NLP基础 GPT和BERT
参考https://www.rethink.fun/chapter16/
GPT 1
GPT1开始还是开源的,结构也比较简单
GPT的全称是Generative Pre-Training,意为生成式预训练,最早在论文《Improving Language Understanding by Generative Pre-Training》(通过生成式预训练改进自然语言理解)提出,目的是解决之前的NLP模型的几个问题
- 需要标注数据
- 模型针对特定领域,难以迁移
- 基于RNN的模型训练无法并行,训练慢
他的解决方法是
- 引入注意力机制,训练可并行
- 结合掩码和自回归训练的注意力机制,可以进行无监督训练
- 预训练一个通用生成式模型,再用它微调解决特定领域问题
需要注意的点有
- decoder only架构,没用attention is all you need里的encoder+decoder架构
- 剩余部分和文章里的decoder一样,有嵌入层和位置编码,然后主体是注意力层+FFN层+归一化
- 注意力采用多头注意力,12个头
- 归一化采用LayerNorm层归一化,并且有残差连接
- 位置编码是可学习参数,不是固定编码
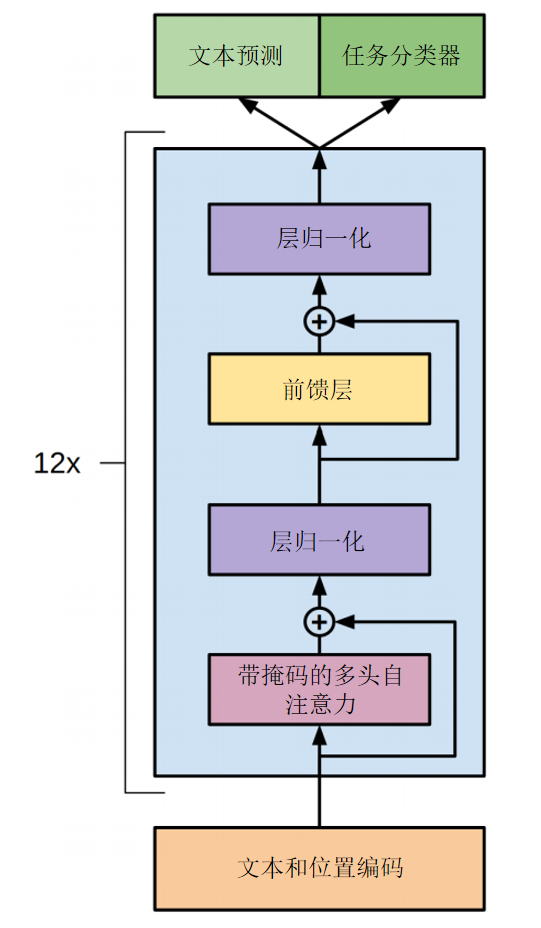
GPT1的意义在于,用预测下一个token的预训练大模型,刷新了当时多个NLP任务的SOTA,证明了预训练大模型统一NLP的潜力。具体来说,现在大量数据上无监督预训练,然后对于特定任务,只要把数据格式处理一下,最后接上一个对应的线性层做微调,就能解决各种特定的的NLP任务,在多项任务中,得分还比原有的专用模型更高。于是在GPT1之后越来越多的NLP研究者转向预训练LLM。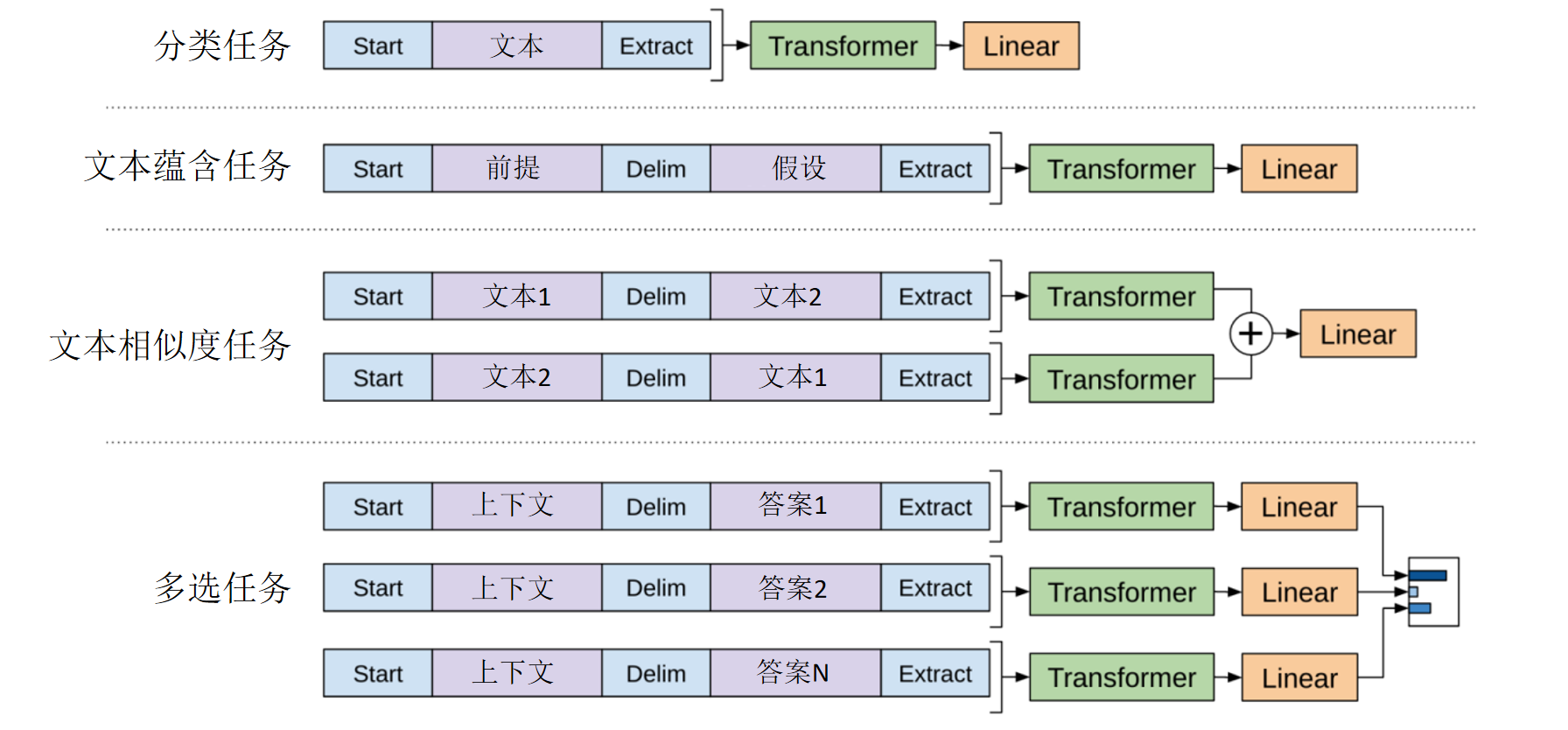
BERT
BERT(Bidirectional Encoder Representations from Transformers)是GPT-1诞生后很长时间内的SOTA,从名字可以看出来这是一个双向注意力编码器架构的模型,设计思想是,在很多任务比如翻译上,需要看到双向的信息,而GPT-1的decoder-only架构决定了他的注意力是单向的,这在文本理解任务上有巨大劣势,一个词的含义显然不只需要上文,还需要下文。
