低成本搭建家庭 AI 服务器:树莓派 + Ollama 完整教程
·
📝 树莓派部署 Ollama + 跨平台调用完整总结
🎯 最终成果
| 项目 | 状态 |
|---|---|
| 树莓派系统 | 64位 (aarch64) |
| 可用空间 | 3.1GB |
| 已安装模型 | qwen2.5:1.5b(约1GB) |
| Ollama 服务 | ✅ 运行中,监听 0.0.0.0:11434 |
| Windows 调用 | ✅ 可连接使用 |
📋 完整部署步骤回顾
第一阶段:环境准备
-
确认系统架构
uname -m # 必须是 aarch64 -
清理空间(删除 Wolfram + Scratch,释放 ~4.7GB)
sudo rm -rf /opt/Wolfram sudo rm -rf "/opt/Scratch 3"
注意:要保证树莓派上的SD卡的空间充足,空间不够可以清理系统烧录中所带来的一些用不上的组件或者库。
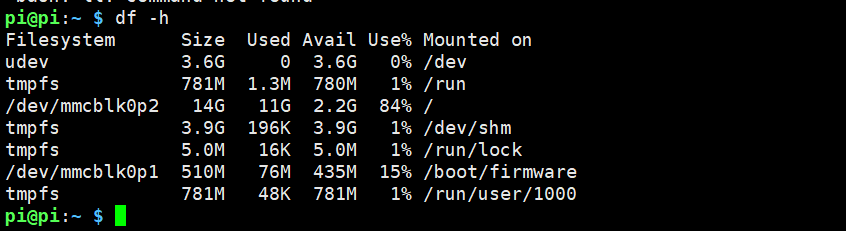
3. 查看空间
df -h /
第二阶段:安装 Ollama
-
下载 Ollama 二进制文件
sudo wget -O /usr/local/bin/ollama https://ollama.com/download/ollama-linux-arm64 sudo chmod +x /usr/local/bin/ollama -
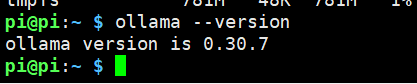
验证安装
ollama --version
第三阶段:启动服务并开放局域网访问
- 启动 Ollama 服务(监听所有接口)
OLLAMA_HOST=0.0.0.0:11434 /usr/local/bin/ollama serve &
- 验证服务状态
sudo netstat -tlnp | grep 11434 # 应显示 0.0.0.0:11434 curl http://localhost:11434/api/tags
第四阶段:下载模型
- 下载中文模型
ollama run qwen2.5:1.5b
第五阶段:Windows 跨平台调用
-
获取树莓派 IP
hostname -I # 例如 192.168.3.217 -
Windows 测试连接
curl http://192.168.3.217:11434/api/tags ```
注意:测试连接的是要保证ollama在树莓派是运行状态中,运行命令如下:
sudo OLLAMA_HOST=0.0.0.0:11434 /usr/local/bin/ollama serve &
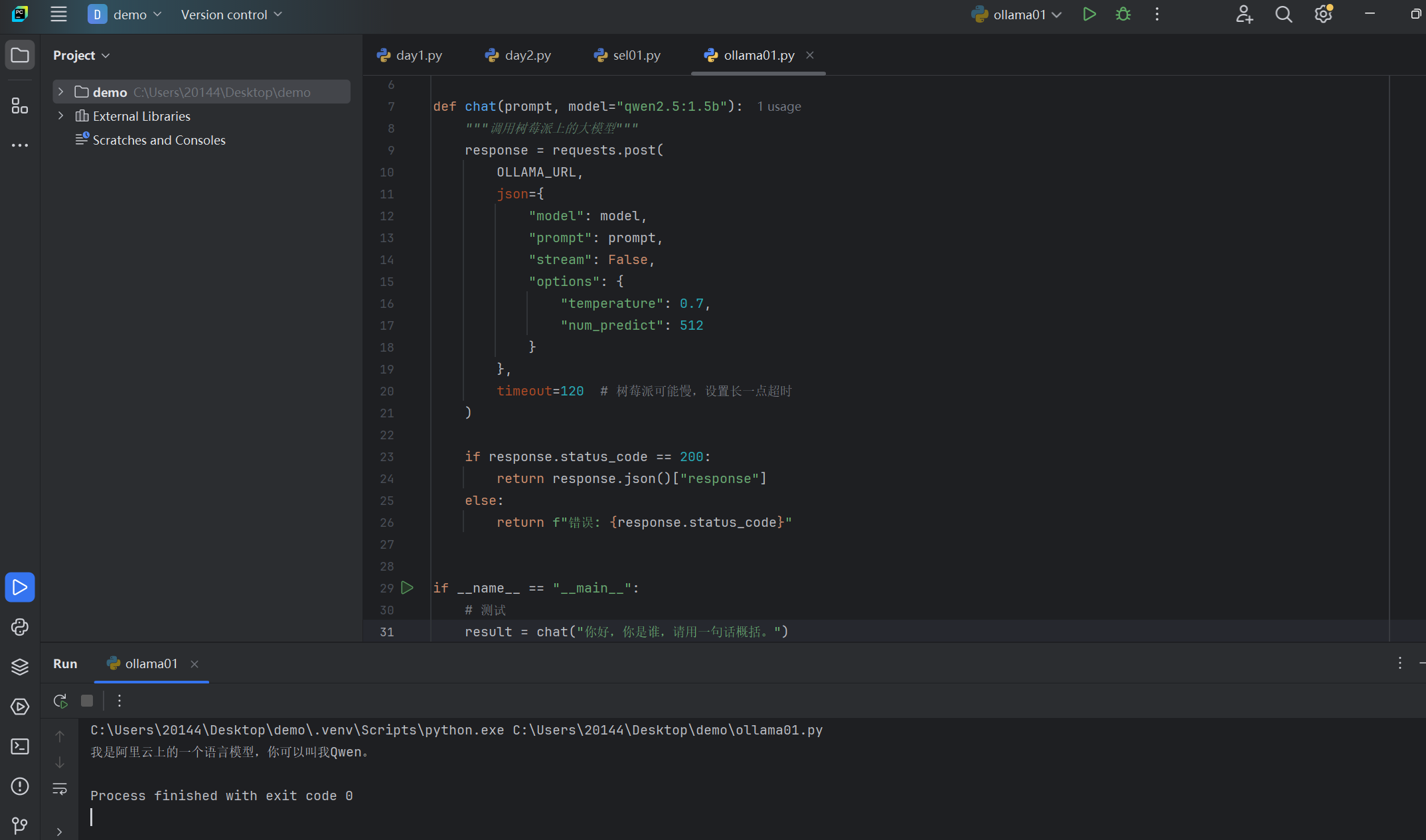
- Python 调用代码
