GLM-4-9B-Chat-1M性能评测:1M上下文大海捞针实验结果与LongBench-Chat排行榜解读
GLM-4-9B-Chat-1M性能评测:1M上下文大海捞针实验结果与LongBench-Chat排行榜解读
【免费下载链接】glm-4-9b-chat-1m  项目地址: https://ai.gitcode.com/hf_mirrors/AI-Research/glm-4-9b-chat-1m
项目地址: https://ai.gitcode.com/hf_mirrors/AI-Research/glm-4-9b-chat-1m
在当今大语言模型激烈竞争的时代,智谱AI推出的GLM-4-9B-Chat-1M模型以其惊人的1M上下文长度(约200万中文字符)能力引起了广泛关注。这款开源大语言模型不仅支持26种语言,还具备网页浏览、代码执行、自定义工具调用等高级功能,成为长文本处理领域的强大竞争者。🚀
🌟 为什么1M上下文如此重要?
在传统的大语言模型中,上下文长度往往限制在几千到几万个token之间,这严重制约了模型处理长文档、多轮对话和复杂任务的能力。GLM-4-9B-Chat-1M突破性地将上下文扩展到1M,相当于约200万中文字符,这意味着它可以:
- 📚 处理整本书籍或长篇报告
- 💬 维持超长、连贯的多轮对话
- 🔍 在大量信息中精确检索关键内容
- 📊 分析复杂的数据集和文档
🔬 大海捞针实验:1M上下文的终极测试
为了验证GLM-4-9B-Chat-1M在超长上下文中的表现,研究人员进行了著名的"大海捞针"实验。这项测试将一个关键信息("针")隐藏在大量无关文本("海")中,评估模型能否准确找到并提取这个信息。
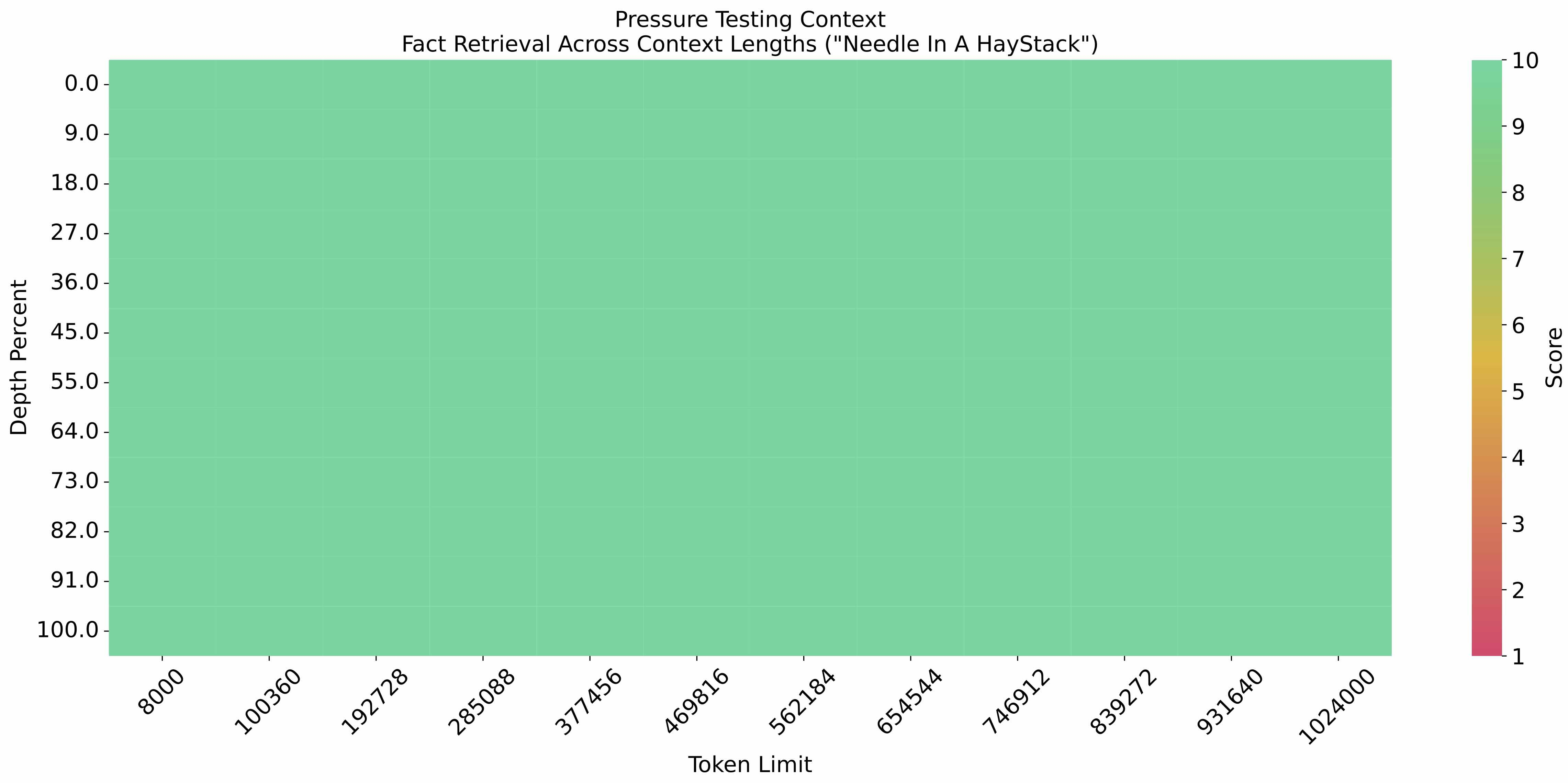
GLM-4-9B-Chat-1M在大海捞针实验中的表现结果
从实验结果可以看出,GLM-4-9B-Chat-1M在1M上下文长度下表现出色,能够有效识别和提取隐藏在大量文本中的关键信息。这一能力对于文档分析、信息检索和知识问答等实际应用场景具有重要意义。