GPT的单向注意力,为了保持训练和推理时的一致,即使是推理时,也用因果掩码把输入序列盖住,这样计算每个token的注意力输出时,即使是开始的输入已经全给出了,一个token也只能看到自己前面的信息,相当于损失了很多。
BERT为了解决这个问题直接不用decoder了,改用encoder only,并且不加因果掩码。代价是很难做生成任务,只能在encoder后面加上线性层做一些特定任务。也就是BERT并不是生成式模型,当然BERT也采用了大规模数据预训练的设计。
尽管如此,BERT也打败了GPT,在很长时间内是NLP许多任务的SOTA,直到GPT-3用超大预训练才反超了BERT。
GPT-2
相比GPT-1,参数量从1亿提升到了15亿,这是最主要的。在训练GPT-2是,OpenAI团队发现,随着预训练数据量的提升,模型性能持续改进,到了15亿看起来还有提升空间,也就是还处于欠拟合,这让OpenAI坚定了继续扩大规模(Scaling Law)的思路,最终催生了破圈的GTP-3,给了研究者预训练LLM可以走向AGI的宏大愿景。
此外,GPT-2还有一些设计优化,都是为了辅助扩大训练规模设计的
- 归一化移动到输入阶段,也就是在注意力,FFN前作归一化而不是之后
- 减小残差连接的权重,这和移动归一化位置都可以降低梯度爆炸,让模型层数增加后还能稳定训练
- 凭借前面两个对训练稳定性的优化,decoder block堆到了48层,参数规模继续扩大。
最终的测试效果,也证明了扩大参数规模的有效性,GPT-2不再像GPT-1一样需要对输入进行预处理,然后做微调,才能处理特定任务了,直接把在输入基础上用自然语言描述需要做的任务,就能在文本翻译,文本分类等特定任务上去的超过专用模型的效果,这就是所谓的,无需微调的“零样本(Zero-shot)”多任务能力
GPT-3
GPT-2的成功让OpenAI验证了Scaling Law的可行性,于是OAI从此开始在堆规模的路上一路狂奔,到了这一代GPT-3,参数规模最大扩到1750亿也就是175B。
