1M上下文 vs RAG:理性分析为什么Agent时代两者必须共存
写在前面
当Gemini 1.5 Pro带着1M token的上下文窗口亮相时,技术圈一片惊呼:“RAG要凉了!”毕竟,把整本书直接塞进Prompt,让模型自己找答案,听起来确实比“切块-向量化-检索”那一套简单粗暴多了。然而半年过去,RAG不仅没有消失,反而在Agent时代找到了新的位置。1M上下文和RAG,到底谁更胜一筹?本文将放下立场偏见,从成本、延迟、效果、动态性四个维度做一次理性PK,并给出一个核心结论:在Agent时代,两者不是替代关系,而是必须互补共存。

一、1M上下文的“高光”与“阴影”
1.1 优势:简单粗暴,全局可见
长上下文模型最大的卖点是“无需预处理”。用户直接把整本手册、全年邮件、整个代码仓库丢进去,然后提问。这种模式对于一次性、大规模、全局性的任务非常高效——比如“从这份100页的合同中找出所有赔偿条款”。
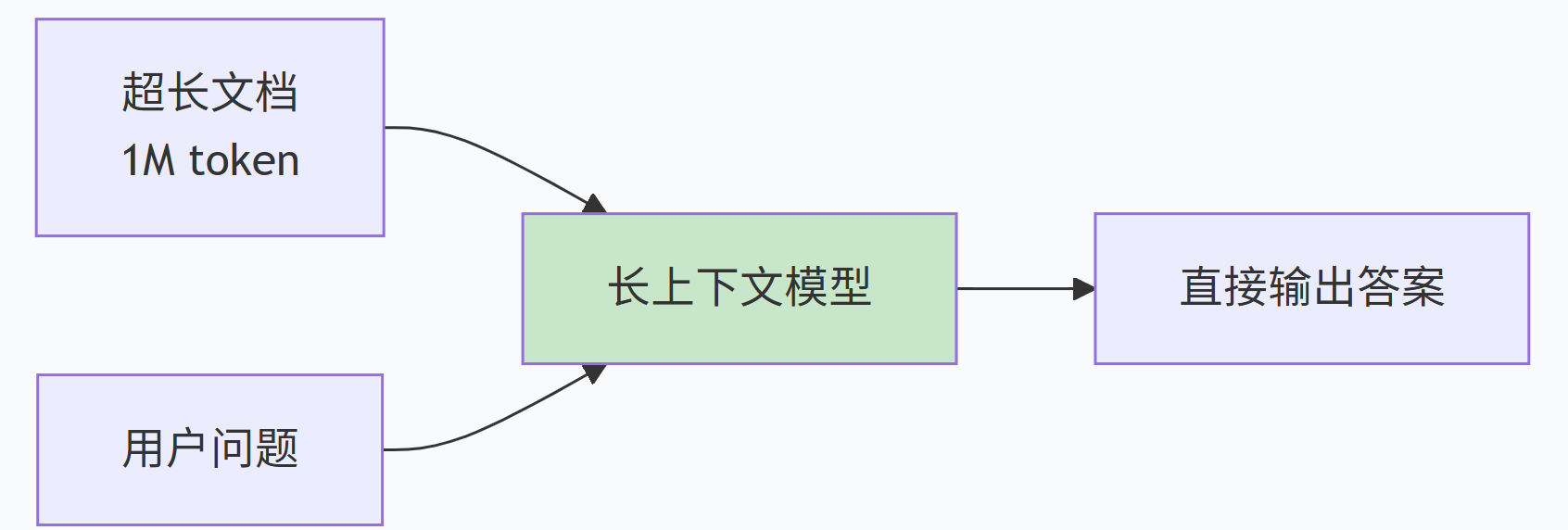
1.2 劣势:成本、延迟、注意力稀释、更新难

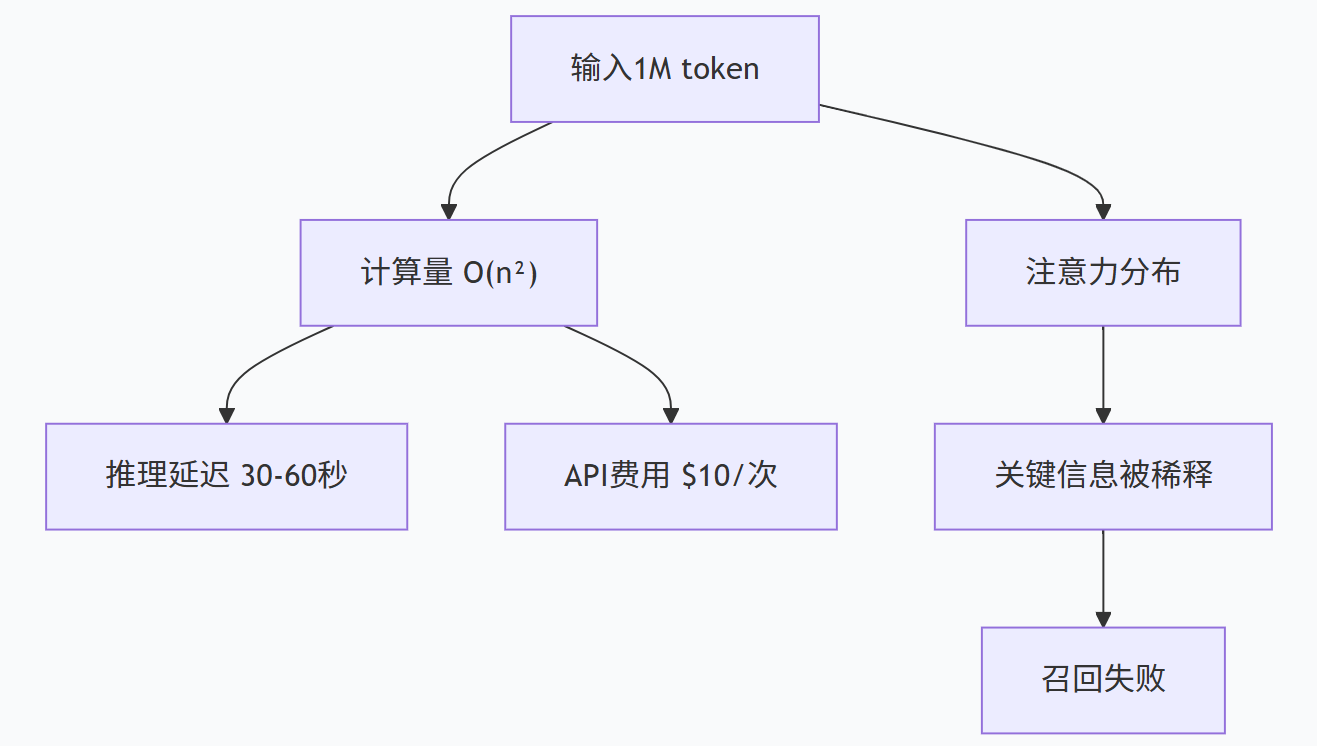
二、RAG的“坚持”与“进化”
2.1 优势:低成本、高精度、可解释
RAG将检索与生成分离,核心优势十分明显:
-
成本:向量检索几乎免费,LLM只处理几K token
-
延迟:检索毫秒级,生成秒级,总延迟<3秒
-
注意力集中:只给模型看最相关的Top-K片段
-
动态更新:向量库增删改查即时生效
-
可解释:可以返回文档来源、页码、章节

2.2 劣势:依赖检索质量
RAG的瓶颈在于“检得准不准”。如果文档切分不当、Embedding模型不合适、向量库索引有偏差,检索阶段就可能漏掉关键信息,导致最终答案不完整。
三、Agent时代:为什么两者必须共存?
