opencode 原理学习提纲
1. opencode 的 agent 原理资料。
OpenCode 的详细介绍、核心原理和学习教程。
什么是 OpenCode?
OpenCode 是一个开源的终端原生 AI 编程 Agent(类似 Claude Code),用 Go 语言编写,在 GitHub 拥有超过 20k+ stars。它的核心理念是不绑定任何 LLM 提供商,支持 Claude、GPT、Gemini、DeepSeek 等 75+ 种模型,甚至本地模型。
官方网站: opencode.ai
核心原理与架构
1. 客户端/服务器架构(Client/Server)
OpenCode 采用独特的 C/S 架构:
- 你可以在电脑上运行 OpenCode 服务端
- 通过 TUI(终端界面)、手机 App 或 Web 界面远程连接
- 这意味着 TUI 只是众多客户端中的一种可能性
2. ACP(Agent Client Protocol)协议层
这是 OpenCode 的重要创新。ACP 是一个完整的中间调解层,负责:
- 连接管理和会话状态维护
- 将 OpenCode 运行时的事件流转发给外部客户端
- 权限处理:当 Agent 需要编辑文件等敏感操作时,ACP 向外部客户端请求决策(而非假设终端提示),这对 IDE 集成至关重要
- 支持编辑器特定的 URI(如
zed://),信号了与 Zed 编辑器的集成路径
ACP 让编码 Agent 成为**“协议化的本地服务”**,任何编辑器都可以托管,而不需要为每个 Agent 写定制插件。
3. 多 Agent 模式
OpenCode 内置多种 Agent 角色(可通过 Tab 切换):
| Agent | 功能 |
|---|---|
| build | 默认模式,拥有完整文件编辑和命令执行权限 |
| plan | 只读模式,用于代码分析和探索,编辑前会请求许可 |
| general | 子 Agent,用于复杂搜索和多步任务 |
4. 项目上下文管理(AGENTS.md)
- 通过
/init命令分析项目结构 - 自动生成
AGENTS.md文件作为项目的"家规" - 每次会话自动读取,让 Agent 理解项目架构和编码规范
安装与快速开始教程
第一步:安装
# 推荐方式(一键安装)
curl -fsSL https://opencode.ai/install | bash
# 或 npm 安装
npm install -g opencode-ai
# macOS 用 Homebrew
brew install anomalyco/tap/opencode
# Windows 用 scoop/choco
scoop install opencode
choco install opencode
第二步:认证
# 交互式选择提供商并登录
opencode auth login
# 查看已登录的提供商
opencode auth list
# 或在 TUI 内输入 /connect
支持的提供商包括:OpenCode Zen(官方推荐)、Claude(Anthropic)、GPT(OpenAI)、Gemini(Google)、OpenRouter、本地模型等。
第三步:启动使用
cd ~/your-project
opencode
常见初次使用命令:
explain what this codebase does— 解释项目add a README section about installation— 写文档find and fix the failing test in src/api.test.ts— 修测试
第四步:初始化项目配置
/init
这会生成 AGENTS.md 文件,建议将其提交到 Git,让整个团队共享。
核心使用方式
TUI 模式(交互式)
opencode
# 进入交互界面后,用自然语言描述需求
一次性命令模式
opencode run "your prompt here" # 执行并退出
opencode run "fix the bug" --continue # 继续上次会话
opencode run "task" --model anthropic/claude-sonnet-4 # 指定模型
opencode run "task" --format json # 机器可读输出
IDE 集成
OpenCode 可与 VS Code、Cursor、Windsurf 等集成:
- 在集成终端中运行
opencode,扩展会自动安装 - 快捷键:
Cmd/Ctrl + Esc快速启动 Cmd/Ctrl + Alt + K插入文件引用(如@File#L37-42)
生态系统与扩展
基于 OpenCode 构建的扩展生态非常丰富:
| 扩展 | 功能 |
|---|---|
| OpenAgentsControl (OAC) | 计划优先的开发工作流,带审批门控 |
| OpenCode Swarm | 多 Agent 协作(架构师、编码器、测试工程师、审查员) |
| opencode-coder | Dynatrace 出品的企业级插件系统 |
| opencode-agent-browser | 无头浏览器自动化 |
| OpenCode Notify | 桌面通知系统 |
与 Claude Code 的关键区别
| 特性 | OpenCode | Claude Code |
