一文看懂 Harness 与 Loop Engineering
预计字数:6500 字 阅读时间:22 分钟 难度等级:⭐⭐(小白友好,技术概念有生活类比)
核心价值:搞懂 AI Agent 为什么总崩,以及怎么让它自己跑起来——用真实配置和代码讲清楚 Harness 与 Loop 两层骨架
 模型再聪明,没有外面的这层包裹,长任务里照样会崩。
模型再聪明,没有外面的这层包裹,长任务里照样会崩。
上下文溢出、工具调用一错就雪崩、子代理失控、状态丢失——这些事跟模型智商没关系。
2026年,AI Agent 工程的讨论焦点完成了一次下沉。从"谁的模型分数更高",变成了两个更具体的问题:
- 运行时怎么不崩? 这就是 Agent Harness。
- 怎么让运行时自己跑起来? 这就是 Loop Engineering。
这两个概念一个管内核、一个管调度。
本文用我自己的系统当案例,把这两层骨架拆开讲。读完你能直接对照自己的工具栈,找出缺的那块。
Framework、Harness、Loop:三个词别搞混
 很多人把这三个词混着用。
很多人把这三个词混着用。
最危险的错觉:以为装了个 LangChain 就等于有了完整的 Agent 系统。
先把三层关系定下来。
- Framework(框架):提供标准化积木——Tool 接口、Prompt 模板、编排原语、基础路由。它解决"零件怎么拼"。LangChain、CrewAI、AutoGen 都是框架。
- Harness(运行时):把积木组装成一个能长期运行、自我纠偏、在安全边界内执行的完整系统。状态持久化、沙盒隔离、分层记忆、中断恢复。它解决"拼好之后怎么不崩"。
- Loop(自主循环):跑在 Harness 之上的调度逻辑。替代人工的一次次手动提示,系统自主发现工作、分发任务、验证结果、记录状态、决定下一步。它解决"系统怎么自己运转起来"。
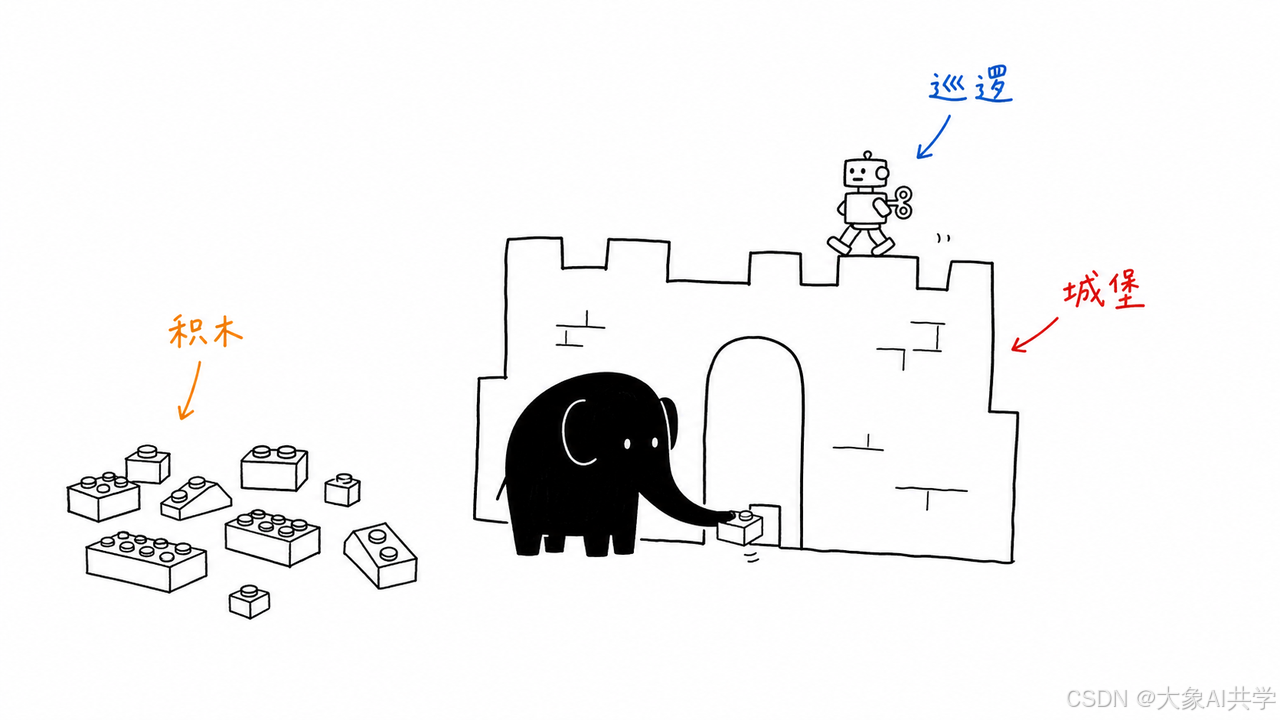
类比:
Framework 是乐高积木。
Harness 是拼好的城堡——有城墙、有门、有结构,不会风一吹就倒。
Loop 是城堡里的自动巡逻机器人——不需要你亲自去巡逻,它自己按路线走。
