零门槛搭建AI聊天机器人:本地DeepSeek + 云端通义千问实战全攻略
前言
这篇博客就是给大家填这些坑的:我会从最基础的Windows WSL Linux环境搭建开始,手把手带你完成两套可落地的AI聊天机器人开发:
一套是基于Ollama+DeepSeek的纯本地聊天机器人,数据完全不出你的电脑,离线也能跑,适合处理敏感数据、内网环境使用;另一套是基于LangChain+阿里云百炼的混合架构机器人,可以无缝切换云端通义千问大模型,适合需要强推理能力的复杂任务。
Ollama本地部署
ollama:是一款旨在简化大型语言模型本地部署和运行过程的开源软件。ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)
通过ollama,开发者可以导入和定制自己的模型,无需关注复杂的底层实现细节。
网址:https://ollama.com
ollama支持多种开源模型,涵盖文本生成、代码生成、多模态推理等场景。用户可以根据需求选择合适的模型,并通过简单的命令行操作在本地运行。
ollama 官方模型库:https://ollama.com/library
windows系统安装Ollama
1.下载Ollama, Windows系统安装包:https://ollama.com/download
2.双击提前下载好的OllamaSetup.exe安装包,选择install,然后一直默认安装即可
点击install即可
运行命令
ollama -v

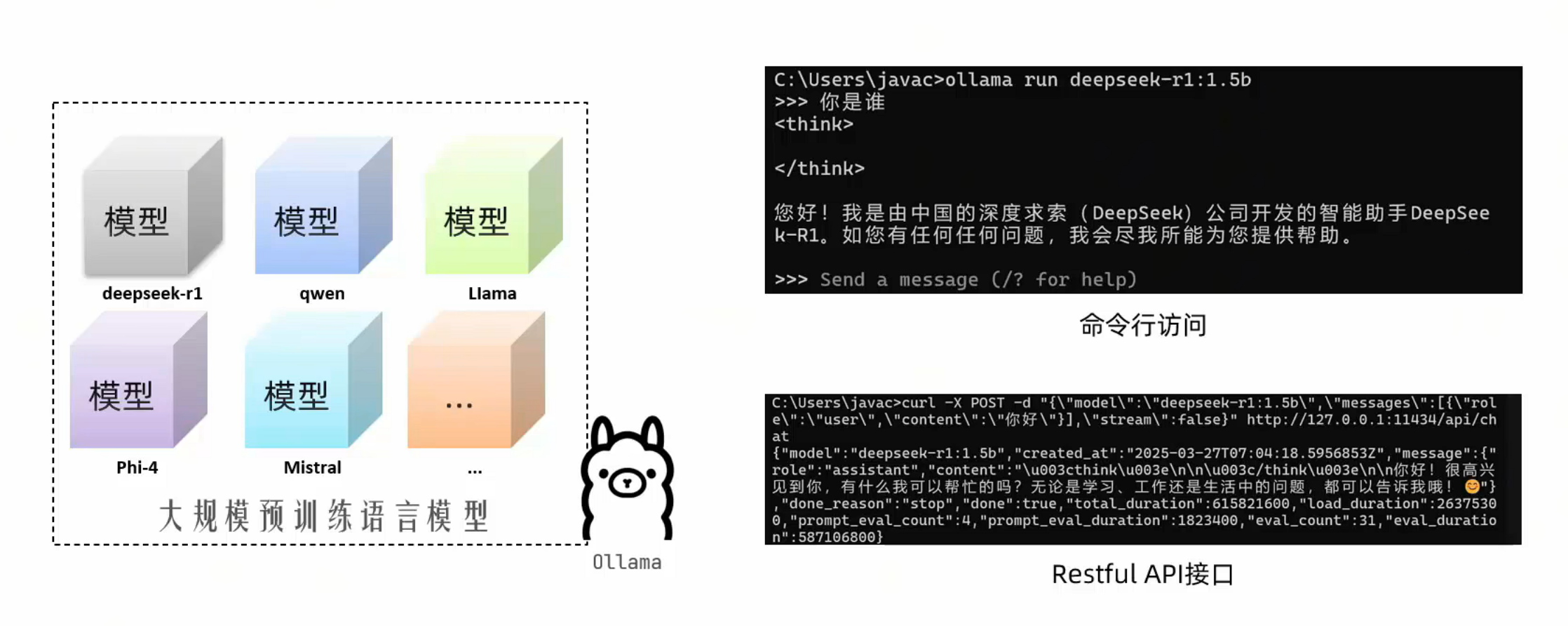
基于window中ollama部署私有大模型
部署deepseek大模型
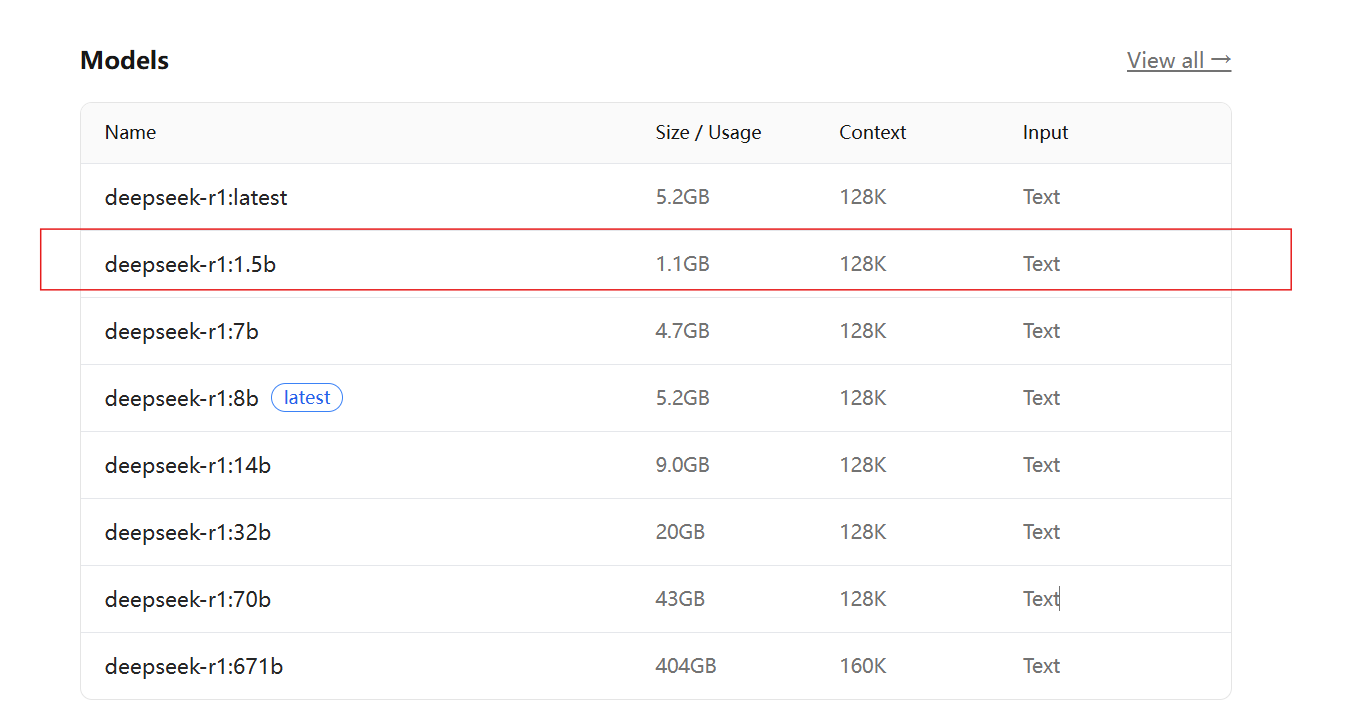
通过https://ollama.com/library查找要使用的模型
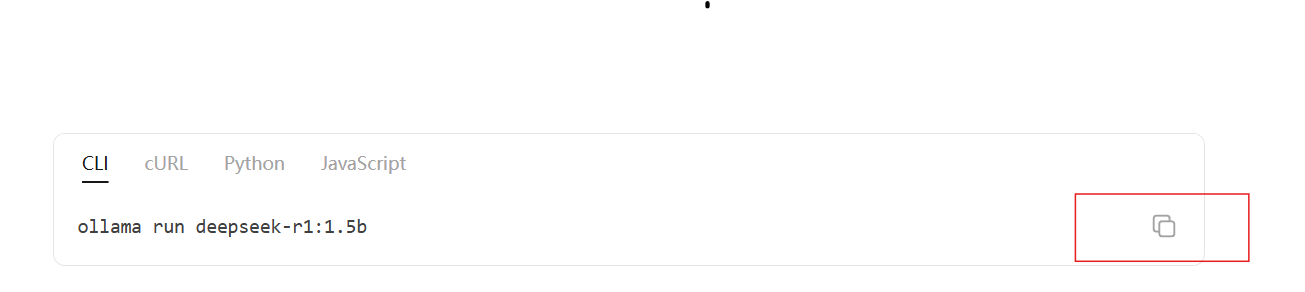
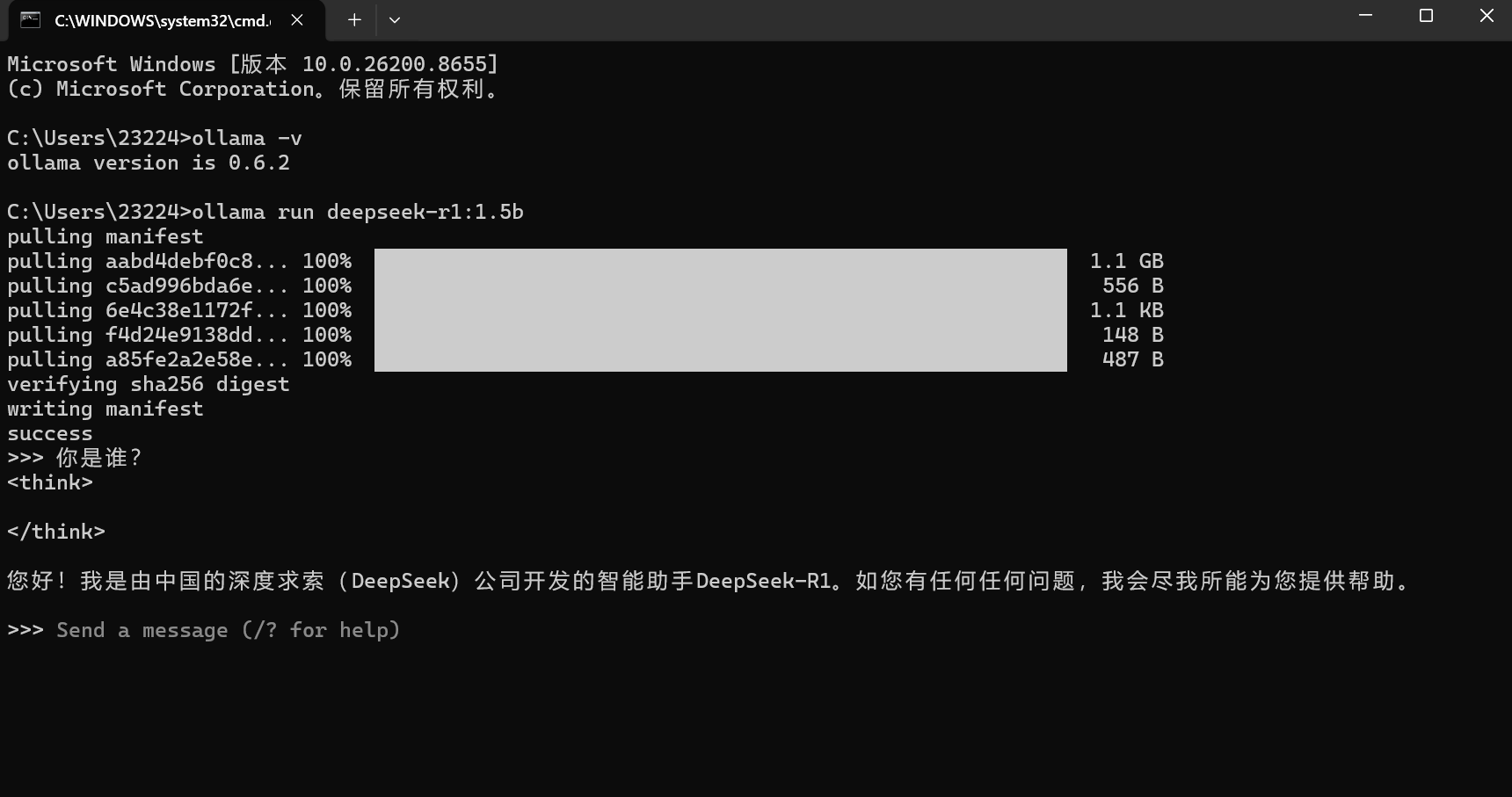
复制命令在终端窗口运行
基于Chatbox部署聊天机器人前端
后端Ollama已经完成,现在需要一个前端方便使用。
基于Chatbox软件,开箱即用,立刻即可构建出私有化聊天机器人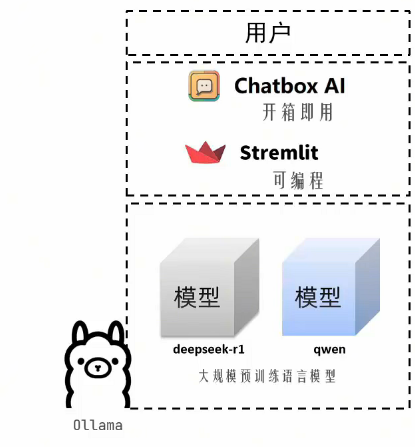
Chatbox是一款基于OpenAI API的开源跨平台智能对话工具,支持Windows、macOS和Linux系统。它旨在为用户提供便捷的AI对话体验,同时具备强大的功能扩展性和灵活性。官网: https://chatboxai.app/zh
Chatbox是一款功能强大、易于使用的开源AI工具,适合开发者、学生、办公人员等多种用户群体。
1.下载安装
