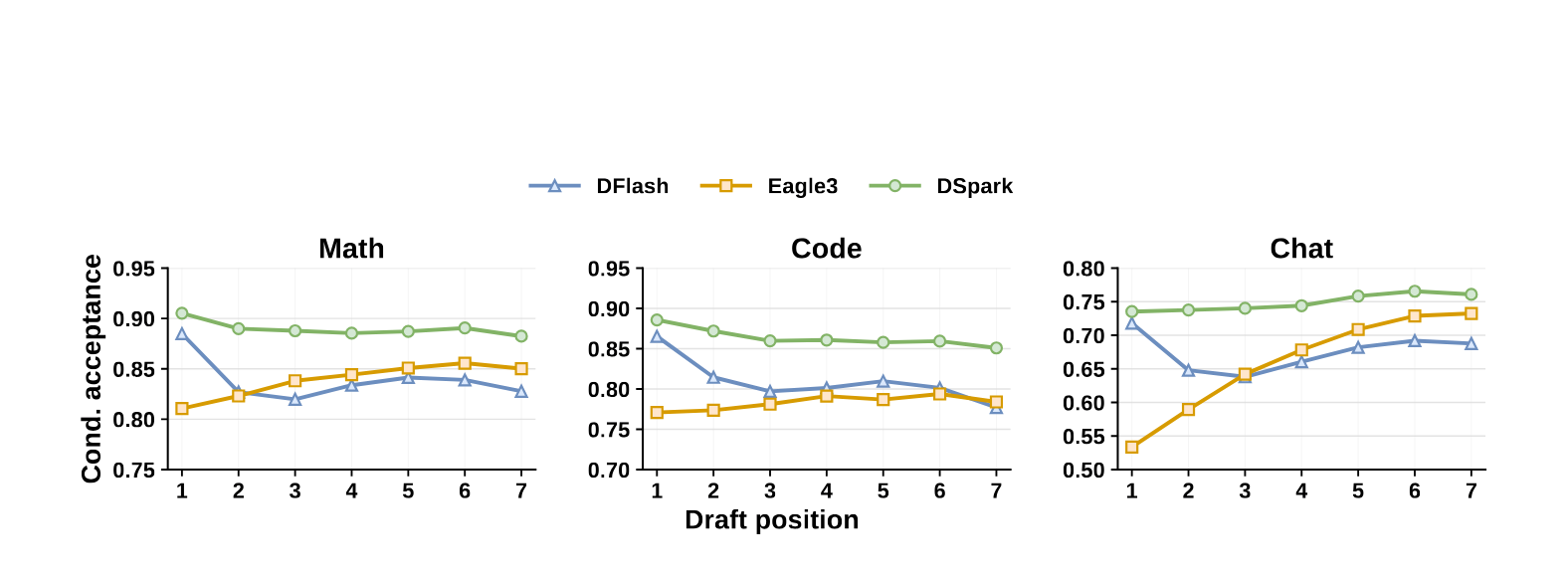
图2:三种架构在各草稿位置的条件接受率对比(Qwen3-4B)。注意 DFlash 在位置 1 的高起点,以及自回归 Eagle3 在后期位置的稳定性,而 DSpark 两者兼得。
这张图揭示了一个反直觉的现象:
- 位置 1:并行模型(DFlash)大幅领先自回归模型(Eagle3)——因为并行模型可以堆更深的层数,第一个词预测更准。而推测解码是严格前缀匹配,第一个词一旦被拒,后面全废,所以位置 1 的优势被极度放大。
- 位置 2-7:自回归模型因为有前词条件,接受率稳定甚至上升;并行模型(DFlash)因独立预测导致"多模态碰撞",接受率快速衰减。
- DSpark:同时继承了两者的优势——高起点 + 稳定后缀。
草稿深度与块长的影响
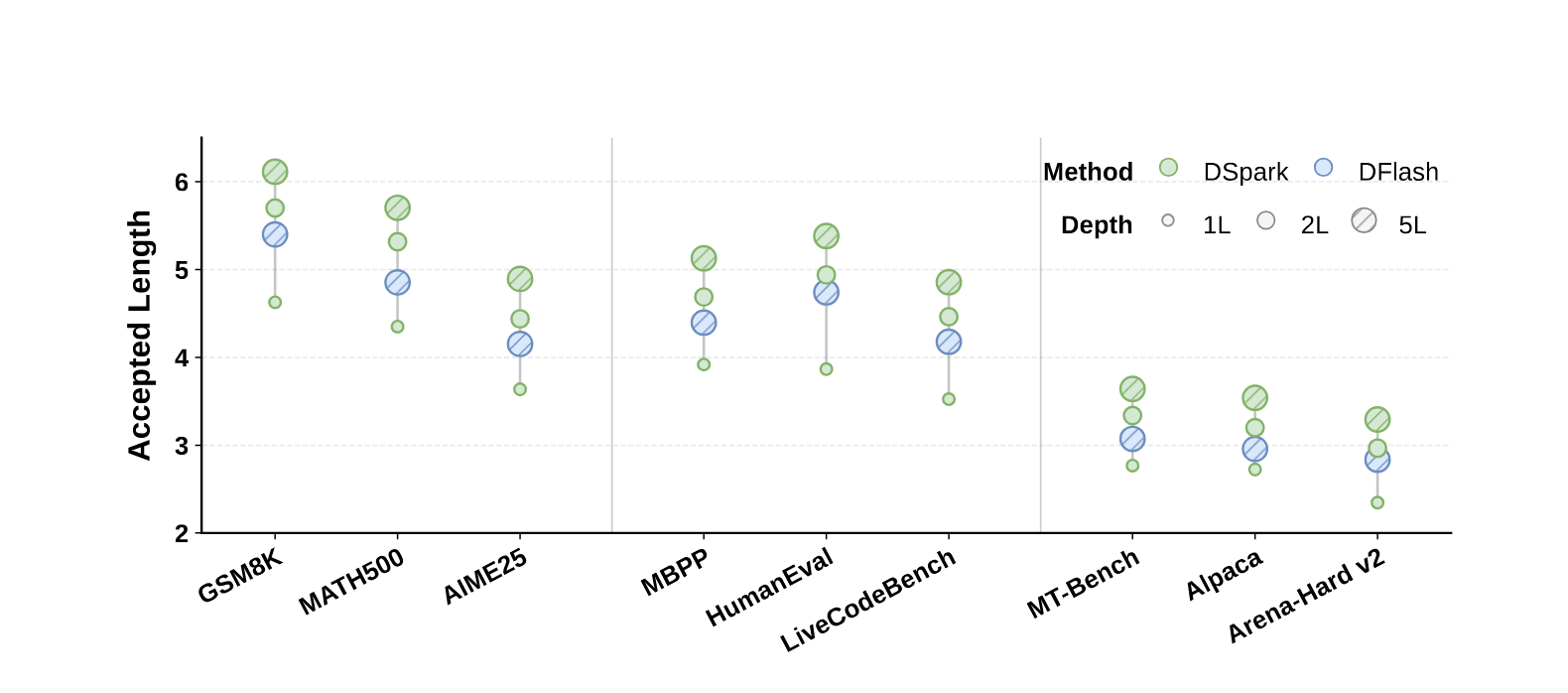
