2 小时搞定 RAG 智能客服:Spring Boot + DeepSeek + Qdrant 最小闭环实践
背景
你一定遇到过这种情况——
接了一个 AI 客服需求,老板说"先做个能跑的通",你打开搜索引擎输入「RAG Java 实现」,出来的是满屏的 Python 教程、LangChain 文档、以及各种"你需要先理解 Transformer 架构"。
我只是想写个 Java 项目,把文档灌进向量库,用户提问时检索一下,让 LLM 别瞎编而已。
这就是本文要解决的问题:用最短路径,在 Java 生态里跑通 RAG 检索增强生成的完整闭环。
不需要啃论文,不需要学 Python,不需要折腾模型训练。你只需要三个东西:
- Spring Boot — Java 人都熟
- DeepSeek — 便宜好用的国产大模型
- Qdrant — 一行 Docker 命令就能起的向量数据库
什么是"最小闭环"?
在聊代码之前,先对齐一个概念。
RAG(Retrieval-Augmented Generation)听起来高大上,但它的核心链路其实只有两步:
文档 → 切片 → 向量化 → 存入向量库 (写入管线)用户提问 → 向量化 → 相似检索 → 拼接上下文 → LLM 回答 (检索管线)
所谓的"最小闭环",就是这两条管线都能跑通:你能把文档灌进去,用户提问时能检索到相关内容,LLM 的回答明显优于凭空生成。
下面我以「黑马点评」这个项目为例,一步步拆解每块怎么实现。
架构总览
整个项目由三层组成,结构清晰:
┌─────────────────────────────────────────────┐│ 前端 (Vue.js + Element UI) ││ 客服悬浮窗 / 知识库管理后台 │└─────────────────┬───────────────────────────┘ │ HTTP┌─────────────────▼───────────────────────────┐│ Spring Boot 后端 ││ ┌──────────┐ ┌───────────┐ ┌───────────┐ ││ │ AI Agent │ │ RAG 引擎 │ │ 业务服务 │ ││ │ 五层架构 │ │ 摄取+检索 │ │ 订单/商铺 │ ││ └──────────┘ └───────────┘ └───────────┘ │└──────┬──────────────────┬───────────────────┘ │ │┌──────▼──────┐ ┌────────▼────────┐│ DeepSeek │ │ Qdrant + Ollama││ LLM API │ │ 向量库 + Embed │└─────────────┘ └─────────────────┘
别被"五层 Agent 架构"吓到,核心代码其实很精简。下面我按最小闭环的两条管线来拆解。
写入管线:让 AI 读懂你的文档
这是 RAG 的第一步——把你手头的 Markdown 文档、产品手册、FAQ 变成 AI 能检索的向量。
Step 1:智能切分文档
关键词:Markdown 结构感知切片
普通的文本切分按固定字数一刀切,往往把一段完整内容切得七零八落。我们实现了一个 MarkdownSplitter,它会:
- ✅ 按 H2/H3 标题层级切分,保持语义完整
- ✅ 代码块和 Markdown 表格自动保护(占位符替换后切分,切完再还原)
- ✅ 每个切片携带标题路径,如
帮助中心 > 退款政策 > 申请流程 - ✅ 段落→句子→字符的三级兜底策略

image.png
核心切分逻辑:
// MarkdownSplitter.java — 切分策略由粗到细,尊重文档层级// Step 1: 按 H2 切分 → Step 2: 按 H3 切分 → Step 3: 段落合并// 每个切片自动携带 heading 上下文路径public List<ChunkWithHeadings> split(String markdown) {// 1. 保护特殊块:代码块 + 表格(占位符替换,切完再还原)// 表格保护的关键:匹配 "表头行 + 分隔行(|-|) + 数据行" 的完整结构 Map<String, String> protectedBlocks = new LinkedHashMap<>(); text = protectSpecialBlocks(text, protectedBlocks); // 先代码块,后表格// 2. 按 H2 → H3 递归切分 List<Section> sections = splitByH2(text, docTitle);// 3. 展开为带标题路径的切片 List<ChunkWithHeadings> result = new ArrayList<>();for (Section sec : sections) { result.addAll(flattenSection(sec)); // headingPath: "帮助中心 > 退款" }// 4. 还原被保护的特殊块for (ChunkWithHeadings c : result) { c.text = restoreBlocks(c.text, protectedBlocks); }return result;}