访问Chatbox官网,下载并安装适合您操作系统的安装包(Windows、macOS或Linux)
2.配置API
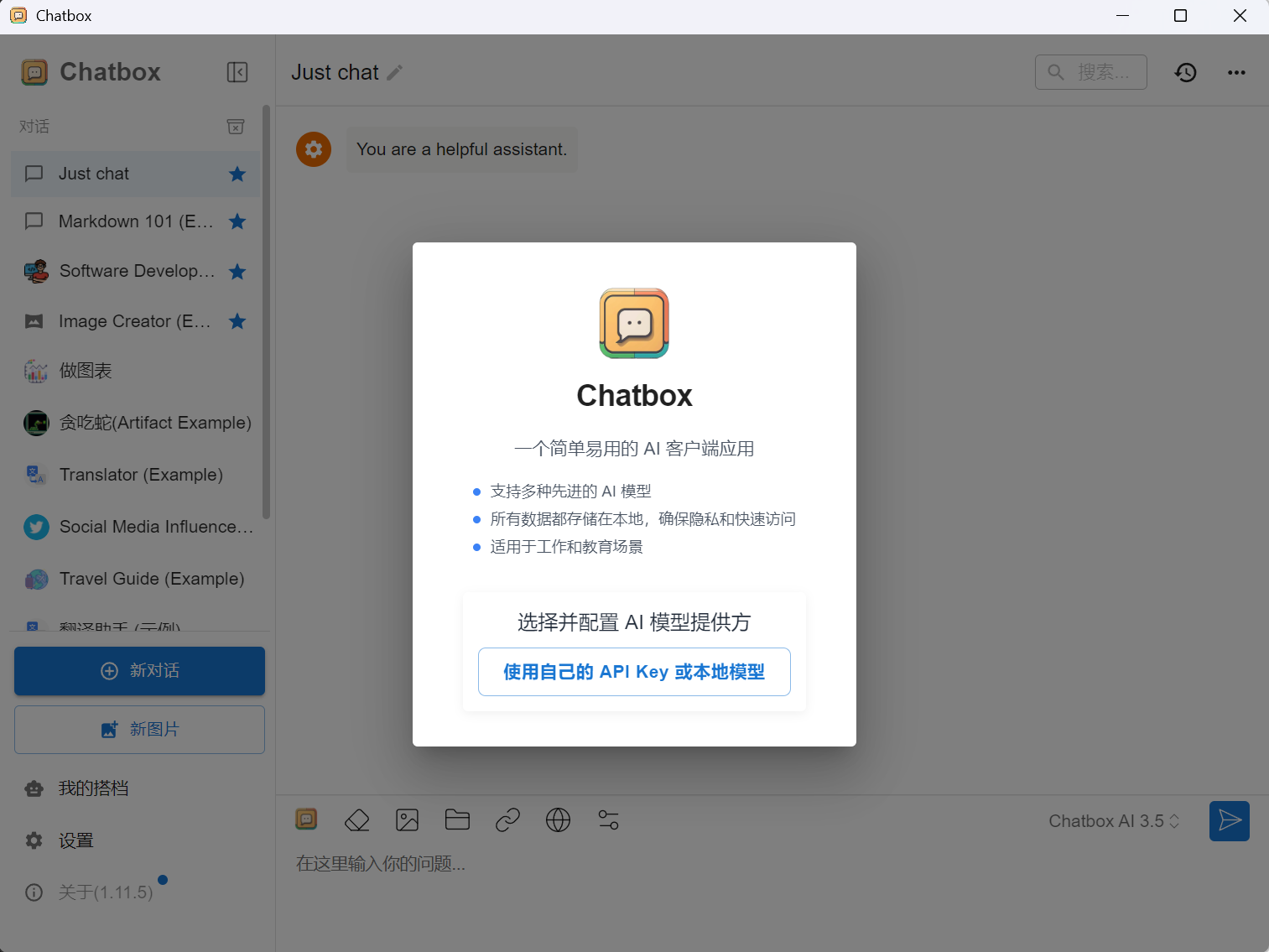
打开Chatbox,进入设置菜单。
选择ollama中本地部署的模型,并保存配置。
3.开始对话
主界面,创建对话窗口,在输入框中输入问题或指令。
4.保存和退出
聊天记录会自动保存到本地。
选择使用本地模型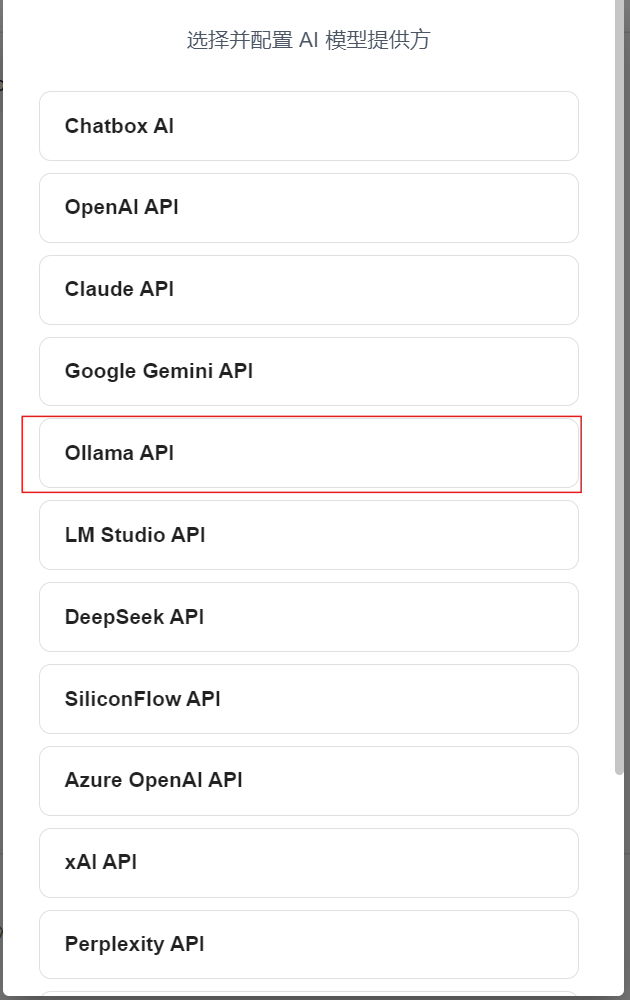
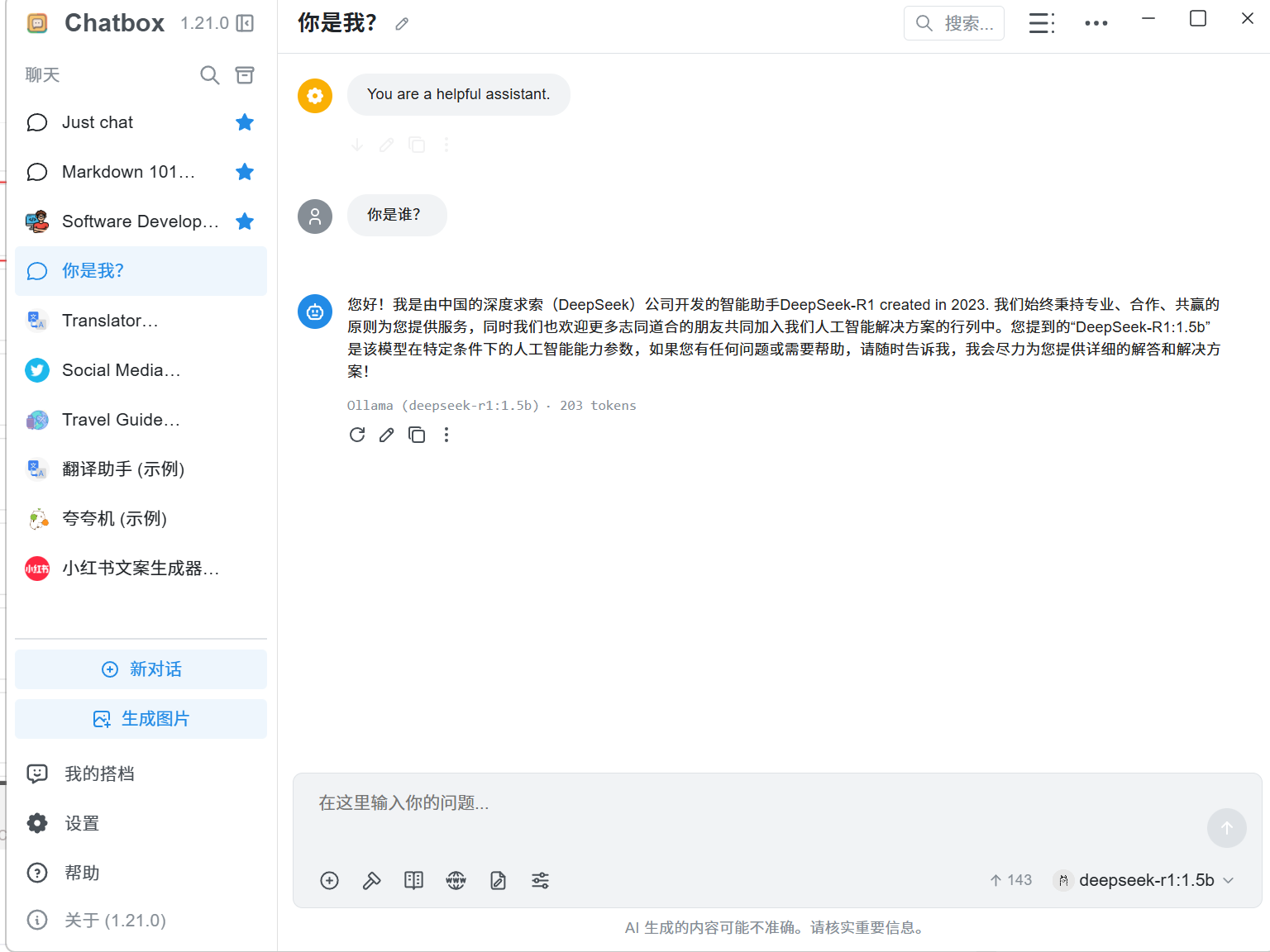
Windows部署WSL(Ubuntu)环境
WSL作为Windows10系统带来的全新特性,正在逐步颠覆开发人员既有的选择。
- 传统方式获取Linux操作系统环境,是安装完整的虚拟机,如VMware
- 使用WSL,可以以非常轻量化的方式,得到Linux系统环境
目前,开发者正在逐步抛弃以虚拟机的形式获取Linux系统环境,而在逐步拥抱WSL环境。
所以,课程也紧跟当下趋势,为同学们讲解如何使用WSL,简单、快捷的获得Linux系统环境。
所以,为什么要用WSL,其实很简单:
- 开发人员都在用,大家都用的,我们也要学习
- 实在是太方便了,简单、好用、轻量化、省内存
WSL:Windows Subsystem for Linux,是用于Windows系统之上的Linux子系统。
作用很简单,可以在Windows系统中获得Linux系统环境,并完全直连计算机硬件,无需通过虚拟机虚拟硬件。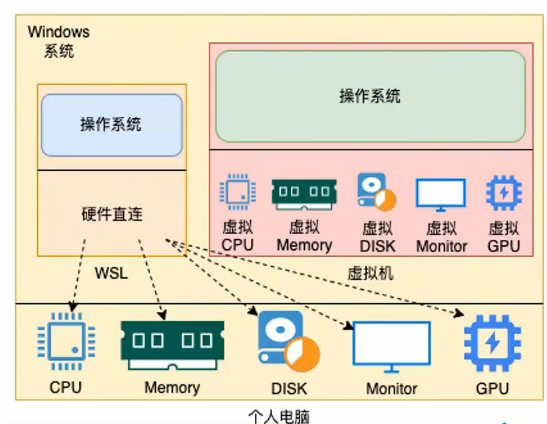
简而言之:
Windows10的WSL功能,可以无需单独虚拟一套硬件设备就可以直接使用主机的物理硬件,构建Linux操作系统
并不会影响Windows系统本身的运行
WSL是Windows10自带功能,需要开启,无需下载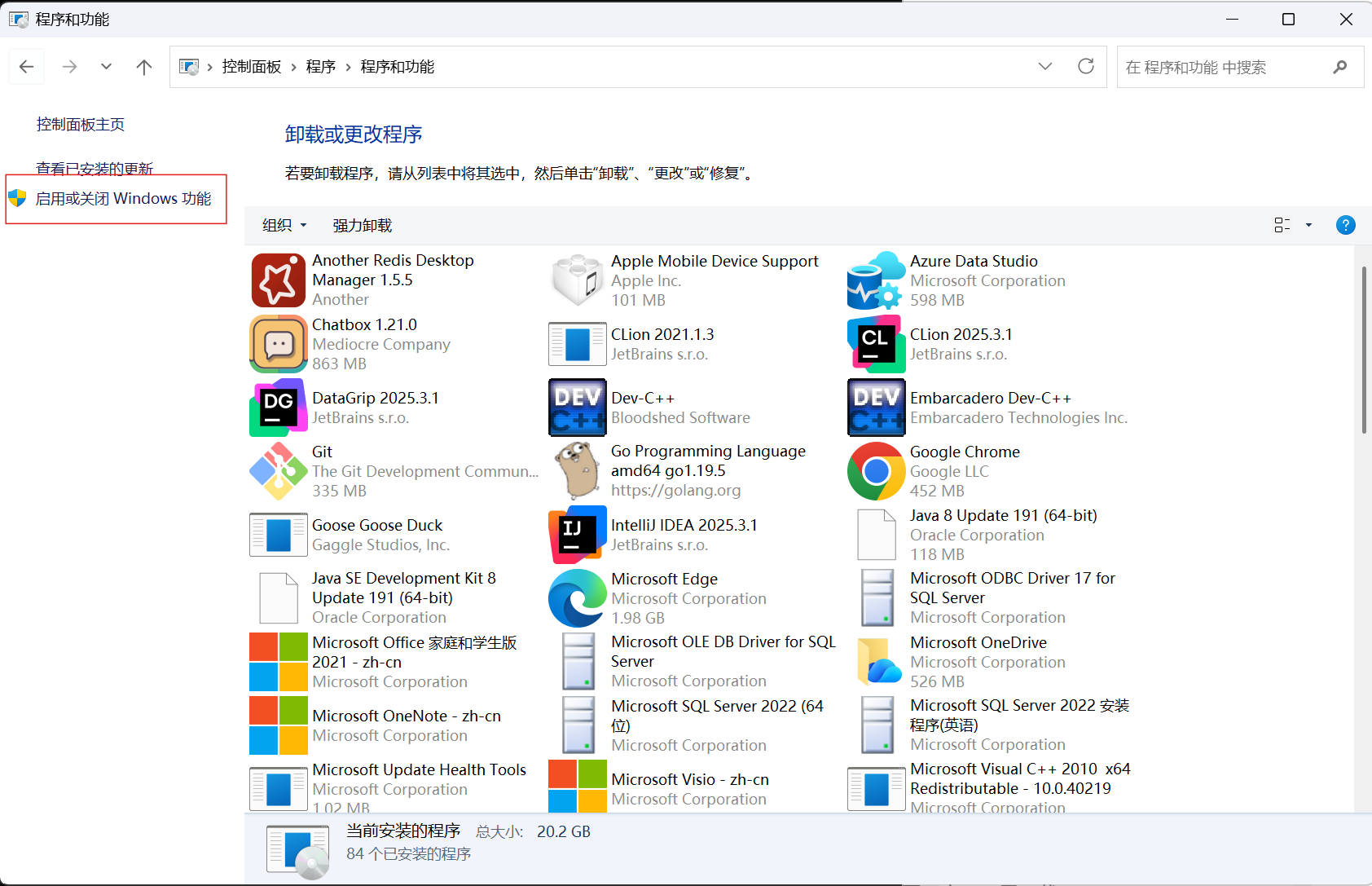
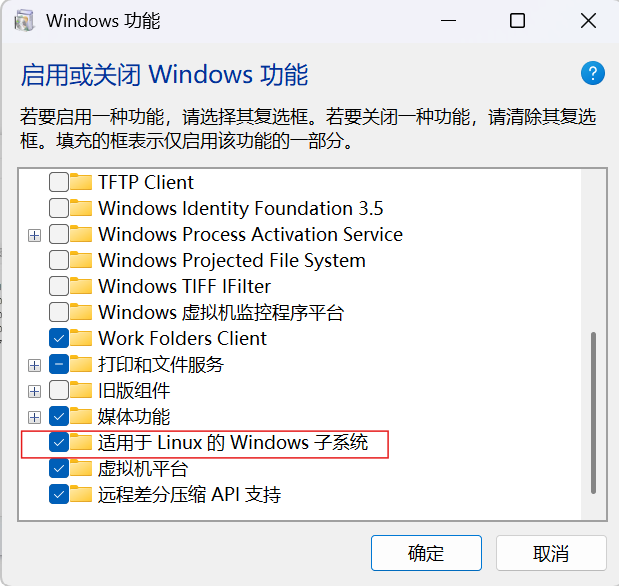
打开Windows应用商店,搜索Ubuntu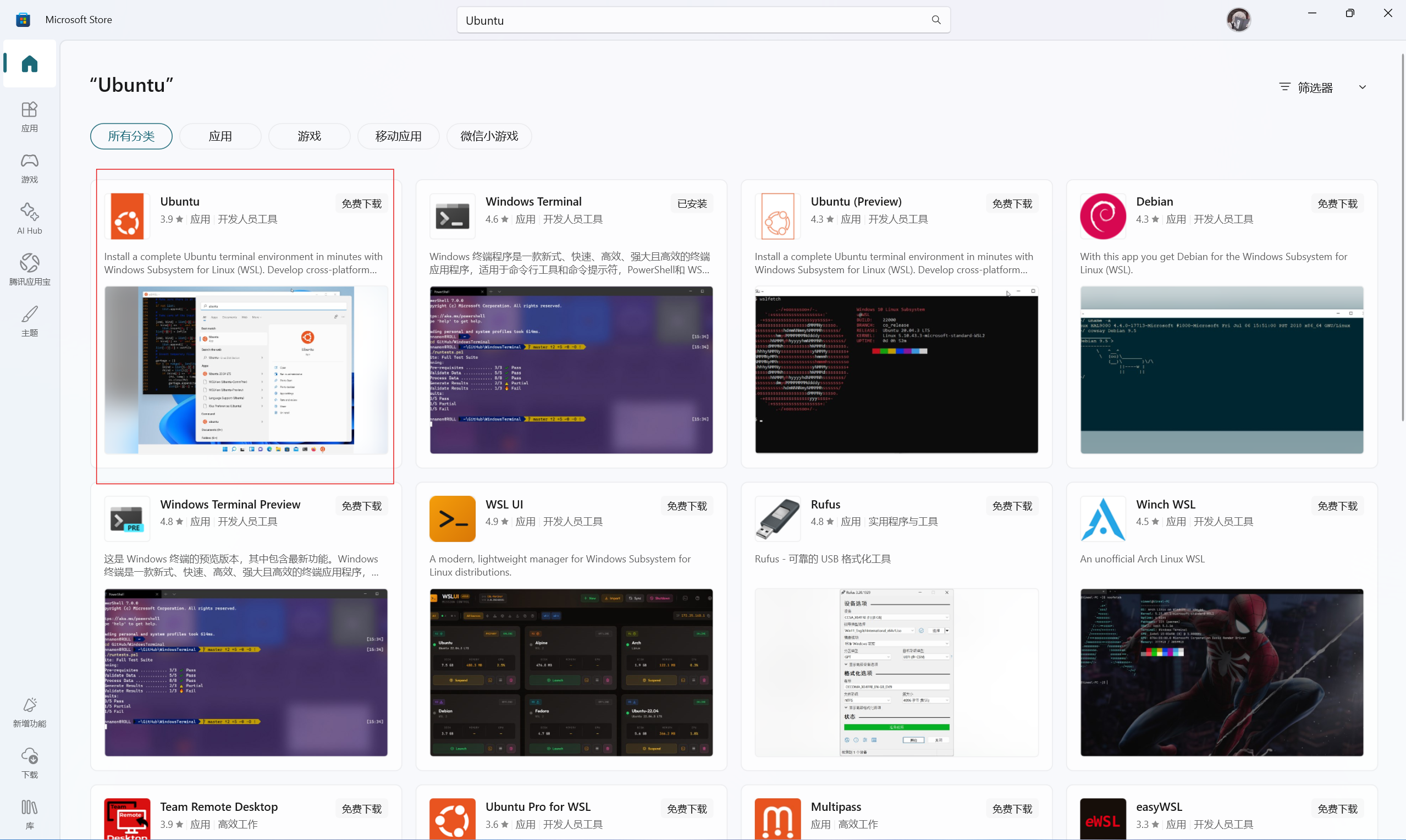
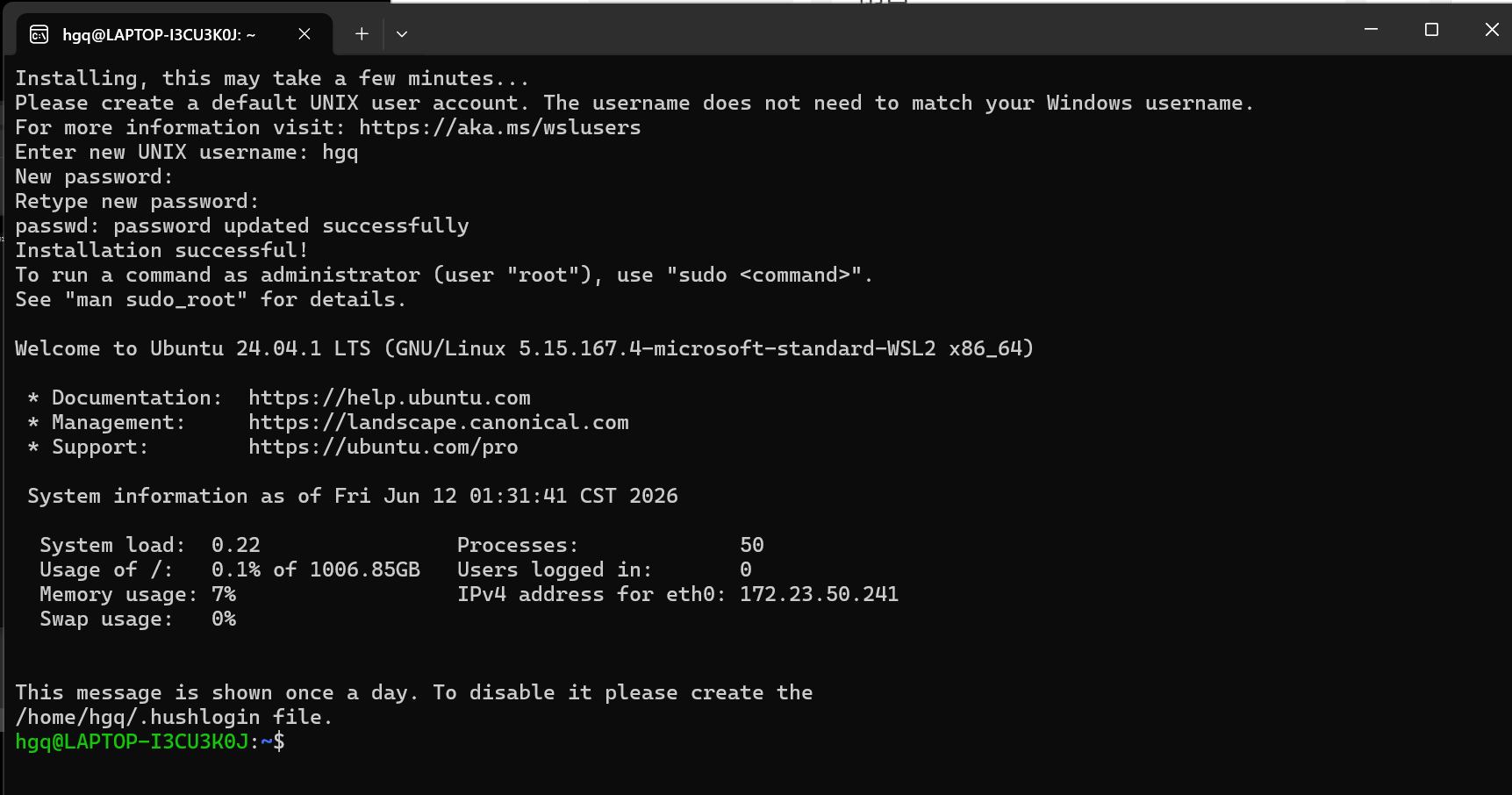
输入用户名用以创建一个用户
输入两次密码确认(注意,输入密码没有反馈,不用理会,正常输入即可)
Ubuntu自带的终端窗口软件不太好用,我们可以使用微软推出的:Windows Terminal软件在应用商店中搜索terminal关键字,找到Windows Terminal软件下载并安装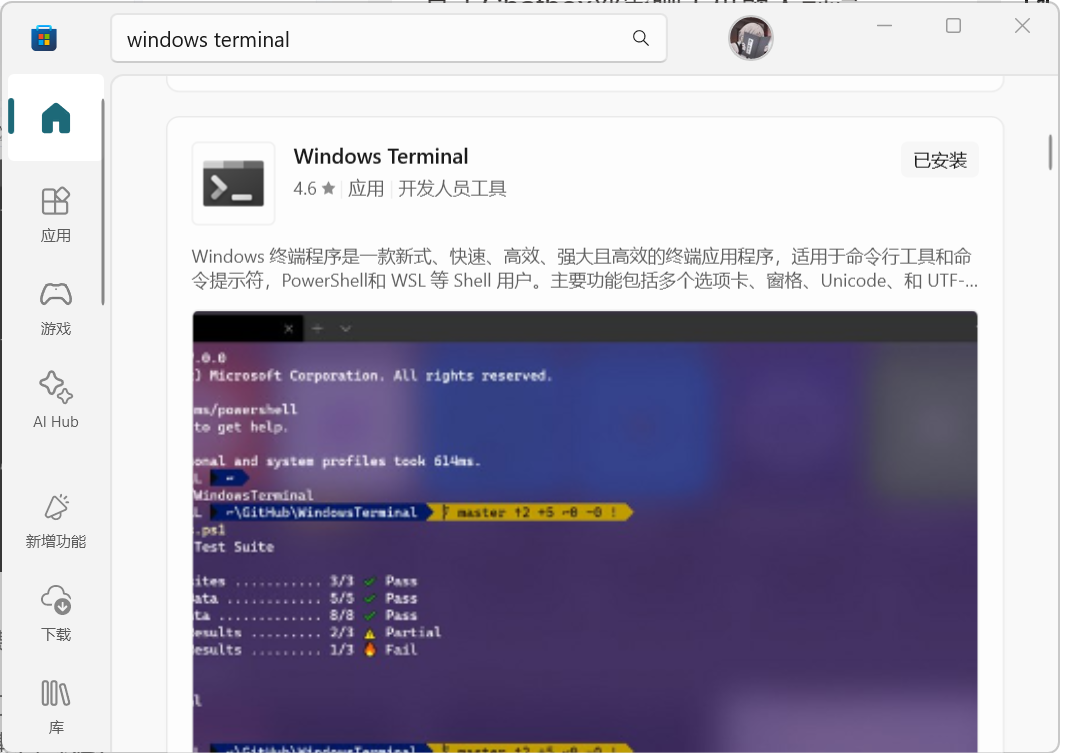
