构建中文版的 nanoGPT - 原始版本 nanoGPT 的分词(tokenization)
构建中文版的 nanoGPT - 原始版本 nanoGPT 的分词(tokenization)
flyfish
参考网址
https://github.com/shaoshengsong/nanoGPT-cn
- tokenizer = 分词器(训练出来的模型/工具)
- tokenization = 分词(这个过程)
- token = 词元(分词后最小单元)
- tokenize = (动词)执行分词
token 是模型用来表示自然语言文本的基本单位,即是模型用来表示自然语言文本的的最小单位。可以直观的理解为字或词;通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token,不同的分词器有不同的分法,有的可能一个汉字为0点几个token。
tiktoken 是 OpenAI 官方开发的 Python 工具,专门给 GPT 系列模型(GPT2/GPT3/GPT4) 用的 分词器。
karpathy用在了他的nanoGPT
参考地址
https://github.com/karpathy/nanoGPT
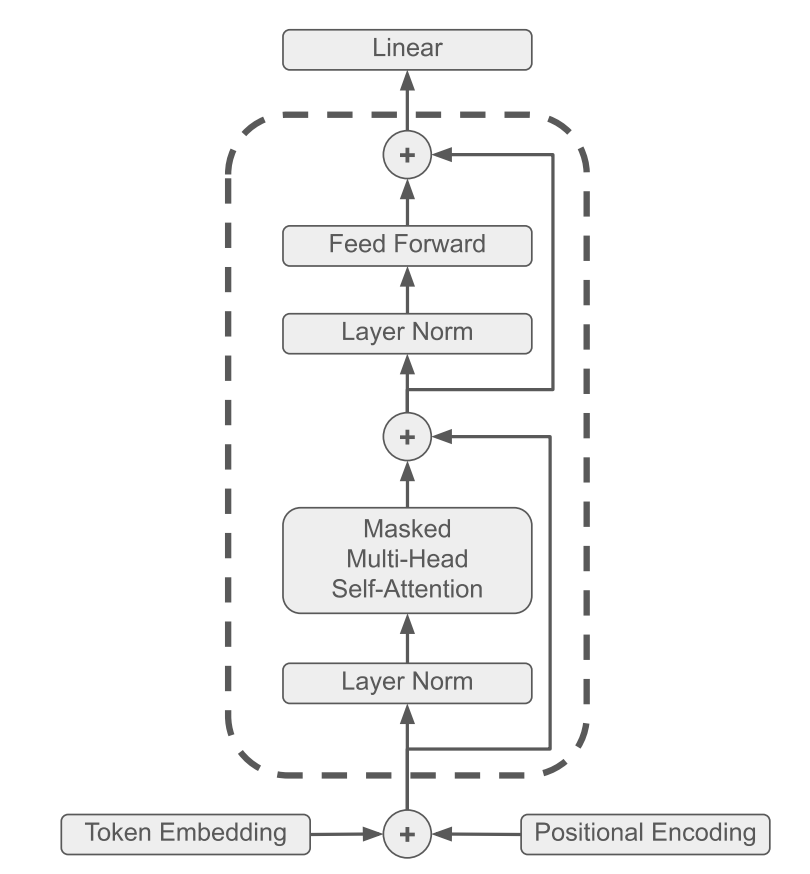
分词(Tokenization)必须在 Embedding(嵌入层)之前
先做分词器(数据预处理阶段)
原始文本是人类语言(字符串),模型完全看不懂,必须先用 tiktoken 分词器把文本切成小单元 → 转成数字 Token IDs → 存成二进制文件,这是把文本转成模型能识别的数字,是所有步骤的第一步。
后做嵌入层编码(模型运行阶段)
等数据加载、转成 Tensor、迁移到 GPU/CPU 后,才会进入 Token Embedding/Position Embedding(嵌入层),这是把数字转成模型能计算的向量,属于模型内部的第一层操作。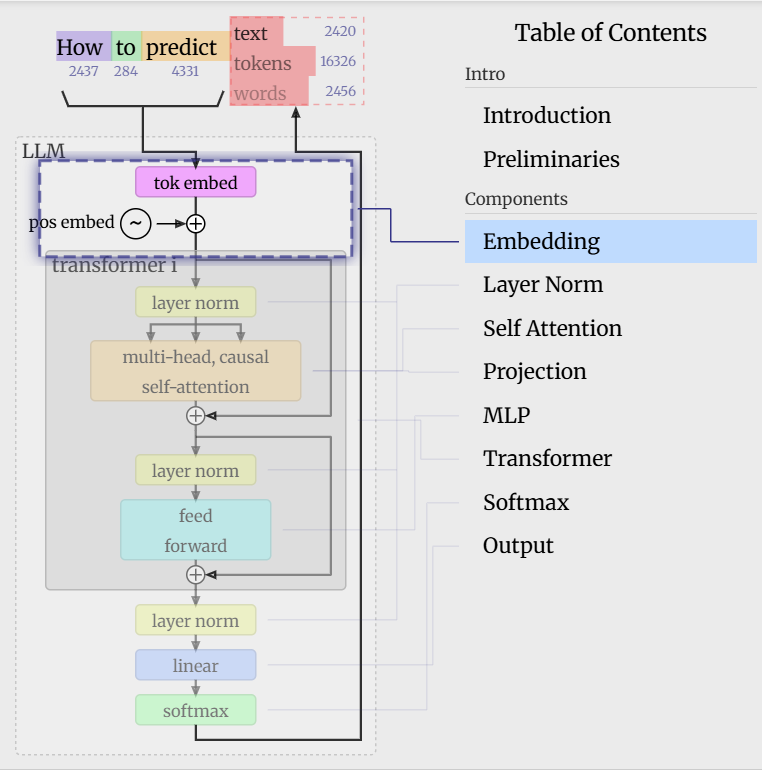
文本
→ 分词器(tiktoken)
→ Token IDs
→ 二进制文件(.bin)
→ 数据加载(get_batch)
→ Tensor转换 + 设备迁移
→ Token Embedding (wte) Word Token Embedding
→ Position Embedding (wpe) Word Position Embedding
→ 向量相加 + Dropout
→ 送入 Transformer 编码器
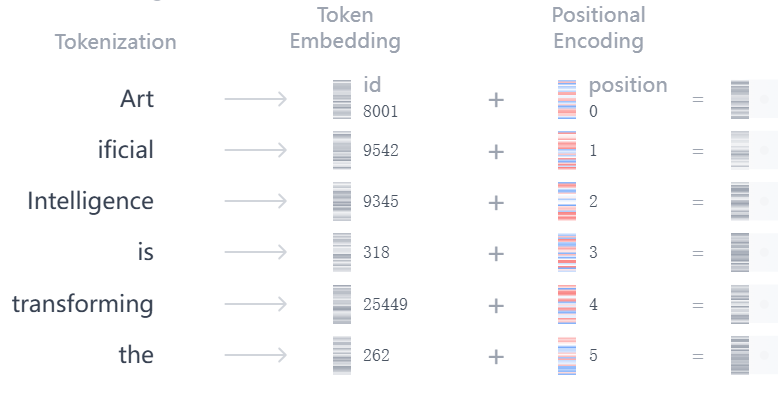
tiktoken 就是专门用来做 Tokenization(分词 )的工具库
文本 → 分词器(tiktoken) → Token IDs
完整的 Tokenization 过程:
分词:把人类的自然语言文本,切割成模型能处理的最小单元(Token,比如单词、子词、符号);
编码:把这些 Token 一一映射成数字 Token IDs。
如果下载不了GPT-2 分词器词表文件,可以从这里下载
import tiktoken
enc = tiktoken.get_encoding("gpt2")
# 查看词汇表大小
print(f"Vocab size: {enc.n_vocab}") # 输出: 50257
# 查看最大 token 值
print(f"Max token value: {enc.max_token_value}") # 输出: 50256
# 测试编码
text = "Hello, world!"
tokens = enc.encode(text)
print(f"Tokens: {tokens}")
输出
Vocab size: 50257
Max token value: 50256