💡 为什么不用现成的 LangChain 文本切分器?因为 LangChain 的
TextSplitter不认识 Markdown 结构。一个 FAQ 文档被切在代码块中间,检索出来的片段就废了。结构化文档必须用结构化切分。
Step 2:一句话完成向量化
切片有了,下一步是把文本变成向量。我们对接 Ollama 的 bge-m3 模型——中文语义理解能力强,1024 维向量,而且 OpenAI 兼容格式,意味着 5 行代码就能切换 provider:
// OpenAiEmbeddingService.java// 调用 Ollama / SiliconCloud / 任何 OpenAI 兼容的 Embedding APIpublic float[] embed(String text) { Map<String, Object> body = Map.of("model", "bge-m3","input", text );// POST → http://localhost:11434/v1/embeddings ResponseEntity<Map> resp = restTemplate.postForEntity(baseUrl + "/embeddings", body, Map.class);// 解析 float[] 返回}
为什么选 bge-m3?实测对中文 FAQ 类内容的检索准确率远高于通用的 text-embedding 模型,而且 Ollama 一键拉起,零配置。
Step 3:一行 Docker 起向量库
向量算出来了,存哪?Qdrant。
# 这就是全部部署工作docker compose up -d
docker-compose.yml 只有 20 行。Qdrant 提供 REST API,意味着你不需要引入任何 Java SDK 依赖。我们用纯 RestTemplate 就写完了整个客户端——集合管理、向量 upsert、相似检索、按来源删除。
// QdrantVectorStore.java — 纯 REST API,零 SDK 依赖public boolean upsert(List<DocumentChunk> chunks) {// POST /collections/{name}/points?wait=true// Body: {"points": [{"id": "...", "vector": [...], "payload": {...}}]}}public List<SearchResult> search(float[] queryVector, int topK, double scoreThreshold) {// POST /collections/{name}/points/search// Body: {"vector": [...], "limit": 5, "score_threshold": 0.3}}
写入管线串联
一条 API 调用,文档就变成了知识库里的向量:
# POST /kb/ingestcurl -X POST http://localhost:8080/kb/ingest \ -H "Content-Type: application/json" \ -d '{"source": "faq", "content": "# 退款政策\n\n## 申请条件\n...", "title": "帮助中心"}'
这条请求背后发生了什么:
文档 Markdown → MarkdownSplitter 切片 → bge-m3 向量化 → Qdrant 存储
至此,写入管线闭环完成 ✅。
检索管线:让 AI 不再胡说八道
Step 4:检索 + 生成 = RAG
写入搞定了,接下来是用户提问时的工作流:
// RetrievalService.java — 检索管线核心public String retrieveAndFormat(String query) {// 1. 用户问题向量化float[] queryVector = embeddingService.embed(query);// 2. Qdrant 余弦相似度检索 Top-5 List<SearchResult> results = qdrant.search(queryVector, topK, scoreThreshold);// 3. 检索结果格式化为 LLM 上下文return formatContext(results); // → "参考以下信息:\n[1] 文档A: ...\n[2] 文档B: ..."}