LangChain 官方自己就把前两层分得很清楚:
LangGraph 是图运行时(Framework),create_agent 是最小 Harness,DeepAgents 是在之上的"全功能 Harness"。
再叠一层 Loop——Claude Code 的 /loop 和 /goal,Codex 的 Automations + Triage Inbox——就构成了 2026 年的完整心智模型。
80% 的生产崩溃,跟模型智商无关
 把一个 Agent 从"Demo 跑通一次"推到"稳定服务",中间隔着一道工程鸿沟。
把一个 Agent 从"Demo 跑通一次"推到"稳定服务",中间隔着一道工程鸿沟。
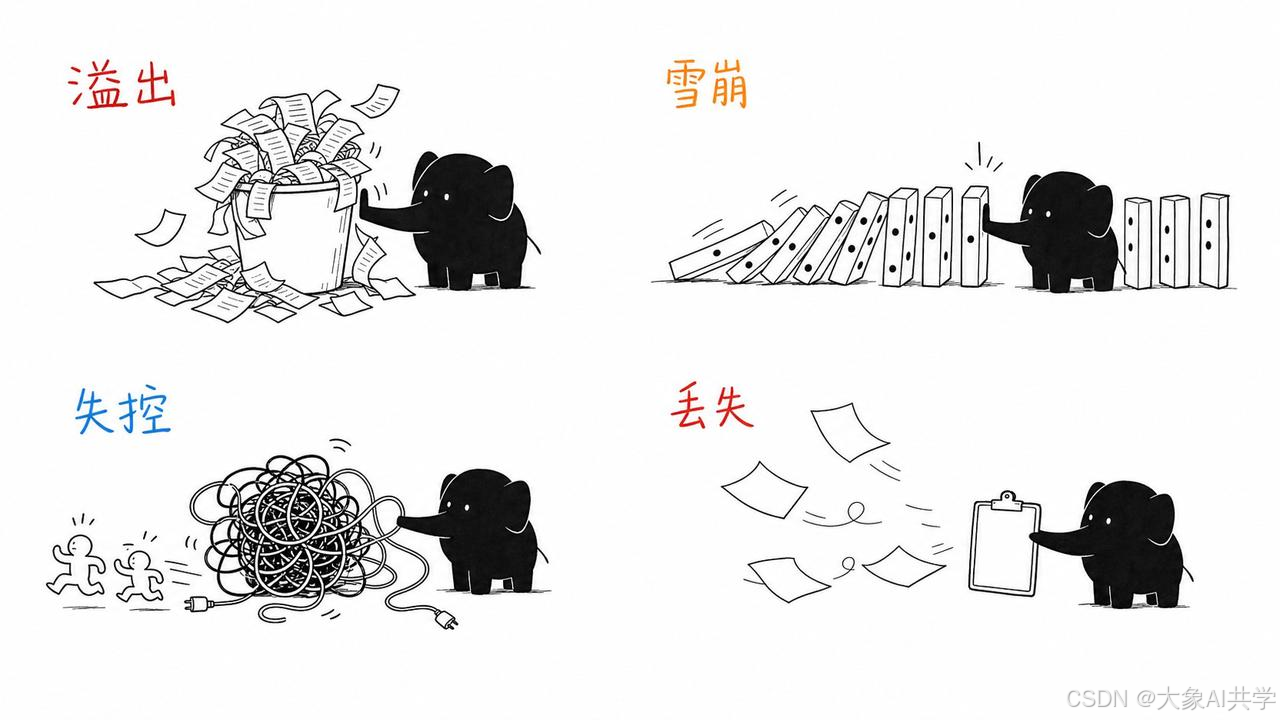
真实环境里的失败,几乎全是四类运行时事故:
- 上下文溢出:对话太长,模型开始"遗忘"前面的内容
- 工具调用雪崩:一个工具报错,后续调用全部跟着错
- 子代理失控:多个 Agent 并行工作,互相不知道对方在干什么
- 状态丢失:进程崩了,所有中间成果归零
这四类问题不是换个更聪明的模型就能解决的。它们是"模型外面那层包裹不够结实"的问题。
我的系统里有一段 YAML 配置,专门对付这些问题:
# ~/.hermes/config.yaml(核心片段)
model:
default: gpt-5.5
provider: openai
agent:
max_turns: 90 # 单轮对话最大工具调用次数,防雪崩
gateway_timeout: 1800 # 网关超时,防无限挂起
api_max_retries: 3 # API 重试次数,工具调用失败自动恢复
tool_use_enforcement: auto # 工具调用失败时的行为策略这几行配置就是在堵四个洞:
max_turns 防上下文无限膨胀,
api_max_retries 给工具调用失败兜底,
gateway_timeout 保证状态不会永远挂着。
但光有配置不够,还需要分层记忆和验证闭环。
Harness 的内核:模型只是中间那个函数