图3:草稿深度对比。仅用 2 层的 DSpark 就超越了 5 层的 DFlash 基线,体现了顺序建模的参数效率优势。
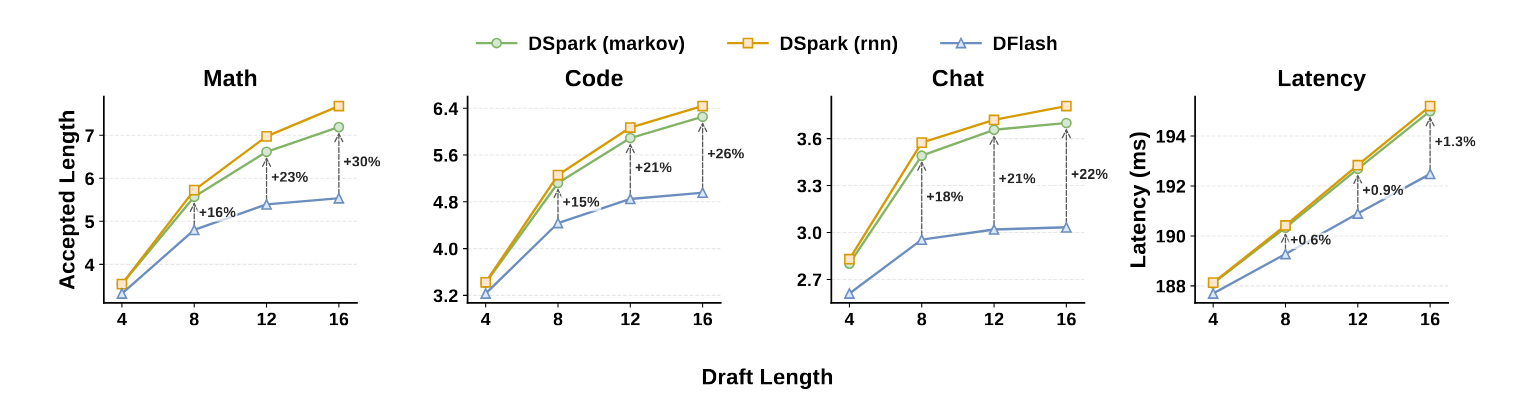
图4:草稿块长度变化时的性能与延迟。随着块长增大,DSpark 与 DFlash 的差距持续扩大,而顺序头的额外延迟几乎可以忽略(最右图)。
置信度阈值扫描
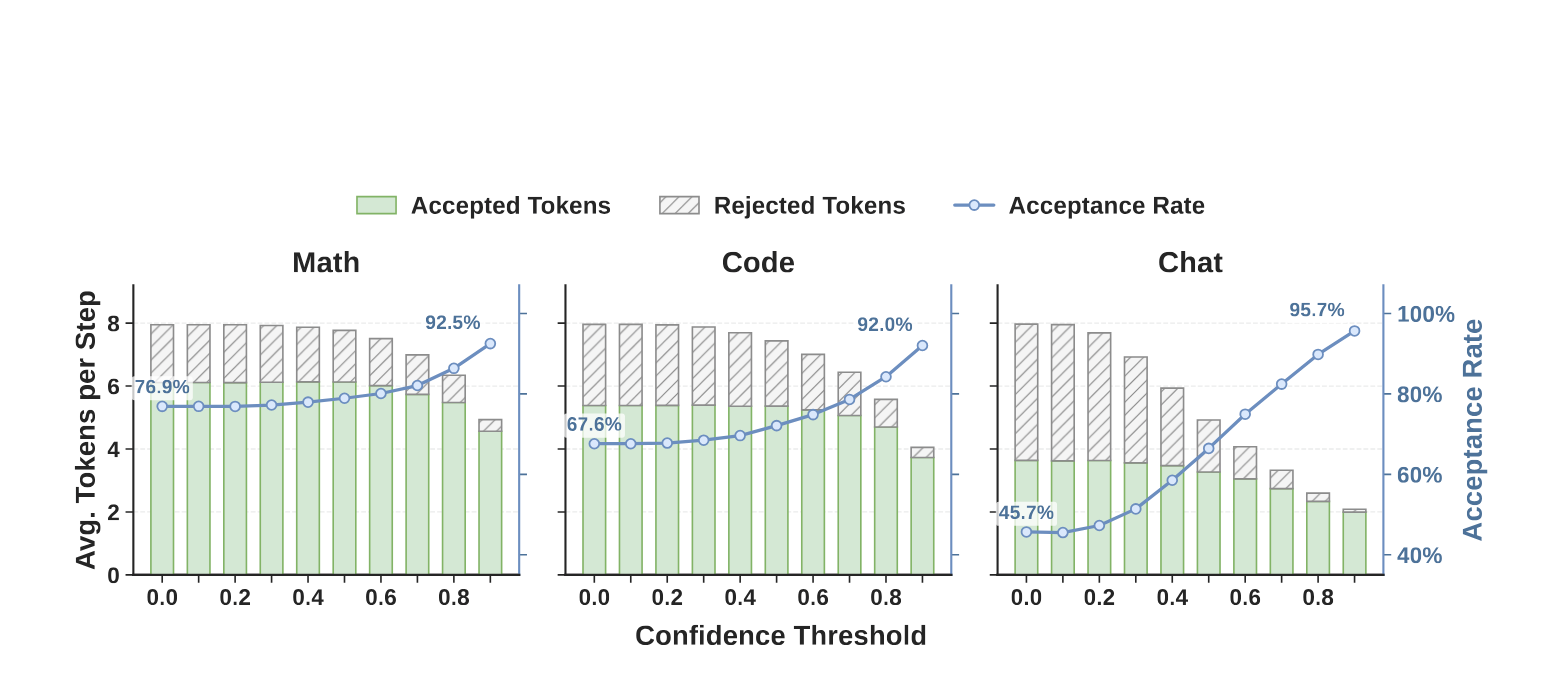
图5:置信度阈值扫描实验。随着阈值上升,被拒词(斜线条)被有效过滤,接受率大幅提升。Chat 任务提升最显著(45.7% → 95.7%),结构化任务(Math/Code)本身接受率高,提升相对温和。
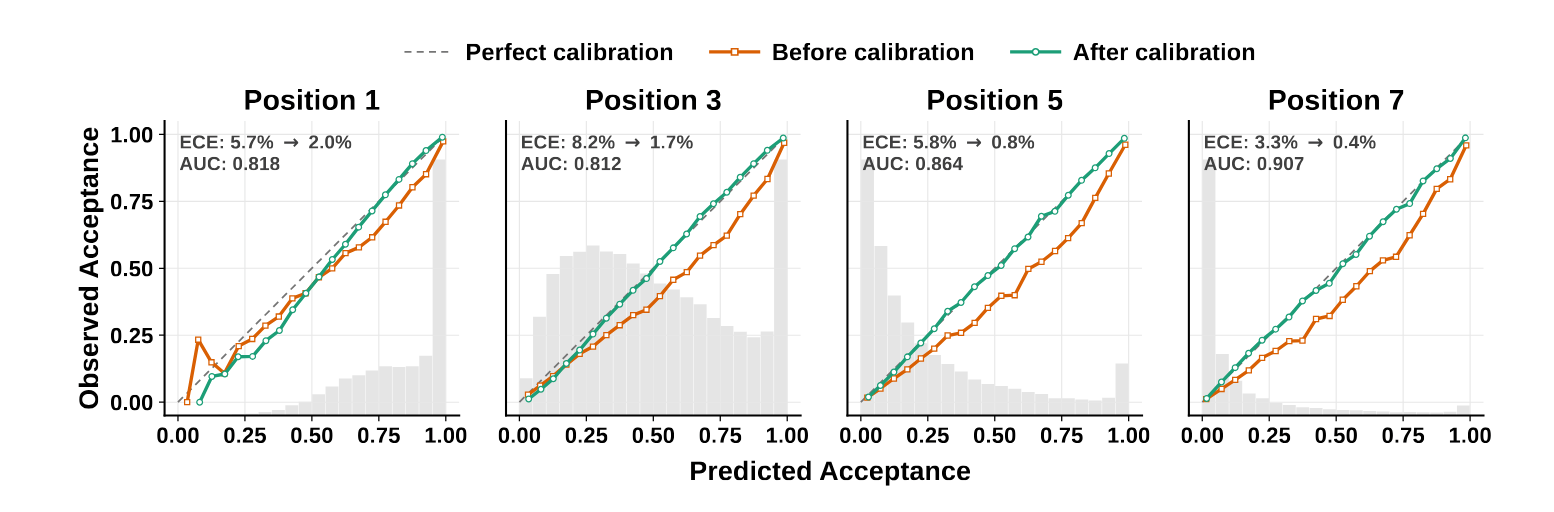
