OpenTrackVLA: 轻量化具身智能的工程化突破
1. 具身智能的新纪元:从感知到行动的统一
在人工智能的演进路径中,我们正在经历从"理解世界"到"改变世界"的范式转变。传统的计算机视觉模型只能识别图像中的对象,语言模型擅长处理文本,但当机器人需要在真实物理世界中执行任务时,这些孤立的能力显得力不从心。具身智能(Embodied AI)的核心挑战在于:如何让智能体不仅能够看懂场景、理解指令,还能生成可执行的物理动作来完成任务。
视觉-语言-动作模型(Vision-Language-Action Models, VLA)应运而生,成为解决这一问题的关键技术路线。VLA模型将视觉感知、语言理解和动作规划三个模块深度融合,构建了从感知到决策的端到端闭环。给定一段机器人视角的视频流和自然语言指令,VLA能够直接输出低层级的控制指令,驱动机器人完成诸如"跟随穿红衣服的人"或"导航到厨房拿取杯子"等复杂任务。根据2025年的最新综述研究,过去三年内已有超过80个VLA模型被提出,应用领域涵盖人形机器人、自动驾驶、医疗辅助和精准农业等多个方向。
然而,当前VLA技术在落地过程中面临一个严峻矛盾:性能与可访问性的失衡。以TrackVLA为代表的高性能模型普遍采用70亿参数级别的Vicuna-7B作为语言骨干网络,这种规模的模型虽然在复杂推理任务上表现出色,但对硬件资源的需求极高,单次推理就需要占用数十GB显存。更关键的问题是,大多数前沿研究仅开放推理权重,训练代码和数据处理流程完全封闭,这使得学术机构和中小型企业难以在此基础上进行定制化开发和场景适配。
2. OpenTrackVLA:打破黑盒的全栈开源方案
OpenTrackVLA的诞生源于对上述困境的深刻洞察。这个项目由联汇科技OM AI Lab主导,于2025年12月在GDPS全球开发者先锋大会上正式开源。其核心使命可以概括为"Democratizing Embodied AI"——让具身智能的研发能力从少数顶尖实验室下沉到更广泛的开发者群体。
项目的设计哲学围绕三个核心支柱展开。第一是完全开放的训练栈。不同于TrackVLA仅发布推理代码的做法,OpenTrackVLA公开了从数据预处理、特征提取到模型训练的全部工具链。开发者不仅能够下载预训练模型进行部署,更能在自己的数据集上进行端到端的重训练和微调。这种透明度使得研究者可以深入理解每个组件的实现细节,为算法创新提供了坚实基础。
第二个支柱是极致的参数效率。项目选择Qwen2.5-0.6B作为语言推理骨干,这是阿里巴巴Qwen团队发布的超轻量级语言模型。尽管只有6亿参数,Qwen-0.6B通过在36万亿token的多语言语料上训练,支持最长32768个token的上下文长度,在多项基准测试中展现出远超同规模模型的推理能力。OpenTrackVLA在此基础上针对视觉跟踪任务进行专项微调,在保持低计算开销的同时实现了核心功能的高精度实现。
第三个支柱是工程化的成熟度。项目提供了开箱即用的Docker容器、详细的数据集准备脚本以及自动化的评估流程。支持PyTorch DDP分布式训练框架,可以灵活适配从单张消费级显卡到多卡服务器的各种硬件配置。配套的HuggingFace模型仓库(omlab/opentrackvla-qwen06b)提供了预训练权重的一键下载,开发者可以在数分钟内完成环境搭建并运行第一个推理示例。
OpenTrackVLA在功能定位上专注于具身视觉跟踪(Embodied Visual Tracking)这一特定场景。给定一段第一人称视角的视频流和一条自然语言指令,系统需要持续定位目标对象并规划出短时域的运动路点序列,引导机器人保持跟踪状态。这个任务的技术挑战在于需要同时处理动态遮挡、外观变化、场景复杂性等多重干扰因素,同时保证实时性以满足在线控制的需求。
