突破百万上下文壁垒:GLM-4-9B-Chat-1M开源模型震撼发布
突破百万上下文壁垒:GLM-4-9B-Chat-1M开源模型震撼发布
【免费下载链接】glm-4-9b-chat-1m  项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-1m
项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-1m
新一代开源大模型登场
2024年,人工智能领域再添重磅成果——智谱AI正式推出GLM-4系列预训练模型的开源版本GLM-4-9B。这款模型在语义理解、数学推理、代码生成和知识问答等多个维度均展现出卓越性能,尤其值得关注的是其对话版本GLM-4-9B-Chat不仅支持流畅的多轮交互,更集成了网页浏览、代码执行、自定义工具调用(Function Call)等高级功能。
作为该系列的重要成员,GLM-4-9B-Chat-1M模型突破性地实现了100万token上下文长度支持(约合200万中文字符),同时扩展了多语言处理能力,可流畅应对日语、韩语、德语等26种语言的任务需求。这一进展标志着开源大模型在长文本理解领域迈入全新阶段,为处理学术论文、法律文档、企业年报等超长文本场景提供了强有力的技术支撑。
长文本能力评测突破
为验证模型在超长上下文场景下的表现,研发团队采用行业标准的"大海捞针实验"(Needle-in-a-Haystack)进行测试。在100万token的上下文长度中,模型成功定位关键信息的准确率表现如下:
 如上图所示,该实验通过在超长文本中嵌入特定关键词,测试模型在百万级上下文里的信息检索能力。结果显示GLM-4-9B-Chat-1M在各位置的准确率均保持在较高水平,充分证明其在长文本中保持信息连贯性的能力,为处理超长文档提供了可靠保障。
如上图所示,该实验通过在超长文本中嵌入特定关键词,测试模型在百万级上下文里的信息检索能力。结果显示GLM-4-9B-Chat-1M在各位置的准确率均保持在较高水平,充分证明其在长文本中保持信息连贯性的能力,为处理超长文档提供了可靠保障。
在权威长文本评测基准LongBench-Chat上,该模型同样表现优异,其综合评分在同类模型中位居前列:
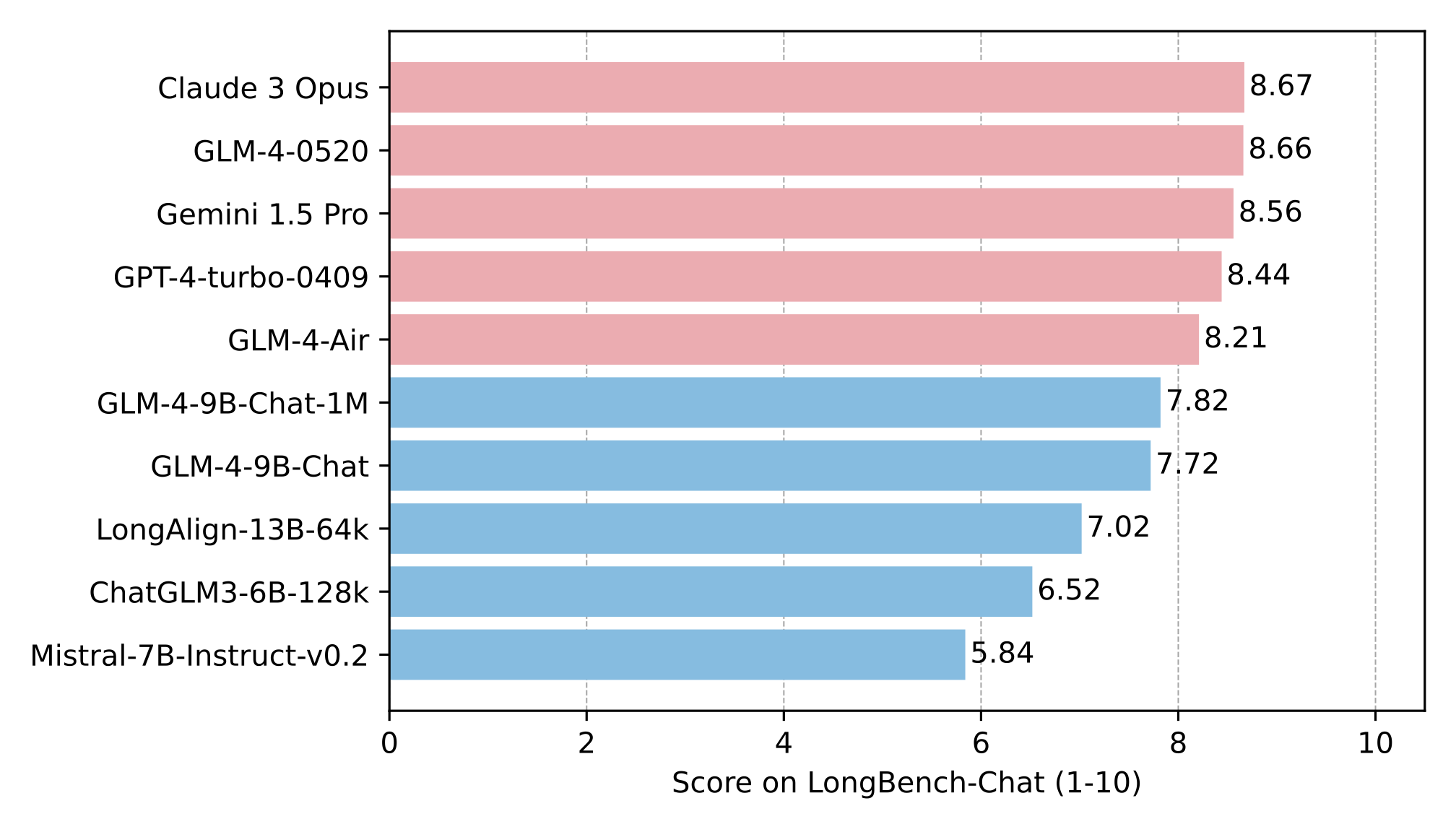 此排行榜展示了GLM-4-9B-Chat-1M与其他主流模型在长文本理解任务上的对比。模型在多轮对话、摘要生成、信息提取等子任务中均表现突出,特别是在需要深度上下文理解的场景中优势明显,为用户提供了处理复杂长文本的高效解决方案。
此排行榜展示了GLM-4-9B-Chat-1M与其他主流模型在长文本理解任务上的对比。模型在多轮对话、摘要生成、信息提取等子任务中均表现突出,特别是在需要深度上下文理解的场景中优势明显,为用户提供了处理复杂长文本的高效解决方案。
本仓库作为GLM-4-9B-Chat-1M的官方模型仓库,特别针对100万token上下文长度进行了优化,开发者可直接基于此仓库开展长文本相关应用开发。
快速上手与环境配置
开发环境准备
为确保模型正常运行,开发者需特别注意环境配置。官方强烈建议通过以下步骤准备开发环境:
- 克隆官方代码仓库:
git clone https://gitcode.com/zai-org/glm-4-9b-chat-1m - 严格按照仓库中
basic_demo/requirements.txt文件安装依赖包 - 确认transformers库版本≥4.44.0(2024年8月12日更新的关键依赖)
环境配置不当可能导致模型无法加载或推理异常,建议使用conda创建独立虚拟环境以避免依赖冲突。
推理代码示例
Transformers后端实现
以下是使用Hugging Face Transformers库进行推理的基础代码:
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(
"THUDM/glm-4-9b-chat-1m",
trust_remote_code=True
)
# 准备对话内容
query = "请分析以下年度报告中的关键财务指标变化趋势..." # 可替换为长文本查询
inputs = tokenizer.apply_chat_template(
