AI Agent Hook 深度解析:概念、用法、优缺点与 AI Coding 实践
- 一句话结论
AI Agent 里的 hook,可以理解为:
在 Agent 工作流程的关键节点,自动触发你预先配置的脚本、HTTP 请求、规则检查或提示逻辑。
它类似后端开发里常见的:
Spring Interceptor
Servlet Filter
AOP Before/After Advice
Git pre-commit / post-commit hook
CI pipeline stage
数据库 trigger
区别是,AI Agent hook 不是拦截普通 HTTP 请求,而是拦截 Agent 的工作生命周期,例如:
用户提交 prompt 前
Agent 调用 shell 命令前
Agent 修改文件后
Agent 请求权限时
Agent 准备结束任务时
上下文压缩前后
子 Agent 启动或结束时
在 AI Coding 场景里,hook 的核心价值是:
把团队工程规范、安全策略、自动校验、上下文注入、日志审计,从“靠人提醒”变成“自动执行”。
- Hook 为什么在 AI Agent 里重要
传统代码助手主要是“补全代码”。现在的 AI Coding Agent 会:
读文件
改文件
运行命令
安装依赖
启动服务
调用 MCP 工具
创建子任务
总结上下文
请求权限
甚至自动提交 PR
这类 Agent 已经有了“执行能力”。只靠 prompt 约束是不够的,因为模型可能:
忘记团队规范
没有运行必要测试
误读项目上下文
执行高风险命令
把敏感信息写入日志或 prompt
在任务没真正完成时就结束
hook 的作用就是在关键节点加上确定性控制。
例如:
PreToolUse:命令执行前检查是否危险
PostToolUse:命令执行后分析结果并注入反馈
Stop:Agent 准备结束时检查是否跑过测试
UserPromptSubmit:用户提交 prompt 时扫描是否包含密钥
SessionStart:会话开始时加载项目约定和上下文
- 通俗理解:Hook 是 Agent 的“自动检查点”
可以把 Agent 的执行流程想象成:
用户提需求
-> Agent 思考
-> Agent 读文件
-> Agent 改文件
-> Agent 跑命令
-> Agent 看结果
-> Agent 决定下一步
-> Agent 总结结束
hook 就是在这些步骤旁边插入检查点:
用户提需求
-> Hook:检查 prompt 是否含密钥
-> Agent 思考
-> Agent 准备跑命令
-> Hook:检查命令是否危险
-> Agent 改文件
-> Hook:改文件后触发 lint/test
-> Agent 准备结束
-> Hook:检查是否有未提交测试失败
所以 hook 不是让模型“更聪明”,而是让 Agent 的执行过程更可控、更工程化。
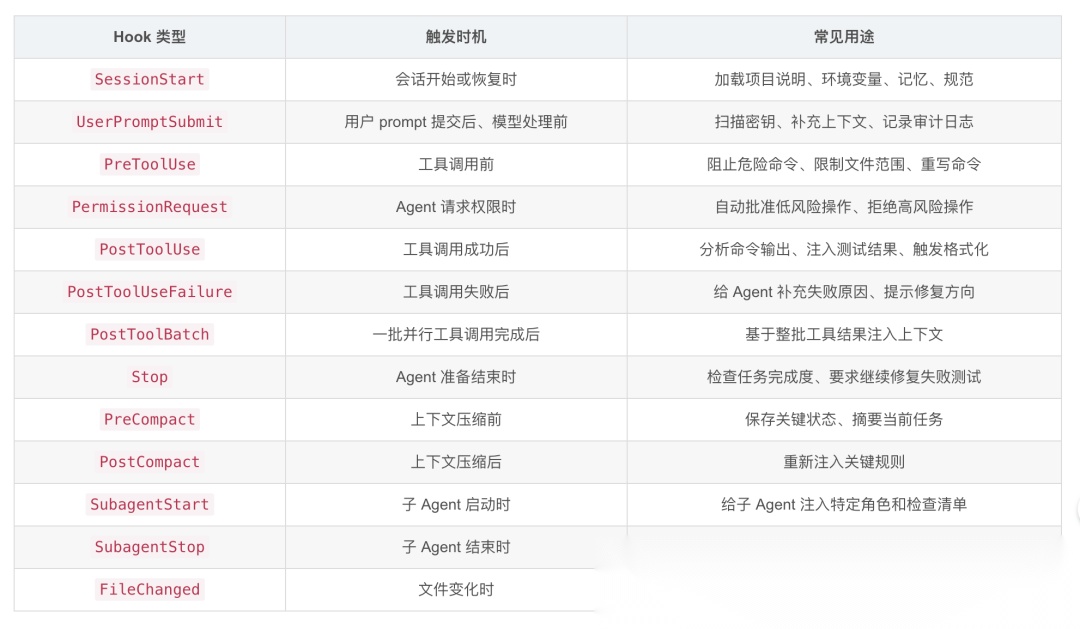
- 常见 Hook 类型
不同 AI Agent 产品命名不完全一样,但常见生命周期大致类似。
- Codex 中的 Hook 实践
5.1 官方定位
OpenAI Codex 文档把 hooks 定义为 Codex 的扩展框架,可以把自定义脚本注入到 agentic loop 中。官方列出的用途包括:
发送会话到日志或分析系统
扫描 prompt,阻止误贴 API key
自动总结会话并形成持久记忆
在对话轮次结束时运行校验
根据目录定制提示
5.2 Codex Hook 的配置位置
Codex 会从这些位置发现 hook:
~/.codex/hooks.json
~/.codex/config.toml
/.codex/hooks.json
/.codex/config.toml
插件也可以携带 hooks。
对团队项目来说,常见做法是:
个人偏好:放 ~/.codex/
项目工程规范:放 /.codex/
企业强制策略:用 managed config / requirements.toml
5.3 Codex Hook 的三层结构
