LLM驱动Grep的代码搜索架构
本文基于2026年3月泄露的Claude Code CLI源码快照,深入拆解了Anthropic放弃RAG、改用LLM驱动Grep的代码搜索架构,对比了行业主流方案的设计取舍,最终澄清了"RAG已死"的真实含义:广义的检索增强生成范式并未消亡,消亡的是"预先建索引、静态一次性检索"的窄义RAG实现。
一、背景:RAG唱衰与Grep的回归
- 行业趋势:2026年"RAG已死"论调盛行,核心依据是长上下文窗口和Agent崛起,Claude Code、OpenAI Codex等新一代AI编程Agent均公开放弃embedding和向量数据库,转而采用LLM驱动的Grep搜索。
- Claude Code的官方表态:创建者Boris Cherny明确表示,早期版本使用RAG+本地向量库,但实测发现智能体式搜索(agentic search)效果更优,"由模型驱动的glob和grep击败了一切"。
- 文章核心目标:从实现层面拆解Claude Code的零索引搜索机制、性能原理,对比行业方案,回答RAG在Agent时代的价值边界。
二、Claude Code的核心:LLM驱动的多轮循环搜索
Claude Code的代码搜索本质是LLM全自主决策的迭代式检索:无预设流程、无固定工具顺序,模型自主决定搜索关键词、工具选择和终止条件。
2.1 核心搜索循环与工具集
