大模型应用开发架构设计:到底是“中心化调度(Orchestration)”还是“去中心化智能(Choreography)”?(Gemini 3 Flash Preview 回答)
·
这是一个非常深刻的架构设计问题,触及了当前大模型应用开发的最前沿:到底是“中心化调度(Orchestration)”还是“去中心化智能(Choreography)”?
为了搭建一个可插拔、模块化的 Agent 平台,我建议采用 “强规划分发层 (Planner/Dispatcher) + 专业执行层 (Specialized Workers)” 的架构。
以下是针对你提出的“A是什么、B是什么、两者的区别”这类复杂问题的两种深度方案对比,以及顶层架构设计的建议。
一、 两种思路的深度对比
思路 A:顶层意图拆解(中心化调度)
做法: 顶层意图识别 Agent(Planner)具备强逻辑能力。它收到问题后,不直接调用 Agent,而是先生成一个执行计划(Execution Plan)。
- 拆解步骤:
- 调用
Knowledge_Agent查询 A 的定义。 - 调用
Knowledge_Agent查询 B 的定义。 - 将 1 和 2 的结果交给
Comparison_Agent或由Planner自己汇总生成差异分析。
- 调用
- 优点:
- 模块化程度最高: 下层的 Agent 可以做得很“薄”,只负责垂直领域,容易插拔。
- 可观测性强: 你能清晰看到 Planner 拆解的每一步,哪里错了调哪里。
- 并发效率: 1 和 2 可以并行执行,极大降低首字延迟。
- 缺点: 顶层 Planner 压力大,如果 Planner 没拆解好,后面步步错。
思路 B:直接丢给 Agentic RAG(去中心化智能)
做法: 顶层只做一个简单的路由,把问题丢给一个具备 Agentic 能力的“全能 RAG Agent”。
- 拆解步骤: 这个 RAG Agent 内部自己发现“我要回答这个问题需要两个知识点”,于是它自己启动内部循环(ReAct 模式),先检索 A,再检索 B,最后自己总结。
- 优点: 顶层设计简单,只需按领域路由(如:关于技术的丢给技术 Agent,关于法律的丢给法律 Agent)。
- 缺点:
- 响应慢: 内部循环通常是串行的,且难以监控内部黑盒。
- 重复造轮子: 如果你有 10 个 Agent,每个都要写一遍 Agentic RAG 的逻辑。
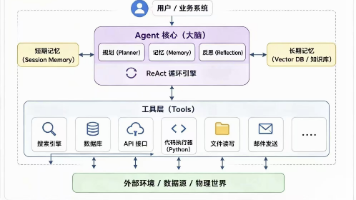
二、 建议的平台顶层架构设计:三层模型
为了兼顾“可插拔”和“高性能”,建议采用以下架构:
1. 意图解析与规划层 (The Brain - Planner)
这一层必须使用最强的模型(如 Qwen2.5-72B-Instruct)。
- 功能:
- Query Decomposition (查询拆解): 将复杂问题拆分为子任务列表。
- Dependency Mapping (依赖映射): 识别哪些子任务可以并行(A 和 B 的定义),哪些必须串行(对比 A 和 B)。
- Routing (路由): 根据子任务的标签,分发给注册在案的特定 Agent。
- 输出示例: 一个 JSON 格式的任务流。
2. Agent 路由与执行引擎 (The Bus - Orchestrator)
这一层不涉及 AI 逻辑,而是工程实现(可以使用 LangGraph 或 Temporal)。
- 功能:
- 并发管理: 同时调用多个执行层 Agent。
- 状态管理(Memory): 维护一个共享的“黑板(Blackboard)”,让 A 的结果和 B 的结果能被后续步骤读取。
- 插件管理: 维护一个 Agent 注册表(每个 Agent 声明自己的描述、输入输出格式)。
3. 执行层 Agent (The Workers - Tools)
这一层是可插拔的模块。
- 特点: 它们可以是“弱 Agent”,甚至是简单的 API。
- 分类:
- Simple RAG Agent: 只负责给关键词出结果,不负责拆解复杂问题。
- Tool Agent: 负责查数据库、查天气、画图。
- Agentic RAG Worker: 只有在处理极度垂直且复杂的领域(如医疗病例分析)时,才给该模块配置内部 Agentic 能力。
三、 针对你的“A vs B”案例的最佳实践流程
在一个成熟的平台上,流程应该是这样的:
- 用户提问: “A和B有什么区别?”
- Planner (72B) 介入:
- 识别到这是一个“对比类”任务。
- 生成逻辑:
[Task1: Define A, Tool: tech_rag], [Task2: Define B, Tool: tech_rag], [Task3: Compare results, Tool: Summarizer]。
- Orchestrator 调度:
- 并行发送 Task1 和 Task2。
- 等待两个结果返回,存入 Context。
- Planner/Summarizer 汇总:
- 基于 Context 里的 A 和 B 信息,生成最终对比回复。
四、 核心设计原则建议
- 意图识别必须“Agentic”化: 顶层路由不能只是简单的分类器(Classifier),而必须是一个能生成**计划(Plan)**的 Planner。
- 接口标准化: 每一个接入平台的 Agent 必须遵循统一的 API 规范(例如:必须接受
query,可选接受context,统一返回thought和answer)。 - 按需智能:
- 顶层: 始终用最强的模型(逻辑大脑)。
- 底层: 根据任务难度分配模型。简单的信息检索用 Qwen2.5-7B 即可,节省成本和时间。
- 引入“反思”机制: 在 Planner 汇总完结果后,增加一个小的 Check 步骤,判断“汇总后的内容是否真的回答了用户最初的问题”。
总结
你不需要每一个 Agent 都是 Agentic 的。最优雅的设计是:一个极其聪明的中心 Planner(负责意图拆解与编排)+ 一群高效专业的专家型 Agent(负责执行特定任务)。 这种“星型架构”最符合插件化和模块化的商业需求。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 15
15 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)