LLM之Agent(五十二)|从Hermes到MAOS:我为什么在Claude Code里重建了一个模块化AI操作系统?
Hermes在46天内从0飙到40,000 GitHub星——比GitHub上任何AI agent系统都快。但读完它的Issues后,我做了完全不同的事。
先问你一个问题:
你有没有遇到过这种情况——安装了一个看起来很酷的AI工具,头几天觉得很惊艳,但三周后开始遇到各种奇怪的问题?
工具自动生成了很多文件,但你不知道哪些该保留;它自称会「自我学习」,但质量却在慢慢下滑;你想在多个项目间切换,却发现每个项目都要重新装一遍?
如果是,这篇文章就是为你写的。
一、Hermes到底是什么
讲清楚我为什么重建它之前,得先理解Hermes在架构层面到底做了什么。去掉那些营销话术,它其实做了三件事:
第一层:身份层
任何一个优秀的AI agent,在写第一个字之前都需要知道三件事:
-
为谁工作
-
品牌的声音是什么样
-
和谁说话
Hermes通过两个文件搞定:memory.md 和 user.md。每次对话开始时注入,让agent知道你是谁、你在乎什么。
这其实非常聪明。没有这一层,每个AI的输出听起来都一样——千篇一律、空洞、一眼就能认出是机器写的。
身份层又细分为五个组件:
什么是ICP?
你在MAOS架构里会反复看到 icp.md。它值得单独解释,因为它是大多数人低估的组件。
ICP = Ideal Customer Profile(理想客户画像)。它不是泛泛的「25-45岁的工程师」,而是一份精准的文字画像——描绘你内容所写的具体人物类型:他们的角色、痛点、渴望,以及最重要的是——他们用什么语言描述自己的问题。
ICP是「触达受众」的内容和「引起共鸣」的内容之间的分水岭。
来看一个对比:

好的ICP vs 泛泛受众
一个定义清晰的ICP回答六个问题:
-
他们是谁?——职位、资历、行业、公司规模
-
什么让他们烦恼?——用他们自己的话说(比如"我六个月前引入了这个工具,现在我在维护一个我自己都解释不清的东西")
-
他们想要什么?——他们在追求什么结果
-
他们怎么说话?——"我们在YAML里淹死了"而不是"我们遇到了运营效率低下的问题"
-
什么能让他们参与?——具体数字、反直觉的观点、诚实的事后复盘
-
什么让他们滑走?——模糊的思想领导力、供应商语气、显而易见的建议
在MAOS的技能链中,ICP模块会强制agent在写一个字之前回答一个问题:「这个特定的人看到这个会停下来吗?」如果答案是「不会」,就重写。
第二层:记忆系统
记忆是agent性能的引擎。Hermes用了三级记忆架构:
-
短期上下文——每次对话的自动总结
-
近期快照——上下文窗口上限约1,300 tokens(约2,500字),每次对话通过
memory.md注入 -
长期检索——近期快照没有答案时,搜索历史对话
1,300 tokens的上限是个聪明的设计。它让上下文窗口保持精简快速,同时确保agent脑子里始终有最重要的最近信息。
第三层:技能系统
Hermes里的技能是程序性文件——告诉agent如何执行重复性任务。它最受赞誉的是自学习循环:完成任务后,agent自动写一个新的技能文件,下次直接使用。
听起来很厉害。第一次运行的时候,确实很神奇。
问题是后面才暴露出来。
二、现成系统的三个隐藏成本
我读了Hermes的Issues后发现的三个问题——都是你已经投入之后才会浮现的。
隐藏成本1:自我验证问题
Hermes的自学习循环有一个根本缺陷:写技能的那个模型,同时也是评判这个技能好坏的那个模型。
没有外部验证步骤。没有人在循环里把关。agent给自己的作业打分。
这意味着什么?