在模型参数达到100B左右,模型的能力出现了涌现(Emergence),也就是突然在代码,数学等任务上能力发生了飞跃。原本的GPT-2虽然在NLP任务上还可以,但是更接近于一个复读机,对与人类语言习惯有一定理解能力,但是对于数学等包含逻辑的问题效果很差。而GPT-3开始,模型数据量扩大到一定规模后,在数学等科学领域的能力也开始变得可用。
GPT-3开始具备生产可用性,不再是实验室玩具,OAI开始了商业化进程。由于模型参数量太大,个人开发者和中小企业难以部署,于是OAI用大规模GPU集群部署模型,然后开放API供商业使用,开启了 MaaS (Model as a Service,模型即服务) 的新时代。
但GPT-3模型是2020年发布的,到ChatGPT服务问世还过去了接近三年,这是因为此时的模型在指令遵循方面很差,类似于一个强大的野兽,不受人类控制。为了解决这个问题,OpenAI 在 2022 年初推出了一个极其重要的过渡模型——InstructGPT。这就是大模型历史上大名鼎鼎的 RLHF(基于人类反馈的强化学习) 技术的首次全面落地。
对齐的过程主要分为三步(也就是 RLHF 的经典三阶段):
阶段一:监督微调(SFT)
OpenAI 找了一批专业的标注员,写了大量人类理想中的“指令-回答”对。比如:
-
指令:“请帮我写一封请假信。”
-
标准回答:“尊敬的老师,我是……因为……特此请假……”
用这些高质量的数据去微调 GPT-3,让模型初步理解什么叫“命令与服从”。
阶段二:训练奖励模型(Reward Model)
让模型针对一个问题输出 4 个不同的回答,然后让人类标注员去给这 4 个回答排个序(哪个讲礼貌?哪个没有胡说八道?哪个切中要害?)。用这个排序数据训练一个“奖励模型”,它就像一个“AI 裁判”,专门模仿人类的口味去给大模型的回答打分。
阶段三:强化学习(PPO 算法)
让大模型自己去拼命生成回答,“AI 裁判”(奖励模型)在后面看着,生成得好就给高分,生成得不好(比如有歧义、有毒、胡说八道)就扣分。通过强化学习不断调整模型参数。
对齐带来了奇迹:OpenAI 发现,经过对齐的 13 亿参数的 InstructGPT,在人类体验上直接击败了 1750 亿参数的原生 GPT-3!
