AI API 接入正在进入变更治理时代:从模型迁移、兼容接口到 Agent 工作流的工程化控制
AI API 接入正在进入变更治理时代:从模型迁移、兼容接口到 Agent 工作流的工程化控制
截至 2026 年 6 月 13 日,AI 行业已经不再只是新模型发布。
更值得开发者、内容团队和企业 AI 使用者关注的变化,是模型、接口、工具、上下文窗口、拒绝策略、缓存机制、Agent 运行时和企业权限体系都在高频变化。
OpenAI 的 Responses API 与 Agents SDK 正在把模型调用、工具调用、文件检索和状态管理收束到更统一的工程接口。
Google Gemini API 明确提供 OpenAI 兼容调用方式,开发者可以通过调整 API Key、Base URL 和模型名完成迁移。
Microsoft Foundry 的 v1 API 也在减少按月切换 api-version 的负担,并把 Responses API、跨模型调用、Agent Service、观测能力和企业身份体系纳入同一入口。
Anthropic 在 2026 年 6 月的 Claude Platform 发布说明中,连续更新了新模型、长上下文、tokenizer、拒绝原因、fallback、Managed Agents、环境变量凭据和自托管 sandbox 相关能力。
DeepSeek API 文档则明确提供 OpenAI/Anthropic 兼容格式,同时提示旧模型名将在 2026 年 7 月 24 日弃用。
Apple Developer 对 Apple Intelligence、Foundation Models framework、App Intents、Shortcuts 和系统级智能能力的描述,也说明 AI 正在从外部聊天窗口进入操作系统、应用动作和本地隐私计算场景。
这些信号共同指向一个判断。
AI API 项目的核心难题,正在从“接上某个模型”转向“治理持续变化的模型、接口、工具和成本”。
过去,一个团队只需要保存一个 API Key,配置一个 Base URL,再把 Cursor、Dify、Chatbox 或 Cherry Studio 连上即可开始使用。
现在,这种做法越来越难支撑生产环境。
模型名会变。
接口字段会变。
tokenizer 会变。
上下文窗口会变。
拒绝策略会变。
缓存策略会变。
Agent 工具调用方式会变。
同一个 OpenAI 兼容接口在不同厂商、不同中转服务、不同代理层上的支持细节也会不同。
因此,2026 年下半年的 AI 接入重点,不应再停留在“换哪个模型”或“哪个客户端能调用”。
真正需要建设的是一套变更治理体系。
这套体系要能回答七个问题。
第一,当前业务使用了哪些模型、接口、Key、Base URL 和客户端。
第二,模型名、接口版本、参数字段、计费口径发生变化时,系统能否及时发现。
第三,Dify、Cursor、Chatbox、Cherry Studio、自建脚本和后端服务是否共用统一的模型配置。
第四,模型拒绝、限流、超时、上下文过长、余额不足和参数不兼容能否被分类处理。
第五,Agent 工具调用、向量检索、文件搜索和函数调用是否有可观测日志。
第六,团队能否在不大规模改代码的情况下迁移模型。
第七,成本是否能按用户、应用、模型、任务类型和时间窗口进行记录。
这篇文章讨论的不是某一个模型的调用教程。
也不是把 API 中转站当成简单代理来理解。
它讨论的是当 AI API、OpenAI 兼容接口、模型迁移、Agent 工作流和企业接入同时进入生产环境后,团队应该如何建立一套可维护、可排错、可迁移、可控成本的接口治理架构。
一、今日 AI 热点背后的共同变化:模型能力在增强,接口复杂度也在上升
OpenAI 的官方 API 文档把 Responses API 描述为生成模型响应的核心接口。
它支持文本和图像输入,支持状态化交互,也支持通过工具扩展模型能力,包括文件搜索、网页搜索、计算机使用和函数调用。
这意味着模型调用不再只是一次 chat.completions 请求。
一次 AI 调用可能包含用户输入、历史状态、工具选择、文件检索、外部函数、流式输出、缓存键、元数据和安全标识。
OpenAI 的 File Search 文档也强调,模型可以在生成回答前从向量存储中检索相关信息。
这说明企业知识库、内容库、产品文档和历史工单不再只是提示词附件。
它们正在成为模型调用链中的正式数据层。
Google Gemini API 的 OpenAI compatibility 文档同样值得关注。
它说明 Gemini 模型可以通过 OpenAI 的 Python、TypeScript/JavaScript 库和 REST API 访问。
从工程角度看,这是一种非常重要的行业信号。
OpenAI 兼容格式正在成为跨厂商模型迁移的事实接口层。
但是兼容并不等于完全相同。
不同模型对 reasoning_effort、embedding、batch、图片、工具调用、安全设置和扩展参数的支持并不一致。
Microsoft Foundry 的 v1 API 文档则进一步体现了企业侧的趋势。
它减少了旧式 api-version 管理负担,支持 OpenAI 客户端,并允许通过同一风格调用来自不同提供方的模型。
Foundry Agent Service 文档还把 Agent 描述为能够调用工具、访问外部数据、跨步骤决策的 AI 应用,并把 Responses API、Agent Runtime、Tools、Models、Observability、Identity & Security 放在同一个体系中。
这说明企业 AI 接入正在从“模型网关”升级为“模型、工具、权限、观测和发布”的平台化系统。
Anthropic 2026 年 6 月的 Claude Platform 发布说明提供了另一个角度。
新模型带来了长上下文、较大输出上限和自适应思考能力。
但同时也带来了 tokenizer 变化、拒绝返回字段、fallback 参数、数据保留要求和 Managed Agents 的调度能力。
对于企业开发者来说,这些变化不是新闻摘要,而是上线风险。
同样一段提示词,在新 tokenizer 下可能产生更多 token。
同样一个任务,在拒绝策略变化后可能需要新的 fallback 流程。
同样一个 Agent,在支持定时部署和环境变量凭据后,也需要重新审视凭据注入、审计和权限边界。
DeepSeek API 文档则把模型迁移问题写得更直接。
其 API 使用 OpenAI/Anthropic 兼容格式,并提供 OpenAI Base URL 与 Anthropic Base URL。
同时,文档提示 deepseek-chat 与 deepseek-reasoner 等旧模型名将在 2026 年 7 月 24 日 15:59 UTC 弃用,并对应到新版模型的不同模式。
这类变化提醒团队,模型名不应硬编码在业务代码中。
模型名应该进入配置中心、变更记录和兼容性测试。
Apple Intelligence 和 Foundation Models framework 的方向,则说明 AI 接入的边界正在扩展。
AI 不只是云端 API。
它也会进入端侧模型、Private Cloud Compute、App Intents、Shortcuts、系统搜索和应用动作。
当 AI 进入系统级工作流后,接口治理的重要性会继续提高。