Tokens: [15496, 11, 995, 0]
上面的代码等同于 下面的代码
假如已经下载了 encoder.json vocab.bpe
encoder.json = 文字数字对照表
vocab.bpe = 单词拆分手册
encoder.json(词汇对照表):记录「文本片段 → 数字ID」的一一映射,是 Token ID 的编码依据
vocab.bpe(BPE规则文件):定义文本拆分规则,负责把长文本、长单词拆分为模型认识的最小 Token 单元
import os
import json
from tiktoken.core import Encoding
from tiktoken.load import data_gym_to_mergeable_bpe_ranks
SAVE_DIR = "./gpt2_tokenizer" # 本地两个文件的路径
# ======================================================================
def load_gpt2_auto():
# 1. 找到本地两个文件的路径
encoder_path = os.path.join(SAVE_DIR, "encoder.json")
bpe_path = os.path.join(SAVE_DIR, "vocab.bpe")
# 2. 加载词汇表
mergeable_ranks = data_gym_to_mergeable_bpe_ranks(
vocab_bpe_file=bpe_path,
encoder_json_file=encoder_path
)
# 3. GPT2固定分词规则
pat_str = r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
# 4. 创建分词器
return Encoding(
name="gpt2",
pat_str=pat_str,
mergeable_ranks=mergeable_ranks,
special_tokens={"<|endoftext|>": 50256}
)
enc = load_gpt2_auto()
print(f"Vocab size: {enc.n_vocab}")
print(f"Max token value: {enc.max_token_value}")
text = "Hello, world!"
tokens = enc.encode(text)
print(f"Tokens: {tokens}")
输出
Vocab size: 50257
Max token value: 50256
Tokens: [15496, 11, 995, 0]
以文本 Hello, world! 为例,完整复现转换过程:
- 文本输入:Hello, world!
- tiktoken分词:得到 Token ID 序列 [15496, 11, 995, 0]
- WTE转换:4 个 Token ID 查表,生成 4 组 768 维语义向量
- WPE转换:生成 4 组对应位置的 768 维位置向量
- 向量融合:语义+位置向量相加,得到最终输入特征
- 模型输入:送入 Transformer
| 模块 | 全称 | 作用 | 矩阵尺寸(GPT2) |
|---|---|---|---|
| WTE | Word Token Embedding | 为 Token 注入语义信息 | [50257, 768] |
| WPE | Word Position Embedding | 为 Token 注入时序位置信息 | [1024, 768] |

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)