|---|---|---|
| 开源 | ✅ 100% 开源 | ❌ 闭源 |
| 模型绑定 | 支持任意提供商 | 仅 Anthropic |
| LSP 支持 | ✅ 开箱即用 | 有限 |
| 架构 | C/S 架构,可多客户端连接 | 单体架构 |
| 协议层 | ACP 协议标准化 | 无 |
| 终端体验 | TUI 重点优化(Neovim 用户打造) | 基础终端 |
推荐学习资源
- 官方文档: opencode.ai/docs
- GitHub 仓库: github.com/sst/opencode
- 快速上手仓库: OpenCode-Everything-You-Need-to-Know
- OpenAgentsControl 文档: 学习计划优先的 Agent 工作流
- OpenCode Swarm 文档: 学习多 Agent 协作模式
总结
以 OpenCode 为代表的现代 AI Agent 的核心原理可以概括为:“协议化、模型无关、上下文感知”。通过 ACP 协议层将 Agent 能力与客户端解耦,通过 AGENTS.md 实现项目上下文的持久化理解,通过多 Agent 协作(build/plan/subagent)实现复杂任务的分解与执行。这种模式正在成为 AI 编程工具的新标准。
2. 进一步的资料
以 OpenCode 为代表的 AI Coding Agent,其底层并不是某种全新的机器学习模型,而是将已有的大语言模型(LLM)通过特定的**推理架构(Agentic Architecture)**进行工程化封装。以下是它依赖的核心机器学习/AI 原理及推荐教材。
一、核心机器学习原理
1. ReAct(Reasoning + Acting)— 最重要的基础框架
这是 OpenCode 等 Agent 最底层的运作范式,来自论文 ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., ICLR 2023)。
核心思想:让 LLM 交替生成 推理(Thought) 和 行动(Action):
用户输入任务
↓
Thought: "我需要先查看项目结构"
↓
Action: 调用 Glob("**/*.ts") 搜索文件
↓
Observation: [返回文件列表]
↓
Thought: "找到了相关文件,接下来读取内容"
↓
Action: 调用 Read("src/index.ts")
↓
Observation: [返回代码内容]
↓
... 循环直到任务完成
↓
Action: Finish[最终回答]
为什么重要:纯推理(如 Chain-of-Thought)无法获取外部信息,容易产生幻觉;纯行动(如直接调用工具)缺乏高层次规划能力。ReAct 将两者结合,实现了**“边想边做”**。
2. Chain-of-Thought (CoT) — 思维链推理
来自论文 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., NeurIPS 2022)。
原理:通过在 prompt 中提供"逐步思考"的示例,引导 LLM 将复杂问题分解为连续的推理步骤。
在 OpenCode 中,CoT 体现在:
- 系统提示(system prompt)要求模型展示完整的思考过程
- 复杂的编辑任务会被分解为"分析 → 定位 → 修改 → 验证"
3. Function Calling / Tool Use(工具调用)
这是 LLM 与外部世界交互的核心机制。相关里程碑论文:
| 论文 | 作者 | 贡献 |
|---|---|---|
| Toolformer | Schick et al. (2023) | LLM 自学使用外部工具 |
| Gorilla | Patil et al. (2023) | LLM 连接海量 API |
| ToolLLM | Qin et al. (2023) | 掌握 16000+ 真实 API |
技术本质:LLM 不直接执行代码,而是生成结构化的 JSON 来"请求"调用某个预定义工具。框架接收到这个 JSON 后执行相应操作,再将结果反馈给 LLM。
4. LATS(Language Agent Tree Search)— 高级规划
来自论文 LATS: Unifying Reasoning, Acting, and Planning in Language Models。
原理:将 ReAct 与**蒙特卡洛树搜索(MCTS)**结合:
- 维护一棵"思考-行动"树
- 每个节点代表一个推理步骤
- 通过模拟和评估选择最优路径
适用场景:复杂的多步骤任务,需要回溯和探索多种方案时。
5. Reflexion — 自我反思
来自论文 Reflexion: Self-Reflective Agents。
原理:Agent 在执行任务后,对自己的输出进行"反思"——检查是否正确、是否有更好的方法,并将这些反思存入记忆,用于改进后续行动。
在 OpenCode 中,当模型发现之前的修改导致测试失败时,会表现出类似的反思行为。
6. Context Engineering(上下文工程)
正如 OpenCode 创始人所强调的:“Context is the bottleneck. Not the model. Not the prompt.”