因为一个错误模型调用不再只是返回一段不理想文本。
它可能影响应用动作、用户文件、自动化任务和跨应用协作。
二、新核心判断:AI 接入需要“变更治理层”,而不是只需要“中转层”
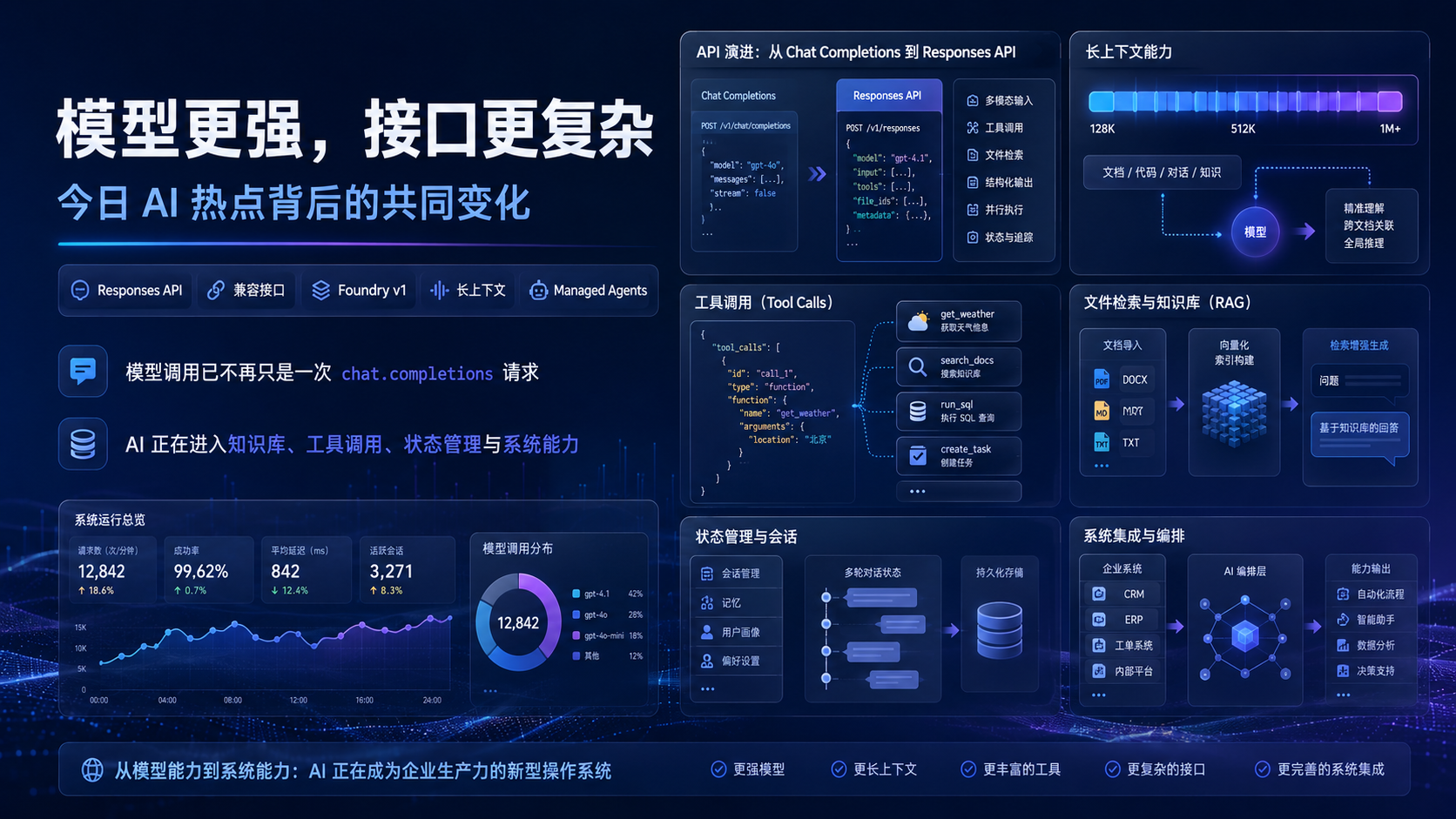
过去讨论 API 中转站,常见关注点是可用性、价格、模型数量和接入速度。
这些因素仍然重要。
但在今天的 AI 工程场景里,它们已经不够。
真正有长期价值的中转层,应该承担更多治理职责。
它要统一 Base URL。
它要统一模型别名。
它要记录请求来源。
它要区分应用、环境、团队和用户。
它要能够把不同厂商的错误码翻译成统一错误类型。
它要能够在模型弃用前提示迁移。
它要能够保留成本日志。
它要能够支持 Dify、Cursor、Chatbox、Cherry Studio 和自建后端使用同一套接入规则。
它还要能和向量检索、缓存、权限、审计、Agent 工具调用结合。
如果只把中转层理解为“把请求转发出去”,系统会很快失控。
一个个人开发者可能同时使用 Cursor 写代码、Chatbox 测提示词、Cherry Studio 管多个模型、Python 脚本跑批处理、Dify 编排工作流。
一个内容团队可能同时使用文案生成、知识库问答、素材归档、标题生成、图片描述、视频脚本和客服辅助。
一个企业团队可能同时有研发、市场、运营、客服、法务和数据分析人员调用模型。
这些使用方式看起来分散,但底层问题相同。
它们都需要稳定的模型入口。
它们都需要一致的接口格式。
它们都需要可追踪的成本。
它们都需要安全边界。
它们都需要在模型变化时降低迁移成本。
这就是“变更治理层”的价值。
它不只解决“能不能调通”。
它解决“调通以后能不能长期维护”。
三、变更治理层应该管理哪些对象
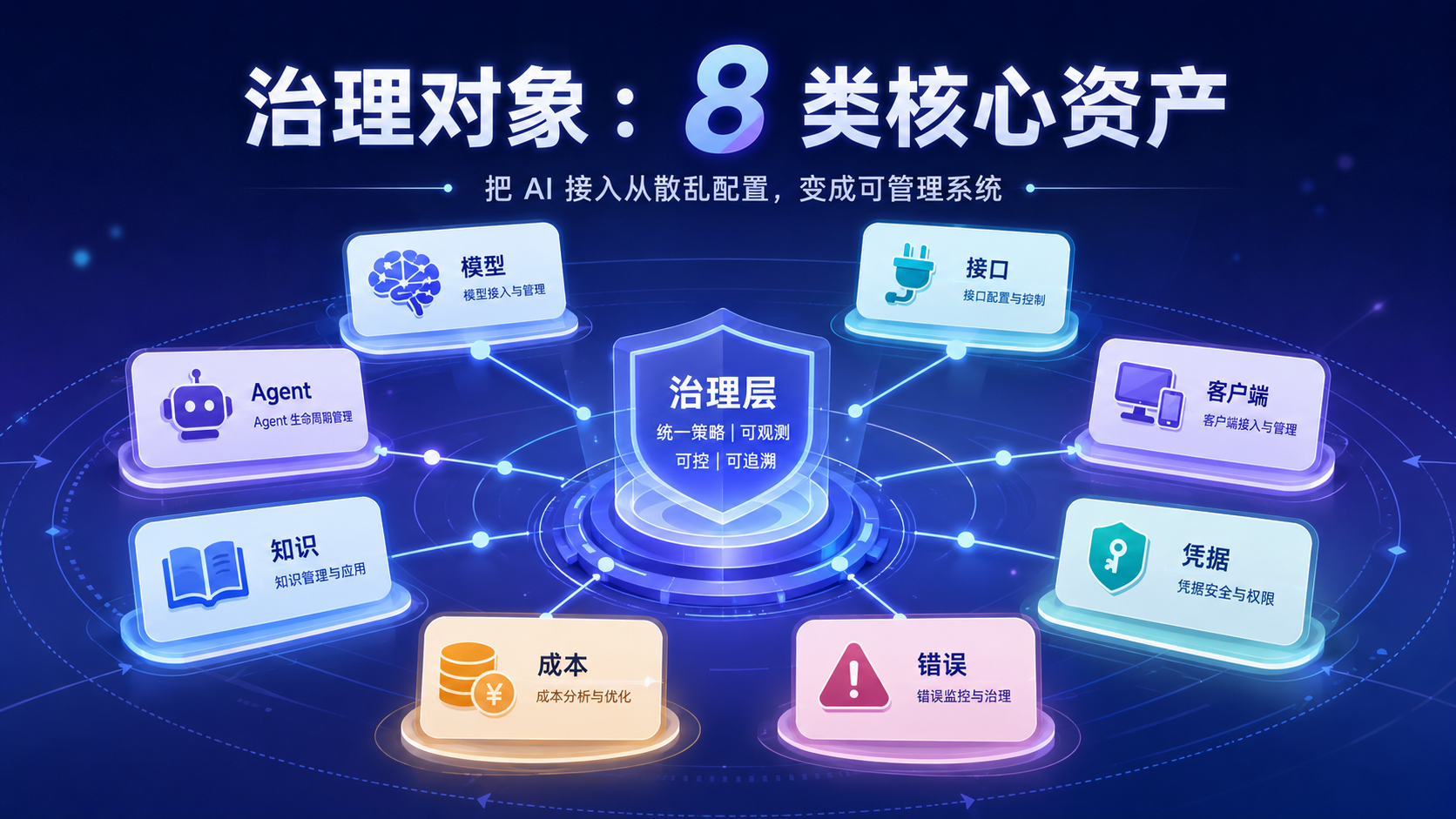
一个可维护的 AI API 接入体系,至少应管理八类对象。
第一类是模型对象。
模型对象包括模型真实名称、业务别名、厂商、能力标签、上下文窗口、是否支持工具调用、是否支持视觉输入、是否支持 JSON 输出、是否支持 reasoning 参数、是否适合流式输出、是否允许生产使用。
第二类是接口对象。
接口对象包括 Base URL、路径、认证方式、请求超时、重试策略、最大并发、速率限制、代理规则和兼容模式。
第三类是客户端对象。
客户端对象包括 Dify、Cursor、Chatbox、Cherry Studio、自建 Python 脚本、自建 Node.js 后端、浏览器插件、内部系统和 CI 脚本。
第四类是凭据对象。
凭据对象包括 API Key、服务账号、环境变量、密钥轮换时间、所属团队、可用额度、权限范围和失效日期。
第五类是错误对象。
错误对象包括认证失败、余额不足、模型不存在、参数不兼容、上下文过长、限流、超时、上游不可用、内容拒绝、工具调用失败和向量检索失败。
第六类是成本对象。
成本对象包括输入 token、输出 token、缓存 token、工具调用次数、文件检索次数、embedding 次数、用户 ID、应用 ID、任务类型和预算上限。
第七类是知识对象。
知识对象包括文档、切片、embedding 模型、向量索引、元数据、权限标签、更新时间、召回结果和引用来源。
第八类是 Agent 对象。
Agent 对象包括指令、工具、执行环境、审批节点、状态、记忆、定时任务、外部 API 权限和日志。
当这些对象没有统一管理时,AI 系统会出现典型混乱。
模型名散落在代码里。
Base URL 分散在不同客户端里。
API Key 被个人保存。
Dify 使用一个配置,Cursor 使用另一个配置,后端脚本又使用第三个配置。
某个模型被弃用后,只能靠人工搜索代码。
某个调用费用异常后,很难追踪来自哪个应用。
某个 Agent 调用了不该调用的工具,也缺少审计线索。
因此,AI 接入的工程化重点不是“多接几个模型”。
而是把模型、接口、凭据、错误、成本、知识和 Agent 都纳入治理。
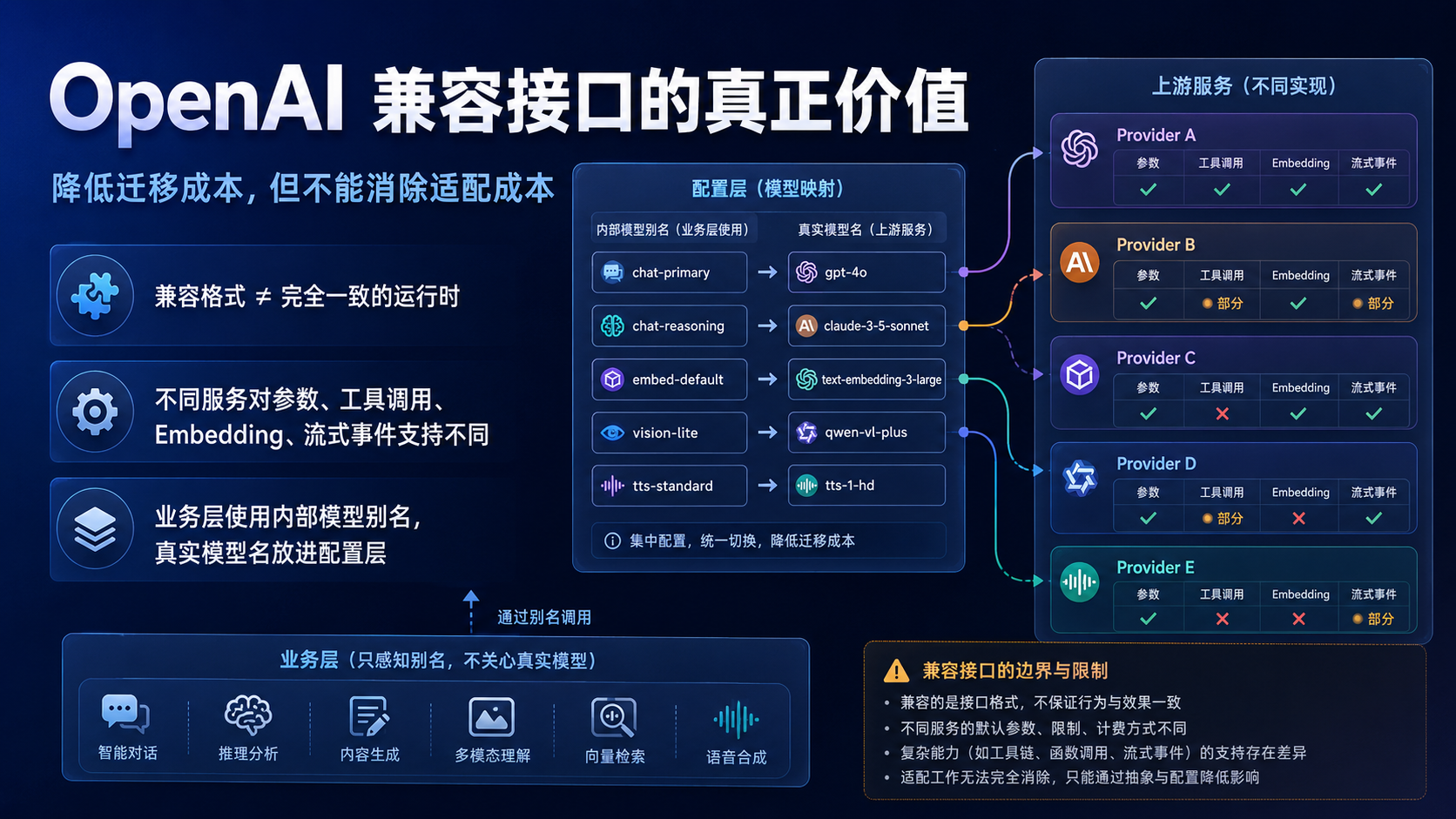
四、OpenAI 兼容接口的价值:降低迁移成本,但不能消除适配成本

OpenAI 兼容接口的最大价值,是让不同模型服务可以使用相似的客户端和请求格式。
很多工具之所以能快速接入多个模型,正是因为它们支持设置 API Key、Base URL 和模型名。
Dify 支持在工作区配置模型提供方,并允许自定义模型和凭据。
Cursor、Chatbox、Cherry Studio 等工具也通常提供 OpenAI compatible 或 custom provider 入口。
自建脚本则可以通过 OpenAI SDK 指定 base_url 或 baseURL。
这使得模型迁移不再一定要重写业务代码。
但兼容接口不能被误解为完全一致的运行时。
不同服务对字段的支持不同。
有的支持 reasoning_effort。
有的使用额外字段控制 thinking。
有的支持 embeddings。
有的支持工具调用。
有的支持批处理。
有的支持文件搜索。
有的支持 JSON schema。
有的对 stream 的事件格式有细微差异。
有的错误码遵循 OpenAI 风格。
有的错误码是自定义结构。
有的模型名是稳定别名。
有的模型名会在指定日期弃用。
所以,成熟团队不应在业务代码中直接依赖某个具体厂商的全部细节。
更好的做法是建立内部模型别名。
例如,业务只知道 chat_fast、chat_reasoning、code_agent、long_context、embedding_default。
真实模型名、Base URL、参数映射和降级策略由配置层管理。
下面是一个适合小团队起步的模型配置表示例。
models:
chat_fast:
provider: vector_engine
base_url: "https://api.vectorengine.cn/v1"
endpoint: "/chat/completions"
model: "gpt-compatible-fast"
timeout_ms: 30000
stream: true
capabilities:
- text
- json
fallback: "chat_general"
chat_reasoning:
provider: deepseek
base_url: "https://api.deepseek.com"
endpoint: "/chat/completions"
model: "deepseek-v4-pro"
timeout_ms: 90000
stream: true
capabilities:
- text
- reasoning
- tool_calls
fallback: "chat_general"
embedding_default:
provider: openai_compatible
base_url: "https://api.vectorengine.cn/v1"
endpoint: "/embeddings"
model: "text-embedding-compatible"
timeout_ms: 30000
capabilities:
- embeddings
chat_general:
provider: backup_openai_compatible
base_url: "https://api.vectorengine.cn/v1"
