AI大模型之旅——LangChain RAG
文章目录
AI大模型之LangChain RAG
一、基础概念(Langchain1.2.8版本)
1.1 什么是RAG?
RAG(Retrieval Augmented Generation)检索增强生成,RAG是一种将信息检索和大语言模型文本生成相结合的技术。简单来说,RAG就是在大语言模型生成答案之前,AI应用先从外部知识库中检索与用户提问相关的信息,然后将检索到的信息作为上下文通过提示词一起传递给大语言模型,从而让大语言模型根据检索出来的内容进行回答
1.2 RAG的优缺点
RAG的优点
1)相比提示词工程,RAG有 更丰富的上下文和数据样本 ,可以不需要用户提供过多的背景描述,就能生 成比较符合用户预期的答案。
2)相比于模型微调,RAG可以提升问答内容的 时效性 和 可靠性 3)在一定程度上保护了业务数据的 隐私性 。RAG的缺点
1)由于每次问答都涉及外部系统数据检索,因此RAG的 响应时延 相对较高。
2)引用的外部知识数据会 消耗大量的模型Token 资源。
1.3 RAG实现步骤
RAG技术的主要由以下几个步骤组成:
(1)文档的收集
(2)文档处理
(3)文档数据向量化
(4)文档数据相似性检索
(5)构建提示词
(6)大语言模型生成结果
向量化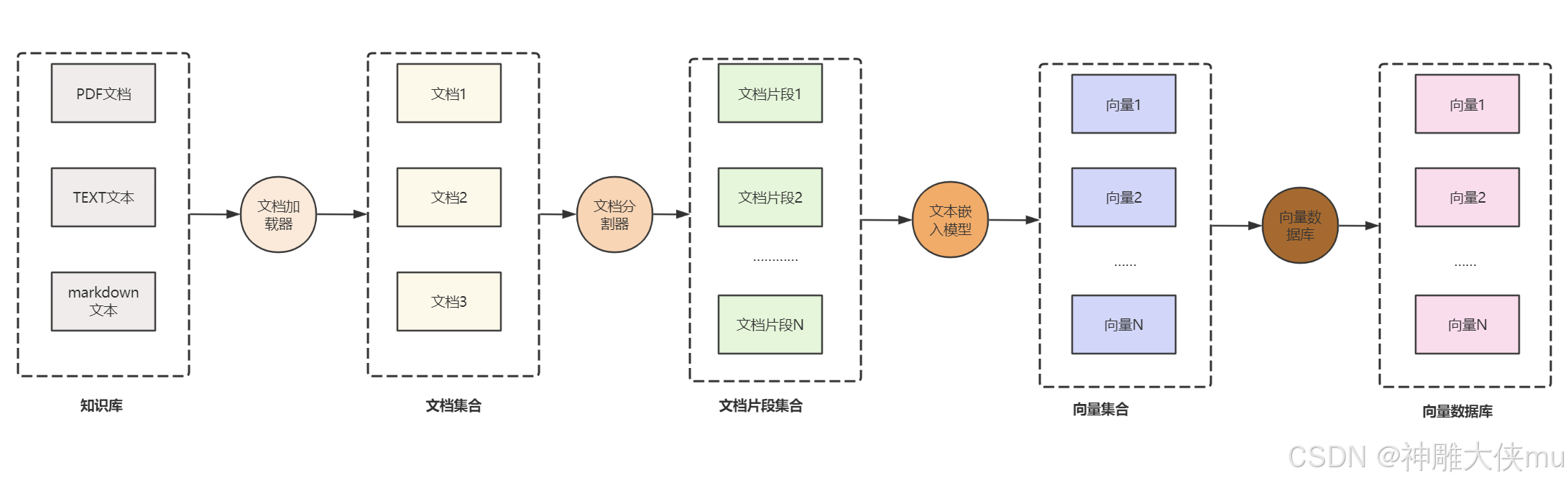
向量化+检索流程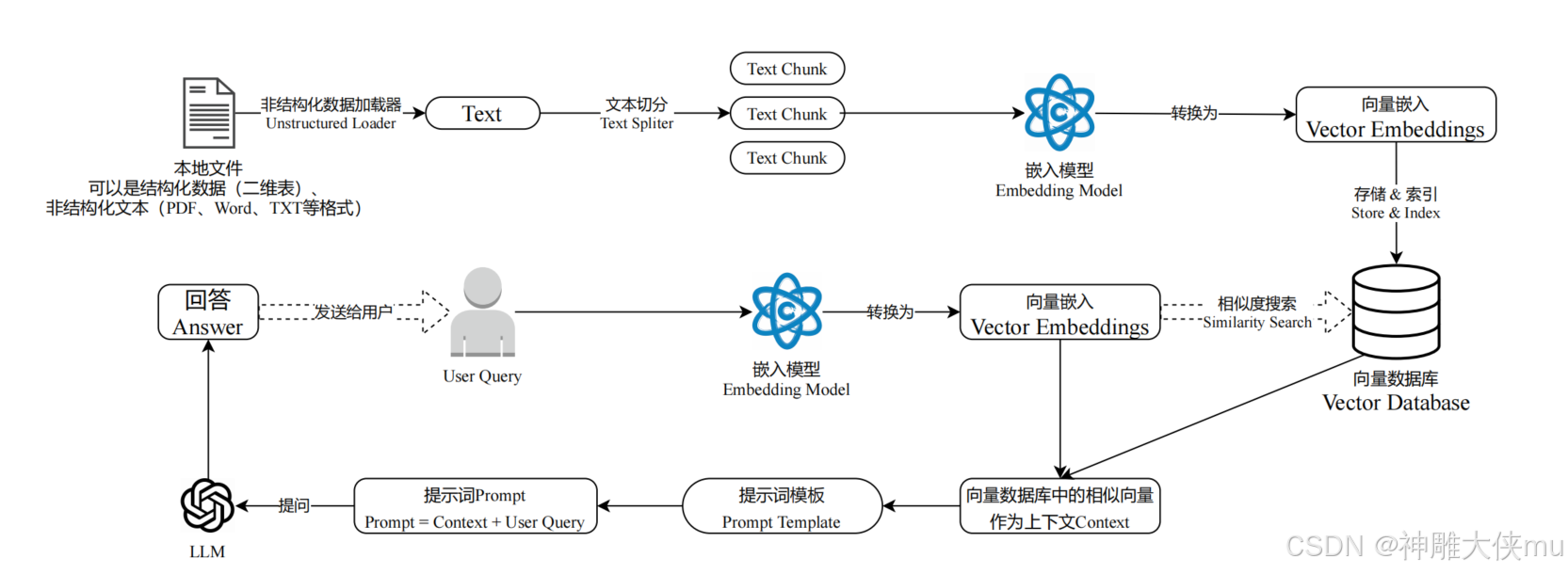
二、文档加载器
2.1 分类
| 文档加载器 | 作用 |
|---|---|
| CSVLoader | 从CSV加载文档 |
| TextLoader | 从TEXT加载文档 |
| PyPDFLoader | 从PDF数据加载文档 |
| JSONLoader | 从JSON数据加载文档 |
| UnstructuredHTMLLoader | 从HTML数据加载文档 |
| UnstructuredMarkdownLoader | 从Markdown加载文档 |
| UnstructuredExcelLoader | 从Excel文件加载数据 |
| DirectoryLoader | 批量加载一个文件夹内的所有文件 |
2.2 LangChain加载text文档加载器
from langchain_community.document_loaders import TextLoader
text_loader = TextLoader(file_path="./学生.txt",encoding="utf-8")
doc = text_loader.load()
print(doc)
"""
加载txt文件
page_content:真正的文档内容
metadata:文档内容的元数据
"""
print(type(doc[0]))
print(doc[0].page_content)
print(doc[0].metadata)
2.3 LangChain加载PDF文档加载器
pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
pdfLoader = PyPDFLoader(file_path="./01-LangChain使用概述.pdf")
pdf = pdfLoader.load()
print( pdf)
print(type(pdf[0]))
print(pdf[0].page_content)
print(pdf[0].metadata)
2.4 LangChain加载CSV文档加载器
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="./01-LangChain使用概述.csv")
data = loader.load()
print(data)
print(type(data[0]))
print(data[0].page_content)
2.5 LangChain加载JSON文档加载器
LangChain提供的JSON格式的文档加载器是 JSONLoader 。在实际应用场景中,JSON格式的数据占有很大比例,而且JSON的形式也是多样的。我们需要特别关注。 JSONLoader 使用指定的 jq结构来解析 JSON文件。jq是一个轻量级的命令行 JSON 处理器 ,可以对 JSON 格式的数据进行各种复杂的处理,包括数据过滤、映射、减少和转换,是处理JSON 数据的首选 工具之一。
from langchain_community.document_loaders import JSONLoader
jsLoader = JSONLoader(file_path="./测试json",jq_schema=".messages[].content")
docs = jsLoader.load()
print(docs)
2.6 LangChain加载EXCEL文档加载器
需要安装依赖包:
pip install \
unstructured \
openpyxl \
msoffcrypto-tool \
pandas \
lxml
代码示例:
from langchain_community.document_loaders import UnstructuredExcelLoader
loader = UnstructuredExcelLoader(
"智能客服知识库便民快巴线路信息.xlsx",mode="elements"
)
docs = loader.load()
print(docs[0].page_content)
print(docs[0].metadata)
2.7 自定义文档加载器
实现自定义文档加载器:通过这些LangChain提供的文档加载器很难满足业务需求,例如需要根据特定规则提取文本片段,这时就需要开发自定义加载器,只需要定义一个自定义文档加载器类,并继承前面提到的BaseLoader类
from typing import List
