MiniMax M3 到底有多强?我用 3 个任务横评了一轮

最近 AI 圈最热闹的新模型之一,应该就是 MiniMax-M3。

开源、1M 上下文、原生多模态、Coding 能力,是现代Token成瘾者最关心的几个关键词。
从社交媒体的反馈看,M3 在测试阶段已经拿到了不错的评价。
当然,热度是一回事,体验又是另一回事。
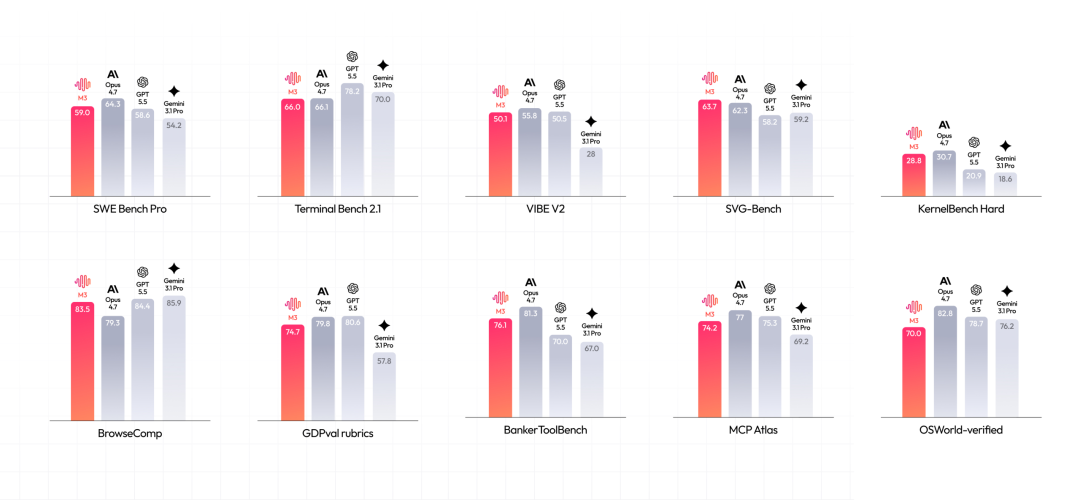
我先看了一圈 MiniMax-M3 的官方信息。基准测试成绩不用展开太多,从结果看绝对能上牌桌。
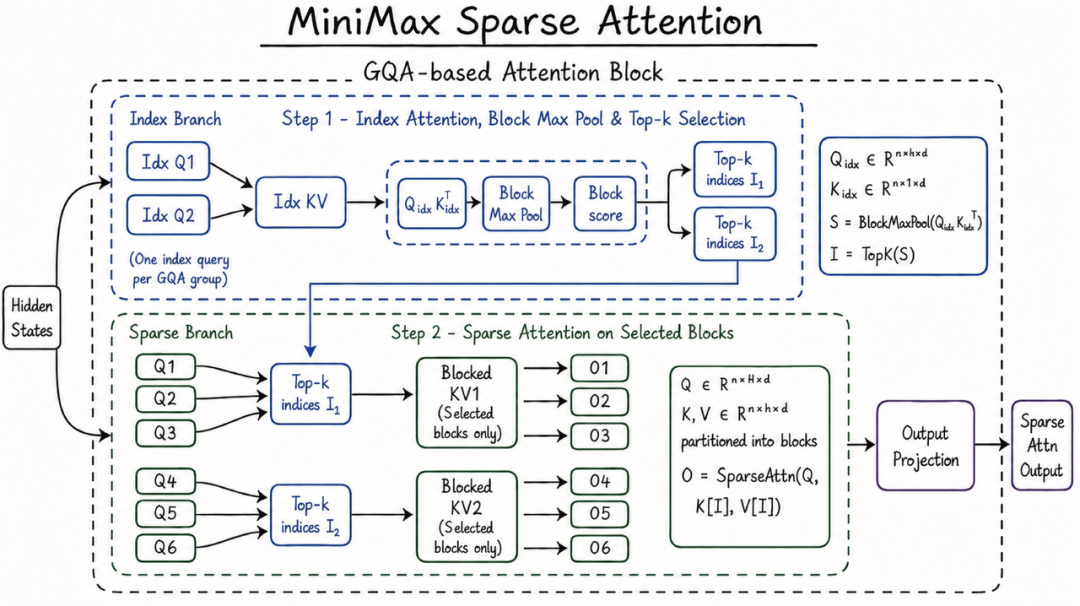