- 循环机制:将用户输入+工具列表传给LLM→LLM返回文本或工具调用→执行工具并将结果追加到对话历史→重复调用LLM,直到模型认为信息充分生成回答。强制退出条件:最大轮次、预算超限、用户中断、权限拒绝。
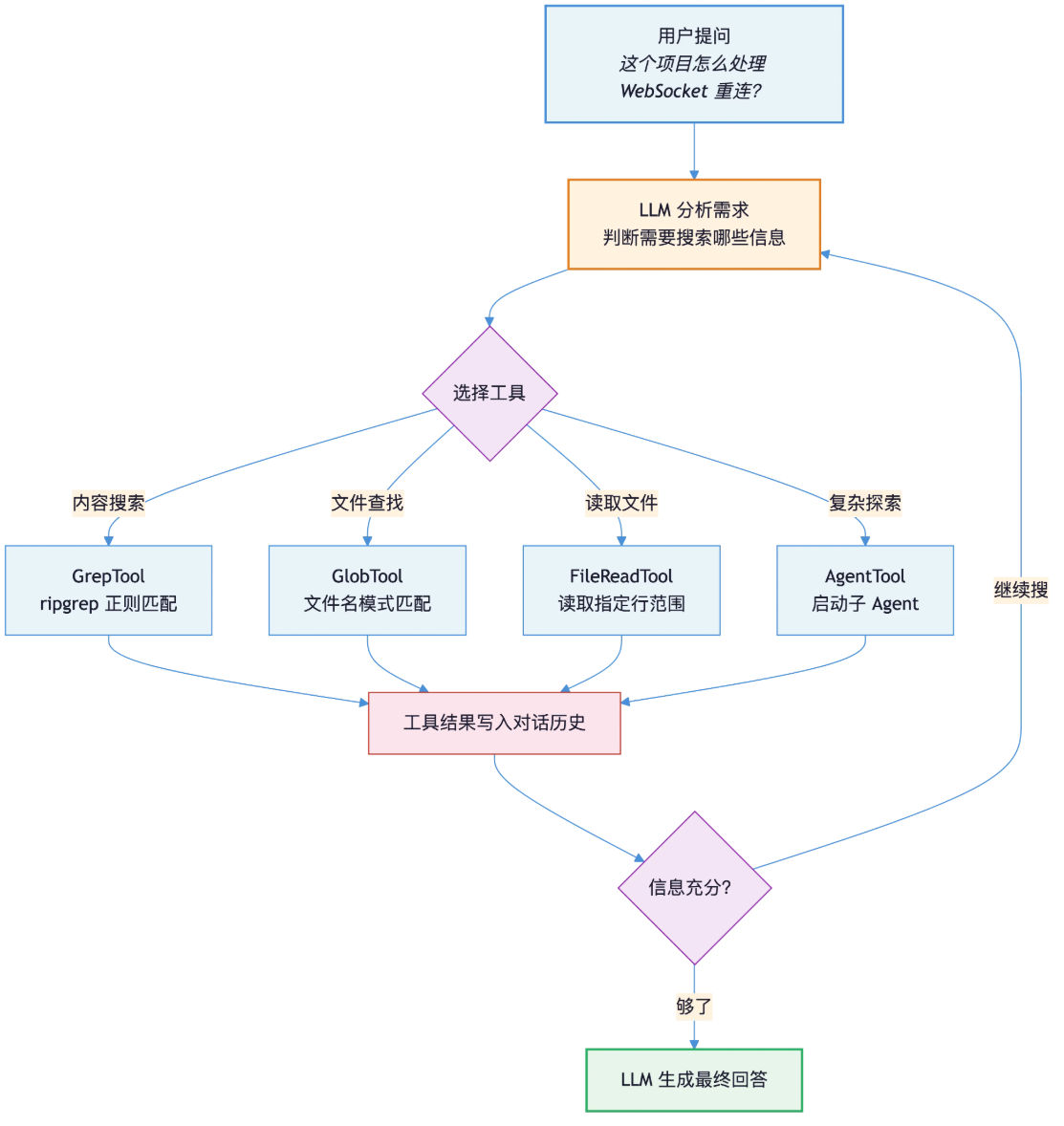
- 四大核心工具:
|
工具 |
底层实现 |
核心作用 |
|
GrepTool |
ripgrep(rg) |
正则搜索文件内容,核心搜索工具 |
|
GlobTool |
glob模式匹配 |
按文件名/路径筛选文件 |
|
FileReadTool |
Node.js fs |
按行范围读取指定文件 |
|
AgentTool |
独立LLM对话 |
启动子Agent完成纯搜索任务,实现上下文隔离 |
- 子Agent的关键价值:Explore类型子Agent仅配备搜索/读取工具,不继承主对话上下文,搜索中间结果仅在子Agent内部处理,最终只返回精炼结论,避免主对话上下文被大量代码片段淹没。
2.2 GrepTool的精细化信息量控制
GrepTool通过三种输出模式灵活平衡检索效率和上下文占用,避免一次性涌入大量无关内容:
- files_with_matches(默认):仅返回匹配文件路径,不返回代码内容,强制模型自主判断哪些文件值得深入读取;内置
head_limit=250保护,最多返回前250条结果。 - content模式:返回匹配行及其前后指定行数的代码片段,适用于确认常量、函数签名等简单场景,无需额外调用Read工具。