from langchain_core.document_loaders import BaseLoader
from langchain_core.documents import Document
class ChatRecordLoader(BaseLoader):
file_path: str
def __init__(self, file_path: str):
self.file_path = file_path
def load(self) -> List[Document]:
"""加载聊天记录文档"""
documents2 = []
with open(self.file_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
# 如果包含中文冒号,则进行分割 表示只切割第 1 次。如果字符串后面还有其他的中文冒号,它们会被保留在分割后的第二部分中,不会继续切割
if ":" in line:
user_name, content = line.split(":", 1)
documents2.append(
Document(
page_content=content.strip(),
metadata={"user_name": user_name.strip()}
)
)
else:
# 不符合格式要求直接跳过
continue
return documents2
# 调用自定义文档加载器
chat_record_loader = ChatRecordLoader(file_path="chat_record.txt")
documents = chat_record_loader.load()
print(f"文档数量:{len(documents)}")
for document in documents:
print(f"文档内容:{document.page_content}")
print(f"文档元数据:{document.metadata}")
三、文档分割器
3.1 为什么要使用文档分割器?
当拿到统一的一个Document对象后,接下来需要切分成Chunks。如果不切分,而是考虑作为一个整体的Document对象,会存在两点问题:
- 假设提问的Query的答案出现在某一个Document对象中,那么将检索到的整个Document对象 直接放入Prompt中并 不是最优的选择 ,因为其中一定会 包含非常多无关的信息 ,而无效信息越 多,对大模型后续的推理影响越大。
- 任何一个大模型都存在最大输入的 Token限制 ,如果一个Document非常大,比如一个几百兆的 PDF,那么大模型肯定无法容纳如此多的信息。
基于此,一个有效的解决方案就是将完整的Document对象进行 分块处理(Chunking)。无论是在存储 还是检索过程中,都将以这些 块(chunks) 为基本单位,这样有效地避免内容不相关性问题和超出最大输 入限制的问题。
3.2 文本分割器的主要作用?
