捡漏王炸|2017 年 Tesla V100 服务器整机
32GB HBM2 + Tensor Core + NVLink + 双路 EPYC 64核 + 256G ECC 内存
——这不是矿机,是退役超算节点,AI 训练/大模型微调的性价比天花板!
为什么说这是“闭眼入”的捡漏机会?
核心部件 规格
GPU NVIDIA Tesla V100 32GB (PCIe 版)
• Volta 架构 + Tensor Core
• HBM2 显存,带宽 900 GB/s
• 支持 NVLink 2.0(多卡互联)
CPU 2× AMD EPYC 7542(32核64线程 ×2 = 64核128线程)
基频 2.9GHz / 睿频 3.4GHz,L3 128MB
内存 256GB DDR4 3200MHz RECC(8通道,带纠错)
系统盘 1TB NVMe SSD(全新三星 PM9A1)
存储 8TB 企业级 HDD(希捷 Exos,7200RPM)
电源 1300W 铂金冗余服务器电源(支持 220V 单相)
散热 原装 AMD SP3-4U M95 风冷模组,静音高效

为什么 V100 仍是“AI 老兵不死”?
别被“2017 年”吓到——V100 是 AI 算力史上的里程碑:
·首代引入 Tensor Core,FP16 算力高达 125 TFLOPS,至今碾压消费卡;
·32GB HBM2 显存,轻松跑 LLaMA-7B 微调、Stable Diffusion 高分辨率训练;
·NVLink 支持多卡通信,未来可扩展第二张 V100(本机已预留插槽+供电);
·驱动稳定、社区支持完善,PyTorch/TensorFlow 开箱即用。
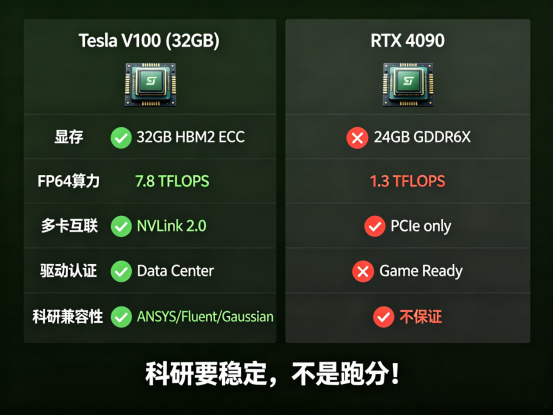
对比 RTX 4090:
·4090:24GB GDDR6X,无 ECC 显存,不支持 NVLink,FP64 被阉割;
·V100:32GB HBM2 ECC,专业驱动认证,FP64 算力 7.8 TFLOPS(4090 仅 1.3)!
实测性能参考(Ubuntu 22.04 + CUDA 11.8)
·LLaMA-7B 微调(QLoRA):batch_size=4,显存占用 28GB,训练稳定无 OOM
·Stable Diffusion XL 推理:512x512 图像生成 ≈ 3.2 秒/张
·ResNet-50 训练:吞吐量 1800 img/s(接近 A100 的 70%)

为什么现在是抄底时机?
·V100 已停产,二手市场库存锐减;
·新卡 A100/H100 受出口管制,价格翻倍且难采购;
如何入手?
私信留言 “V100” 获取真正的超算残骸,从来不会等你犹豫。
附赠:
·完整 CUDA + PyTorch 环境部署脚本
·《V100 能效优化手册》PDF
科研不靠堆新,而靠用对。
这台 V100 服务器,或许就是你毕业论文的最后一块拼图。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)