- count模式:仅返回每个文件的匹配数量,用于快速评估关键词在项目中的分布密度。
2.3 实战演示:多轮搜索的完整流程
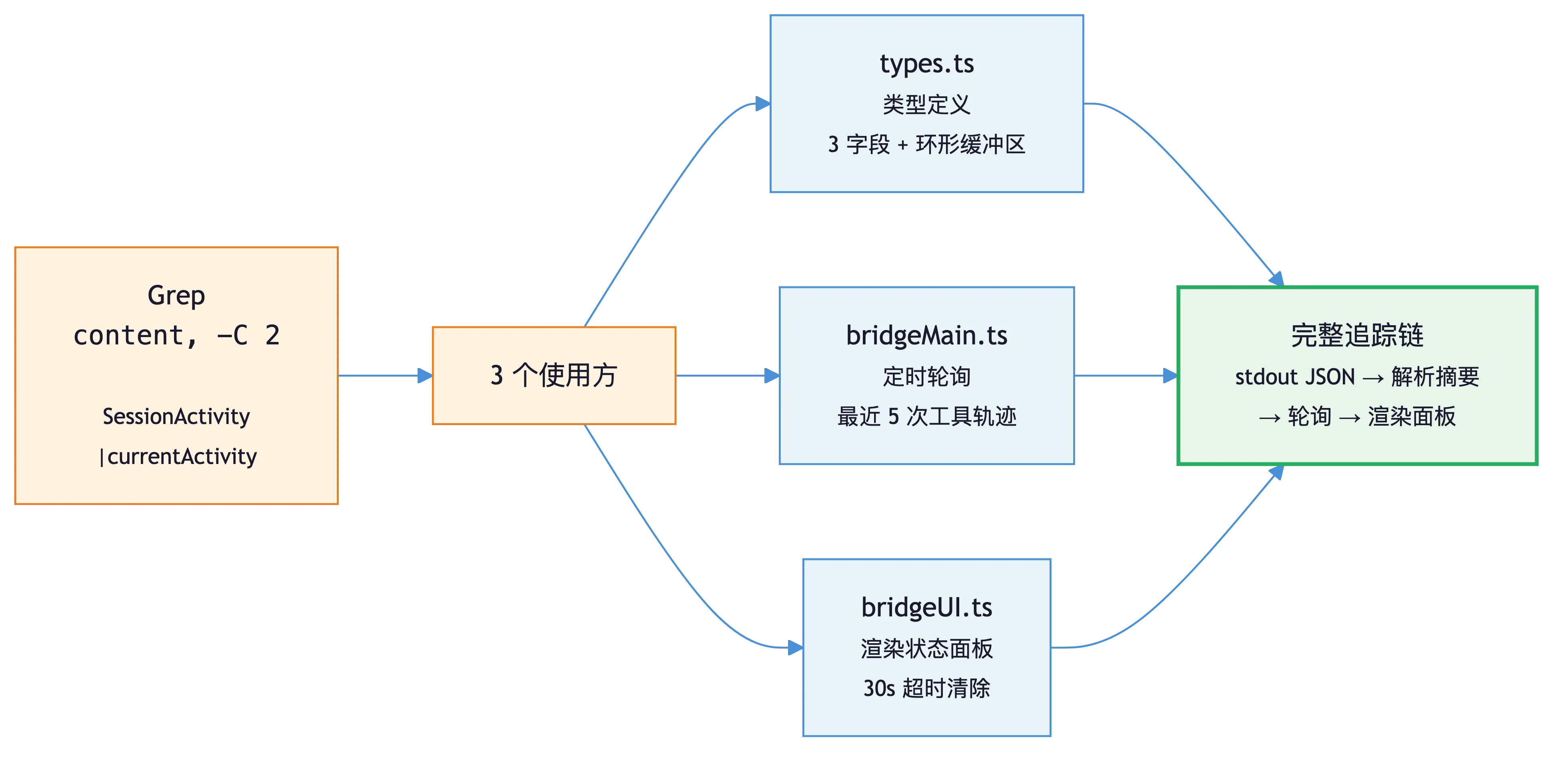
以"追踪bridge系统对GrepTool调用的记录"为例,展示了典型的四轮迭代搜索:
- 广撒网:默认模式Grep关键词,定位4个相关文件,聚焦bridge目录下的
sessionRunner.ts。

- 看上下文:切换content模式Grep该文件,发现代码片段被截断,需要完整读取。

- 深入读取:调用Read工具获取完整代码,找到工具名-动词映射表、摘要生成函数和活动解析器。
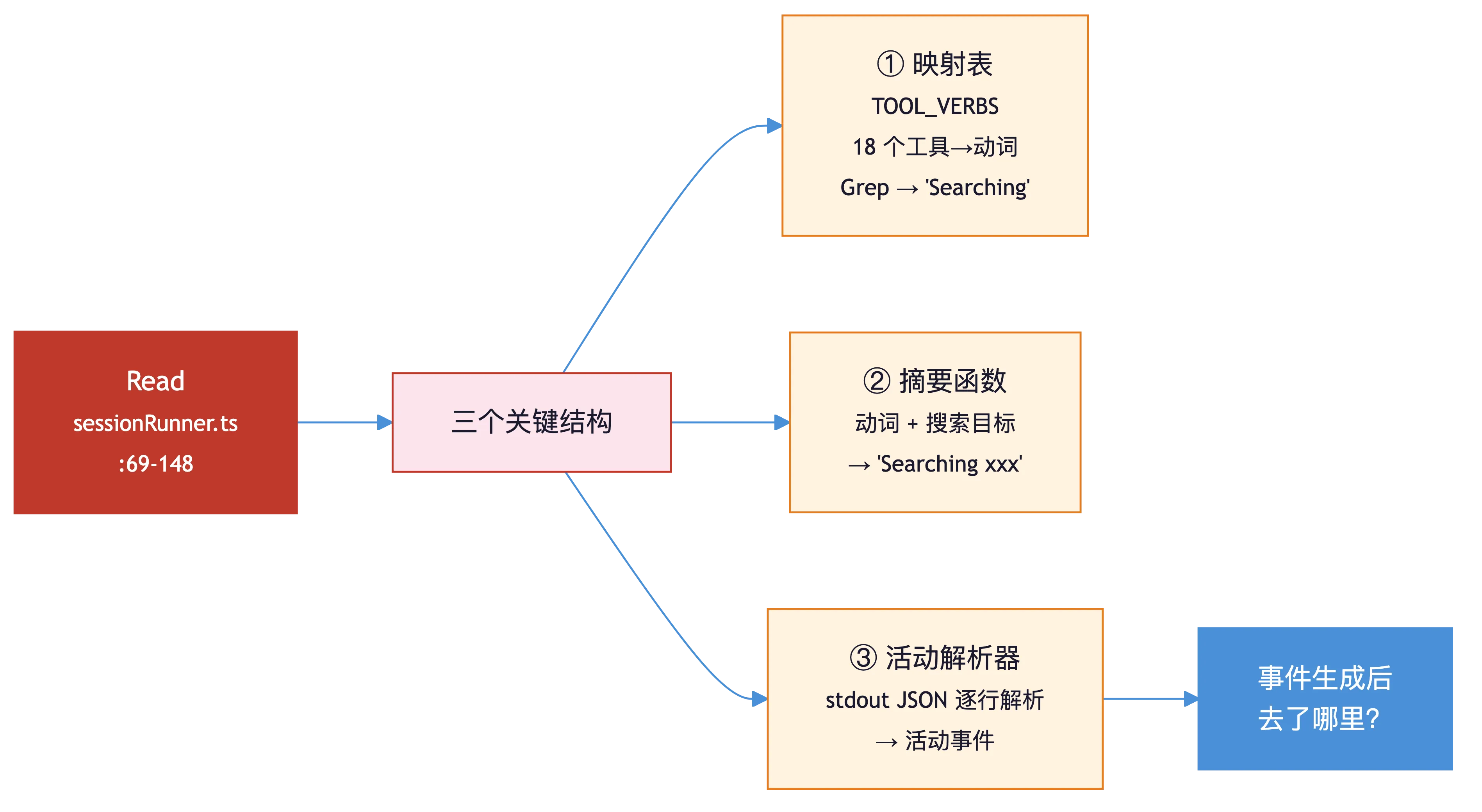
- 追踪链路:Grep搜索
SessionActivity的引用,拼出"session输出JSON→活动解析→bridge主进程轮询→UI渲染"的完整追踪链。
三、性能原理:暴力搜索为什么足够快
Claude Code的Grep并非传统GNU grep,而是基于Rust编写的ripgrep,通过多层过滤和硬件加速,在本地项目规模下实现了毫秒级响应。
3.1 ripgrep的五层过滤机制(乘法叠加缩小范围)
- 目录级剪枝:自动遵守
.gitignore,跳过node_modules等整棵目录子树。 - 路径范围限制:通过