图6:置信度可靠性图(Alpaca 数据集)。校准前(蓝色)明显过度自信,经 STS 后(红色)与完美校准线高度吻合,ECE 从 5.7%~8.2% 降至约 0.4%~2.0%。
生产部署:Pareto 前沿的跃迁
真实流量下的性能突破
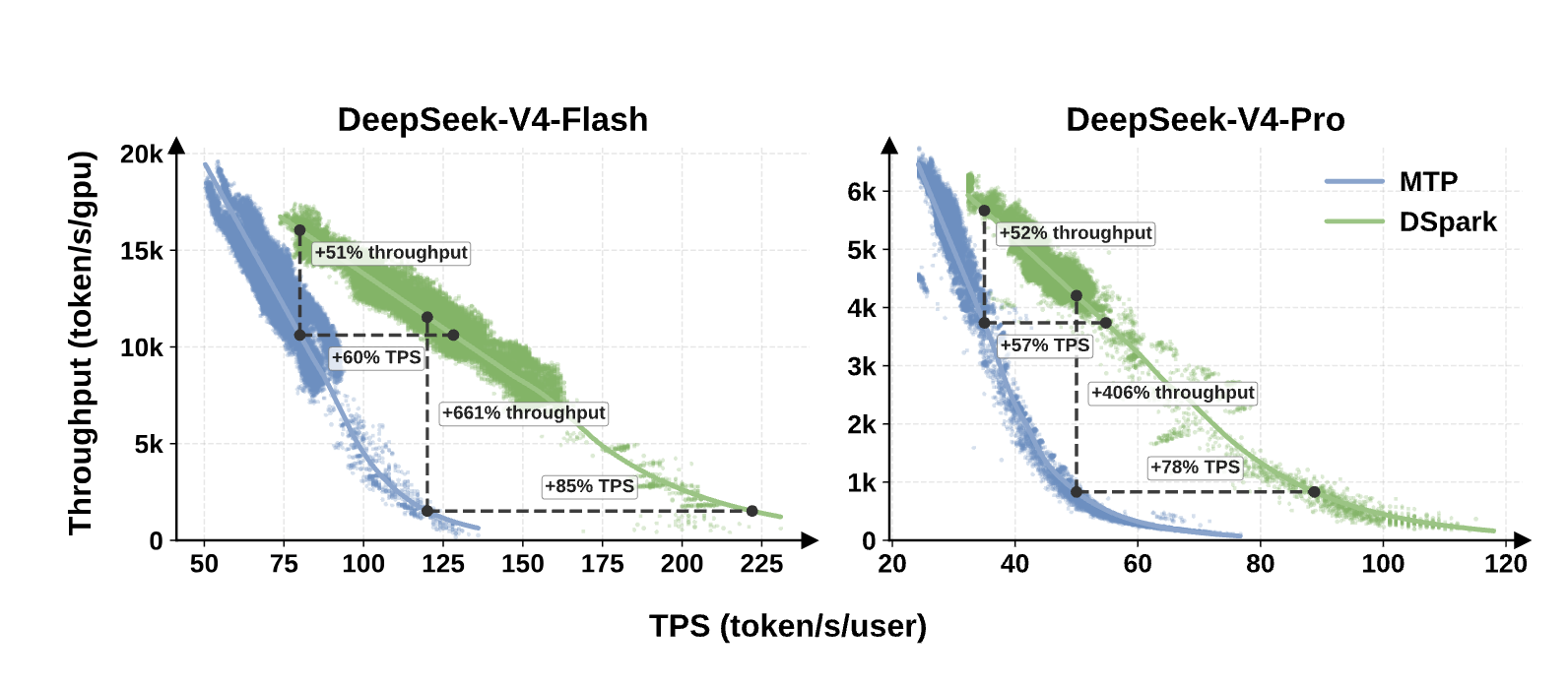
图7:DeepSeek-V4-Flash(左)和 V4-Pro(右)在真实用户流量下的吞吐量 vs. 每用户生成速度(TPS)。散点为实测遥测数据,曲线为拟合的 Pareto 前沿。DSpark 将整条曲线显著向右上方平移。
在 DeepSeek-V4 生产系统中对比旧基线 MTP-1(单词草稿):
V4-Flash
- 中等 SLA(80 tok/s/user):吞吐量提升 51%,同等吞吐下 TPS 提升 60%
- 严格 SLA(120 tok/s/user):MTP-1 接近崩溃,DSpark 仍可维持有效吞吐,TPS 提升 85%
