AI 编程避坑指南:从效率幻觉到质量防线的完整攻略
AI 编程避坑指南:从效率幻觉到质量防线的完整攻略
2025 最新数据:AI 让 75% 的开发者以为自己更快了,但随机对照实验显示资深开发者实际慢了 19%。一文讲透 AI 编程的真相、问题和解决之道。

一、AI 编程 vs 传统编程:数据说了算
先用一张表看清 AI 编程和传统编程的本质区别:

关键数据速览(2025 年最新研究)
| 数据指标 | 数值 | 来源 |
|---|---|---|
| AI 工具团队采用率 | 90%(2024 年为 61%) | Jellyfish 2025 |
| 开发者使用率 | 84% | Stack Overflow 2025 |
| 资深开发者实际效率 | -19%(更慢) | METR 随机对照实验 |
| 主观效率感知 | +20%(以为自己更快) | METR |
| AI 代码需重大修改 | 56% | Stack Overflow 2025 |
| 逐行审查 AI 代码 | 75% | Stack Overflow 2025 |
| 高度信任 AI 准确性 | 仅 3.1% | Stack Overflow 2025 |
| AI 代码安全漏洞 | 10 倍于人工 | Apiiro 研究 |
| PR 审查时间增加 | +91% | Faros AI 报告 |
| AI 代码"异味"占比 | 90%+ | Sonar 研究 |
核心结论:AI 让代码写得快,但审查、验证、修复的时间把省下的全吃回去了。效率的关键不在"生成速度",而在"质量防线"。
四个编程范式
| 范式 | 说明 | 开发者角色 |
|---|---|---|
| 传统编程 | 手写每行代码,完全的确定性和控制力 | 唯一作者 |
| AI 辅助编程 | 人类主导,AI 补全建议(Copilot/Cursor) | 编码者 + 审查者 |
| Vibe Coding | 纯自然语言描述,"忘记代码存在" | 高层协调者 |
| Agentic Coding | 自主 AI 代理处理多步骤(Claude Code/Devin) | 编排者 |
不同场景该用什么范式
| 场景 | 推荐方式 | 理由 |
|---|---|---|
| 快速原型 / MVP | Vibe Coding | 几天完成,快速验证 |
| 标准 CRUD 业务 | AI 辅助编程 | 效率 5-10 倍 |