path参数限定遍历起点,例如仅搜索bridge/目录。 - 文件类型过滤:通过
glob参数筛选指定后缀文件(如*.ts)。 - 二进制文件检测:读取文件头字节,自动跳过非文本文件。
- 内容搜索:仅对通过前四层过滤的文件执行正则匹配。
示例效果:在4471个文件的Claude Code源码中,仅通过path=bridge/限制,就将搜索范围从4471个文件缩小到32个。

3.2 文件内搜索的五大加速手段
- SIMD向量化匹配:利用CPU的AVX2指令一次处理32个字节,多模式搜索采用Teddy算法。
- Boyer-Moore跳跃:固定字符串搜索时从末尾比对,不匹配时直接跳过多个字符。
- 操作系统Page Cache:开发者常用项目的文件几乎永久缓存在内存中,避免磁盘I/O。
- mmap零拷贝:大文件采用内存映射,省去内核空间到用户空间的数据复制。
- 多线程并行:线程池并行处理多个文件,结果通过无锁队列汇总。
3.3 实测数据与规模边界
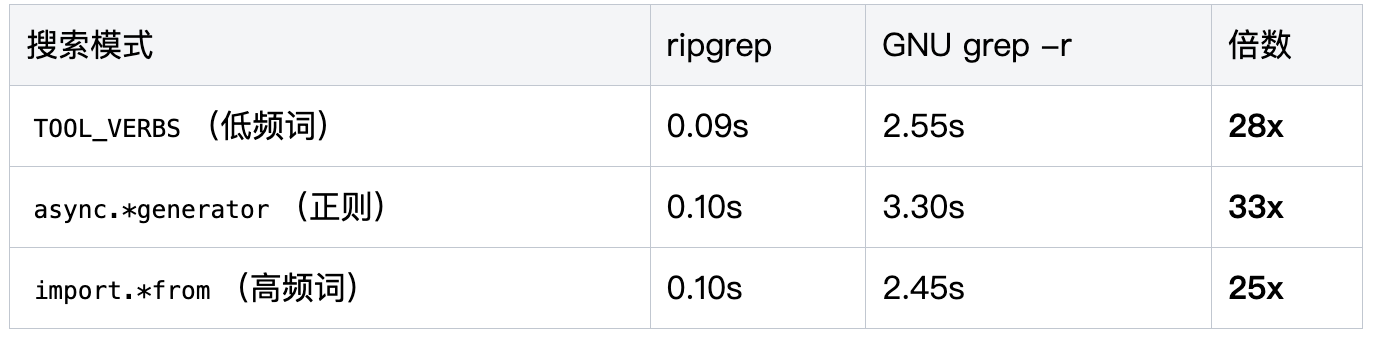
- 性能对比:在4500个文件、95万行代码的Claude Code源码中,ripgrep比GNU grep快25-33倍,单次搜索耗时稳定在0.1秒左右,交互式使用无感知。
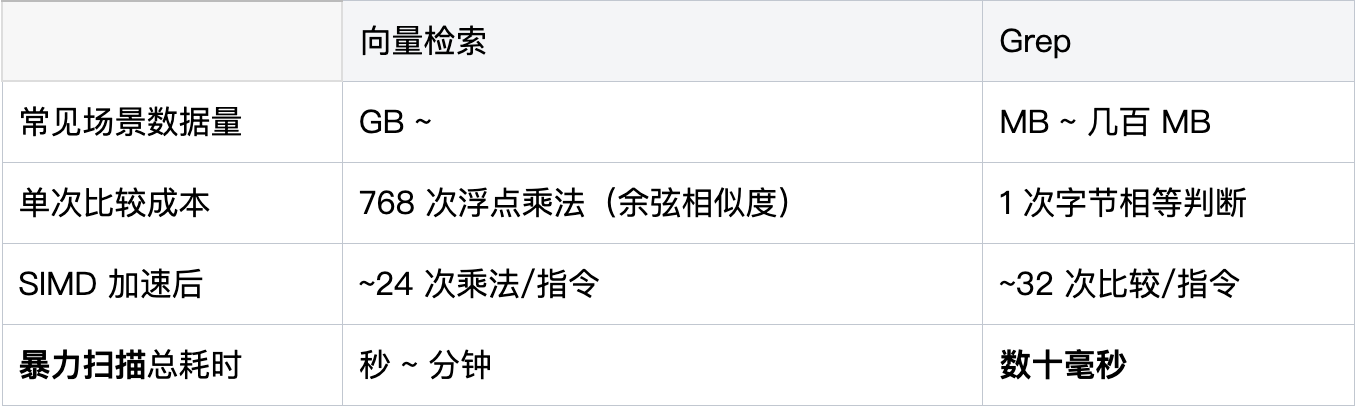