V4-Pro
- 中等 SLA(35 tok/s/user):吞吐量提升 52%,TPS 提升 57%
- 严格 SLA(50 tok/s/user):MTP-1 严重退化,DSpark TPS 提升 78%
更重要的是,DSpark 解锁了此前根本无法维持的严格交互性层级——那是 MTP-1 无论如何也到不了的区域。
负载自适应调度
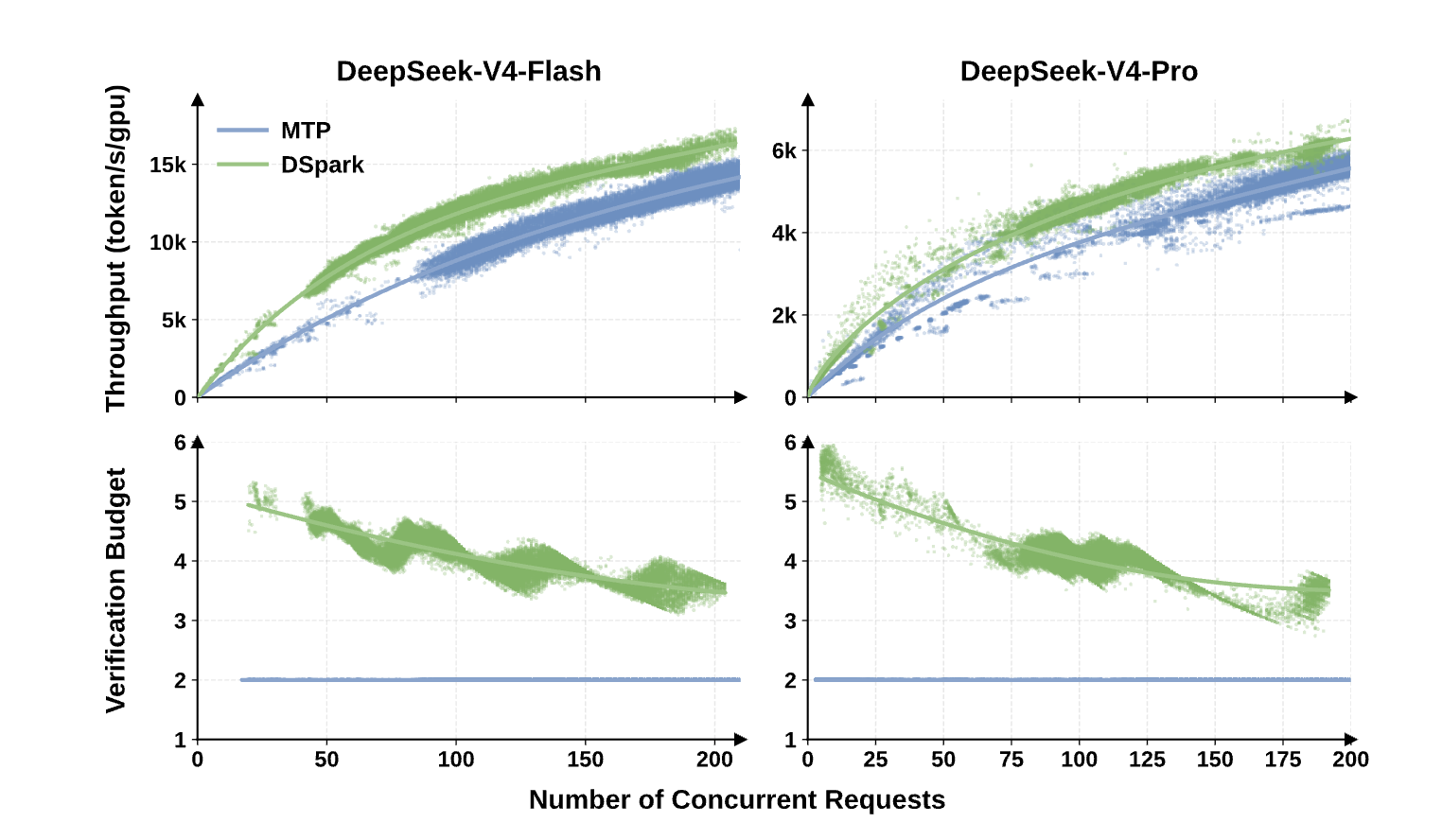
图8:吞吐量与验证预算随并发数的变化。轻负载下调度器分配 4–6 个验证词(超越 MTP-1 的静态 2 词),高负载下自动收缩预算,防止 batch 容量争抢。
这张图展示了 DSpark 调度器的核心价值:它不是一个固定策略,而是一个实时感知硬件负载的自适应系统——轻载时大胆展开,高载时精准收缩,始终在当前硬件状态下寻找最优工作点。
技术细节:工程上的挑战