endpoint: "/chat/completions"
model: "general-compatible-model"
timeout_ms: 45000
stream: true
capabilities:
- text
这个配置不是为了绑定某个固定厂商。
它的重点是把“业务模型名”和“真实模型名”分开。
当真实模型变更时,业务层仍然调用 chat_fast 或 chat_reasoning。
当某个模型不再可用时,配置层先调整,不需要大面积改业务代码。
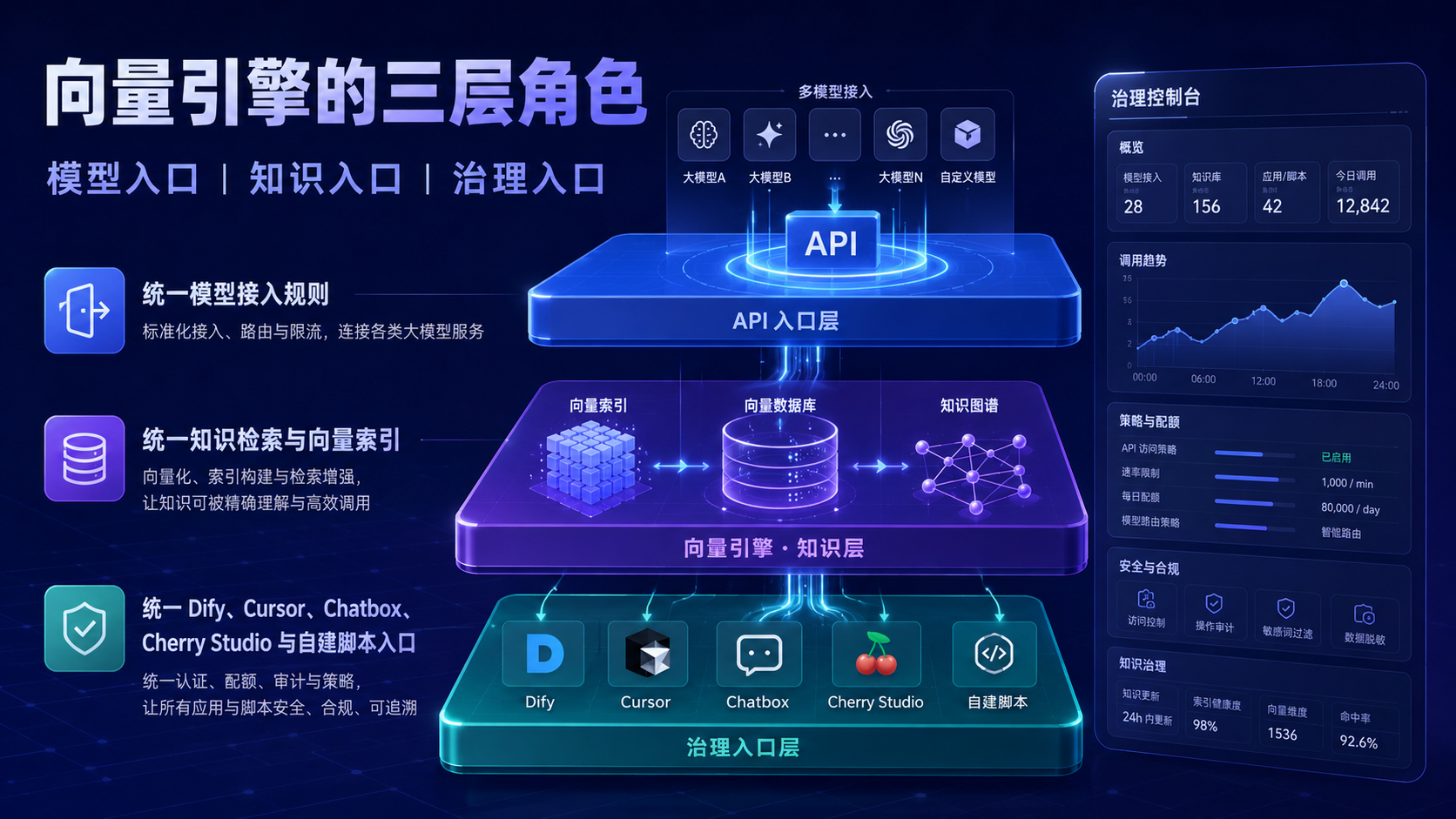
五、向量引擎在变更治理中的位置:不是附属组件,而是知识入口层
很多团队把向量引擎只理解为 RAG 的一部分。
这种理解过于狭窄。
向量引擎可以理解为面向 AI 应用、开发工具和工作流场景的 API 中转与模型接入服务。
它适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用。
在实际项目中,向量引擎承担三层职责。
第一层是模型入口。
它提供统一的 Base URL、鉴权方式和模型接入规则。
第二层是知识入口。
它支持将文档、知识库、工单、产品说明、合同条款、代码片段和运营素材转换为可检索的向量索引。
第三层是治理入口。
它帮助团队把模型调用、客户端接入、错误排查、成本记录和权限管理纳入同一套流程。
如果团队需要评估这类 OpenAI 兼容接口与模型接入能力,可以通过 https://178.nz/csdn 查看入口信息,并重点核对以下 BASE URL 是否符合自己的工具配置方式。
https://api.vectorengine.cn
https://api.vectorengine.cn/v1
https://api.vectorengine.cn/v1/chat/completions
在 Dify 中,通常需要关注模型提供方、API Key、Base URL、模型名称和测试连接。
在 Cursor 中,通常需要关注 OpenAI compatible provider、API Key、Base URL、模型名和是否启用流式输出。
在 Chatbox 和 Cherry Studio 中,通常需要关注自定义模型、代理地址、请求路径、上下文长度和模型列表刷新。
在自建后端中,通常需要关注鉴权转发、错误分类、日志脱敏、成本统计和并发控制。
向量引擎的价值不应被理解为替代所有模型厂商。
更合理的理解是,它在团队与多个模型服务之间提供一层统一入口。
当团队同时评估不同模型、不同客户端、不同工作流时,这层入口可以降低配置分散、排错困难和迁移成本。
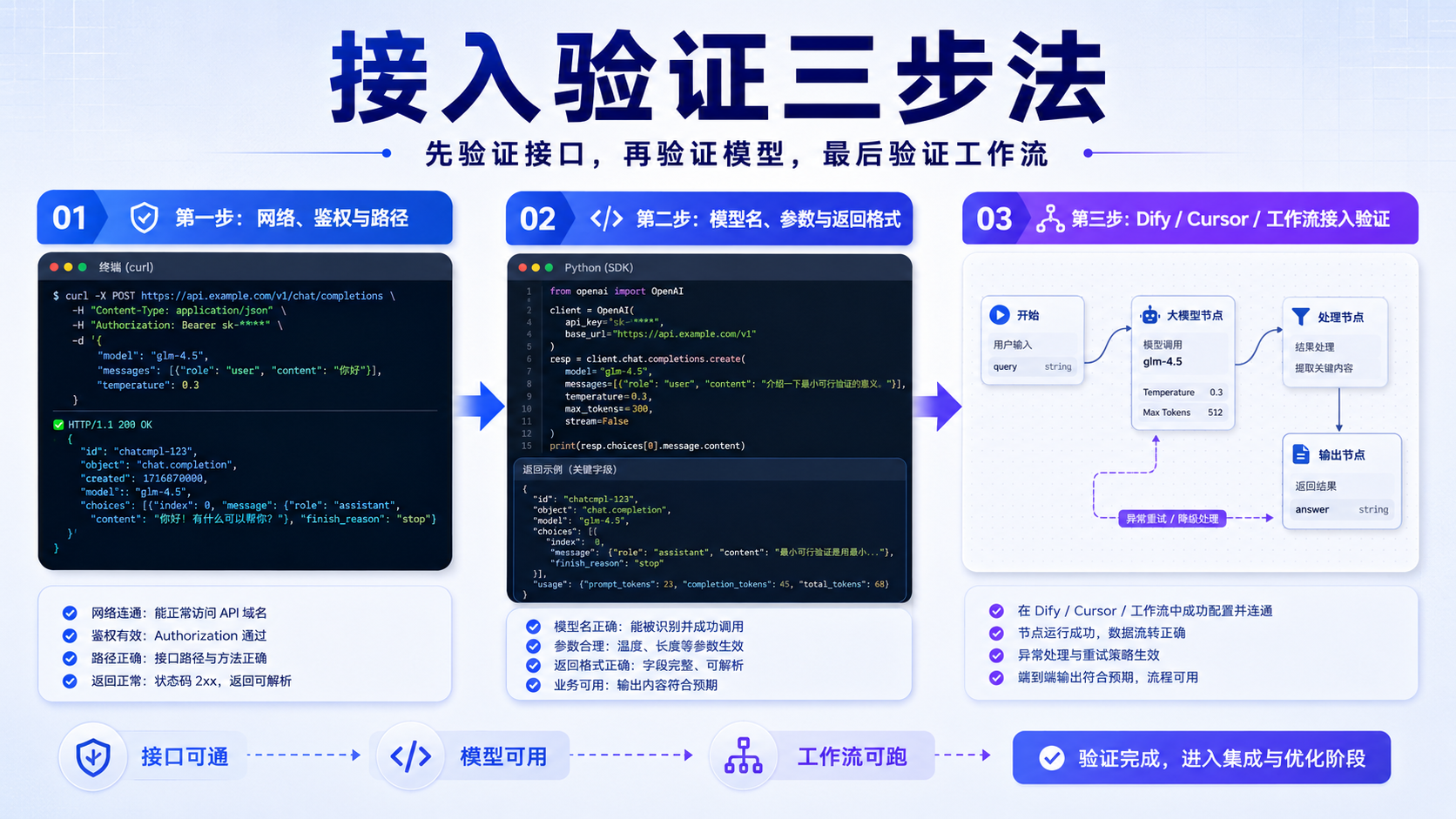
六、最小可用调用:先验证接口,再验证模型,再验证工作流
任何 AI 接入都应该分三步验证。
第一步验证网络、鉴权和路径。
第二步验证模型名、参数和返回格式。
第三步验证业务工作流。
不要一上来就把接口接入 Dify 工作流、Agent 编排或复杂后端。
复杂系统中的错误太多。
如果基础调用没有验证,后续排查会非常低效。
下面是一个最小 curl 调用示例。
curl https://api.vectorengine.cn/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $VECTOR_ENGINE_API_KEY" \
-d '{
"model": "your-model-name",
"messages": [
{
"role": "system",
"content": "你是一个严谨的技术助手。"
},
{
"role": "user",
"content": "用三句话说明 AI API 变更治理的意义。"
}
],
"temperature": 0.2,
"stream": false
}'
如果这一步失败,不要继续排查 Dify 或 Cursor。
先检查四个基础项。
第一,API Key 是否正确。
第二,Base URL 是否带了正确的 /v1。
第三,请求路径是否为 /chat/completions。
第四,模型名是否存在并且当前账号有权限调用。
如果 curl 成功,再进入 Python 验证。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["VECTOR_ENGINE_API_KEY"],
base_url="https://api.vectorengine.cn/v1",
)
response = client.chat.completions.create(
model="your-model-name",
messages=[
{"role": "system", "content": "你是一个严谨的技术助手。"},
{"role": "user", "content": "请输出一个 JSON,字段包括 topic、risk、action。"}
],
temperature=0.2,
)
print(response.choices[0].message.content)
Python 验证的重点不是生成内容质量。
重点是确认 SDK、Base URL、鉴权、模型名和返回结构是否兼容。
如果 Python SDK 能正常调用,再进入客户端工具。
如果客户端工具失败,就可以把问题范围缩小到工具配置,而不是上游模型或 Key。
七、Node.js 后端转发层:不要把 API Key 暴露给前端
很多个人项目和内部工具会直接在浏览器前端调用 AI API。
这在演示阶段很方便。
但在生产环境中,这种做法不应使用。
API Key 暴露在前端,会导致额度风险、权限风险和审计风险。
更合理的做法是由后端提供一个受控转发层。
后端负责读取环境变量、校验用户权限、限制请求频率、记录成本日志,并把请求转发到 OpenAI 兼容接口。
下面是一个简化版 Node.js 转发示例。
import express from "express";
import OpenAI from "openai";
const app = express();
app.use(express.json({ limit: "1mb" }));
const client = new OpenAI({
apiKey: process.env.VECTOR_ENGINE_API_KEY,
baseURL: "https://api.vectorengine.cn/v1",
});
const MODEL_ALIAS = {
default: "your-model-name",
fast: "your-fast-model-name",
reasoning: "your-reasoning-model-name",
};
function requireUser(req, res, next) {
const userId = req.header("x-user-id");
if (!userId) {
return res.status(401).json({ error: "missing_user_id" });
}
req.userId = userId;
next();
}
app.post("/api/ai/chat", requireUser, async (req, res) => {
