【三万字长文】从GPT到DeepSeek:大语言模型架构技术演进全解析!
简介
文章深度对比分析了多个主流大语言模型(LLM)的架构演进,包括DeepSeek、OLMo、Gemma、Mistral等系列。详细探讨了多头潜在注意力(MLA)、混合专家模型(MoE)、滑动窗口注意力(SWA)等关键技术创新,指出MoE已成为2025年大模型主流选择,各种注意力机制优化旨在提高计算效率和降低内存占用,揭示了LLM开发的技术走向和效率优化策略。

大语言模型架构深度对比
自 GPT 架构问世以来已历经七年。回顾 2019 年的 GPT-2 到 2024-2025 年的 DeepSeek V3 和 Llama 4,虽然基础结构依然相似,但细节演进显著:位置编码从绝对位置演变为旋转位置编码(RoPE),多头注意力机制(MHA)大多被分组查询注意力(GQA)取代,更高效的 SwiGLU 激活函数也替代了 GELU。
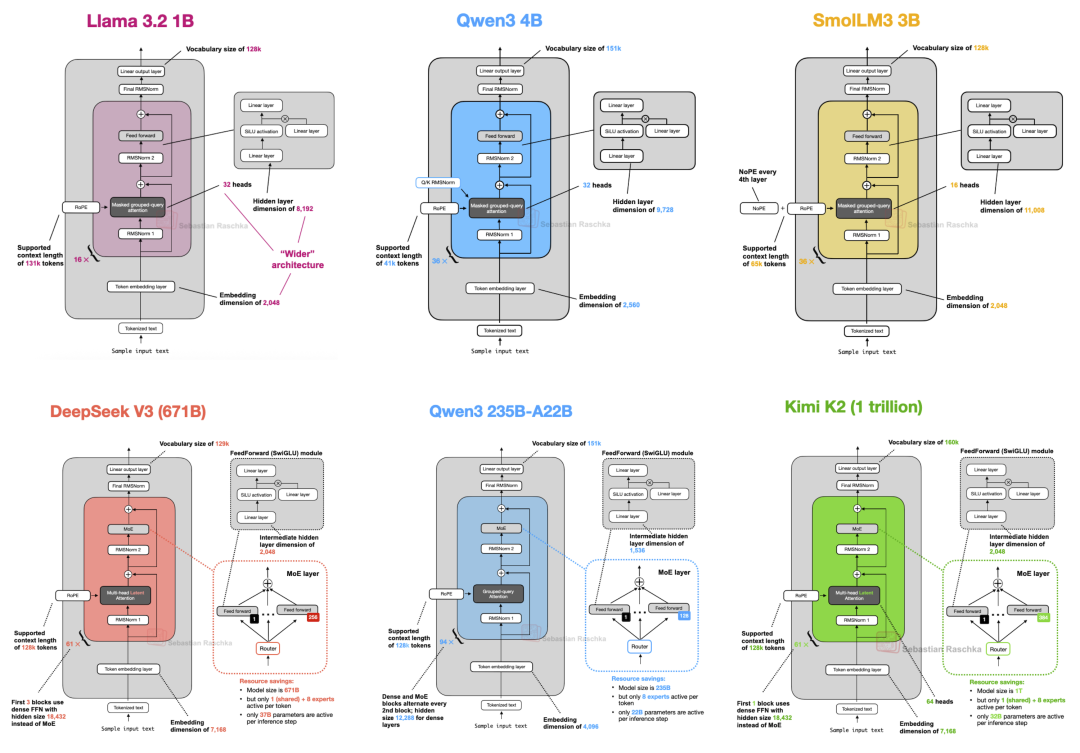
图 1:本文涵盖的部分模型架构。
本文将重点分析定义当今主流开源模型的架构演进,探讨 LLM 开发在 2025 年的技术走向。
- DeepSeek V3/R1
=================
DeepSeek R1[1] 是在 DeepSeek V3 架构[2]基础上构建的推理模型。DeepSeek V3 引入了两项关键架构技术,显著提升了计算效率,使其在众多大语言模型中脱颖而出:
- 多头潜在注意力机制 (Multi-Head Latent Attention, MLA)
- 混合专家模型 (Mixture-of-Experts, MoE)
1.1 多头潜在注意力机制 (MLA)
在讨论 MLA 之前,先看作为背景的组查询注意力 (Grouped-Query Attention, GQA)。GQA 近年已成为替代多头注意力 (Multi-Head Attention, MHA) 的主流方案,旨在提高计算和参数效率。
简而言之,MHA 为每个头分配独立的 Key (K) 和 Value (V);而 GQA 则通过让多个 Query (Q) 头共享同一组 K 和 V 投影来减少内存占用。
如下图 2 所示,如果设有 2 个 KV 组和 4 个注意力头,那么头 1 和 2 共享一组 K 和 V,头 3 和 4 共享另一组。这种方式减少了 K 和 V 的总计算量,从而降低显存占用并提升效率。消融实验证明,这种优化几乎不会影响模型性能。
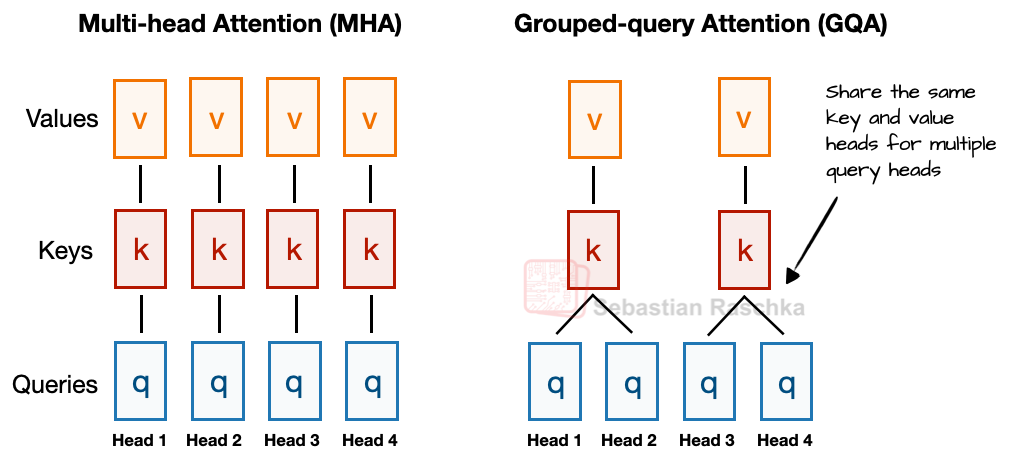
图 2:MHA 与 GQA 的对比。此处组大小为 2,即一对 KV 被两个 Query 共享。
GQA 的核心逻辑是通过减少 KV 头的数量来实现:(1) 降低模型参数量;(2) 推理时减少 KV Cache 的显存带宽占用,因为需要从缓存中读写的 KV 张量变小了。
虽然 GQA 本质上是针对 MHA 的一种计算优化技巧,但消融实验(如 GQA 原论文[3]和 Llama 2 论文[4])表明,其建模性能与标准 MHA 相当。
而 MLA 则采用了另一种内存节省策略,且与 KV Cache 的配合极其高效。MLA 并非像 GQA 那样共享 KV 头,而是在将 KV 张量存入 KV Cache 之前,先将其压缩到低维空间。
推理过程中,这些压缩后的张量在使用前会被投影回原始维度,如图 3 所示。虽然这增加了一次矩阵乘法开销,但大幅削减了显存占用。
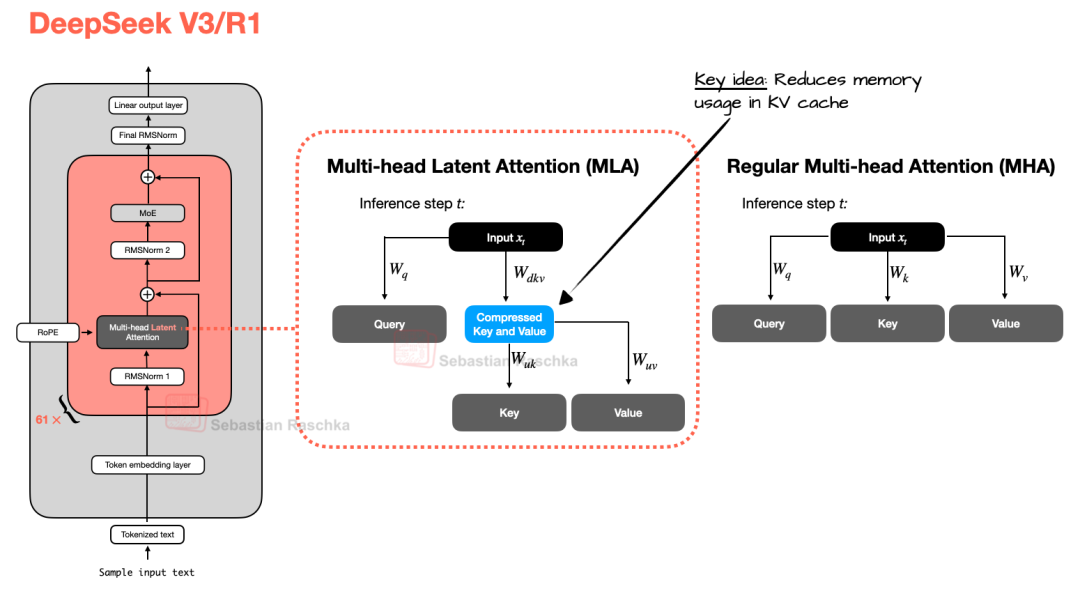
图 3:MLA(用于 DeepSeek V3 和 R1)与常规 MHA 的对比。
(注:Query 在训练阶段也会被压缩,但在推理阶段不会。)
MLA 并非 DeepSeek V3 首创,其前身 DeepSeek-V2[5] 就已引入该技术。V2 论文中的消融实验解释了开发团队选择 MLA 而非 GQA 的原因(见图 4)。
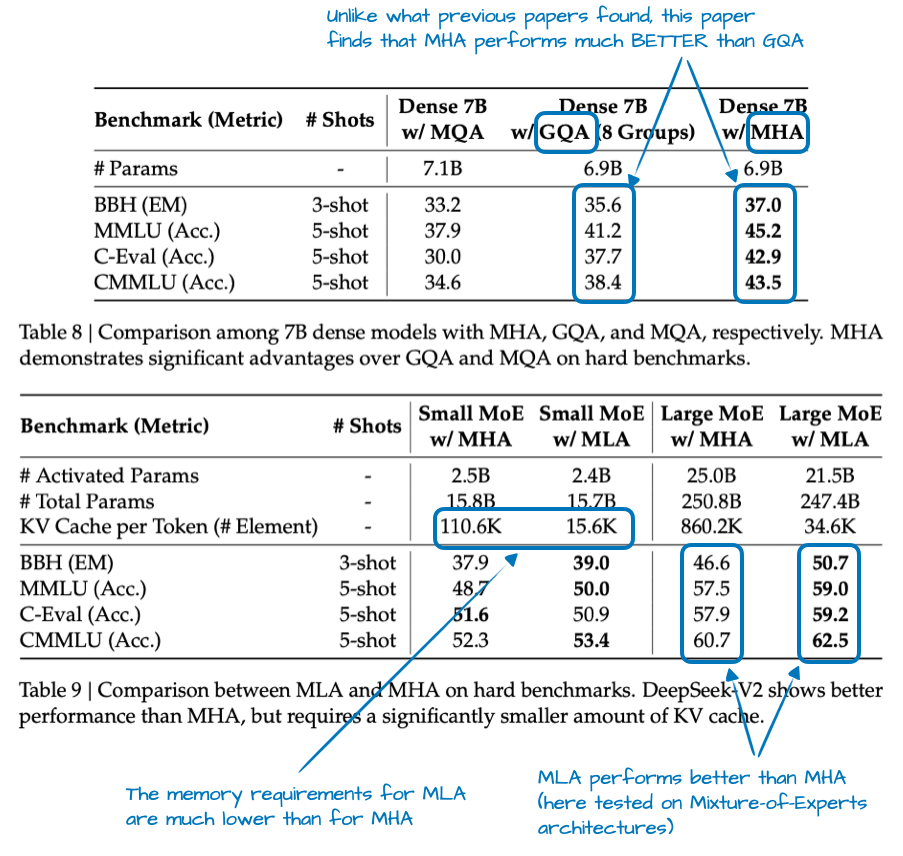
图 4:DeepSeek-V2 论文中的实验数据表,https://arxiv.org/abs/2405.04434
如图 4 所示,GQA 的表现似乎略逊于 MHA,而 MLA 的建模性能甚至优于 MHA。这很可能就是 DeepSeek 团队最终押注 MLA 的核心原因。
MLA 巧妙地降低了 KV Cache 的内存占用,且在建模性能上甚至略优于 MHA。
1.2 混合专家模型 (MoE)
DeepSeek 架构中另一个值得关注的核心组件是混合专家模型(Mixture-of-Experts,简称 MoE)层。虽然 MoE 并非 DeepSeek 首创,但该技术在今年再度翻红,后续我们要讨论的许多架构也都采用了这种设计。
MoE 的核心思想是将 Transformer 块中的每个前馈网络(FeedForward)模块替换为多个“专家”层,其中每个专家层本身也是一个前馈网络模块。也就是说,我们将单个前馈网络块替换成了多个并行的前馈网络块,如下图 5 所示。
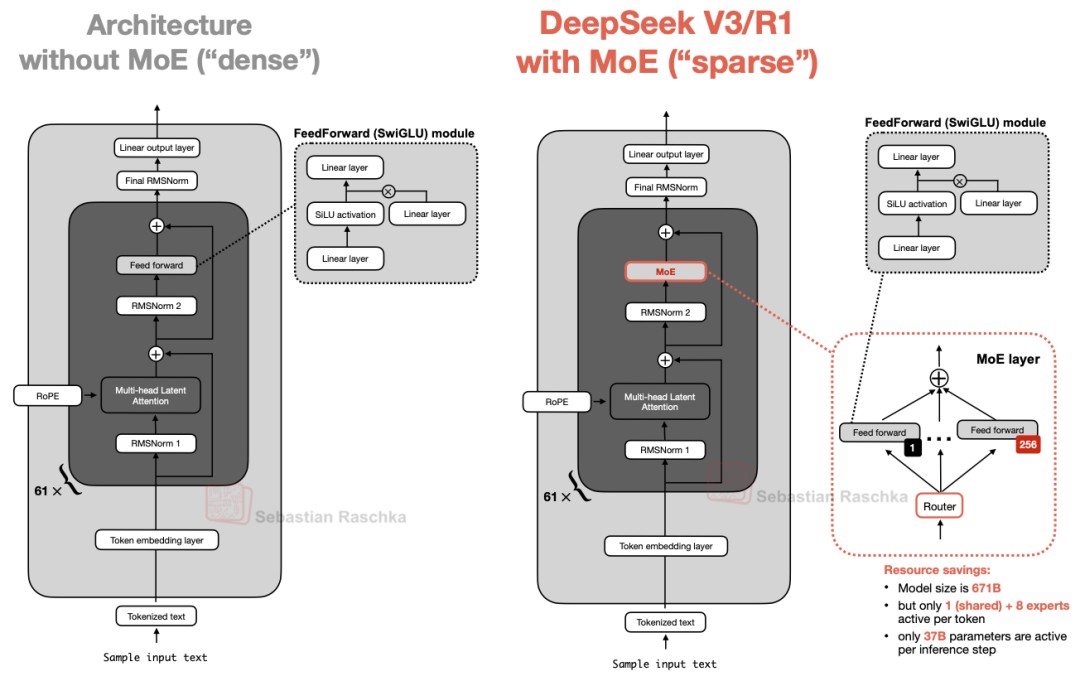
图 5:DeepSeek V3/R1 中的 MoE 模块(右)与标准前馈网络块(左)的对比。
Transformer 块中的前馈网络块(上图中的深灰色方块)通常占据了模型总参数量的很大一部分。(注意,Transformer 块及前馈网络块在 LLM 中会重复多次;以 DeepSeek V3 为例,共重复了 61 次。)
因此,将单个前馈网络块替换为多个块(即 MoE 配置)会显著增加模型的总参数量。但这里的关键技巧在于:我们并不会为每个 Token 激活所有的专家。相反,路由器(Router)会为每个 Token 仅选择一小部分专家进行计算。
由于每次只有少数专家处于激活状态,MoE 模块通常被称为“稀疏(Sparse)”模块,这与始终使用全部参数集的“稠密(Dense)”模块形成对比。MoE 带来的庞大总参数量提升了 LLM 的容量,使其在训练期间能吸收更多知识;而稀疏性则保证了推理效率,因为我们不需要同时运行所有参数。
例如,DeepSeek V3 的每个 MoE 模块拥有 256 个专家,总参数量达 6710 亿。但在推理时,每个 Token 仅激活 9 个专家(1 个共享专家加 8 个由路由器选出的专家)。这意味着每次推理步骤仅使用 370 亿参数,而非全部 6710 亿。
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

DeepSeek V3 MoE 设计的一个显著特点是引入了“共享专家(Shared Expert)”。这是一个对所有 Token 始终保持激活状态的专家。这一理念并非首次出现,在 DeepSeek 2024 MoE[6] 和 2022 DeepSpeedMoE[7] 的论文中已有提及。
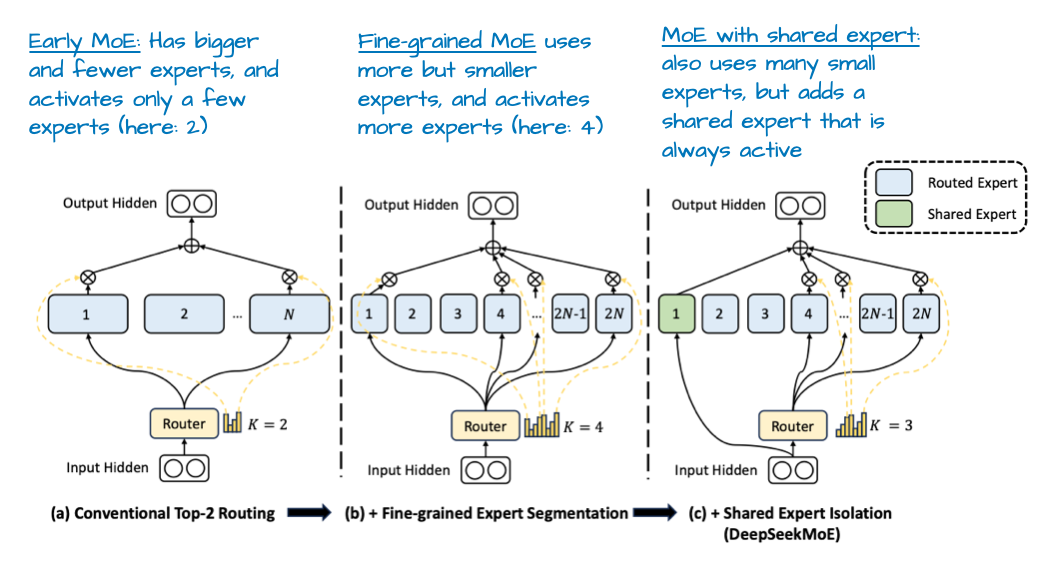
图 6:摘自论文《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》,https://arxiv.org/abs/2401.06066
DeepSpeedMoE 论文[7]最早指出了共享专家的优势:与不设共享专家的配置相比,它能提升整体建模性能。这可能是因为一些通用或重复的模式不需要由各个独立专家重复学习,从而让独立专家能腾出空间去学习更专业化的模式。
1.3 DeepSeek 总结
总而言之,DeepSeek V3 是一个拥有 6710 亿参数的巨量模型,其发布时的表现超越了包括 Llama 3 405B 在内的其他开源权重模型。尽管体量更大,但得益于 MoE 架构(每 Token 仅激活 370 亿参数),它在推理时表现得非常高效。
另一个关键特性是 DeepSeek V3 采用了多头潜在注意力(MLA)而非分组查询注意力(GQA)。MLA 和 GQA 都是针对 KV Cache 优化的推理高效型方案,旨在替代标准的多头注意力(MHA)。虽然 MLA 的实现更为复杂,但 DeepSeek-V2 的论文研究表明,其建模性能优于 GQA。
- OLMo 2
=========
Allen AI 研究所(Ai2)推出的 OLMo 系列模型在训练数据、代码透明度以及技术报告的详尽程度方面表现突出。
虽然 OLMo 模型在各基准测试或排行榜上未必位居榜首,但其极高的透明度为大语言模型(LLM)的开发提供了一份优秀的蓝图。
OLMo 2[8] 模型的表现并不逊色。在今年 1 月发布时(早于 Llama 4、Gemma 3 和 Qwen 3),其算力与性能的帕累托前沿分布如下图 7 所示。
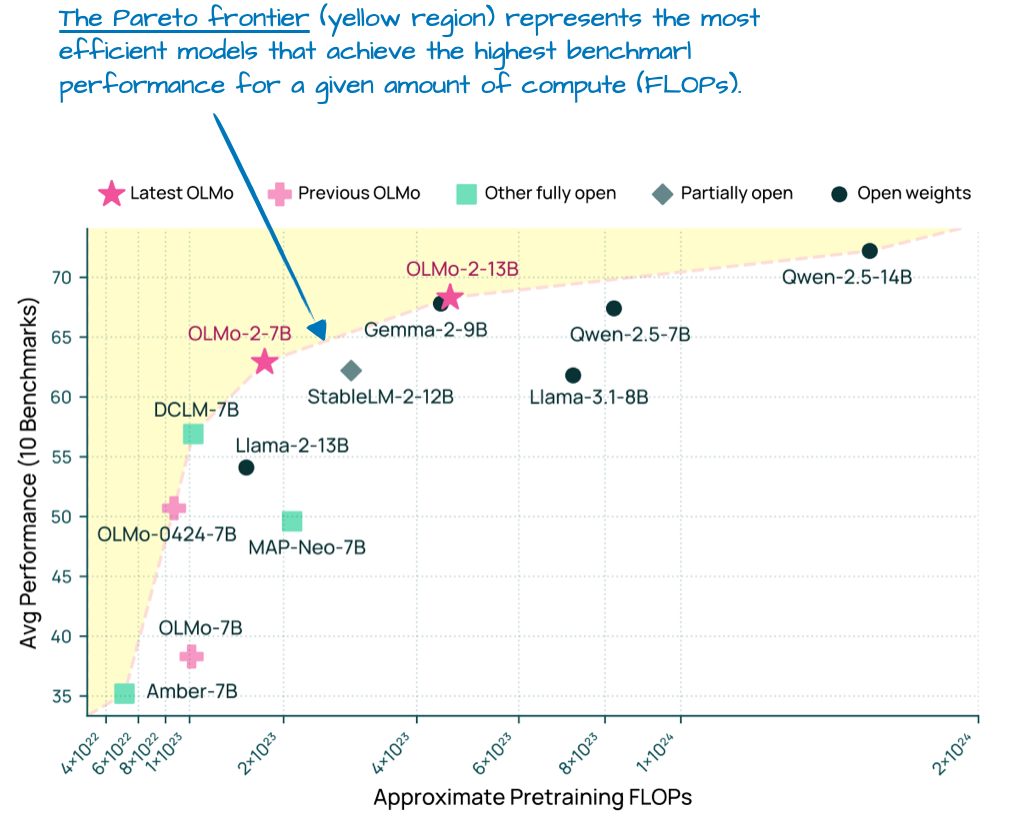
图 7:不同 LLM 的模型基准测试性能(越高越好)与预训练成本(FLOPs;越低越好)对比。来源:OLMo 2 论文,https://arxiv.org/abs/2501.00656