-
它可能悄悄覆盖你精心调优、手动改进的技能,换成更差的自生成版本
-
时间一长,你会积累15个几乎一样的技能文件——
linkedin-post-v1.md、linkedin-post-v2.md、linkedin-post-client-a.md——没有一个明确的优胜者 -
没有审计日志,你无法追溯质量什么时候、为什么下降了
-
你辛辛苦苦调优的成果就这么消失了,可能永远不知道发生了什么
隐藏成本2:安全黑盒
OpenClaw——和Hermes同类的上一代系统——上线以来发现了超过200个漏洞,包括严重和高危问题。一位安全研究员发现,单个威胁行为者在技能市场上投放了386个恶意包。
当你安装别人的agent架构,安全层面出问题时,你是在调试一个你根本不懂底层假设的代码。看不到的东西,自然也修不了。
隐藏成本3:搞不定多客户场景
Hermes围绕单人使用假设构建。如果你需要为多个客户运行它,就不得不启动完全独立的安装——各自有各自的记忆、技能和学习循环。
不同客户之间的技能不能共享,即使底层流程一模一样。每新增一个客户,维护成本就线性增长。那个当初让你觉得如虎添翼的系统,慢慢变成了负担。
「Hermes上手可能更快,但你自己搭的系统在规模化时才是真正更快的那个。」
三、我如何在Claude Code里重建它——MAOS架构
我没有替换Hermes,而是把真正需要的部分在我的环境里重建了。结果就是MAOS——模块化agent操作系统(Modular Agentic Operating System)——独立的文件、一个目录、完全运行在Claude Code内部。
关键洞察:Claude Code每次会话自动加载 CLAUDE.md。这一个文件就相当于Hermes整个自动注入机制。它告诉agent在做任何事之前,先读取身份、记忆和运行状态。
完整结构:
Rebuilt_Hermes_in_Claude_Code/
├── CLAUDE.md ← 每次启动自动加载 = Hermes的上下文注入
├── user.md ← 你是谁、你的角色、你的沟通方式
├── memory.md ← 1,300 tokens的会话快照(对标Hermes)
├── solder.md ← 运行状态——上次进行到哪里了
│
├── clients/
│ ├── _template/ ← 每新增一个客户,复制此模板
│ └── techfounder/ ← 示例客户:语调、ICP、定位、视觉风格
│
├── skills/
│ ├── core/ ← 语音模块、ICP模块、格式模块
│ ├── systems/ ← LinkedIn帖子、邮件触达、YouTube转LinkedIn
│ ├── staging/ ← 待人工审核(自学习关卡)
│ ├── promoted/ ← 退休的旧版本技能(永久存档)
│ └── audit-log.md ← 每次技能变更永久记录
│
└── memory/archive/ ← 按主题组织的长期记忆
身份层——一次安装、无限客户
MAOS通过「逻辑上下文注入」而非「物理分开安装」来解决Hermes的单客户限制。
每个客户拥有自己的文件夹:
clients/
├── techfounder/
│ ├── voice.md ← 直接、有看法、不打鸡血
│ ├── icp.md ← 资深工程师,信任数据,讨厌遗留复杂性
│ ├── positioning.md ← 架构自主权 vs 开箱即用的便利性
│ └── visual-identity.md ← 深色、极简、技术美学
└── acmecorp/
├── voice.md ← 温暖、专业、易接近
├── icp.md ← 人力资源经理、非技术买家
├── positioning.md ← 企业可靠性 vs 前沿新奇性
└── visual-identity.md ← 明亮、品牌化、企业友好skills/systems/ 里的技能在所有客户之间共享。切换客户时,只需要改变注入的客户上下文。一次安装,无限客户,零技能重复。
记忆系统——短期注入+语义存档
MAOS保留了Hermes最好的记忆模式,同时修复了最差的那个。
保留的:1,300 tokens的 memory.md 快照在会话开始时注入。快速、轻量、始终是最新的。