Codex hook 配置通常是三层:
hook event 例如 PreToolUse、PostToolUse、Stop
matcher group 例如只匹配 Bash 或 apply_patch
hook handler 实际执行的命令脚本
示意:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "/usr/bin/python3 \"$(git rev-parse --show-toplevel)/.codex/hooks/pre_tool_use_policy.py\"",
"statusMessage": "Checking Bash command"
}
]
}
]
}
}
5.4 Codex 当前能力边界
截至官方文档当前版本,Codex hooks 需要注意这些边界:
只有 type: “command” 的 handler 会运行
prompt 和 agent handler 目前会被解析但跳过
async 字段会被解析,但异步 command hooks 尚不支持,会跳过 async: true 的 handler
多个匹配 command hooks 会并发启动
非 managed command hooks 需要用户 review 和 trust
PreToolUse 是 guardrail,不是完整安全边界
部分 shell / WebSearch / 非 shell / 非 MCP 路径可能无法完全拦截
这意味着:Codex hook 很适合做工程自动化和安全提示,但不应该被当成唯一的安全隔离层。真正高风险控制仍应依赖:
sandbox
权限审批
受限网络
只读凭证
CI 门禁
代码评审
最小权限
5.5 Codex 的好实践
建议优先做这些 hook:
UserPromptSubmit:扫描密钥、token、生产数据库地址
PreToolUse:拦截 rm -rf、sudo、chmod 777、curl | sh、生产环境命令
PermissionRequest:对低风险命令自动放行,对高风险命令强制拒绝
PostToolUse:命令失败后把错误摘要反馈给 Agent
Stop:没跑测试或测试失败时要求 Agent 继续
SessionStart:加载项目结构、常用命令、代码规范
PreCompact:保存任务进度和关键决策
- Claude Code 中的 Hook 实践
6.1 官方定位
Claude Code 官方文档把 hooks 描述为:在 Claude Code 生命周期特定点自动执行的用户自定义 shell 命令、HTTP endpoint 或 LLM prompts。
参考:Claude Code Hooks reference
https://code.claude.com/docs/en/hooks
Claude Code 的 hook 体系相对丰富,支持:
command hooks
HTTP hooks
MCP tool hooks
prompt-based hooks
agent-based hooks
async hooks
FileChanged / CwdChanged / WorktreeCreate 等更细生命周期
6.2 Claude Code Hook 配置位置
Claude Code 支持多个作用域:
~/.claude/settings.json 用户级,不适合提交
.claude/settings.json 项目级,可提交
.claude/settings.local.json 项目本地,通常 gitignored
Managed policy settings 组织级,管理员控制
plugin hooks/hooks.json 插件级
skill 或 agent frontmatter 组件激活时
这对企业更友好,因为可以区分:
个人自动化
项目规范
本地私有配置
组织强制策略
插件分发能力
6.3 Claude Code 常见 Hook 示例