🏆 LongBench-Chat排行榜:全面评估长文本能力
除了大海捞针实验,GLM-4-9B-Chat-1M还在LongBench-Chat基准测试中接受了全面评估。LongBench-Chat是一个专门设计用于测试大语言模型长文本处理能力的综合性基准,涵盖了多种任务类型:
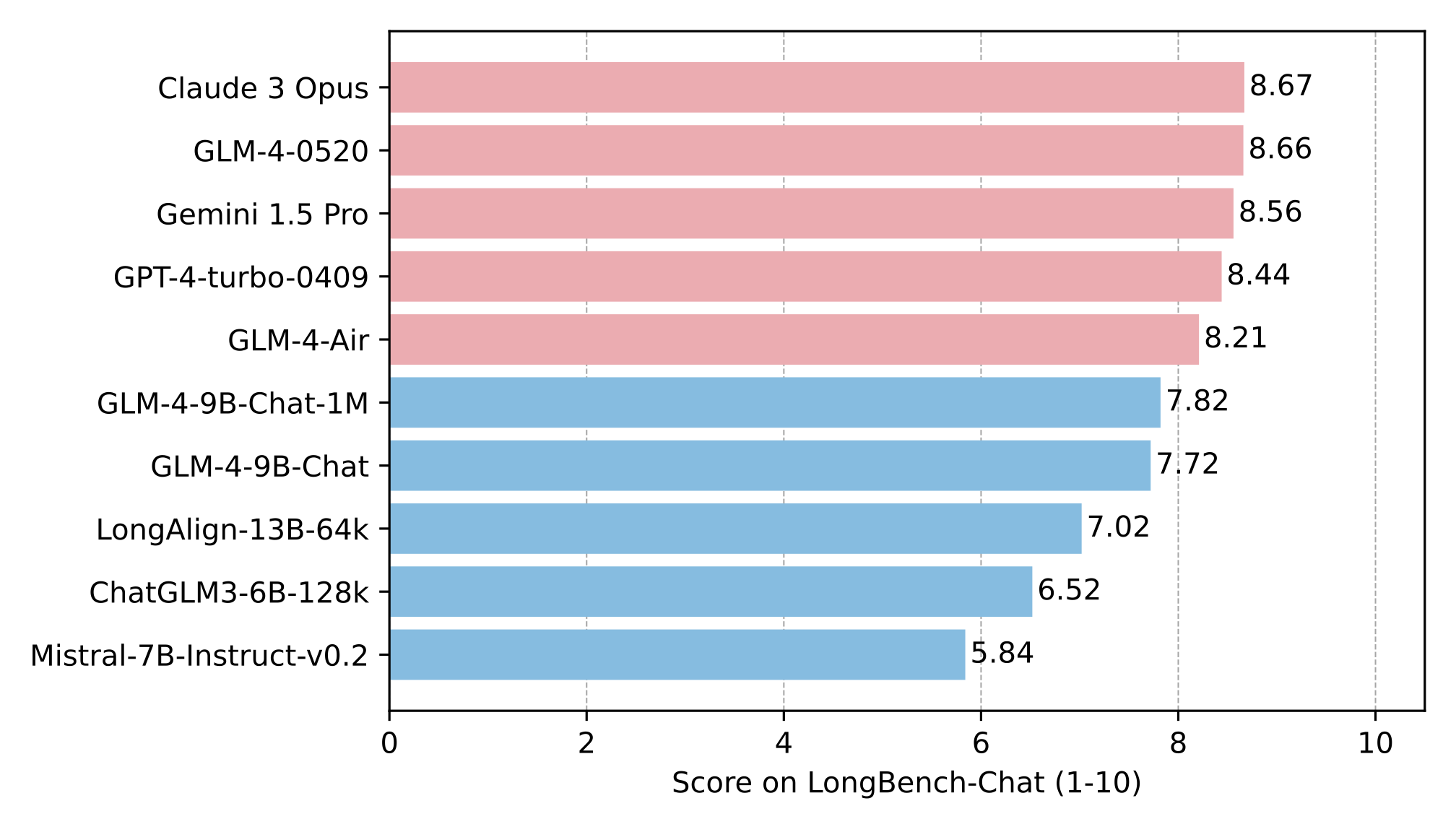
GLM-4-9B-Chat-1M在LongBench-Chat排行榜上的表现
📋 评测维度解析
- 文档理解能力:模型能否理解长篇文档的核心内容和细节
- 信息提取精度:从长文本中准确提取特定信息的能力
- 多轮对话连贯性:在超长对话中保持上下文一致性和逻辑性
- 代码分析与执行:处理长代码文件和复杂编程任务的能力
⚙️ 技术架构亮点
GLM-4-9B-Chat-1M之所以能够支持1M上下文,得益于其先进的技术架构:
- 40层Transformer架构:深层网络结构提供强大的表征能力
- 32个注意力头:多头注意力机制增强模型的并行处理能力
- 4096隐藏维度:充足的参数空间支持复杂计算
- 多语言支持:支持包括中文、英文、日文、韩文、德文在内的26种语言
🚀 快速上手指南
想要体验GLM-4-9B-Chat-1M的强大能力?以下是简单的使用步骤:
环境准备
首先确保安装了必要的依赖,可以参考项目中的requirements.txt文件:
# 安装基础依赖
pip install torch transformers
基础推理示例
使用以下代码快速体验模型的基本功能:
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("AI-Research/glm-4-9b-chat-1m", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("AI-Research/glm-4-9b-chat-1m", trust_remote_code=True)
# 简单对话示例
response = model.chat(tokenizer, "你好,请介绍一下你自己")