修复的:Hermes的长期记忆用关键词搜索——如果你记不起六个月前某次对话的准确用词,agent就找不到它。MAOS用按主题组织的语义档案 memory/archive/ 来替代。未来的检索基于概念和含义,而不是精确短语匹配。
检索层级:
-
先查
memory.md—— 最快,覆盖最近1-3次会话 -
找不到 → 搜索
memory/archive/<主题>-<YYYY-MM>.md—— 按语义搜索,覆盖全部历史
模块化技能系统——链式调用胜过单体巨石
这是架构优势最明显的地方。
在Hermes里,一个「写LinkedIn帖子」的技能直接嵌入了语调、受众和格式逻辑。品牌声音变了?你要更新这个技能。还有邮件技能、内容技能……每一个嵌入了语调逻辑的技能都要改。
在MAOS里,你维护三个独立的核心模块:
-
skills/core/voice-module.md—— 通用语调规则、禁用词、校准提示 -
skills/core/icp-module.md—— 受众校准规则 -
skills/core/formatting-module.md—— 平台特定的结构规则
技能系统把这些模块链式组装:
linkedin-post.md
→ 加载 voice-module.md(如何应用语调)
→ 加载 icp-module.md(如何校准受众)
→ 加载 formatting-module.md(如何搭建结构)
→ 加载 clients/techfounder/voice.md(语调具体是什么)
→ 加载 clients/techfounder/icp.md(受众具体是谁)
→ 写帖子当TechFounder的品牌语调改变时:只需编辑一次 clients/techfounder/voice.md。所有引用它的技能系统自动使用更新版本。零传播成本。第一天搭建花的时间多一点,但第100天维护起来会快得多。
四、自学习——修复了,不是删掉了
大多数人第一个问题就是:「但Hermes的自学习循环不是让它越来越聪明吗?你的重建不就没这个功能了吗?」
不。MAOS有自学习。只是没有了自我验证的问题。
Hermes的循环做了什么
每次任务完成后,Hermes自动写一个新的技能文件并加入库。没人看到它,没人批准它。系统给自己的输出打分并立即投入使用。
第一次运行,感觉像魔法。agent从你的会话中学到了东西,下次记住了模式。
到了第20次迭代,你就有问题了:
linkedin-post-v1.md
linkedin-post-v2.md
linkedin-post-client-a.md
linkedin-post-client-b.md
linkedin-post-writer-v1.md
linkedin-post-writer-v2.md六个技能,都做差不多的事,每个捕捉了稍有不同的时间点。没有明确的胜者。当agent需要写LinkedIn帖子时,它不知道该用哪个。当品牌语调改变时,你得更新六个文件而不是一个。
而且因为没有审计日志,你无法追溯性能从什么时候开始下降。
MAOS的三区管道
MAOS用一个三区管道替代了自主循环——保留了技能库增长的好处,同时消除了风险。
┌─────────────────────────────────────────────────────┐
│ 一区:skills/staging/ │
│ 「候选区」—— agent只能在这里写入 │
│ 在离开这个区之前,什么都不生效 │
└────────────────────┬────────────────────────────────┘
│ ← 人工审核 + 批准
▼
┌─────────────────────────────────────────────────────┐
│ 二区:skills/systems/ │
│ 「激活区」—— agent实际使用的技能 │
│ 只有人工提升才可能进入 │
└────────────────────┬────────────────────────────────┘
│ ← 被替代时
▼
┌─────────────────────────────────────────────────────┐
│ 三区:skills/promoted/ │
│ 「归档区」—— 退休版本,永不删除 │