拦截危险命令:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "${CLAUDE_PROJECT_DIR}/.claude/hooks/block-dangerous-command.sh"
}
]
}
]
}
}
对应脚本逻辑:
#!/usr/bin/env bash
set -euo pipefail
INPUT="$(cat)"
COMMAND="$(printf '%s' "$INPUT" | jq -r '.tool_input.command // ""')"
if printf '%s' "$COMMAND" | grep -Eq 'rm -rf|sudo|chmod 777|curl .* \| sh'; then
jq -n --arg reason "Blocked dangerous command: $COMMAND" '{
hookSpecificOutput: {
hookEventName: "PreToolUse",
permissionDecision: "deny",
permissionDecisionReason: $reason
}
}'
fi
文件写入后异步跑测试:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "${CLAUDE_PROJECT_DIR}/.claude/hooks/run-tests-async.sh",
"async": true,
"timeout": 300
}
]
}
]
}
}
Claude Code 支持 async hooks,但官方也明确说明:异步 hook 不能阻止工具调用或返回控制决策,因为触发动作已经继续执行。
6.4 Claude Code 的安全提醒
Claude Code 官方文档强调:command hooks 会以当前系统用户权限运行,能访问、修改、删除当前用户能访问的文件。官方建议包括:
验证并清洗输入
引用 shell 变量时加引号
阻止路径穿越
使用绝对路径
跳过 .env、.git、密钥等敏感文件
这点非常关键:hook 本身也是代码,也可能成为新的攻击面。
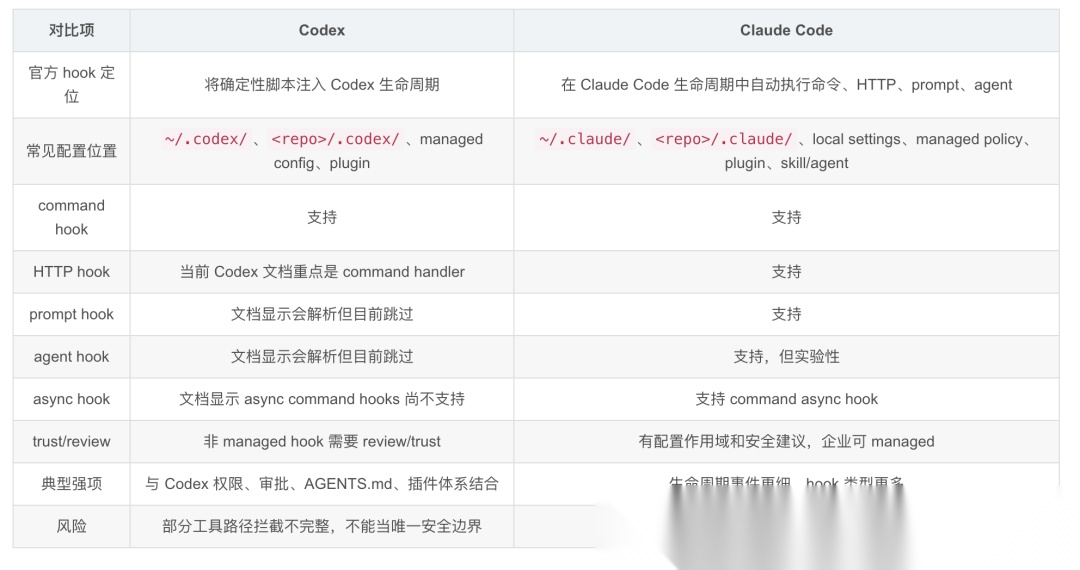
- Codex 与 Claude Code Hook 对比
- Hook 的优点
8.1 把规范变成自动化
原来需要口头提醒:
改完要跑测试
不要动 generated 文件
不要提交 console.log
不要改生产配置
不要直接 rm -rf
hook 可以自动检查。
8.2 降低 prompt 负担
不用每次都在 prompt 里重复:
请遵守项目规范
请运行 npm test
请不要修改 generated 文件
请检查安全问题
这些可以放到 AGENTS.md、rules、hook 里。
8.3 提高安全性
hook 可以在命令执行前拦截:
删除命令
生产环境命令
泄露密钥的 prompt
越权路径写入
可疑网络请求
不允许的 MCP 写操作
8.4 提高结果质量
Stop hook 可以在 Agent 准备结束时检查:
是否还有 failing tests
是否还有 lint 错误
是否有 TODO 没处理
是否修改了不该改的文件
是否文档和实现不一致
让 Agent 自动多跑一轮修复。
8.5 便于审计和观测
hook 可以记录:
谁发起了任务
Agent 执行了哪些命令
哪些权限请求被允许或拒绝
哪些测试失败反复出现
哪些目录最常被 AI 修改
这对团队治理很有价值。
- Hook 的缺点和风险
9.1 配置复杂度上升
hook 太多后,开发者可能不知道:
为什么命令被拦截
为什么 Agent 一直不结束
为什么测试被重复触发
为什么每次都很慢
需要有清晰文档和调试日志。
9.2 性能开销
每次工具调用都跑 hook,可能显著拖慢 Agent。
尤其是:
每次 Edit 后全量 npm test
每次 Bash 后跑安全扫描
每次 Stop 都跑完整 e2e
建议做增量和分层。
9.3 Hook 本身可能有安全风险
hook 接收来自 Agent 的 JSON 输入。如果脚本写得粗糙,可能产生:
命令注入
路径穿越
敏感文件泄露
误删文件
日志泄露 token
9.4 不能替代真正的权限和沙箱
PreToolUse 是 guardrail,不是绝对安全边界。Agent 可能通过其他工具路径达到类似效果,或者某些工具当前不被 hook 拦截。
高风险场景必须依赖:
系统沙箱
最小权限账号
只读凭证
网络隔离
CI/CD 审批
代码评审
密钥扫描
生产环境隔离
9.5 容易过度自动化
hook 不是越多越好。过度 hook 会导致:
Agent 频繁被打断
反馈噪声过大
模型上下文被无关信息污染
开发体验变慢
问题定位困难
- AI Coding 中推荐的 Hook 分层
建议把 hook 分成四层。
10.1 安全层
目标:防止高风险操作。
建议 hook:
UserPromptSubmit:扫描密钥和敏感信息
PreToolUse:拦截危险命令和敏感路径
PermissionRequest:自动拒绝生产环境操作
拦截示例:
rm -rf /
sudo
chmod -R 777
curl | sh
wget | bash
kubectl delete
terraform destroy
aws iam
mysql -h prod
psql production
.env
id_rsa
*.pem
10.2 质量层
目标:让 Agent 改完后自动验证。
建议 hook:
PostToolUse:改代码后跑局部 lint/typecheck
Stop:结束前检查是否跑过测试
PostToolUseFailure:命令失败后给 Agent 注入修复建议
10.3 上下文层
目标:让 Agent 自动获得项目规则。
建议 hook:
SessionStart:加载项目命令、目录说明、近期失败记录
SubagentStart:给子 Agent 注入局部模块说明
PreCompact:保存关键决策
PostCompact:恢复关键规则
10.4 观测层
目标:记录 Agent 行为,方便团队改进。
建议 hook:
UserPromptSubmit:记录任务类型,但脱敏
PostToolUse:记录命令耗时和失败类型
Stop:记录任务是否通过校验
PermissionRequest:记录高风险审批
- 一套适合 AI Coding 的 Hook 改进方案
如果当前项目刚开始引入 AI Coding hook,建议按以下顺序落地。
11.1 第一步:建立项目级 Agent 说明
先写:
AGENTS.md
CLAUDE.md
放这些内容:
项目架构
常用命令
测试命令
代码规范
禁止修改目录
生成文件说明
数据库迁移规则
提交前检查清单
这不是 hook,但它是 hook 的基础。hook 负责执行硬规则,说明文件负责告诉 Agent 怎么做。
11.2 第二步:加危险命令拦截
最先做 PreToolUse。
规则建议:
默认拒绝 rm -rf、sudo、chmod 777、生产库命令
对 curl | sh、wget | bash 直接拒绝
对 .env、密钥、证书路径写入直接拒绝
对包管理 install 提醒或请求确认
11.3 第三步:加 Stop 完成度检查
Stop hook 用来避免 Agent 过早结束。
检查:
是否有未处理测试失败
是否修改了源码但没有运行相关测试
是否有明显 lint/typecheck 失败
是否最终说明中没有写验证结果
如果不满足,让 Agent 继续:
{
“decision”: “block”,
“reason”: “Run the relevant test command and fix any failure before stopping.”
}
11.4 第四步:加轻量局部验证
不要每次全量跑测试。建议:
改前端 TS/Vue:先跑 vue-tsc 或 eslint 相关文件
改后端 Java:先跑对应模块 mvn test 或 gradle test
改 SQL:跑 schema lint 或迁移校验
改文档:不跑重测试
11.5 第五步:加观测和复盘
记录:
Agent 经常失败在哪些命令
