【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 --- (3)--- 总体思考目录
概要
本系列的目的是:借着对 OpenClaw-RL 源码的学习,来梳理强化学习的一些相关概念和思想。所以,会有一些基础概念、扩展和发散,OpenClaw-RL 只是一个切入点。而且,因为整篇系列是一个整体,所以有些概念的解读/学习会在不同的文章中出现,还请大家谅解。
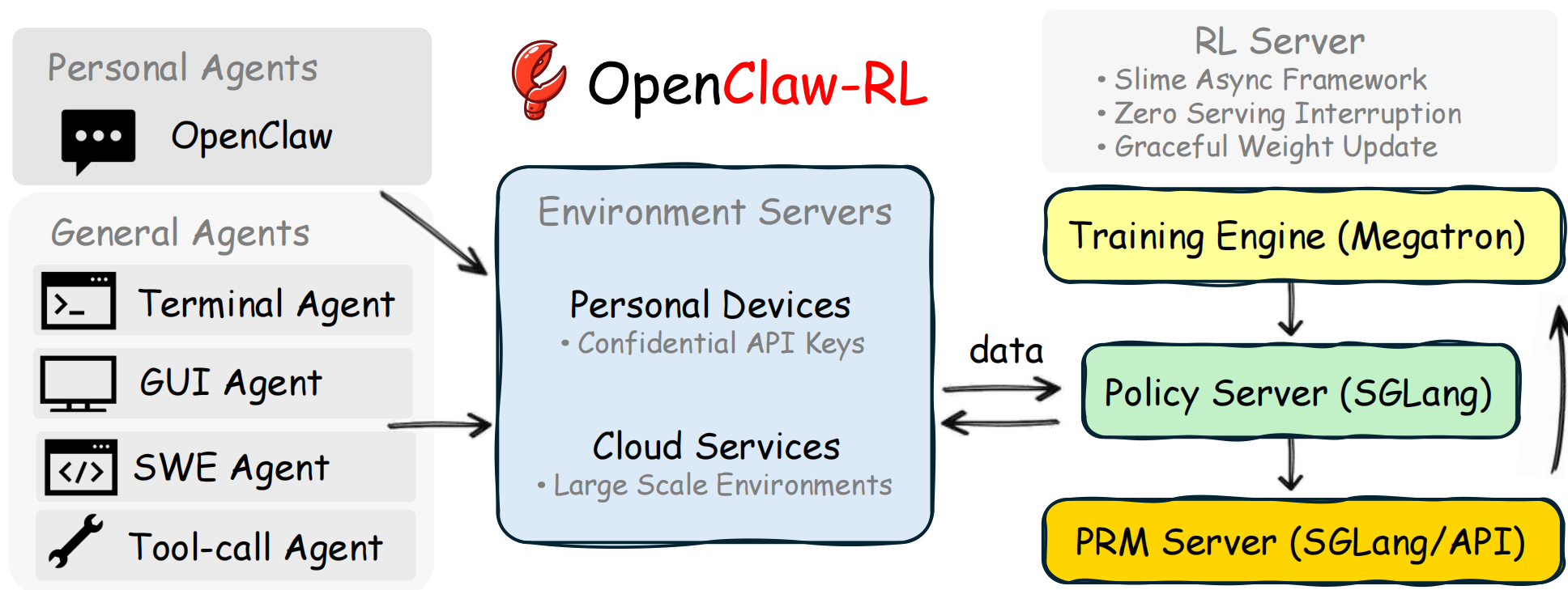
OpenClaw-RL 是一个用于在线强化学习(Online RL)的框架,专门针对智能体工具使用场景。它通过从环境反馈中提取过程奖励信号来训练语言模型,支持三种主要模式:
- openclaw-rl:基于二元奖励的强化学习(Binary RL / GRPO)
- openclaw-opd:基于后见之明提示的在线策略蒸馏(On-Policy Distillation, OPD)
- openclaw-combine:联合方法,在同一 PPO 更新中同时利用 RL reward 和 OPD teacher signal
本篇是在一篇好文基础上的进一步思考,若有错误,还请读者不吝指出。
0x01 四个要点
1.1 三大不变量
Agentic RL 训练:它不是单一 RL 算 法,而是一整套环境建模、学习信号、异步数据流、策略优化和基础设施的协同系统文中提到,Agentic RL 的三个不变量:
- 第一不变量:策略可探索空间不能过早塌缩
- 第二不变量:学习信号必须持续非退化
- 第三不变量:训练采样、参数更新和真实部署之间的偏移必须可控
如果把 Agentic RL 理解成一个在真实环境里持续交互、持续采样、持续更新的策略学习系统,那么最重要的就不再是这一步用哪种 RL 算法,而是训练闭环能否长期守住三个更底层的条件。这里的不变量,不是指某个量在数学上严格恒定,而是指它们虽然会天然漂移,却必须在整个训练过程中被不断拉回到一个仍然可学习和可优化的区间里。更准确地说,前两个是不应跌破的下限:策略探索空间不能塌缩,学习信号不能退化。第三个是不应越过的上限:Rollout 分布、更新分布与部署分布之间的偏移不能失控。
这三个不变量并不是彼此独立的三条要素,而是同一个训练系统的三个耦合边界。第一不变量决定策略空间是否还足够宽,第二不变量决定这个空间里的差异能否转成有效梯度,第三不变量决定这些梯度是否仍然作用在正确的分布上。
1.2 扩展
我们结合 OpenClaw-RL,再扩展出四个要点。
- 保护探索多样性(温度 + KL约束)
- 维持advantage的方差(归一化 + rejection sampling)
- 控制off-policy 偏移(staleness上限 + 解耦PPO)
- 解决long-horizon 信用分配(turn discount + dense reward shaping)
因此,Agentic RL 训练可以围绕着四个要点来理解:
- Policy Entropy守护:防止输出分布缩小,保持policy对多样输入的响应弹性。
- 梯度信号非退化:从奖励源头开始,保证奖励非全零(reward层),且每批次内 advantage 有足够方差(advantage 层)
- On-Policy Gap 约束:数据生成策略与当前更新策略的 KL散度须在 clip ratio 有效范围内,防止重要性采样失效。
- 有效样本率维持:确保进入训练的样本中,有足够比例携带真实梯度信号(loss_mask=1),而非被中性样本稀释。
我们接下来看看OpenClaw-RL如何处理这几个不变量的。
1.3 总览矩阵
不变量① 不变量② 不变量③ 不变量④
Policy 梯度信号 On-Policy 有效样本
Entropy 非退化 Gap 约束 率维持