关键设计决策:分开了检索和格式化。RetrievalService 只负责检索,格式化上下文的方法独立出来,方便后续加缓存、加重排序、加多轮对话的上下文压缩——每个扩展点都是开放的。
Step 5:Agent 工具化调用
在实际业务里,RAG 检索不能只是独立 API,它需要被 AI Agent 按需调用。我们通过 LangChain4j 的 @Tool 注解把它变成了 Agent 工具箱里的一把利器:
// KnowledgeRetrievalTool.java@Tool("从知识库中检索信息。当用户询问平台规则、使用帮助时调用")public String searchKnowledge(String query) {return retrievalService.retrieveAndFormat(query);}
Agent 的 System Prompt 里规定了决策逻辑:
GENERAL_QA → 先调用 searchKnowledge 检索知识库SHOP_INFO → 先调用 searchKnowledge 检索知识库(商家信息、营业时间、评分等)USER_INFO → 先调用 searchKnowledge 检索知识库(账号设置、修改密码等)ORDER_QUERY → 必须调用 queryMyOrders 获取真实订单数据COMPLAINT → 先安抚情绪,记录反馈
LLM 自己决定什么时候调用工具、调用哪个工具——你不需要写 if-else 路由。
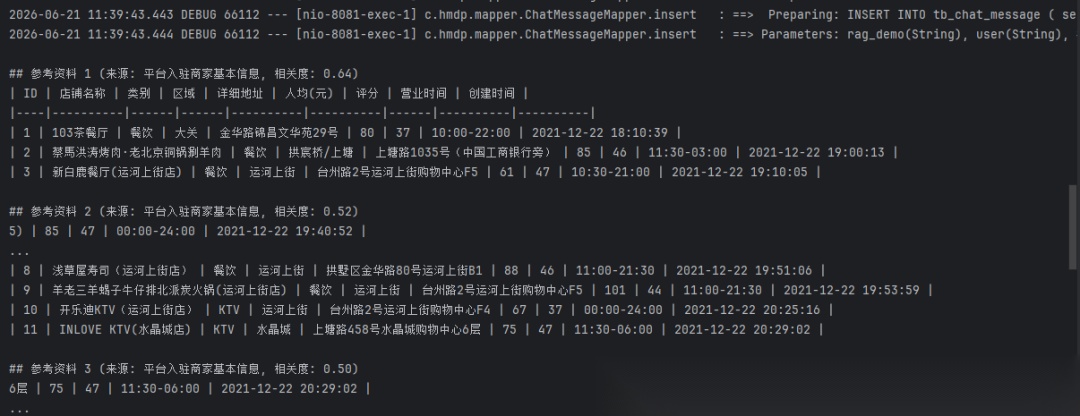
image-2.png
两个关键坑,帮你填了
坑一:DeepSeek 不认 role=function
LangChain4j 0.31 把工具执行结果序列化为 role=function,但 DeepSeek API 只接受 role=tool / system / user / assistant。
症状:Agent 调用了工具,LLM 返回 400 Bad Request。
最初的方案是在 MySqlChatMemory 里把 ToolExecutionResultMessage 转成 SystemMessage,但这只是绕过——工具调用的原始语义丢了,而且 MCP 和未来的 function calling 扩展都受限。
更好的方案:写一个 HTTP 代理。拦截 LangChain4j 发出的 HTTP 请求,在 JSON body 层做正则替换 role=function → role=tool,再转发给 DeepSeek:
LangChain4j → localhost:8081/api/deepseek-proxy/v1 (我们的代理) → replace "role":"function" → "role":"tool" → forward to api.deepseek.com/v1
``````plaintext
// DeepSeekProxyController.java —— 60 行代码的 HTTP 代理@RequestMapping(value = "/**")public ResponseEntity<String> proxy(HttpServletRequest request,@RequestBody(required = false) String body) {// 构造目标 URL:去掉 /api/deepseek-proxy 前缀,拼接真实 DeepSeek 地址String path = request.getRequestURI().replace("/api/deepseek-proxy", "");String targetUrl = realBaseUrl + path + "?" + query;// ★ 核心修复:一行正则替换if (body != null && body.contains("\"role\":\"function\"")) { body = body.replace("\"role\":\"function\"", "\"role\":\"tool\""); }// 添加 API Key,转发请求,原样返回响应 headers.setBearerAuth(apiKey);return restTemplate.exchange(targetUrl, method, new HttpEntity<>(body, headers), String.class);}
为什么代理方案更好?