核心问题:
- Agent 没有真正的"记忆",只有上下文窗口(context window)
- 所有项目信息、工具结果、历史对话都挤在有限的 token 中
- 上下文管理决定 Agent 的表现
关键技术:
- AGENTS.md:项目级别的上下文注入
- 上下文压缩:选择性保留重要信息
- Skills 系统:将常用能力编码为可复用的 prompt 片段
二、推荐教材与资源
必读论文(按重要性排序)
基础必读:
-
ReAct: Synergizing Reasoning and Acting in Language Models — Yao et al., ICLR 2023
- arXiv:2210.03629
- Agent 架构的奠基之作
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models — Wei et al., NeurIPS 2022
- arXiv:2201.11903
- 思维链推理的开山之作
-
Toolformer: Language Models Can Teach Themselves to Use Tools — Schick et al., 2023
- arXiv:2302.04761
- 工具学习的里程碑
-
LATS: Language Agent Tree Search Unifies Reasoning, Acting, and Planning — 2023
- arXiv:2310.04406
- 高级规划机制
综述与拓展:
5. Tool Learning with Large Language Models: A Survey — Qu et al., 2024
- 工具学习领域的全面综述
- SoK: Agentic Skills — Beyond Tool Use in LLM Agents — Jiang et al., 2026
- 技能系统的前沿综述
在线学习资源
OpenCode 源码分析(强烈推荐):
- 📖 AIエージェントの推論プロセスを読み解く:OpenCodeのコードリーディングから
- 逐行解读 OpenCode 如何实现 ReAct 循环、工具调用和上下文管理
工程实践:
-
理解现代 Agent 的三层架构
-
📖 Tool-Augmented LLM Agents: Production Architecture Patterns
-
生产级工具调用架构设计
论文合集:
- 📖 Awesome LLM Agent Skills Papers
- curated 的 Agent 技能论文列表
书籍推荐
| 书名 | 作者 | 适合人群 |
|---|---|---|
| 《动手学大语言模型》 | 上海交通大学团队 | 中文读者,系统了解 LLM 原理与工具调用 |
| 《AI Agent 从 0 到 1》 | various | 中文实战教程,涵盖 ReAct、CoT 等实现 |
| 《Natural Language Processing with Transformers》 | Tunstall et al. | Transformer 基础与 HuggingFace 实践 |
| “Build LLM Apps” | various | 英文,聚焦 LLM 应用开发 |
三、一句话总结
OpenCode 这类 Agent 的"智能"并非来自某个专门训练的 Agent 模型,而是来自 ReAct 循环架构 + Function Calling 机制 + 精心设计的上下文管理 这三者的工程组合。LLM 只是推理引擎,真正的魔力在于如何组织推理与行动的交替循环。
3. 解读 AI Agent 的推理过程:从 OpenCode 源码阅读出发
原文作者:tsurubee(SAKURA internet 研究员)
原文链接:https://zenn.dev/tsurubee/articles/ai-agent-reasoning-from-opencode
翻译整理日期:2026/05/30
目录
开篇:Agent 的能力不只来自模型的聪明程度
日常使用 Claude Code 或 OpenCode 等 AI 编码 Agent 时,我们常常惊叹于它们输出结果的高质量。这种时候,人们很容易将目光投向各家公司最新的前沿模型本身。但冷静想想,产出优质输出的原因,绝不仅仅是模型自身的能力。
这些 Agent 如何调用 LLM、如何处理它的响应、又如何将响应连接到下一个动作——这种**“推理过程的设计”**,才是左右 Agent 实力的另一个关键要素。然而,日常我们只是作为工具使用者,这一部分对我们来说完全是黑箱。
本文将一边阅读开源 AI 编码 Agent OpenCode (anomalyco/opencode) 的源代码,一边解读 Agent 的推理过程是如何实现的。同时,也会介绍其背后的理论框架及相关重要论文。
理论篇:Agent 推理的框架
在深入代码之前,先确认理解 AI Agent 推理过程所需的理论基础。
Chain-of-Thought Prompting(Wei et al., 2022; Kojima et al., 2022)
论文:
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., NeurIPS 2022, arXiv:2201.11903)
- Large Language Models are Zero-Shot Reasoners (Kojima et al., NeurIPS 2022, arXiv:2205.11916)
**Chain-of-Thought(CoT)**是一种让 LLM 不仅生成最终答案,还生成中间的推理过程(思考链),从而提升复杂推理任务准确率的技术。
Wei 等人提出的 few-shot CoT 通过在提示词中加入少量包含推理过程的示例,大幅改善了算术推理和常识推理的性能。Kojima 等人则将这一思路进一步延伸,发现即使不给任何示例,仅在提示词末尾加上一句"Let’s think step by step(让我们一步一步地思考)"就能达到类似效果(zero-shot CoT)。两者是互补关系,从不同角度验证了 CoT 的有效性。

在 Agent 语境下的重要性: CoT 提供了内部推理能力的底层支撑。后文介绍的 ReAct 中的 “Thought”(思考)部分正是 CoT 的应用,它为 Agent 在采取行动前"将应该做什么用语言表达出来"这一机制提供了理论根基。
ReAct: Synergizing Reasoning and Acting(Yao et al., 2023)
论文:
- ReAct: Synergizing Reasoning and Acting in Language Models (ICLR 2023, arXiv:2210.03629)
ReAct 是当前 AI Agent 推理过程中最具基础性的框架之一。其核心思想是让 LLM 的 推理(Reasoning) 与 行动(Acting) 交替生成,从而实现两者的协同效应。
具体而言,循环按以下方式运转:
Thought: 分析当前任务状况,推理下一步该做什么
Action: 调用外部工具(搜索、文件操作等)
Observation: 接收工具执行结果
Thought: 将 Observation 结果纳入上下文,推理下一步行动
Action: ...(重复)
...
