Neo4j笔记(五):查询的处理流程
·
实现流程
整体流程图:
是
否
用户提问
获取图谱 Schema
LLM 生成 Cypher 查询
Neo4j 执行查询
查询成功?
获取查询结果
返回错误信息
LLM 增强生成
自然语言回答
详细流程说明:
Neo4j图数据库大语言模型用户Neo4j图数据库大语言模型用户自然语言问题 + 图谱Schema生成 Cypher 查询语句Cypher语句执行 Cypher 查询返回查询结果问题 + 查询结果增强生成(总结回答)自然语言回答
流程:
- 用户提问 → 2. 获取图谱结构 → 3. 生成 Cypher → 4. 执行查询 → 5. LLM 汇总回答
大模型和图数据库的连接
环境配置
创建 .env 文件:
NEO4J_URL=bolt://localhost:7687
NEO4J_USER=neo4j
NEO4J_PASSWORD=your_password
OPENAI_API_KEY=your_api_key
OPENAI_BASE_URL=https://api.deepseek.com/v1
我这里用的是Deepseek,也可以根据自己的环境选择比如豆包,或者本地Ollama,或者Microsoft Foundry。
大模型调用
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="deepseek-v4-flash",
api_key=OPENAI_API_KEY,
base_url=OPENAI_BASE_URL,
temperature=0 # 设为 0 提高输出确定性
)
Neo4j 连接
from langchain_neo4j import Neo4jGraph
graph = Neo4jGraph(
url=NEO4J_URL,
username=NEO4J_USER,
password=NEO4J_PASS
)
第一步:文本转知识图谱
核心思想:利用 LLM 将自然语言文本转换为 Cypher 语句,自动创建知识图谱。
def text_to_knowledge_graph(text):
prompt = f"""
请将以下文本转换为 Neo4j Cypher 语句:
文本:{text}
要求:
1. 识别实体作为节点(Person、Location、Event 等)
2. 识别关系作为边(COOPERATE_WITH、PERFORMED_AT 等)
3. 使用 MERGE 语句避免重复
4. 只输出 Cypher 语句
"""
cypher = llm.invoke(prompt).content
# 清理 markdown 代码块标记
if cypher.startswith('```'):
cypher = cypher.split('\n', 1)[1].rsplit('\n', 1)[0]
graph.query(cypher)
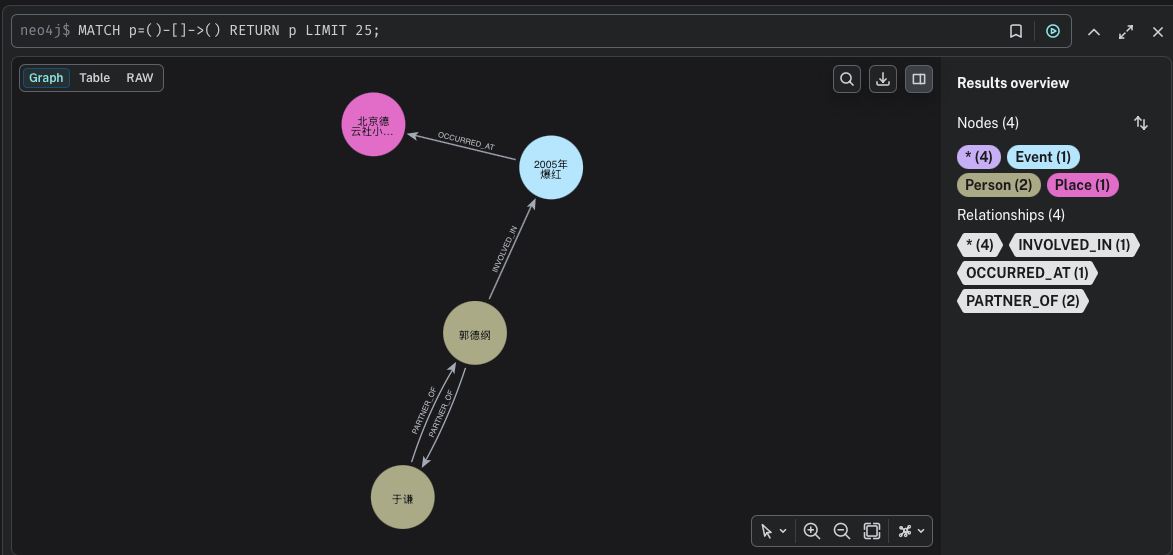
正巧昨天跟苏鹏老师聊起了郭德纲,所以这里就用郭德纲和于谦来做示例。
输入文本示例:
郭德纲 1973年出生,相声演员,与于谦长期搭档,2005年爆红
于谦 1969年出生,相声演员,擅长捧哏,常年和郭德纲合作
生成的 Cypher:
MERGE (g:Person {name: '郭德纲', birth_year: 1973, occupation: '相声演员'})
MERGE (y:Person {name: '于谦', birth_year: 1969, occupation: '相声演员'})
MERGE (g)-[:COOPERATE_WITH]->(y)
生成的知识图谱
第二步:获取图谱结构
目的:获取数据库的 schema 信息,为生成准确的 Cypher 查询提供上下文。这个思路跟TEXT2SQL基本是一致的。
这里我选择的是先从APOC插件中获取图谱的schema信息,如果失败,再从Neo4j数据库中获取。由于APOC不是默认被安装的,所以目标Neo4j环境很有可能没有这个插件。
def get_graph_schema():
# 获取节点标签
labels = graph.query("CALL db.labels() YIELD label RETURN collect(label)")
# 获取关系类型
rels = graph.query("CALL db.relationshipTypes() YIELD relationshipType RETURN collect(relationshipType)")
# 获取属性键
props = graph.query("CALL db.propertyKeys() YIELD propertyKey RETURN collect(propertyKey)")
# 尝试使用 APOC(如果安装)
try:
apoc_schema = graph.query("CALL apoc.meta.data()")
return {"labels": labels, "relationships": rels, "properties": props, "apoc": apoc_schema}
except:
return {"labels": labels, "relationships": rels, "properties": props}
APOC 安装方法(tar包安装):
- 下载对应版本的 APOC jar 文件
- 放入
neo4j/plugins/目录 - 修改
neo4j.conf:apoc.enabled=true apoc.meta.data.allowlist.all=true - 重启 Neo4j
第三步:生成 Cypher 查询并汇总增强生成结果
其它方法都已经准备好,最终再通过如下方法做调度:
def query_and_summarize(question):
# 获取图谱结构
schema = get_graph_schema()
# 生成 Cypher
cypher_prompt = f"""
图谱结构:{schema}
用户问题:{question}
请生成 Cypher 查询语句。
"""
cypher = llm.invoke(cypher_prompt).content
# 执行查询
result = graph.query(cypher)
# LLM 汇总
summary = llm.invoke(f"问题:{question}\n结果:{result}\n请用自然语言回答").content
return summary
常见问题与解决方案
问题:LLM 返回带 markdown 代码块
错误信息:
Invalid input '```cypher': expected 'MATCH', 'MERGE', ...
某些模型会带一些前置和后置标记,有些不会,所以需要根据实际情况处理下。
解决方案:清理代码块标记
if cypher.startswith('```'):
cypher = cypher.split('\n', 1)[1].rsplit('\n', 1)[0]
总结

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)