在模型架构方面,没有大改,只是引入了Sparse Attention(稀疏注意力机制),让每个Q不再和全部的KV计算注意力,而是选择一部分KV计算,选择方式有很多,这里不细讲,常见的有滑动窗口,聚类,跨步,分块等方式。剩余架构基本和GPT-2保持一致,这是OAI的设计哲学:重要的是数据和参数量,有了参数量智能自然就上来了,不用在架构层折腾。
GPT-4
此时的OpenAI已经不再open,几乎没有公开的技术报告。目前可公开的情报:
-
有多模态能力,可以识别图片,输出文字描述。参数量达到千B级别,最大模型大概1800B,或者用更大单位,1.8T。上下文窗口拉长,从4K提升到32K
-
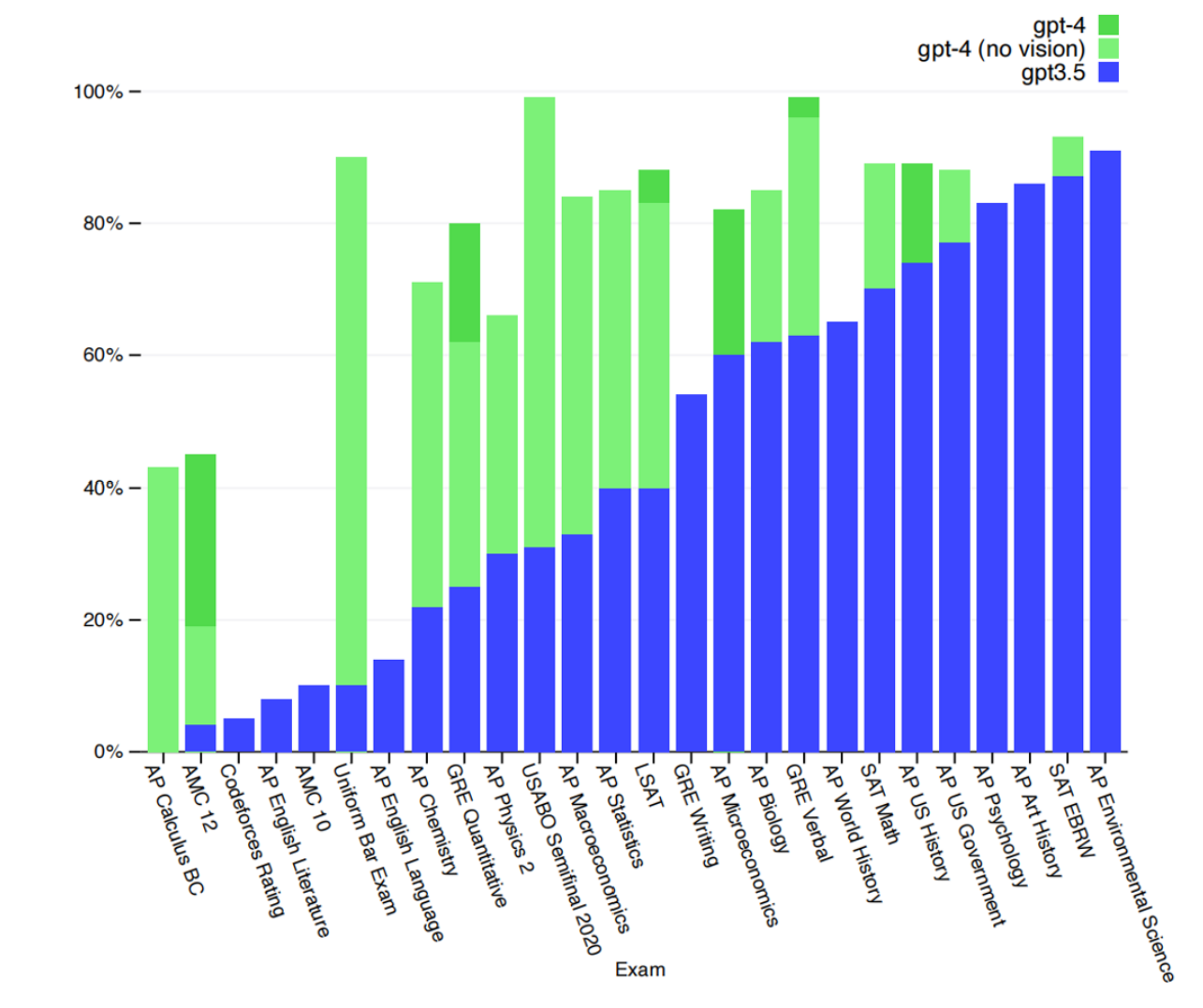
专业推理能力接近人类专家水平,此前的GPT-3只是初步拥有推理能力,但是在许多benchmark上仍不如人类普通从业者,更不用说专家了。但GPT-4一出来就在美国律师资格考试等领域超过大部分人类考生。
-
对齐继续优化,幻觉继续降低
-
采用MoE架构,很反直觉的一点,MoE并不是Deepseek第一次大规模应用的,24年1月Deepseek V1发布,而GPT-4发布于23年7月。但是GPT的MoE是粗糙的标准MoE,就是16个专家每次选两个来推理,共享专家等优化是Deepseek的原创