- 规模边界:本地项目(MB~几百MB)是暴力搜索的舒适区,250MB代码库在Page Cache命中时,数据搬运下界仅8毫秒;而向量检索适用于GB级以上数据,单次比较成本远高于Grep(768次浮点乘法 vs 1次字节相等判断)。
四、行业对比与设计哲学
4.1 Cursor vs Claude Code:双索引 vs 零索引
|
维度 |
Cursor(双索引架构) |
Claude Code(零索引架构) |
|
核心路线 |
预处理路线:离线分块、生成embedding、构建索引 |
按需路线:无预处理,LLM实时决定搜索策略 |
|
索引类型 |
1. 语义索引:tree-sitter分块+embedding+向量库 |
无任何索引 |
|
工具优先级 |
Grep为主要探索工具,语义搜索仅用于概念性查询 |
Grep为唯一核心搜索工具 |
|
优势 |
支持大型代码库、跨仓库检索 |
零启动延迟、零维护、无索引过期问题 |
关键结论:架构选择由规模决定。Cursor面向大型代码库(100亿+向量、1000万+代码库),索引是必需;Claude Code面向开发者本地小项目,零索引的工程简洁性更有价值。
4.2 Codex的验证:殊途同归的零索引
OpenAI Codex CLI同样放弃了向量索引,社区提交的向量索引功能请求被官方明确拒绝。两者的核心共识是LLM驱动ripgrep在本地代码场景下优于向量检索,仅在工具封装上存在差异:
- Claude Code:封装专用结构化工具(GrepTool、GlobTool等),LLM无需处理原始shell输出,出错率低。
- Codex:通过通用shell工具执行
rg、find等Unix命令,灵活性更高,但需要模型自行解析非结构化输出。
4.3 Grep方案的成本问题与应对
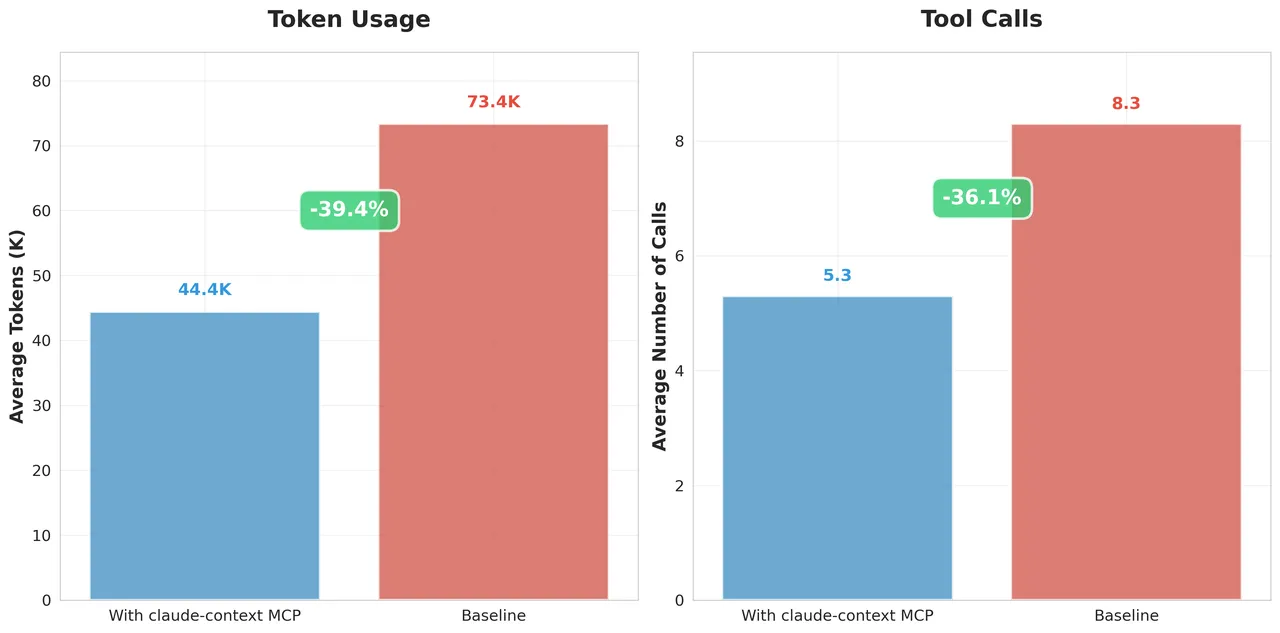
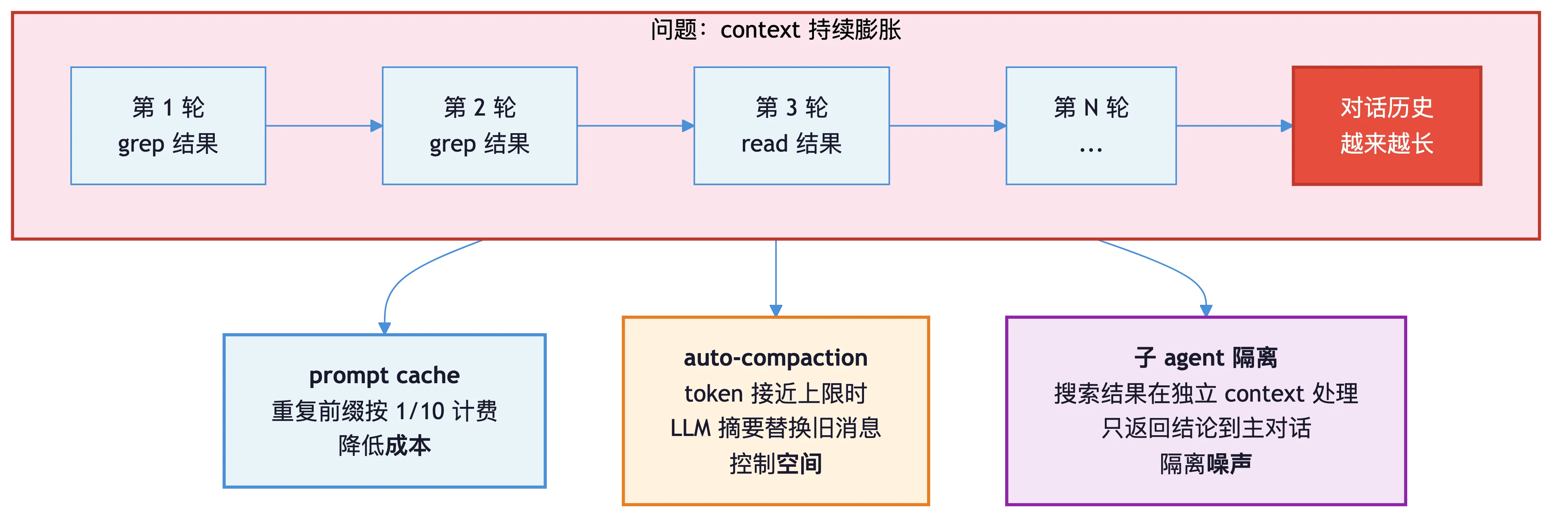
向量数据库厂商Milvus曾批评Grep方案存在token膨胀、时间税、零语义三大问题,Claude Code通过三层工程机制控制成本:
- Prompt Cache:API识别重复的对话前缀,仅对新增增量部分全价计费,前缀部分按1/10缓存价计费,实测agentic循环中92%的前缀可复用,总成本降低约81%。
- Auto-compaction:当token数接近上下文窗口上限时,自动用LLM压缩旧对话历史,用摘要替换原始消息。
- 子Agent隔离:大量搜索中间结果在子Agent上下文消化,主对话仅接收结论。
4.4 Grep的有效性边界:代码 vs 自然语言
- 代码场景:Grep的绝对优势:ISSTA '26的GrepRAG论文验证,单轮Grep检索的代码补全精确匹配率(38.61%)远超传统embedding RAG(24.99%)。核心原因是代码搜索95%的关键词是类名、方法名、变量名等标识符,精确匹配是最直接的语义检索方式。