───────────────────────────────────────────────────────────────────────────────────────
Binary RL ● 无正则 ● at-least-one ✓ PPO clip ● at-least-one
依赖用户多样性 majority vote kl_coef=0 但 loss_mask=0
样本仍入队
───────────────────────────────────────────────────────────────────────────────────────
OPD ● 无正则 ● hint-reject ✓ PPO clip ✓ force-drop
依赖用户多样性 = drop样本 teacher拉力 只有高质量hint
≈ 软KL约束 才进队
───────────────────────────────────────────────────────────────────────────────────────
Combine ● 无正则 ✓ 3-way dispatch ✓ PPO clip ✓ 最严格
依赖用户多样性 互补两信号 双信号对冲 OPD+RL才入队
最高风险 最强保障 On-Policy Gap 最低比例
注:
- at-least-one是指 当一个session的所有turn评分都是(中性)时,强制将第一条被评估的turn的loss_mask设为[1]。
- at-least-one 解决的问题:防止reward全零导致的训练信号完全消失(信号缺失/奖励真空问题)。
我们具体解读下。
1.4 不变量①
面对第一不变量:策略可探索空间不能过早塌缩,我们看看如何保护探索多样性(温度 + KL约束)。
可探索空间 讨论
我们先看看可探索空间的相关信息。
单轮RL:
- 探索空间 =
{不同回复风格丨同一个prompt} - 扁平的、单层的
- 维护方式:保持response 多样性
Agentic RL:
-
探索空间 = {不同轨迹|同一个初始状态} = 指数级树
-
层级的、递归的
-
维护方式:在每个状态节点都保持行为多样性,否则后续子树整个丢失
关键差异:
- Agentic RL的探索空间"塌缩是传导的",Step1塌缩→Step2可能的状态减少→Step3可能的状态更少
- 单轮RL无此连锁反应
OpenClaw-RL
Policy Entropy(三方法一致:都未显式保障,只有隐形保证)
┌──────────┬─────────────────────┬─────────────────────────────┐
│ 方法 │ 实际依赖 │ 风险 │
├──────────┼─────────────────────┼─────────────────────────────┤
│ 全部三种 │ 用户输入自然多样性 │ 用户群分布 drift 时无护栏 │
├──────────┼─────────────────────┼─────────────────────────────┤
│ 全部三种 │ 短期训练窗口(未 overfit)│ 长时间运行可能熵崩 │
└──────────┴─────────────────────┴─────────────────────────────┘
三种方法没有区别 --- 这是OpenClaw框架层面的选择(--no-entropy-reg),不是各方法独立决定的。
1.5 不变量②
针对第二不变量:学习信号必须持续非退化,我们来讨论如何维持advantage的方差 。
梯度非退化讨论
根本原因:时间跨度越长,信号越稀疏。
单轮RL:
- 每条response 都直接对应一个reward,即 1 response→ 1 reward → 1 次梯度更新
- 梯度信号是密集的(dense reward),即信号密度=1/1=100%
Agentic RL:
- Episode结束才有reward,中间步骤无信号