-
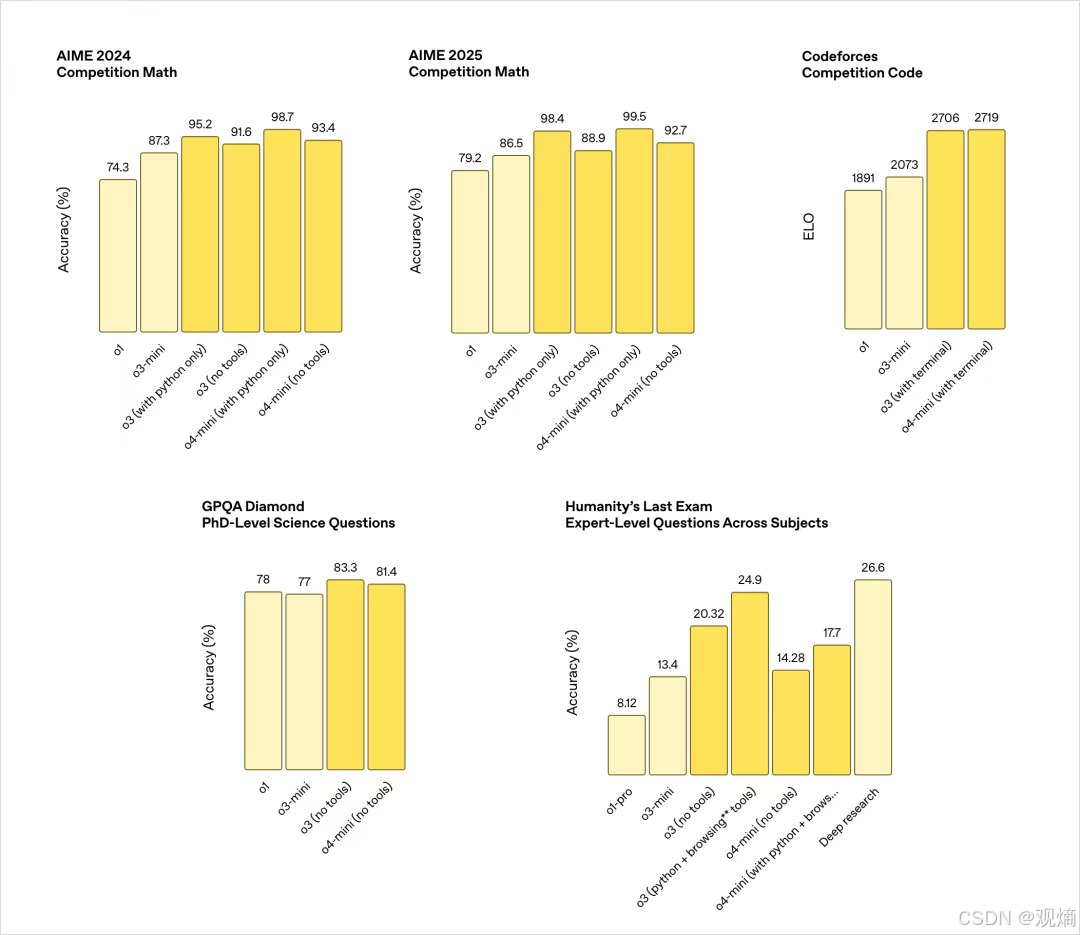
o1引入了思维链,后来大火的Deepseek-R1就是受到了这个的启发,允许模型输出前经过几十秒甚至几分钟的思维链思考,换来更高质量的输出,对于专业推理尤为重要,正是这一代模型在奥数,Codeforces的问题上开始崭露头角,o1的CF分数能达到1600-1900的水平,已经超过CF上80%人类
-
o3继续沿着o1的路线推进,CF分数达到2700(OAI自己宣称的,有一定水分,因为CF题目本身是优质数据,已经包含在模型训练过程中了,以此为bench很容易作弊)
-
随后在 2025 年阿塞拜疆巴库举办的 ICPC World Finals 2025 上,AI(满血o3) 第一次作为“影子参赛者”在真题上进行闭卷盲测,引爆了整个计算机竞赛圈,拿到了12/12的冠军级成绩,吓哭一众算法竞赛选手,顶尖人类选手开始感受到柯洁面对AlphaGO时的感受;
-
此外,在 2025 年 7 月刚刚举行完的 第 66 届 IMO 2025(澳大利亚) 真实比赛中,o3也拿到了35/42分的成绩,压线获得金牌
-