更值得注意的是架构的更迭。MiniMax-M3 采用新的自研 MSA 架构,支持原生超长上下文预训练。官方给出的 M3 API 上下文窗口最高可到 1M tokens,并保障至少 512K tokens 可用。对长程 Agent、长程 Coding、长视频理解这类任务来说,用锦上添花都是不恰当的,完全是基础设施级别的能力。
官方还提到,M3 具备在复杂任务中连续稳定执行数十小时的能力。在 CUDA FP8 GEMM 优化任务里,M3 连续运行约 24 小时,完成 147 次 benchmark 提交,中间经历多个性能平台期,最后做到了 9.4 倍加速。除了 Opus 4.7,其余模型大多在前 30 次提交内就停滞退出。
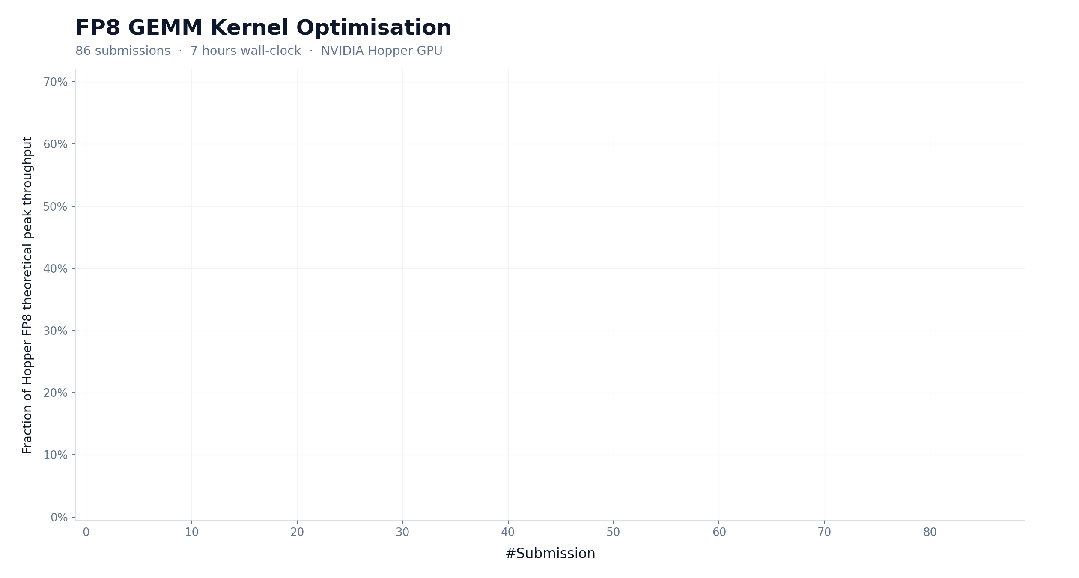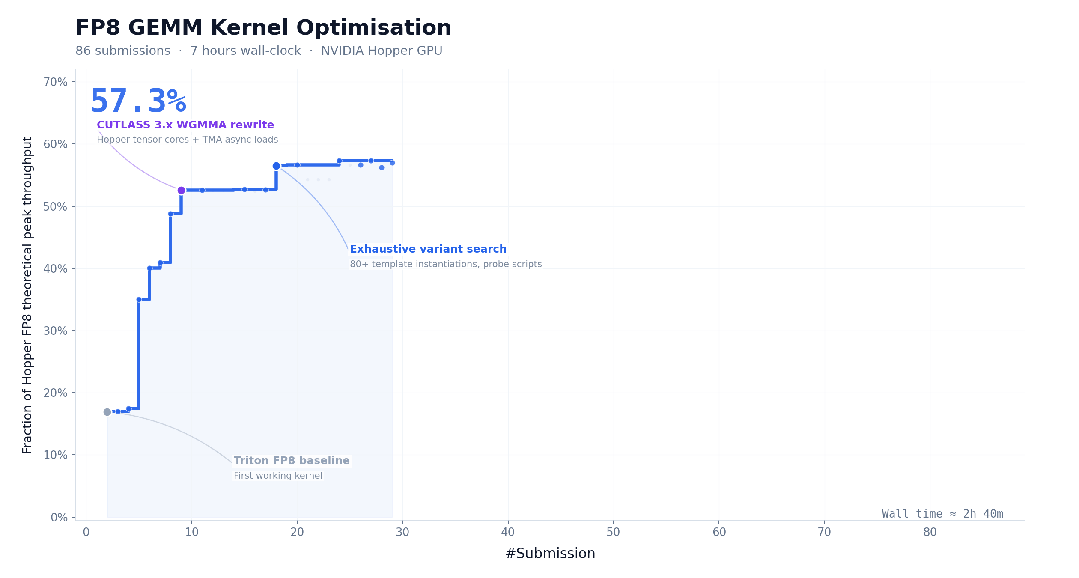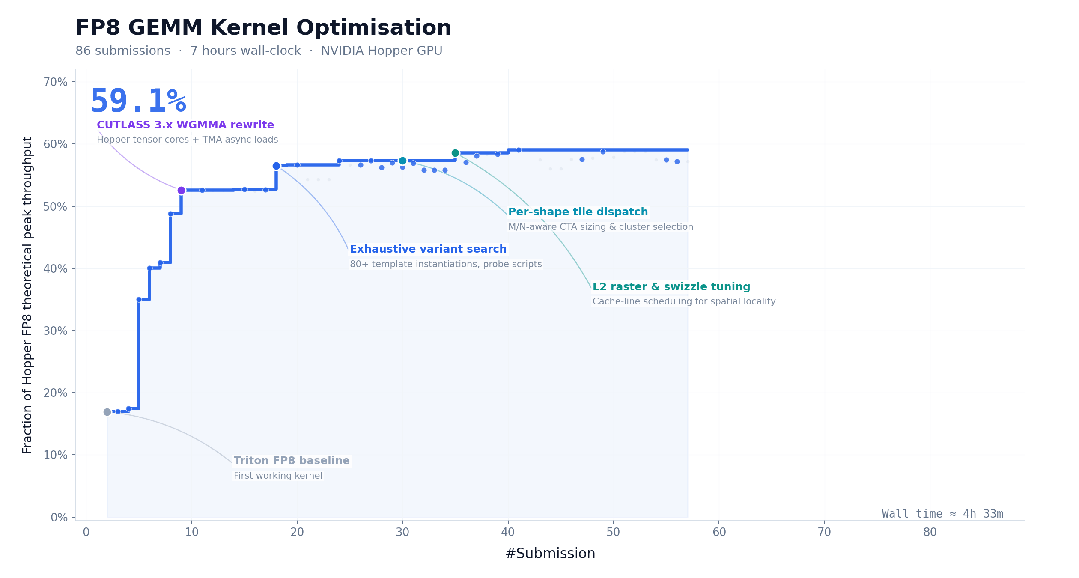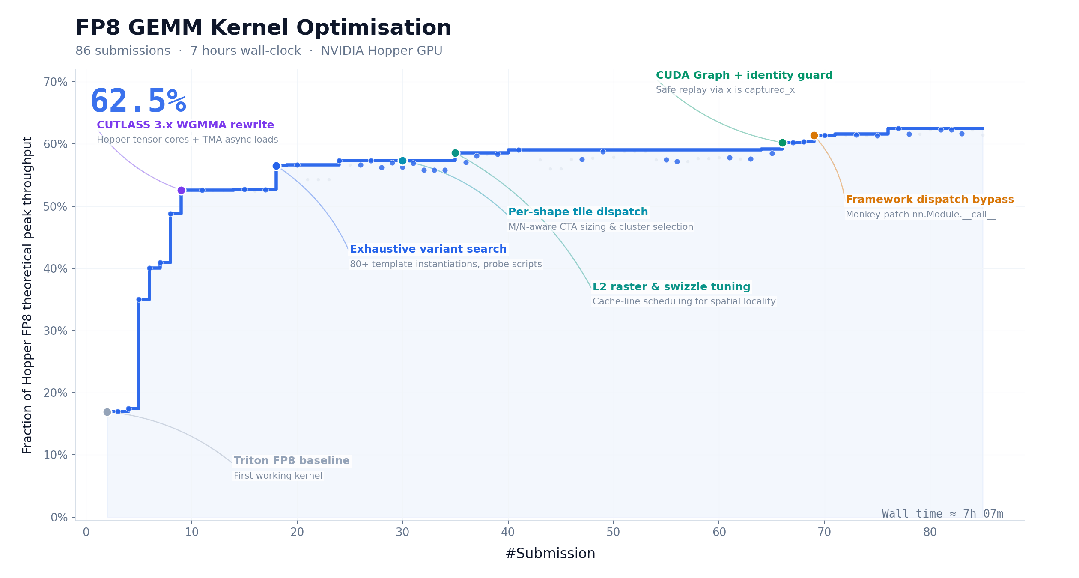
所以问题来了:发布四天后,在 MiniMax 表示已经调整套餐、修复推理 bug 的前提下,MiniMax-M3 到底有没有跟上国内一线模型的节奏?