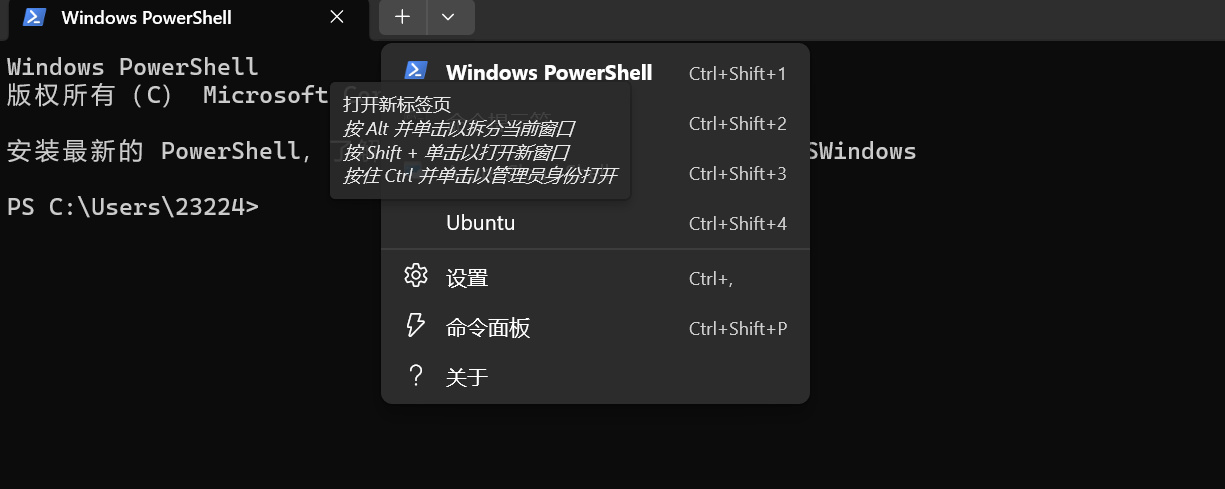
就可以进入Ubuntu
Linux中部署Ollama
CUDA是英伟达(NVIDIA)推出的一种并行计算平台和编程模型。
它允许开发者利用英伟达GPU(图形处理单元)的强大计算能力来加速计算密集型任务,而不仅仅是用于图形渲染。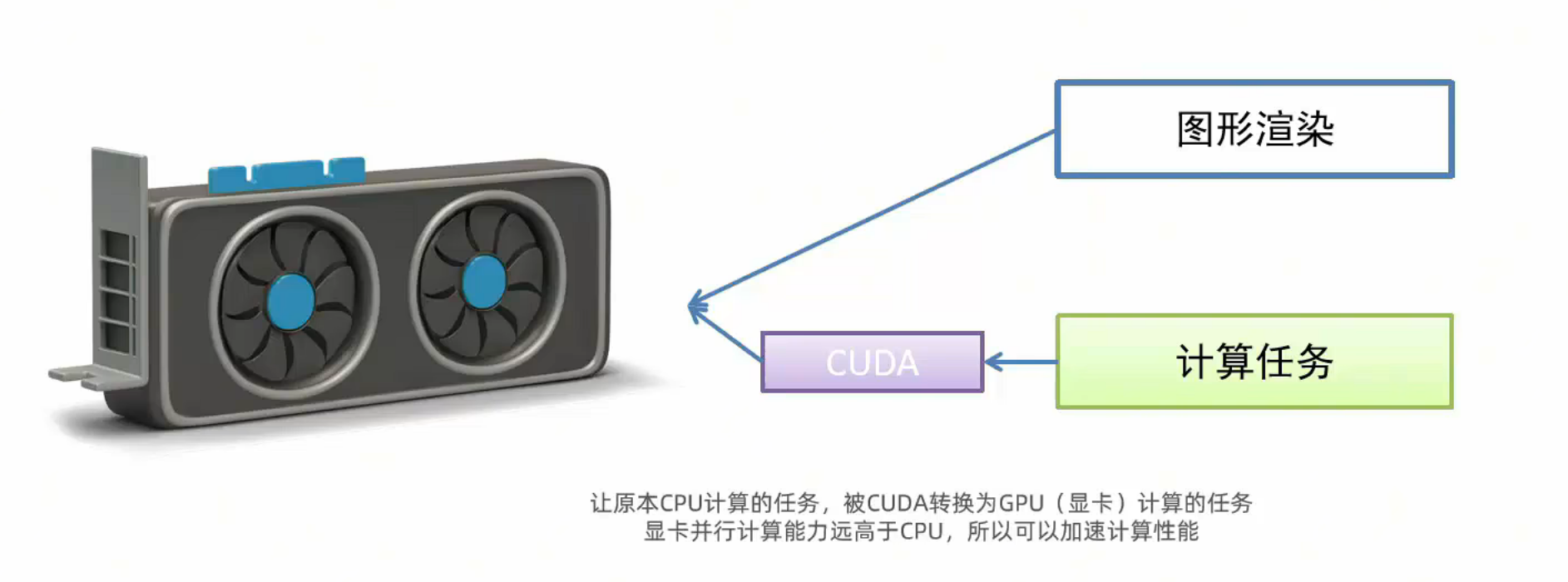
WSL在安装好Ubuntu后,自动安装了显卡驱动以及CUDA,可以通过命令:nvidia-smi验证
打开ollama官网,https://ollama.com/download/linux可以看到,只需要一行命令,即可在Linux系统中部署Ollama

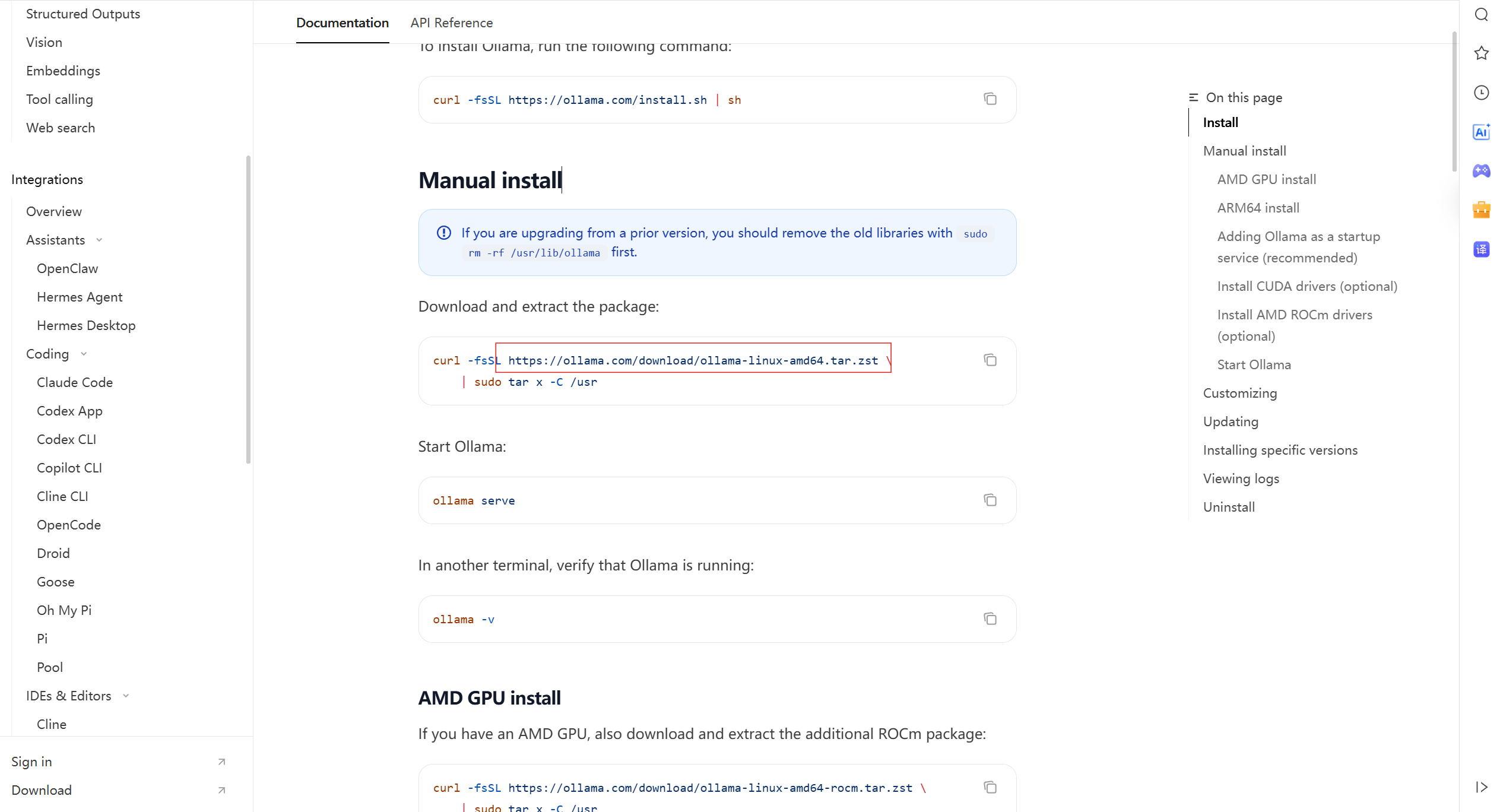
复制到浏览器即可
打开Ubuntu,输入命令cd /mnt,ls之后即可发现windows系统中的磁盘
然后cd到刚下载的安装包的位置

将文件移到home目录下

sudo tar -xvf ollama-linux-amd64.tgz -C /usr
通过上述命令进行解压

此时就能查询到ollama的版本
运行ollama
ollama serve
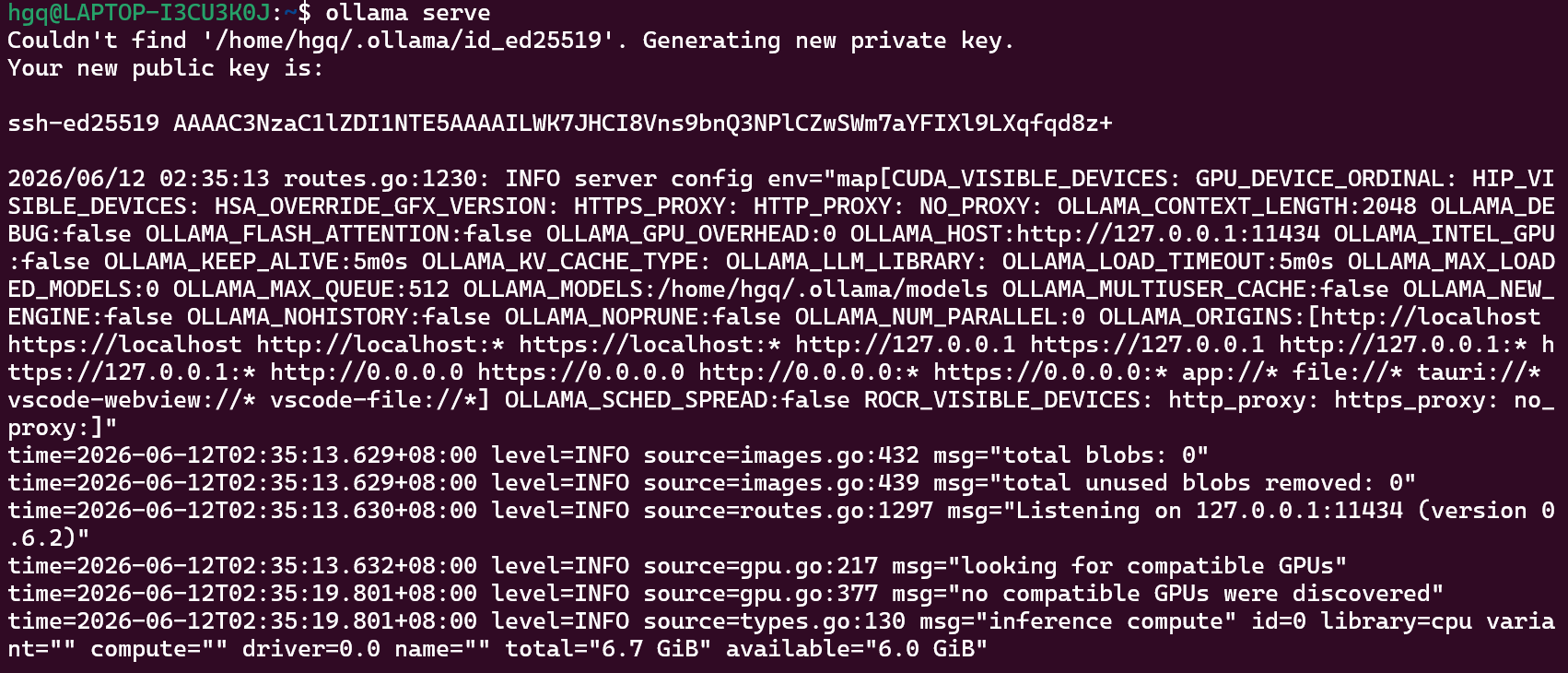
后台启动(推荐)
nohup ollama serve >> ollama.log 2>&1 &
运行模型:
ollama run 模型名称
ollama run deepseek-r1:1.5b
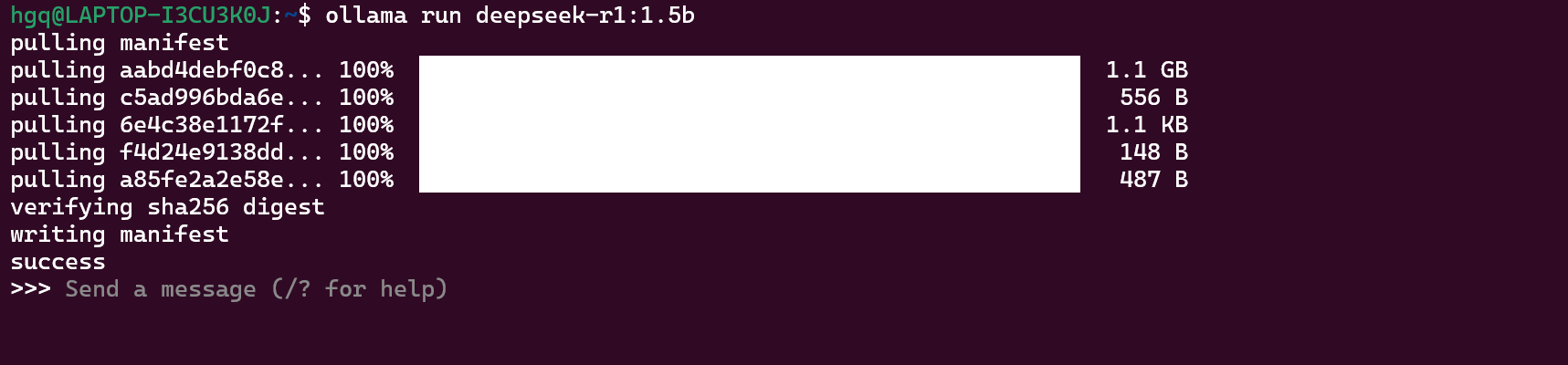
查看本地有那些模型
ollama list

查看当前正在运行的模型
ollama ps
查看模型的详细信息
ollama show 模型名称
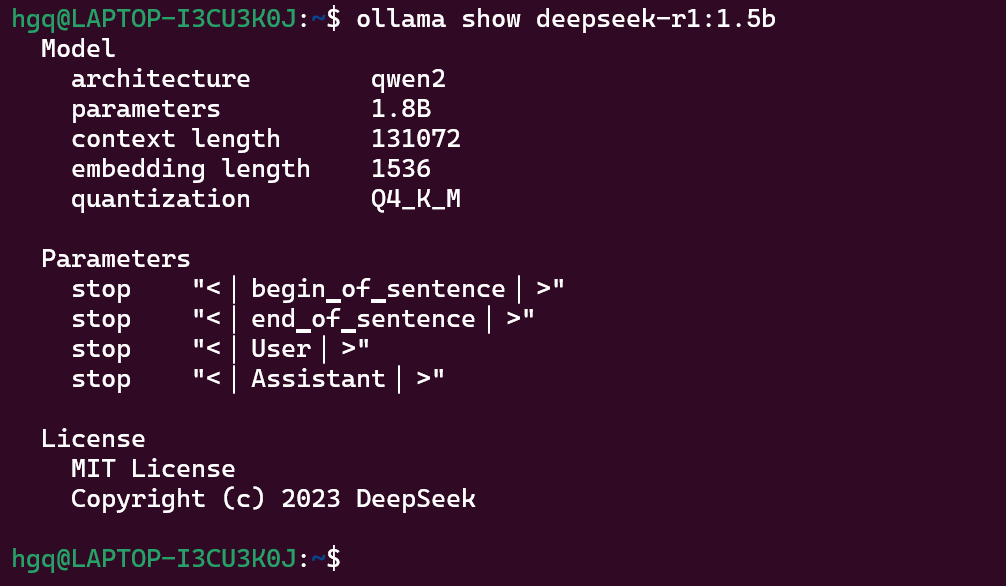
Linux部署Python环境
WSL(Ubuntu)内置了Python(版本3.8),所以无需部署Python,但如果需要编写代码调用Ollama,需要安装Ollama库
- 安装pip工具
sudo apt install python3-pip
2.验证pip的使用
pip-V
注意V是大写字母
3.安装ollama库(用于Python调用Ollama)
pip install ollama
4.安装Streamlit库(用于Python开发对话页面)
pip install streamlit
在Ubuntu系统上使用pip install ollama时出现错误"externally-managed-environment",提示外部管理环境。
使用虚拟环境安装
# 创建虚拟环境(可放在任意目录,比如 ~/ollama-env)
python3 -m venv ~/ollama-env