3. 技术架构深度解析:小参数撬动大性能
OpenTrackVLA的核心竞争力源于其精心设计的模型架构。整个系统由四个关键模块组成:双流视觉编码器、跨模态投影层、语言推理骨干和动作规划头,共同构成了从感知到决策的端到端流水线。
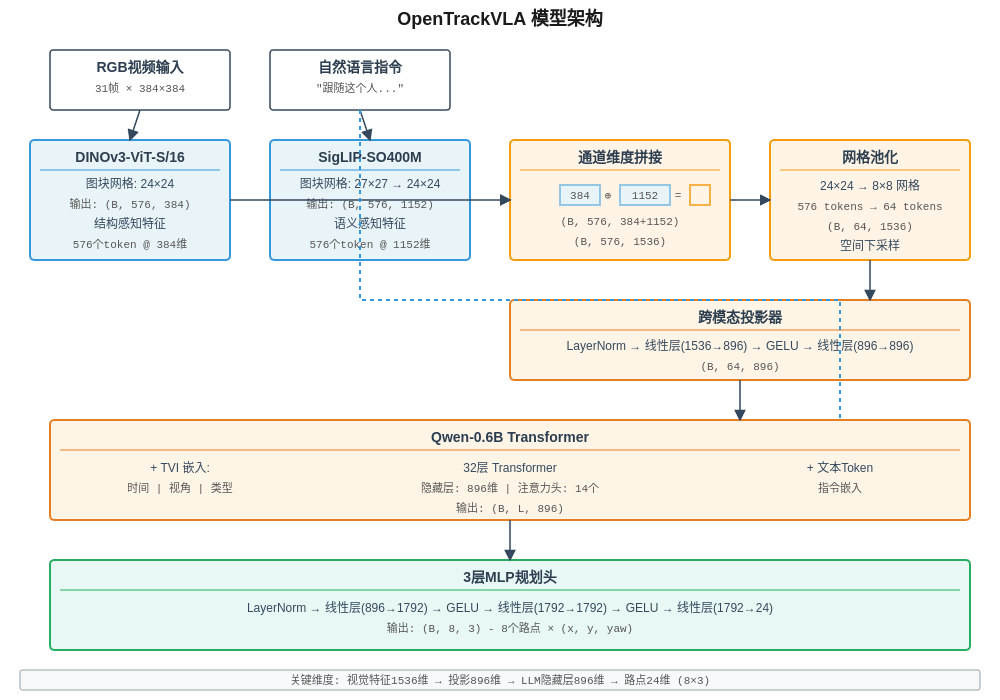
图3: OpenTrackVLA完整模型架构,展示了从输入到输出的完整数据流与特征维度变换
3.1 双流视觉编码:结构与语义的协同
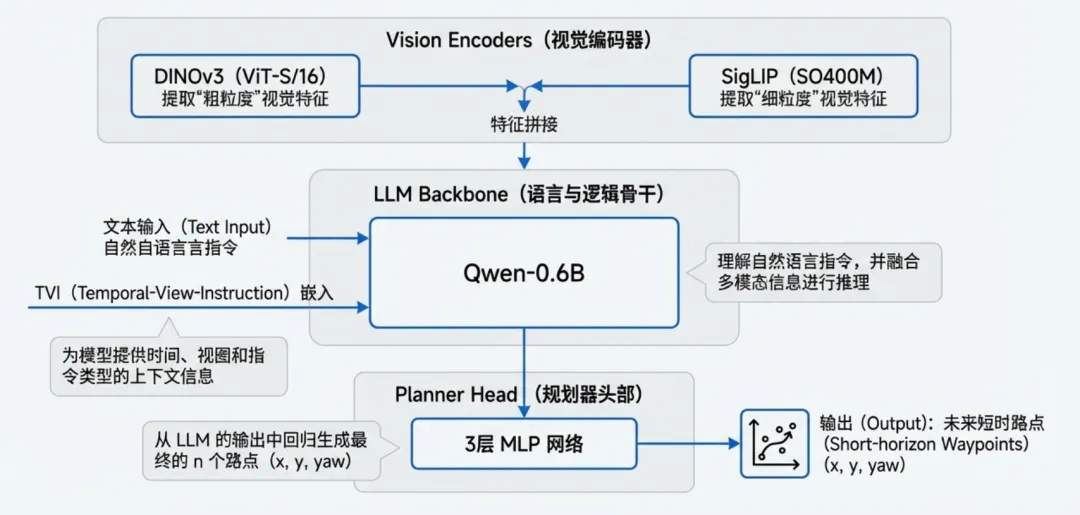
视觉感知是具身智能的第一道关口。OpenTrackVLA采用双流架构并行处理视觉信息,这一设计理念源于对目标跟踪任务本质的洞察:既需要精确的空间定位能力,也需要对指令语义的深刻理解。
第一条流:DINOv3结构感知编码器。DINOv3是Meta在2023年发布的自监督视觉模型,通过对比学习在大规模图像数据上训练,对物体边界和几何结构具有天然的敏感性。OpenTrackVLA选择了其ViT-S/16变体,处理流程如下:
输入: 384×384 RGB图像
↓ Patch Embedding (16×16 patches)
↓ ViT Transformer Encoder
输出: (Batch, 576, 384) # 24×24网格, 每个token 384维
这576个tokens形成24×24的空间网格,每个token对应原图的16×16像素区域。这些特征擅长捕捉"哪里有物体"的空间定位信息,但对语义属性(如颜色、类别)的编码能力有限。
第二条流:SigLIP语义理解编码器。SigLIP是Google提出的改进版CLIP模型,通过sigmoid损失函数优化视觉-语言对齐,在开放词汇理解任务上表现优异。对于 384x384 的图像,patch 大小通常为 14x14,因此图像被划分为 (384/14) x (384/14) ≈ 27x27 个 patch,总共 729 个 patch。其处理流程为:
输入: 384×384 RGB图像
↓ Patch Embedding (14×14 patches)
↓ ViT Transformer Encoder
输出: (Batch, 729, 1152) # 27×27网格, 每个token 1152维
↓ Adaptive Average Pooling (空间维度池化)
输出: (Batch, 576, 1152) # 对齐到24×24网格
SigLIP原始输出729个tokens (27×27网格),通过自适应平均池化对齐到与DINOv3相同的24×24空间分辨率,得到576个tokens。这些特征强于理解"红色衣服的人"这类语言描述,确保模型能准确响应自然语言指令。
特征融合策略。两路特征在通道维度上拼接,形成联合表示:
DINOv3: (Batch, 576, 384)
⊕ (通道维度拼接)
SigLIP: (Batch, 576, 1152)
‖
(Batch, 576, 1536) # 576个tokens, 每个token 1536维
这一设计避免了复杂的注意力融合机制,在保持轻量级的同时实现了互补能力的叠加。拼接后的特征经过Grid Pooling降低token数量(576→64,即24×24→8×8网格),然后通过CrossModalityProjector (LayerNorm + 两层MLP)将特征维度从1536降至896,正好与Qwen-0.6B的隐藏层大小匹配,完成跨模态对齐。