在架构设计方面,OLMo 2 的核心亮点在于归一化(Normalization)的处理:包括 RMSNorm 层的层级位置调整以及引入了 QK-norm。
此外,OLMo 2 依然沿用了传统的全量多头注意力机制(MHA),而非 MLA 或 GQA。
2.1 归一化层的位置
总体而言,OLMo 2 基本遵循了原始 GPT 的架构,但在归一化层上做了显著调整。
与 Llama、Gemma 等主流模型一致,OLMo 2 将 LayerNorm 替换为 RMSNorm。相比 LayerNorm,RMSNorm 是一种简化版本,具有更少的训练参数。
更值得关注的是归一化层的位置。原始 Transformer(来自论文《Attention is all you need[9]》)将两个归一化层分别放置在注意力模块和前馈网络(FFN)模块之后。
这种结构被称为 Post-LN 或 Post-Norm。
而 GPT 及后续的大多数模型则将归一化层放置在注意力模块和前馈网络模块之前,即 Pre-LN 或 Pre-Norm。下表对比了 Post-Norm 与 Pre-Norm。
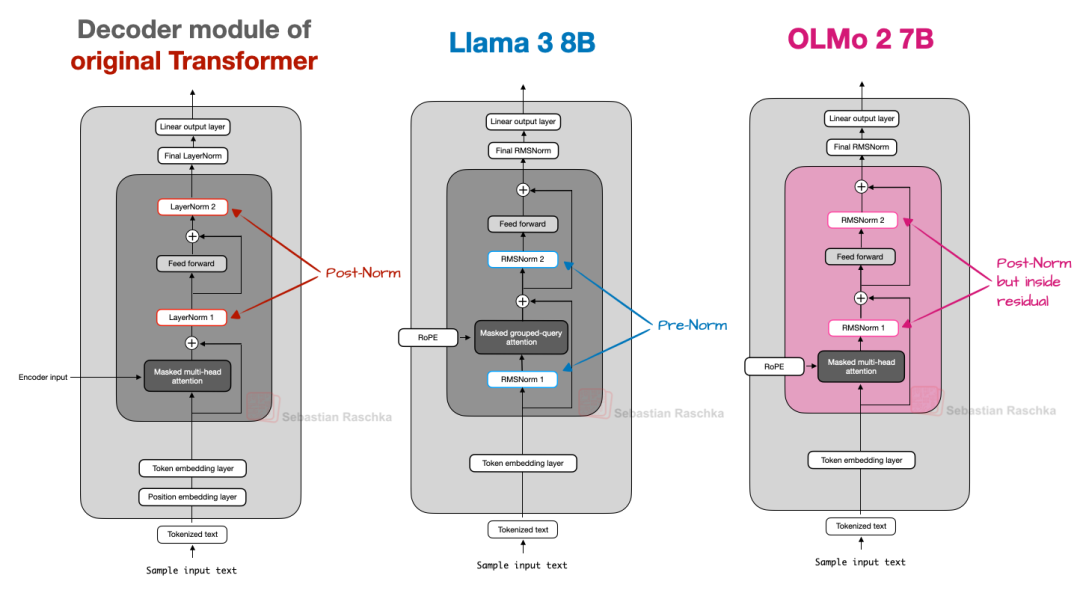
图 8:Post-Norm、Pre-Norm 与 OLMo 2 变体 Post-Norm 的对比。
Xiong 等人在 2020 年[10]的研究表明,Pre-LN 在初始化时能产生更稳定的梯度。此外,Pre-LN 在没有精细调整学习率预热(warm-up)的情况下也能表现良好,而这对于 Post-LN 则是必不可少的。
OLMo 2 采用了一种 Post-Norm 形式(即使用 RMSNorm 的 Post-LN)。
如图 8 所示,OLMo 2 将归一化层放置在层之后,但与原始 Transformer 不同的是,这些归一化层依然位于残差连接(Skip Connections)之内。
这种调整的主要目的是为了提升训练稳定性,结果见下图 9。
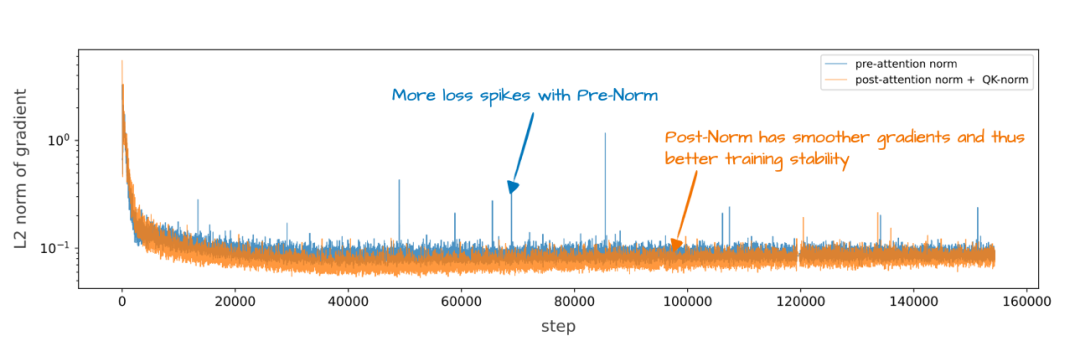
图 9:Pre-Norm(如 GPT-2、Llama 3)与 OLMo 2 版 Post-Norm 的训练稳定性对比。来源:OLMo 2 论文,https://arxiv.org/abs/2501.00656
需要注意的是,该实验结果是层顺序调整与 QK-Norm 共同作用的结果,因此很难单独拆解出层顺序调整的具体贡献。
2.2 QK-Norm
由于 OLMo 2 以及后续要讨论的 Gemma 2 和 Gemma 3 都采用了 QK-norm,这里简要解释其概念。
QK-Norm 本质上是另一种 RMSNorm 层。它被放置在多头注意力(MHA)模块内部,在应用 RoPE 之前作用于查询(q)和键(k)。为了直观展示这一点,下面是我为 Qwen3 从零实现项目[11] 编写的分组查询注意力(GQA)层代码片段(GQA 中的 QK-Norm 应用方式与 OLMo 的 MHA 类似):
class
GroupedQueryAttention
(
nn.Module
):
def
__init__
(
self
,
d_in
,
num_heads
,
num_kv_groups
,
head_dim
=
None
,
qk_norm
=
False
,
dtype
=
None
):
# ...
if
qk_norm:
self
.q_norm =
RMSNorm
(head_dim,
eps
=
1e-6
)
self
.k_norm =
RMSNorm
(head_dim,
eps
=
1e-6
)
else
:
self
.q_norm =
self
.k_norm =
None
def
forward
(
self
,
x
,
mask
,
cos
,
sin
):
b, num_tokens,
_
= x.shape
# Apply projections
queries =
self
.
W_query
(x)
keys =
self
.
W_key
(x)
values =
self
.
W_value
(x)
# ...
# Optional normalization
if
self
.q_norm:
queries =
self
.
q_norm
(queries)
if
self
.k_norm:
keys =
self
.
k_norm
(keys)
# Apply RoPE
queries =
apply_rope
(queries, cos, sin)
keys =
apply_rope
(keys, cos, sin)
# Expand K and V to match number of heads
keys = keys.
repeat_interleave
(
self
.group_size,
dim
=
1
)
values = values.
repeat_interleave
(
self
.group_size,
dim
=
1
)
# Attention
attn_scores = queries @ keys.
transpose
(
2
,
3
)
# ...
如前所述,QK-Norm 与 Post-Norm 配合使用可以稳定训练过程。值得注意的是,QK-Norm 并非 OLMo 2 首创,其来源可以追溯到 2023 年的 Scaling Vision Transformers 论文[12]。
2.3 OLMo 2 架构总结
简而言之,OLMo 2 在架构设计上的显著特点主要是 RMSNorm 的位置布局:它将 RMSNorm 置于注意力模块和前馈网络模块之后(Post-Norm 的变体),而非之前;同时在注意力机制内部为查询和键引入了 RMSNorm(QK-Norm)。这两者共同作用,有助于稳定训练损失。
下图对比了 OLMo 2 与 Llama 3 的架构。可以看出,除了 OLMo 2 仍采用传统的 MHA 而非 GQA 之外,两者的架构非常相似。(不过,OLMo 2 团队在三个月后发布的 32B 版本[13] 已经开始使用 GQA 了。)
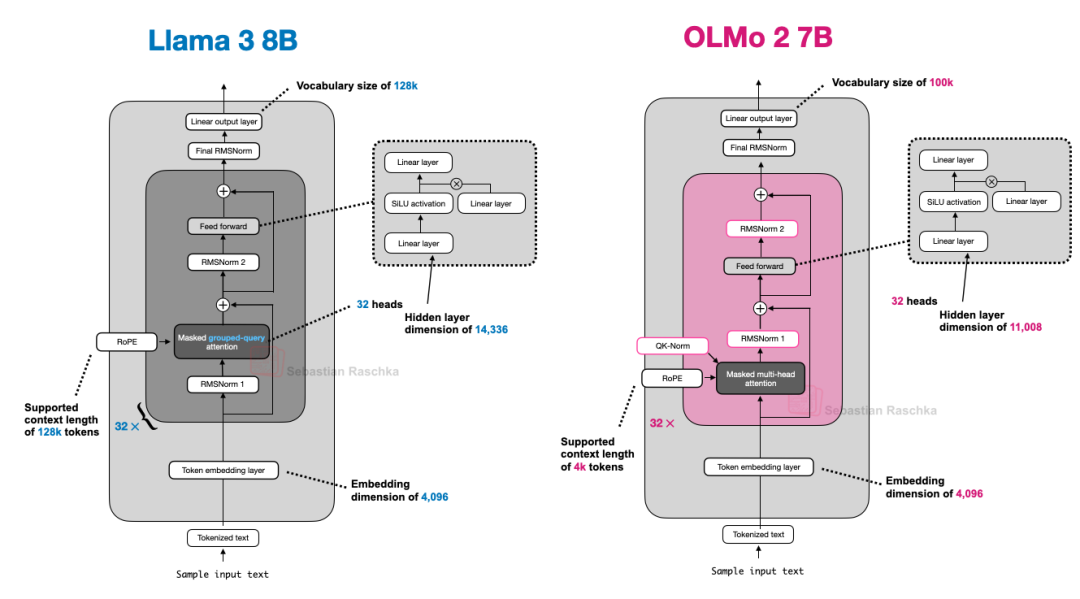
图 10:Llama 3 与 OLMo 2 的架构对比。
- Gemma 3
==========
Gemma 系列模型的一大特色是拥有庞大的词表(以更好地支持多语言),并重点发力 27B 这一尺寸(而非传统的 8B 或 70B)。此外,Gemma 2 还提供了 1B、4B 和 12B 等规格。
27B 版本找到了一个极佳的平衡点:它的能力远超 8B 模型,而资源消耗又不像 70B 那样夸张,在 Mac Mini 上即可流畅运行。
那么 Gemma 3[14] 还有哪些亮点?Deepseek V3/R1 等模型采用混合专家模型(MoE)架构,在固定模型参数量的同时降低推理时的内存需求。
而 Gemma 3 则采用了另一种“技巧”来降低计算成本,即滑动窗口注意力机制(Sliding Window Attention)。
3.1 滑动窗口注意力
通过滑动窗口注意力(最初由 2020 年的 LongFormer 论文[15] 提出,并已在 Gemma 2[16] 中应用),Gemma 3 团队大幅降低了 KV 缓存(KV Cache)的内存占用,如下图所示。
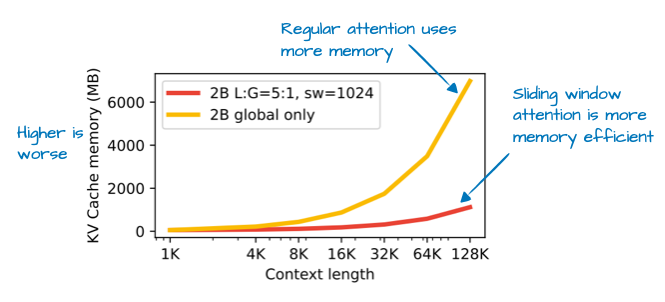
图 11:来自 Gemma 3 论文的插图,展示了通过滑动窗口注意力节省的 KV 缓存内存。
什么是滑动窗口注意力?如果将普通的自注意力视为“全局”注意力机制(每个序列元素都能访问其他所有元素),那么滑动窗口注意力就可以看作是“局部”注意力,因为它限制了当前查询(Query)位置周围的上下文范围。下图展示了这一原理。
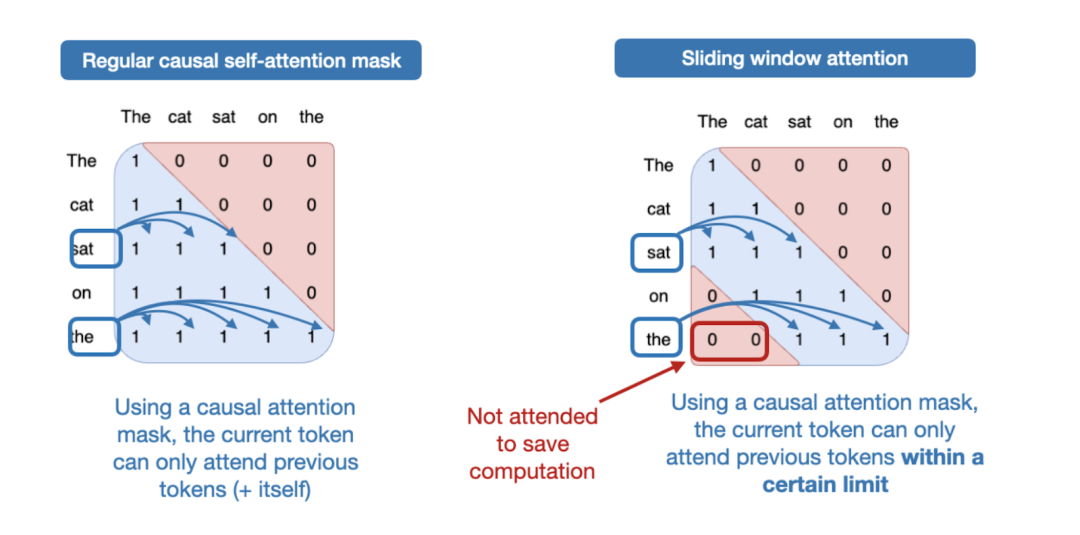
图 12:普通注意力(左)与滑动窗口注意力(右)的对比。
需要注意的是,滑动窗口注意力既可以配合多头注意力(MHA)使用,也可以配合分组查询注意力(GQA)使用;Gemma 3 采用的是后者。
滑动窗口注意力之所以被称为“局部”注意力,是因为局部窗口会随着当前查询位置同步移动。与之相对,普通注意力由于每个 Token 都能访问所有其他 Token,因此是“全局”的。
虽然 Gemma 2 已经使用了该技术,但 Gemma 3 调整了全局(普通)注意力与局部(滑动窗口)注意力的比例。
例如,Gemma 2 采用混合注意力机制,局部与全局的比例为 1:1,每个 Token 可以关注 4k 长度的邻近上下文。
在 Gemma 2 中,滑动窗口注意力是每隔一层交替使用的。而 Gemma 3 将比例调整为 5:1,即每 5 层局部注意力层才配有 1 层全量注意力层;此外,滑动窗口的大小从 Gemma 2 的 4096 缩减到了 Gemma 3 的 1024。这一改动使模型更加侧重于高效的局部计算。
