阿里千问最新文章Qwen-VLA 登场:具身智能大一统!
最近科技圈的视线似乎都被大模型和纯软件 Agent 的跑分大战吸引了,但在物理世界里,具身智能(Embodied AI) 正在悄悄酝酿一场底层架构的革命。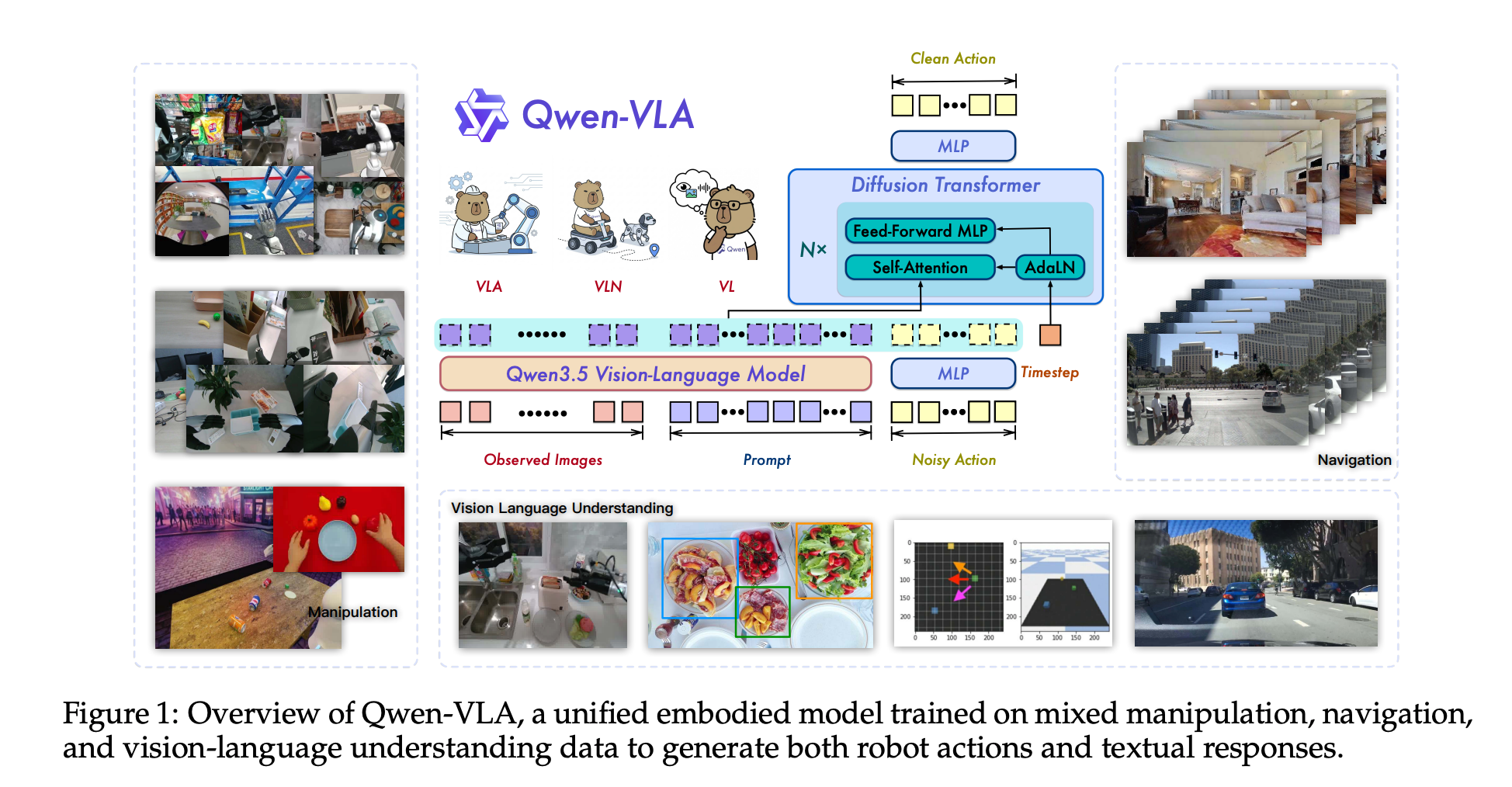
今天给大家拆解一篇刚刚(2026年5月底)挂在 arXiv 上的重磅论文:《Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments》(编号:2605.30280)。
文章地址:Qwen-VLA: From Understanding the World to Acting in It
这篇工作试图回答当前机器人算法领域最核心的一个痛点问题:我们能不能用一个统一的视觉-语言-动作(VLA)大模型,打破“一个萝卜一个坑”的专机专用限制?
直接抛结论:Qwen-VLA 跑通了这条路。 它不仅打通了物体操作(Manipulation)和空间导航(Navigation)等异构任务,还能在完全不同的机器人硬件形态之间实现跨界泛化。
痛点:为什么之前的机器人模型那么“脆”?