- 梯度信号是稀疏的(sparse reward)
- “制造非退化梯度“的代价在Agentic RL里大得多:需要 Process Reward Model (PRM) 或 Step-Wise Reward,否则 T 步episode只有最后1步有梯度
- 比如20步episode:
- 20 steps→1 terminal reward → 20次梯度更新
- 有效信号密度=1/20=5%
- 其余19步:reward=0→advantage~0 → 梯度 ≈ 0
OpenClaw-RL
梯度信号非退化(三方法有显著差异)
-
Binary RL:
-
Reward 层:
- majority vote(m=3)降低None概率
- at-least-one保证:如果session中,全score =0 → 强制第一条loss_mask=1
-
Advantage 层:无 baseline,方差未约束。→ 一批全+1或全-1时advantage无对比,梯度退化
-
- OPD:
- Reward层:N/A(无整体reward,用teacher log-prob)
- Advantage层:
- teacher_lp - rollout_lp 天然有正有负(不同token 教师偏好各异)→ 单条样本内advantage 自然不退化!
- hint-reject → drop(而非置零),保证进队的都是高信噪比样本
- Combine:
- 两路信号互补 = 最强的梯度非退化保障:
- 当GRPO全为+1→OPD的per-token差值仍有正负→总advantage未退化
- 当OPD级联噪声→GRPO的全局均值拉回→方向不完全消失
- 两路信号互补 = 最强的梯度非退化保障:
1.6 不变量③
针对第三不变量:训练采样、参数更新和真实部署之间的偏移必须可控,我们来讨论如何控制off-policy 偏移。
Off-Policy Gap讨论
单轮RL:
- 一条response=一个训练单元
- 生成后立即训练,off-policy gap很小
Agentic RL:
- 一个episode=T步
- Episode开始时用的是policy_old
- T步后policy可能已更新多次
- → 前面步骤的数据相对policy_T更加off-policy
- → Off-Policy Gap = f(episode_length)。episode越长,gap越大,PPO clip假设越容易被违反
OpenClaw-RL
On-Policy Gap约束(三方法一致:PPO clip兜底)
统一依赖:
- PPO clip(e=0.2,e_high=0.28)
- ratio = t_0_new(a|s) / t_0_old(a/s)
- 超出 [0.8, 1.28] 的 ratio 被截断 → 隐式 KL 约束
OPD特有的额外保障:
-
teacher_lp - rollout_lp 的梯度方向 = "向 teacher 靠拢" = 隐式 KL 拉力
-
→ 防止 policy 漂离有 teacher 指导的区域
三种方法的 On-Policy Gap 风险都不大,因为 OpenClaw 是在线服务,数据实时产生,天然接近 on-policy。weight sync 暂停窗口是主要偏差来源,被 503 pause 机制控制。
1.7 不变量④
我们看看如何解决long-horizon 信用分配(turn discount + dense reward shaping)
有效样本率讨论
单轮RL:
- 每条response = 1个样本,有reward就有梯度
Agentic RL:
- 每个episode = T步,但可能只有1个terminal reward
- 前T-1步:reward=0 → 无梯度(用0填充)
- “有效样本率“的真正含义在Agentic RL里变成:"reward信号能有效反向传播到多少步的action?"