- 自然语言场景:Grep的短板:自然语言存在严重的词汇不匹配问题,即使通过LLM做查询扩展,召回率仍不如向量检索;当用户仅记得概念特征、无法提供精确关键词时,向量检索仍是最优选择。
五、最终结论:RAG没有死,只是换了形态
- 概念澄清:广义的"检索增强生成(RAG)"范式并未消亡,Claude Code的"LLM驱动Grep→上下文注入→生成回答"完全符合RAG的核心逻辑。真正被淘汰的是"预先分块、embedding、静态一次性检索"的窄义RAG实现。
- 代码场景下Grep替代预索引RAG的三大原因:
-
- 代码本身Grep友好:标识符是程序员预埋的高精度语义锚点。
- 本地项目规模有限:暴力扫描的延迟完全可接受,无需离线索引。
- Agent带来检索模式革命:从"系统预投喂内容"的被动检索,转变为"模型自主迭代探索"的主动检索,多轮搜索可弥补单轮Grep的不足。
- 适用范围:
-
- Grep方案最优:开发者本地中小型代码库、以精确符号匹配为主的任务。
- 仍需向量检索:自然语言软语义问答、超大型代码库、跨仓库检索场景。
- 行业趋势:未来将走向混合搜索架构,例如Cursor正在弱化纯向量搜索、转向Grep+语义的混合模式;Claude Code也引入了LSP语义工具补充Grep的不足。
参考文章:RAG已死?不,是Grep回归了!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)