# 激活虚拟环境
source ~/ollama-env/bin/activate
# 在虚拟环境中安装 ollama
pip install ollama
激活后,你的命令行提示符会显示 (ollama-env)。之后运行 Python 脚本时也需在激活状态下执行。
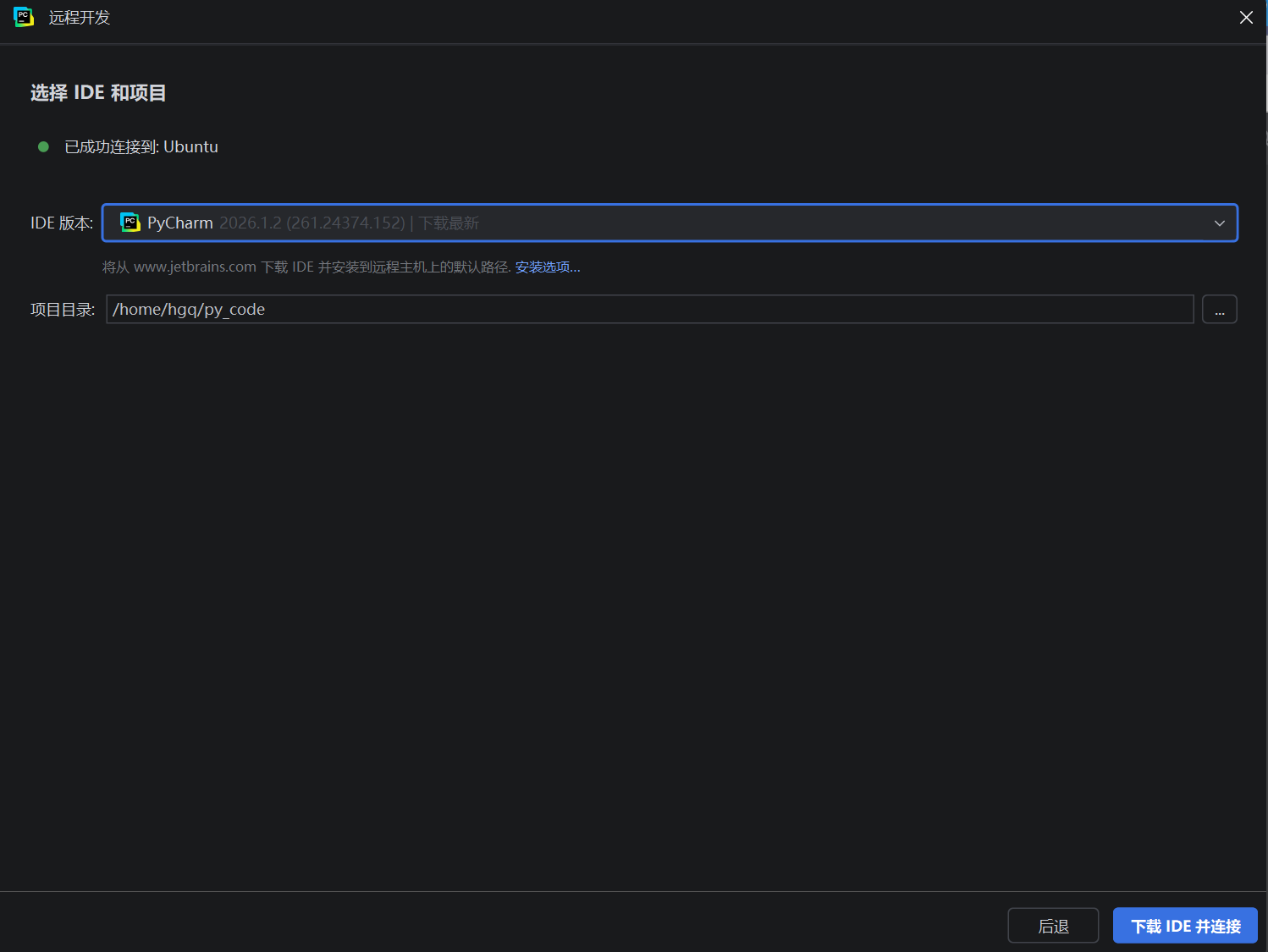
PyCharm连WSL(Ubuntu)
IDE PyCharm内置WSL的支持,可以将Python解释器程序直接连接到WSL内。实现:用Windows的PyCharm,在Linux上写代码,并在Linux上运行。创建一个基于WSL的PyCharm工程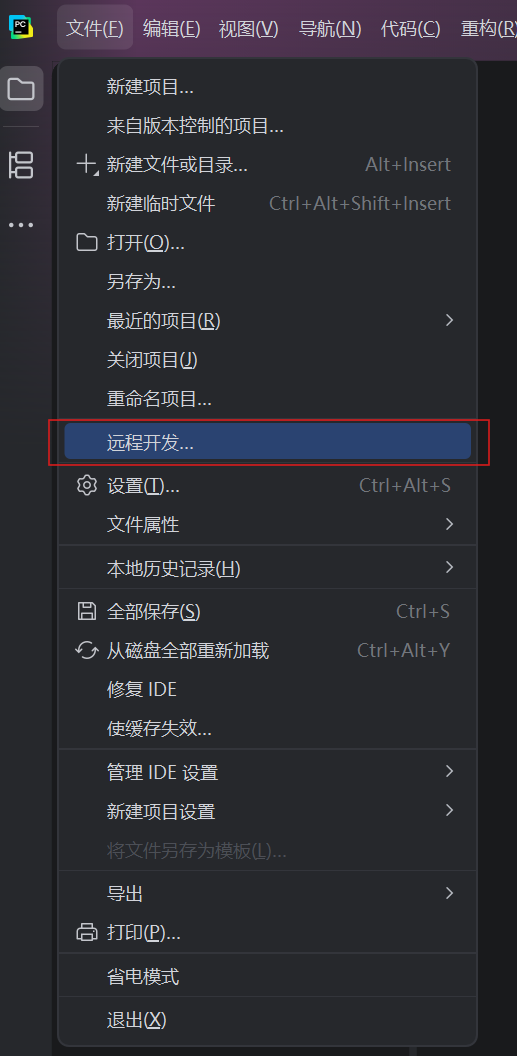
选择WSL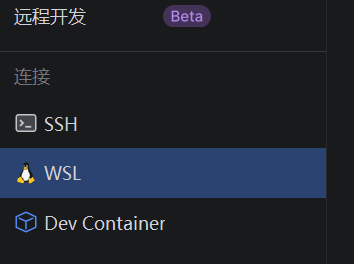
选择添加新的解释器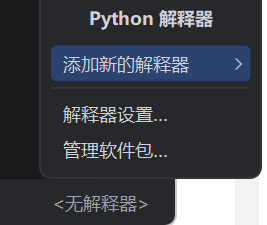
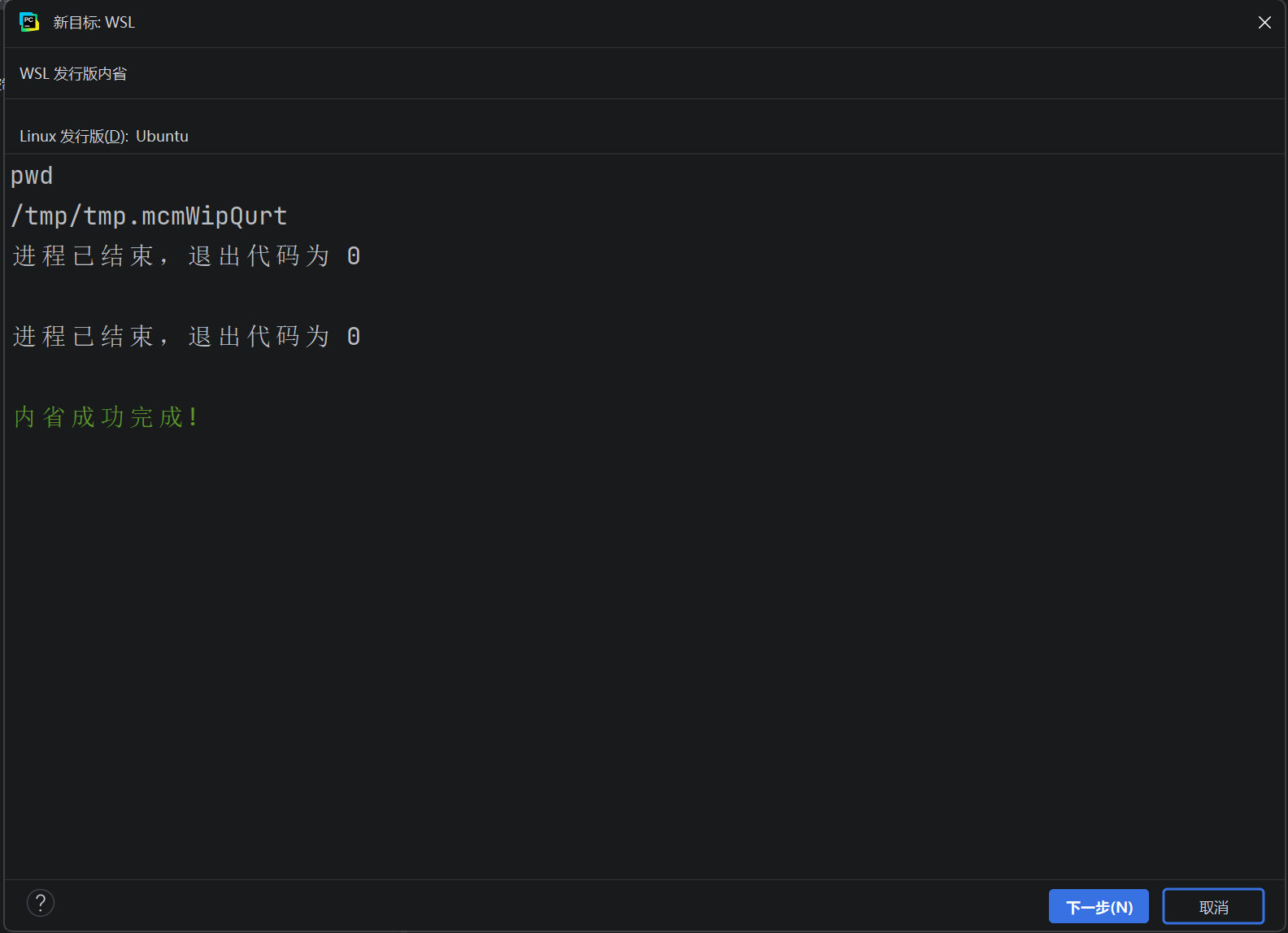
选择现有的虚拟环境中的解释器,位置在~/ollama-env/bin/python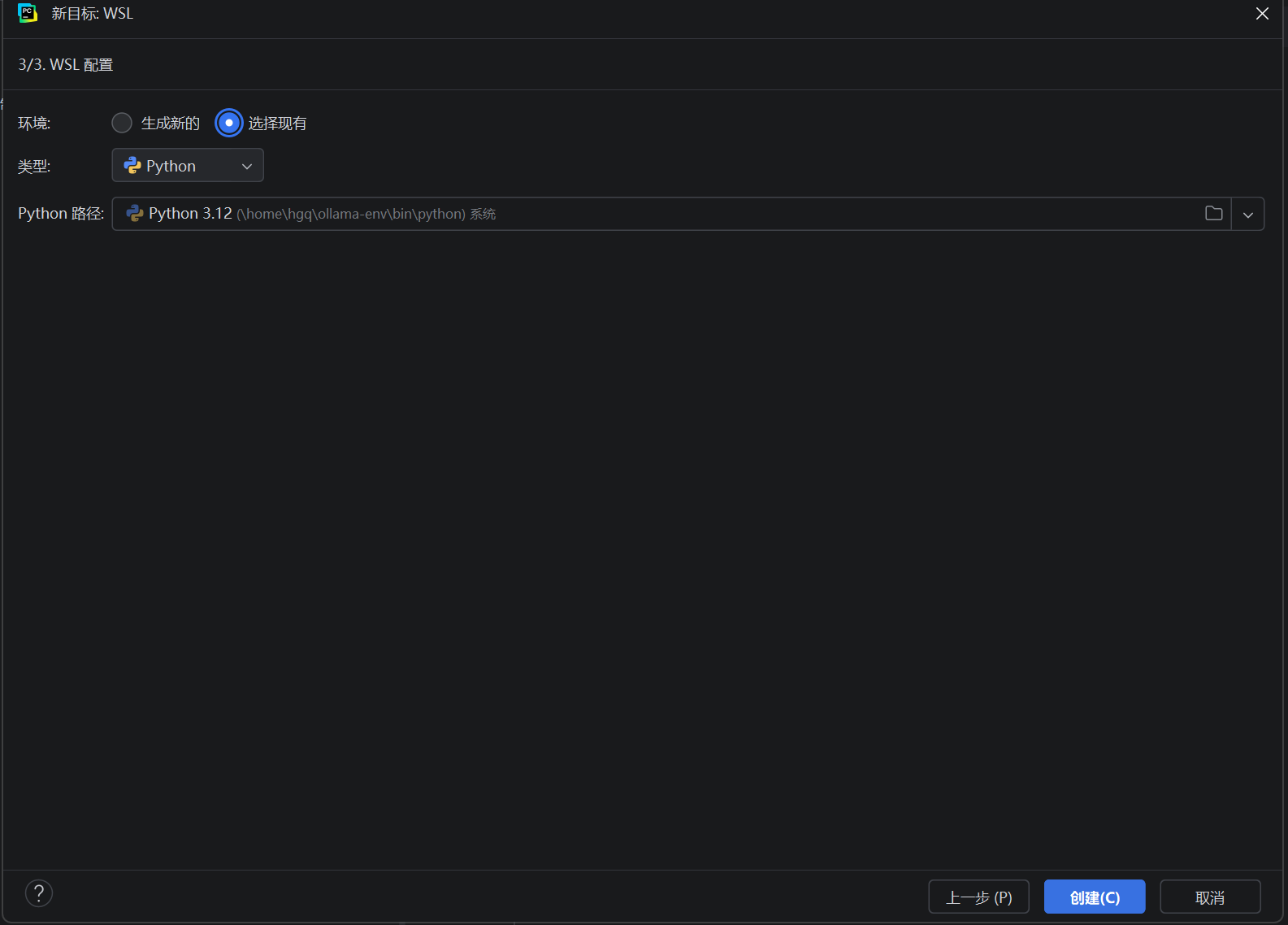
import ollama
import streamlit
print(f"ollama当前可用的模型为:{ollama.list()}")
print(f"streamlit库的版本为:{streamlit.__version__}")
运行结果为:
ollama当前可用的模型为:models=[Model(model='deepseek-r1:1.5b', modified_at=datetime.datetime(2026, 6, 12, 2, 43, 35, 980789, tzinfo=TzInfo(28800)), digest='e0979632db5a88d1a53884cb2a941772d10ff5d055aabaa6801c4e36f3a6c2d7', size=1117322768, details=ModelDetails(parent_model='', format='gguf', family='qwen2', families=['qwen2'], parameter_size='1.8B', quantization_level='Q4_K_M'))]
streamlit库的版本为:1.58.0
Ollama Python库API
首先确认Ollama已经启动(sudo systemctl start ollama)使用Python操作Ollama,最主要的一步是获得Ollama客户端对象,使用如下代码