Action: Finish[最终回答]
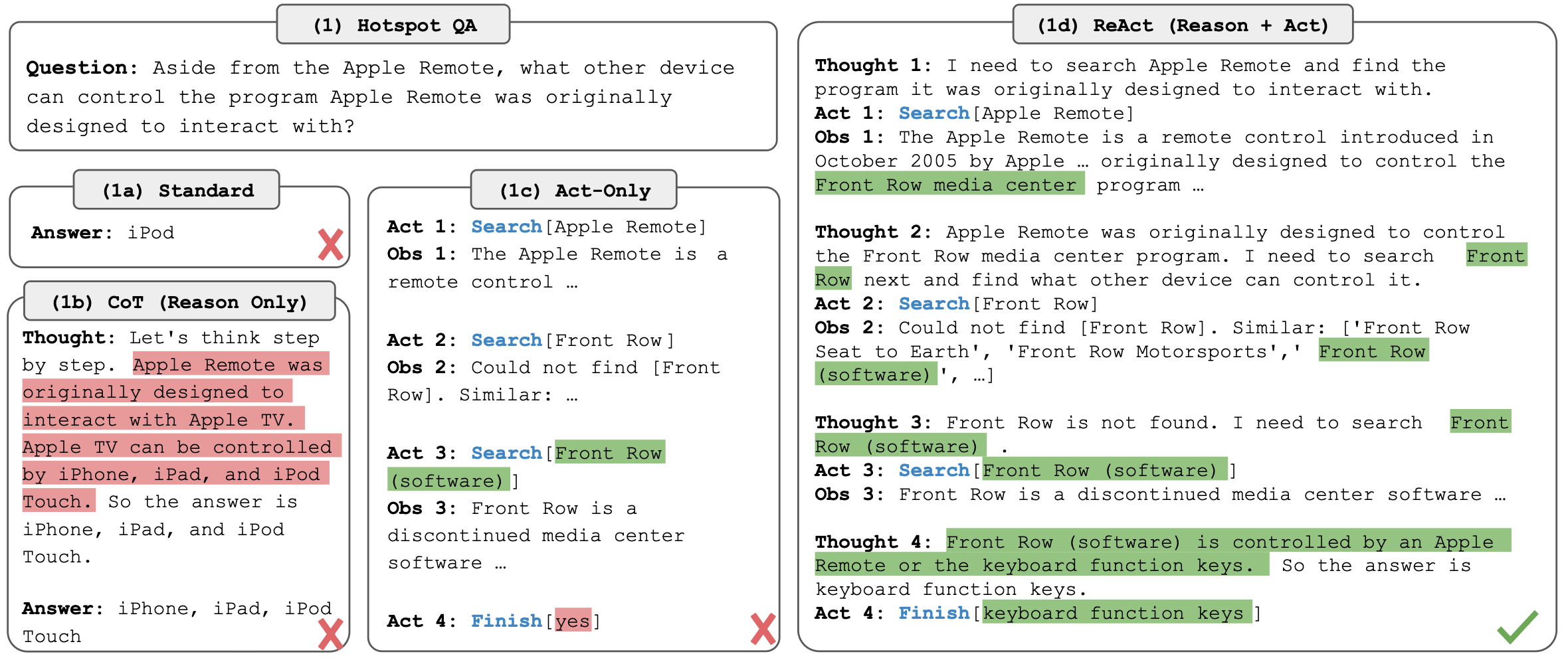
ReAct 的重要贡献在于同时解决了两个局限:仅靠推理(仅有 CoT)无法访问外部信息,容易产生幻觉;仅靠行动(仅有动作生成)无法做高层次的计划制定和异常处理。这一 ReAct 模式已成为现代编码 Agent 实现中的主流架构。
从理论到实现
基于这些理论,AI 编码 Agent 的核心就是 ReAct 循环的实现——即 用户输入 → LLM 推理 → 工具执行 → 结果反馈 → 再推理 的循环。但要让这一循环成为实用的工具,还需要在系统提示词设计(控制 Agent 的行为)以及上下文管理(将长对话历史压缩进模型的上下文窗口)等方面下功夫。
下一节将通过 OpenCode 的源代码,看看这些是如何实现的。
实现篇:OpenCode 源码阅读
OpenCode (anomalyco/opencode) 是一个用 TypeScript 编写的开源 AI 编码 Agent,截至 2026 年 2 月已获得 10 万以上 GitHub Star。它采用客户端-服务端架构,多个前端(CLI、TUI、桌面端、Web)通过共同的后端 API 使用推理功能。推理的核心逻辑集中在服务端(packages/opencode/src/session/)。
注: 本文的源码阅读基于 commit 572a037e5 的源代码。未来版本更新可能导致结构变化,请注意。此外,本文展示的代码片段侧重于把握整体流程而非细节实现,部分代码经过简化。准确实现请参考上述 commit 的源代码。
ReAct 循环的整体图景
理论篇中看到的 ReAct 的 Thought → Action → Observation → … → Finish 循环,在 OpenCode 中是如何实现的呢?首先,让我们看看 ReAct 的各个步骤对应 OpenCode 的哪些组件。
| ReAct 步骤 | OpenCode 中的实现 | 负责文件 |
|---|---|---|
| Thought(推理) | 系统提示词 + LLM 的文本输出 / Extended Thinking | system.ts, processor.ts |
| Action(行动) | LLM 生成的工具调用(tool-call 事件) |
processor.ts, tool/*.ts |
| Observation(观察) | 工具执行结果记录到消息历史(tool-result 事件) |
processor.ts |
| Finish(结束) | LLM 以纯文本(而非工具调用)完成响应 | prompt.ts(循环终止判断) |
驱动这一切的是 session/prompt.ts 中的 while(true) 循环。以下代码标注了各注释对应上表中的哪个步骤:
// prompt.ts > SessionPrompt.loop(简化版)
while (true) {
// 获取到目前为止的消息历史(包含上一次的 Observation)
let msgs = await MessageV2.filterCompacted(MessageV2.stream(sessionID))
// ── Finish 判定 ──
// 如果 LLM 在上一次已以非工具调用的原因结束响应,则退出循环