抛开框架差异,一个生产级 Harness 的内核都围绕同一组职责展开。
那篇原文里有句话我特别喜欢:
"模型只是中间那个被反复调用的函数,构成 Agent 的是外面那一圈。"
换框架只是换了那一圈的实现风格。
换模型只是换了中间那个函数。长期能复用、能沉淀的工程资产,全部在外圈。
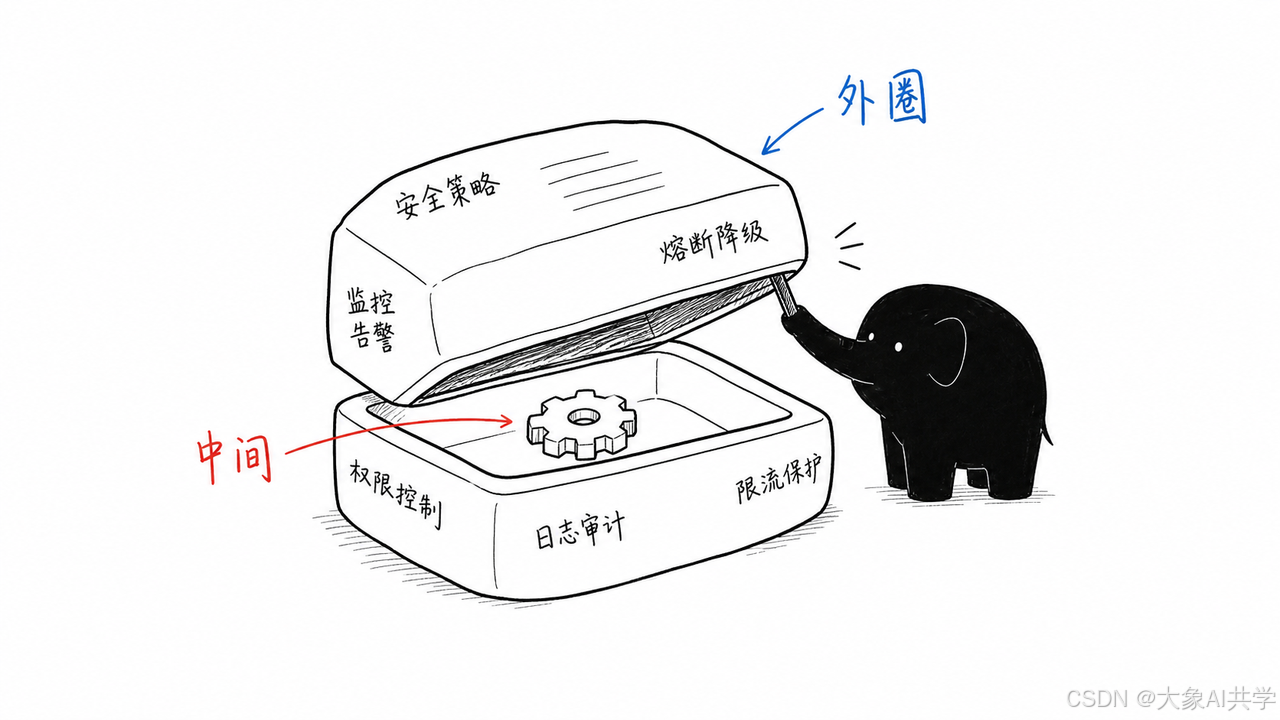 我的系统外圈长什么样?
我的系统外圈长什么样?
直接看我的 AGENTS.md——这是整个 Harness 的"宪法层":
# Core Identity
- 用户:大象
- 工作方式:一人 + AI,高频执行,重结果
- 主事实源:Obsidian 根目录 `/Users/dx/Hermes-agent`
# Core Rules
1. 不虚构案例、数据、经历;不确定就标注不确定。
5. 以 Obsidian 为唯一事实源,避免多份漂移。
10. 任一 Agent 遇到 token 耗尽、限额、skill 失败或网络故障时,
先按 Agent Fallback 机制降级处理,再决定是否切换 Agent。PS:Agent.md 的部分摘录
这是 Harness 的最外层。
模型每次启动都会读它,知道自己是谁、边界在哪、出了事怎么办。
再往里一层,是具体的技能文件。
我有 78 个技能,每个技能是一个 .md 文件:
---
name: obsidian
description: Obsidian 笔记管理 — 读取/搜索/创建 Markdown 笔记
---
# Obsidian Vault
**Location:** Set via `OBSIDIAN_VAULT_PATH` environment variable
## Read a note
```bash
VAULT="${OBSIDIAN_VAULT_PATH:-$HOME/Documents/Obsidian Vault}"
cat "$VAULT/Note Name.md"
这些技能不会一次性全塞进上下文。Agent 决定用哪个技能的时候才加载,用完就丢弃。这就是原文说的 **on-demand skills**。