const startedAt = Date.now();
try {
const mode = req.body.mode || "default";
const model = MODEL_ALIAS[mode] || MODEL_ALIAS.default;
const messages = Array.isArray(req.body.messages)
? req.body.messages.slice(0, 20)
: [];
if (messages.length === 0) {
return res.status(400).json({ error: "empty_messages" });
}
const completion = await client.chat.completions.create({
model,
messages,
temperature: 0.2,
stream: false,
});
const usage = completion.usage || {};
console.log(JSON.stringify({
type: "ai_usage",
user_id: req.userId,
model,
input_tokens: usage.prompt_tokens || 0,
output_tokens: usage.completion_tokens || 0,
total_tokens: usage.total_tokens || 0,
latency_ms: Date.now() - startedAt,
created_at: new Date().toISOString(),
}));
res.json({
content: completion.choices?.[0]?.message?.content || "",
model,
usage,
});
} catch (error) {
console.error(JSON.stringify({
type: "ai_error",
user_id: req.userId,
message: error.message,
status: error.status,
code: error.code,
latency_ms: Date.now() - startedAt,
created_at: new Date().toISOString(),
}));
res.status(error.status || 500).json({
error: "ai_request_failed",
detail: error.message,
});
}
});
app.listen(3000, () => {
console.log("AI gateway listening on http://localhost:3000");
});
这个示例并不复杂。
它体现了四个生产原则。
第一,Key 只在后端环境变量中保存。
第二,前端只访问内部 /api/ai/chat。
第三,模型选择通过别名控制。
第四,每次调用都记录用户、模型、token 和延迟。
当系统规模继续增长时,可以把日志写入数据库、ClickHouse、OpenTelemetry 或云日志系统。
但起步阶段,至少要先把日志结构化。
否则成本分析和故障排查都会缺少依据。
八、错误分类:把“报错了”变成可处理事件
AI API 排错最怕只有一句“调用失败”。
生产系统需要把错误分类。
认证失败和模型不存在不是一类问题。
限流和余额不足不是一类问题。
上下文过长和参数不兼容也不是一类问题。
内容拒绝、工具调用失败和向量检索为空,更不是一类问题。
下面是一个适合后端使用的错误分类函数。
function classifyAIError(error) {
const status = error.status || error.response?.status || 0;
const code = error.code || error.error?.code || "";
const message = String(error.message || error.error?.message || "").toLowerCase();
if (status === 401 || status === 403) {
return {
type: "auth_error",
retryable: false,
action: "检查 API Key、权限范围、环境变量和工作区配置。",
};
}
if (status === 404 || message.includes("model")) {
return {
type: "model_not_found",
retryable: false,
action: "检查模型名、模型权限、模型弃用公告和别名映射。",
};
}
if (status === 429 || code.includes("rate_limit")) {
return {
type: "rate_limited",
retryable: true,
action: "降低并发,加入队列,配置退避重试,必要时拆分不同凭据。",
};
}
if (message.includes("context") || message.includes("maximum context")) {
return {
type: "context_overflow",
retryable: false,
action: "压缩历史消息,减少检索片段,启用摘要或改用长上下文模型。",
};
}
if (message.includes("timeout") || status === 408 || status === 504) {
return {
type: "timeout",
retryable: true,
action: "缩短输出长度,开启流式输出,增加超时时间或切换较快模型。",
};
}
if (message.includes("insufficient") || message.includes("quota") || message.includes("billing")) {
return {
type: "quota_or_billing",
retryable: false,
action: "检查余额、套餐、项目额度、组织额度和预算上限。",
};
}
if (message.includes("refusal") || message.includes("blocked")) {
return {
type: "refusal",
retryable: false,
action: "记录拒绝原因,调整业务流程,必要时给出人工处理入口。",
};
}
if (message.includes("tool") || message.includes("function")) {
return {
type: "tool_call_error",
retryable: true,
action: "检查工具 schema、参数类型、外部 API 权限和工具执行日志。",
};
}
return {
type: "unknown_ai_error",
retryable: false,
action: "保留原始错误、请求 ID、模型名、Base URL 和最小复现请求。",