if (lastAssistant?.finish && !["tool-calls", "unknown"].includes(lastAssistant.finish)) {
break
}
// ── Action 的准备 ──
// 解析 LLM 可以选择的工具列表
const tools = await resolveTools({ agent, session, model, ... })
// ── Thought + Action + Observation ──
// 调用 LLM。在这 1 次调用中:
// 1. LLM 进行推理(Thought:文本输出或 extended thinking)
// 2. LLM 选择工具(Action:tool-call 事件)
// 3. 工具被执行,结果记录下来(Observation:tool-result 事件)
const result = await processor.process({ system, messages, tools, model })
if (result === "stop") break
continue // 如果发生了工具调用,回到循环开头进入下一个 Thought
}
下面详细看看各步骤的实现。
Thought:LLM 如何思考
循环中的位置: processor.process() 中,LLM 生成文本或推理 token 的阶段。
ReAct 中的 Thought 是 LLM 分析当前状况并推理下一步行动的阶段。这也是理论篇中介绍的 Chain-of-Thought 的应用。
在 OpenCode 中,Thought 以 两种形式 呈现。查看 processor.ts 的流式事件处理就能清楚理解这一点。
1. 文本输出(text-* 事件)
这是所有模型共有的、最基本的 Thought 形态,即 LLM 生成的普通文本响应。例如"这个 Bug 的原因是○○,首先我们来确认一下△△"这类输出。它出现在工具调用的前后,LLM 的推理过程就这样被直接可视化。
在 processor.ts 中,以 text-start → text-delta → text-end 的事件序列处理:
// processor.ts(简化版)
case "text-start":
currentText = { type: "text", text: "", /* ... */ }
break
case "text-delta":
currentText.text += value.text // 文本以流式方式累积
break
2. Extended Thinking(reasoning-* 事件)
这是 Claude 等部分模型支持的额外 Thought 通道。它在文本输出之前生成,通过更具试错性、探索性的推理来增强 Thought 的质量。在 Extended Thinking 中进行深入思考后,其结论以文本输出或工具调用的形式呈现。OpenCode 将其作为 reasoning 类型的独立部分记录。
// processor.ts(简化版)
case "reasoning-start":
const reasoningPart = {
type: "reasoning",
text: "",
metadata: value.providerMetadata, // 也保留提供商特有的元数据
// ...