在AI Agent系统中,任务通常是多步骤、多工具、多轮交互的。单一的上下文模式或RAG模式都无法满足全部需求。
3.1 典型Agent任务拆解
假设Agent需要完成:“分析本公司Q3财报中提到的风险因素,并与竞争对手的公开披露做对比”。
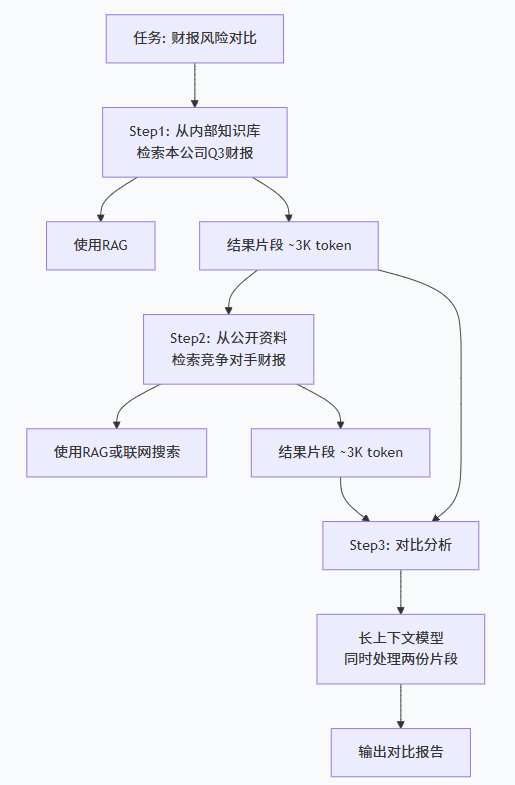
这个流程中:
-
前两步需要RAG从海量知识库中精准召回相关片段
-
第三步需要长上下文能力同时理解两份文档并进行推理
3.2 互补架构:RAG for 检索,长上下文 for 深度推理
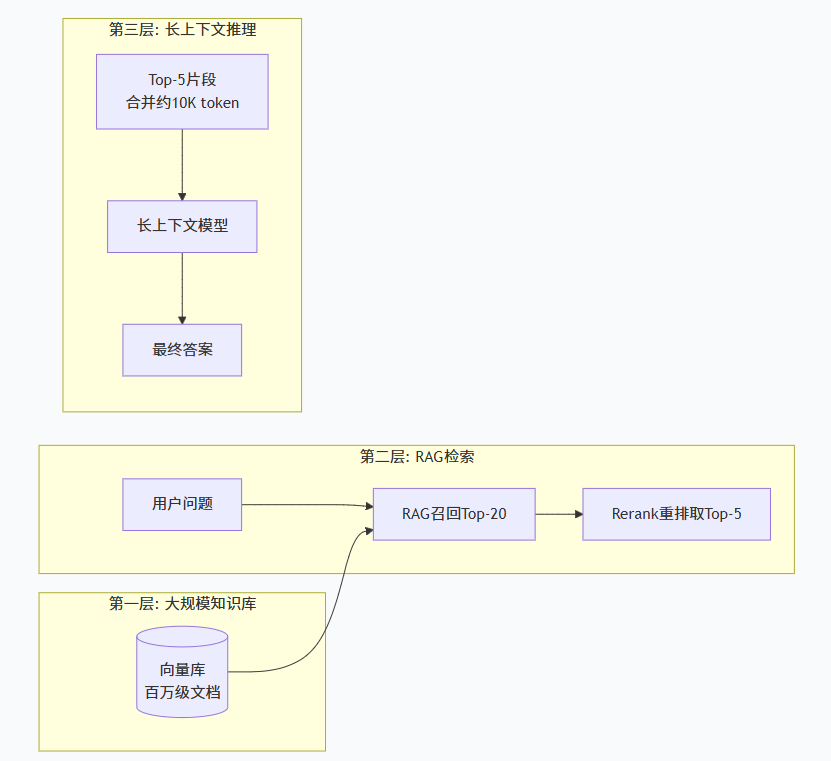
这种“RAG前置过滤 + 长上下文后置推理”的架构,既规避了RAG检索遗漏的风险,又避免了将整个知识库直接塞入长上下文模型的高昂成本。
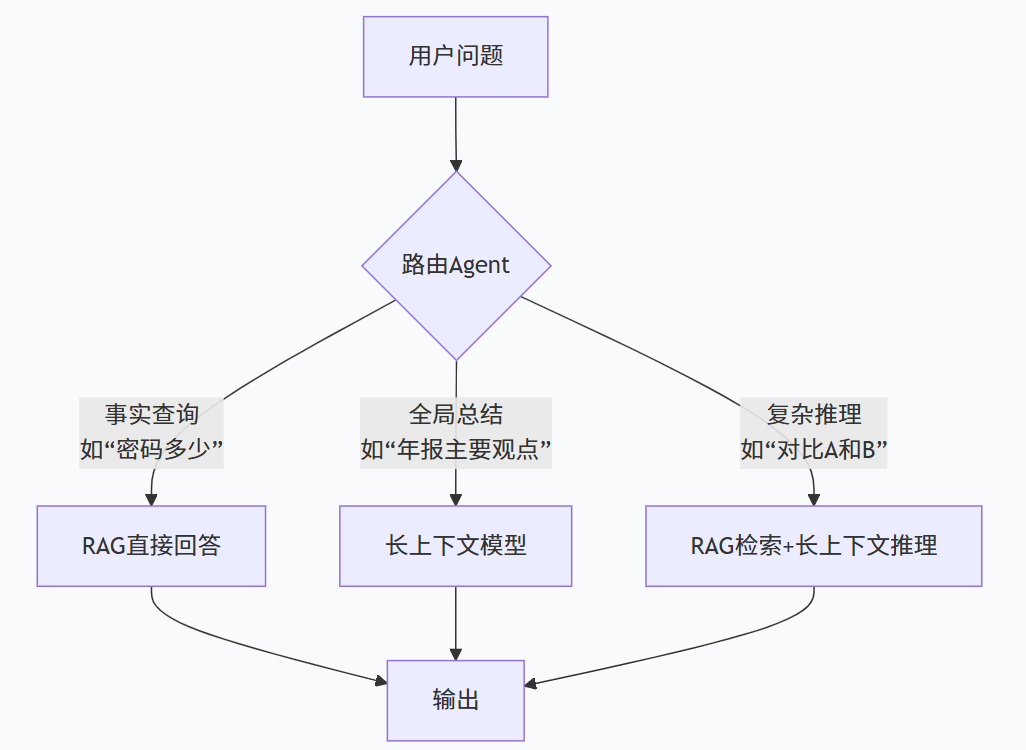