| 样板代码 / 测试 / 文档 | Agentic Coding | 一致性好,速度快 |
| 大型生产级系统 | 传统 + AI 混合 | 需要全局架构设计 |
| 安全关键系统 | 传统编程为主 | 形式化验证、合规审计 |
| 遗留系统集成 | 传统编程 | AI 无法理解私有协议 |
二、AI 编程的 9 大常见问题及解决方案
根据 2025 年多项研究汇总,AI 编程的问题远不止"代码质量差":

问题 1:包幻觉与供应链攻击
AI 会幻觉出不存在的软件包名。研究显示约 20% 的 AI 推荐包实际上不存在,攻击者可预先注册这些虚构包名植入恶意代码(称为 Slopsquatting 攻击)。
解决:
-
每次构建生成加密签名的 SBOM(软件物料清单)
-
CI/CD 中集成 Safety CLI 检测已知漏洞
-
在 Docker 容器中沙盒执行 AI 生成的安装命令
-
降低 AI 温度参数以减少幻觉率
问题 2:安全漏洞 — AI 代码漏洞是人工的 10 倍
Apiiro 研究显示 AI 用户产出的安全问题数量是纯人工的 10 倍。CodeRabbit 数据表明 AI 生成的 PR 安全漏洞是人工的 2.74 倍。最常见漏洞:XSS、日志注入、硬编码凭证。
解决:
-
用最强大的模型作为 Reviewer(而非 Writer)进行独立安全审查
-
SAST/DAST 安全扫描集成到 CI/CD(Semgrep、Snyk)
-
AI 生成代码不得绕过人工审核直接进入生产
-
AI Agent 采用最小权限原则
问题 3:逻辑幻觉 — 代码能跑但结果错误
新版模型生成的代码表面能运行,但产生隐蔽错误:移除安全检查、编造看似合理的假数据、悄悄绕过缺失输入。具体表现包括矛盾条件、不可达代码路径、无效测试(mock 测 mock)。
解决:
-
始终独立验证 AI 输出,不信任 AI 的自我声明
-
关键任务使用稳定版本模型(GPT-4、Claude 3)
-
引入属性测试(Property-based Testing)和变异测试
-
要求 AI 对模糊需求主动提问澄清而非猜测
问题 4:上下文退化与"雪崩效应"
20 轮 AI 辅助修改后,原本 0 个编译错误的代码可能变成 23 个。根因:上下文污染、依赖搅动、边界逻辑被覆盖。
解决:
-
每次 AI 修改后立即 commit,一建议一提交
-
每次修改后自动运行单元测试
-
增量验证:每个小改动通过测试后再接受下一个
-
任务完成后果断开新会话