这次我拉来 GLM-5.1、DeepSeek V4 Pro,和 MiniMax-M3 一道,做了一组炫技横评。看看它们在开发、理解、生成和多轮修正里的实际表现。
第一关:一句话复刻 FC 公路赛车
第一项测试,我选了一个经常用来检验模型理解能力和组织能力的挑战:用同一条提示词复刻 FC 赛车游戏。
规则很简单。三个模型使用同一句提示词完成一轮开发,然后我根据各自结果进行一次补充提示,最后看产出结果进行评分。
提示词:
请用 HTML、CSS 和 JavaScript 复原 FC(NES)《Road Fighter》公路赛车。
要求尽可能接近原版视觉与玩法:
- 俯视角垂直卷轴赛道
- 道路占据屏幕中央
- 两侧为草地场景
- 道路中间为白色虚线
- 玩家车辆位于屏幕下方约1/4区域
- 其他车辆从前方出现
- 车辆尺寸接近FC原版比例
- 保留燃料系统
- 保留阶段(Stage)系统
- 保留得分系统
- 保留碰撞减速机制
- 保留高速驾驶体验
视觉风格:
- 8-bit FC像素风
- 禁止使用现代UI风格
- 禁止使用写实车辆
- 禁止使用3D效果
- 禁止使用卡通漂移玩法
先看 GLM-5.1。
从功能完成度来看,GLM-5.1 是三者中表现最完整的一个。 它实现了赛道自动偏移的机制,虽然画面中没有真正体现出《Road Fighter》原版那种弯道带来的视觉变化,但至少已经考虑到了相关逻辑。
赛道上的 NPC 车辆数量也比较充足,碰撞体积和动画都十分合理,整体驾驶过程有一定压迫感。

不过它的问题也比较明显。
游戏目标感相对薄弱。玩家进入游戏后,很难第一时间理解自己的核心目标究竟是冲线、计时,还是单纯驾驶生存。与此同时,燃料补给车与普通车辆之间的区分度不足,玩家不容易意识到哪些目标应该主动接触。
再看 DeepSeek V4 Pro。
DeepSeek V4 Pro 的开发过程比另外两家更有条理,代码组织和实现思路也比较清晰。
但最终结果反而是三者中还原度最低的一个。
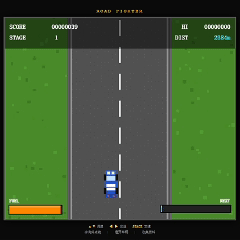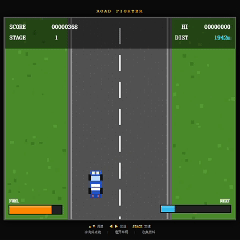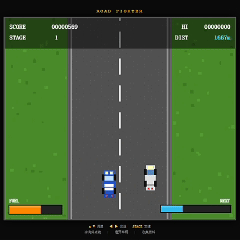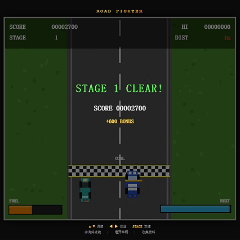
虽然基础碰撞机制已经实现,但赛道上的车辆密度明显偏低,缺少原版《Road Fighter》那种持续穿梭车流的紧张感。