78 个技能在索引里,活跃上下文任何时候只有 3-5 个。Token 成本跟着实际用到的技能走,不是跟着可用技能数走。
> ❌ 别把上下文窗口当垃圾桶。什么技能都往 Prompt 里塞,模型还没干活就爆了。按需加载不是优化,是让系统能跑起来的前提。
---
## 分层记忆:上下文溢出的头号解药
这是我自己踩过最大的坑。
刚开始用 AI Agent,我觉得信息越多越好。所有背景知识、历史对话、项目文档全部塞进上下文。结果上下文爆了,模型开始忽略前面的指令,越长的任务越不可靠。
后来学了分层记忆。核心思路:**不是所有东西都进 Prompt。**
我的系统把记忆分成三层,每层有独立的生命周期和衰减规则:
```python
# memory_tiered.py 核心结构
# L1 会话摘要:临时性,衰减快(avg_decay_score: 0.83)
# L2 结构化知识:稳定事实,143条,15个分类(avg_decay_score: 0.278)
# L3 核心洞察:长期不变,14条路由规则是这样的:
模型从不直接看到原始分层数据。
由一个 Context Engine 决定每一轮从哪一层取什么、取多少,进模型之前先做压缩。
这套设计强制三条规则,正好对应前面那四类崩溃:
- 预算在进模型之前就算,不是事后救火 → 防上下文溢出
- 只有稳定事实才晋升到长期记忆,噪音不污染语义层 → 防幻觉积累
- 每轮写 checkpoint,崩了从上一次断点继续 → 防状态丢失
做上下文压缩(compact)时,不能用破坏性的纯文本摘要,否则会彻底抹除数据源的引用元数据。
生产级做法是"保留骨架"的结构化压缩,确保模型回答能精准溯源回原始文件。
验证闭环:不要相信 Agent 第一次说"任务完成"
先说一个很多人踩过的坑。
有创作者让 AI 改标题。第一版:"普通人用 AI 翻身,先学会这 4 个循环"——有对象,有钩子。
AI 自查后觉得"不够专业",改到第五版变成了:"关于人工智能应用能力提升的系统性方法研究"。
看起来高级了,实际上没人想点。
这就是为什么验证闭环里必须有人类定义的验收标准。AI 能判断"是否符合规则",但不能判断"改完是不是更差"——品味判断不在它的能力范围内。