问题 5:代码不可维护
AI 生成 3000+ 行单一函数,所有逻辑高度耦合,命名风格不统一,后来者完全无法理解。
解决:
-
设定硬性规则:单函数 ≤ 50 行,类方法 ≤ 10 个
-
每个 AI 会话后进行架构审查
-
如果看不懂 AI 写的代码,立刻停下来
-
重构前先写全面测试
问题 6:指令漂移与过度设计
AI 逐渐偏离原始需求,擅自"优化"未要求的部分。搜索功能可能被设计成 Elasticsearch + Redis + MySQL 三层架构。
解决:
-
在提示前编写明确的验收标准
-
小颗粒度"外科手术式"任务定义
-
及时打断:"停,只关注 X"
-
提示中显式约束:"只实现核心逻辑,不要添加额外的错误处理"
问题 7:边界处理与异常场景缺失
AI 极度擅长 Happy Path,但系统性忽略空值处理、超时、并发竞争、除数为零等边缘情况。
解决:
-
在需求中显式列出边界场景
-
用属性测试让框架生成大量随机输入验证
-
AI Review 阶段专门检查异常场景覆盖
-
提交前自检:数据量 10 倍?多人并发?最坏情况?
问题 8:性能退化
AI 生成代码功能正确但性能显著低于人工。四大根因:低效函数调用、低效循环、低效算法选择、低效语言特性使用。
解决:
-
用真实数据规模对 AI 代码做性能分析
-
使用包含性能示例的 few-shot 提示
-
生成多个实现方案并基准测试对比
问题 9:调试开销 — 开发者反而更慢
开发者花 63% 更多时间调试 AI 生成的 Bug。METR 实验显示资深开发者使用 AI 后实际慢了 19%。
解决:
-
先写规格说明再提示(意图、预期行为、约束、涉及文件)
-
调试失败 3 次后立即切换为手动模式
-
跟踪 time-to-merge 和 post-merge defect rates,而非代码生成行数
三、AI 代码审查策略
AI 写的代码审查重点完全不同:
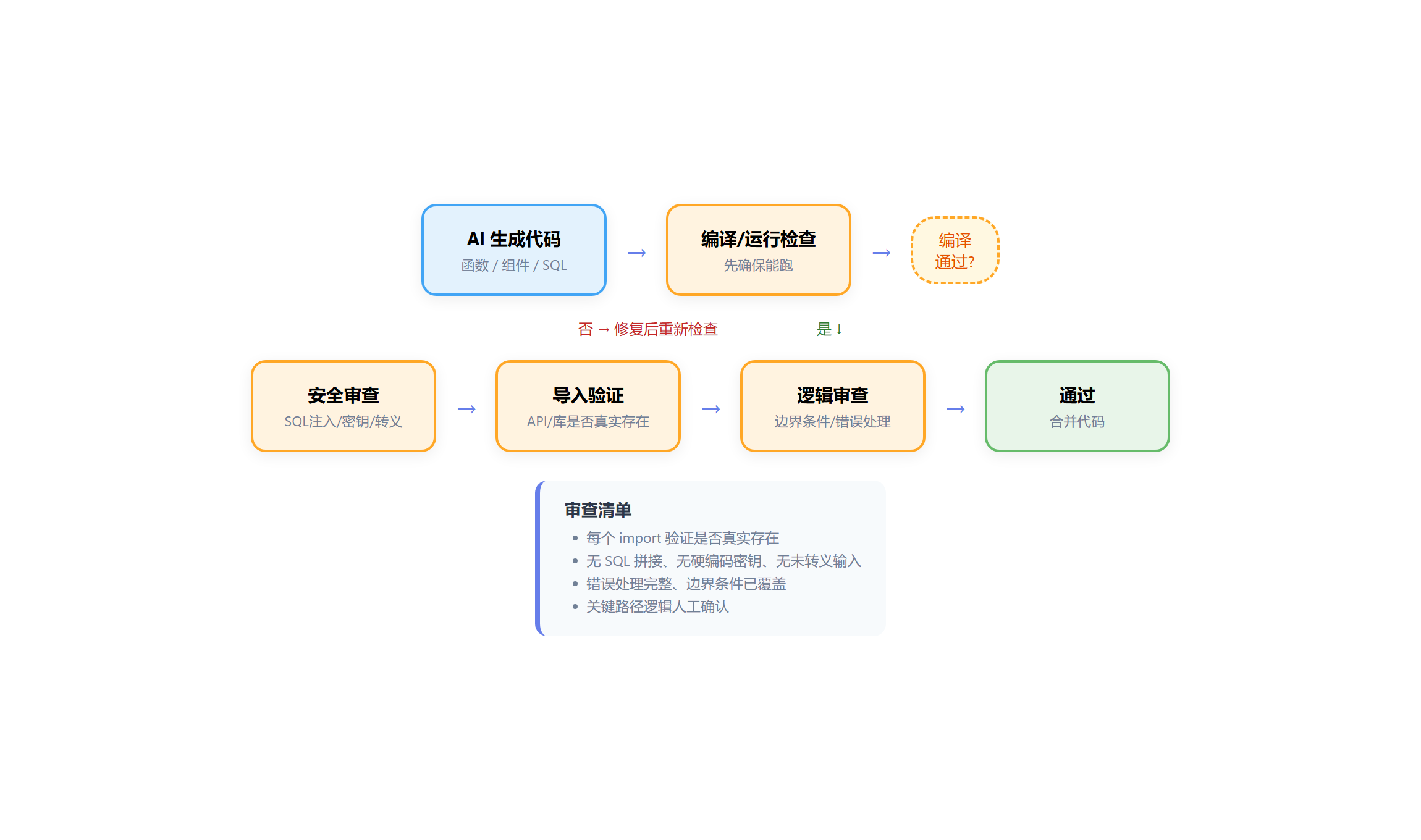
传统 Code Review vs AI Code Review
| 维度 | 传统 Review | AI 代码 Review |
|---|---|---|
| 关注点 | 逻辑正确性、代码风格 | 安全性、幻觉、边界 |
| 耗时 | 5-10 分钟/PR | 15-30 分钟/PR |
| 风险 | 边界条件遗漏 | 调用不存在的 API |