根据消融实验,使用滑动窗口注意力对模型性能的影响微乎其微,如下图所示。
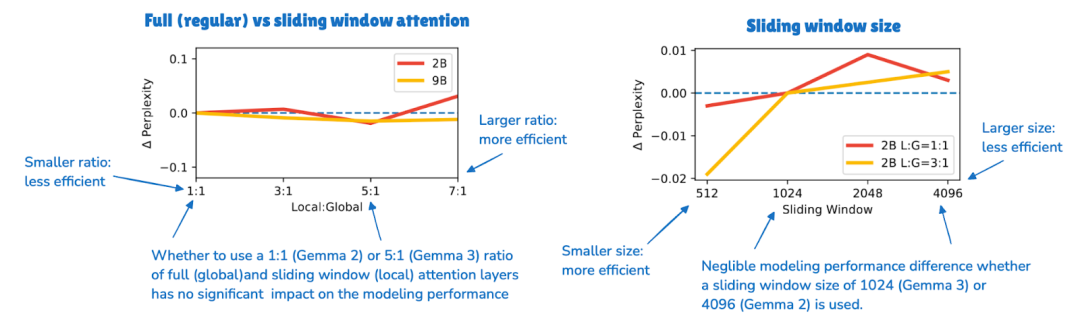
图 13:Gemma 3 论文插图显示,滑动窗口注意力对 LLM 生成输出的困惑度(Perplexity)几乎没有影响。
除了滑动窗口注意力这一显著的架构特征,Gemma 3 在归一化层(Normalization Layer)的放置位置上也值得关注。
3.2 归一化层位置
Gemma 3 在其分组查询注意力模块周围同时使用了 Pre-Norm 和 Post-Norm 设置的 RMSNorm。
这种设计虽然延续自 Gemma 2,但依然值得留意,因为它区别于:(1) 原始 Transformer 论文中的 Post-Norm;(2) GPT-2 引入并被后续多种架构采用的 Pre-Norm;以及 (3) OLMo 2 所采用的 Post-Norm 变体。
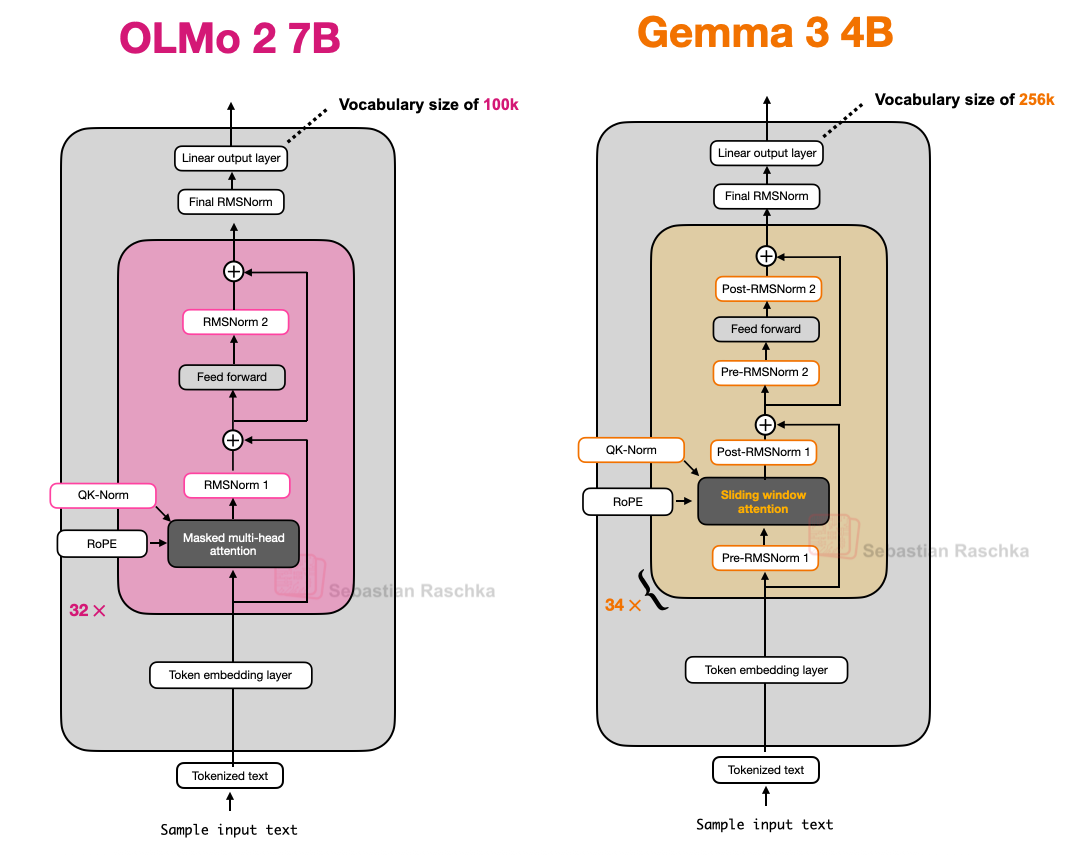
图 14:OLMo 2 与 Gemma 3 的架构对比;注意 Gemma 3 中额外的归一化层。
这种归一化层的布局方式非常直观,因为它兼顾了 Pre-Norm 和 Post-Norm 的优点。多加一层归一化并无大碍,最坏的情况也只是增加了一点冗余计算。考虑到 RMSNorm 的计算开销在整体模型中几乎可以忽略不计,这种冗余在实践中不会对性能产生明显影响。
3.3 Gemma 3 总结
Gemma 3 是一款性能出色的权重开放 LLM。其最值得关注的设计是引入了滑动窗口注意力机制(Sliding Window Attention)来提升效率。
此外,Gemma 3 采用了独特的归一化层布局,在注意力模块和前馈网络(FeedForward)的前后都放置了 RMSNorm 层。
3.4 进阶版:Gemma 3n
Google 推出了 Gemma 3n[17],这是针对移动端等小型设备效率优化的版本。
Gemma 3n 实现高效率的核心改进之一是采用了“逐层嵌入”(Per-Layer Embedding, PLE)参数层。其核心思路是仅在 GPU 显存中保留模型参数的一个子集,而针对特定模态(如文本、音频、视觉)的 token 层嵌入参数,则根据需求从 CPU 或 SSD 中实时流式读取。
下图展示了 PLE 带来的显存节省。图中列出的标准 Gemma 3 模型参数量为 54.4 亿,这很可能对应的是 Gemma 3 的 4B 版本。
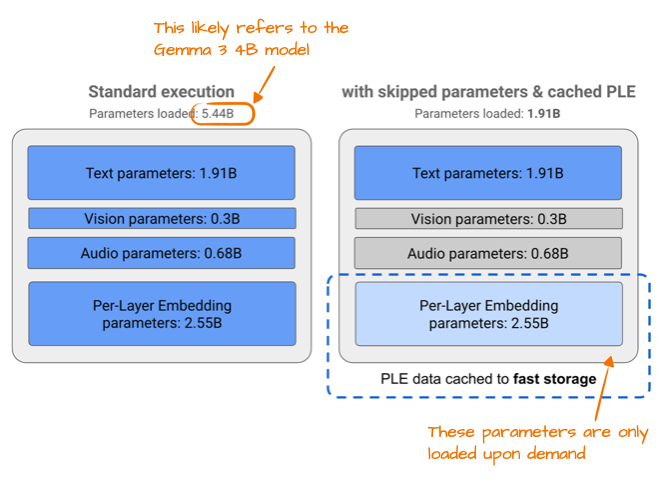
图 15:Google Gemma 3n 博客中的标注图,展示了 PLE 节省显存的效果。
关于 54.4 亿与 4 亿参数的差异,源于 Google 统计 LLM 参数的特殊习惯:为了让模型显得更轻量,他们通常会剔除嵌入层参数;但在需要展示模型规模优势时(如本例),又会将其计入。这种做法在目前的行业中已相当普遍。
另一个有趣的技巧是引入了 MatFormer[18](Matryoshka Transformer)概念。Gemma 3n 使用单一的共享 LLM 架构,但可以将其“切片”为多个独立使用的小模型。每个切片都经过专门训练,因此在推理时,可以根据需求仅运行模型的一部分,而无需加载整个大模型。
- Mistral Small 3.1
====================
Mistral Small 3.1 24B[19] 在多个基准测试(除数学外)中超越了 Gemma 3 27B,且推理速度更快。
Mistral Small 3.1 的推理延迟低于 Gemma 3,主要归功于其自定义的分词器(Tokenizer)、缩减的 KV 缓存以及更少的层数。除此之外,其架构遵循标准设计,如下图所示:
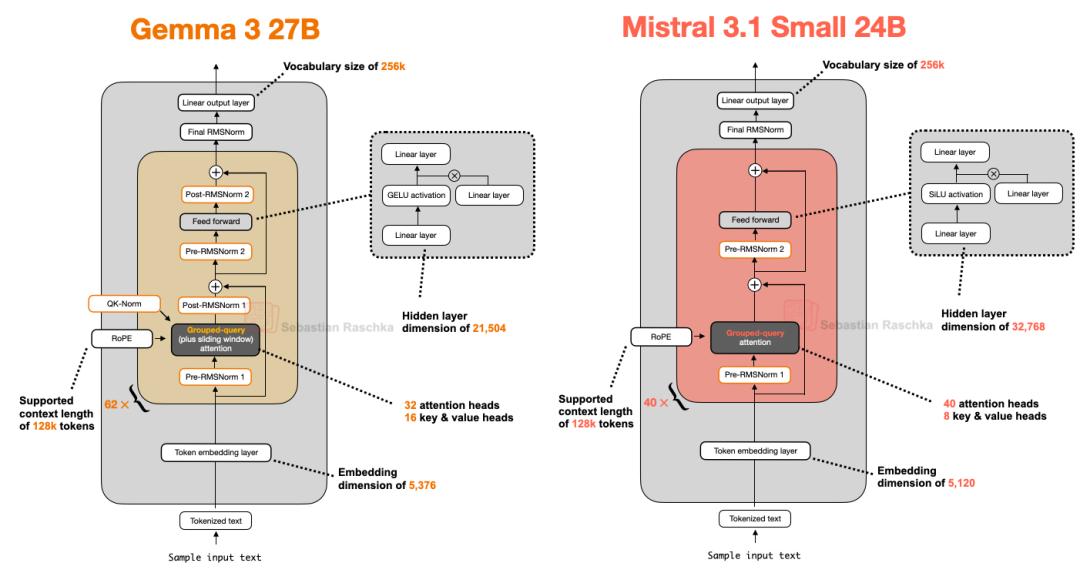
图 16:Gemma 3 27B 与 Mistral 3.1 Small 24B 的架构对比。
值得注意的是,早期 Mistral 模型曾使用滑动窗口注意力,但在 Mistral Small 3.1 中似乎已弃用。官方 Model Hub 配置文件[20] 中显示 “sliding_window”: null,且模型说明卡[21]中也未提及。
由于 Mistral 采用了常规的分组查询注意力(GQA),而非 Gemma 3 那种带滑动窗口的 GQA,这可能通过调用更成熟的优化算子(如 FlashAttention)来节省推理算力。推测认为,虽然滑动窗口注意力能减少显存占用,但并不一定能降低推理延迟,而后者正是 Mistral Small 3.1 的核心优化目标。
- Llama 4 架构解析
===============
Llama 4[22] 同样采用了混合专家模型(MoE)设计,其整体架构与 DeepSeek V3 非常相似(如下图所示)。尽管 Llama 4 原生支持多模态,但本文的核心在于语言建模,因此我们仅聚焦于其文本模型部分。
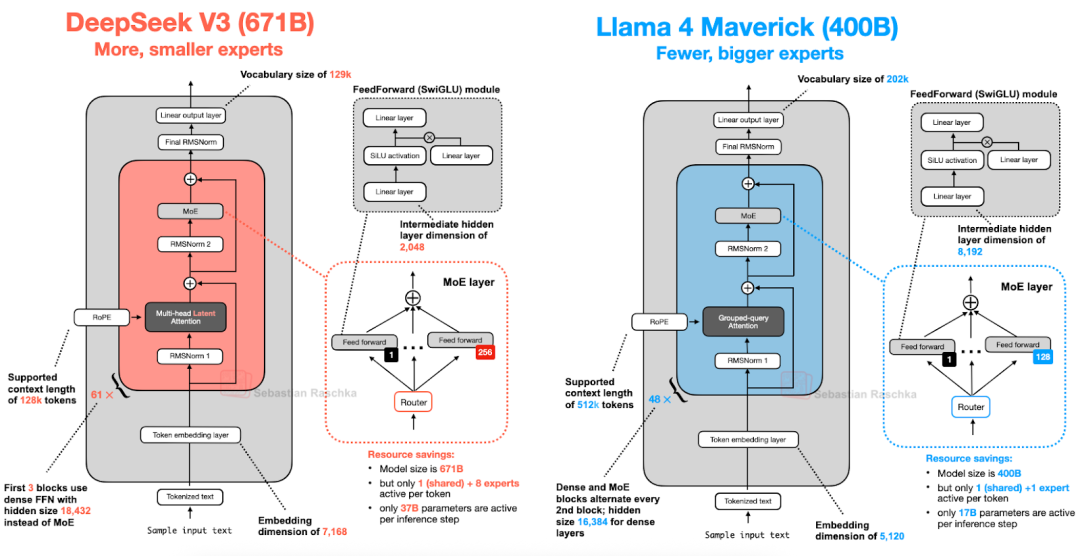
图 17:DeepSeek V3(671B 参数)与 Llama 4 Maverick(400B 参数)架构对比
虽然 Llama 4 Maverick 的架构在宏观上与 DeepSeek V3 趋同,但细节上仍有几处值得关注的差异。
首先,Llama 4 沿用了前代作品中的分组查询注意力(GQA),而 DeepSeek V3 则采用了多头潜在注意力(MLA)。在规模上,DeepSeek V3 的总参数量比 Llama 4 Maverick 大约多出 68%,且其激活参数量(37B)是 Llama 4 Maverick(17B)的两倍以上。
在 MoE 的具体实现上,Llama 4 Maverick 选择了更传统的配置:专家数量较少但单体规模较大(激活 2 个专家,隐藏层维度为 8,192);相比之下,DeepSeek V3 倾向于“细粒度”专家策略(激活 9 个专家,隐藏层维度为 2,048)。此外,DeepSeek V3 除前 3 层外在每个 Transformer 块中都使用了 MoE 层,而 Llama 4 则采取了 MoE 层与密集(Dense)层交替堆叠的方案。
虽然很难量化这些架构微调对最终性能的具体贡献,但可以确定的是,MoE 架构在 2025 年已成为大模型的主流选择。
- Qwen3
========
Qwen 团队始终致力于发布高质量的开源权重 LLM。在 NeurIPS 2023 的 LLM 效率挑战赛中,排名前列的解决方案均基于 Qwen2 构建。
目前,Qwen3 系列在各参数量级的排行榜上均表现出色。该系列包含 7 个稠密(Dense)模型:0.6B、1.7B、4B、8B、14B 和 32B;以及 2 个 MoE 模型:30B-A3B 和 235B-A22B。
6.1 Qwen3 (Dense)
首先讨论稠密模型架构。0.6B 版本可能是目前最小的当代开源权重模型。尽管体积小巧,但其性能表现优异,具备极高的 token/sec 吞吐量和极低的内存占用,非常适合本地运行。此外,得益于其参数量级,它也非常适合用于本地教学目的的训练。
在多数场景下,Qwen3 0.6B 已经可以替代 Llama 3 1B。下表展示了这两种架构的对比。
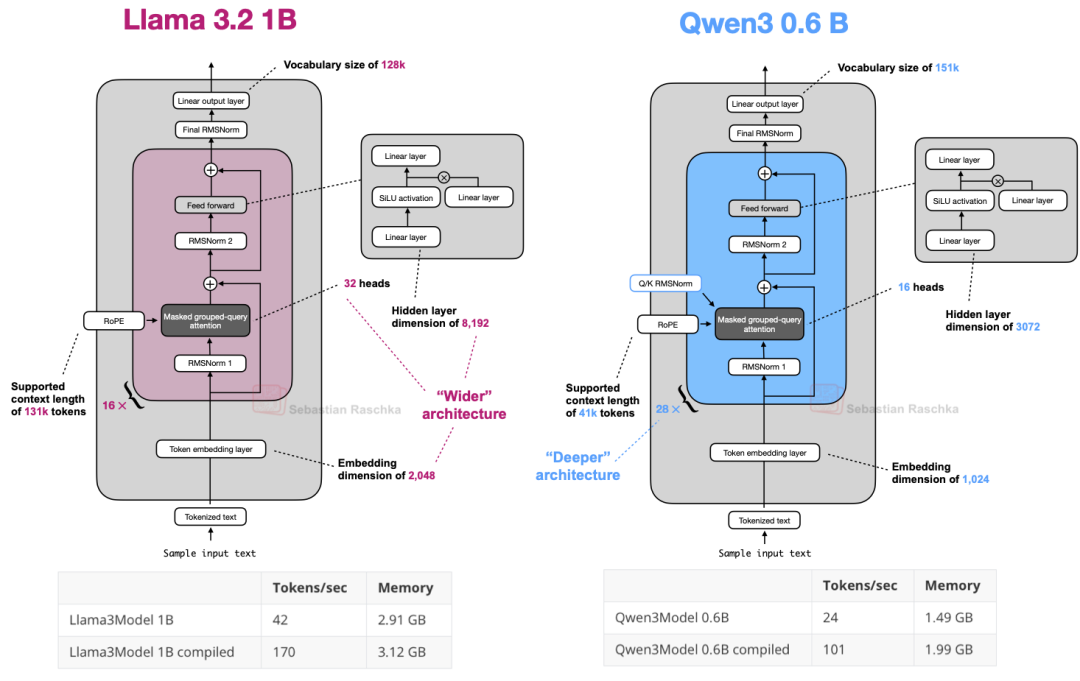
图 18:Qwen3 0.6B 与 Llama 3 1B 的架构对比;可见 Qwen3 架构更深(层数更多),而 Llama 3 架构更宽(注意力头数更多)。
上图中的计算性能数据基于 A100 GPU 上的纯 PyTorch 实现。可以看出,由于整体架构较小,且采用了更小的隐藏层和更少的注意力头,Qwen3 的内存占用更低。然而,由于其 Transformer 模块(层数)多于 Llama 3,导致推理速度(token/sec)相对较慢。
6.2 Qwen3 (MoE)
Qwen3 提供了两种 MoE 版本:30B-A3B 和 235B-A22B。
MoE 变体旨在降低大型基座模型的推理成本。同时提供稠密和 MoE 版本,可以根据不同的目标和硬件限制为用户提供灵活性。
稠密模型通常在各种硬件上的微调、部署和优化过程更加直接。而 MoE 模型则针对推理扩展进行了优化。在固定的推理预算下,MoE 模型可以实现更高的模型容量(即在训练中吸收更多知识),而不会按比例增加推理开销。
通过发布这两种类型,Qwen3 系列支持了更广泛的应用场景:稠密模型适用于稳定性、简洁性和微调需求;MoE 模型则适用于大规模的高效服务。
最后,我们将 Qwen3 235B-A22B(其中 A22B 代表 22B 激活参数)与 DeepSeek V3 进行对比,后者的激活参数量(37B)几乎是前者的两倍。
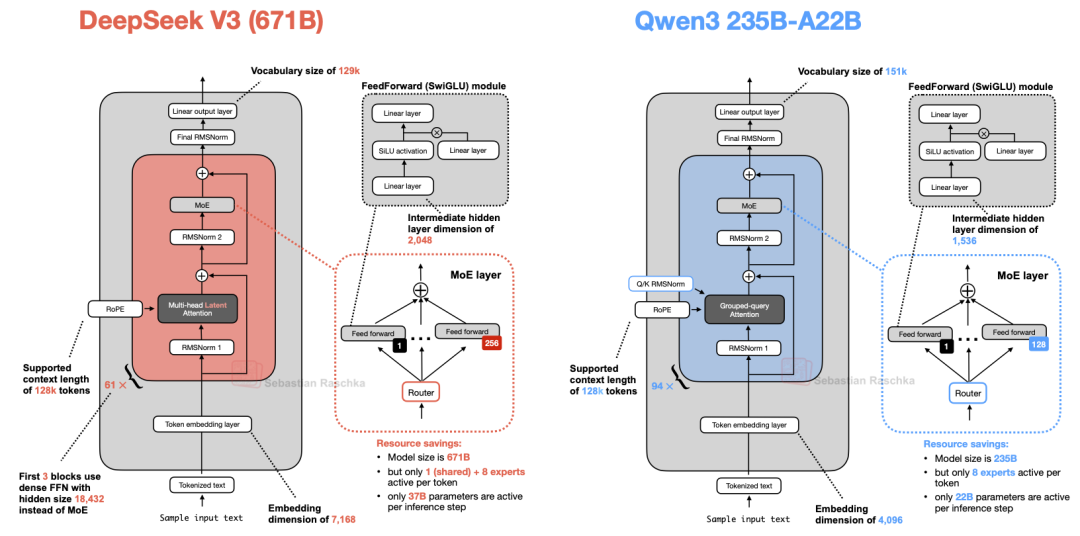
图 19:DeepSeek V3 与 Qwen3 235B-A22B 的架构对比。
