Apache Doris 4.0 AI 函数实战:SQL 直连 DeepSeek 等主流大模型完整落地排坑教程
AI 概述
Apache Doris 是一款高性能、实时分析型数据库,深度融合文本搜索、向量搜索、AI 函数与 MCP 智能交互能力,构建从数据存储、检索到分析的完整 AI 数据栈,为 AI 应用提供一体化的数据基础设施。
下表列出常见 AI 场景与 Doris 提供的对应能力,帮助快速定位适合的方案。
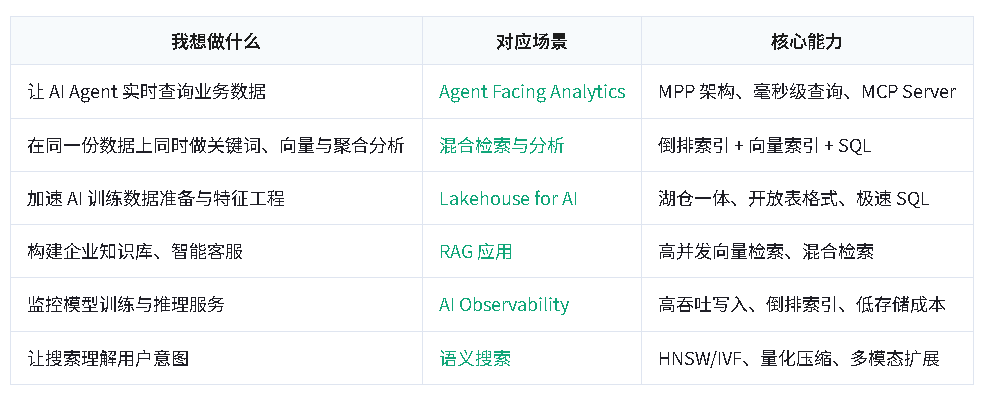
Agent Facing Analytics
随着 AI Agent 技术兴起,越来越多的分析决策由 AI 自动完成,这要求数据平台具备极致的实时性与高并发能力。与传统"人工分析"不同,Agent Facing Analytics 需要在毫秒级完成数据查询和决策,支持海量 Agent 的并发访问。典型场景包括实时反欺诈检测、智能广告投放、个性化推荐等。
Doris MCP Server :类似于给 Agent 提供工具的。Agent 只需要告诉 doris 你需要做什么,它就会选择性的执行某个工具。
Hybrid(混合) Search and Analytics Processing
结构化查询,非结构化查询,以及文本查询 多种组合均支持。
结构化数据: 有行有列的数据
非结构化数据:数据不是按照行,列这种存储 json(半结构化)
Lakehouse(湖仓一体) for AI
AI 模型与应用开发需要从海量数据中准备训练集、进行特征工程、评估数据质量,传统架构往往需要在数据湖和分析引擎间频繁迁移数据。Lakehouse 架构将数据湖的开放存储与实时分析引擎深度融合,在统一平台上支撑数据准备、特征工程与模型评估的全流程,消除数据孤岛,加速 AI 开发迭代。
只用一份原始数据存在数据湖上,不用复制迁移,分析引擎(Doris 这类仓库引擎)直接读取湖上的数据做高速查询,一套存储兼顾 “海量存储”+“极速分析”。
数据仓库:存储各种文本数据,只是数据来源比较多,比如 mysql oracle redis 日志 将多个项目中的数据全部导入进来,进行数据分析
数仓湖: 结构化(库表)、半结构化(JSON/CSV/Parquet)、非结构化(图片、音视频、日志、文档)全部兼容 这个概念比数据仓库大
做数据湖比较有名的技术有Iceberg、Paimon(火)
架构特性:
- 湖仓一体:基于开放湖表格式(如 Iceberg、Paimon 等)和 Catalog 构建开放湖仓,统一管理分析数据与 AI 数据
- 极速 SQL 引擎:Doris 作为实时分析引擎,支持交互式查询与轻量级 ETL,为数据准备和特征工程提供高效的 SQL 计算能力
- 无缝数据流转:直接读写数据湖,无需数据搬迁,存储层统一管理,计算层灵活加速
RAG(Retrieval-Augmented Generation)
RAG = 大模型+ 外部数据库(doris)
RAG 通过从外部知识库检索相关信息为大模型提供上下文,有效解决模型幻觉与知识时效性问题。向量引擎是 RAG 系统的核心组件,需要在海量知识库中快速召回最相关的文档片段,同时支持高并发的用户查询请求,确保应用响应体验。
典型应用:
- 企业知识库:基于内部文档、手册构建智能问答系统,员工通过自然语言快速获取准确答案
- 智能客服助手:结合产品知识库与历史案例,为客服人员或聊天机器人提供精准的回复建议
- 智能文档助手:在大规模文档集合中快速定位相关内容,辅助研究、写作与决策过程
Doris 构建 RAG 的优势:
- 高并发性能:分布式架构支持高并发向量检索,轻松应对大规模用户并发访问