3.3 混合调度的智能路由
更成熟的系统会引入一个路由Agent,根据问题类型动态选择策略:
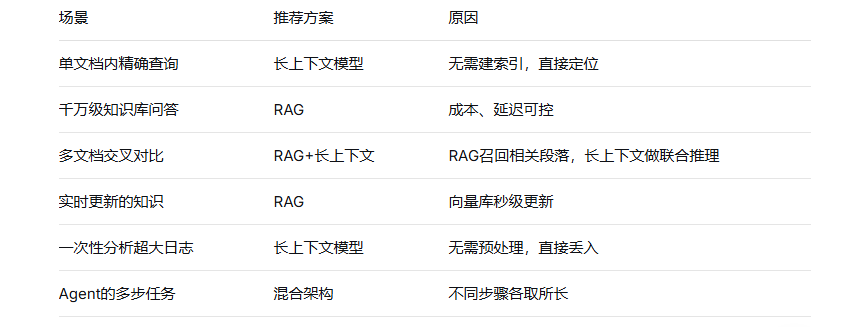
四、实战数据:何时选哪个?
五、结论:共存才是未来
1M上下文模型和RAG不是对手,而是战友。
-
长上下文模型擅长:小规模、全局性、一次性深度理解。
-
RAG擅长:大规模、动态更新、精准检索、低成本高频问答。
-
Agent时代需要的是混合智能:用RAG从海量知识中快速定位相关信息,再交给长上下文模型进行复杂推理。
未来的AI系统不会只用一种技术。作为开发者,我们需要理解各自的优劣势,在设计Agent架构时灵活组合。这才是“理性分析”的真正价值。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)