如上图所示,DeepSeek V3 和 Qwen3 235B-A22B 的架构非常相似。值得注意的是,Qwen3 取消了共享专家(Shared Expert)设计,而早期的 Qwen 模型(如 Qwen2.5-MoE)曾使用过该设计。
Qwen3 团队并未公开弃用共享专家的具体原因。推测可能是当专家数量从 2 个(Qwen2.5-MoE)增加到 8 个(Qwen3)时,共享专家对训练稳定性的贡献已不再显著,因此通过移除共享专家来节省额外的计算和内存开销。
Qwen3 开发者之一 Junyang Lin 对此回应如下:
当时我们并未发现共享专家带来足够显著的提升,且担心共享专家会给推理优化带来麻烦。老实说,这个问题目前还没有一个定论。
- SmolLM3
==========
SmolLM3[23] 是一款性能出色的 3B 参数模型。虽然其知名度略逊于主流大模型,但在 1.7B 和 4B 的 Qwen3 模型之间,它提供了一个兼顾性能与尺寸的理想平衡点。
此外,SmolLM3 像 OLMo 一样公开了大量训练细节,这对技术社区极具参考价值。
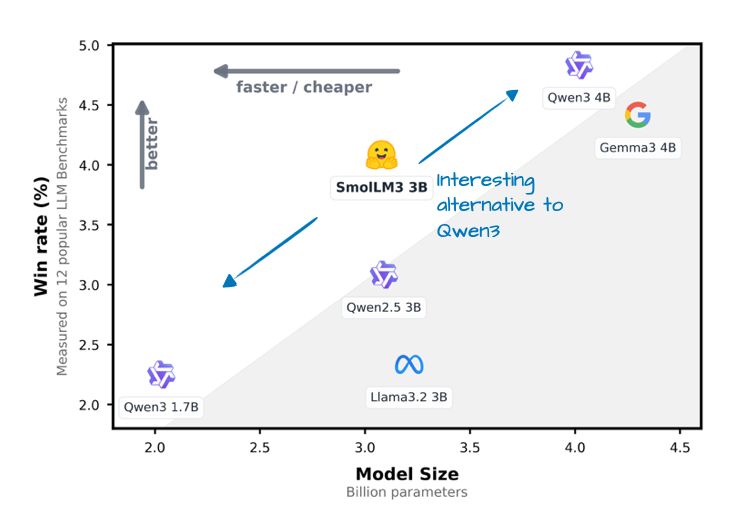
图 20:SmolLM3 发布公告中的对比图。展示了 SmolLM3 与 Qwen3 1.7B/4B、Llama 3 3B 以及 Gemma 3 4B 的胜率对比。
从下方的架构对比图来看,SmolLM3 的设计基本遵循标准范式,但其最值得关注的技术点在于使用了 NoPE(无位置嵌入)。
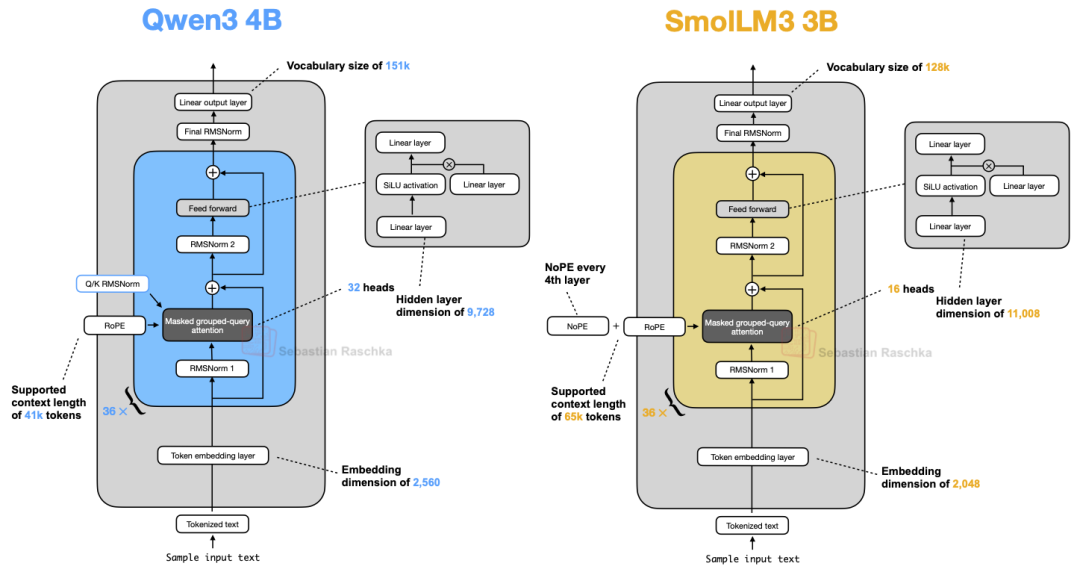
图 21:Qwen3 4B 与 SmolLM3 3B 的架构详细对比。
7.1 无位置嵌入 (NoPE)
NoPE 并非新技术,其核心思想源自 2023 年的一篇论文(The Impact of Positional Encoding on Length Generalization in Transformers[24])。该方法旨在取消显式的位置信息注入,无论是早期 GPT 架构中的绝对位置嵌入,还是目前主流的 RoPE。
在 Transformer 模型中,由于自注意力机制在处理 Token 时与顺序无关,通常需要位置编码。绝对位置嵌入通过增加一个额外的嵌入层,将位置信息叠加到 Token 嵌入中来解决这一问题。
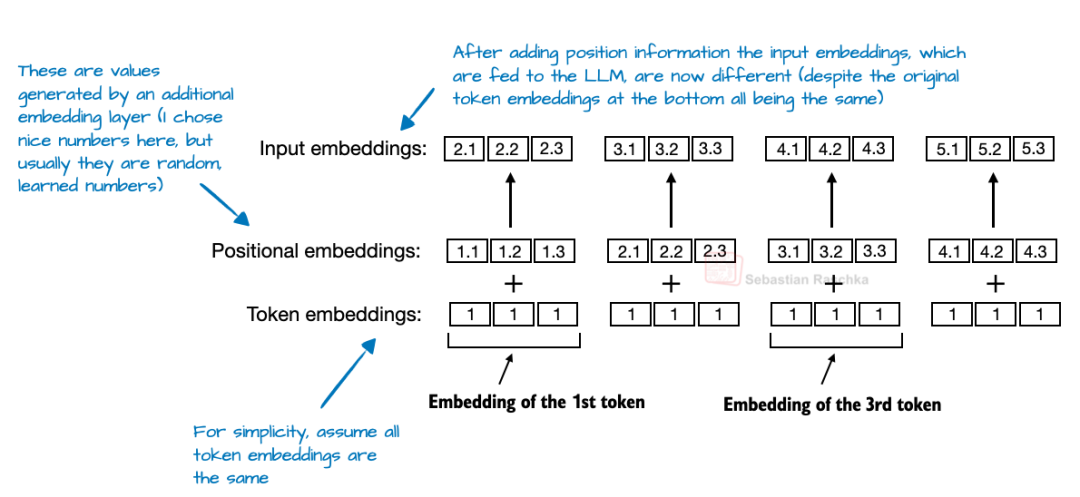
图 22:绝对位置嵌入示意图。
相比之下,RoPE 通过根据 Token 位置旋转查询(Query)和键(Key)向量来实现位置编码。
而在 NoPE 层中,完全不添加任何位置信号:既没有固定编码,也没有可学习编码或相对编码。
即便没有显式的位置嵌入,模型依然能感知 Token 的先后顺序,这归功于因果注意力掩码(Causal Attention Mask)。该掩码确保每个 Token 只能关注其之前的 Token。因此,位置 t 的 Token 只能看到位置 ≤ t 的信息,从而维持了自回归顺序。
虽然没有显式注入位置信息,但模型结构中依然隐含了方向性。在基于梯度下降的常规训练中,如果对优化目标有利,大模型能够学会利用这种隐含信息。
NoPE 论文[24]的研究表明,显式位置信息注入并非必不可少。更重要的是,NoPE 展现了更强的长度泛化能力,即随着序列长度的增加,模型的表现衰减更小。
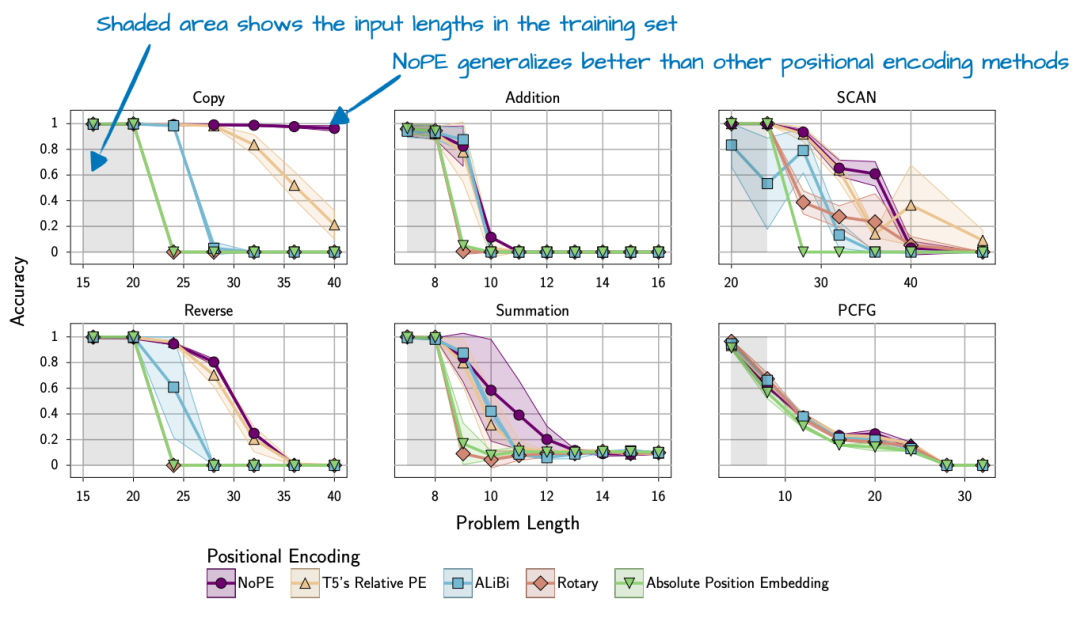
图 23:NoPE 论文中的实验数据,显示了其在长度泛化上的优势。
需要注意的是,上述实验是在约 100M 参数的 GPT 风格模型及较短上下文环境下完成的。这些结论在更大规模的现代 LLM 中是否依然成立尚存变数。
基于这种考量,SmolLM3 团队采取了折中方案:仅在每 4 层中应用一次 NoPE(或者说每 4 层省略一次 RoPE)。
- Kimi K2 与 Kimi K2 Thinking
=============================
Kimi K2[25] 最近在 AI 社区引起了巨大轰动,作为一款开源权重模型,其性能表现极其出色。根据各项基准测试,它已足以比肩 Google Gemini、Anthropic Claude 以及 OpenAI ChatGPT 等顶级闭源模型。
一个值得关注的技术细节是,Kimi K2 采用了相对较新的 Muon[26] 优化器的变体,而非传统的 AdamW。就目前所知,这是 Muon 首次被应用于如此大规模的生产级模型训练(此前[27]该优化器仅在 16B 规模下验证过可扩展性)。这带来了非常理想的训练损失曲线,可能正是助力该模型在基准测试中登顶的关键因素之一。
虽然有评论认为其 Loss 曲线因缺乏尖峰而显得格外平滑,但对比下图中的 OLMo 2 曲线可以发现,这种平滑程度并非孤例(实际上,梯度 L2 范数可能是衡量训练稳定性更佳的指标)。不过,其 Loss 曲线的下降效率确实非常惊人。
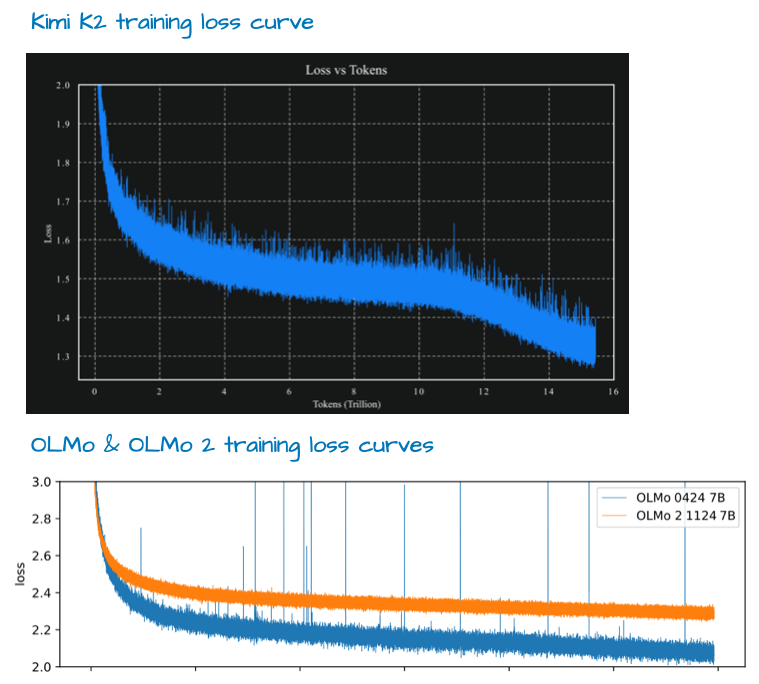
图 24:Kimi K2 公告博客 (https://moonshotai.github.io/Kimi-K2/) 与 OLMo 2 论文 (https://arxiv.org/abs/2305.19466) 的标注图。
该模型拥有 1 万亿参数量,规模十分宏大。
在 Llama 4 尚未发布、且排除闭源模型以及 Google 早期架构(如 1.6 万亿参数的 Switch Transformer[28])的前提下,这可能是目前参数量最大的通用 LLM。
在设计上,Kimi K2 沿用了 DeepSeek V3 的架构并进行了扩容,如下图所示。
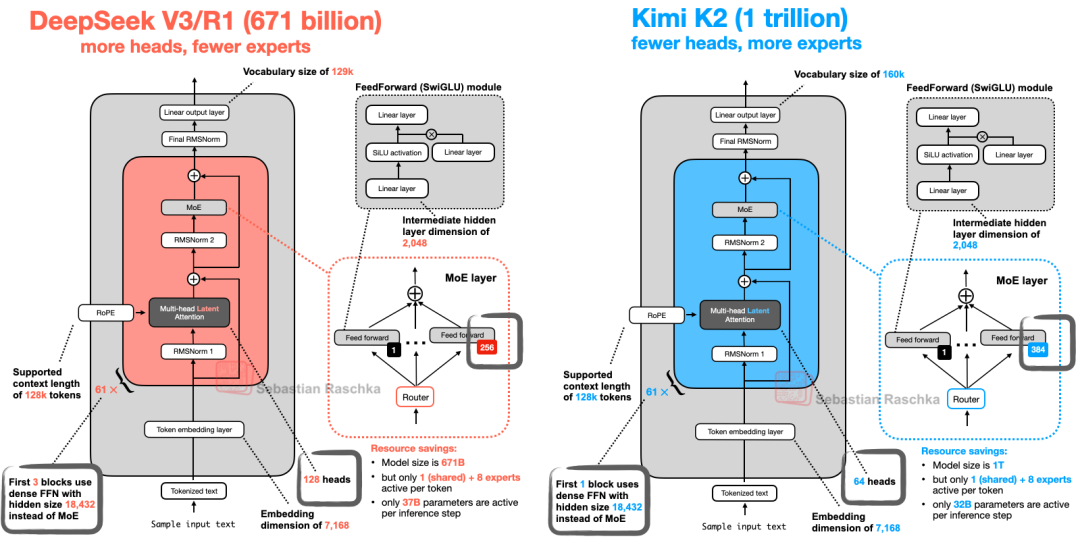
图 25.1:DeepSeek V3 与 Kimi K2 的架构对比。
如上图所示,Kimi K2 与 DeepSeek V3 的架构基本一致,主要的区别在于 MoE 模块使用了更多的专家,而多头潜变量注意力(MLA)模块则减少了 Head 数量。
Kimi K2 的爆发并非偶然。此前的 Kimi 1.5(详见 Kimi k1.5: Scaling Reinforcement Learning with LLMs[29])表现已颇为不俗。尽管 Kimi 1.5 在发布时正撞上 DeepSeek R1 的发布日,且并未开源模型权重,但 Kimi K2 团队显然吸取了经验,在 DeepSeek R2 发布前选择了开源权重。目前,Kimi K2 是性能最强悍的开源权重模型之一。
更新: Kimi K2 团队随后发布了全新的“Thinking”模型变体。该版本保持了 Kimi K2 的架构,但将上下文窗口从 128k 扩展到了 256k。
根据 Kimi 团队分享的基准测试数据[30],该模型的表现超越了主流的闭源 LLM(遗憾的是,目前尚无与 DeepSeek R1 的直接对比)。
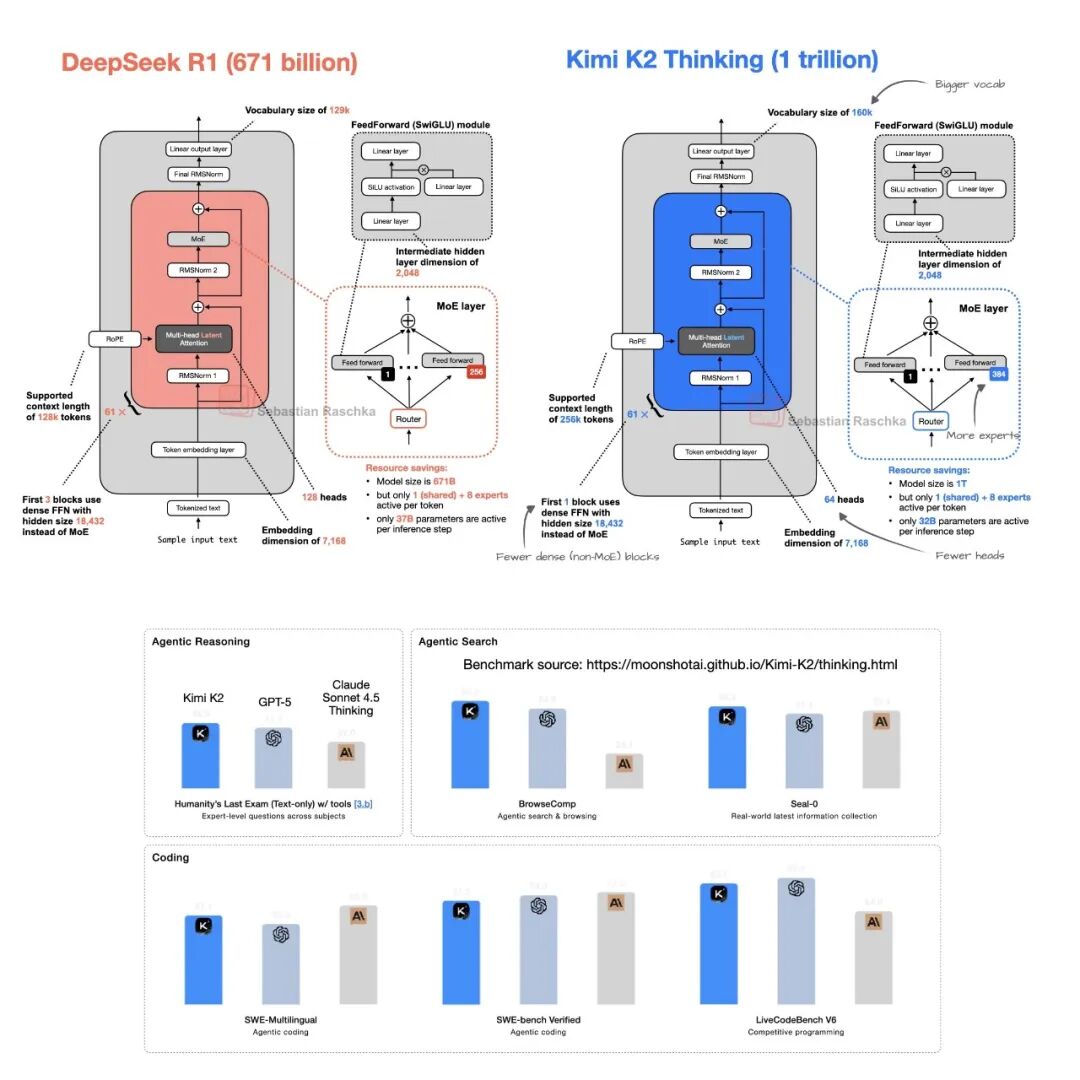
图 25.2:DeepSeek R1 与 Kimi K2 Thinking 架构对比(上)及 Kimi K2 Thinking 基准测试结果(下)。
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
- GPT-OSS
==========
OpenAI 发布了 gpt-oss-120b 和 gpt-oss-20b,这是自 2019 年 GPT-2 以来其首批开源权重的模型。
下方的图 26 展示了 gpt-oss-20b 和 gpt-oss-120b 这两款模型的架构概览。
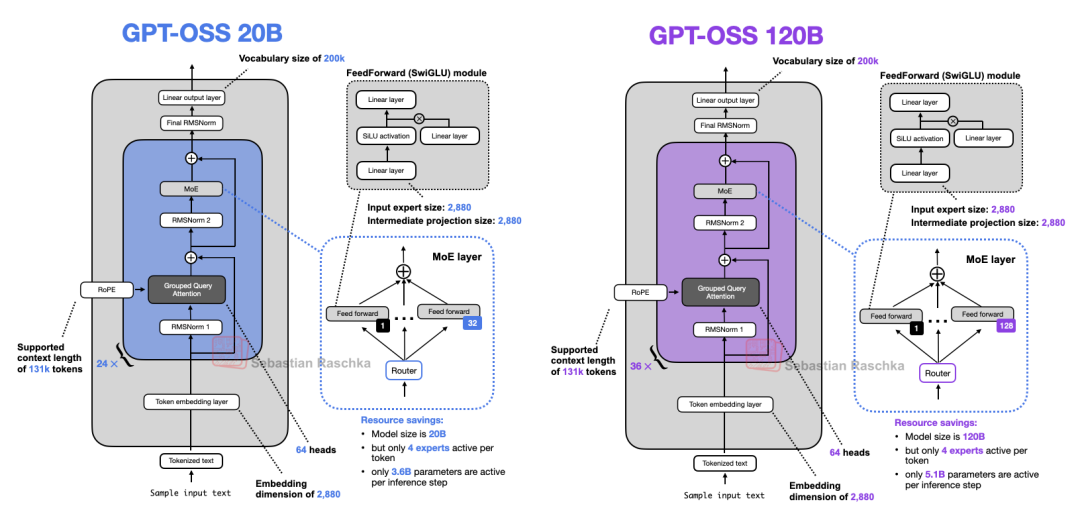
图 26:两款 gpt-oss 模型的架构概览
从图 26 可以看出,该架构包含了我们之前讨论过的其他架构中所有熟悉的组件。例如,图 27 将较小的 gpt-oss 架构与 Qwen3 30B-A3B 进行了对比,后者也是一个 MoE 模型,且拥有相近的激活参数量(gpt-oss 的激活参数为 3.6B,Qwen3 30B-A3B 为 3.3B)。
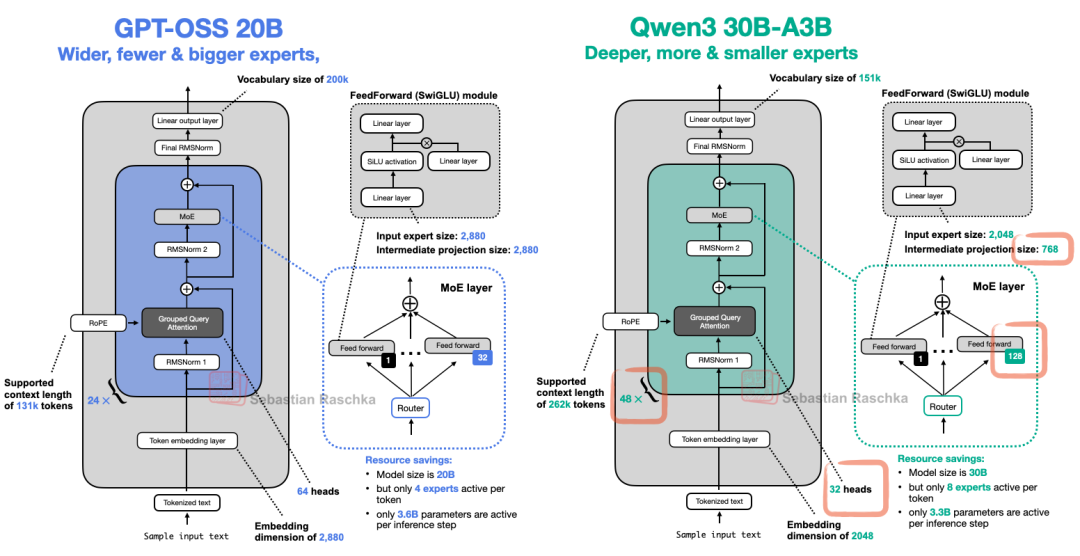
图 27:gpt-oss 与 Qwen3 的架构对比
图 27 中未显示的一个细节是,gpt-oss 采用了滑动窗口注意力(Sliding Window Attention),类似于 Gemma 3,但它是在每隔一层中使用,而非采用 5:1 的比例。
9.1 宽度与深度
图 27 显示 gpt-oss 和 Qwen3 使用了相似的组件。但如果仔细观察,我们会发现 Qwen3 的架构要深得多,拥有 48 个 Transformer 块,而 gpt-oss 只有 24 个。
另一方面,gpt-oss 的架构更宽:
- 嵌入维度(Embedding Dimension)为 2880,而非 2048