- 混合检索能力:在单条 SQL 中同时执行向量相似度搜索与关键词过滤,兼顾语义召回和精确匹配
- 弹性扩展:随集群扩容线性提升检索性能,从百万到百亿级向量无缝平滑过渡
- 一体化方案:统一管理向量数据、原始文档与业务数据,简化 RAG 应用的数据架构
AI Observability(可观察性) 【之前这个功能是 ELK 干的】
将 AI 运行或者训练中产生的大量日志存储到 doris 中,便于后期观察或者排错,定位问题
AI 模型训练迭代与应用运行过程中会产生海量日志、指标和追踪数据。为精准定位问题、持续优化性能,可观测性系统成为 AI 基础设施的关键一环。随着业务规模扩张,可观测平台面临 PB 级数据的高吞吐写入、毫秒级检索响应和成本控制的多重挑战。
典型用例:
- 模型训练监控:实时追踪训练指标、资源消耗,快速定位训练异常与性能瓶颈
- 推理服务追踪:记录每次推理请求的完整链路,分析延迟来源与错误模式
- AI 应用日志分析:海量应用日志的全文检索与聚合分析,支持故障排查和行为洞察
Semantic(语义) Search
语义搜索通过向量化技术捕捉文本深层含义,即使查询词与文档用词不同,也能召回语义相关的内容。这对跨语言检索、同义词识别、意图理解等场景至关重要,可显著提升搜索的召回率和用户体验。
语义搜索的意思是:使用自然语言,搜索相关的数据
之前这个事情是问的大模型的产品,比如 deepseek,豆包+数据库
现在是 doris 集成了大模型
典型用例:
- 企业文档检索:员工用自然语言描述问题,系统理解意图后从海量文档中召回语义相关的政策、流程与知识
- 电商商品搜索:用户输入"适合夏天穿的透气鞋子",系统理解需求并召回相关产品,而非仅匹配关键词
- 内容推荐平台:基于文章、视频的语义相似度进行智能推荐,发现用户可能感兴趣但用词不同的内容
Doris 构建语义搜索的优势:
- 高性能向量检索:支持 HNSW 与 IVF 算法,亿级向量亚秒级响应,轻松应对大规模语义搜索需求
- 混合检索增强:单条 SQL 融合语义搜索与关键词过滤,在召回语义相关内容的同时确保必要词汇命中
- 多模态扩展:不仅支持文本语义搜索,还可扩展至图片、音频等多模态内容的语义检索
- 灵活量化优化:通过 SQ/PQ 量化技术,在保证检索精度的前提下大幅降低存储和计算成本
AI 函数
什么是 Doris AI 函数
Apache Doris 4.0 重磅推出原生 AI 函数(AI Function),是数据库内置的一类特殊 SQL 函数,核心能力:直接在 SQL 语句内部调用外部大语言模型(LLM),完成各类非结构化文本智能分析,无需把数据导出到 Python、Java 等外部程序做中转处理,真正实现「数据分析 + AI 处理」同一条 SQL 闭环执行Apache Doris。
传统文本 AI 处理链路:Doris 导出数据 → 外部服务调用大模型 API → 结果写回 Doris,链路冗长、数据一致性差、网络开销高、运维复杂; Doris AI 函数新模式:一条 SQL 完成查询 + AI 计算,消除数据来回搬运,简化整个数据智能分析架构。
官方原生支持 10 类大模型厂商
OpenAI、Anthropic、Gemini、DeepSeek、Local 本地模型、MoonShot 月之暗面、MiniMax、Zhipu 智谱、Qwen 通义千问、Baichuan 百川; 若自定义模型兼容 OpenAI 协议格式,也可快速适配接入Apache Doris。
内置 AI 函数能力清单
Doris 预置十余种开箱即用的 AI 语义函数,覆盖绝大多数文本处理场景:
shi'li
| 函数名称 | 核心作用 |