│ 这是Hermes完全没有的版本历史 │
└─────────────────────────────────────────────────────┘每个新技能或升级版本落地到一区。它一直待在那里,直到你做明确的决定。agent不能自己提升自己的作品。
一次自学习会话如何运作
当agent识别到重复模式时,它运行 self-learn.md 技能系统——在写任何东西之前,先强制进行重复检查。
-
步骤1——重复检查:读取
skills/audit-log.md,扫描skills/systems/里的每个文件。如果已有技能覆盖这个模式,不进一区。记录原因,停止。 -
步骤2——提取学习成果:识别可重复的工作流——输入什么、产出什么、需要哪些核心模块、这次会话产生好结果的非显而易见的原因。
-
步骤3——写入一区:候选文件写到
skills/staging/<技能名>-staged-<YYYY-MM-DD>.md。不是skills/systems/。永远不是直接写skills/systems/。 -
步骤4——呈现给人类:agent立即停下来,展示:
-
这个技能做什么(一句话)
-
它和现有技能有什么不同(填补了什么具体缺口)
-
选项:(A)提升 /(B)修改后提升 /(C)拒绝 /(D)搁置
-
-
步骤5——等待:在你做决定之前,agent什么也不做。不再提示。不做假设。
-
步骤6——执行决定:
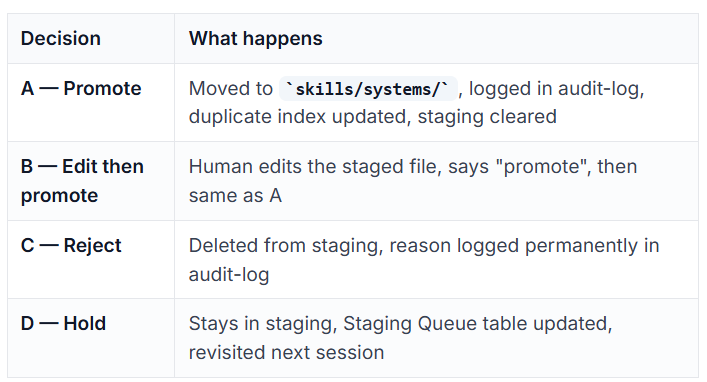
三区决策流程
三条护栏
三条具体规则防止Hermes出现的那些失败模式:
-
护栏1——一区是强制性的。agent永远不能直接把新技能写到
skills/systems/。每个新技能和每个升级版本都必须先经过一区。这防止了手动调优的技能被悄悄覆盖。 -
护栏2——写入一区之前先做重复检查。写入任何内容之前,agent读取
skills/audit-log.md里的完整防重复索引,扫描每个活跃技能。如果已有技能覆盖了这个模式——哪怕只是部分覆盖——就不进一区。这防止了Hermes那种几乎相同的技能越积越多的问题。 -
护栏3——永久审计日志。每次技能变更记录在
skills/audit-log.md中,包含日期、触发条件、决定和原因。这是让系统可检查、可恢复的记录。你可以随时看到任何时间点的技能库状态,以及它为什么发生变化。
升级路径
当一次会话揭示了对现有技能的更好方法时,agent把它作为升级候选提上一区——而不是新技能。如果被提升,旧版本移到 skills/promoted/ 并标注退休日期。新版本进入 skills/systems/。两者都记入日志。
什么都不会被删除。什么都不会被静默覆盖。完整历史始终可查。
「Harness Engineering会话之前的技能库:3个技能。之后:4个技能——而且你确切知道它什么时候增长的、为什么增长的、增长之前检查了什么。这就是Hermes的自学习循环给不了你的信息。」
五、MAOS拥有而Hermes没有的完整优势
MAOS vs Hermes完整对比
最后这一点值得强调:架构自主权——知道你AI系统的每一个底层假设——不仅仅是一个技术偏好。它决定了当系统出问题时,你是能修好它,还是只能重启它。
六、实景演示:从YouTube视频到LinkedIn帖子
展示MAOS的实际运作流程。这是一个完整的workflow,为TechFounder客户生成一篇关于「Harness Engineering」(关于AI模型周围系统的推理框架)的LinkedIn帖子。
第一步——设定客户上下文
输入「切换到TechFounder」。agent加载 clients/techfounder/voice.md 和 clients/techfounder/icp.md 到会话中。
第二步——提取源内容
提供了关于Harness Engineering的YouTube视频。MAOS运行字幕提取。
结果:9分05秒的视频,1,736个词,带时间戳的全文。
第三步——生成研究摘要
agent读取全文并提取:
-
核心概念:Harness Engineering = 设计围绕模型的系统,而不是模型本身。四个杠杆:上下文、工具、循环、治理。
-