import ollama
client = ollama.Client(host='http://localhost:11434')
当有了client对象后,可以使用client对象提供的方法,完成对Ollama的操作
client对象提供的操作API有
1.list方法,列出可用模型
clent.list()
2.show 方法,显示指定模型的详细信息
client.show('deepseek-r1:7b')
3.ps方法,显示当前正在运行的模型
client.ps()
4.chat方法,与模型进行对话
reponse = client.chat(model='deepseek-r1:1.5b',messages=[{'role':'user', 'content': '你是谁'}])
print(reponse['message']['content'])

Streamlit入门
Streamlit的基础API使用
Streamlit是一个开源Python库。它旨在让数据科学家和工程师能够以最少的代码和配置,将他们的数据分析和模型展示转化为交互式的Web应用。Streamlit的设计目标是简单易用,同时保持高度的灵活性和可定制性。
官网地址:https://streamlit.io
Streamlit自带了一个示例程序,我们可以执行:streamlit hello 启动
执行后输入一个Email地址即可,会自动打开浏览器,如下: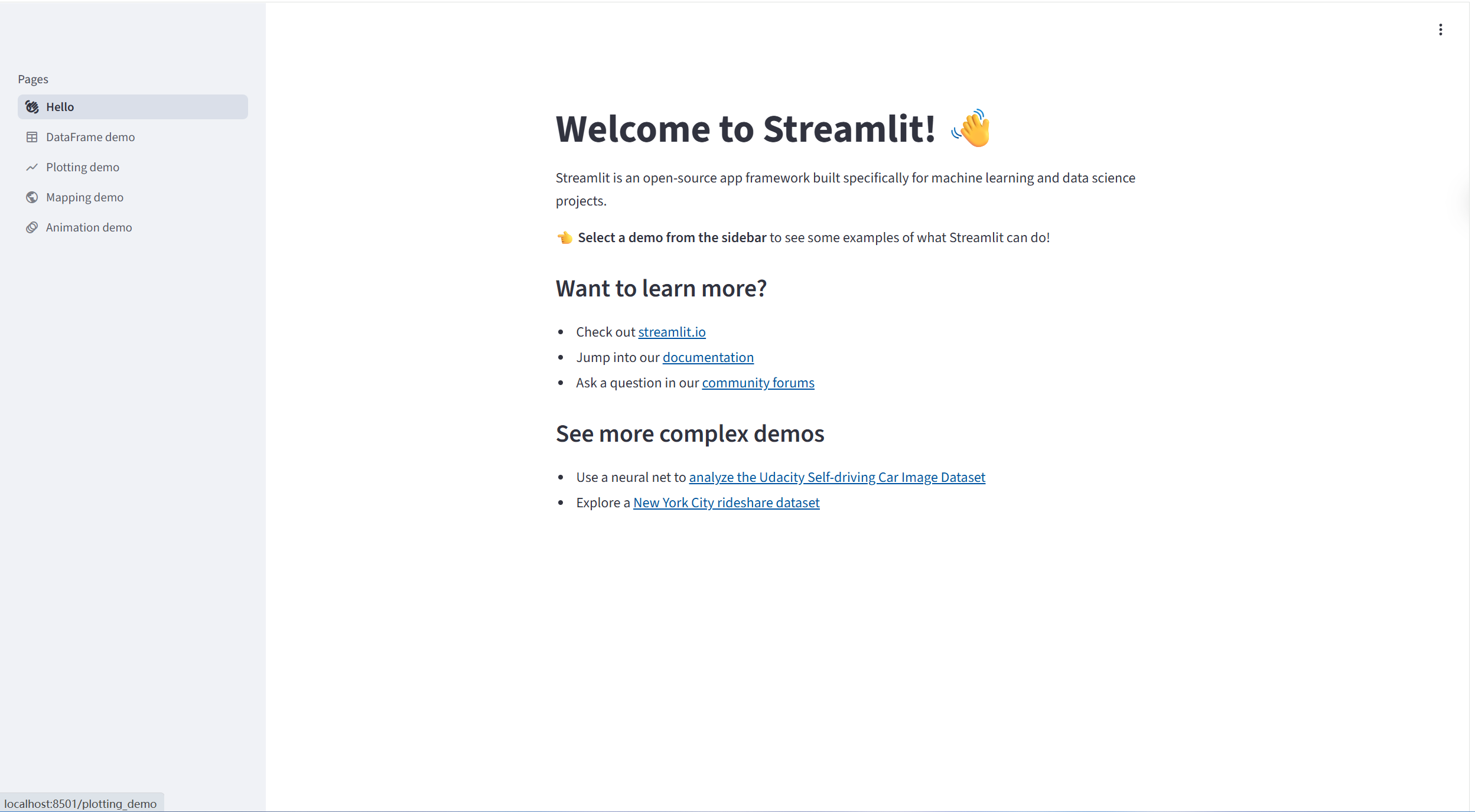
导包
import streamlit as st
标题
使用st.title()可以设置标题内容。
st.title('Test标题')

段落write
段落就是HTML里的< p >元素,在 streamlit 里使用 st.write(‘内容’)的方式去书写。
import streamlit as st
st.write('hello world')

分割线
分隔线就是HTML里的< hr >。在 streamlit 里使用st.divider() 方法绘制分隔线。
import streamlit as st
st.divider()

聊天输入框
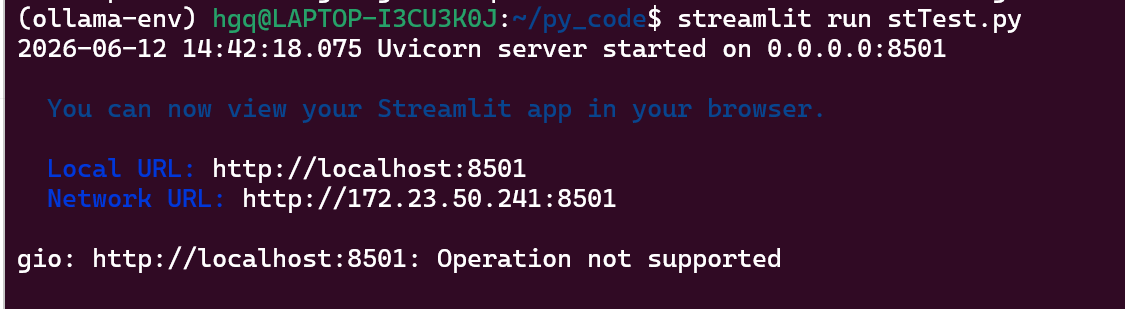
聊天输入框使用 st.chat_input() 渲染。
name=st.chat_input('请输入你的名字:')
if name:
st.write(f"你好,你的名字是{name}")
等待提示框
在需要等待的场景中,给出等待提示和动画
使用 st.spinner()
with st.spinner("思考中..."):
time.sleep(3)
st.write("思考完成.")

