可学习位置编码与 RoPE 详解
位置编码 核心问题:自注意力机制是排列不变的
自注意力:
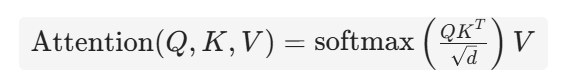
注意力分数:
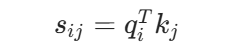
- 自注意力的计算只关心 token 之间的相似度,不关心它们的顺序
可学习位置编码(Learnable Position Embedding)
核心原理:可学习位置编码是数据驱动的方案,完全让模型从数据中学习位置信息
设最大序列长度为 Lmax,模型维度为 d,则位置编码矩阵为:
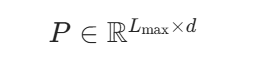
第 i 个位置的位置向量为 pi∈Rd,第 i 个 token 的词嵌入为 ei∈Rd,最终输入为:
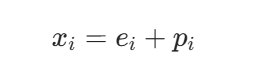
这些位置向量和模型其他参数一起通过梯度下降更新:
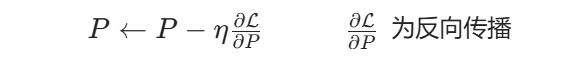
加入注意力后,有 qi=(ei+pi)WQ, kj=(ej+pj)WK,因此注意力分数为:
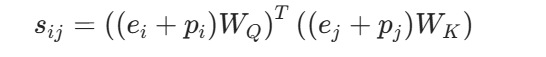
典型应用场景
- 经典 NLP 模型:BERT、GPT-2
- 视觉 Transformer:ViT(视觉 Transformer)
- 短序列任务:分类、短文本匹配等,序列长度固定,不会出现超长输入
旋转位置编码(RoPE, Rotary Position Embedding)
核心思想:RoPE 不直接给输入加位置向量,而是通过“旋转”操作,把位置信息编码到 Query 和 Key 中。
普通注意力分数为 smn=qmTkn。RoPE 先旋转 Query 和 Key:
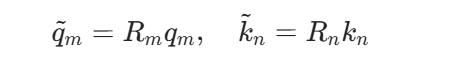
然后计算注意力分数:
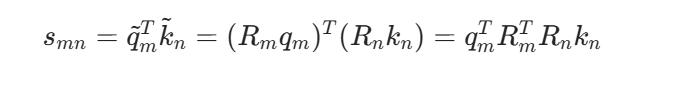
旋转矩阵满足:
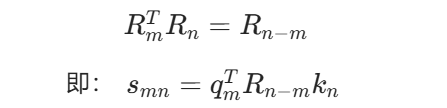
这说明 RoPE 的注意力分数天然包含两个 token 的相对位置 n−m。
RoPE 把向量按两个维度一组拆分,例如 (x0,x1),(x2,x3),…,每组在位置 m 的旋转角度为 mθi,其中:
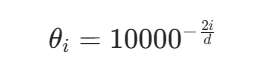
低维度分量中 θi 较大,旋转频率高,适合捕捉短距离位置关系;
高维度分量中 θi 较小,旋转频率低,适合提供长距离位置信号。
典型应用场景
- 大语言模型:LLaMA、Qwen、ChatGLM、RoFormer
- 长文本处理:需要支持超长序列、可变长度的任务
两者核心对比
|
特性 |
可学习位置编码 |
RoPE |
|
参数形式 |
有可训练位置矩阵 P∈RLmax×d |
无额外参数,基于数学规则生成 |
|
核心公式 |
xi=ei+pi |
smn=qmTRn−mkn |
|
位置信息类型 |
绝对位置 |
通过旋转实现相对位置效果 |
|
长度外推性 |
差,超过 Lmax 后难处理 |
较好,适合长序列 |
|
相对性感知 |
弱,需要模型自己学习 |
强,内积自动反映 n−m |
|
典型应用模型 |
BERT、GPT-2、ViT |
LLaMA、Qwen、ChatGLM、RoFormer |

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)