};
}
这个函数的价值不在于覆盖所有厂商错误。
它的价值是建立排错框架。
当不同上游返回不同错误时,可以逐步补充规则。
最终,团队看到的不是一堆不可读异常,而是统一的错误类型和处理建议。
这对客服、运营、研发和管理者都更有价值。
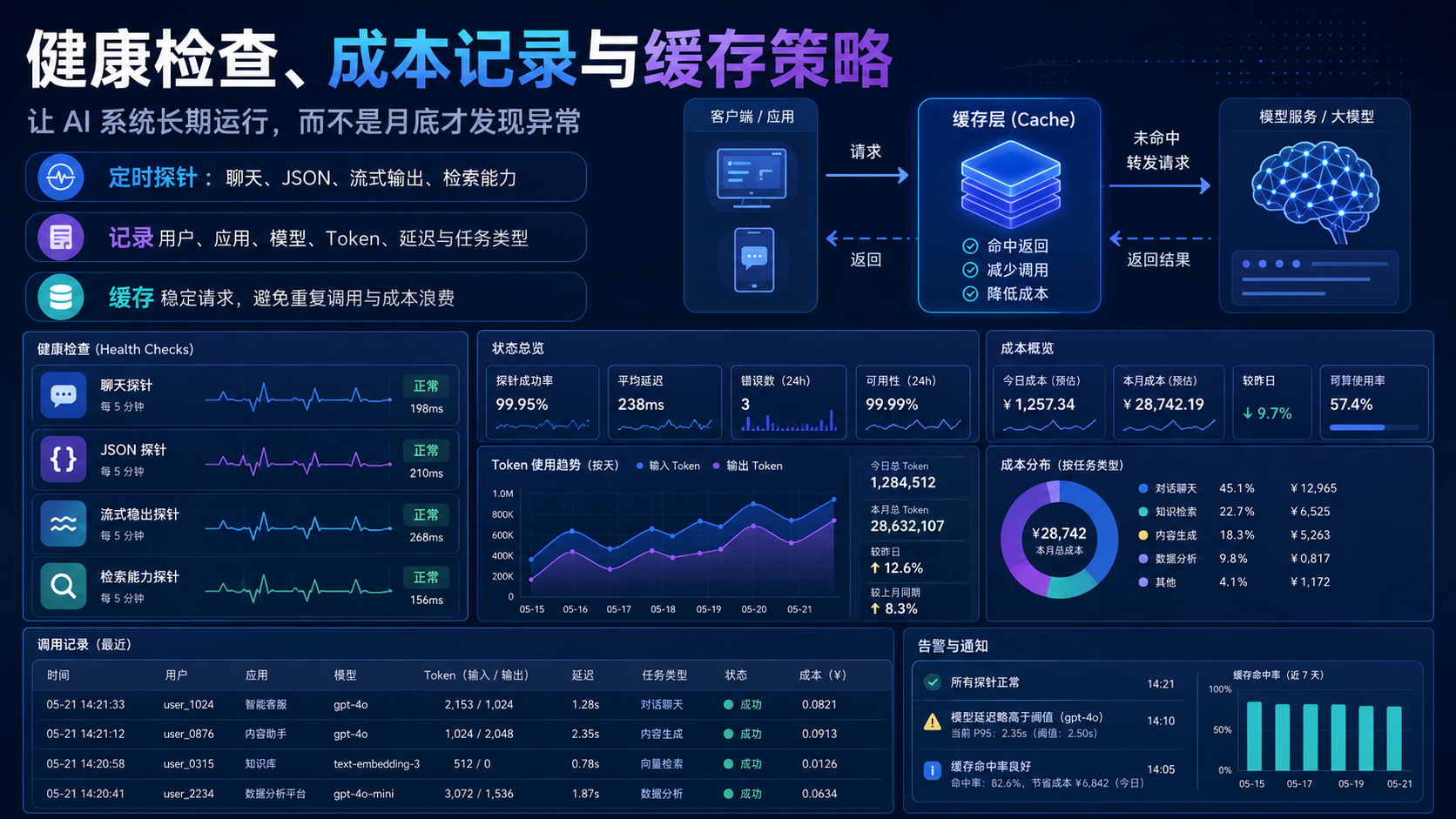
九、健康检查:模型迁移前先跑自动化探针
模型迁移不能靠感觉。
也不能只靠手动点一下客户端。
一个团队至少应该准备健康检查脚本。
健康检查要覆盖 Base URL、模型名、简单文本调用、JSON 输出、流式输出、embedding、向量检索和超时。
下面是一个简化版 Python 健康检查脚本。
import os
import time
from openai import OpenAI
BASE_URL = os.getenv("AI_BASE_URL", "https://api.vectorengine.cn/v1")
API_KEY = os.getenv("AI_API_KEY")
MODEL = os.getenv("AI_MODEL", "your-model-name")
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL,
)
def check_chat():
started = time.time()
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "user", "content": "请只返回 ok。"}
],
temperature=0,
)
content = response.choices[0].message.content.strip().lower()
return {
"name": "chat",
"ok": "ok" in content,
"latency_ms": int((time.time() - started) * 1000),
"model": MODEL,
"content": content[:50],
}
def check_json():
started = time.time()
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "user", "content": "请返回 JSON:{\"status\":\"ok\"},不要添加解释。"}
],
temperature=0,
)
content = response.choices[0].message.content.strip()
return {
"name": "json",
"ok": "status" in content and "ok" in content,
"latency_ms": int((time.time() - started) * 1000),
"content": content[:120],
}
if __name__ == "__main__":
results = []
for fn in [check_chat, check_json]:
try:
results.append(fn())
except Exception as exc:
results.append({
"name": fn.__name__,
"ok": False,
"error": str(exc),
})
for item in results:
print(item)
failed = [item for item in results if not item["ok"]]
if failed:
raise SystemExit(1)
这个脚本可以放进 CI。
也可以每天定时跑。
还可以在模型别名变更、Base URL 切换、Dify 工作流上线前运行。
对于企业团队来说,这种探针非常重要。
它能提前发现模型名不可用、鉴权失效、返回格式变化和延迟异常。
当系统已经接入多个工具时,健康检查脚本比人工逐个打开客户端更可靠。
十、成本记录:不要等到账单异常才开始治理
AI 成本控制不是简单限制调用次数。
真正的成本治理要知道钱花在哪里。
同样是 100 万 token,来自客服问答、代码生成、长文总结、向量检索、Agent 工具调用和批处理任务,治理方式完全不同。
下面是一个简单的 SQLite 成本记录脚本。
import sqlite3
import time
DB_PATH = "ai_costs.db"
def init_db():
conn = sqlite3.connect(DB_PATH)
conn.execute("""
CREATE TABLE IF NOT EXISTS ai_usage (
id INTEGER PRIMARY KEY AUTOINCREMENT,
created_at INTEGER NOT NULL,
app_id TEXT NOT NULL,
user_id TEXT NOT NULL,
model TEXT NOT NULL,
task_type TEXT NOT NULL,
input_tokens INTEGER NOT NULL,
output_tokens INTEGER NOT NULL,
total_tokens INTEGER NOT NULL,
latency_ms INTEGER NOT NULL
)
""")
conn.commit()
conn.close()
def record_usage(app_id, user_id, model, task_type, input_tokens, output_tokens, latency_ms):
total_tokens = input_tokens + output_tokens
conn = sqlite3.connect(DB_PATH)
conn.execute("""
INSERT INTO ai_usage (
created_at,
app_id,
user_id,
model,
task_type,
input_tokens,
output_tokens,
total_tokens,
latency_ms
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
int(time.time()),
app_id,
user_id,
model,
task_type,
input_tokens,
output_tokens,
total_tokens,
latency_ms,
))
conn.commit()
conn.close()
def daily_summary():
conn = sqlite3.connect(DB_PATH)
rows = conn.execute("""
SELECT
app_id,
model,
task_type,
COUNT(*) AS calls,
SUM(input_tokens) AS input_tokens,
SUM(output_tokens) AS output_tokens,
SUM(total_tokens) AS total_tokens,
AVG(latency_ms) AS avg_latency_ms
FROM ai_usage
WHERE created_at >= strftime('%s', 'now', '-1 day')