消息容器
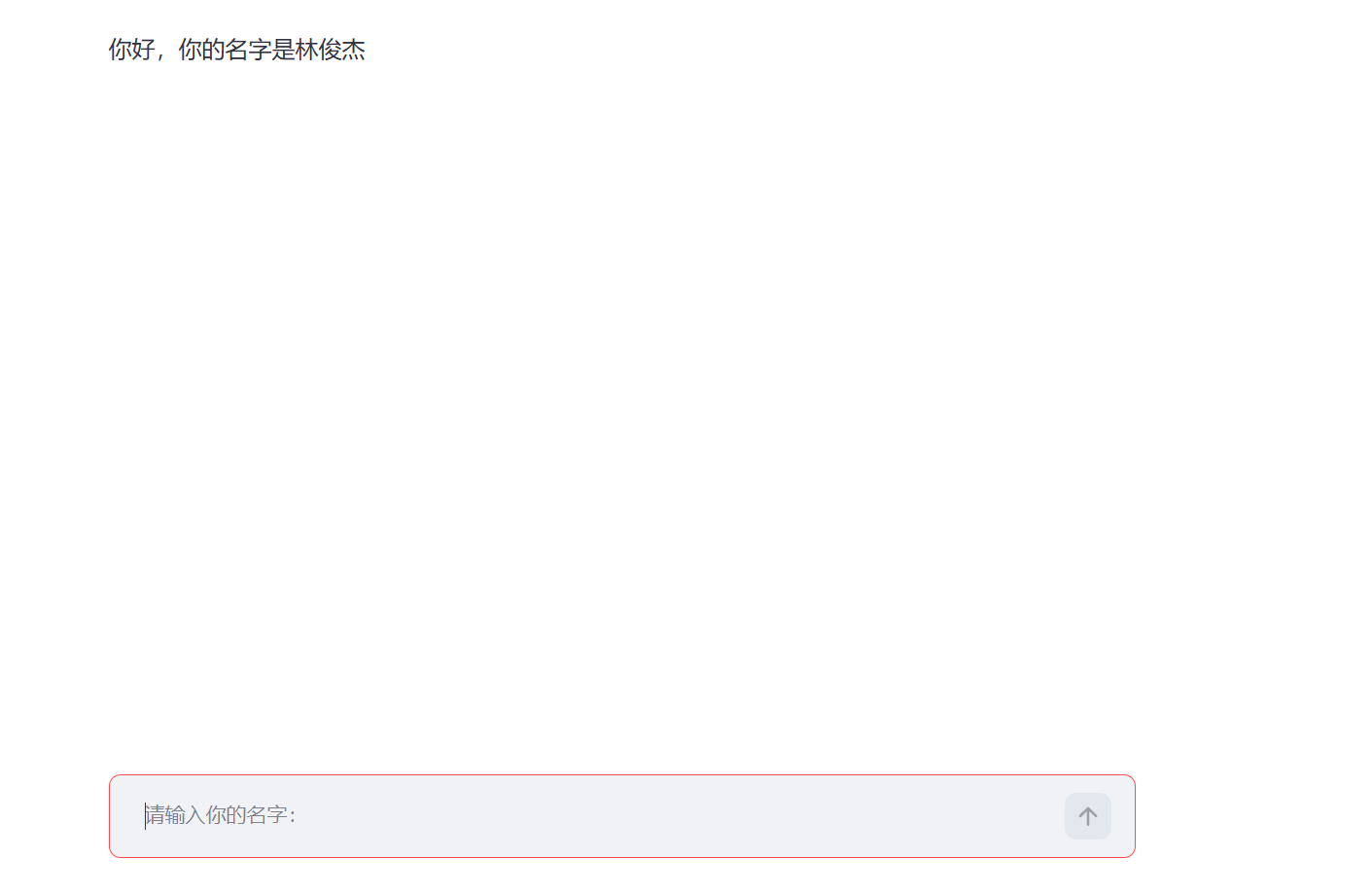
可以创建消息容器,容纳文本信息,使用 st.chat_message()
# chat_message需要传入角色,可用:user、assistant、ai、human
#每一个角色对应不同的聊天背景色和图标
st.chat_message('user').markdown('用户')
st.chat_message('assistant').markdown('我是智能聊天机器人')
#markdown表示以markdown格式在容器内渲染信息
Streamlit开发对话网页
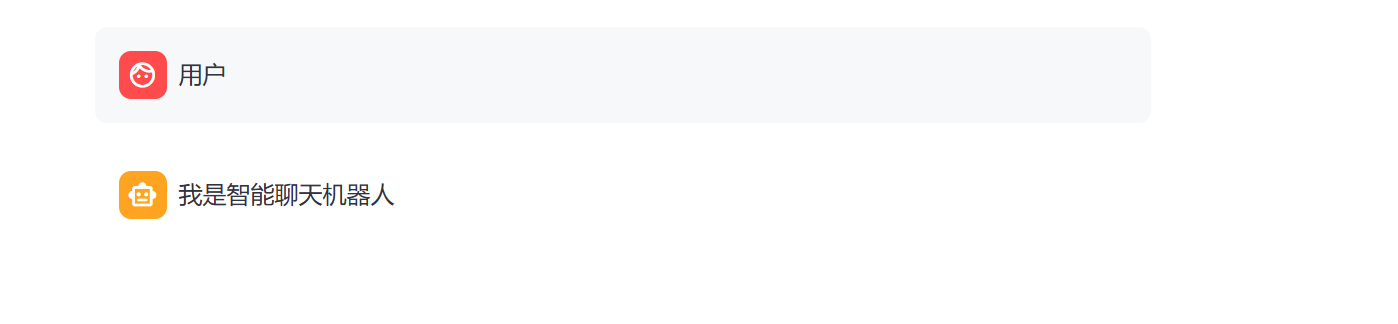
掌握了基础API后,现在可以开发一个基础的对话网页了
如图所示,可以完成多轮对话
用户可以提问
也可以输出回答(固定回答,后续替换为大模型回答)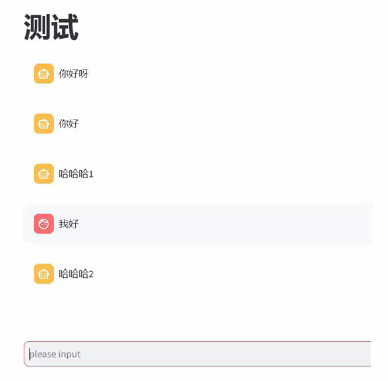
import streamlit as st
# 标题
st.title("测试")
# 分割线
st.divider()
# 消息输入框
prompt = st.chat_input("请输入你的问题:")
# 消息容器
if prompt:
# user表示用户提问 assistant表示ai回答
st.chat_message("user").markdown(prompt)
# AI回答
st.chat_message("assistant").markdown("思考中")
实现效果: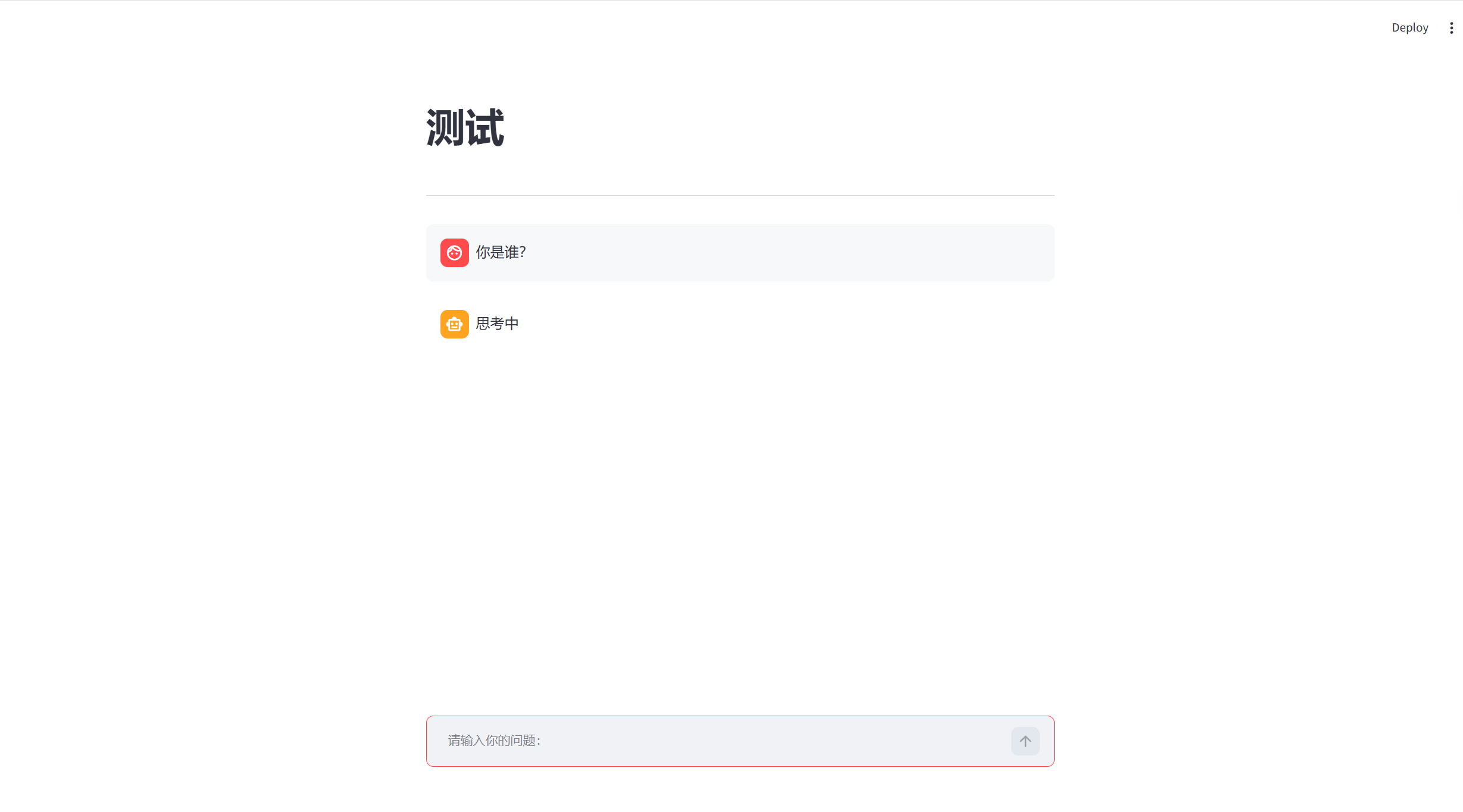
Streamlit session_state的使用
Streamlit本质是无限循环执行用户代码。如果要保存上下文状态,可以使用Streamlit的session_state
session_state是一个字典,基于Key-Value形式,可以保存任意用户所需的内容
状态保存
session_state以Key-Value模式保存用户所需内容
#存入
st.session_state['you_key']= "value"
#取出
st.session_state['you_key']
import time
import streamlit as st
if "count" not in st.session_state:
st.session_state["count"] = 1
if "message" not in st.session_state:
st.session_state["message"] = []
# 标题
st.title("测试")
# 分割线
st.divider()
# 消息输入框
prompt = st.chat_input("请输入你的问题:")
# 1. 角色 2. 消息 [{"role": "user/assistant", "content":"xxx"}]
if prompt:
st.session_state["message"].apend({"role": "user",
"content": prompt})
for message in st.session_state["message"]:
st.chat_message(message["role"]).markdown(message["content"])
with st.spinner("思考中"):
time.sleep(2)
response = f"不会回答{st.session_state["count"]}"
# 把ai回答放到历史记录中
st.session_state["message"].apend({"role": "assistant",
"content": response})
st.session_state["count"] += 1
# 把ai回答渲染到界面中
st.chat_message("assistant").markdown(response)
- 用户输入消息 → 先存到历史记录
- 把所有历史记录(包括刚发的用户消息)重新渲染到页面上(因为Streamlit每次重跑会清空页面,所以需要重绘所有历史,避免聊天记录丢失)
- 显示加载动画,暂停2秒模拟思考
- 生成固定回复,存入历史记录,计数器+1
- 渲染AI的回复到页面上
演示效果: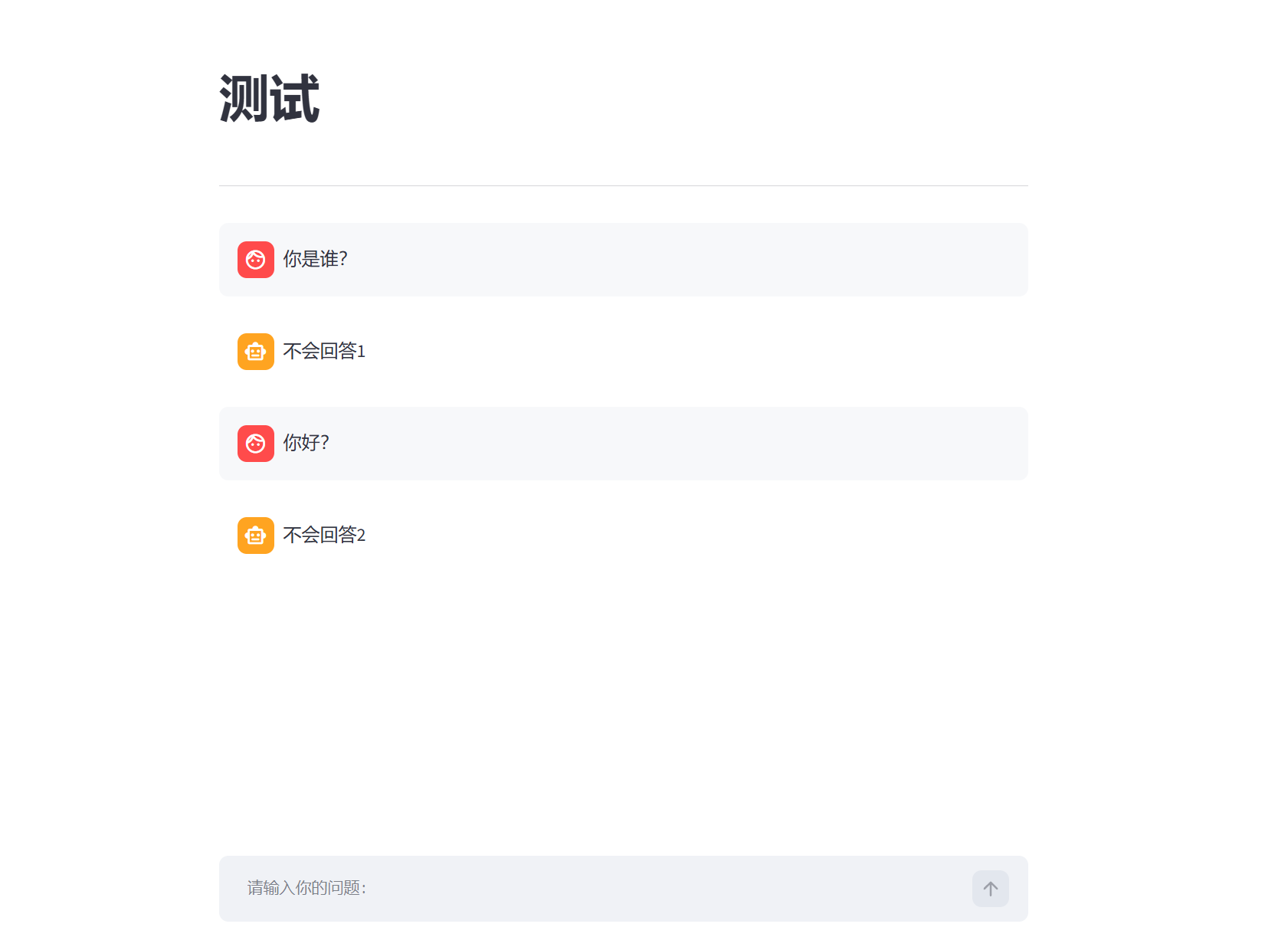
Ollama&Streamlit智聊机器人
import time
import ollama
import streamlit as st
# ollama 获取客户端
client = ollama.Client(host="http://localhost:11434")
# 初始化消息记录
if "message" not in st.session_state:
st.session_state["message"] = []
# 添加标题
st.title("智聊机器人")
st.divider()
# 用户输入问题
prompt = st.chat_input("请输入问题")
# 用户输入内容则开始工作
if prompt:
# 将用户提问添加到历史记录中
st.session_state["message"].append({"role": "user", "content": prompt})
# 将历史消息全部输入到消息容器中去
for message in st.session_state["message"]:
st.chat_message(message['role']).markdown(message['content'])
with st.spinner("AI思考中"):
response = client.chat(
model="deepseek-r1:1.5b",
messages=[{"role": 'user', "content": prompt}]
)
# 从response中取出来message和content两个key
st.session_state['message'].append({"role": 'assistant', 'content': response['message']['content']})
# 在页面中渲染ai回答
st.chat_message("assistant").markdown(response['message']['content'])
遍历 st.session_state[“message”] 中所有的历史消息。
st.chat_message(role) 创建一个对话气泡容器,role 可以是 “user” 或 “assistant”,Streamlit 会自动分配不同的样式(用户消息靠右,AI 消息靠左)。