[{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
# 模型加载与推理
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat-1m",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
# 推理参数设置
gen_kwargs = {
"max_length": 2500, # 根据需求调整输出长度
"do_sample": True,
"top_k": 1
}
# 生成响应
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
response = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(response[0], skip_special_tokens=True))
VLLM后端加速实现
对于需要更高推理效率的场景,推荐使用VLLM后端:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# 模型配置参数
max_model_len = 1048576 # 1M上下文长度
tp_size = 4 # 根据GPU数量调整张量并行度
model_name = "THUDM/glm-4-9b-chat-1m"
# 准备对话内容
prompt = [{"role": "user", "content": "请总结这份长达500页的技术文档核心观点..."}]
# 加载分词器与模型
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# 内存优化参数(如遇OOM可启用)
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
# 推理参数设置
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(
temperature=0.95,
max_tokens=1024,
stop_token_ids=stop_token_ids
)
# 生成响应
inputs = tokenizer.apply_chat_template(
prompt,
tokenize=False,
add_generation_prompt=True
)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
注意:完整的推理代码和高级应用示例,请参考官方GitHub仓库。生产环境部署时,建议根据硬件条件调整张量并行度(tp_size)和批处理参数,以达到最佳性能。
使用许可与学术引用
GLM-4-9B-Chat-1M模型的权重使用需严格遵守仓库中的LICENSE协议。研究机构和企业在使用该模型时,请确保符合许可条款中的相关要求。
如需在学术研究中引用本模型,请使用以下引用格式:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
技术演进与未来展望
GLM-4-9B-Chat-1M的发布代表了开源大模型在长文本理解领域的重要突破。研发团队在2024年7月24日发布的技术报告中详细阐述了其长文本处理技术,包括上下文扩展算法、注意力机制优化和内存效率提升等创新点。这些技术不仅实现了百万级上下文的支持,更在保持模型性能的同时显著降低了计算资源消耗。
随着大模型上下文能力的不断提升,企业级文档处理、智能法律顾问、学术文献分析等场景将迎来革命性变革。未来,智谱AI将持续优化模型效率,探索多模态长文本理解,并构建更完善的工具调用生态,为开发者提供更全面的AI能力支持。
对于开发者而言,GLM-4-9B-Chat-1M不仅是一个高性能模型,更是一个开放的技术平台。通过官方提供的工具链和API,开发者可以快速构建从文档分析到智能创作的各类应用,加速AI技术在各行各业的落地应用。
【免费下载链接】glm-4-9b-chat-1m 项目地址: https://ai.gitcode.com/zai-org/glm-4-9b-chat-1m

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)