验收标准不是写得好一点这种模糊要求,而是机器可自查、人类可复判的具体规则——比如标题有没有具体收益正文有没有空话套话读完知不知道下一步。标准越具体,AI 越不需要猜,你越不需要盯。
 如果只能从这篇文章带走一条实践,就是这条。
如果只能从这篇文章带走一条实践,就是这条。
大量"看起来跑通了、其实留了一地破绽"的事故,都源于缺少一个独立的校验回路。
我的系统有一个"一票否决三问"机制——每篇文章写完后必须回答:
- 1. 用户为什么要读完这篇文章?
- 2. 读完后能得到什么?
- 3. 有没有分享出去的欲望?
三点任一答不上来,一票否决,重写。
这是在内容创作场景的验证闭环。
代码场景也一样——DeepAgents 的安全模型精神内核是:边界要在 tool/sandbox 层强制,不是指望模型自我约束。
"自认为完成"和"被证据证明完成"是两回事。执行和验证不能是同一个 Agent。
Loop Engineering:让 Harness 自己跑起来
先用一个生活类比把 Loop 说透。
你家的洗衣机不会每 5 分钟弹出来问你"现在进水吗""现在搅拌吗"。你选一个模式,它自己走完:进水 → 搅拌 → 排水 → 甩干 → 结束。
Loop Engineering 就是给 AI 选洗衣模式。
一个最小 Loop 只有 5 个环节:目标(交付什么)→ 步骤(按什么顺序)→ 执行(做第一版)→ 检查(对照验收标准自查)→ 修正(不合格就改,合格就停)。
Prompt Engineering 解决怎么问,Loop Engineering 解决怎么做完。
以我自己的系统举例:我的"每日记忆蒸馏"Loop,每天凌晨 2 点触发,脚本自动扫描当天会话、蒸馏 L1 为 L2、晋升 L2 为 L3,3:10 同步到 Obsidian。整个过程不需要我坐在键盘前写任何 Prompt——cron 是触发器,memory_tiered.py 是执行引擎,L1/L2/L3 文件是外部记忆,脚本退出码是退出条件。一个完整的 5 环节闭环。
Harness 解决了"怎么不崩"。但谁来按下开始键?谁来决定下一步?