在气泡内调用 .markdown(content) 显示消息内容(支持 Markdown 格式)。
st.spinner 会在模型推理期间显示一个加载动画和提示文字 “AI思考中”。
client.chat 向 Ollama 服务发送请求:
- model=“deepseek-r1:1.5b”:指定使用该模型(需已通过 ollama pull deepseek-r1:1.5b 下载)。
- messages:对话上下文,这里只传入了当前用户问题(没有使用完整历史记录,不过 Ollama 本身会维护会话状态?不,这里每次只传当前问题,所以模型是无状态的,每个回答只依赖当前输入,不依赖之前对话。如果要连续对话,需要把 st.session_state[“message”] 中所有消息都传给 messages 参数)。
展示结果如下: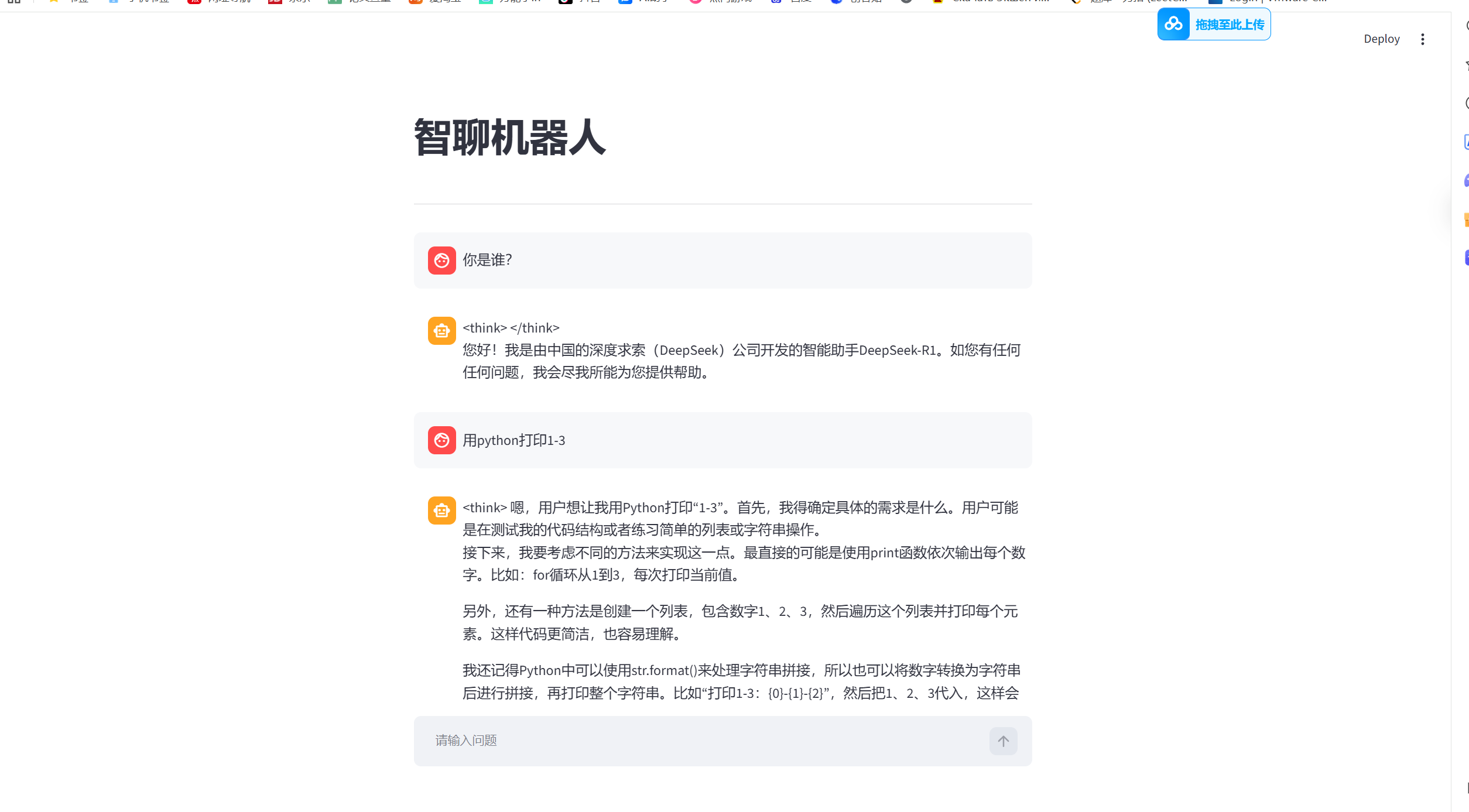
LangChain
云上大模型架构
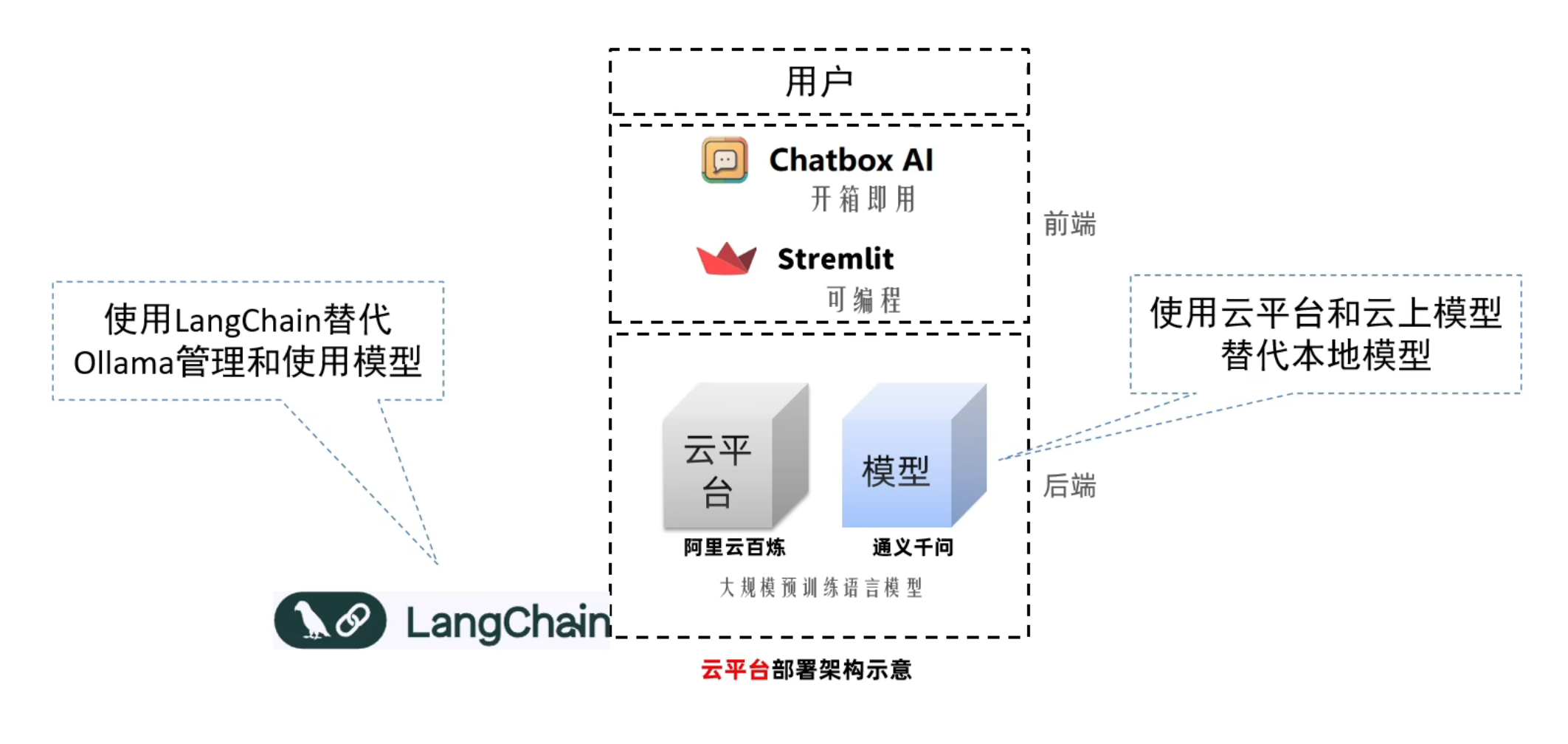
使用阿里云平台提供的云上模型构建聊天机器人,在技术架构上,主要的改动有:
- 使用LangChain框架代替Ollama,完成对模型的管理和使用,用基于LangChain提供Python调用支持
- 使用阿里云百炼平台的通义千问系列模型,提供云上
的模型算力支持 - 前端不变,继续使用Streamlit原有代码即可
LangChain简介
LangChain由Harrison Chase 创建于2022年10月,它是围绕LLMs(大语言模型)建立的一个框架.
LangChain自身并不开发LLMs,它的核心理念是为各种LLMs实现通用的接口,把LMs相关的组件“链接”在一起,简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用.
LangChain目前有两个语言的实现:python 和 NodeJS.
LangChain是一个用于构建和管理基于语言模型(Language Models,LM)的应用程序的框架。它提供了一系列工具和组件,帮助开发者更高效地构建、训练、部署和管理语言模型应用。LangChain的设计目标是简化语言模型的使用过程,使其更加容易被集成到各种应用场景中。
LangChain之所以大火,是因为它提供了一系列方便的工具、组件和接口,大大降低了AI应用开发的门槛,也极大简化了大模型应用程序的开发过程。
网址: https://python.langchain.com/docs
模块化设计:LangChain采用模块化设计,将不同的功能拆分成独立的组件,如Prompts、Models、Chains、Memory、Retriever 和Agent。这些组件可以灵活组合,以满足不同应用的需求。
强大的模型支持:支持多种预训练语言模型,如GPT-3、BERT、T5等。这些模型经过大规模数据训练,具备强大的语言理解和生成能力。
易用的API:提供简单易用的PythonAPI,开发者可以通过几行代码快速实现复杂的语言处理任务。
丰富的工具和组件:包括数据处理工具、模型训练和微调工具、服务接口、应用开发工具等,覆盖了从数据准备到模型部署的全流程。
社区支持:拥有一个活跃的社区,提供了大量的示例和教程,帮助开发者快速上手和解决常见问题。
相关包简介:
langchain:主要用于构建和管理基于语言模型的应用程序,提供从模型管理到应用开发的一站式解决方案。
langchain_community:是langchain的社区版,包含社区贡献的额外功能和插件,提供更多扩展性的工具。
dashscope:主要用于构建和管理数据科学和机器学习应用,提供丰富的数据可视化和模型部署工具。
cmd命令行执行如下命令:
pip install langchain -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install langchain-community -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install dashscope -i https://pypi.tuna.tsinghua.edu.cn/simple
LangChain主要组件
Prompts 提示,包括提示管理、提示优化和提示序列化
Models 模型,各种类型的模型和模型集成,比如GPT-4
Memory 记忆,用来保存和模型交互时的上下文状态
Indexes 索引,用来结构化文档,以便和模型交互
Chains 链,一系列对各种组件的调用
Agents 代理,决定模型采取哪些行动,执行并且观察流程,直到完成为止
LangChain框架应用场景
文本生成:自动生成文章、故事、诗歌、代码等。
机器翻译:将一种语言的文本翻译成另一种语言。
问答系统:回答用户提出的问题,提供准确的信息。
文本分类和情感分析:对文本进行分类,判断其情感倾向(正面、负面、中性等)。
摘要生成:从长篇文章中提取关键信息,生成简洁的摘要。
对话系统:构建聊天机器人、虚拟助手,进行自然的对话交互。
创建阿里云百炼平台APIKEY
阿里云百炼平台介绍
官网地址:https://bailian.console.aliyun.com
点击应用,再点击应用管理
点击右上角创建应用
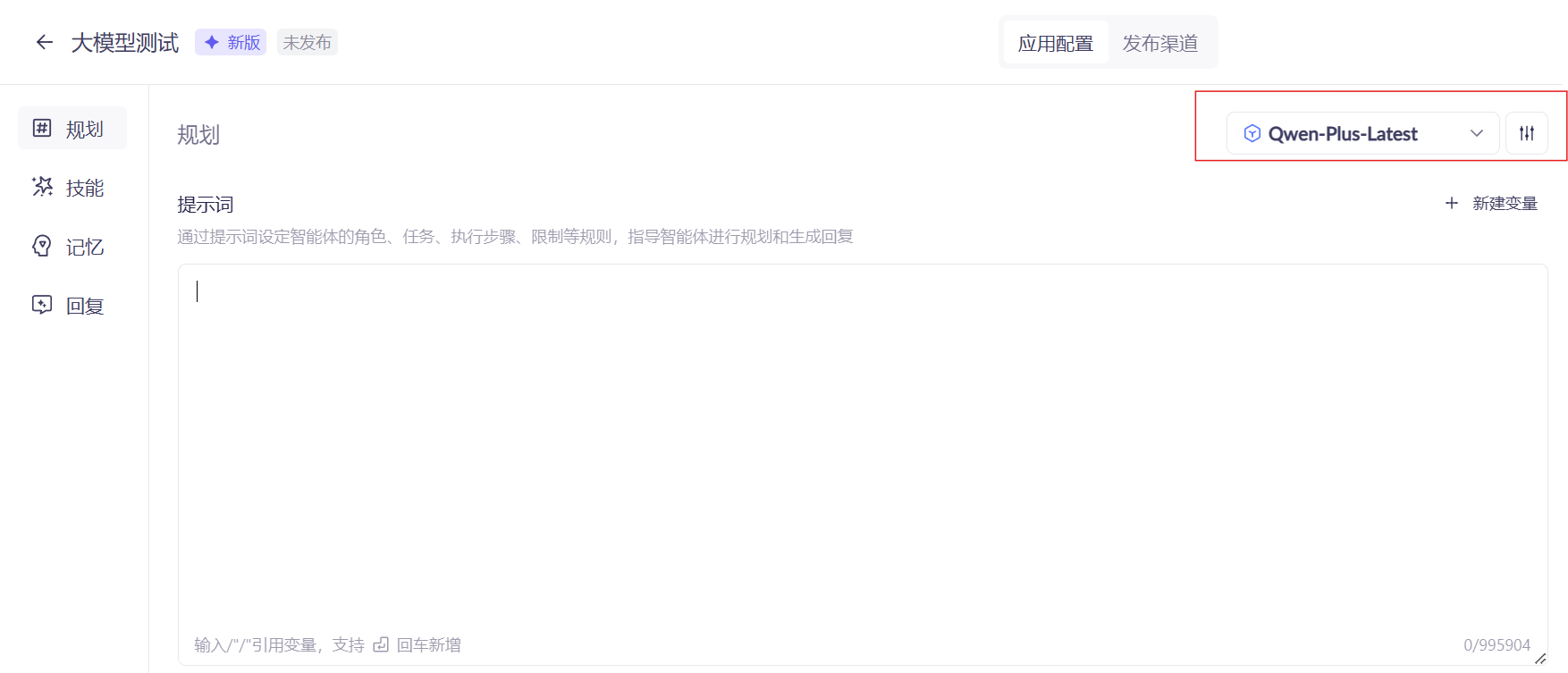
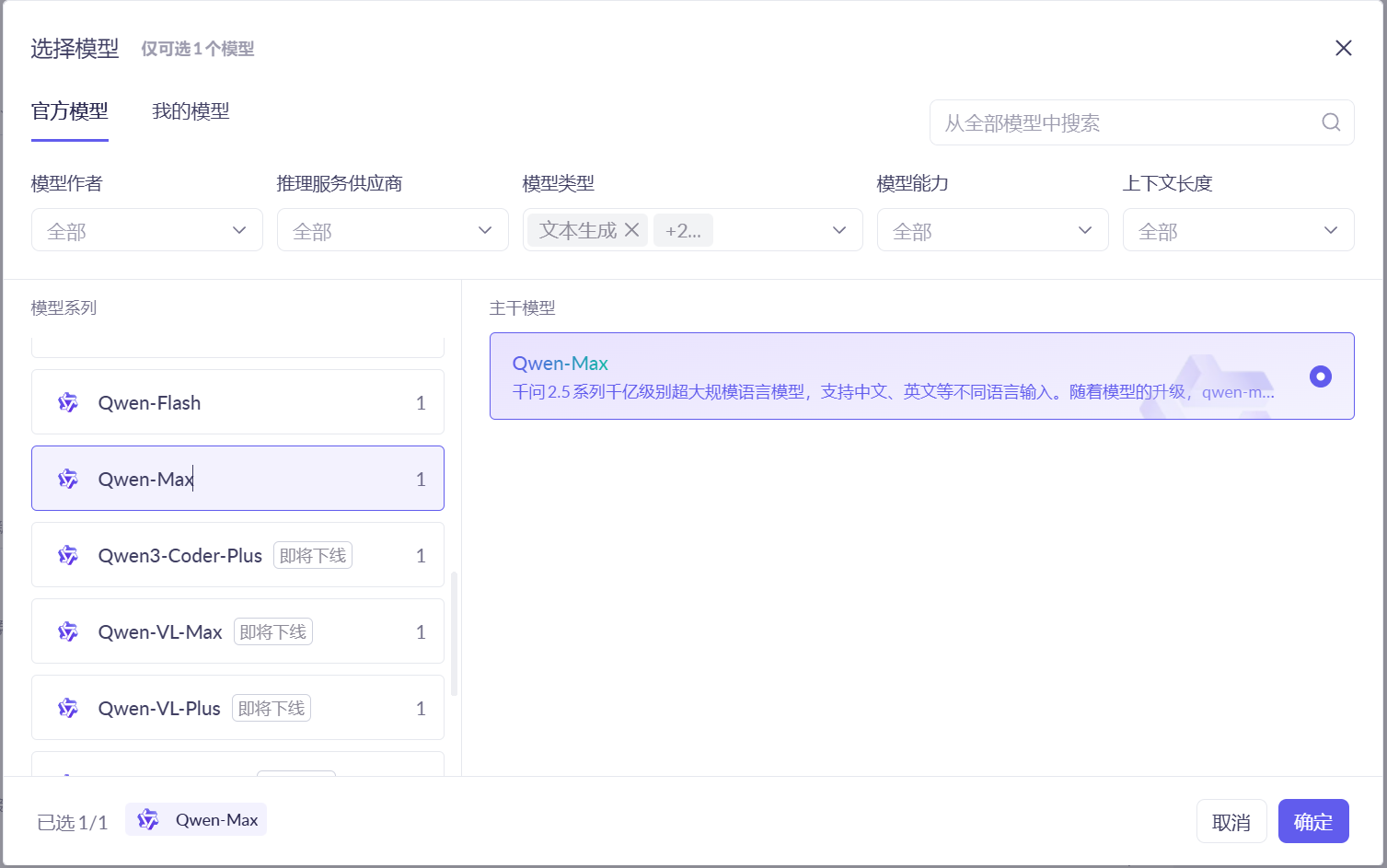
在这里选择模型
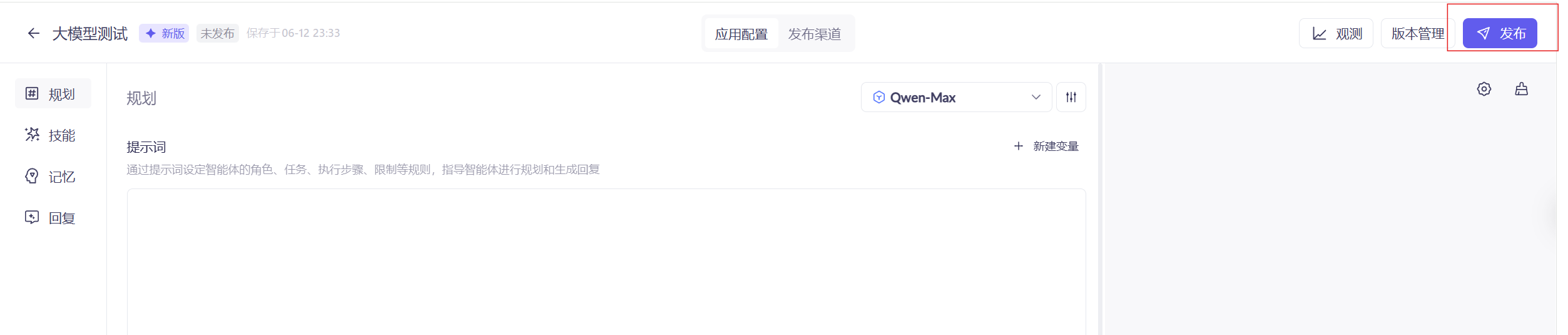
点击发布
点击APIKey,创建API Key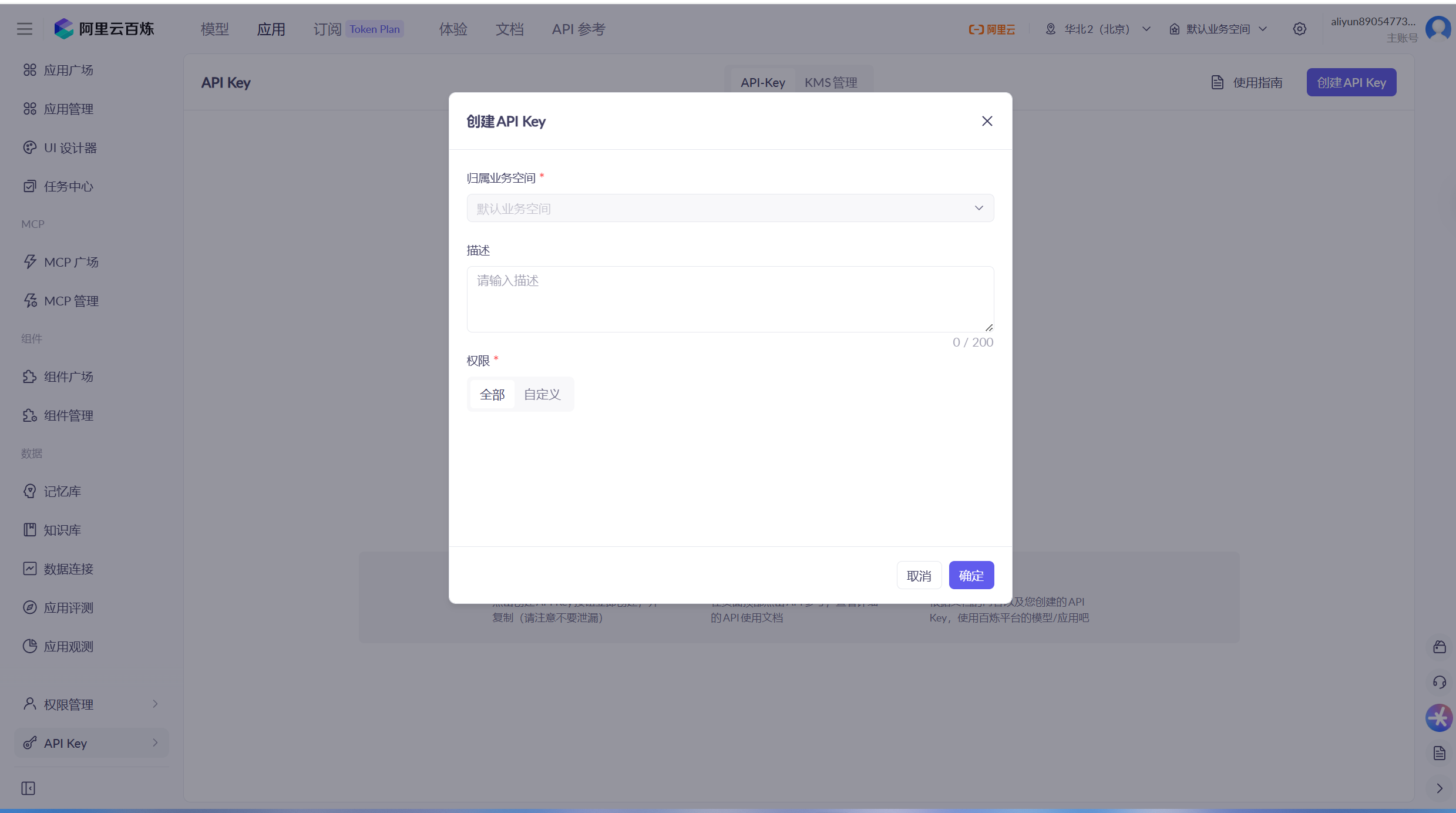
LangChain入门案例
LangChain环境
LangChain本质上上一个Python框架,要部署LangChain环境可以通过pip命令安装对应的包即可。
命令如下:
pip install langchain -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install langchain-community -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install dashscope -i https://pypi.tuna.tsinghua.edu.cn/simple
- langchain:大模型应用开发核心框架,提供链、记忆、检索等功能
- langchain_community:LangChain社区贡献组件,含第三方工具、模型集成
