GPT详解
GPT被称为生成式预训练Transformer,其为纯解码器架构的自回归语言模型。
1. 自回归语言模型
给定文本序列:x1,x2,…,xn 自回归建模将联合概率分解为条件概率乘积:
![]()
训练目标是最大化整段文本的对数似然:
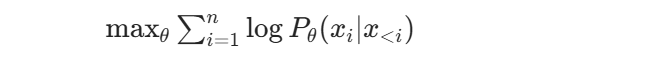
等价于最小化负对数似然损失:
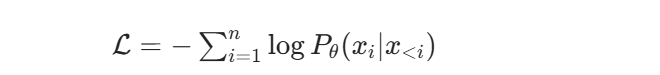
含义:模型预测第 i 个 token 时,只能看到它前面的 token:x<i=x1,…,xi−1 不能看到后面的 token。
2. “生成式”的含义
给定初始文本:x1,…,xk 模型计算下一个 token 的概率分布:
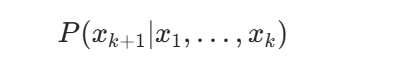
然后通过贪心搜索、Top-k、Top-p 或温度采样得到 xk+1,再把新 token 拼回输入中,重复生成:
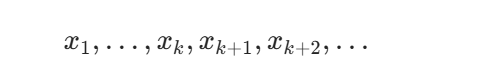
直到生成结束符 [EOS] 或达到最大长度。
3. GPT 架构:纯解码器 Transformer
GPT 使用 decoder-only 架构,但它不是完整的原始 Transformer 解码器,因为它去掉了交叉注意力层。
即:掩码自注意力 → FFN GPT 不需要编码器输出,适合做纯文本生成。
4. GPT 单层结构
输入 token 先经过词嵌入和位置编码:
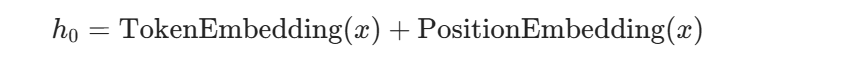
第 l 层 GPT Block 通常采用 Pre-LN 结构:
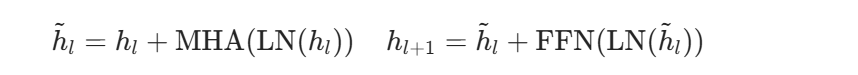
其中 MHA 是因果多头自注意力,FFN 是前馈网络,通常隐藏层维度约为:
![]()
最后通过线性层输出词表概率: ![]()
5. Causal Mask:保证只能看过去
GPT 的关键是因果掩码。注意力分数为:
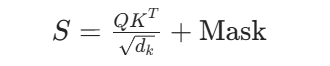
其中 Mask 是下三角可见矩阵。对于位置 i 和 j:
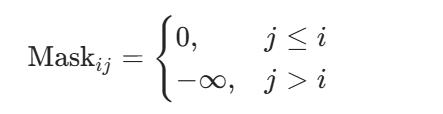
含义:第 i 个 token 只能关注自己和左边的 token,不能关注右边未来 token。Softmax 后,未来位置的注意力权重变为 0。
6. Pre-LayerNorm
原始 Transformer 常用 Post-LN: 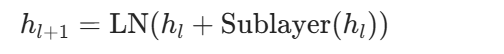
GPT-2 之后的 GPT 类模型通常使用 Pre-LN: 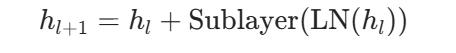
Pre-LN 的优点是训练更稳定,梯度传播更顺畅,更适合深层大模型。
7. 位置编码的演进
GPT-1、GPT-2、GPT-3 这类早期 GPT 系列通常使用可学习绝对位置编码:

其中: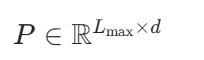 缺点是最大长度固定,超过训练长度后外推能力较差。
缺点是最大长度固定,超过训练长度后外推能力较差。
后续很多开源大模型,例如 LLaMA、Qwen、ChatGLM、RoFormer,常用 RoPE 旋转位置编码。RoPE 不直接加位置向量,而是旋转 Query 和 Key:
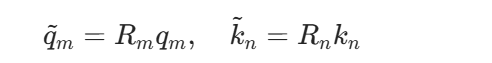
其注意力分数可写为: 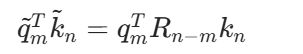 因此 RoPE 能在注意力内积中自然表达相对位置 n−m。
因此 RoPE 能在注意力内积中自然表达相对位置 n−m。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)