}
break
case "reasoning-delta":
part.text += value.text // 推理过程以流式方式累积
break
两者的关系总结如下:
| 文本输出 | Extended Thinking | |
|---|---|---|
| 事件 | text-* |
reasoning-* |
| 记录类型 | TextPart | ReasoningPart |
| 生成顺序 | 后 | 先(在文本输出和工具调用之前) |
| 作用 | Thought 的基本通道(推理 + 响应) | Thought 的增强通道(深度思考) |
| 支持模型 | 全部模型 | Claude 等部分模型 |
Extended Thinking 并非取代文本输出的 Thought,而是在其前段进行更深入的推理,从而提升 Thought 整体质量。不支持 Extended Thinking 的模型中,文本输出成为唯一的 Thought 通道,同时承担推理与响应。两种形态都会被记录到消息历史中,在下次循环迭代时传递给 LLM,因此都直接作为 ReAct 循环的 Thought 发挥作用。
系统提示词的关键作用
左右推理质量的还有系统提示词。OpenCode 在 system.ts 中按模型家族选择不同的系统提示词:
// system.ts(简化版)
export function provider(model: Provider.Model) {
if (model.api.id.includes("gpt-5")) return [PROMPT_CODEX]
if (model.api.id.includes("gpt-") || model.api.id.includes("o1") || model.api.id.includes("o3"))
return [PROMPT_BEAST]
if (model.api.id.includes("gemini-")) return [PROMPT_GEMINI]
if (model.api.id.includes("claude")) return [PROMPT_ANTHROPIC]
return [PROMPT_ANTHROPIC_WITHOUT_TODO]
}
同一 Agent,因连接的模型不同,控制 Thought 行为的提示词也会改变。这是为了适配各模型的指令跟随性和 Function Calling 能力的差异。实际提示词存放在 session/prompt/ 目录下,对比阅读非常有趣。特别值得注意的是任务管理指令方式的差异。
OpenCode 有一个名为 TodoWrite 的内置工具(tool/todo.ts)。这是 LLM 用于任务计划和进度管理的工具,可以将任务列表化(如"1. 执行构建 → 2. 修复类型错误 → 3. 运行测试"),完成一项就更新状态。TodoWrite 工具本身在 registry.ts 中对所有模型提供,但系统提示词中的强调程度因模型而异。
例如,Claude 专用的 anthropic.txt 中反复强调了 TodoWrite 的使用:
“Use these tools VERY frequently to ensure that you are tracking your tasks and giving the user visibility into your progress.”
(要非常频繁地使用这些工具,确保你正在追踪任务并向用户展示进度。)“If you do not use this tool when planning, you may forget to do important tasks - and that is unacceptable.”
(如果在计划时不用这个工具,你可能会忘记重要任务——这是不可接受的。)
为什么这么强调? 因为 ReAct 循环的特性,LLM 是逐个步骤顺序推进的,在复杂任务中很容易"迷失"——不知道自己在整体任务中的哪个位置。TodoWrite 通过让 LLM 显式管理任务列表来缓解这一问题。此外,TodoWrite 的结果会持久化到数据库,在 TUI 和桌面应用的 UI 中以勾选列表形式展示(如"3 of 5 todos completed")。这不是 LLM 的内部备忘录,而是让用户能实时查看进度的机制。
另一方面,GPT 系列的 beast.txt 中根本没有提及 TodoWrite 工具,取而代之的是"用反引号将 Markdown 的 todo 列表包围起来显示"这种基于文本的任务管理指示。Gemini 专用的 gemini.txt 中则不包含任何任务管理相关指令。
可见,面对"不要迷失任务"这一相同问题,不同模型采用了不同的应对策略:对 Claude 强烈促使其使用专用工具,对 GPT 系列要求其以文本输出自我管理,对 Gemini 则不做任务管理要求。这是根据各模型的工具使用能力和指令跟随性差异所做的设计。
指令的描述风格也有差异。Claude 用提示词比较简洁,是信任模型能力的写法。相比之下,Gemini 的 gemini.txt 则详细规定每一步,甚至包含"输出以 3 行以内为目标""1 + 2 → 3"这样的具体示例,是非常细致的指令。
当连接的模型不属于 GPT 系列、Gemini 或 Claude 中的任何一种时,默认使用 qwen.txt 作为系统提示词。代码中以 PROMPT_ANTHROPIC_WITHOUT_TODO 变量名引用它,顾名思义是不含 TodoWrite 指示的版本。与 Gemini 提示词类似,它包含丰富的控制响应风格的具体示例("1 + 2 → 3""输出 4 行以内"等)。
Action:LLM 如何行动
循环中的位置: processor.process() 中,LLM 生成 tool-call 事件的阶段。可调用的工具由前一步的 resolveTools() 已确定。
ReAct 中的 Action 是 LLM 决定调用外部工具的阶段。OpenCode 中,LLM 响应中包含的工具调用(tool-call 事件)即对应此阶段。
LLM 能选择的工具由 prompt.ts 中的 resolveTools 函数决定。该函数分两个阶段收集工具:
1. 内置工具(通过 ToolRegistry.tools())
各工具以文件为单位在 tool/ 目录下实现(如 tool/read.ts、tool/bash.ts 等),在 tool/registry.ts 中统一管理。主要工具有:
| 工具 | 功能 |