- dashscope:阿里云官方的大模型开发Python库,用于调用通义千问(Qwen)等阿里系大模型的API,实现对话、生成、推理等功能。
LangChain示例代码
Langchain下载软件包0.1.20版本
from langchain_community.llms import Tongyi
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 创建一个内存记忆对象
memory = ConversationBufferMemory(return_messages=True)
def get_reponse(prompt, api_key):
model = Tongyi(model="qwen-max", dashscope_api_key=api_key)
chain = ConversationChain(llm=model, memory=memory)
# 发送请求对象
response = chain.invoke({"input": prompt})
return response["response"]
if __name__ == '__main__':
print(get_reponse("请用python输出1-10","sk-ws-H.REDEMRI.RomY.MEUCIQDJbdKnFQ0jyvWtNG3IdgPn1wuPQ_bHSyE0lksNJO00DAIgcgxf8ailz5WIo_axXXp_ETZvRHAHR1kp7mvYO9CfvEY"))
参数:
-
prompt:用户输入的字符串。
-
api_key:阿里云 DashScope 的 API 密钥(用于认证和计费)。
模型初始化:
- Tongyi(model=“qwen-max”, dashscope_api_key=api_key):指定使用通义千问的 qwen-max 模型(阿里云最高性能版本之一),并传入 API Key。
创建对话链:
- ConversationChain(llm=model, memory=memory):将模型和记忆组件绑定到一个链中。这个链会在每次调用时自动:
- 从 memory 中读取历史对话。
- 将历史 + 当前用户输入拼接成完整的提示词。
- 调用模型生成回答。
- 将新的问答对存入 memory 中。
调用链:
- chain.invoke({“input”: prompt}):传入用户输入(注意字典的键必须是 “input”,这是 ConversationChain 预定义的输入键)。
返回值是一个字典,其中 “response” 键对应的值是模型生成的回答文本。
运行结果:
当然可以!以下是用 Python 输出 1 到 10 的几种常见方式(每种都附带简要说明):
✅ **方法 1:使用 `for` 循环 + `range()`(最常用、推荐)**
for i in range(1, 11):
print(i)
👉 `range(1, 11)` 生成从 1 开始(含)、到 11 结束(不含)的整数序列:`1, 2, ..., 10`。
✅ **方法 2:一行打印成列表形式(不换行)**
print(list(range(1, 11)))
输出:`[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]`
✅ **方法 3:用空格分隔,同一行输出**
print(*range(1, 11))
输出:`1 2 3 4 5 6 7 8 9 10`
(`*` 是解包操作符,将 `range` 对象展开为独立参数传给 `print`)
✅ **方法 4:用逗号分隔(字符串拼接)**
print(', '.join(map(str, range(1, 11))))
输出:`1, 2, 3, 4, 5, 6, 7, 8, 9, 10`
需要我帮你运行其中某段代码、解释 `range` 的底层原理,或者扩展成“输出 1-10 的平方”“只输出偶数”等变体吗?😊
LangChain与Streamlit结合
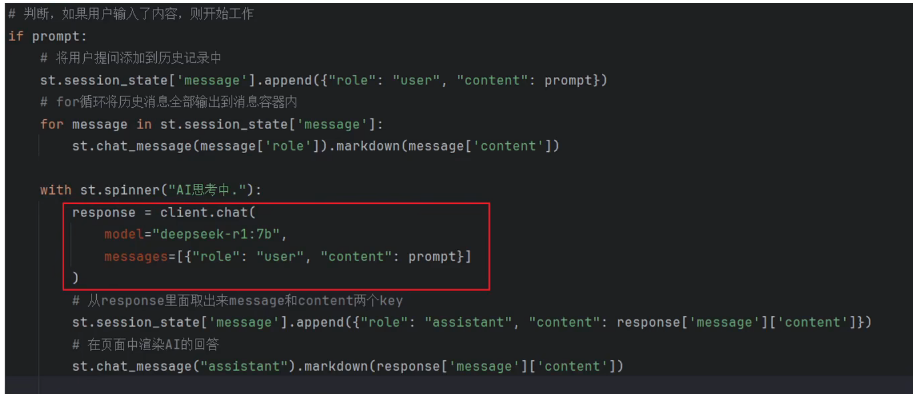
将原有代码的调用Ollama函数,改为调用刚刚准备的LangChain函数即可
import time
import ollama
import streamlit as st
from Langchain_test.Langchain_util import get_reponse
# ollama 获取客户端
client = ollama.Client(host="http://localhost:11434")
# 初始化消息记录
if "message" not in st.session_state:
st.session_state["message"] = []
# 添加标题
st.title("智聊机器人")
st.divider()
# 用户输入问题
prompt = st.chat_input("请输入问题")
# 用户输入内容则开始工作
if prompt:
# 将用户提问添加到历史记录中
st.session_state["message"].append({"role": "user", "content": prompt})
# 将历史消息全部输入到消息容器中去
for message in st.session_state["message"]:
st.chat_message(message['role']).markdown(message['content'])
with st.spinner("AI思考中"):
response = get_reponse(prompt,"sk-ws-H.REDEMRI.ZIVB.MEUCIBXv3_MhJelb4thE-tH7rkmyjvr_RQfOmeCEqMCf1y2iAiEAiGfwYO49FNJgsiNRhPAZ93NgeyNzQIm9NnEMOsvkKqo")
# 从response中取出来message和content两个key
st.session_state['message'].append({"role": 'assistant', 'content': response})
# 在页面中渲染ai回答
st.chat_message("assistant").markdown(response)
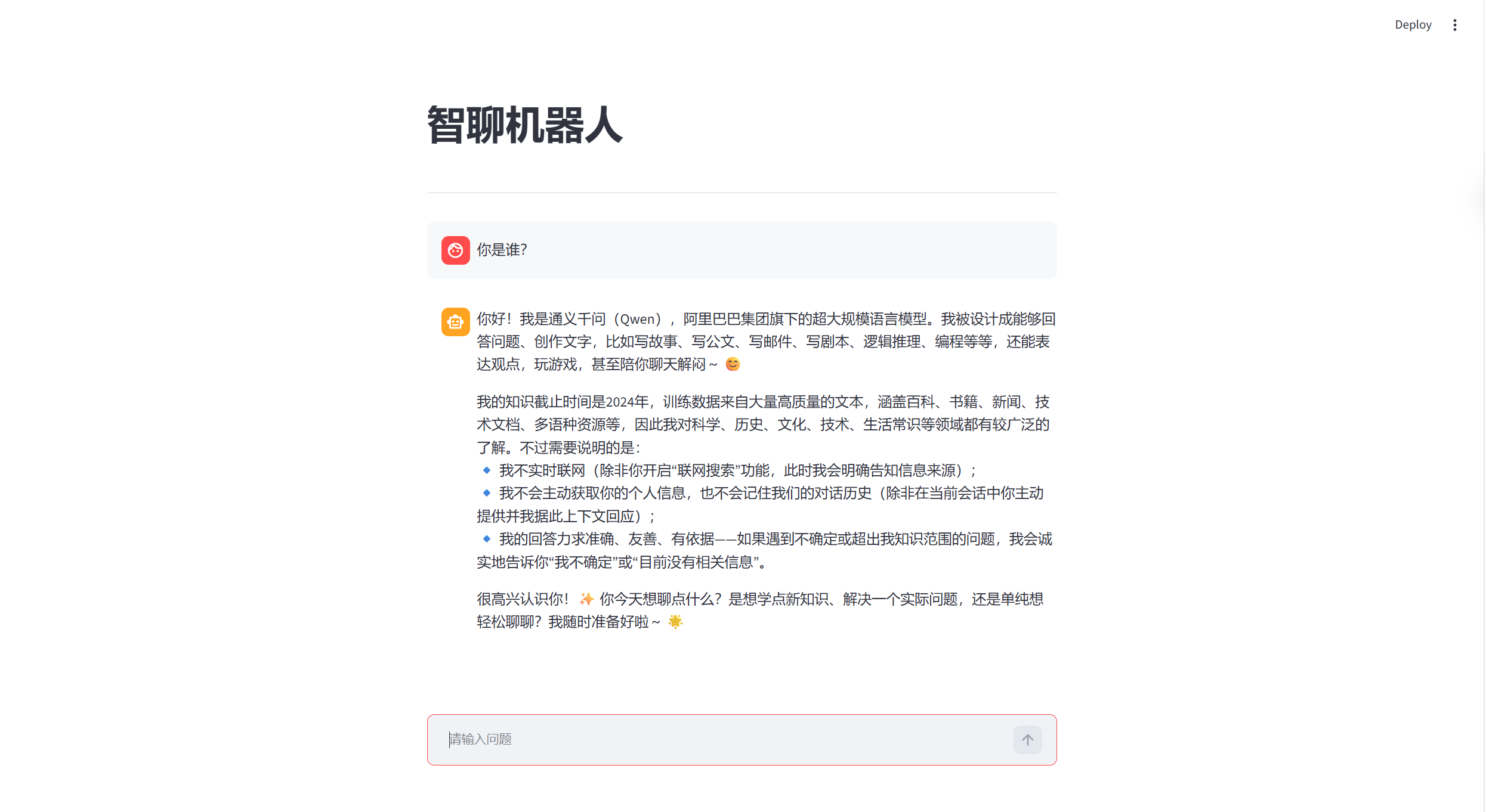
总结
这篇博客从最底层的系统环境搭建,到本地大模型部署,再到两套不同架构的聊天机器人落地,完整覆盖了「大模型本地部署→轻量应用开发→云端能力扩展」的全流程,最终我们得到了两个不同定位的AI聊天工具。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)