3.2 TVI嵌入:显式的时空上下文编码
小参数模型的推理能力有限,如何让0.6B的语言模型理解视频的时序结构和多帧关系?OpenTrackVLA的解决方案是TVI(Temporal-View-Instruction)嵌入机制,这是一种显式的上下文编码策略。
TVI由三个独立的嵌入层组成。时间嵌入(Time Embedding)为每个视觉token附加一个可学习的时间戳标识,范围从0到4095,告诉模型"这是第t帧的特征"。视角嵌入(View Embedding)用于区分不同相机视角,虽然当前版本主要针对单目输入,但该设计为未来扩展多相机跟踪预留了接口。类型嵌入(Kind Embedding)区分历史帧和当前帧,这对于模型判断"应该基于历史做预测还是关注当前状态"至关重要。
这三种嵌入通过加法融合到视觉特征中,相当于给每个token打上了身份标签。在训练过程中,模型学会了利用这些标签进行时空推理,例如"t=0到t=30的历史帧显示目标在向右移动,因此未来路点应该继续向右"。这种显式编码大幅降低了小模型的学习难度,避免了让模型从原始像素隐式推断时序关系的复杂性。
3.3 Qwen-0.6B骨干:轻量级的多模态推理中枢
语言模型在VLA架构中扮演了"中央处理器"的角色,负责融合视觉、语言和时空信息,并生成高层语义表示。OpenTrackVLA选择Qwen2.5-0.6B作为骨干网络,这是一个经过精心优化的小型Transformer模型。
Qwen-0.6B包含32层Transformer blocks,隐藏层维度896,注意力头数为14。尽管参数量只有6亿,但其预训练数据规模达到36万亿tokens,覆盖119种语言,这使得它在通用推理能力上远超传统的小模型。在OpenTrackVLA中,Qwen的输入序列由三部分拼接而成:带有TVI嵌入的视觉tokens(31帧历史 + 1帧当前,约18K tokens)、文本指令的token嵌入(通常10-20 tokens),以及一个特殊的action query token。
训练策略上,OpenTrackVLA默认冻结Qwen的权重(freeze_llm=True),仅训练投影层和规划头。这一选择基于两方面考虑:一是避免灾难性遗忘,保留预训练模型的通用推理能力;二是大幅减少可训练参数,从6亿降至约1.8亿,降低过拟合风险。实验表明,即使冻结LLM,模型仍能通过投影层和规划头的学习有效适配视觉跟踪任务。
3.4 规划头:从语义到动作的直接映射
传统VLA模型通常让语言模型生成文本形式的控制指令,例如"向前走0.5米",然后通过额外的解析器转换为机器人可执行的底层命令。这种设计链路冗长且容易累积误差。OpenTrackVLA采用了更直接的方案:用一个简单的3层MLP网络(PlannerHead3L)直接回归路点坐标。
规划头的输入是Qwen输出的action token的隐藏状态(896维),经过LayerNorm归一化后,依次通过两个GELU激活的全连接层(896→1792→1792),最终输出24维向量。这24个数值被reshape为8×3的矩阵,每一行对应一个路点的(x, y, yaw)坐标,分别表示相对于当前位置的前向位移、横向位移和转向角度。
为了保证输出的数值稳定性,网络默认在最后一层使用Tanh激活函数,将坐标范围限制在[-1, 1]之间。训练时采用L1损失函数,直接监督预测路点与真实轨迹的偏差。这种端到端的回归方式完全绕过了语言生成和文本解析的环节,不仅降低了延迟(推理速度达到10 FPS),也提升了控制精度。
4. 环境搭建与快速开始