哪些 hook 拦截最多
哪些任务经常缺测试
哪些 prompt 容易包含敏感信息
这些数据用于改进 AGENTS.md、测试脚本、项目结构,而不是单纯处罚 Agent。
- 示例:Codex 项目级 Hook 配置
文件:
/.codex/hooks.json
示例:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "/usr/bin/python3 \"$(git rev-parse --show-toplevel)/.codex/hooks/pre_tool_use_policy.py\"",
"timeout": 10,
"statusMessage": "Checking command safety"
}
]
}
],
"PostToolUse": [
{
"matcher": "Bash|apply_patch",
"hooks": [
{
"type": "command",
"command": "/usr/bin/python3 \"$(git rev-parse --show-toplevel)/.codex/hooks/post_tool_use_review.py\"",
"timeout": 30,
"statusMessage": "Reviewing tool result"
}
]
}
],
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "/usr/bin/python3 \"$(git rev-parse --show-toplevel)/.codex/hooks/stop_check.py\"",
"timeout": 30
}
]
}
]
}
}
注意:
Codex 当前 async command hooks 尚不支持。
Codex 当前 prompt / agent handler 会被解析但跳过。
项目本地 hook 需要 review/trust。
- 示例:Claude Code 项目级 Hook 配置
文件:
/.claude/settings.json
示例:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "${CLAUDE_PROJECT_DIR}/.claude/hooks/block-dangerous-command.sh"
}
]
}
],
"PostToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "${CLAUDE_PROJECT_DIR}/.claude/hooks/run-related-checks.sh",
"async": true,
"timeout": 300
}
]
}
],
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "${CLAUDE_PROJECT_DIR}/.claude/hooks/stop-quality-gate.sh",
"timeout": 60
}
]
}
]
}
}
- Hook 脚本编写规范
14.1 输入必须按 JSON 解析
不要用正则粗暴解析 stdin。
推荐:
INPUT=“ ( c a t ) " C O M M A N D = " (cat)" COMMAND=" (cat)"COMMAND="(printf ‘%s’ “$INPUT” | jq -r ‘.tool_input.command // “”’)”
14.2 shell 脚本必须开启严格模式
#!/usr/bin/env bash
set -euo pipefail
14.3 变量必须加引号
错误:
rm -rf $TARGET
正确:
rm -rf “$TARGET”
14.4 路径必须校验
检查:
是否为空
是否包含 …
是否指向 repo 外
是否命中敏感路径
14.5 默认失败策略要明确
对安全 hook:
解析失败时应 fail closed,拒绝高风险操作
对辅助 hook:
解析失败时可 fail open,只记录 systemMessage,避免阻断正常工作
14.6 输出要短
hook 注入给模型的内容不宜太长。
推荐:
只给结论
只给关键错误
只给下一步建议
日志全文写文件,不要塞进模型上下文
- 哪些场景适合用 Hook
适合:
安全拦截
敏感信息扫描
测试门禁
lint/typecheck 自动反馈
项目上下文自动加载
命令审计
Agent 结束前质量检查
子 Agent 角色约束
自动生成任务摘要
不适合:
复杂业务决策
长时间全量构建
需要人工判断的代码评审
生产发布审批的唯一控制
替代 CI/CD
替代权限系统
替代安全沙箱
- Hook 与 CI/CD 的关系
Hook 是开发期或 Agent 运行期的即时反馈。
CI/CD 是合并前或发布前的正式门禁。
两者关系:
Hook:快、早、局部、帮助 Agent 自我修正
CI:慢、正式、全量、保护主干和生产
不要把 hook 当成 CI 的替代品。
推荐组合:
Hook 跑相关测试和快速检查
CI 跑全量测试、安全扫描、构建、部署检查
- Hook 与 AGENTS.md / CLAUDE.md 的关系
AGENTS.md / CLAUDE.md 是说明书。
hook 是执行器。
例子:
AGENTS.md 写:前端改动后运行 npm run build
Stop hook 检查:如果改了 src/**/* 但没运行 npm run build,则要求继续
再比如:
AGENTS.md 写:禁止修改 generated 目录
PreToolUse hook 检查:如果 apply_patch 目标在 generated 目录,则拒绝
两者配合才稳定。
- Hook 改进 AI Coding 的推荐清单
18.1 初级版
添加 AGENTS.md / CLAUDE.md
添加 PreToolUse 危险命令拦截
添加 Stop 测试检查
添加 UserPromptSubmit 密钥扫描
18.2 中级版
按文件类型跑局部测试
改 package.json 后提醒重装依赖
改数据库 migration 后跑 migration 校验
改 API 类型后跑前后端契约检查
记录 Agent 命令失败原因
18.3 高级版
企业 managed hooks
统一 hook 脚本包或插件
hook 事件日志入审计系统
结合 MCP 做代码所有权、工单、PR 检查
根据失败数据自动改进 Agent 指令
Stop hook 接入轻量 eval
- 推荐的最小落地方案
如果只做 3 个 hook,建议做:
- PreToolUse:危险命令和敏感路径拦截
- UserPromptSubmit:密钥和敏感信息扫描
- Stop:任务结束前验证是否跑过必要检查
这三个能覆盖最核心问题:
别乱执行
别泄密
别半成品结束
- 关键注意事项
1.hook 不是银弹。
它能提升 Agent 的可靠性,但不能替代人类 review、CI 和权限隔离。
2.hook 要少而准。
只拦截高价值节点,不要每一步都做重检查。
3.hook 要可解释。
拦截时必须告诉 Agent 和开发者原因,否则会变成黑盒。
4.hook 要可调试。
保留日志,记录输入摘要、匹配规则、输出决策、耗时。
5.hook 要安全编写。
hook 自己就是可执行代码,必须按生产脚本标准写。
- 最终建议
在 AI Coding 中,hook 最佳定位是:
把确定性、重复性、高风险的工程规则自动化。
不要把复杂业务判断全部塞进 hook,也不要指望 hook 完全替代安全边界。
对个人开发者:
用 hook 自动跑检查、提醒测试、阻止危险命令。
对团队:
用项目级 hook 固化工程规范,用 managed hook 固化安全底线,用 CI/CD 兜底。
对企业:
把 hook、权限、沙箱、审计、代码评审、CI 门禁组合起来,形成 AI Coding 的治理体系。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献557条内容
已为社区贡献557条内容

所有评论(0)