关键引用:「模型设置了天花板,但harness决定了你实际能用到的天花板有多大。」
-
关键洞察:一个顶尖模型放在糟糕的harness里,结果可能看起来出人意料地笨。一个较小的模型放在设计良好的harness里,反而可以超越它。
-
3个候选帖子角度——每个都根据TechFounder的ICP进行评分。
第四步——ICP角度评分
agent读取 clients/techfounder/icp.md,给每个角度评分:
ICP角度评分表
第五步——运行 linkedin-post.md 技能链
加载了研究摘要后,技能系统依次执行:
-
voice-module.md→ 应用通用语调规则 -
icp-module.md→ 校准TechFounder受众 -
formatting-module.md→ 应用LinkedIn结构规则 -
techfounder/voice.md→ 直接、有看法、不打鸡血 -
techfounder/icp.md→ 资深工程师、信任数据
生成了3个钩子选项。选中最佳。完成全文撰写。通过自我审查清单。
最终帖子(189个词,可发布状态)
模型设定了天花板。但harness决定了你实际能达到多高。
大多数调试失败agent的工程师都把时间花在了错误的问题上。
「这个模型是不是不行?」很少是正确的出发点。
正确的出发点应该是:4个杠杆中哪一个断了?
上下文——模型是在正确的时间、以正确的形式获得了正确的信息吗?不只是提示词里「有」这个信息,而是在做出决策的那个精确时刻?
工具——模型有正确的操作界面吗?这个界面是否以它能理解、能正确选择的方式暴露出来?
循环——它知道什么时候该继续,什么时候该停吗?没有明确停止条件的agent会一直重试、卡住、或者在还没完成时就宣称「做好了」。
治理——harness是否定义了哪些自动运行、哪些需要审批、哪些完全禁止?
顶尖模型放在糟糕的harness里,结果可能看起来出人意料地笨。较小的模型放在设计良好的harness里,反而可以超越它。
失败几乎从不是模型本身的问题。而是围绕它搭建的系统的结构问题。
第六步——触发自学习
这次会话之后,MAOS识别出一个可重复的模式:YouTube链接→LinkedIn帖子这个工作流值得作为一个可复用的技能捕捉下来。自学习系统运行了:
-
重复检查——扫描所有活跃技能。
linkedin-post.md是从你已经有的主题开始;这个工作流覆盖的是上游的研究管道。没有重复。 -
候选写入一区——写到
skills/staging/youtube-to-linkedin-staged-2026-05-31.md -
呈现给人类——选项:提升/修改/拒绝/搁置
-
人类说:A(提升)
-
技能移至
skills/systems/youtube-to-linkedin.md -
审计日志更新——记录了一区条目、提升条目、更新了重复索引
-
一区清空
技能库从3个增长到4个技能。审计日志显示了这个变化发生的确切时间、原因以及变化之前检查了什么。这种透明度是Hermes的自主循环做不到的。
七、最后总结
Hermes上手很快。它确实有一些好想法——记忆注入机制、身份文件、会话快照上限。这些值得借鉴。
但它在三个方面所做的赌注在规模化时并不奏效:没有外部验证的自学习循环、你无法检查的安全表面、以及强制每个品牌或客户单独安装的单客户架构。
MAOS吸收了Hermes最好的部分,并在你拥有的基础上重建了它:
-
身份层:通过上下文注入,一次安装处理无限客户
-
记忆系统:对标Hermes的短期快照,用语义档案替代其脆弱的关键词检索
-
模块化技能系统:核心逻辑放在一个地方,自动传播到所有地方
-
人工验证的自学习:三区管道(一区→二区→三区)、重复检查、永久审计日志
折衷是真实的:开头会慢一些。有些地方你会搞错。 但每一个层次都是你能看到、能编辑、能复用的东西。出问题的时候,你确切知道该打开哪个文件。
「你看不懂的东西,你也修不了。」
缩小AI委托差距的工程师,不是那些拥有最好工具的人——而是那些拥有架构自主权的人。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 4
4 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)