|---|---|
AI_SENTIMENT |
情感分析,判断文本正负向情绪 |
AI_CLASSIFY |
文本分类,匹配预设标签归类 |
AI_EXTRACT |
关键信息抽取(姓名、手机号、地址等) |
AI_SUMMARIZE |
长文本智能摘要 |
AI_TRANSLATE |
多语言翻译 |
AI_FIXGRAMMAR |
文本语法纠错 |
AI_SIMILARITY |
两段文本语义相似度打分 |
AI_FILTER |
自定义语义条件过滤,返回布尔值 |
AI_MASK |
敏感信息脱敏打码 |
AI_GENERATE |
自定义指令生成内容 |
AI_AGG |
多行文本聚合式 AI 分析 |
案例
步骤一:首先要先创建AI资源
CREATE RESOURCE 'deepseek_example3'
PROPERTIES (
'type' = 'ai',
'ai.provider_type' = 'deepseek',
'ai.endpoint' = 'https://api.deepseek.com/chat/completions',
'ai.model_name' = 'deepseek-chat',
-- 输入自己的密钥
'ai.api_key' = 'xxxxxx'
);步骤二:设置默认资源
此处设置的名字一定要和上面创建的资源名字吻合
SET default_ai_resource = 'deepseek_example3';步骤三:下载CA 证书
要在每一个安装BE和FE的节点上都下载
curl https://curl.se/ca/cacert.pem -o /etc/ssl/certs/ca-certificates.crt
chmod 644 /etc/ssl/certs/ca-certificates.crt一定要下载,否则会报错如下错误
ERROR 1105 (HY000): errCode = 2, detailMessage = (hadoop12)[HTTP_ERROR]error setting certificate verify locations: CAfile: /etc/ssl/certs/ca-certificates.crt CApath: none, url=https://api.deepseek.com/v1/
步骤四:测试案例
示例一:候选人简历与岗位需求的语义匹配
CREATE TABLE candidate_profiles (
candidate_id INT,
name VARCHAR(50),
self_intro VARCHAR(500)
)
DUPLICATE KEY(candidate_id)
DISTRIBUTED BY HASH(candidate_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE job_requirements (
job_id INT,
title VARCHAR(100),
jd_text VARCHAR(500)
)
DUPLICATE KEY(job_id)
DISTRIBUTED BY HASH(job_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO candidate_profiles VALUES
(1, 'Alice', 'I am a senior backend engineer with 7 years of experience in Java, Spring Cloud and high-concurrency systems.'),