控制上下文长度:把长文档分割成更小,缩小上下文长度提高检索准确性:小的文本片段能提升文档检索的精确度保持语义完整性:在分割过程中,能尽量保持文本的语义连贯性
3.3 常用文档分割器
| 分割器 | 作用 |
|---|---|
| RecursiveCharacterTextSplitter | 递归按字符分割文本 |
| CharacterTextSplitter | 按指定字符分割文本 |
| MarkdownHeaderTextSplitter | 按Markdown标题分割 |
| PythonCodeTextSplitter | 专门分割Python代码 |
| TokenTextSplitter | 按Token数量分割 |
| HTMLHeaderTextSplitter | 按HTML标题分割 |
3.4 分割文本的核心方法:
| 方法 | 作用 |
|---|---|
| split_text() | 将文本字符串分割成字符串列表 |
| split_documents() | 将Document对象列表分割成更小文本片段的Document对象列表 |
| create_documents() | 通过字符串列表创建Document对象 |
3.5 RecursiveCharacterTextSplitter 文档分割器
安装: pip install -qU langchain-text-splitters
RecursiveCharacterTextSplitter构造函数几个核心参数:
chunk_size:每个片段的最大字符数
chunk_overlap:片段之间的重叠字符数
length_function:计算长度函数
is_separator_regex:分隔符是否为正则表达式
separators:自定义分隔符
使用代码示例
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1.分割文本内容
content = ("杜甫(712年2月12日~770年),字子美,自号少陵野老,出生于河南巩县(今河南省巩义市),祖籍襄阳(今湖北省襄阳市),后迁居巩县。"
""
"唐代伟大的现实主义诗人,被后人誉为“诗圣”,其诗被称为“诗史”,与李白并称为“李杜”,为了与另两位诗人李商隐与杜牧即“小李杜”区别,杜甫与李白又合称“大李杜”。"
""
"杜甫出身于京兆杜氏,乃晋代名将杜预之后,其祖父杜审言亦是初唐著名诗人。其人忧国忧民,人格高尚,一生颠沛流离,历经安史之乱,深切体验民间疾苦。"
""
"杜甫深受儒家思想影响,秉持“致君尧舜上,再使风俗淳”的政治理想,有《杜工部集》传世。其诗作风格沉郁顿挫,内容深刻反映社会现实,代表作有《春望》《登高》《茅屋为秋风所破歌》、“三吏”(《石壕吏》《新安吏》《潼关吏》)、“三别”(《新婚别》《垂老别》《无家别》)等。")
# 2.定义递归文本器
# chunk_size: 返回块的最大尺寸,单位是字符数。默认值为4000(由长度函数测量)
# chunk_overlap: 相邻两个块之间的字符重叠数,避免信息在边界处被切断而丢失。默认值为200,通常会设置为chunk_size的10% - 20%。
# length_function: 用于测量给定块字符数的函数。默认赋值为len函数。len函数在Python中按Unicode字符计数,所以一个汉字、一个英文字母、一个符号都算一个字符。
# separators:自定义分隔符
# text_spliter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=30, length_function=len)
text_spliter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0, length_function=len, separators=["。", "?", "\n\n", "\n", " ", ""])
# 3.调用split_text()方法分割文本
spliter_tests = text_spliter.split_text(content)
# 4.将文本片段转换为Document对象
spliter_documents = text_spliter.create_documents(spliter_tests)
# 5.打印结果
print(f"分割文档数量:{len(spliter_documents)}")
for splitter_document in spliter_documents:
print(f"文档片段大小:{len(splitter_document.page_content)}, 文档元数据:{splitter_document.metadata},文档内容:{splitter_document.page_content}")
3.6 MarkdownHeaderTextSplitter 分割器
按标题分割Markdown文件
在对Markdown格式的文档进行分割时,一般不能像RecursiveCharacterTextSplitter默认分割规则方式进行分割,通常需要按照标题层次进行分割,LangChain提供了MarkdownHeaderTextSplitter类来实现这个功能。 在对Markdown文件进行分割时,对于那些很长的文档,可先利用MarkdownHeaderTextSplitter按标题分割,将分割后的文档再使用RecursiveCharacterTextSplitter进行分割,使用示
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import MarkdownHeaderTextSplitter,RecursiveCharacterTextSplitter
# 1.文档加载
loader = TextLoader("杜甫.md",encoding="utf-8")
documents = loader.load()
document_text = documents[0].page_content
# 2.定义文本分割器,设置指定要分割的标题
headers_to__split_on = [