| 谁来审 | 同级开发者 | 建议 Senior 以上 |
AI 代码审查清单
- 编译/运行检查:不通过不提交
- 导入验证:每个 import 真实存在
- 安全检查:无 SQL 拼接、无硬编码密钥、无未转义输入
- 错误处理:try-catch 完整、边界已处理
- 性能检查:无 N+1 查询、循环中无 IO
- 测试质量:测试覆盖关键路径,非 mock 测 mock
高效审查技巧
-
AI 双审:生成的代码丢给另一个 AI 审查,两个 AI 之间容易互相发现幻觉
-
Diff 优先:只看增量变化,用
Explain this diff快速理解 -
关键路径手动写:涉及资金、权限、数据删除的核心逻辑自己把控
四、AI 编程项目管理

Delegate → Review → Own 模型(OpenAI 推荐)
| 阶段 | AI 做什么 | 人做什么 |
|---|---|---|
| Delegate | 第一轮审查:识别 Bug、执行风格检查、跨文件追踪 | — |
| Review | — | 验证 AI 发现、评估架构影响、检查业务正确性 |
| Own | — | 最终合并决策、处理模糊边界、战略权衡 |
三条管理铁律
-
人肉签名:AI 代码必须标记
@ai-generated: model, reviewed-by: name, date -
架构门禁:migration 文件、配置、核心业务入口 — AI 不得直接操作,变更需人工审批
-
代码考古:每两周团队 Review AI 代码 — 挑出最差 3 段分析原因,挑出最好 3 段提炼模板
五、五层质量防线
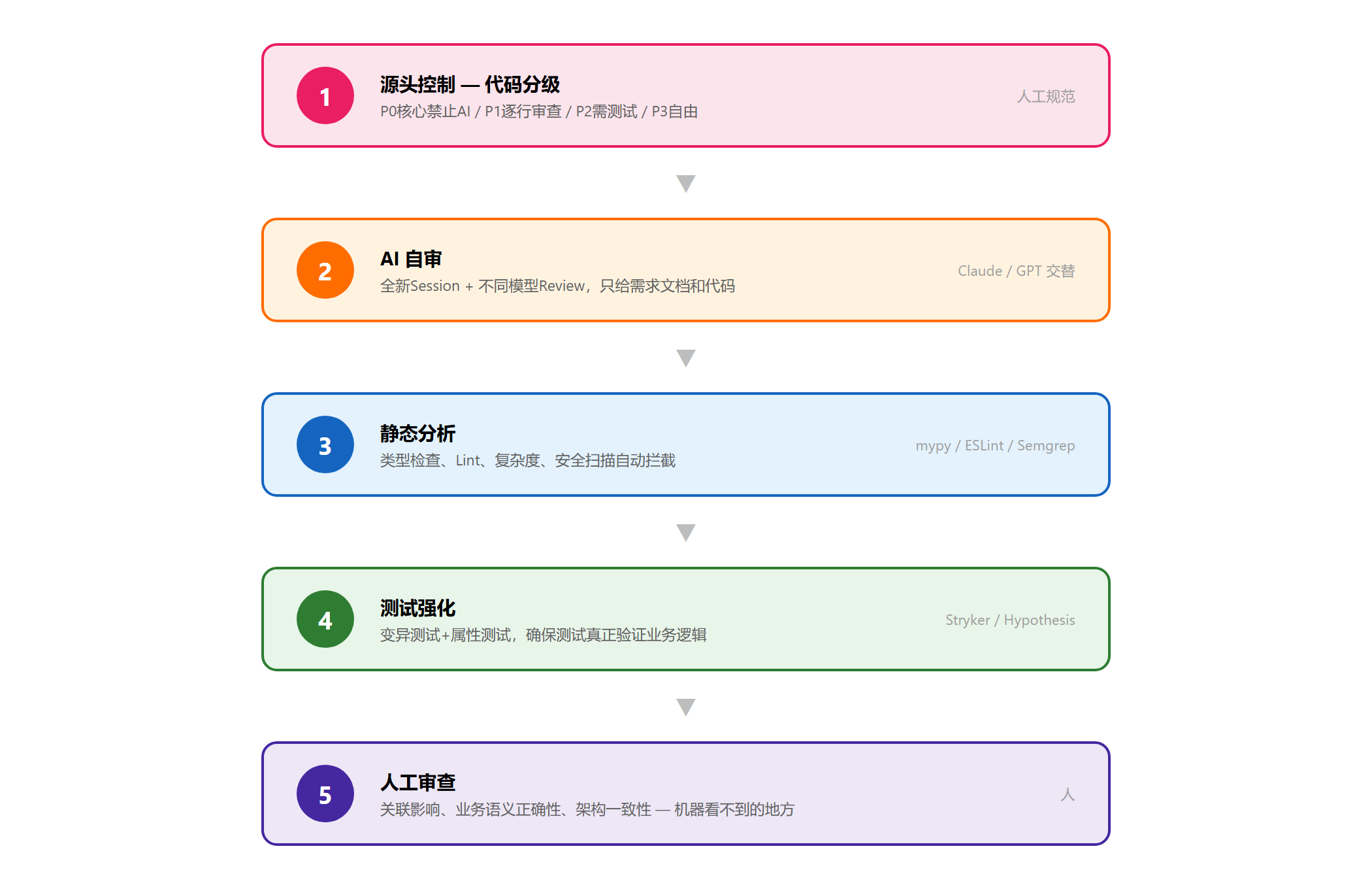
| 层级 | 措施 | 工具推荐 |
|---|---|---|
| 第一层:源头控制 | P0 核心禁止 AI / P1 逐行审查 / P2 需测试 / P3 自由 | 人工规范 |
| 第二层:AI 自审 | 全新 Session + 不同模型 Review,只给需求 + 代码 | Claude/GPT 交替 |
| 第三层:静态分析 | 类型检查、Lint、安全扫描、复杂度检查 | mypy/ESLint/Semgrep |
| 第四层:测试强化 | 变异测试 + 属性测试,确保测试真正验证业务逻辑 | Stryker/Hypothesis |
| 第五层:人工审查 | 聚焦关联影响、业务语义、架构一致性 | 人 |