DSpark 的生产部署并非一帆风顺,论文详细记录了两个核心工程挑战:
挑战1:训练效率
- 草稿模型需要目标模型输出分布作为监督,朴素实现通信开销极大(词表大小 ~10⁵)
- 解法:只传递目标模型最后一层 hidden state,再在本地做 LM head 投影,通信复杂度从 O(V) 降至 O(d)
- 另外实现了"锚点有界序列打包",解耦草稿训练与完整上下文长度,大幅减少内存和计算开销
挑战2:异步调度与 ZOS 兼容
- 实际硬件 SPS 曲线是锯齿状非单调的,朴素早停会陷入局部最优
- ZOS(Zero-Overhead Scheduling)要求下一步 batch size 在当前步完成前就必须确定
- 解法:异步调度,用前两步的置信度预测来确定当前步的验证容量上限(top-K 选取),实际候选词仍用当前最新置信分排序
- 关键洞察:异步设计天然形成因果屏障,使得去掉早停后的全局搜索依然满足无损解码的非预期性要求
与相关工作的对比
| 方法 | 架构 | 调度 | 生产验证 |
|---|---|---|---|
| Eagle3 | 自回归(TTT) | 静态长度 | 无 |
| DFlash | 完全并行 | 静态长度 | 无 |
| SpecDec++ | 任意 | 静态置信阈值 | 无 |
| DSpark | 半自回归 | 硬件感知动态调度 | DeepSeek-V4 生产 |
DSpark 是目前已知的唯一同时解决草稿质量衰减(Semi-AR)、系统级吞吐优化(置信调度)并在超大规模生产系统中验证的方法。
开源信息
DeepSeek 已开源:
- DSpark checkpoints:DeepSeek-V4-Flash (preview) 和 DeepSeek-V4-Pro (preview) 对应的草稿模型权重
- DeepSpec:算法驱动的推测解码训练仓库,包含 Eagle3、DFlash、DSpark 三个算法实现
社区研究者可以直接基于这些资源复现和改进 DSpark。
总结
DSpark 用一个简洁但深刻的洞察击中了推测解码的两个核心痛点:
-
草稿质量:并行快但不准,自回归准但慢——半自回归用 1% 的延迟开销买来了 30% 的接受长度提升,两头都不丢。
-
验证效率:静态长度在高并发下是灾难,动态调度根据硬件负载实时分配验证预算,使 Pareto 前沿整体外移。
对于正在思考如何在高并发场景下高效部署大模型的工程师,DSpark 提供的不只是一个技术方案,更是一套将算法设计与系统现实深度结合的工程哲学。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 1
1 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)