OpenTrackVLA的部署难度远低于传统VLA系统,得益于其轻量级设计和完善的工程支持。整个环境搭建过程可以在标准的Linux工作站上在30分钟内完成,无需高端GPU即可运行推理。
4.1 依赖环境与安装步骤
项目基于Python 3.9开发,核心依赖包括PyTorch 2.0+、Transformers 4.30+和Habitat-Sim仿真引擎。Habitat-Sim是Meta开发的高性能3D环境模拟器,专为具身AI研究设计,支持逼真的物理交互和光照渲染。OpenTrackVLA使用Habitat来生成训练数据和评估模型性能。
完整的环境安装分为四个步骤。第一步创建独立的Conda虚拟环境,指定Python版本为3.9,并安装cmake用于后续的C++扩展编译:
conda create -n omtrack python=3.9 cmake=3.14.0
conda activate omtrack
第二步安装与CUDA版本匹配的PyTorch深度学习框架。由于Habitat-Sim和视觉编码器都依赖PyTorch进行GPU加速计算,必须确保安装正确的CUDA版本。对于CUDA 11.5环境,推荐安装PyTorch 2.2.2的cu118版本,该版本自带CUDA运行时库,可向下兼容CUDA 11.5驱动:
pip install torch==2.4.1+cu118 torchvision==0.19.1+cu118 torchaudio==2.4.1+cu118 --index-url https://download.pytorch.org/whl/cu118
这里使用PyTorch官方的cu118索引源。由于PyTorch官方未提供cu115预编译版本,cu118是CUDA 11.x系列的最佳选择,其自带的CUDA运行时库可以在CUDA 11.5及以上的驱动环境中正常运行。安装完成后,通过以下命令验证GPU是否正确识别:
python -c "import torch; print(torch.cuda.is_available()); print(torch.version.cuda)"
如果输出True,说明PyTorch已正确配置GPU支持。若使用CUDA 12.x系列,需调整为cu121或cu124版本,可参考PyTorch官方安装页面。
第三步安装Habitat-Sim,这是Habitat生态系统的核心仿真引擎,包含Bullet物理引擎用于碰撞检测和动力学模拟。根据系统环境不同,提供两种安装方式:
方式一:Conda安装(适用于常规环境)
对于CUDA 11.x和较旧驱动版本的系统,可以直接通过Conda安装预编译版本:
conda install habitat-sim=0.3.1 withbullet -c conda-forge -c aihabitat
方式二:源码编译安装(推荐,适用于新驱动/CUDA 12.x+)
如果你的系统使用较新的NVIDIA驱动(如580.x+)或CUDA 12.x/13.x版本,Conda预编译版本可能存在EGL设备枚举问题,表现为unable to find CUDA device 0 among N EGL devices错误。此时需要从源码编译以确保与当前驱动兼容:
# 克隆Habitat-Sim源码
git clone https://github.com/facebookresearch/habitat-sim.git
cd habitat-sim
git checkout v0.3.1
# 安装编译依赖
pip install -r requirements.txt
pip install -e .