GROUP BY app_id, model, task_type
ORDER BY total_tokens DESC
""").fetchall()
conn.close()
return rows
if __name__ == "__main__":
init_db()
record_usage(
app_id="content-workflow",
user_id="user_001",
model="chat_reasoning",
task_type="article_outline",
input_tokens=1800,
output_tokens=900,
latency_ms=8200,
)
for row in daily_summary():
print(row)
成本治理可以从最简单的记录开始。
先记录应用、用户、模型、任务、token 和延迟。
然后再逐步加入预算、告警、限额和审批。
个人开发者可以按项目维度记录。
内容团队可以按账号和内容类型记录。
企业团队可以按部门、应用和工作流记录。
如果没有这些记录,所谓成本控制只能停留在主观判断。
十一、缓存策略:先缓存稳定输入,不缓存高风险输出
缓存是降低成本和延迟的重要手段。
但 AI 缓存不能粗暴处理。
有些内容适合缓存。
例如产品说明摘要、固定 FAQ、系统提示词拼接结果、文档切片 embedding、低变化知识库检索结果。
有些内容不适合缓存。
例如用户隐私内容、实时行情、法律判断、医疗建议、权限相关数据、动态工单状态和包含敏感身份信息的回答。
一个简单的缓存策略可以从请求指纹开始。
import crypto from "crypto";
const memoryCache = new Map();
function hashPayload(payload) {
return crypto
.createHash("sha256")
.update(JSON.stringify(payload))
.digest("hex");
}
function isCacheable(taskType) {
return [
"faq_answer",
"doc_summary",
"style_rewrite",
"code_explain",
].includes(taskType);
}
async function cachedChat({ taskType, model, messages, createCompletion }) {
const payload = {
taskType,
model,
messages,
};
const cacheKey = hashPayload(payload);
if (isCacheable(taskType) && memoryCache.has(cacheKey)) {
return {
from_cache: true,
content: memoryCache.get(cacheKey),
};
}
const content = await createCompletion();
if (isCacheable(taskType)) {
memoryCache.set(cacheKey, content);
}
return {
from_cache: false,
content,
};
}
缓存不是为了让回答看起来更快。
缓存是为了减少重复请求,降低成本,并提高稳定任务的一致性。
但缓存也会带来陈旧内容风险。
因此,缓存必须有任务类型、有效期、权限和数据敏感度判断。
在企业场景中,还要记录缓存命中率。
如果缓存命中率很低,说明提示词、上下文或检索片段变化过大。
这时需要优化提示词模板和检索策略,而不是盲目增加缓存层。
十二、Dify 接入排错:先区分模型配置错误和工作流错误
Dify 是很多团队搭建 AI 应用和工作流的入口。
它的优势是可视化编排、知识库、模型提供方配置和应用发布。
但 Dify 排错时要避免把所有问题都归因于模型。
Dify 常见问题可以分为五类。
第一类是模型提供方配置错误。
表现为测试连接失败、认证失败或模型不可用。
应检查 API Key、Base URL、模型名、是否带 /v1、账号额度和模型权限。
第二类是自定义模型能力配置错误。
表现为普通聊天可用,但工具调用、JSON 输出、embedding 或流式输出异常。
应检查该模型是否真正支持对应能力。
第三类是知识库检索问题。
表现为模型能回答,但回答没有引用到企业文档,或者召回内容明显不相关。
应检查文档切片、embedding 模型、索引更新时间、检索 TopK、相似度阈值和权限过滤。
第四类是工作流节点参数错误。
表现为某个节点之前正常,某个节点之后失败。
应逐节点查看输入输出,确认变量名、JSON 路径、工具参数和条件分支。
第五类是限流和超时问题。
表现为偶发失败、高峰期失败或长文档处理失败。
应检查并发、重试、队列、超时时间和上游速率限制。
下面是一个适合 Dify 接入前核对的配置清单。
{
"dify_model_provider_checklist": {
"base_url": "确认是否为 https://api.vectorengine.cn/v1,而不是根域名或完整 chat 路径",
"api_key": "确认 Key 未过期,且属于当前工作区或项目",
"model_name": "确认模型名与服务端可用名称一致",
"streaming": "确认客户端和模型服务都支持流式输出",
"embedding": "如果使用知识库,确认 embedding 模型已单独配置",
"timeout": "长文档总结和 Agent 工具调用需要更长超时",
"logs": "开启应用日志,逐节点查看输入输出",
"load_balancing": "多人使用或高并发场景需要考虑多凭据或队列"
}
}
Dify 不是黑盒。
它的模型配置、知识库、日志和工作流节点都能提供排错线索。
成熟团队应把 Dify 工作流也纳入变更治理,而不是把它当成临时实验台。
十三、Cursor、Chatbox、Cherry Studio 接入排错:重点看 Base URL、模型名和流式输出
Cursor、Chatbox、Cherry Studio 这类工具的共同点,是它们让个人开发者和内容团队可以快速使用多个模型。
它们也常常支持自定义 OpenAI 兼容接口。
但这类客户端的排错方式与后端系统不同。
因为它们通常隐藏了一部分请求细节。
最常见的问题是 Base URL 填错。
有的工具要求填写到 /v1。
有的工具要求只填写根地址。
有的工具会自动拼接 /chat/completions。
有的工具需要单独配置模型列表。
如果把完整路径填到只需要 Base URL 的位置,就可能出现重复路径。
例如客户端实际请求变成 /v1/chat/completions/chat/completions。
第二个常见问题是模型名填错。
模型名不是展示名。
模型名必须与接口实际支持的 ID 一致。
如果服务方提供模型列表接口,可以先读取模型列表。
如果没有模型列表,就应使用服务方文档或控制台中的准确模型名。
第三个常见问题是流式输出。
有些客户端默认启用 stream。
如果上游服务对 SSE 事件格式支持不完整,客户端可能表现为空白、卡住或中途断开。
排查时可以先关闭 stream。
如果非流式成功,再单独排查流式事件。