核心原则:让自动化工具前置拦截低级错误,让测试真正验证业务逻辑,让人把稀缺注意力花在机器看不到的地方。
六、最佳实践清单
五项核心范式转变
| 范式 | 说明 |
|---|---|
| 先规划再执行 | 宁可回滚重来,不在错误方向上反复修补 |
| 上下文精简 | 不塞入所有文件,适时开新会话 |
| 用 Rules 固化规范 | .cursorrules / CLAUDE.md — 一次性配置替代重复对话 |
| 减少对话轮次 | 核心需求一次说清楚,避免"补丁式对话" |
| AI 是协作者 | 给具体指令、配置明确的"成功信号" |
工具配置建议
| 工具 | 配置文件 | 用途 |
|---|---|---|
| Cursor | .cursorrules |
技术栈、编码规范、禁止库 |
| Copilot | .github/copilot-instructions.md |
项目上下文、编码约定 |
| Claude Code | CLAUDE.md |
项目结构、技术栈、约束 |
关键衡量指标
| 指标 | 衡量什么 |
|---|---|
| PR 周期时间 | 从 open 到 merge 的耗时 |
| 缺陷逃逸率 | AI 审查 vs 纯人工的 Bug 上线率 |
| 返工时间 | 处理审查反馈的时间 |
| 审查覆盖率 | AI 在人工审查前发现问题的 PR 占比 |
七、总结
AI 编程不是银弹,七条核心结论:
-
效率幻觉:AI 让你以为自己快了 20%,实测算慢了 19%
-
安全代价:AI 代码漏洞是人工的 10 倍,安全审查不能省
-
质量防线:五层防线(源头→AI自审→静态分析→测试→人工)是底线
-
审查翻倍:PR 审查时间增加 91%,AI 写代码的速度超过了人审查的能力
-
信任但验证:100% 的开发者表示 AI 代码需要修改,75% 逐行审查
-
人管架构:关键路径自己把控,让 AI 做 CRUD、测试、文档
-
规范先行:没有
.cursorrules/CLAUDE.md,就别抱怨 AI 代码乱
AI 是副驾驶,不是代驾。代码可以 AI 写,但理解代码、承担责任、把控质量的必须是人。
数据来源:Stack Overflow 2025、METR 随机对照实验、Tilburg University、Apiiro、Sonar、Faros AI、OpenAI

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)