# 返回上级目录
cd ..
源码编译过程会自动检测系统的CUDA版本和EGL配置,生成与当前环境完全兼容的二进制文件。编译时间约10-20分钟,取决于CPU性能。如果编译过程中遇到CMake版本问题,可通过pip install cmake --upgrade升级。
安装完成后,通过以下命令验证Habitat-Sim是否正确识别GPU:
# 查看版本以及是否habitat使用gpu了,一般来说是要使用的
python -c "import habitat_sim; print(habitat_sim.__version__); print('GPU:', habitat_sim.cuda_enabled)"
python examples/viewer.py --scene /media/bigdisk/VLN-CE/data/scene_datasets/mp3d/1pXnuDYAj8r/1pXnuDYAj8r.glb
如果出现latform::GlfwApplication: virtual DPI scaling 1
EGL: Failed to get EGL display: One or more argument values are invalid
Platform::GlfwApplication::tryCreate(): cannot create a window with core OpenGL context, falling back to compatibility context
EGL: Failed to get EGL display: One or more argument values are invalid
Platform::GlfwApplication::tryCreate(): cannot create a window with OpenGL context
则代表EGL存在问题,这里提供habitat-sim问题from magnum import shaders, text ImportError: cannot import name ‘text‘ from ‘magnum‘以及Github issue以供学习参考,这里提到ldd $(python -c "import habitat_sim; print(habitat_sim._ext.habitat_sim_bindings.__file__)")有可能是软连接问题,如果解决不了,那就重新装nvidia以及cuda,有可能某些遗漏问题导致的bug。如果出现GL::Context: cannot retrieve OpenGL version: GL::Renderer::Error::InvalidValue Aborted (core dumped)问题我需要强制移除 conda 环境中的图形相关库conda uninstall libgl libegl libglvnd --force来完成加载,因为这些产生了信息冲突
第四步克隆OpenTrackVLA仓库到本地,并进入项目根目录:
git clone https://github.com/om-ai-lab/OpenTrackVLA.git
cd OpenTrackVLA
第四步安装Habitat-Lab,这是Habitat生态系统的高层API封装,提供了任务定义和评估工具:
pip install -e habitat-lab
pip install transformers
pip install modelscope
使用-e参数以可编辑模式安装,方便后续根据需求修改配置文件。至此,核心环境搭建完毕。
4.2 数据集准备:场景与人形目标
OpenTrackVLA的训练和评估依赖两类数据资产:3D场景数据集和人形角色模型。场景数据使用HM3D(Habitat-Matterport 3D)和MP3D(Matterport3D)两个大规模真实室内环境数据集。HM3D包含超过1000个高质量扫描场景,涵盖住宅、办公室、商店等多样化空间;MP3D则提供90个标注完整的多房间场景。
4.2.1 HM3D与MP3D数据集详细对比
为了帮助读者更好地理解这两个数据集的特点和适用场景,下面从多个维度进行详细对比:
| 对比维度 | HM3D (Habitat-Matterport 3D) | MP3D (Matterport3D) |