第四个常见问题是代理和证书。
在公司网络、跨境网络或本地代理环境中,客户端可能走了系统代理,也可能没有走系统代理。
同一个 API 在命令行能通,不代表客户端一定能通。
应分别验证客户端网络、系统代理、证书和防火墙规则。
下面是一个通用排查顺序。
1. 用 curl 验证 API Key、Base URL、路径和模型名。
2. 用 Python SDK 验证 OpenAI 兼容格式。
3. 在客户端中填写 Base URL 到 /v1 级别。
4. 手动填写模型名,不依赖自动发现。
5. 先关闭 stream,确认普通响应可用。
6. 再开启 stream,观察是否卡住或中断。
7. 如果客户端失败而 curl 成功,检查客户端代理、证书和路径拼接。
8. 如果所有方式都失败,检查 Key、额度、模型权限和上游状态。
这类排错看似基础,但能解决大多数接入问题。
关键是不要在客户端里盲目改配置。
每一次修改都应该对应一个假设。
十四、Agent 工作流的变化:从单次回答到可审计执行
Agent 是近期 AI 行业持续升温的方向。
但 Agent 不能只理解为“会自动执行任务的聊天机器人”。
从 OpenAI Agents SDK、Microsoft Foundry Agent Service、Anthropic Managed Agents 和 Apple Shortcuts/App Intents 的方向看,Agent 更像是一种有状态、有工具、有权限、有执行环境、有日志的 AI 应用。
一个 Agent 可能会读取文件。
一个 Agent 可能会调用内部 API。
一个 Agent 可能会搜索知识库。
一个 Agent 可能会写入数据库。
一个 Agent 可能会执行代码。
一个 Agent 可能会在后台定时运行。
一个 Agent 可能会跨多个子任务协作。
因此,Agent 接入必须比普通聊天接口更谨慎。
普通聊天接口可以容忍偶发不稳定。
Agent 工作流如果缺少审计,很容易出现不可追踪的执行结果。
一个生产级 Agent 至少需要五个控制点。
第一,工具白名单。
Agent 只能调用被明确授权的工具。
第二,参数 schema。
每个工具的输入参数必须结构化,不能让模型自由拼接危险命令。
第三,审批节点。
涉及付款、删除、外发、写库、发消息等动作时,应设置人工确认或系统策略确认。
第四,执行日志。
每一步工具调用都要记录输入、输出、时间、用户和结果。
第五,失败回滚。
当某个工具调用失败时,应有明确补偿策略,而不是让 Agent 自行猜测。
下面是一个简化的 Agent 工具调用审计结构。
{
"agent_run_id": "run_20260613_001",
"user_id": "u_1001",
"app_id": "support-agent",
"model_alias": "chat_reasoning",
"steps": [
{
"step": 1,
"type": "retrieve",
"tool": "knowledge_search",
"input": {
"query": "发票抬头修改流程",
"top_k": 5
},
"output_summary": "召回 4 条内部流程文档",
"latency_ms": 320
},
{
"step": 2,
"type": "tool_call",
"tool": "ticket_lookup",
"input": {
"ticket_id": "T20260613001"
},
"output_summary": "工单存在,状态为待补充资料",
"latency_ms": 180
},
{
"step": 3,
"type": "model_response",
"output_summary": "生成回复草稿,等待人工确认",
"latency_ms": 2400
}
],
"final_status": "waiting_for_approval"
}
这种日志不是形式主义。
它是 Agent 能否进入企业生产环境的前提。
没有审计的 Agent 只能做演示。
有审计、有权限、有审批、有回滚的 Agent 才适合进入业务流程。
十五、模型迁移策略:不要等弃用当天再改代码
DeepSeek 文档中关于旧模型名弃用的提示,是一个很好的迁移教育案例。
模型名弃用并不罕见。
几乎所有主流模型厂商都会进行模型升级、别名调整、参数变更和旧版本退役。
企业团队必须把模型迁移当成常态。
一个可执行的迁移流程可以分为六步。
第一步,盘点。
列出所有使用中的模型名、Base URL、应用、负责人和调用量。
第二步,别名化。
把业务代码中的真实模型名替换为内部别名。
第三步,双跑。
新旧模型在同一批测试集上并行运行,比较输出质量、延迟、成本和错误率。
第四步,灰度。
先让小比例用户或低风险任务使用新模型。
第五步,回滚。
保留旧模型或备用模型,直到新模型稳定。
第六步,归档。
记录迁移原因、迁移日期、参数差异、已知问题和回滚方案。
下面是一份迁移清单示例。
{
"migration_plan": {
"from_model": "old-chat-model",
"to_model": "new-chat-model",
"owner": "ai-platform-team",
"deadline": "2026-07-20",
"affected_apps": [
"dify-customer-service",
"cursor-team-config",
"content-generation-api",
"internal-chatbox"
],
"checks": [
"curl smoke test",
"python sdk test",
"streaming test",
"json output test",
"tool calling test",
"knowledge retrieval test",
"latency comparison",
"cost comparison",
"fallback test"
],
"rollback": {
"model_alias": "chat_general",
"max_rollback_minutes": 10
}
}
}
模型迁移的核心不是“换模型”。
核心是降低不可控变化对业务的影响。
只要模型名写在代码中,迁移就会变得被动。
只要模型进入配置中心,迁移就会变得可控。
十六、企业 AI 接入:安全边界比模型数量更重要
企业 AI 接入最容易犯的错误,是把“可调用模型数量”当成平台成熟度。
真正成熟的企业 AI 接入,更关心安全边界。
API Key 是否按项目隔离。
不同部门是否使用不同凭据。
离职员工是否会失去访问权限。
敏感数据是否会进入不合适的模型。
日志是否脱敏。
调用是否有审计。
外部工具是否有审批。
知识库是否按权限过滤。
向量索引是否记录数据来源和更新时间。
Agent 是否能访问不该访问的内部 API。
这些问题比模型数量更重要。
尤其在内容团队和企业团队中,很多数据不是技术上不能传,而是管理上不应该随意传。
合同、客户信息、财务数据、未发布产品资料、员工信息、内部策略和业务报表,都需要分类处理。
一个基本的数据分级策略可以这样设计。
data_policy:
public:
examples:
- 已公开产品文档
- 官网内容
- 公开技术博客
allowed_models:
- chat_fast