|---|---|
read / write / edit |
文件操作 |
bash |
Shell 命令执行 |
grep / glob |
代码搜索 |
task |
启动子 Agent |
todowrite |
任务管理(前述) |
websearch / webfetch |
Web 搜索 / 获取 |
内置工具也会根据连接的模型进行过滤。例如,GPT 系列模型中,用 apply_patch 这一单一工具替代 edit / write。
2. 外部工具
在内置工具之外,用户还可以通过以下方式添加工具:
- 自定义工具文件: 在
.opencode/tool/或.opencode/tools/文件夹中放置.js/.ts文件,registry.ts会自动加载。扫描范围是项目的.opencode/目录以及全局配置目录(~/.opencode/),文件名作为工具的命名空间。 - MCP 服务器: 从 MCP(Model Context Protocol)服务器动态获取并添加工具。
这样收集到的工具列表被传递给 LLM,由 LLM 自身决定调用哪个工具。这正是 ReAct 的设计,由 LLM 提供商的 Function Calling / Tool Use API 支撑这一机制。
Observation → 下一个 Thought
循环中的位置: processor.process() 内工具执行完成后。结果被记录到消息历史中,通过回到循环开头连接到下一个 Thought。
ReAct 中的 Observation 是接收 Action 执行结果的阶段。OpenCode 通过将工具执行结果添加到消息历史来实现这一点。
具体由 processor.ts 的 tool-result 事件处理程序负责:
// processor.ts(简化版)
case "tool-result": {
const match = toolcalls[value.toolCallId]
if (match && match.state.status === "running") {
await Session.updatePart({
...match,
state: {
status: "completed",
input: value.input ?? match.state.input,
output: value.output.output,
time: { start: match.state.time.start, end: Date.now() },
},
})
}
break
}
工具的执行结果(output)与执行时间等元数据一同被记录到消息历史中。带着这条更新后的消息历史回到循环开头,再次调用 LLM。LLM 接收包含 Observation 的上下文,生成下一个 Thought。如此,ReAct 的"Thought → Action → Observation → Thought → …"循环持续运转。
Finish:循环的终止
循环中的位置: 循环开头的 if (lastAssistant?.finish && ...) 终止判断。
OpenCode 通过 LLM 响应附带的 finish reason(终止原因) 来判断。这是与响应内容(文本或工具调用)分开的、由 LLM API 提供的"为什么停止生成"的元数据。
在 processor.ts 的 finish-step 事件中以 value.finishReason 接收,记录到助手消息中:
// processor.ts(简化版)
case "finish-step":
input.assistantMessage.finish = value.finishReason // "end-turn", "tool-calls" 等
break
在循环开头的终止判断中,检查这个 finish reason:
| finish reason | 含义 | 结果 |
|---|---|---|
"tool-calls" |
LLM 执行了工具调用后停止 | 循环继续(经 Observation 进入下一个 Thought) |
"end-turn" / "stop" |
LLM 未调用工具,以纯文本响应停止 | 循环结束(Finish) |
也就是说,LLM 自己判断"不再需要工具"并以纯文本完成响应,这一行为本身就相当于 ReAct 的 Finish。这个判断由 LLM 自身做出,OpenCode 侧并不会显式指示终止。
实用层面的工程技巧
以上就是与 ReAct 理论直接对应的部分。但实际编码 Agent 中,存在 ReAct 框架本身无法应对的问题。OpenCode 中实现了以下工程层面的技巧:
死循环(doom loop)检测
processor.ts 中包含检测 LLM 重复相同行为导致无限循环的机制:
// processor.ts(简化版)
const lastThree = parts.slice(-DOOM_LOOP_THRESHOLD) // 最近 3 次的部分
if (
lastThree.length === DOOM_LOOP_THRESHOLD &&
lastThree.every(p =>
p.type === "tool" &&
p.tool === value.toolName && // 同一工具
p.state.status !== "pending" && // 已执行
JSON.stringify(p.state.input) === JSON.stringify(value.input) // 同一参数
)
) {
await PermissionNext.ask({ permission: "doom_loop", ... }) // 向用户确认
}
最近 3 次工具调用如果是同一工具、同一参数,则不自动继续,而是向用户确认。这是理论框架中不包含的、实用层面重要的安全装置。
上下文压缩
ReAct 循环持续较久时,消息历史会超出模型的上下文窗口。compaction.ts 是应对这一问题的机制,采用两阶段方法:
第 1 阶段:旧工具结果的裁剪(prune)
首先,对旧的工具调用结果进行轻量化。prune 函数从消息历史末尾向前追溯,保护最近 40,000 token 的工具结果,清除更旧的工具结果输出:
// compaction.ts(简化版)
const PRUNE_PROTECT = 40_000 // 保护的 token 数阈值
// 从消息历史末尾向前追溯,累加工具结果的 token 数