|---|---|---|
| 场景数量 | 1000+ 个场景 | 90 个场景 |
| 发布时间 | 2021年(较新) | 2017年(较早) |
| 发布方 | Meta与Matterport联合发布 | Matterport公司 |
| 数据规模 | ~15TB(完整版) | ~1.3TB |
| 场景类型 | 住宅、办公室、商店、酒店等多样化空间 | 主要为住宅和办公室的多房间场景 |
| 语义标注 | HM3D-Semantics v0.2(可选下载) | 完整的语义分割标注 |
| 标注精细度 | 场景多但单场景标注相对简单 | 场景少但每个场景标注非常详细 |
| 申请方式 | 通过Habitat工具自动下载(需Token) | 需填写学术申请表,人工审批 |
| 主要用途 | 大规模训练,提供场景多样性 | 精细评估,提供高质量标注 |
通俗理解:可以把这两个数据集类比为"图书馆":
- HM3D 像一个大型公共图书馆——藏书量巨大(1000+场景),涵盖各种类型的书籍(多样化空间),但每本书的批注相对简单。适合用于大规模训练,让模型见识更多不同的环境。
- MP3D 像一个精品专业图书馆——藏书量较少(90场景),但每本书都有详尽的注释和解读(完整标注)。适合用于精细评估和需要高质量标注的研究任务。
在OpenTrackVLA中的角色分工:
- HM3D:主要用于训练阶段,提供丰富多样的场景让模型学习泛化能力
- MP3D:主要用于评估阶段(EVT-Bench),利用其精细标注验证模型性能
选择建议:
- 如果你只是想快速跑通流程或进行小规模实验,可以先只下载HM3D的minival子集
- 如果需要完整训练模型,建议同时下载两个数据集以获得最佳效果
- 如果磁盘空间有限,优先下载HM3D(场景更多样),MP3D可后续补充
这两个数据集需要通过官方渠道申请访问权限。HM3D的申请地址为Habitat官方文档,MP3D则需要前往Matterport3D主页填写学术用途申请表。审批通过后,下载解压到data/scene_datasets目录,这个token是通用的,我们可以参考NaVILA 导航VLA记录(habitat 0.2.4)完成MP3d的下载,然后HM3d,则是
# 设置API令牌
MATTERPORT_TOKEN_ID=a5e78a715f3285af
MATTERPORT_TOKEN_SECRET=676cd40457b6b0fe59adf497e32bd6c3
DATA_DIR=</path/to/vlfm/data>
# 下载HM3D训练集
python -m habitat_sim.utils.datasets_download \
--username $MATTERPORT_TOKEN_ID --password $MATTERPORT_TOKEN_SECRET \
--uids hm3d_train_v0.2 \
--data-path $DATA_DIR
# 下载HM3D验证集
python -m habitat_sim.utils.datasets_download \
--username $MATTERPORT_TOKEN_ID --password $MATTERPORT_TOKEN_SECRET \
--uids hm3d_val_v0.2 \
--data-path $DATA_DIR
python -m habitat_sim.utils.datasets_download \
--username $MATTERPORT_TOKEN_ID --password $MATTERPORT_TOKEN_SECRET \
--uids hm3d_minival_v0.2 \
--data-path $DATA_DIR--uids
默认情况下,下载 train/val/example 场景的数据也会提取 HM3D-Semantics v0.2 的语义注释和配置。要仅下载这些拆分的语义文件,请使用 uid hm3d_semantics。最终形成如下结构:
data/
scene_datasets/
hm3d/
train/00800-TEEsavR23oF/...
val/00009-vLpv2VX547B/...
minival/...
mp3d/
1LXtFkjw3qL/...
17DRP5sb8fy/...