OpenClaw-RL
有效样本率
- Binary RL:
- loss_mask = 0 的样本仍进训练队列(Megatron 做零梯度forward)
- → 占用GPU计算资源但无学习信号
- → 有效样本率 =(score ≠ 0的turn 数) / (队列总turn数)
- at-least-one 保障下限:每 session ≥ 1个有效样本
- OPD:
- hint-reject→完全不进队→有效率最纯净
- 所有进入队列的样本loss_mask全为1
- 但:效率上限 ≤ hint accept rate(hint 拒绝率可能很高)
- Combine:
- OPD-only + RL-only + "OPD+RL" 都进队
- 但hint-rejected AND eval=0 → drop (最严格过滤)
- 结果:样本数最少,但信号质量最高(每条都有至少一路有效信号)
1.8 设计哲学小结
- Binary RL → 宁愿噪声多,不放弃任何数据(at-least-one + 全入队)
- OPD → 宁愿数据少,只要高纯度信号(hint-accept才入队)
- Combine → 精准门控,按信号类型分路,最大化信噪比
0x02 第一不变量理解
我们在本小节再仔细学习理解下 第一不变量:策略可探索空间不能过早塌缩。
2.1 直觉理解
塌缩 = 模型“认定“了某种回复模式,放弃探索其他可能性。具体如下:
训练前(高entropy,充分探索):
-
P("好的,我来帮你") =0.15
-
P("让我分析一下") =0.18
-
P("这个问题需要...") =0.20
-
P("首先...") =0.12
-
...(很多候选,均匀分布)
过早塌缩后(低entropy,退化):
- P("让我分析一下") =0.87
- P(“好的,我来帮你") =0.08
- P(其他所有)=0.05
2.2 深入思考
第一不变量不是说"模型要随机”,而是说:在每种情境下,模型必须仍然"知道"多种有意义的应对方式,并且真实地有能力选择它们。这是RL持续学习的前提条件一没有这个可探索空间,后续的奖励信号无论多精确,都无法引导模型走向更好的策略。
2.2.1 多样性
此处回答"为什么token级随机性不等于探索?”
支撑集
支撑集(Support)的数学含义:分布P的支撑集 = 所有概率 > 0 的事件集合
Token 级支撑集 ≠ 行为级支撑集。
示例:
- 模型在token 1选"Let"时,有("Let","First","To","I")都有高概率
- 但一旦选了"Let",之后的token高概率会走"直接推理"路径
结论:
token级很高,但行为级已经锁定成"直接推理"这一种策略。表面上”每个token位置的词表分布仍有多样性",但是”模型生成的所有回答都遵从同一种模式"。”直接推理"就是永远走” → 长链推理 → → 答案"的固定模板。
行为级支撑集崩塌(Support Collapse):
训练前:
-
P(分解为子问题策略)=30%
-
P(直接推理策略)=40%
-
P(先搜索再答策略) =20%
-
P(反例验证策略)=10%
RL训练后(+1奖励集中在"直接推理"):
- P(分解为子问题策略) =2% 快崩塌了
- P(直接推理策略) =94% 支撑集过度收缩
- P(先搜索再答策略) =3%
- P(反例验证策略) =1%
此时token级熵可能依然很高(词语选择多样),但行为空间的支撑集已经崩塌了。这就是为什么ARLArena观察到"训练崩溃"往往在特定任务类型上(如 ALFWorld),而非所有任务一特定任务对行为多样性的要求更高。
策略层面的多样性
token级熵测试的是”用词多样性",行为级是”策略多样性",前者高不代表后者没有

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)