(2, 'Bob', 'Frontend developer focusing on React, TypeScript and performance optimization for e-commerce sites.'),
(3, 'Cathy', 'Data scientist specializing in NLP, large language models and recommendation systems.');
INSERT INTO job_requirements VALUES
(101, 'Backend Engineer', 'Looking for a senior backend engineer with deep Java expertise and experience designing distributed systems.'),
(102, 'ML Engineer', 'Seeking a data scientist or ML engineer familiar with NLP and large language models.');下面的命令需要在进入到doris中运行(命令行)
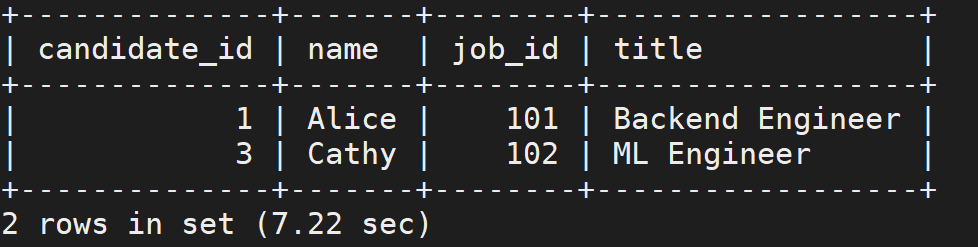
SELECT
c.candidate_id, c.name,
j.job_id, j.title
FROM candidate_profiles AS c
JOIN job_requirements AS j
WHERE AI_FILTER(CONCAT(
'Does the following candidate self-introduction match the job description?',
'Job: ', j.jd_text, ' Candidate: ', c.self_intro
));运行结果:
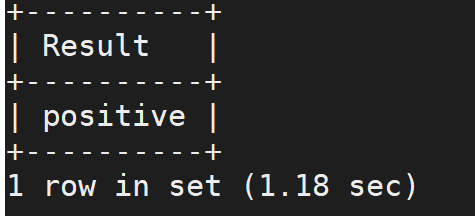
示例二:分析文本的情感倾向
SELECT AI_SENTIMENT('Apache Doirs is a great DB system.') AS Result;运行结果为:
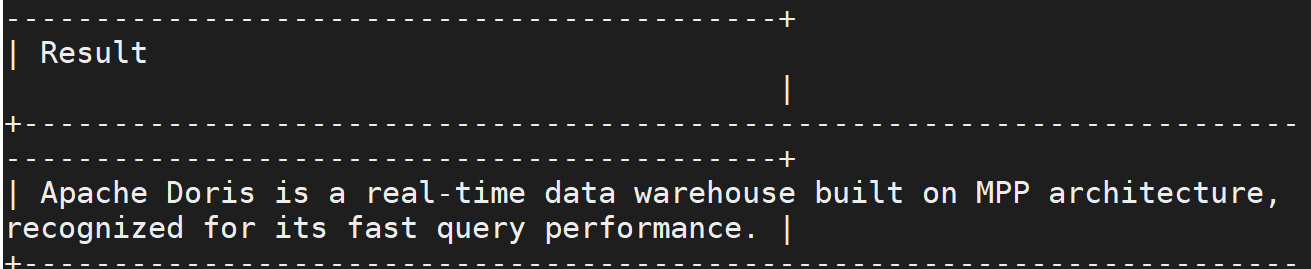
示例三:生成文本的简明摘要
SELECT AI_SUMMARIZE('Apache Doris is an MPP-based real-time data warehouse known for its high query speed.') AS Result;结果为:
示例四:将文本翻译为特定语言
SELECT AI_TRANSLATE('In my mind, doris is the best databases management system.', 'zh-CN') AS Result;运行结果

对于以上的所有示例,结果是由大模型生成,所以不是所有人的结果都一摸一样。
真实业务拓展
电商平台:商品评论智能分析体系
电商平台每天会产生海量买家评价、追评、差评内容,传统只能依靠关键词模糊检索,无法识别深层情绪与问题类型。借助 Doris AI 函数,可直接在数仓内完成全量评论智能化处理:
- 使用
AI_SENTIMENT自动判定每条评论正向 / 中性 / 负向情感,快速统计商品差评率、好评占比; - 通过
AI_CLASSIFY自动归类差评原因:物流慢、质量瑕疵、尺码不符、客服问题、价格问题等; - 利用
AI_EXTRACT自动提取评价里关键信息,比如色差、掉毛、异味、破损等具体问题关键词; - 结合