值得一提的是我的hm3d下的常见其实是完全依赖versioned_data当中的数据,hm3d只是一个链接,不是真正的数据
如果你先把下载放在别处,可以用以下命令移动它们:
mv /path/to/hm3d data/scene_datasets/
mv /path/to/mp3d data/scene_datasets/
确保目录名保持小写(hm3d、mp3d),这样Habitat配置才能正确解析。
人形目标模型则通过项目提供的下载脚本自动获取:
python download_humanoid_data.py
该脚本会从Google Drive拉取humanoids.zip压缩包(约2GB),包含20个不同姿态和外观的FBX格式人形模型。若遇到网络问题,可手动下载后解压到data/humanoids目录。这些模型在Habitat中作为动态目标渲染,模拟真实的人员跟踪场景。
4.3 一键推理:使用预训练模型
对于仅需部署推理的用户,OpenTrackVLA提供了HuggingFace托管的预训练权重,支持两种加载方式。
第一种是自动下载模式,通过环境变量指定模型ID,评估脚本会自动从HuggingFace Hub拉取权重:
HF_MODEL_ID=omlab/opentrackvla-qwen06b bash eval.sh
第二种是本地加载模式,适合网络受限或需要离线部署的场景:
huggingface-cli download omlab/opentrackvla-qwen06b --local-dir ./pretrained_model
HF_MODEL_DIR=$(pwd)/pretrained_model bash eval.sh
eval.sh脚本会启动Habitat仿真环境,加载EVT-Bench静态目标跟踪任务(STT),并在指定的测试场景中运行模型。默认配置下,评估会分30个chunk并行处理,每个chunk包含若干episode,最终输出成功率(SR)、跟踪率(TR)和碰撞率(CR)三项指标,以及每个episode的可视化视频。
当评估结束后,我们可以使用下面的功能完成代码评估
python calculate_metrics.py

5. 数据处理流水线:从仿真到训练样本
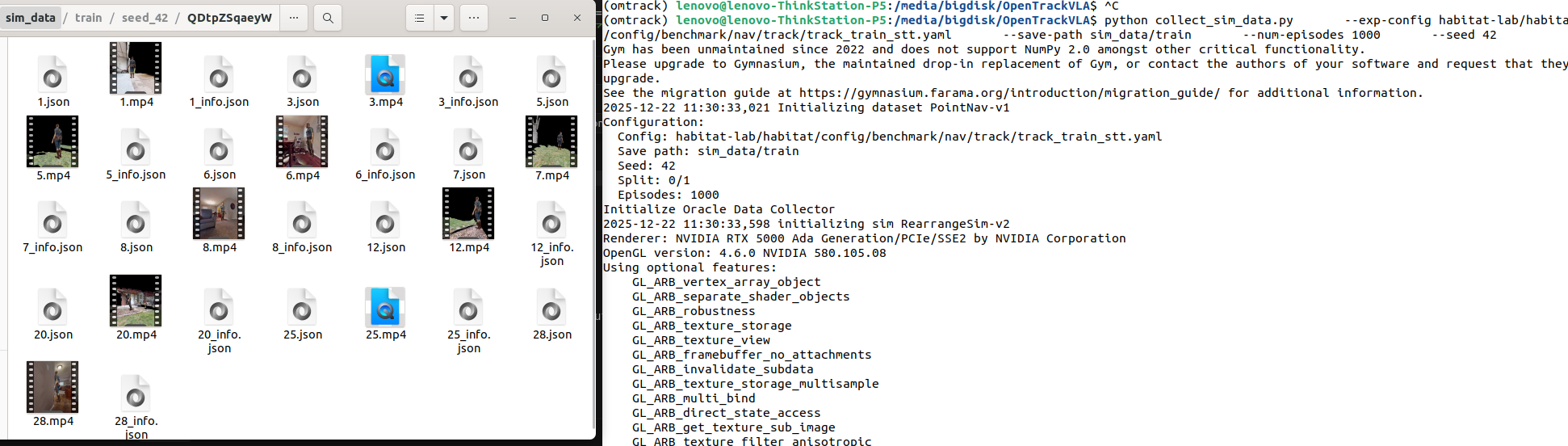
OpenTrackVLA最具工程价值的贡献之一,是提供了完整的数据处理管线,将Habitat仿真器生成的原始episode转化为可直接用于训练的JSONL格式数据集。这套流程包含三个核心阶段:仿真数据采集(collect_sim_data.py)、轨迹数据生成(make_tracking_data.py)和视觉特征预缓存(precache_frames.py)。

图4: 从Habitat仿真到训练样本的完整数据处理流程,展示了四个关键阶段的转换逻辑
5.1 仿真数据批量采集:补全缺失的闭环(新增!)