一直以来,具身智能的开发都面临着严重的“碎片化”。
做机械臂抓取的团队,和做轮式机器人底盘导航的团队,往往用着完全不同的算法框架。即便是同一种模型,换个实验室的光照条件,挪动一下桌子上的干扰物,甚至只是换个夹爪,模型大概率就直接罢工了。
这种泛化能力的缺失,是因为过去的模型往往在单一任务和特定硬件上过拟合。而 Qwen-VLA 的核心解题思路就是:用极致的通用基础架构 + 海量混合数据,去硬生生堆出“涌现”的物理泛化能力。
核心架构:当 Qwen 视觉栈遇上 DiT
对于每天和网络结构打交道的算法工程师来说,这篇论文在架构设计上非常干净利落。Qwen-VLA 并没有从零开始造轮子,而是巧妙地站在了视觉语言大模型(VLM)的肩膀上。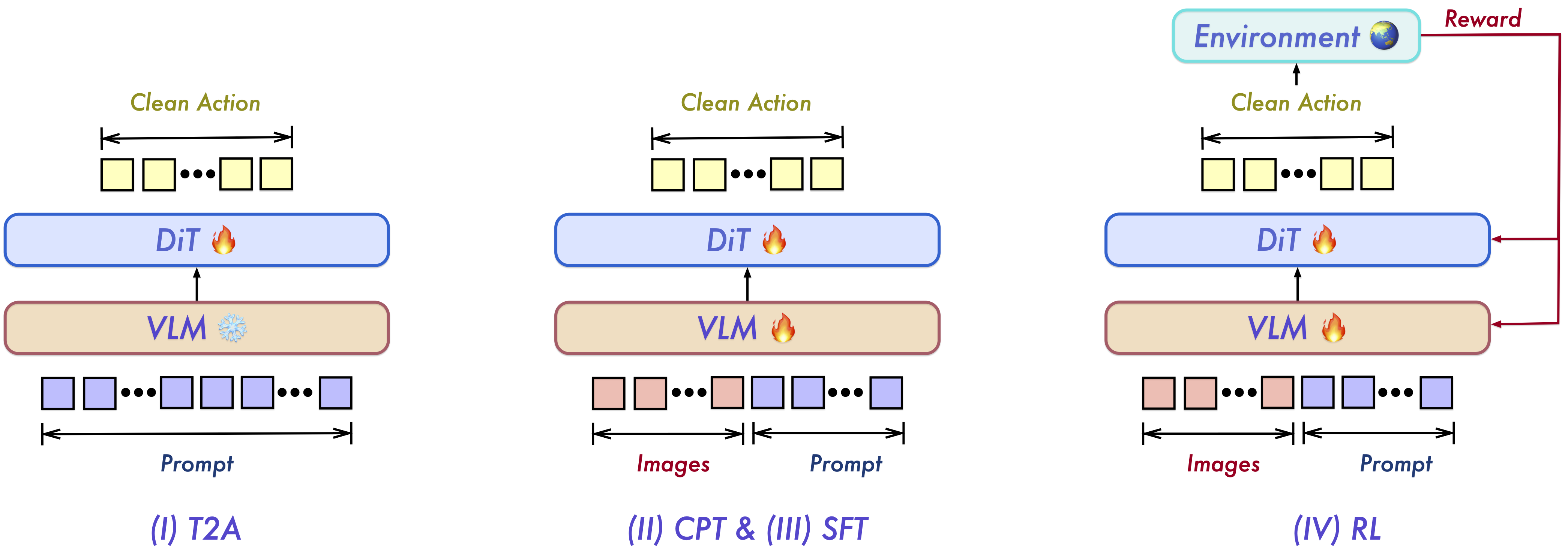
它的架构亮点可以拆解为两部分:
- 感知与推理的底座:模型直接复用了 Qwen 强大的视觉-语言(Vision-Language)建模栈。这意味着它自带了出色的零样本感知能力,能够像往常一样“看懂”复杂的场景,并进行常识逻辑推理。
- 动作生成的杀手锏 —— DiT 解码器:这是打通物理世界的最硬核部分。传统 VLM 的终点是输出文本,而 Qwen-VLA 引入了一个基于 Diffusion Transformer (DiT) 的动作解码器(Action Decoder)。它将大模型提取的高维语义特征,直接映射为连续的物理动作和轨迹生成。
这种设计完美弥合了“离散的语义理解”与“连续的物理控制”之间的鸿沟。
跨硬件的魔法:具身感知提示词 (Embodiment-aware Prompting)
一个大模型要怎么控制不同的身体?毕竟不同的机器人,自由度不同,关节不同,底层控制指令也天差地别(比如四足机械狗 vs 六轴机械臂)。
论文提出了一种非常优雅的解法:具身感知提示词条件化(Embodiment-aware prompt conditioning)。
在输入端,算法通过特定的文本描述(Textual Descriptions),直接告诉大模型当前“附身”的躯体是什么形态,以及底层的控制约定是什么。
你可以把它理解为大模型版的热插拔“驱动程序”。 只要通过提示词动态切换硬件 ID 和参数设定,同一个大脑就能无缝切换肌肉的控制逻辑。
史诗级的联合预训练
众所周知,大模型的壁垒永远在数据。Qwen-VLA 的训练配方(Recipe)堪称豪华,它把目前能搜刮到的多源异构数据全烩进了一锅进行大规模联合预训练:
数据来源
-
机器人操作轨迹:是动作学习的主体,覆盖桌面操作、移动操作、双臂操作和灵巧手控制。公共数据规模超过 10,000 小时,加上超过 1,000 小时的内部真实机器人轨迹和超过 800 万条合成仿真轨迹。
-
人类第一视角数据:提供了开放环境中更丰富的物体、场景和手部动作先验。引入了 Ego4D、EPIC-KITCHENS、EgoDex(829 小时)、EgoVerse(1,300+ 小时、1,965 个任务、240 个场景)、Xperience 等数据集。
-