- 中间专家层(前馈网络)的投影维度同样为 2880,而非 768
值得注意的是,gpt-oss 使用了两倍数量的注意力头,但这并不会直接增加模型的宽度,宽度主要由嵌入维度决定。
在参数量固定的情况下,哪种方法更有优势?经验法则表明,更深的模型具有更好的灵活性,但由于梯度爆炸和梯度消失问题(尽管 RMSNorm 和捷径连接旨在缓解这些问题),训练难度可能更大。
更宽的架构优势在于推理速度更快(吞吐量更高,即每秒生成的 Token 数更多),因为它具有更好的并行化能力,但内存成本也更高。
在模型性能方面,目前尚无完美的对等比较(即保持参数量和数据集完全一致)。不过,Gemma 2 论文(表 9)[31]中的消融实验发现,对于 9B 参数的架构,较宽的设置略优于较深的设置。在 4 项基准测试中,较宽的模型平均得分为 52.0,而较深的模型为 50.8。
9.2 少数大专家 vs. 多数小专家
如上图 27 所示,gpt-oss 的专家数量少得惊人(32 个,而非 128 个),且每个 Token 仅使用 4 个激活专家(而非 8 个)。然而,其单个专家的规模远大于 Qwen3 中的专家。
这一点非常有趣,因为近期的趋势和研究普遍认为“更多、更小的专家”更有利。在总参数量恒定的情况下,这种演变在下方 DeepSeekMoE 论文的图 28 中得到了很好的展示。
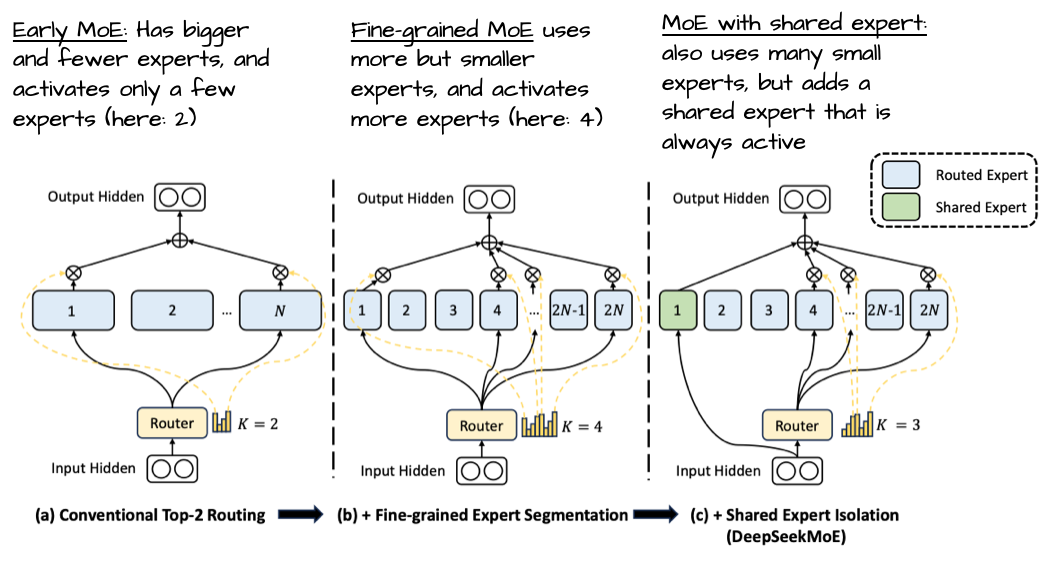
图 28:选自 “DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models” 的注释图,https://arxiv.org/abs/2401.06066
值得注意的是,gpt-oss 和 Qwen3 都没有像 DeepSeek 模型那样使用共享专家(Shared Experts)。
9.3 注意力偏置与注意力汇聚
gpt-oss 和 Qwen3 都使用了分组查询注意力(Grouped Query Attention)。主要的区别在于,gpt-oss 如前所述,通过在每隔一层使用滑动窗口注意力来限制上下文窗口。
此外,一个值得关注的细节是:gpt-oss 似乎在注意力权重中使用了偏置单元(Bias Units),如图 29 所示。
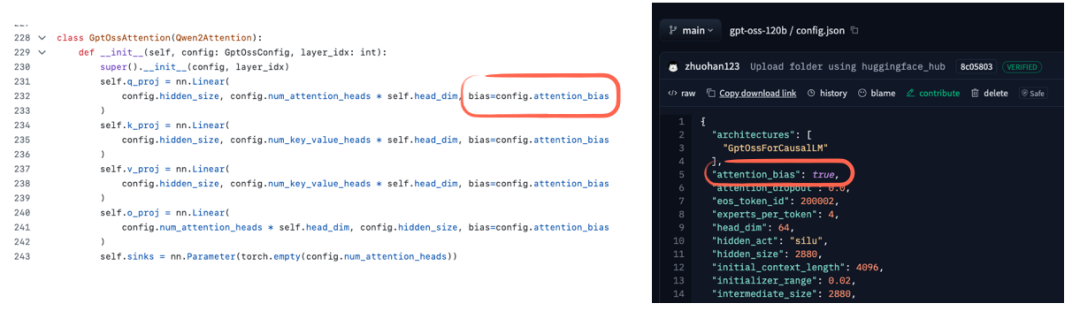
图 29:gpt-oss 模型在注意力层中使用了偏置单元。
偏置单元(bias units)自 GPT-2 时代以后就鲜有露面,目前普遍被视为冗余设计。最近有论文从数学层面证明,这种冗余性在键变换(k_proj)中尤为明显。此外,实证结果也表明,是否使用偏置单元对模型表现几乎没有影响(见下图 30)。
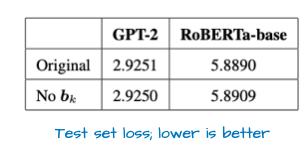
图 30:来自 https://arxiv.org/pdf/2302.08626 的表格,展示了模型在从头训练时,使用与不使用偏置单元的平均测试损失对比。
另一个值得关注的细节是图 30 代码截图中定义的 sinks。在通用模型中,注意槽(attention sinks)是放置在序列开头的特殊“常驻”标记,用于稳定注意力机制,在长文本场景下尤为有效。即使上下文极长,模型依然会关注开头的这些特殊标记,从而学习并存储有关整个序列的全局有用信息。(该机制最初由论文 Efficient Streaming Language Models with Attention Sinks[32] 提出。)
在 gpt-oss 的实现中,“注意槽”并非输入序列中的真实标记。相反,它们是为每个注意力头学习到的偏置对数(bias logits),并被拼接在注意力得分后面(见图 31)。这种设计在不修改分词输入的前提下,实现了与上述注意槽相同的目标。

图 31:gpt-oss 中注意槽的应用;基于 Hugging Face 的代码实现。
- Grok 2.5
xAI 发布了拥有 270B 参数的 Grok 2.5 模型权重。
作为 xAI 去年的旗舰生产级模型,Grok 2.5 的架构具有很高的参考价值。相比之下,之前讨论的模型大多从一开始就定位为开源权重模型。例如,gpt-oss 并非 GPT-4 的开源克隆版,而是专门为开源社区训练的定制模型。通过 Grok 2.5,我们可以难得地窥见真实生产系统的设计思路。
从架构上看,Grok 2.5 整体比较常规(见图 32),但仍有几处细节值得留意。
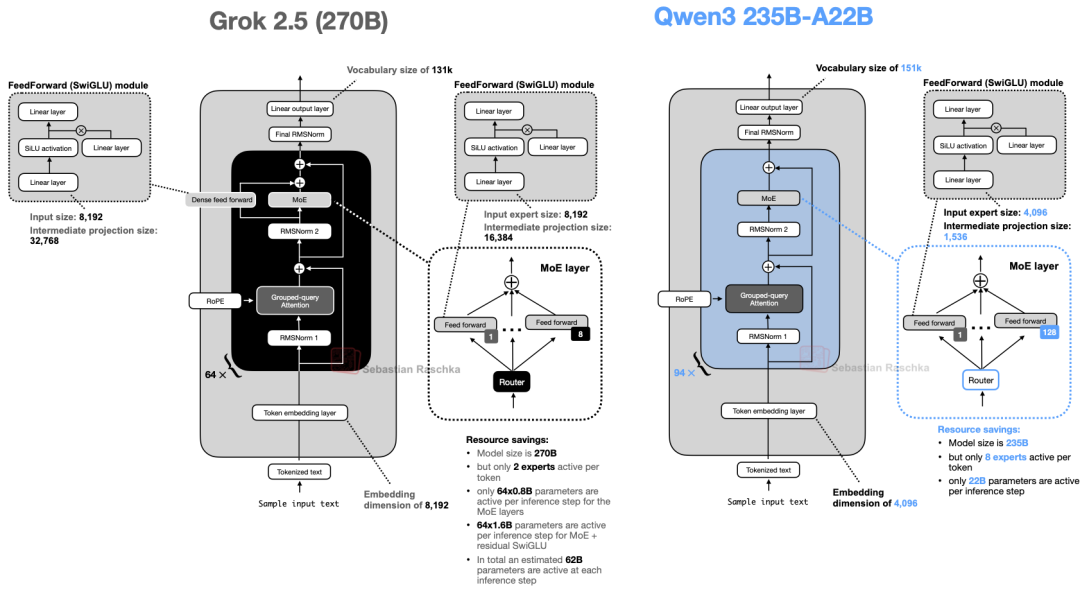
图 32:Grok 2.5 与同等规模的 Qwen3 模型对比
例如,Grok 2.5 采用了“少量大专家”的设计(共 8 个专家),这反映了较早期的技术趋势。如前所述,DeepSeekMoE 等近期设计更倾向于“大量小专家”的方案(Qwen3 亦是如此)。
另一个有趣的抉择是引入了等效于共享专家(shared expert)的设计。图 32 左侧显示的额外 SwiGLU 模块充当了“常驻”的共享专家。虽然它的中间维度翻倍了,与经典的共享专家设计不完全一致,但核心思路是一脉相承的。值得注意的是,Qwen3 舍弃了共享专家,这一设计在 Qwen4 或后续模型中是否会回归,非常值得期待。
- GLM-4.5
===========
GLM-4.5[33] 是今年发布的又一重磅模型。
它是一款类似于 Qwen3 的指令/推理混合模型,但在函数调用(Function Calling)和智能体(Agent)场景下表现出了更优的优化效果。
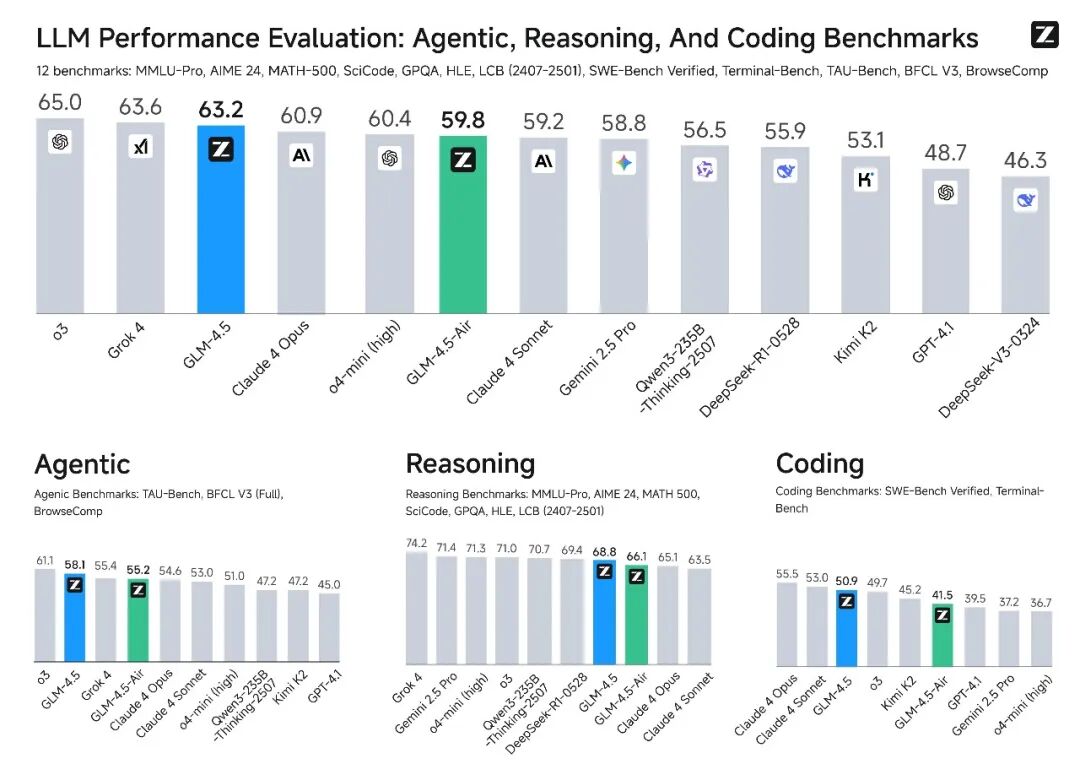
图 33:来自 GitHub 官方仓库 https://github.com/zai-org/GLM-4.5 的 GLM-4.5 基准测试结果
如图 34 所示,GLM-4.5 包含两个版本。旗舰版拥有 3550 亿参数,在 12 项基准测试中的平均表现超越了 Claude 4 Opus,仅略逊于 OpenAI 的 o3 和 xAI 的 Grok 4。此外还有 GLM-4.5-Air 版,其参数量为 1060 亿,性能仅比 355B 版本稍弱。
图 35 将 355B 架构与 Qwen3 进行了对比。
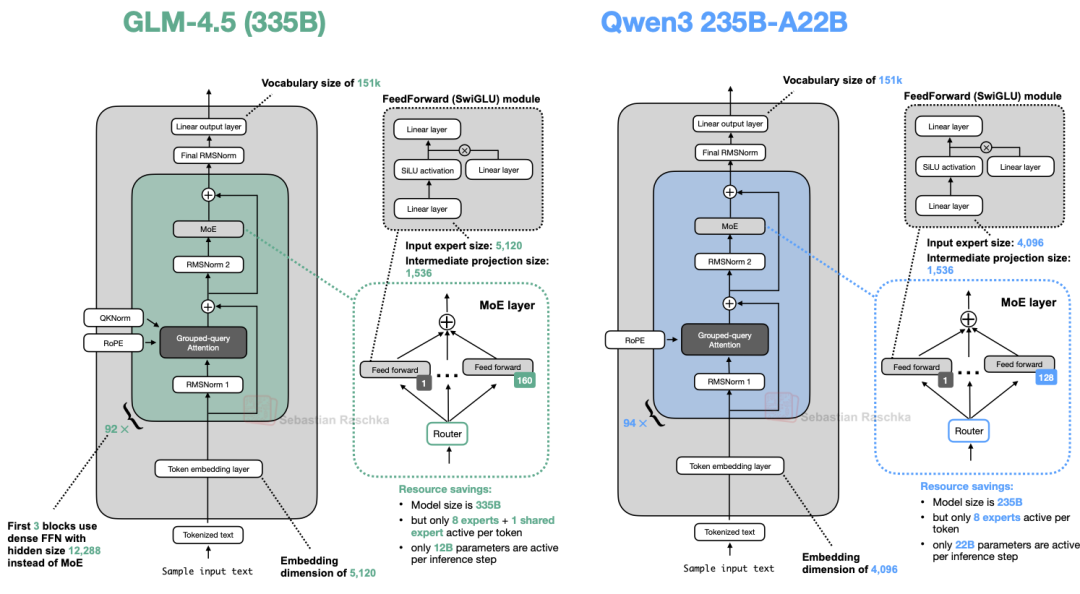
图 34:GLM-4.5 与同量级 Qwen3 模型的对比
两者的设计大体相似,但 GLM-4.5 采用了由 DeepSeek V3 率先引入的一种结构设计:在混合专家(MoE)模块之前先设置 3 个稠密层(Dense Layers)。究其原因,在大规模 MoE 系统中,先通过若干稠密层可以提升模型的收敛稳定性和整体性能。如果过早引入 MoE 路由机制,稀疏专家选择的不稳定性可能会干扰早期的语法和语义特征提取。因此,保留初始的稠密层能确保模型在路由决策介入高层处理之前,先形成稳定的底层表示。
此外,GLM-4.5 与 DeepSeek V3 类似,也采用了共享专家(Shared Expert)设计(这一点与 Qwen3 不同)。
(值得注意的是,GLM-4.5 还保留了 GPT-2 和 gpt-oss 中使用的注意力偏置机制。)
- Qwen3-Next
==============
Qwen3 Next 80B-A3B 包含 Instruct 和 Thinking 两个版本。虽然其设计延续了 Qwen3 架构,但在专家设计和注意力机制上引入了显著变化。
12.1 专家规模与数量
Qwen3 Next 架构的一个显著特点是,尽管模型参数量比之前的 235B-A22B 缩小了 3 倍,但它引入了 4 倍之多的专家,并额外增加了一个共享专家(Shared Expert)。高专家数量结合共享专家的设计,是当前 MoE 架构演进的重要方向。
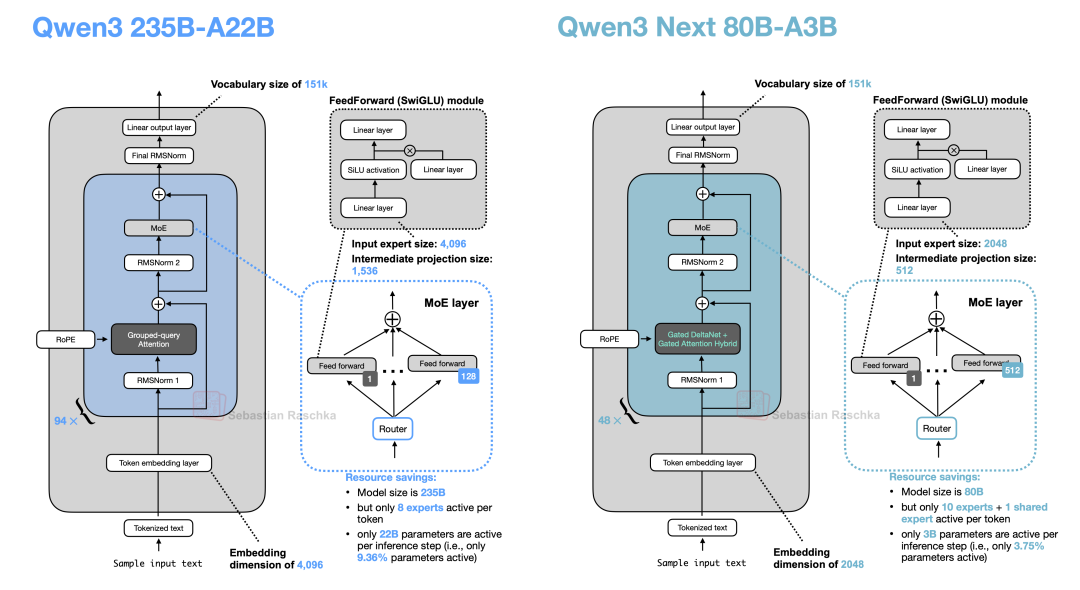
图 35:5 月发布的原始 Qwen3 模型(左)与 9 月发布的 Qwen3 Next 模型(右)对比。
12.2 Gated DeltaNet 与门控注意力混合架构
另一大亮点是该模型采用了 Gated DeltaNet[34] + Gated Attention[35] 的混合机制。这种设计在显存占用方面极具优势,实现了原生 262k 长度的上下文支持(相比之下,先前的 235B-A22B 模型原生仅支持 32k,通过 YaRN[36] 插值才可扩展至 131k)。
这种新型混合注意力机制的运作原理如下:传统的组查询注意力(GQA)虽然通过共享 K/V 头减少了 KV Cache 的大小和内存带宽占用,但其推理成本和缓存需求仍随序列长度线性增长。而 Qwen3 Next 的混合机制将 Gated DeltaNet 模块与 Gated Attention 模块以 3:1 的比例交替堆叠,如图 36 所示。
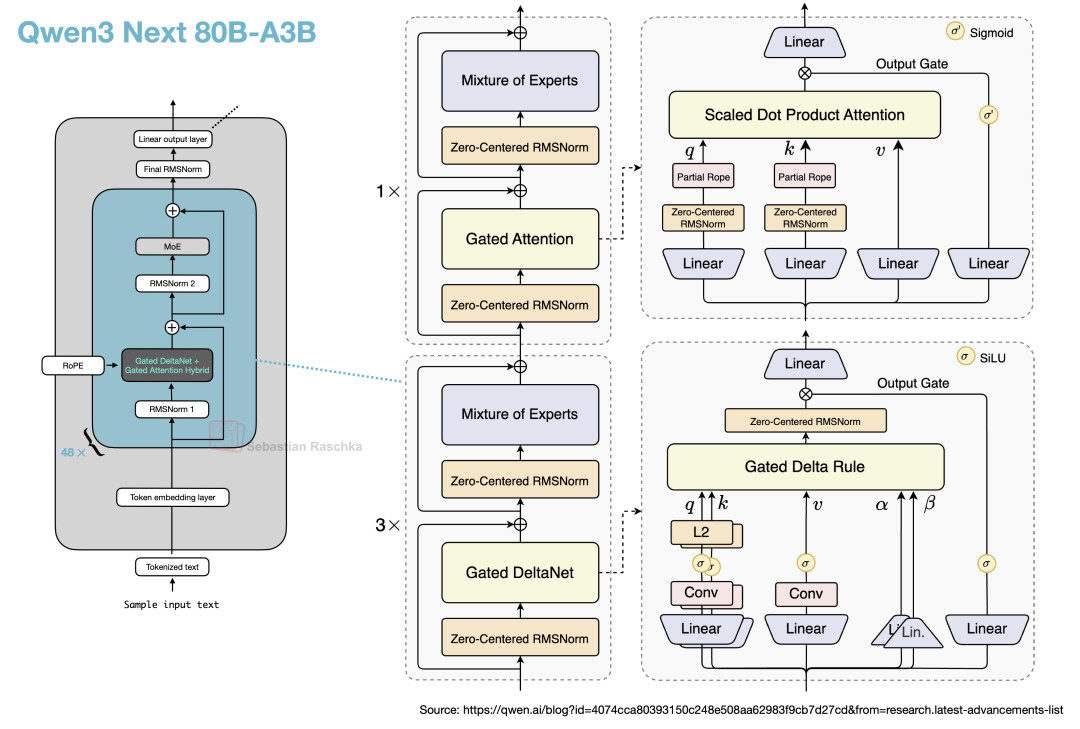