原始OpenTrackVLA仓库只提供了sim_data/sample下的少量样本数据,但没有提供如何从HM3D/MP3D场景批量生成这些数据的脚本。这导致开发者无法进行大规模训练。现在我们补全了这一关键环节。
5.1.1 问题分析:缺失的数据生成环节
训练流程需要的仿真数据格式如下:
sim_data/
seed_xxx/
<scene_id>/
<episode_id>.mp4 # 机器人视角的RGB视频
<episode_id>_info.json # 每步状态信息(base_velocity, dis_to_human, facing)
<episode_id>.json # Episode统计(success, collision等)
原有的eval.sh和run_eval.py是用于评估训练好的模型,而非生成训练数据。我们需要一个使用Oracle专家策略来控制机器人的数据采集脚本。
5.1.2 Oracle策略原理
Oracle策略是一种基于路径规划的专家策略,其核心思想是:
- 使用Habitat的
pathfinder计算从机器人当前位置到目标人类的最短路径 - 根据路径点计算速度命令(前进速度vx、侧向速度vy、转向角速度wz)
- 添加少量随机扰动增加数据多样性
关键代码逻辑(来自evt_bench/additional_action.py中的OracleNavCoordinateActionForRobot):
def _compute_oracle_action(self, robot_pos, robot_forward, human_pos):
# 1. 计算到人类的路径
path_points = self._path_to_point(robot_pos, human_pos)
# 2. 获取下一个路径点
next_waypoint = path_points[1]
rel_targ = (next_waypoint - robot_pos)[[0, 2]] # 2D相对位置
# 3. 计算速度命令
if dist_to_human < self.dist_thresh:
# 已经很近,只需转向面对人类
vel = self._compute_turn_speed(rel_human, robot_forward_2d)
else:
# 需要移动,计算组合速度(前进+侧向+转向)
vel = self._compute_combine_speed(rel_targ, robot_forward_2d, dist_to_human)
return vel # [vx, vy, wz]
5.1.3 使用collect_sim_data.py采集数据
基本用法:
python collect_sim_data.py \
--exp-config habitat-lab/habitat/config/benchmark/nav/track/track_train_stt.yaml \
--save-path sim_data/train \
--num-episodes 1000 \
--seed 42
参数说明:
| 参数 | 说明 | 默认值 |
|---|---|---|
--exp-config |
Habitat配置文件(STT/DT/AT) | track_train_stt.yaml |
--save-path |
输出目录 | sim_data/train |
--num-episodes |
采集的episode数量 | 全部 |
--seed |
随机种子 | 42 |
--split-id/--split-num |
并行采集时的分片参数 | 0/1 |
并行采集(推荐用于大规模数据):
# 使用一体化脚本进行并行采集
bash generate_train_data.sh --num-episodes 5000 --num-parallel 4 --seed 100
5.1.4 完整数据生成流程脚本
generate_train_data.sh提供了一键式的完整数据生成流程:
# 完整流程:采集 → 处理 → 缓存
bash generate_train_data.sh --num-episodes 5000 --num-parallel 8
# 或分阶段执行:
bash generate_train_data.sh --mode collect # 阶段1:采集仿真数据
bash generate_train_data.sh --mode process # 阶段2:转换为训练格式
bash generate_train_data.sh --mode cache # 阶段3:预缓存视觉特征
完整流程图:
┌─────────────────────────────────────────────────────────────┐
│ 阶段1: collect_sim_data.py (新增!) │
│ 输入: HM3D/MP3D场景 + Humanoid Avatars + Episode定义 │
│ 处理: Oracle策略控制机器人跟踪人类,记录RGB视频和动作 │
│ 输出: sim_data/train/seed_*/scene_id/*.mp4 + *_info.json │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 阶段2: make_tracking_data.py │
│ 输入: sim_data/train/ │
│ 处理: 提取视频帧,积分速度为轨迹,构建滑动窗口样本 │
│ 输出: data/generated/frames/ + jsonl/ │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 阶段3: precache_frames.py │
│ 输入: data/generated/frames/ │
│ 处理: DINO+SigLIP编码,Grid Pooling │
│ 输出: data/generated/vision_cache/*.pt │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 阶段4: train.py │
│ python train.py --train_json data/generated/jsonl \ │
│ --cache_root data/generated/vision_cache │
└─────────────────────────────────────────────────────────────┘
5.1.5 数据格式详解
仿真数据格式(*_info.json):
[
{
"step": 1,
"dis_to_human": 1.628,
"facing": 1.0,
"base_velocity": [0.41, -0.08, -0.22]
},
{
"step": 2,
"dis_to_human": 1.459,
"facing": 0.0,
"base_velocity": [-0.47, -0.13, -0.29]
}
]
Episode统计(*.json):
{
"finish": true,
"status": "Success",
"success": 1.0,
"following_rate": 0.85,
"following_step": 255,
"total_step": 300,
"collision": 0.0,
"instruction": "Follow the man wearing a black jacket."
}
5.2 轨迹数据生成:从速度到路点的积分
…详情请参照古月居

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)