total += estimate
if (total > PRUNE_PROTECT) {
toPrune.push(part) // 超过 40,000 token 的部分成为裁剪对象
}
被裁剪的工具结果在 toModelMessages 中被替换为 "[Old tool result content cleared]" 字符串。工具被调用的事实保留,但详细输出被丢弃。
第 2 阶段:LLM 驱动的对话摘要(compaction)
仅靠裁剪还不够时,在 ReAct 循环开头通过 isOverflow 判断 token 使用量是否接近上下文上限,若超出则触发 compaction 处理。这是用 LLM 自身对整个对话历史进行摘要的过程。摘要生成使用以下模板(compaction.ts 的 defaultPrompt 变量):
## Goal
[用户试图达成的事]
## Instructions
[用户提出的重要指令]
## Discoveries
[对话中明确的重要信息]
## Accomplished
[已完成的工作、进行中的工作、剩余的工作]
## Relevant files / directories
[相关文件的结构化列表]
定制化方向
基于以上理解,介绍几种定制化方向:
系统提示词的定制
最简便的入口。在 opencode.json 的 agent 配置中可定义自定义 Agent,设置自己的系统提示词和工具权限。
llm.ts 中,若 Agent 设置了提示词,则不会使用 Thought 部分介绍的按模型选择提示词(anthropic.txt、gemini.txt 等)的机制,而是优先使用该自定义提示词:
// llm.ts(简化版)
// 如果 agent 有 prompt 则优先使用,否则回退到模型专用 prompt
...(input.agent.prompt ? [input.agent.prompt] : SystemPrompt.provider(input.model)),
无需直接编辑 session/prompt/ 的文件即可实现。但要注意,模型切换功能会完全失效——无论 Claude 还是 Gemini 都会使用同一提示词。
工具的添加
添加工具有两种方法:
方法 1:自定义工具文件
在 .opencode/tool/ 或 .opencode/tools/ 目录中放置 .js / .ts 文件,registry.ts 会自动加载并注册为工具。扫描范围是项目的 .opencode/ 目录和全局配置目录(~/.opencode/),文件名成为工具的命名空间。
方法 2:MCP 服务器
MCP 是将外部进程作为工具服务器连接的标准协议。在 opencode.json 中描述服务器的启动命令,该服务器提供的工具就会被动态添加到 LLM 的工具列表中。MCP 不是 OpenCode 特有的机制,Claude Desktop、Cursor 等其他 AI 工具也采用,因此一次实现即可在多个工具中复用。
推理过程本身的定制
无需修改 OpenCode 源代码即可实现。OpenCode 具有插件系统,可在推理循环的各个阶段插入钩子函数。
插件以 npm 包或本地文件的形式实现,在 opencode.json 的 plugin 数组中注册。插件以向 Hooks 接口(packages/plugin/src/index.ts)中定义的钩子点提供函数的方式运作。与推理过程相关的主要钩子如下:
| 钩子名 | 调用时机 | 可做的事 |
|---|---|---|
experimental.chat.messages.transform |
LLM 调用前 | 加工 / 过滤消息历史 |
experimental.chat.system.transform |
LLM 调用前 | 动态改写系统提示词 |
experimental.session.compacting |
上下文压缩时 | 替换压缩提示词或注入上下文 |
tool.execute.before / after |
工具执行前后 | 加工工具参数或结果 |
chat.params |
LLM 调用前 | 更改 temperature 等参数 |
tool.definition |
工具列表构建时 | 改写工具描述或参数 |
例如使用 experimental.chat.messages.transform,可以在每次调用时加工传递给 LLM 的消息历史,从而实现特定条件下插入上下文或排除不必要消息等定制。
结语
本文通过 OpenCode 的源代码,展示了 AI 编码 Agent 的推理过程是如何实现的。理论篇中确认的 ReAct 框架(Thought → Action → Observation → Finish 的循环),在 OpenCode 中被忠实地实现为 prompt.ts 中的 while(true) 循环。Thought 通过文本输出和 Extended Thinking 两个通道实现,模型专用的不同系统提示词控制着其质量。Action 对应内置工具与用户添加工具的动态解析,Observation 对应工具结果到消息历史的记录,Finish 对应基于 finish reason 的循环终止判断——每个环节都在代码中找到了明确的对应。
模型的聪明程度与 Agent 的实现如同车的两个轮子。模型再优秀,没有合适的推理过程设计,也无法充分发挥其能力。反过来说,理解并定制推理过程,有可能从同一模型中引出更好的输出。
参考文献
-
Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. arXiv:2201.11903
-
Kojima, T., et al. (2022). Large Language Models are Zero-Shot Reasoners. NeurIPS 2022. arXiv:2205.11916
-
Yao, S., et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023. arXiv:2210.03629
-
OpenCode 仓库: https://github.com/anomalyco/opencode
原文作者:tsurubee — SAKURA internet 研究员;AI/ML for drug discovery and material science.

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)