图 36:Gated DeltaNet + Gated Attention 混合机制。每 3 个使用 Gated DeltaNet 的 Transformer 块后跟随 1 个使用 Gated Attention 的 Transformer 块。右图源自 Qwen 官方博客。
Gated Attention 模块可以看作是标准缩放点积注意力(可用于 GQA)的增强版,主要改进包括:
- 增加了一个输出门(由 Sigmoid 控制,通常是逐通道的),在将注意力结果加回残差连接前进行缩放;
- 在 QKNorm 中使用零中心 RMSNorm(Zero-centered RMSNorm),而非标准 RMSNorm;
- 采用部分 RoPE(仅在部分维度上应用旋转位置编码)。
这些改动本质上是为了提升 GQA 的训练稳定性。
Gated DeltaNet 的变化则更为彻底。在 DeltaNet 模块中,q、k、v 以及两个门控信号(α, β)通过线性层、轻量级卷积层及归一化层生成。该层不再使用传统的注意力机制,而是采用了一种快速权重 Delta Rule[34] 进行更新。
不过,DeltaNet 在基于内容的精准检索能力上略逊于全注意力机制,这也是为何架构中仍保留了 1/4 的 Gated Attention 层。
考虑到注意力机制的计算量随长度呈平方级增长,引入 DeltaNet 组件极大提升了内存效率。在“线性时间复杂度、无缓存”的架构家族中,DeltaNet 模块基本上是 Mamba 的一种替代方案。Mamba 通过学习到的状态空间滤波器(本质上是随时间变化的动态卷积)来维护状态;而 DeltaNet 则通过 α 和 β 更新一个微型的快速权重记忆库,并使用 q 进行读取,其中卷积仅用于辅助生成 q、k、v、α、β。
12.3 多 Token 预测
除了上述两项提升效率的设计外,Qwen3 还引入了第三种优化技术:多 Token 预测[37](Multi-Token Prediction, MTP)。
(需要注意的是,DeepSeek V3/V3.2 以及后来的 GLM-4.5 和 MiniMax-M2 在训练阶段都使用了 MTP 技术。由于这主要是一种训练手段,通常在纯架构对比中不被单独列出。)
多 Token 预测(Multi-token prediction)的核心在于改变 LLM 的训练目标:在每个步长 t 中,模型不再仅预测下一个 Token,而是同时预测后续的多个 Token。具体实现上,模型在位置 t 额外增加若干预测头(通常为线性层),分别输出 t+1 \dots t+k 的 Logits,并对这些偏移量的交叉熵损失进行求和(根据 MTP[37] 论文建议,k 取值通常为 4)。这种机制能为训练提供更丰富的信号,从而提升收敛速度,且推理时仍可保持单 Token 生成模式。
此外,这些额外的预测头也可用于投机式多 Token 解码(Speculative multi-token decoding)。Qwen3-Next 似乎采用了这一方案,尽管目前公开的技术细节有限:
Qwen3-Next 引入了原生多 Token 预测(MTP)机制,这不仅产生了一个在投机解码中具有高接受率的 MTP 模块,还提升了整体性能。此外,Qwen3-Next 专门优化了 MTP 的多步推理性能,通过保持训练与推理一致性的多步训练,进一步提高了实际场景下投机解码的接受率。来源:Qwen3-Next 官方博客[38]
13. MiniMax-M2
近期,开源权重 LLM 的开发者们陆续分享了针对效率优化的核心架构。例如 Qwen3-Next 将部分全注意力(Full Attention)模块替换为快速门控 DeltaNet 模块;DeepSeek V3.2 则采用了稀疏注意力(Sparse Attention),通过牺牲部分建模性能来提升计算效率。
MiniMax-M1[39] 同样属于这一范畴,它使用了一种名为 Lightning Attention 的线性注意力变体,效率优于常规注意力。虽然 MiniMax M1 最初的关注度不及其他模型,但新发布的 MiniMax-M2[40] 在基准测试中表现极其出色,目前被视为性能最强的开源权重模型之一。
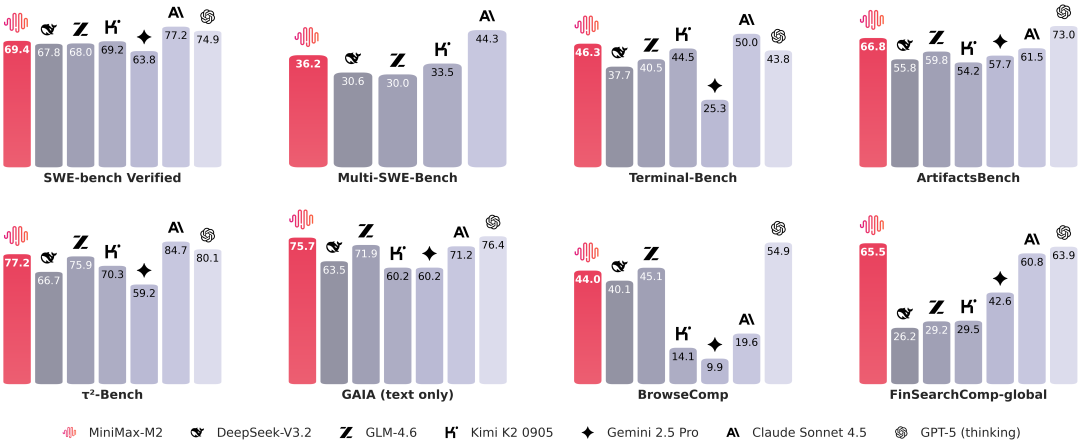
图 37:MiniMax-M2 与其他主流开源及闭源 LLM 的基准测试性能对比。图片来自官方模型库的 Readme 文件。
如下图所示,我将 MiniMax-M2 归类为传统的 Decoder 风格 Transformer LLM,因为它并没有沿用 MiniMax-M1 中的高效 Lightning Attention 变体。开发者转而回归全注意力架构,这很可能是为了追求更高的建模能力和基准测试分数。
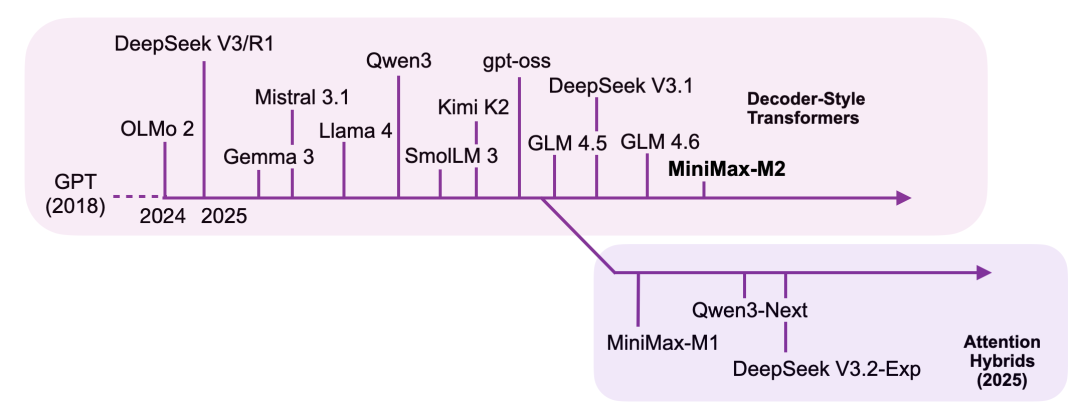
图 38:本文涵盖的主要 LLM 时间线,以及一些通过牺牲部分建模性能来换取效率的注意力混合模型。
总体而言,MiniMax-M2 与 Qwen3 惊人地相似。除了层数、尺寸等参数差异外,两者的整体组件基本一致。
13.1 Per-Layer QK-Norm
MiniMax-M2 唯一值得关注的技术亮点是采用了所谓的 “per_layer” QK-Norm,而非普通的 QK-Norm。深入研究 代码[41] 可以发现,其注意力机制内部的实现如下:
self
.q_norm =
RMSNorm
(hidden_size,
eps
=config.rms_norm_eps)
self
.k_norm =
RMSNorm
(hidden_size,
eps
=config.rms_norm_eps)
在这里,hidden_size 等于所有头部的总维度(num_heads * head_dim),因此 RMSNorm 的缩放向量(Scale Vector)为每个注意力头及其维度都提供了独立的参数。
所谓的 “per_layer” 是指 RMSNorm(用于 QK-Norm)虽然像常规 QK-Norm 一样定义在每个 Transformer 块中,但它不再由所有注意力头共享,而是为每个头分配了唯一的规范化参数。
此外,模型配置文件[42] 中也包含了滑动窗口注意力(Sliding-window Attention)设置,但与 Mistral 3.1 类似,该选项默认处于关闭状态。
除了 per-layer QK-Norm,其架构与 Qwen3 非常接近,如下图所示。
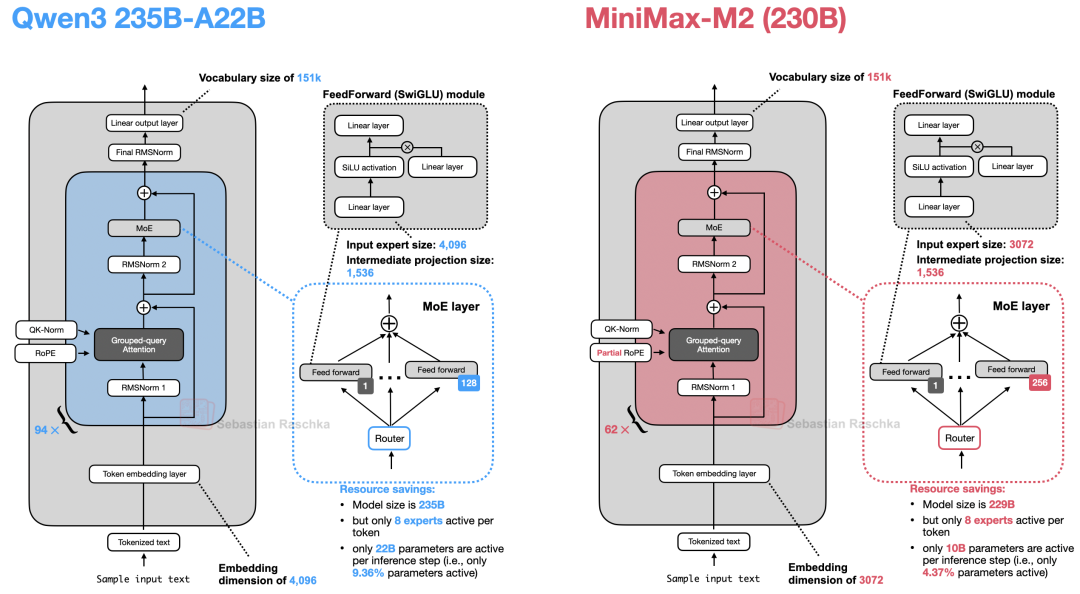
图 39:Qwen3 与 MiniMax-M2 的对比。
13.2 MoE 稀疏度
另一个有趣的细节是,MiniMax-M2 没有使用共享专家(Shared Expert),这一点与 Qwen3 一致,但不同于 Qwen3-Next。通常认为共享专家有助于减少其他专家之间的冗余。
此外,从上图可以看出,MiniMax-M2 的“稀疏性”是 Qwen3 的两倍。在总参数量与 Qwen3 235B-A22B 相当的情况下,MiniMax-M2 每个 Token 的激活专家仅为 10B,而非 22B。这意味着 MiniMax-M2 在单次推理步中仅使用了 4.37% 的参数,而 Qwen3 的激活参数占比为 9.36%。
13.3 Partial RoPE 机制
与 MiniMax-M1 类似,MiniMax-M2 在注意力模块中采用了 “Partial RoPE”(部分旋转位置编码)而非标准的 RoPE 来处理位置信息。与标准 RoPE 一样,旋转操作是在 QK-Norm 之后应用于查询(Query)和键(Key)上的。
所谓 Partial RoPE,是指每个 Head 中只有前 rotary_dim 个通道会进行旋转位置编码,而剩下的 head_dim - rotary_dim 个通道则保持原样。
在 M1 的官方 README[43] 文档中,开发团队提到:
将旋转位置编码(RoPE)应用于注意力头一半的维度,基频设为 10,000,000。
我们可以通过下图直观理解:
Full RoPE: [r r r r r r r r]
Partial RoPE: [r r r r - - - -]
在上面的概念示意图中,“r” 代表经过旋转(位置编码)的维度,而短横线则代表未做改动的维度。
这样做有什么好处?在 M1 论文[44] 中,开发者指出:
在 Softmax 注意力的一半维度上实现 RoPE,可以在不损失性能的前提下实现长度外推。
推测其原因在于,这种做法能防止长序列(尤其是超出训练集最大长度的序列)出现“过度旋转”。也就是说,与其让模型面对训练中从未见过的、可能导致偏离的“极端旋转”,不如保留一部分不旋转的维度,这样效果反而更稳健。
14. Kimi Linear
近期,为了提升大语言模型(LLM)的效率,线性注意力机制(linear attention)迎来了复兴。