import requests OLLAMA_URL = "http://192.168.3.217:11434/api/generate" def chat(prompt): response = requests.post( OLLAMA_URL, json={"model": "qwen2.5:1.5b", "prompt": prompt, "stream": False} ) return response.json()["response"] print(chat("你好,你是谁,一句话概括。"))
⚠️ 踩过的坑及解决方法
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 空间不足 | Wolfram + Scratch 占 4.7GB | 删除这两个软件 |
| 解压太慢 | SD 卡随机写入慢 | 改用直接下载二进制文件(50MB) |
ollama: command not found |
未复制到 /usr/local/bin |
sudo cp ~/bin/ollama /usr/local/bin/ |
| systemd 启动失败 (status=217/USER) | 服务配置问题 | 改用 nohup 或直接命令行启动 |
| Windows 无法连接 | Ollama 只监听 127.0.0.1 | 设置 OLLAMA_HOST=0.0.0.0:11434 |
连接后 {"models":[]} |
用 sudo 启动,读取了 root 的配置 | 去掉 sudo,用 pi 用户启动 |
🚀 常用命令速查
| 用途 | 命令 |
|---|---|
| 启动服务 | OLLAMA_HOST=0.0.0.0:11434 /usr/local/bin/ollama serve & |
| 查看服务状态 | sudo netstat -tlnp | grep 11434 |
| 查看已安装模型 | ollama list |
| 运行模型 | ollama run qwen2.5:1.5b |
| 删除模型 | ollama rm 模型名 |
| 查看空间 | df -h / |
| 查看树莓派 IP | hostname -I |
📊 性能说明
| 模型 | 速度 | 适用场景 |
|---|---|---|
| qwen2.5:1.5b | 较慢(3-5 tokens/秒) | 中文对话、一般问答 |
| tinyllama | 较快 | 快速响应、轻量任务 |
| gemma3:1b | 中等 | 英文对话、平衡选择 |
树莓派 CPU 推理就是慢的,这是正常现象。 如需更快速度,建议:
- 换更小的模型(tinyllama)
- 外接 USB SSD 启动
- 或直接用电脑跑
✅ 最终验证
# 树莓派上
curl http://localhost:11434/api/tags
# Windows 上
curl http://192.168.3.217:11434/api/tags
两者都应返回包含 qwen2.5:1.5b 的 JSON。
部署完成! 🎉

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)