合成仿真数据:补足长尾场景。视觉条件合成数据覆盖 20 个桌面场景、200 个基础配置、450 个操作任务,包含 359,848 条成功轨迹;纯文本动作数据覆盖 6 类模板 × 6 种单臂机器人,生成约 720 万条轨迹、超过 14,000 小时。
-
视觉语言导航数据:为模型提供长程轨迹规划和指令跟随能力。
-
通用视觉语言数据 :保留多模态理解、空间定位和指令跟随能力。此外还构建了约 48,000 条细粒度具身动作描述,从 13 个维度刻画动作过程,将自然语言与具体执行细节对齐。
四阶段训练
核心理念: 先让模型学会如何从语言生成动作结构,再学习如何根据视觉环境调整动作。
-
Stage I: T2A(文本到动作预训练)。 一句”拿起红色杯子”只有几个词,但对应的机器人动作是一段高维连续轨迹。Qwen-VLA 将这个过程看作一种从语言到动作的”解压缩”。在 T2A 阶段,我们冻结 VLM,不引入任何图像,只让动作解码器从语言指令和机器人形态描述中学习动作先验。
-
Stage II: CPT(预训练)。 解冻 VLM 和动作解码器,在完整的多模态数据上联合训练。这一阶段将 T2A 习得的语言-动作先验对齐到具体视觉场景,同时让骨干模型适应具身感知,产出 Qwen-VLA-Base。
-
Stage III: SFT(监督微调)。 从 CPT checkpoint 出发,分为两条路线:多任务 SFT 在操作、导航、VQA 等异构任务上联合微调;真机 SFT 在内部遥操作数据上微调,用于真实机器人部署。
-
Stage IV: RL(强化学习)。 从 SFT checkpoint 出发,在仿真环境中通过 PPO 直接优化闭环任务成功率,产出最终模型 Qwen-VLA-Instruct。RL 仅在 SimplerEnv 中进行,但实验表明收益可迁移到其他未见过的环境和机器人形态。
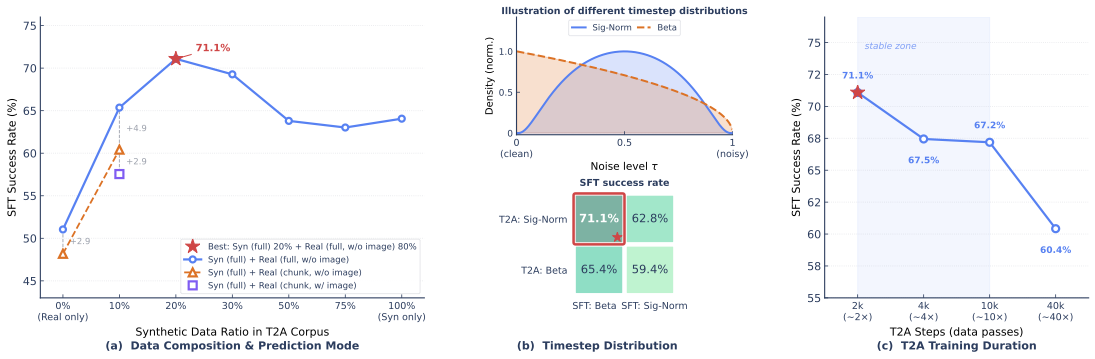
这种力大砖飞的结果,就是其惊人的 OOD(分布外)泛化能力:
在官方给出的基准测试中,无论是场景布局大改、背景和光照突变、物体摆放混乱,还是直接更换机器人硬件本体,Qwen-VLA 都能保持极高的鲁棒性,多任务表现远超以往的各种专用基线模型。
总结与思考
从单纯的“聊聊天”、“写写代码”,到能够指挥物理硬件进行复杂操作,AI 正在从数字世界真正越狱到物理世界。Qwen-VLA 的出现,印证了 “统一大模型基础架构 + 规模化多模态数据” 这一通用人工智能的范式,在具身智能领域同样不可阻挡。
作为开发者,我们或许很快就能像今天调用 API 生成文本一样,直接调用 VLA 模型输出工业设备的控制流了。算力与算法的狂飙,正在以肉眼可见的速度填平虚拟指令与现实物理的鸿沟。
你认为这种端到端的 VLA 大模型,离真正的大规模工业流水线落地还有多远?欢迎在评论区聊聊你的看法!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 11
11 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)