在 2017 年《Attention Is All You Need》论文中提出的注意力机制,即缩放点积注意力,至今仍是 LLM 中最主流的变体。除了传统的多头注意力(MHA),它还演化出了更高效的形式,如分组查询注意力(GQA)、滑动窗口注意力(SWA)以及多头潜在注意力(MLA)。
14.1 传统注意力与平方级开销
原始的注意力机制其开销随序列长度呈平方级增长:
( ext{Attention}(Q, K, V) = ext{softmax}!\left(\frac{QK^\ op}{\sqrt{d}}
ight)V )
这是因为查询矩阵 (Q)、键矩阵 (K) 和值矩阵 (V) 都是 n imes d 矩阵,其中 d 是嵌入维度(超参数),而 n 是序列长度(即 token 数量)。
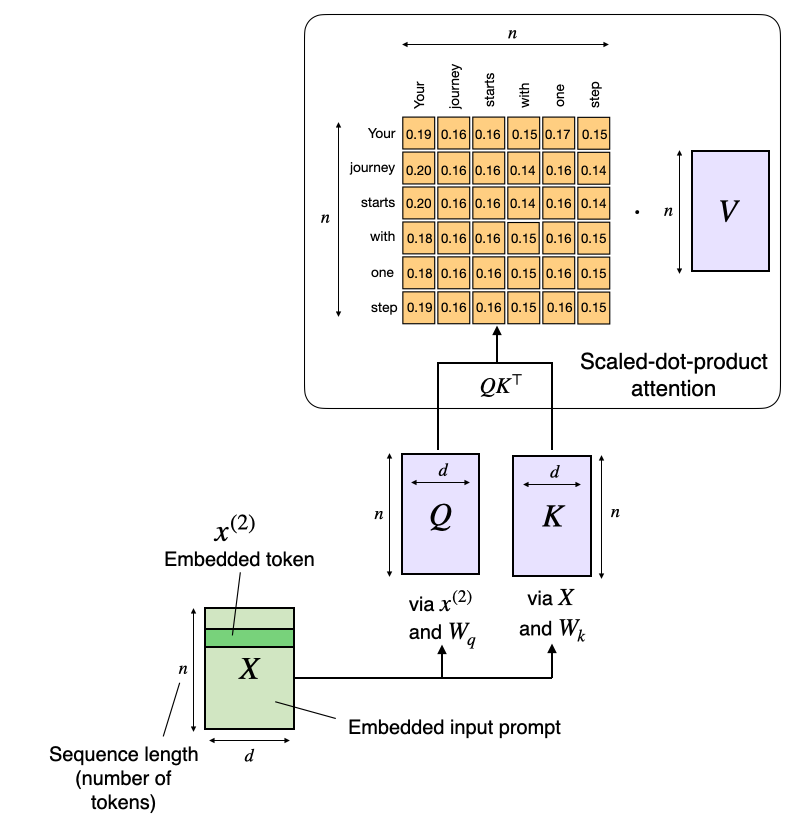
图 40:注意力机制中序列长度 n 导致的平方级开销示意图。
14.2 线性注意力
线性注意力变体早已存在。早在 2020 年的论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》中,研究人员就对注意力机制进行了近似处理:
( ext{Attention}(Q, K, V) = ext{softmax}!\left(\frac{QK^\ op}{\sqrt{d}}
ight)V \approx \phi(Q)\big(\phi(K)^\ op V\big))
这里 \phi(\cdot) 是核特征函数,设定为 \phi(x) = ext{elu}(x) + 1。
这种近似方法非常高效,因为它避免了显式计算 n imes n 的注意力矩阵 QK^T。它不再执行所有 token 之间的两两交互(这会消耗 O(n^2d) 的时间和空间),而是通过改变计算顺序来降低开销。
这些早期尝试的核心在于将时间与空间复杂度从 O(n^2) 降低到 O(n),使得处理长序列时的效率大幅提升。然而,这些变体通常会导致模型精度下降,因此在主流的开源 SOTA 模型中并不常见。
14.3 线性注意力的复兴
今年下半年,线性注意力变体再次活跃。首先是 6 月发布的 MiniMax-M1,这是一个拥有 456B 参数(活跃参数 46B)的混合专家模型(MoE),采用了 Lightning Attention。
随后,Qwen 团队在 8 月推出了 Qwen3-Next,DeepSeek 团队在 9 月宣布了 DeepSeek V3.2。这三个模型(MiniMax-M1、Qwen3-Next、DeepSeek V3.2)在大部分或全部层中都用高效的线性变体取代了传统的平方级注意力机制。
有趣的是,剧情随后出现了反转:MiniMax 团队发布的 230B 参数新模型 M2 弃用了线性注意力,回归了常规注意力。该团队表示,线性注意力在生产级 LLM 中非常棘手。虽然它在处理常规 Prompt 时表现尚可,但在推理和多轮对话任务(这些任务对 Chat 和 Agent 应用至关重要)中的精度较差。
这本该是线性注意力走向没落的转折点,但情况变得更加有趣。10 月,Kimi 团队发布了采用线性注意力的 Kimi Linear[45] 模型。
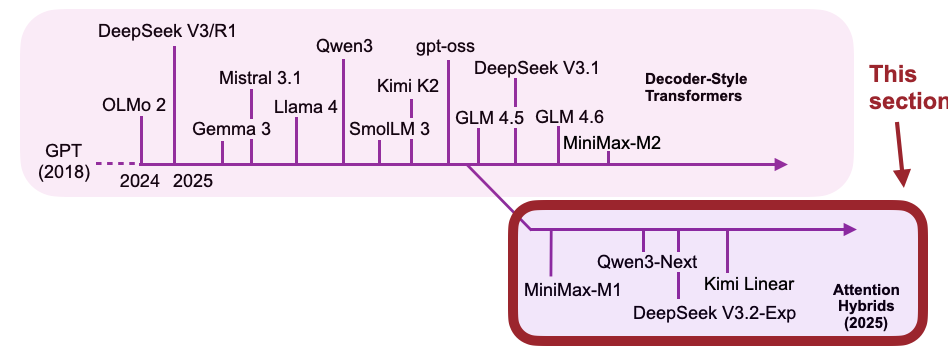
图 41:线性注意力混合架构概览。
注:Qwen3-Next 和 Kimi Linear 也可以被归类为 Transformer-状态空间模型(SSM)混合架构。通常这类混合架构可以分为两类:一类是以 SSM 为主并加入 Transformer 组件,另一类(如 Qwen3-Next 和 Kimi Linear)则是以 Transformer 为主并加入 SSM 组件。由于 IBM Granite 4.0 和 NVIDIA Nemotron Nano 2 已被归入 Transformer-SSM 范畴,因此将它们统一分类也是合理的。
14.4 Kimi Linear 与 Qwen3-Next 的对比
Kimi Linear 在结构上与 Qwen3-Next 存在诸多相似之处。两者均采用了混合注意力策略,即结合了轻量级的线性注意力(Linear Attention)与开销较大的全注意力(Full Attention)层。具体而言,两款模型均采用了 3:1 的配比:如下图所示,每三个使用线性 Gated DeltaNet 变体的 Transformer 块,就会搭配一个使用全注意力的块。
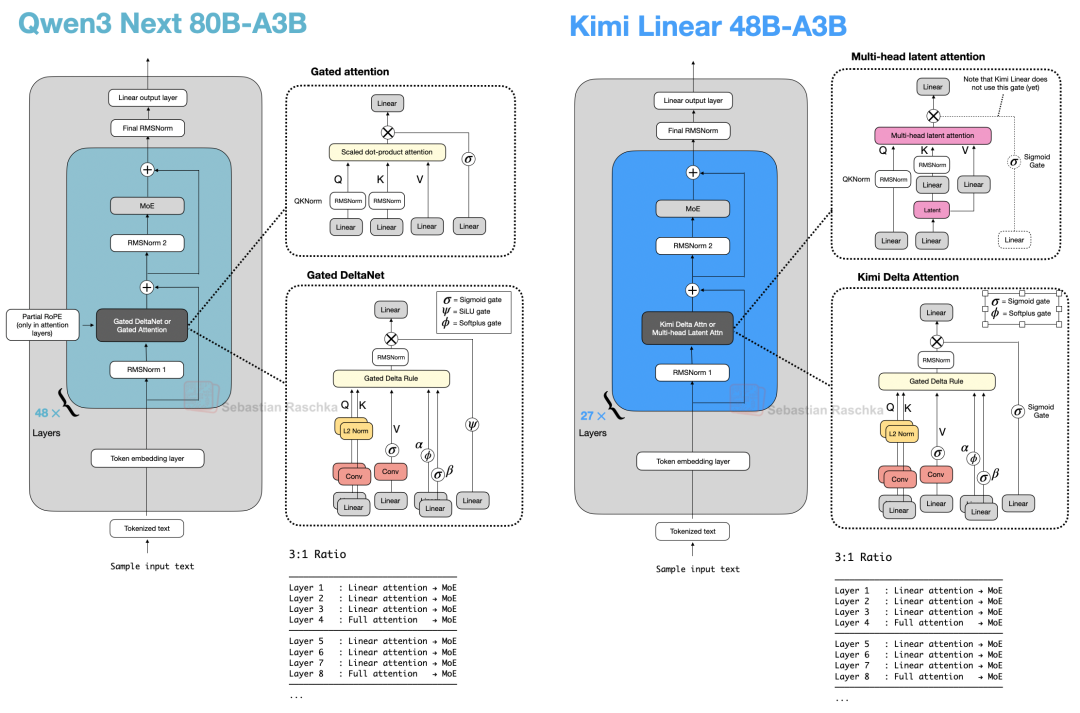
图 42:Qwen3-Next 与 Kimi Linear 架构对比。
Gated DeltaNet 是一种借鉴了循环神经网络(RNN)思想的线性注意力变体,引入了来自 Gated Delta Networks: Improving Mamba2 with Delta Rule[34] 论文中的门控机制。从某种意义上说,Gated DeltaNet 就是融合了 Mamba 风格门控的 DeltaNet,而 DeltaNet 本身即为一种线性注意力机制。
值得注意的是,上图中 Kimi Linear 部分特意省略了 RoPE(旋转位置编码)框。这是因为 Kimi 在多头潜变量注意力(MLA)层(全局注意力)中应用了 NoPE(无位置嵌入)方案。根据作者的表述,这种设计使 MLA 在推理时能以纯多查询注意力(Multi-query Attention)模式运行,并避免了在长文本扩展时进行 RoPE 重调优(其位置偏差据称由 Kimi Delta Attention 块处理)。
14.5 Kimi Delta Attention
Kimi Linear 对 Qwen3-Next 的线性注意力机制进行了改进,引入了 Kimi Delta Attention (KDA) 机制,这实质上是对 Gated DeltaNet 的精细化改进。Qwen3-Next 使用标量门控(每个注意力头一个值)来控制内存衰减率,而 Kimi Linear 将其替换为针对每个特征维度的通道级(Channel-wise)门控。作者认为,这增强了对内存的控制力,进而提升了长文本推理能力。
此外,在全注意力层方面,Kimi Linear 将 Qwen3-Next 的门控注意力层(本质上是带输出门控的标准多头注意力)替换为多头潜变量注意力(MLA)。这与 DeepSeek V3/R1 中讨论的 MLA 机制相同,但额外增加了一个门控。(回顾一下,MLA 通过压缩 Key/Value 空间来减小 KV 缓存占用。)
虽然没有与 Qwen3-Next 的直接对比,但与 Gated DeltaNet 论文中的 Gated DeltaNet-H1 模型(本质上是带滑动窗口注意力的 Gated DeltaNet)相比,Kimi Linear 在保持相同 Token 生成速度的同时,实现了更高的建模精度。
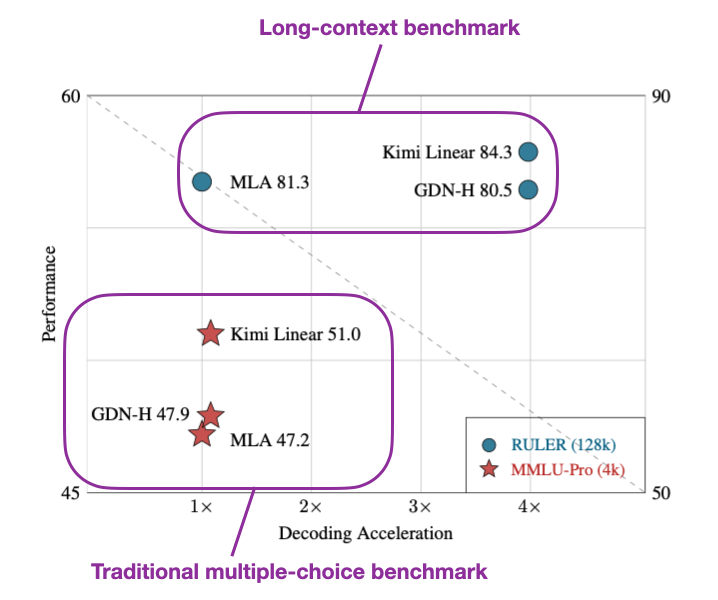
图 43:Kimi Linear 论文插图。结果显示 Kimi Linear 的速度与 GatedDeltaNet 持平,远快于 MLA 架构(如 DeepSeek V3/R1),且在基准测试中表现更优。
此外,根据 DeepSeek-V2 论文[5] 的消融实验,在精心选择超参数的情况下,MLA 的表现与常规全注意力机制相当。
Kimi Linear 在长文本和推理基准测试中的出色表现,再次证明了线性注意力变体在大规模 SOTA 模型中的应用潜力。尽管 Kimi Linear 拥有 48B 参数,但其规模仍比 Kimi K2 小 20 倍。Kimi 团队是否会在未来的 K3 模型中采用这一方案,非常值得关注。
Olmo 3 架构解析
Olmo 模型因其完全开源的特性备受关注,不仅提供了详细的训练报告[46],还公开了多个训练检查点(checkpoints)以及训练数据信息。
此次 Olmo 系列除了基础模型(base)和指令微调模型(instruct)外,还推出了推理模型(reasoning)。在架构对比上,最适合与 Olmo 3 进行参照的是 Qwen3,两者的模型规模和性能表现都非常接近。
首先看较小规模的 Olmo 3 7B。
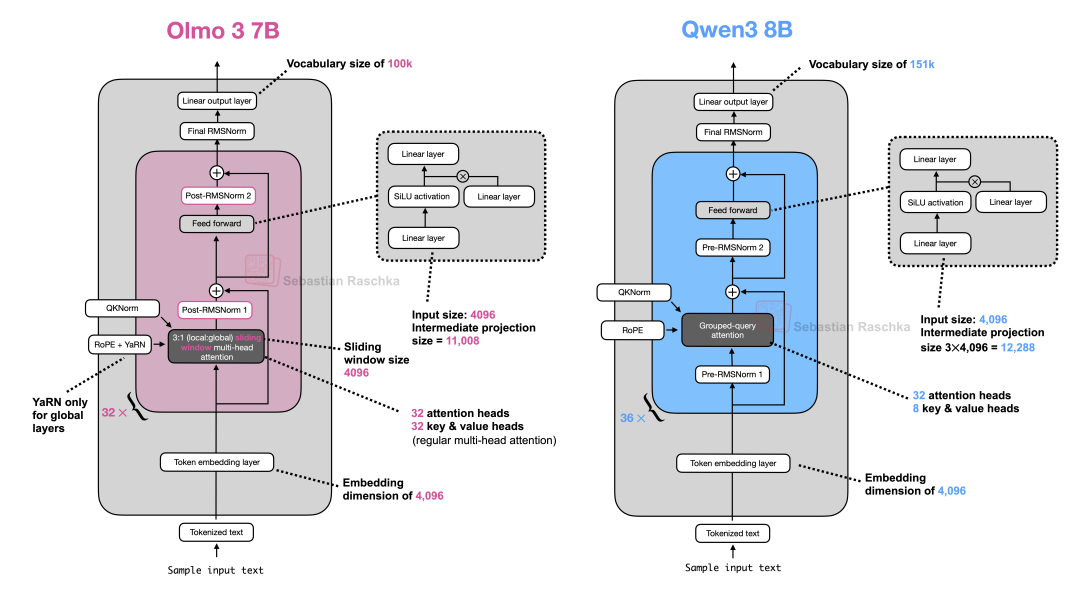
图 44:Olmo 3 7B 与 Qwen3 8B 架构对比
Olmo 3 的架构与 Qwen3 较为相似,但这很大程度上是延续了其前作 Olmo 2 的设计思路。
与 Olmo 2 一致,Olmo 3 坚持使用 Post-Norm 而非 Pre-Norm 结构,因为研发团队在 Olmo 2 的研究中发现这种方式能提升训练的稳定性。
值得注意的是,7B 模型依然采用了类似 Olmo 2 的多头注意力(Multi-Head Attention)机制。不过为了提高效率并减小 KV 缓存(KV cache)的体积,它引入了滑动窗口注意力(Sliding Window Attention,类似于 Gemma 3)。
接下来看 32B 模型。
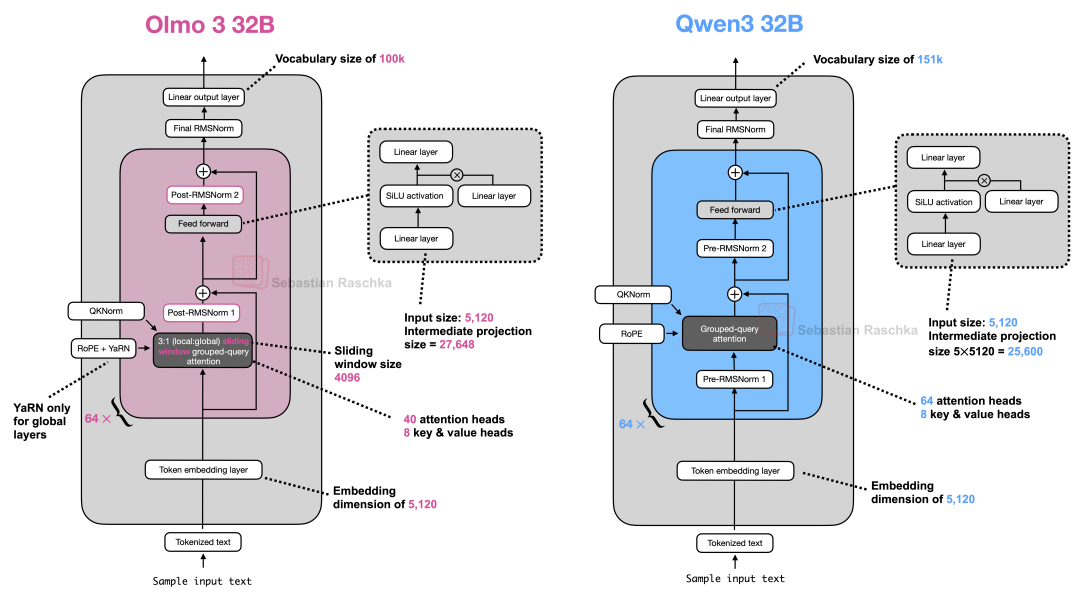