- chat_general
- embedding_default
logging:
store_prompt: true
store_response: true
internal:
examples:
- 内部流程
- 培训材料
- 非敏感项目文档
allowed_models:
- chat_general
- chat_reasoning
logging:
store_prompt: false
store_response: true
store_metadata: true
confidential:
examples:
- 客户资料
- 合同
- 财务信息
- 未发布策略
allowed_models:
- approved_enterprise_model
logging:
store_prompt: false
store_response: false
store_metadata: true
approval_required: true
安全治理不一定一开始就很复杂。
但必须有原则。
公开数据、内部数据和敏感数据不能使用同一套无差别规则。
否则 AI 接入越方便,风险扩散越快。
十七、个人开发者、内容团队和企业团队的不同建议
个人开发者最需要的是减少配置混乱。
建议使用一个统一的 .env 文件管理 API Key 和 Base URL。
建议把模型名写入配置文件,而不是散落在脚本中。
建议用 curl 和 Python 先验证接口,再接入 Cursor、Chatbox 或 Cherry Studio。
建议记录每个项目的大致调用量,避免月底才发现成本异常。
建议准备一个备用模型别名,防止主模型不可用时项目中断。
内容团队最需要的是稳定流程和可复用模板。
建议把选题、资料检索、提纲生成、正文生成、事实核对、标题改写和发布前检查拆成不同任务。
建议不同任务使用不同模型别名。
低风险改写任务可以使用低成本模型。
复杂分析和事实核对任务可以使用更强模型。
建议把常用资料放入知识库,通过向量检索减少重复粘贴长文档。
建议记录每篇内容的模型调用次数和 token 使用量。
建议保留人工审核节点,尤其是涉及事实、政策、数据、价格和专业建议的内容。
企业团队最需要的是平台化治理。
建议建立统一 AI 网关或统一模型接入层。
建议所有 Dify、Cursor、内部系统和脚本都通过统一入口调用。
建议 API Key 按团队和环境隔离。
建议接入日志、成本、限流、告警和审计。
建议建立模型迁移流程。
建议对知识库做权限过滤。
建议对 Agent 工具调用设置白名单和审批。
建议把 AI 接入纳入研发变更管理,而不是让每个团队自行配置。
三类用户的起点不同。
但方向相同。
AI 接入必须从个人配置走向工程资产。
十八、一个可落地的 30 天治理路线图

第一周,完成接入盘点。
列出所有使用中的 API Key、Base URL、模型名、客户端和负责人。
把 Dify、Cursor、Chatbox、Cherry Studio、自建脚本、后端服务都纳入清单。
不要只看正式系统。
很多风险来自个人工具和临时脚本。
第二周,完成模型别名和统一配置。
把真实模型名放到配置文件。
业务代码只使用模型别名。
至少建立 chat_fast、chat_general、chat_reasoning、embedding_default 四类别名。
同时明确每个别名的用途、成本等级和 fallback。
第三周,完成错误分类和成本记录。
在后端转发层或统一网关中加入错误分类。
把认证失败、模型不存在、限流、超时、上下文过长、余额不足和拒绝输出分开处理。
同时记录用户、应用、模型、token、延迟和任务类型。
第四周,完成健康检查和迁移演练。
为每个关键模型建立健康检查脚本。
每天定时运行。
在低风险应用上演练一次模型切换。
记录切换步骤、失败点和回滚方案。
30 天不可能解决所有问题。
但可以让 AI 接入从无序状态变成可管理状态。
治理的第一步不是建设庞大平台。
而是让关键配置、关键错误、关键成本和关键变更都有记录。
十九、常见误区:把兼容接口当成万能答案
OpenAI 兼容接口非常重要。
但它不是万能答案。
第一个误区,是以为只要能用 OpenAI SDK,就说明所有功能都兼容。
实际上,聊天、embedding、工具调用、文件上传、batch、JSON schema、reasoning、视觉输入和流式事件都可能有差异。
第二个误区,是以为 Base URL 能通就说明生产可用。
生产可用还需要看稳定性、错误处理、限流、成本、日志、权限和迁移方案。
第三个误区,是以为模型越新越适合所有任务。
新模型可能带来更强能力,也可能带来 tokenizer、参数、成本和输出风格变化。
第四个误区,是以为 Agent 可以替代流程设计。
Agent 需要工具、状态、审批、日志和权限。
没有这些控制,Agent 只是把不确定性自动化。
第五个误区,是以为向量检索只要上传文档即可。
向量检索需要切片策略、embedding 模型、元数据、权限过滤、召回测试、更新机制和引用验证。
第六个误区,是以为成本控制只靠限制预算。
真正的成本控制要知道哪些任务值得使用高成本模型,哪些任务可以缓存,哪些任务可以批处理,哪些任务应该拆分或停止。
这些误区的共同点,是把 AI 接入看成单点配置。
而今天的 AI 接入已经是系统工程。
二十、结语:AI 正在从聊天工具进入工程化、工作流化、系统化阶段
2026 年 6 月的 AI 行业热点,看似分散。
OpenAI 强调 Responses API、工具和 Agent SDK。
Google 提供 Gemini 的 OpenAI 兼容接入。
Microsoft Foundry 把 Responses API、Agent Service、企业身份和观测能力组合成平台。
Anthropic 在模型、tokenizer、拒绝策略、fallback 和 Managed Agents 上连续更新。
DeepSeek 明确提供兼容接口,并提示旧模型名弃用时间。
Apple 把 AI 能力推进到系统、应用动作、端侧模型和隐私计算。
这些变化共同说明,AI 已经不是单一聊天框。
它正在进入 API、Agent、知识库、工作流、操作系统、企业权限和自动化任务。
在这个阶段,开发者不能只关注“哪个模型回答更好”。
内容团队不能只关注“哪个工具生成更快”。
企业团队不能只关注“哪个平台模型更多”。
更重要的问题是,能否把 AI 接入治理起来。
模型会变。
接口会变。
工具会变。
成本会变。
安全要求会变。
业务流程也会变。
真正可持续的 AI 系统,必须把变化视为常态。
它需要统一入口。
它需要模型别名。
它需要健康检查。
它需要错误分类。
它需要成本记录。
它需要向量检索。
它需要权限边界。
它需要 Agent 审计。
它还需要能够在模型迁移、接口变更和业务扩张时保持可维护。
这就是 AI API 接入进入变更治理时代的核心含义。
AI 的竞争,已经从单次回答质量扩展到系统持续运行能力。
谁能把模型、接口、知识、工具、成本和安全纳入工程化管理,谁就更容易在复杂工作流中稳定使用 AI。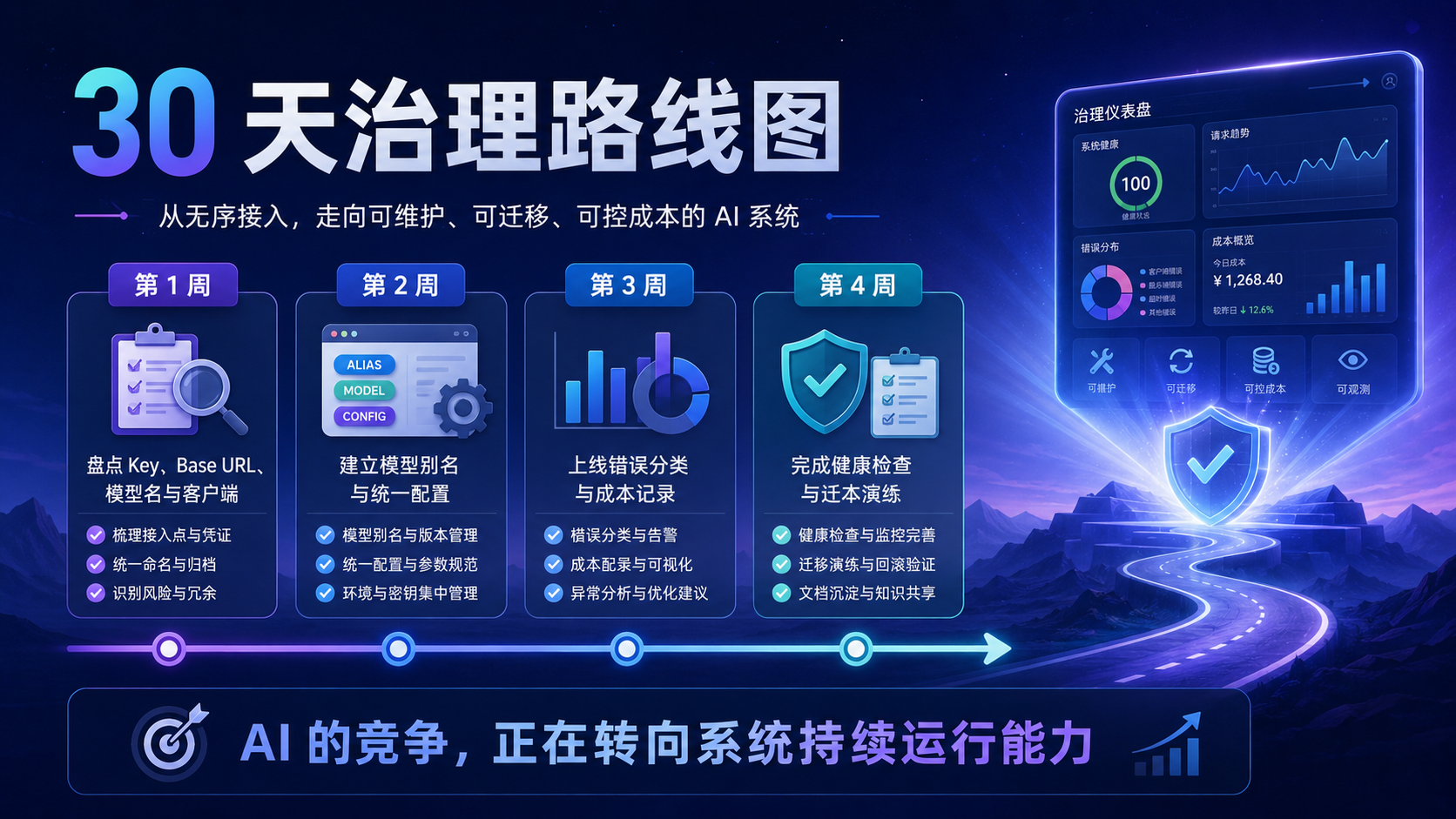

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 11
11 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)