开源的流式文本转语音(TTS)模型(英法)速览:tts-1.6b-en_fr
Kyutai TTS模型介绍
一、模型概述
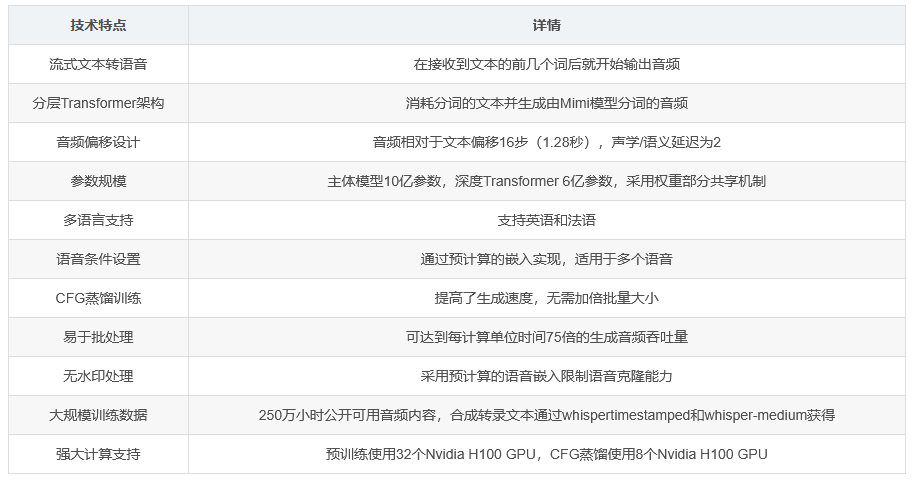
Kyutai TTS是一个用于流式文本转语音(TTS)的模型。与传统的离线文本转语音模型不同,该模型在接收到文本的前几个词后就能开始输出音频,而不是需要整个文本才能生成音频。这使得它在实时应用中具有显著的优势。
二、模型架构与细节
模型架构
Kyutai TTS的架构基于分层Transformer,它接收的是经过分词处理的文本,并生成由Mimi模型分词的音频。该模型的帧率是12.5Hz,每个音频帧由32个音频令牌表示,但在推理时可以使用更少的令牌以加快生成速度。模型的主体部分拥有10亿个参数,其深度Transformer部分有6亿个参数,并采用与Hibiki类似的权重部分共享机制。音频相对于文本的偏移量为16步(1.28秒),并且模型采用了声学/语义延迟为2的设计。
模型描述
Kyutai TTS是一个仅解码器的模型,用于流式语音转文本。它利用Moshi的多流架构来基于语音流建模文本流。文本流相对于音频流偏移,使模型能够根据输入的音频预测文本令牌。
开发者与许可
该模型由Kyutai团队开发,属于流式文本转语音模型,支持英语和法语。模型的权重在知识共享署名4.0(CC-BY 4.0)许可下发布。
三、应用场景
直接应用
Kyutai TTS能够进行流式文本转语音的生成,包括对话场景。该模型支持通过预计算的嵌入进行语音条件设置,这些嵌入在tts-voices仓库中为多个语音提供。尽管模型本身不直接支持Classifier Free Guidance(CFG),但它是通过CFG蒸馏训练的,从而提高了速度(无需加倍批量大小)。该模型易于批处理,可以达到每计算单位时间75倍的生成音频吞吐量。此外,该模型不进行水印处理,原因有两个:一是开源模型的水印容易被禁用;二是早期实验表明,通过Mimi对音频进行简单的编码和解码,就可以去除现有TTS所使用的水印系统。因此,该模型更倾向于限制语音克隆能力,仅使用预计算的语音嵌入。
四、如何开始使用该模型
可以通过GitHub仓库了解如何开始使用Kyutai TTS模型。
五、训练详情
训练步骤
该模型训练了75万步,采用的批量大小为64,每个片段的持续时间为120秒。然后,进行了24万次CFG蒸馏更新。
六、训练数据
预训练阶段使用了250万小时的公开可用音频内容。对于该数据集,通过运行带有whisper-medium的whispertimestamped获得合成的转录文本。
七、计算基础设施
预训练使用了32个Nvidia H100 GPU进行。而CFG蒸馏则在8个这样的GPU上完成。
八、核心技术汇总

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献114条内容
已为社区贡献114条内容

所有评论(0)