2025 年之前,这件事全靠人——坐在键盘前一次次写 Prompt。
2025 年下半年开始,社区共识变了:
不要手动提示 Agent,去设计循环来提示它。
Anthropic Claude Code 负责人 Boris Cherny 说他已经不再直接提示 Claude 了——他写循环,由循环去提示 Claude 并决定下一步。
Google 的 Addy Osmani 给的定义更直白:Loop Engineering 就是用系统取代你自己去提示 Agent。
更早的源头是 2025 年 Geoffrey Huntley 提出的 Ralph Loops——一个最朴素的 bash while 循环 + 一次只做一个任务 + 每轮全新上下文。极低成本,却完成了原本要外包数万美元的活。
循环本身比模型更重要。
好模型配差循环,得到的是昂贵的垃圾。普通模型配上优秀循环和强验证,才能稳定出货。
我的 33 个 Loop:真实系统长什么样
 概念讲完了,直接看我的系统。
概念讲完了,直接看我的系统。
我每天有 33 个定时任务在后台跑。每一个都是一个 Loop。我不用手动触发任何一个。
先看最核心的几个:
每日记忆蒸馏——每天凌晨 2 点自动触发:
# 每日凌晨 2:00 执行
python3 /Users/dx/Hermes-agent/memory/memory_tiered.py这个脚本自动扫描当天所有会话,把高价值的 L1 摘要蒸馏为 L2 结构化知识,把经过时间验证的 L2 晋升为 L3 核心洞察。每天 3:10 再把记忆同步到 Obsidian。
这是 Loop 六大组件的实际映射:
- 触发器:cron 定时
- 隔离:独立进程,独立上下文
- 技能:memory_tiered.py(蒸馏逻辑)
- 连接器:读写 SQLite + 写入 Obsidian
- 子代理:蒸馏、压缩、清理各是一个子脚本
- 外部记忆:L1/L2/L3 三层 SQLite + Obsidian md 文件
- 退出条件:脚本执行完毕(成功/失败都有日志)
再看一个更复杂的:系统健康巡检——每 5 分钟一次:
这个 Loop 的逻辑是:
检查 Gateway 进程是否存活 → 如果挂了自动重启 → 检查 WebSocket 连接 → 检查密钥池健康度 → 生成健康报告。任何一个检查点失败都有对应的自动恢复逻辑。
这就是原文说的 Plan-Execute-Verify Loop 的变体:发现异常 → 执行修复 → 验证结果。
还有内容运营方向的 Loop:
- 每天早上 5 点自动执行"创作雷达"——扫描竞品内容、分析公众号数据基线、生成选题建议
- 每周一早上 6:30 生成"每周创作策略"——基于上周数据驱动决策
- 每周二早上 9 点采集竞品内容
这些 Loop 覆盖了五大领域:
| 领域 | Loop 数量 | 举例 |
| 记忆管理 | 12 | 蒸馏、压缩、清理、衰减、统计、同步、索引 |
| 系统监控 | 5 | 健康检查、验证、备份、日志 |
| 内容运营 | 6 | 选题雷达、竞品采集、创作策略、数据提醒 |
| 知识沉淀 | 5 | 周总结、月归档蒸馏、知识图谱、Skill 审计 |
| 自动化维护 | 5 | Obsidian 清理、AI 新闻归档、Vault 检查 |
每加一个 Loop,我需要盯着屏幕的时间就少一点。
动手搭建你的第一个 Loop
我的建议:从一个最小可用的 Loop 开始,不要追求一步到位。
我最早的 Loop 只有一个:每天凌晨写日报。
一个 cron 脚本,触发一次对话,生成总结,写入文件。
然后加了记忆管理。再加了系统监控。再加了内容运营。
每一步都是在踩坑之后才明白为什么需要。
推荐从一个日常维护 Loop 起步。
你不需要 Claude Code,任何能跑脚本的环境都行:
第一步:创建你的 AGENTS.md(核心规则文件)。
这是 Harness 的"宪法层"。把你的项目规则、工具用法、边界写进去。
第二步:创建一个 PROGRESS.md(状态文件)。
这是 Loop 的外部记忆。记录"已尝试什么、测试结果、开放项、下一步"。
第三步:写一个最简单的 Loop 脚本。
比如:每天自动扫描你电脑上的笔记文件夹,把超过 30 天没更新的笔记列出来。