- 工具调用走标准
role=tool协议,Agent 的 @Tool 能力完整恢复 - 对 LangChain4j 和 DeepSeek 都是透明的——两边都不需要改
- MCP、function calling 等后续扩展不再受兼容性限制
- 只需要在配置里把
deepseek.base-url指向代理:
deepseek:base-url: http://localhost:8081/api/deepseek-proxy/v1 # 指向代理real-base-url: https://api.deepseek.com/v1 # 真实地址
💡 这个代理模式在 Java 生态里通用:当你需要在 API 调用链路中插入轻量级中间层,Spring Boot 的
@RestController+RestTemplate是最轻量的方案。
效果对比
打开 rag-demo.html 页面,你能直观看到 RAG 增强 vs 普通模式的差异:
| 对比维度 | 普通 LLM 模式 | RAG 增强模式 |
|---|---|---|
| 商家信息 | 泛泛而谈,可能是编的 | 引用知识库原文,给到具体信息 |
| 订单查询 | 编造订单号(幻觉) | 通过 Agent Tool 查真实数据 |
| 知识更新 | 必须重新训练/微调 | 重新摄入文档即可 |
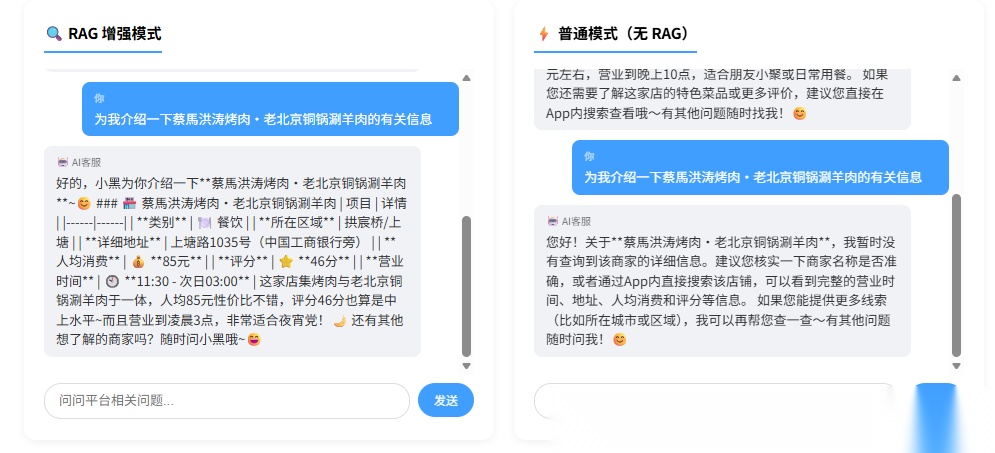
image-1.png
总结
核心要点:
- 最小 RAG 闭环 = 写入管线 + 检索管线,两个管线各 3 步,代码量不超过 500 行 Java
- Markdown 文档必须用结构感知切分——代码块和表格需要占位符保护,普通的字符切分在结构化文档上会翻车
- Qdrant REST API 足够好用,不需要 SDK,RestTemplate 就能写完整客户端
- DeepSeek 与 LangChain4j 的 role=function 兼容问题用 HTTP 代理一劳永逸——拦截请求 → 替换 role → 转发,60 行代码搞定,对上下游完全透明
适用场景:
- 企业知识库问答(FAQ、帮助中心、规章制度)
- 电商客服(商品信息、退换政策)
- 任何"有文档库,需要 AI 基于文档回答"的场景
还没做的事(留给你扩展):
- 检索结果的 Re-rank 重排序(目前直接用余弦相似度排序)
- 多轮对话的上下文压缩(长对话时 token 会爆)
- 增量更新的 Webhook 触发(文档改了自动重新摄入)
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 7
7 0
0- 0



 已为社区贡献421条内容
已为社区贡献421条内容

所有评论(0)