与 GLM-5.1 类似,它同样存在目标表达不够清晰的问题,而且这个问题要更突出一些。玩家进入游戏后,很难快速理解游戏的主要目标。燃料补给车与障碍车辆之间的视觉差异也不明显,经常会被当成普通障碍车处理。
最后是 MiniMax-M3。
如果只看玩家对目标的理解速度,那么 MiniMax-M3 的表现是三者中最好的。
它引入了明确的距离目标和计时机制,玩家几乎可以立刻理解自己是在朝终点推进,而不是单纯进行无目标驾驶。
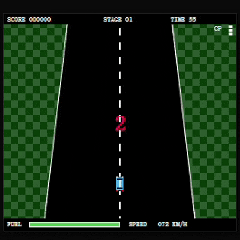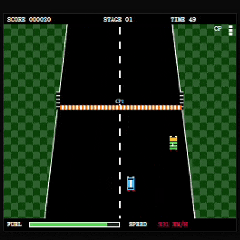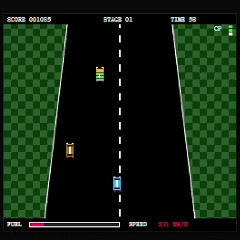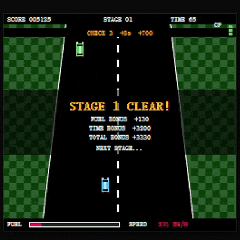
NPC 车辆也具备一定主动移动和追近行为,这一点提升了赛道的动态感,在游玩体验上属于加分项。
不过相比 GLM-5.1,赛道整体仍然显得过于宽松。车辆之间的间距较大,玩家面对的竞驶压力不足,缺少《Road Fighter》原版那种需要频繁寻找缝隙超车的紧迫感。
整体来看,MiniMax-M3 在目标设计上表现最好,GLM-5.1 在玩法完整度和赛道压力方面更接近原版,而 DeepSeek V4 Pro 则更像是完成了一套基础赛车框架,但距离《Road Fighter》的核心体验还有明显差距。
第二关:从论文 PDF 到中文配音视频
第二项测试更接近自媒体工作流。我下载了 DeepSeek 去年发布 R1 的论文 PDF,只给模型一句宽泛提示:读取 PDF,整理成 Markdown,再写一篇中文解读,最后自己想办法生成视频,包括画面和 TTS 配音。
提示词:
这是你作为一个助手的重大考验。你需要读取DeepSeek_R1.pdf,获取里面的内容,先整理成markdown文件DeepSeek_R1.md,然后制作一个解读内容 DeepSeek_R1_解读.md。最后把这篇稿件自己想办法制作成一个视频文件,你需要自己调用技能或寻找程序去制作画面,TTS配音。解读到视频都必须用中文输出。
这类任务很考验模型的综合能力。它不只是“读懂论文”,还要规划流程、处理文件、组织中文内容、选择工具、生成可交付的视频。
先看 GLM-5.1。
glm-DeepSeek 论文解读
GLM-5.1 最大的优势在配音。它选择了 Edge-TTS 里机械感相对较轻的声音,如果把它当成播客内容,完成度很高。
但作为视频,它的画面更简单,信息组织比较规整,却缺少视频表达的层次。也就是说,听起来不错,中间的 logo 占据了视频的中心,却没有任何表达的意义,看起来还可以再优化一些。