这就是一个完整的 Loop——有触发器(cron)、有技能(扫描脚本)、有外部记忆(笔记文件夹)、有退出条件(脚本跑完)。
第四步:加验证。让脚本不只列出旧笔记,还要检查每个笔记是否有 TODO 项,只报告有未完成 TODO 的。
这就是一个 Plan-Execute-Verify Loop 的雏形。
避坑清单:这些弯路我替你走了
原文总结的避坑清单,每一条我都踩过:
必须做的:
- 明确退出条件。不要让循环"一直跑到有人干预"。我的每个 cron 都有超时和日志
- Maker-Checker 分离。执行和验证不能是同一个 Agent。我的内容创作是"写作 Agent + 一票否决三问"
- 严格上下文管理。用外部文件而不是无限聊天历史。我的三级记忆就是这个思路
- 成本监控。无 guardrail 的循环很容易烧钱。我的 max_turns: 90 就是硬预算
- 从小而窄的任务入手。先做"每日笔记扫描",再做"全自动内容生产"
- 人类在环。生产变更和架构决策保留人工 checkpoint
常见失败模式:
- 目标模糊 → Agent 反复猜测,token 爆炸
- 缺少退出条件 → 无限循环
- 验证太弱 → 大量低质量输出进主分支
- 忽略并行隔离 → 文件冲突或状态损坏
- 把所有事都 Loop 化 → 吞掉需要人类创造力的部分
最后一条我特别有感触。我的实践是:Loop 负责把任务推到 90% 完成,最后 10% 留给人精炼。
四类失败,你能在自己的栈里对号入座吗
 回到那四类生产崩溃。问自己四个问题:
回到那四类生产崩溃。问自己四个问题:
- 你的系统有上下文管理吗? 对话太长的时候,有没有机制压缩、卸载、检查点?没有 → 上下文溢出迟早发生。
- 你的系统有工具失败恢复吗? 一个 API 调用超时了,Agent 知道重试还是换路吗?不知道 → 工具调用雪崩。
- 你的系统有子代理隔离吗? 多个 Agent 并行的时候,有没有独立的工作空间?没有 → 子代理失控。
- 你的系统有状态持久化吗? 进程崩了,中间成果还在吗?不在 → 状态丢失。
如果你无法在自己的栈里为这四条各指出一个具体模块,那你手里的是 Demo,不是生产系统。
回头看,过去三年 AI 工程的演化有一条清晰的脉络:
2023 年我们在学怎么写 Prompt,2024 年我们在学怎么编排 Agent,2025 年我们在学怎么给 Agent 加一层运行时,到 2026 年,我们终于在学习怎么让这个运行时自己跑起来。
每一次跃迁,都是把"人需要亲自做的事"往外推一层。
这个过程里,模型一直是最受关注的部分,却也是最不属于你的部分。
属于你的,是你给模型套上的那个 Harness——它决定了你的系统在长任务面前会不会原地崩。
以及你架在 Harness 之上的那个 Loop——它决定了你需不需要 24 小时盯着屏幕。
这两层加在一起,才是你可以累积、可以交接、可以变成护城河的工程资产。
模型每周都在变强,但能让强模型变成可靠产出的,从来都不是模型本身。
 既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果可以给我个星标⭐,将不胜感激~谢谢你看我的文章,我们,下次再见。
既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果可以给我个星标⭐,将不胜感激~谢谢你看我的文章,我们,下次再见。
#Harness #Loop Engineering #AI Agent #大象AI共学
作者:大象-推动 AI 共学,让普通人轻松上手AI
相关链接
- 1. 社群站:https://daxiangnaoyang.github.io/daxiang-ai-gongxue/
- 2. Addy Osmani - Loop Engineering(开创性框架文章)
- 3. Geoffrey Huntley - everything is a ralph loop(Ralph Loops 起源与哲学)
- 4. Cobus Greyling - Loop Engineering Playbook(实战 playbook)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)