AI_SUMMARIZE按月聚合批量评论,生成商品整体口碑摘要,供给运营、产品迭代参考。 整条分析链路全部通过 SQL 完成,无需导出数据对接外部 Python 脚本,实时同步分析当日新增评价,支撑商家及时调整商品、优化售后策略。
客服工单智能治理
企业客服系统每日沉淀大量用户咨询工单、投诉记录,人工分拣归类效率低下。基于 Doris AI 函数搭建自动化工单处理方案:
- 调用
AI_CLASSIFY将咨询内容自动划分:订单查询、退款售后、活动咨询、投诉维权、产品使用问题等类目; - 使用
AI_SUMMARIZE精简大段用户描述,压缩成简短问题摘要,减少坐席阅读耗时; - 通过
AI_FILTER自动识别高危投诉、情绪激烈内容,设置加急标记优先流转处理; - 批量汇总周期性高频问题,辅助运营梳理 FAQ 知识库,优化自助问答页面,降低人工客服进线量。
政企内容合规与敏感信息脱敏
政务、传媒、互联网内容平台存在大量文案、公告、用户发帖、表单填报文本,需要常态化内容审核与隐私脱敏:
AI_MASK对文本中的手机号、身份证号、银行卡、住址等隐私信息自动脱敏打码,满足数据安全合规要求;- 自定义 Prompt 搭配
AI_FILTER实现违规内容筛查,识别涉敏、广告引流、辱骂类内容,自动标记拦截; - 借助
AI_TRANSLATE完成多语种内容翻译,适配多地区业务内容统一审核。 数据入库即完成智能校验,不用额外部署独立审核服务,降低系统架构复杂度。
人力资源简历智能筛选
企业招聘场景简历量大,HR 人工筛选匹配岗位效率极低,复用本文简历匹配案例做规模化落地:
- 简历信息入库后,使用
AI_EXTRACT自动抽取工作年限、技术栈、项目经验、学历等结构化字段; - 通过
AI_FILTER输入岗位 JD 要求,自动判断简历与岗位匹配度,筛选符合门槛候选人; - 使用
AI_SIMILARITY计算简历描述与岗位需求语义分值,实现高分优先排序,大幅缩减 HR 筛选工作量; - 批量汇总候选人技能分布,辅助人力部门复盘招聘渠道质量、人才供给趋势。
线下门店 / 外卖差评归因分析
外卖、连锁零售门店积累海量用户打分评价,可直接在 Doris 中做实时经营分析:
- 情感分析区分差评订单,定位门店、菜品、服务问题;
- 自动提炼高频负面关键词:出餐慢、口味偏咸、包装破损、配送超时等;
- 按门店、区域、时间段聚合分析问题趋势,指导门店整改、优化品控与配送管理。
数据仓库脏数据智能清洗治理
数仓日常接入的文本类数据经常存在语句不通、格式混乱、描述杂乱等脏数据,传统规则清洗覆盖不全:
AI_FIXGRAMMAR对杂乱文本、错别字、语病语句自动修正规整;AI_EXTRACT从自由格式文本里提取地址、联系方式、业务编号等关键结构化字段;- 借助 AI 语义判断补齐缺失字段、修正异常填写内容,替代海量繁琐的正则匹配规则,提升数据治理效率与覆盖面。
总结
Apache Doris 4.0 正式迈入AI 原生数仓时代,通过内置 AI 函数能力,让用户一条 SQL 即可调用大模型,无需额外开发服务、不用导出数据,极大简化了智能数据分析架构。
本文完整演示了 Doris AI 资源部署、证书排坑、各类 AI 函数实操用法,并结合电商、客服、人事、数据治理等真实业务场景,验证了 Doris 在文本分类、情感分析、语义匹配、内容摘要、数据清洗等场景的落地能力。
未来随着 Doris AI 能力持续迭代,传统数仓将彻底摆脱纯统计分析,真正实现检索、分析、AI 智能处理一体化。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)