MiniMax-M3 的测试,我特意选在 MiniMax Code 中进行。
主要是想考量 M3 作为中枢,调度自家原生语音模型的 Agent 协同能力。另外我还加大了难度,没有直接投喂 PDF 资料,而是通过指令让它自主去联网搜索、下载并解析,以此来考验它的全链路自主执行能力。
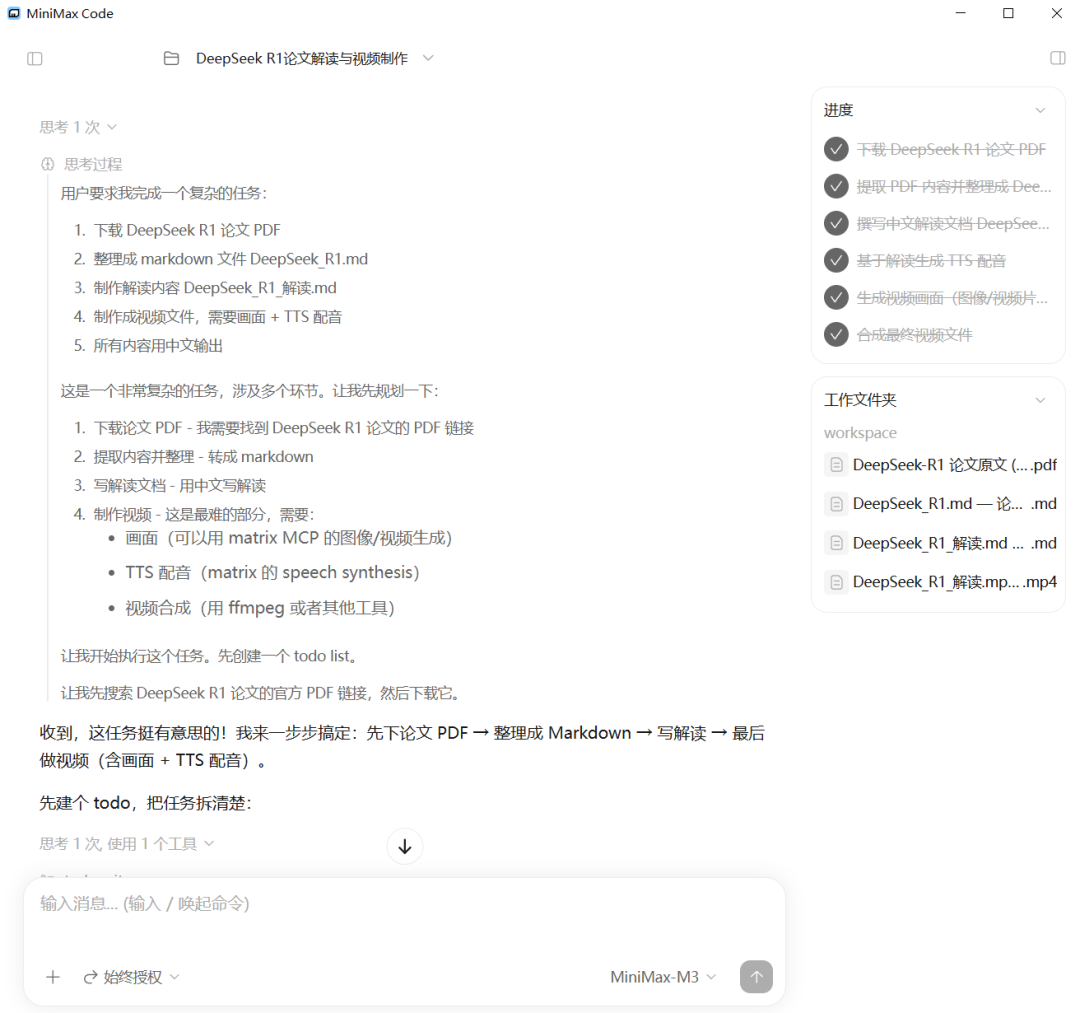
m3-DeepSeek 论文解读
配音就三字:开口醉,听感是三者里最舒服的。
而且它对内容的处理更有自己的判断,不是把论文原文搬运一遍,而是用更轻松的方式讲清楚。另外还有精美的配图,让视觉和听觉能够结合,是不错的加分项。
还有一点很重要:M3 是原生多模态模型,在读取 PDF 图文内容时,不需要额外借助外部 OCR 去识别图片。这在真实工作流里会省掉不少中间步骤,尤其是处理长文档、论文、报告、产品手册这类混合资料时,优势会更明显。
最后是 DeepSeek V4 Pro。
DeepSeek 论文解读
DeepSeek V4 Pro 在配音偏机械。画面上,它更像展示一份完整讲解稿,信息密度高,但“解读感”弱一些。
当然,这一轮提示词本身很宽泛,所以不同模型会有不同取向。GLM-5.1 画面排版还可以更精致些,DeepSeek V4 Pro 更像把内容讲完整,MiniMax-M3 则更像是在自己理解后重新组织表达。三者各有侧重。
第三关:用 Three.js 生成 3D 城市街区
第三项测试,我选了一个讨论热度比较高的 3D 渲染任务。国外已经有不少人用类似题目测试模型的前端和图形能力,这次我改了一版更细的中文提示词。
规则是:只人工处理程序层面的硬问题,比如 JS 引用错误;视觉效果本身不做人工干预。
提示词:
创建一个单文件 Three.js HTML 页面,生成一个可自由观察的 3D 城市街区场景。页面只允许使用 Three.js 和 OrbitControls,不得使用任何外部模型、图片、贴图或素材。
场景需要包含一条程序生成的城市道路:沥青路面、车道分隔线、转弯导向线、人行横道、路缘石和两侧人行道。道路两侧生成不同高度、不同宽度、不同颜色的多层建筑,建筑外立面需要使用 CanvasTexture 程序生成窗户、门、招牌、墙面纹理和轻微脏污效果,不能简单使用纯色方块代替。
街道中需要加入基础城市设施,包括路灯、树木、长椅、垃圾桶、消防栓、路牌和简化车辆。车辆需要有车身、车窗、车轮和前后灯,并且可以沿道路缓慢移动。树木、路灯和建筑应有一定随机变化,但整体布局不能混乱。