图 45:Olmo 3 32B 与 Qwen3 32B 架构对比
整体而言,32B 版本是相同架构的等比例缩放。其前馈网络(Feed Forward Layer)中输入维度到中间层维度的比例等参数,与 Qwen3 大致匹配。
由于词表大小较小,Olmo 3 的初始架构规模可能略逊于 Qwen3,因此团队将中间层的扩展比例从 Qwen3 的 5 倍提升至 5.4 倍,从而实现 32B 的参数规模以进行直接对比。
此外,32B 模型采用了分组查询注意力(Grouped Query Attention)。
在长文本处理方面,Olmo 3 支持 64k 的上下文长度,并针对全局注意力层(非滑动窗口层)使用了 YaRN[36] 技术进行上下文扩展。YaRN 是一种精细的 RoPE 重缩放技术,能更好地保持模型在长文本下的性能。相比之下,Qwen3 将 YaRN 作为可选方案,用于将原生 32k 上下文扩展至 131k。
以下是 Olmo 3 的从零实现参考:
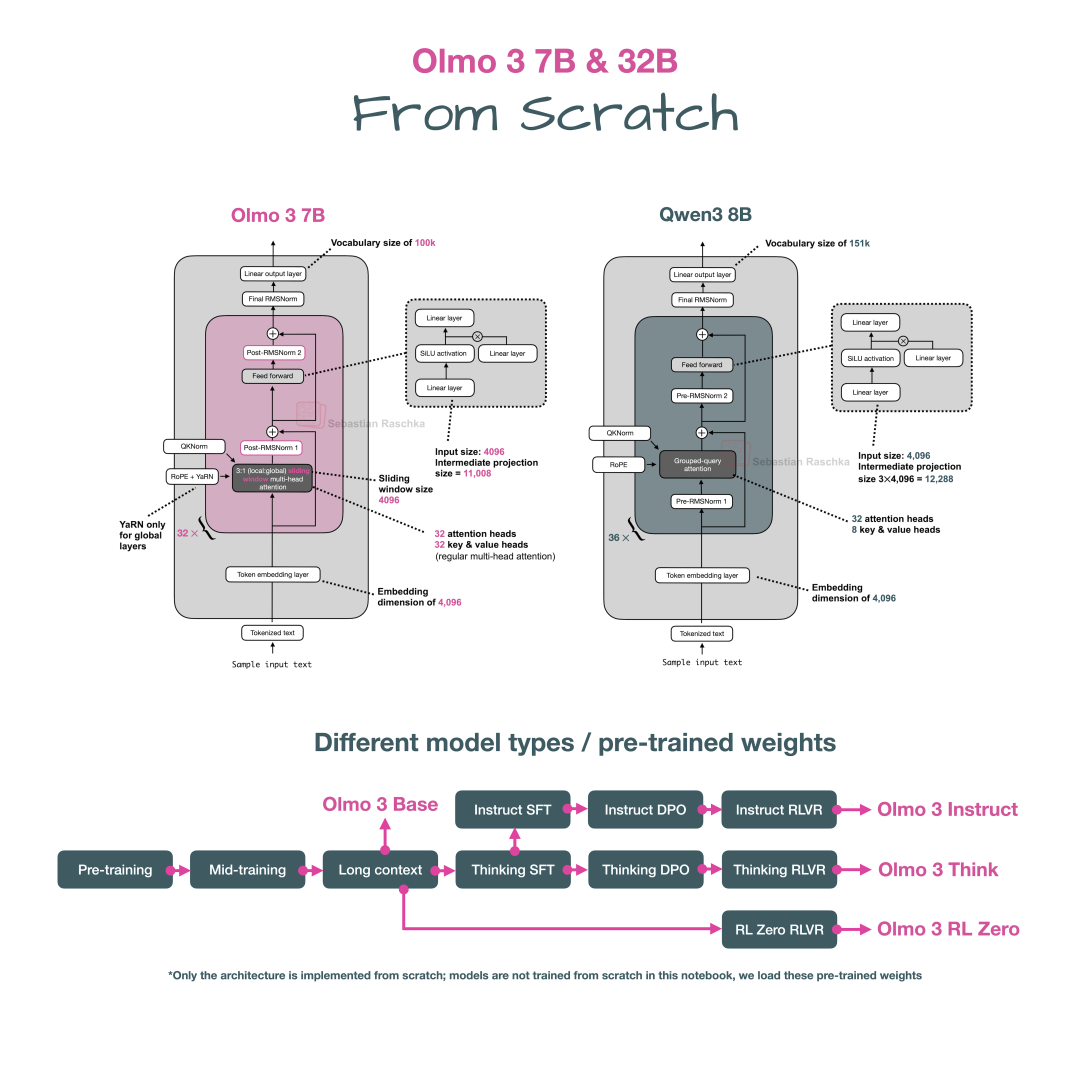
图 46:Olmo 3 的从零实现代码示例
DeepSeek V3.2
DeepSeek V3.2 是一次重大更新,在特定基准测试中已能与 GPT-5.1 和 Gemini 3.0 Pro 齐平。
图 47:DeepSeek 系列模型发布时间线(红色为旗舰模型)
其架构整体延续了 DeepSeek V3 的设计,但新增了稀疏注意力(Sparse Attention)机制以进一步提升效率。
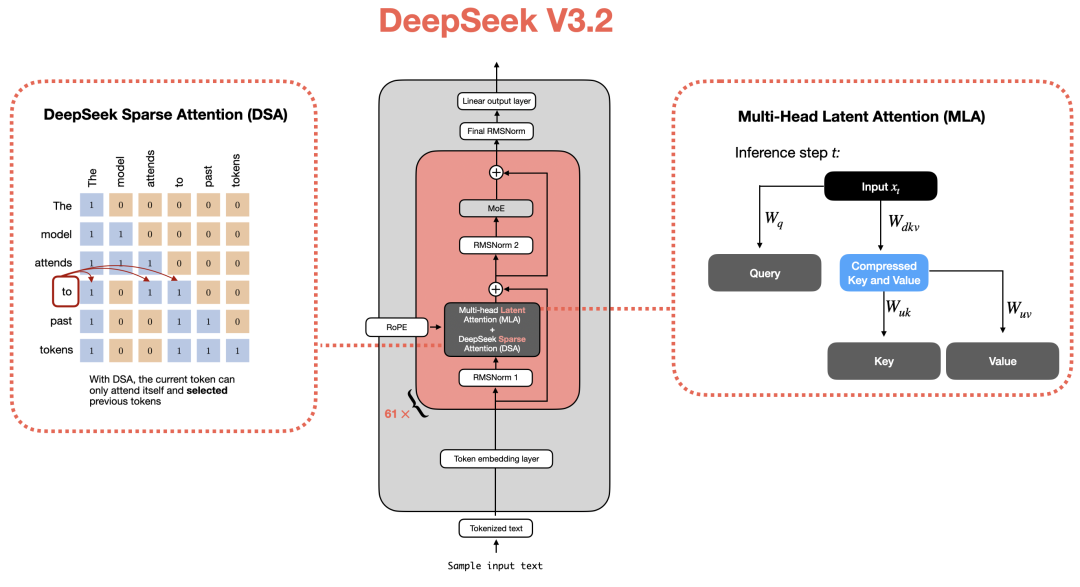
图 48:包含多头潜变量注意力(Multi-head Latent Attention)与稀疏注意力的 DeepSeek 架构
关于 DeepSeek 从 V3 到 V3.2 的详细技术演进,可参考以下深度解析:
DeepSeek 系列模型技术巡礼:从 V3 到 V3.2[47]
- Mistral 3
=============
Mistral 团队发布了全新的 Mistral 3[48] 模型家族。该系列包括三款名为 Ministral 3 的小型稠密模型(3B、8B 和 14B),以及旗舰级的 Mistral 3 Large 模型。后者是一个拥有 675B 参数的 MoE(混合专家)模型,激活参数量为 41B。
Mistral 3 Large 的具体构成如下:
- 一个参数量为 673B、激活参数量为 39B 的 MoE 语言模型
- 一个 2.5B 的视觉编码器(Vision Encoder)
这是 Mistral 自 2023 年发布 Mixtral 以来首次回归 MoE 架构。该系列涵盖了 Base、Instruct 和 Reasoning(推理)三种变体。
在硬件优化方面,Mistral 与 NVIDIA 合作,针对 Blackwell 芯片优化了 tokens/sec 吞吐量。
在性能基准测试中,较小的 Ministral 模型与 Qwen3 表现相当,而旗舰级的 Large 模型则与 DeepSeek V3.1 处于同一水平。在 LMArena Elo 评分中,DeepSeek V3.2 以 1423 分略领先于 Mistral 3 的 1418 分。
下图对比了 Mistral 3 Large Instruct 与 DeepSeek V3.2-Thinking 的基准测试数据:
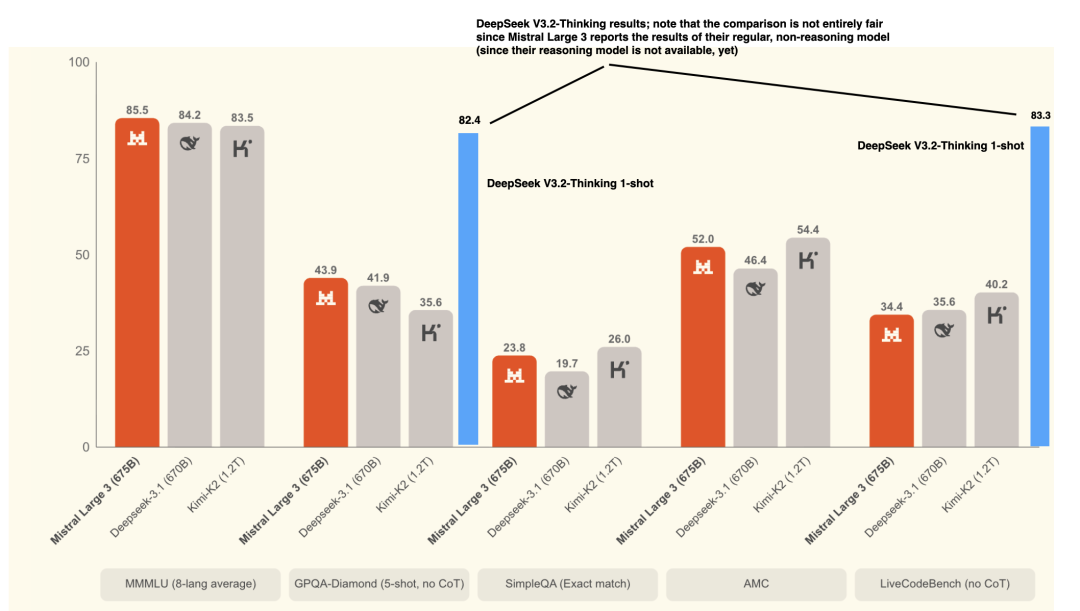
图 49:Mistral 3 官方公告中的基准测试数据,叠加了 DeepSeek V3.2 论文中的结果。
从数据来看,DeepSeek V3.2-Thinking 模型的表现更为出色。目前,Mistral 3 Large 凭借其优化特性,成为高性价比、低延迟部署的理想选择;而 DeepSeek V3.2-Thinking 则在追求极致回答质量的场景中更具优势。此外,Mistral 3 Large 支持多模态,而 DeepSeek V3.2 仅支持文本。
通过分析 Hugging Face 上的模型权重参数[49],可以发现 Mistral 3 Large 的架构与 DeepSeek V3/V3.1 基本一致。唯一的区别在于,Mistral 3 将专家的规模扩大了 2 倍,同时将专家数量相应减少了 2 倍。
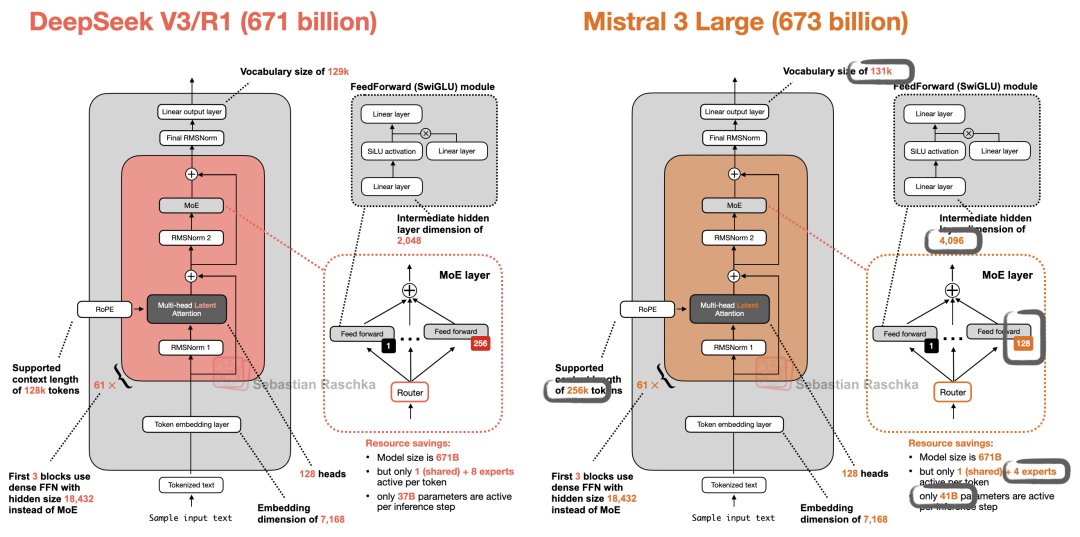
图 50:DeepSeek V3 与 Mistral 3 Large 架构对比。
尽管架构极其相似,但由于 Mistral 使用了自研的分词器(Tokenizer),推测该模型应该是从零开始训练的,而非基于 DeepSeek V3 的初始化微调。
继 Kimi K2 之后,Mistral 3 成为第二个采用 DeepSeek V3 架构的模型系列。不同于 Kimi K2 将模型规模从 671B 提升至 1 万亿参数,Mistral 3 团队仅调整了专家规模比例,并增加了视觉编码器以支持多模态。DeepSeek V3 架构设计非常扎实,其 MoE(混合专家模型)和 MLA(多头潜在注意力)带来的效率优势非常显著。目前大模型的核心竞争力很大程度上取决于训练流水线以及推理侧的缩放策略。
- Nemotron 3
==============
NVIDIA 发布了 Nemotron 系列的最新成员 Nemotron 3。与 Olmo 3 类似,Nemotron 不仅开源了模型权重并发布了技术报告,还公开了数据集和训练代码。
Nemotron 3 包含三种规模:
- Nano (30B-A3B)
- Super (100B)
- Ultra (500B)
在架构设计上,该系列模型采用了 MoE Mamba-Transformer 混合架构。目前 Nano 模型已开源权重,其架构示意图如下:
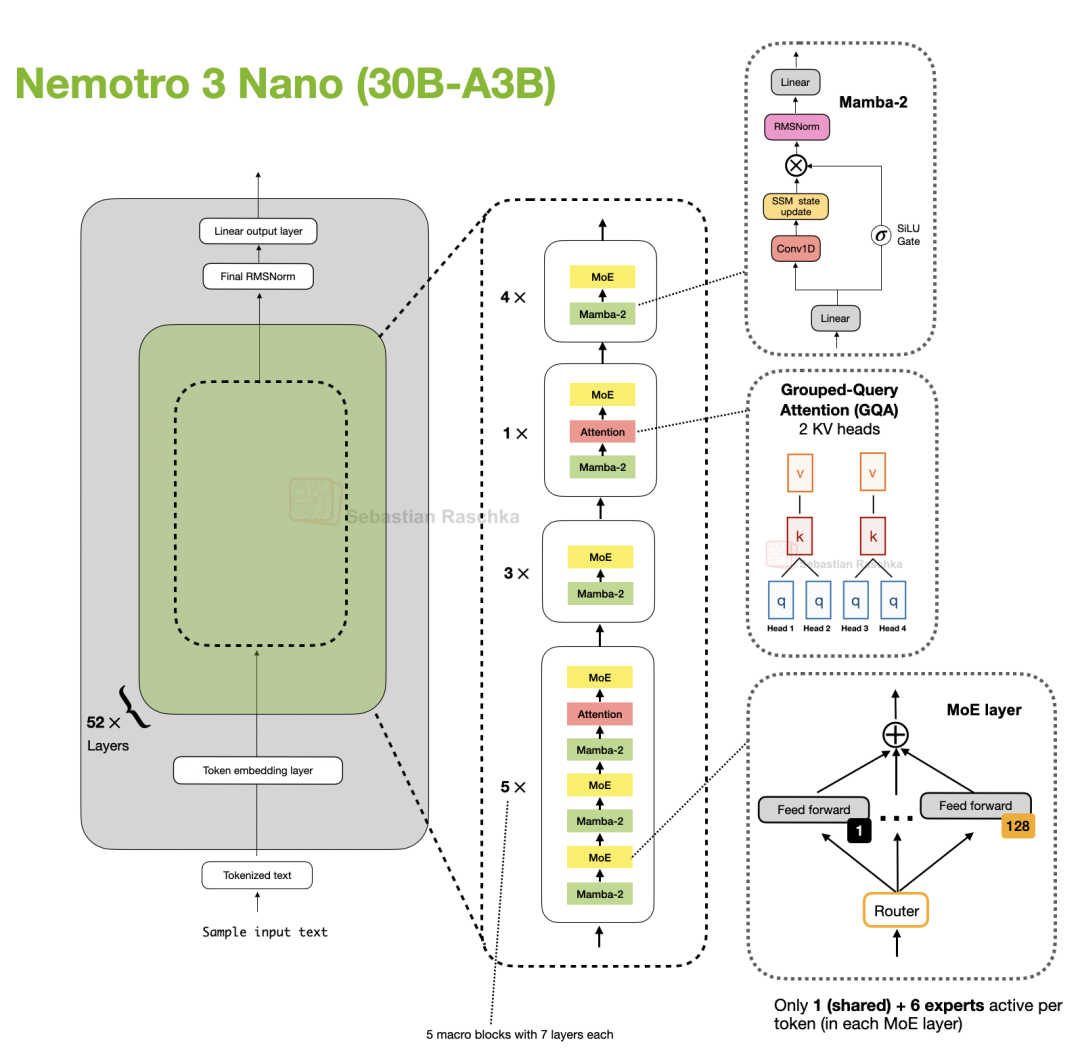
图 51:Nemotron 3 Nano 模型概览,采用 Transformer-Mamba 混合架构。
Nemotron 3 Nano (30B-A3B) 是一个 52 层的混合架构模型,它将 Mamba-2 序列建模块与稀疏 MoE 前馈层交替堆叠,并且仅在极少数层中使用了自注意力机制。
具体而言,该架构由 13 个宏块(macro blocks)组成,每个宏块内部包含重复的“Mamba-2 → MoE”子块,并辅以少量分组查询注意力(GQA)层。通过宏块与子块的组合,整个架构共计 52 层。
在 MoE 模块方面,每个 MoE 层包含 128 个专家,但每个 token 仅激活 1 个共享专家和 6 个路由专家。
从概念上讲,Mamba-2 层与 Qwen3-Next 和 Kimi-Linear 所使用的 Gated DeltaNet 方案类似。两者的共同点在于都使用门控状态空间更新(gated-state-space update)取代了标准的注意力机制。这种状态空间模块通过维护一个持续运行的隐藏状态,并利用学习到的门控机制融合新输入。与注意力机制相比,它的计算复杂度随输入序列长度呈线性增长,而非平方增长。
这种架构的亮点在于,在保持与同等规模纯 Transformer 模型相当的性能时,能够实现更高的 token 吞吐量。
相比 Qwen3-Next 和 Kimi-Linear,Nemotron 3 对注意力层的使用更加克制,这是一个非常值得关注的方向。考虑到 Transformer 架构的优势之一在于超大规模下的性能表现,Nemotron 3 Super 尤其是 Ultra 版本在与 DeepSeek V3.2 等顶尖模型的对标中表现如何,非常值得期待。
- 小米 MiMo-V2-Flash
====================
小米发布了最新的 MiMo-V2-Flash 模型,其基准测试性能足以媲美 DeepSeek V3.2,但参数量仅为后者的一半,且推理速度更快。该模型采用混合专家模型(MoE)架构,总参数量为 309B,每个 Token 激活参数量为 15B。
在注意力机制上,该模型采用了滑动窗口注意力(SWA)与全局注意力的组合,比例为 5:1,这一设计与 Gemma 3 类似。不过,小米采用了更激进的窗口策略:其滑动窗口大小仅为 128,比 Gemma 3 的 1024 小了 8 倍。
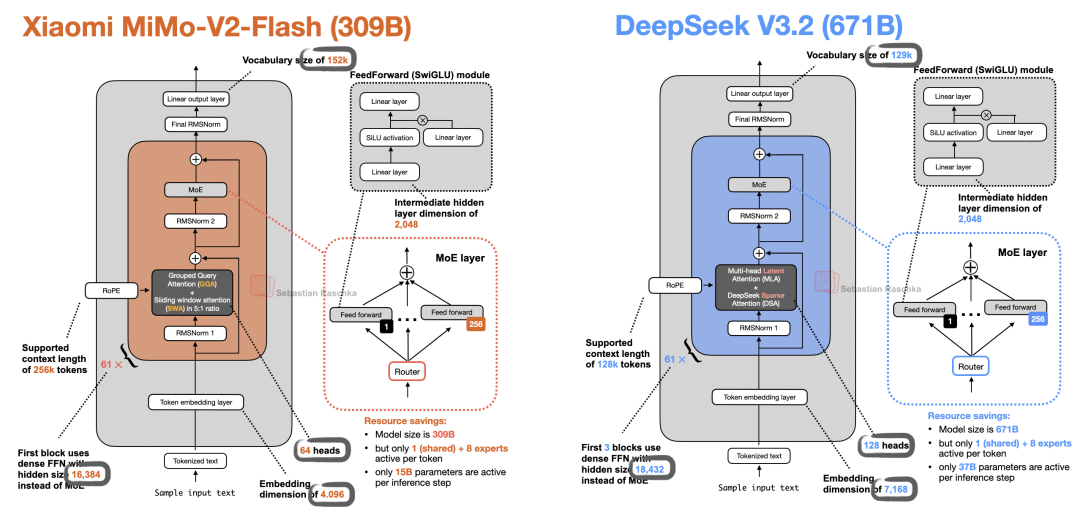
图 52:小米 MiMo-V2-Flash 与 DeepSeek V3.2 的基准性能对比。
这是目前已知参数规模最大的采用滑动窗口注意力机制的模型。
此外,该模型也引入了多 Token 预测(MTP)技术。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 19
19 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)