print(response)
配置文件说明
模型的详细配置可以在config.json中找到,包括模型架构、参数设置等关键信息。
📈 性能优化建议
在使用GLM-4-9B-Chat-1M处理长文本时,以下优化建议可以帮助您获得更好的体验:
- 分批处理:对于超长文档,可以考虑分批输入和处理
- 内存管理:确保有足够的GPU内存支持1M上下文的计算
- 推理优化:使用vLLM等优化后端可以提高推理速度
🔍 实际应用场景
GLM-4-9B-Chat-1M的1M上下文能力在多个领域都有广泛应用价值:
📚 学术研究
- 长篇论文分析和总结
- 文献综述自动生成
- 研究数据深度分析
💼 企业应用
- 长合同文档审查
- 市场报告自动分析
- 客户服务长对话管理
🎓 教育培训
- 教材内容深度理解
- 学习材料自动问答
- 个性化学习路径规划
🎯 核心优势总结
GLM-4-9B-Chat-1M作为开源大语言模型的重要代表,具有以下核心优势:
- 超长上下文:1M上下文长度领先同类开源模型
- 多语言支持:26种语言覆盖主要使用场景
- 开源免费:完全开源,支持商业使用
- 功能丰富:支持代码执行、工具调用等高级功能
- 性能优异:在多项评测中表现突出
📊 未来展望
随着大语言模型技术的不断发展,GLM-4-9B-Chat-1M为代表的超长上下文模型将在更多领域发挥重要作用。无论是学术研究、商业应用还是个人使用,这种能够处理海量信息的人工智能助手都将成为不可或缺的工具。
如果您对长文本处理有需求,GLM-4-9B-Chat-1M绝对值得尝试!它的开源特性也让开发者可以基于此进行二次开发和优化,推动整个AI社区的发展。🌟
本文基于README.md和README_en.md中的技术文档编写,详细技术信息请参考官方文档。
【免费下载链接】glm-4-9b-chat-1m 项目地址: https://ai.gitcode.com/hf_mirrors/AI-Research/glm-4-9b-chat-1m

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)