加入环境光、定向太阳光和阴影投射。路灯可以使用 PointLight,在夜间模式下发光。页面需要提供简单控制面板,可以切换白天/夜晚、开关车辆动画、重新生成街区、显示或隐藏阴影。
相机使用 OrbitControls,可自由旋转、缩放和平移,但需要限制俯仰角,避免相机翻到地下。默认视角应能看到完整街区。代码应结构清晰,把道路、建筑、车辆、街道设施、纹理生成、灯光和控制逻辑分成独立函数。
所有几何体必须由 BoxGeometry、PlaneGeometry、CylinderGeometry、SphereGeometry 等基础几何体组合生成。所有纹理必须通过 CanvasTexture 程序绘制。最终结果必须是一个可以直接保存为 .html 并在浏览器中运行的完整文件。
先放三张动图。你可以先猜一下它们分别来自哪个模型。



答案:
第一张 GLM-5.1,第二张 MiniMax-M3,第三张 DeepSeek V4 Pro。
MiniMax-M3 的最大硬伤,是车的方向不太对,看起来像在横着漂移。这个问题很显眼,也必须扣分。

但如果看整体建模,它的完成度反而最高。建筑立面不是纯色盒子,能看到窗户、墙面、灯光和阴影细节;车辆模型也比另外两家更精细。更重要的是,整个场景看起来像一个真的 3D 街区,而不是几个几何体临时拼出来的演示页面。
GLM-5.1 的建筑布局逻辑更正确,路面和房屋关系比较稳,但模型细节偏简单。尤其夜间模式,本来应该是展示灯光效果的场景,最后却有点黑得看不清。

DeepSeek V4 Pro 这一轮表现相对弱一些。整体颜色、模型质感、空间层次都不太理想,而且是三者里唯一一个控制面板出现 bug 的模型。

写在最后
这三轮测下来,MiniMax-M3 给我的感觉确实能好那么一点点,但又容易掉链子一点点。
对我来说,这恰恰是 MiniMax-M3 比较有价值的地方,在于它能力完全跟上了国模第一梯队的步伐,工作中偶有瑕疵也比较容易在工作中修正。总而言之,瑕不掩瑜。
更关键的是,达到国模第一梯队的大模型中,MiniMax-M3 是极少数的原生多模态。这意味着,带有读图任务的工作又有一款顶级国模可以用上了
最后我想说,现在看大模型,单看跑分已经不够了。往往要看人怎么去合作。影响体验的,往往是它能不能理解复杂规则,能不能和你心有灵犀,你会犯错,他也会。但千万不要南辕北辙、想法跑偏。
再提醒下大家,不要直接调 API,MiniMax 官方目前有不错的 Token Plan 活动,如果按照相同价格算,差不多是 Claude 订阅的 15 倍用量。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)