严格来说o3不是4系列的,而是单独开的一个推理系列,但是肯定是在4系列的基础上做的训练,故放在一起。在5推出前的很长一段时间里,OAI都在专注于这个系列的推理模型研发
-
4系列真正的优化主线是4o(omni),意为全能,这版模型原生支持视觉,语音多模态,也就是你可以和他直接麦克风聊天。
-
4o小插曲:4o的语音RLHF训练让其拥有了一定的人格化,相比其他模型更善解人意,以至于后来为了推广gpt5下架4o时还引起了用户抗议。但OAI很快注意到了这一点,认为这很危险,于是在对齐训练做出了修正,GPT5回归了冷静严肃的机器人模式
-
人们开始讨论AGI的诞生,认为GPT-4已经接近AGI,此后这个词成为奥特曼等人吹牛拉投资的惯用口头禅
GPT-5
我们现在的时代。
上下文窗口400K,模型参数保守估计2.5T,最重要的是有了原生的多步规划和任务调用能力,于是在基模之外,另一个赛道开始崛起,也就是Agent,以GPT-5位基模的AI Agent展现出了强大的全流程接管能力,大模型不再只是聊天玩具和数学推理工具,而是第一次开始接管软件开发。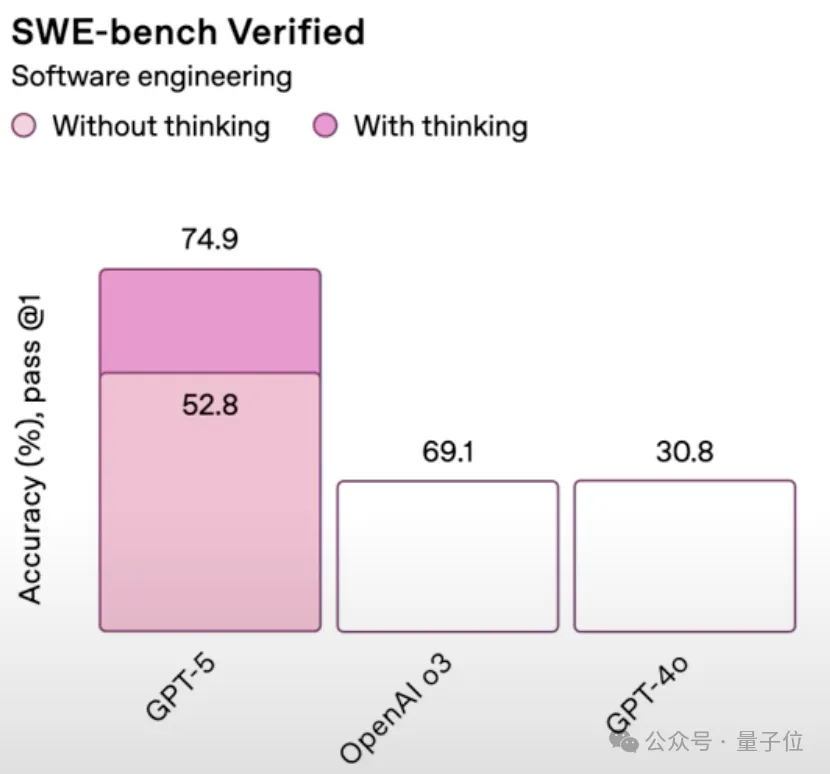

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)