("#", "Header 1"),
("##", "Header 2")
]
headers_to__split_on = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to__split_on)
# 3.按标题分割文档
docs = headers_to__split_on.split_text(document_text)
print(f"标题分割文档数量:{len(docs)}")
for doct in docs:
print(f"文档片段大小:{len(doct.page_content)}, 文档元数据:{doct.metadata},文档内容:{doct.page_content}")
print("*"*300)
# 4.定义递归文本分割器
text_spliter = RecursiveCharacterTextSplitter(chunk_size=100,
chunk_overlap=0,
length_function=len,
separators=["。", "?", "\n\n", "\n", " ", ""])
# 5.递归分割文本
r_docs = text_spliter.split_documents(docs)
print(f"递归分割文档数量:{len(r_docs)}")
for r_doc in r_docs:
print(f"文档片段大小:{len(r_doc.page_content)}, 文档元数据:{r_doc.metadata},文档内容:{r_doc.page_content}")
3.7 自定义文本分割器
当内置的的文本分割器无法满足业务需求时,可以继承TextSplitter类来实现自定义分割器
from typing import List
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import TextSplitter
class CustomTextSplitter(TextSplitter):
def split_text(self, text: str) -> List[str]:
text = text.strip()
# 1.按段落进行分割
text_array = text.split("\n\n")
result_texts = []
for text_item in text_array:
strip_text_item = text_item.strip()
if strip_text_item is None:
continue
# 2.按句进行分割
result_texts.append(strip_text_item.split("。")[0])
return result_texts
# 1.文档加载
loader = TextLoader(file_path="杜甫.md",encoding="utf-8")
documents = loader.load()
document_text = documents[0].page_content
# 2.定义文本分割器
splitter = CustomTextSplitter()
# 3.文本分割
splitter_texts = splitter.split_text(document_text)
for splitter_text in splitter_texts:
print(
f"文本分割片段大小:{len(splitter_text)}, 文本内容:{splitter_text}")
四、文本嵌入模型组件
4.1 什么是文本嵌入模型?
文本嵌入模型可以将一段文本转换为高维向量表示,向量可以理解为是一组数字,文本嵌入模型根据多个不同维度将文本转换为具有语义含义的向量数据,这个转换过程叫做文本嵌入。
Text Embedding Models:文档嵌入模型,提供将文本编码为向量的能力,即 文档向量化 。 文档写入和 用户查询匹配 前都会先执行文档嵌入编码,即向量化。
4.2 Embeddings类提供两个方法
在LangChain中,Embeddings类是为文本嵌入模型设计的标准接口,针对不同的文本嵌入模型供应商(如OpenAI、HuggingFace、通义千问等)提供不同的实现类。
Embeddings类提供了两个方法:embed_documents:传入多个文本片段,将文本片段转换为多个向量返回
embed_query:传入查询文本,将查询文本转换为向量返回
4.3 OpenAIEmbeddings用法
import dotenv
from langchain_openai import OpenAIEmbeddings
# 加载环境变量,这里使用了.env文件来存储OPENAI的key和url
dotenv.load_dotenv()
texts = [
"宋代杰出女词人,号易安居士,婉约词派代表,有“千古第一才女”之称。李清照工诗善文,更擅长词,其词前期多写悠闲生活,后期多悲叹身世,情调感伤。",
"李清照,(1084年3月13日-约1155年)号易安居士,汉族,齐州济南(今山东省济南市章丘区)人。出身书香门第,早期生活优裕,婚后与夫赵明诚共同致力于书画金石的搜集整理。",
"其词语言清丽,强调协律,崇尚典雅,提出词“别是一家”之说,反对以作诗文之法作词。能诗,留存不多,部分篇章感时咏史,情辞慷慨。代表作有《声声慢·寻寻觅觅》《一剪梅·红藕香残玉簟秋》《夏日绝句》等,后人有《漱玉词》辑本。",
]
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectors = embeddings.embed_documents(texts)
print("文档向量:")
for i, vector in enumerate(vectors):
print(f"文档 {i+1}: {vector}")
print("="*30)
query = "谁是李清照?"
query_vector = embeddings.embed_query(query)
print(f"查询向量: {query_vector}")
4.4 CacheBackedEmbeddings结果缓存
当使用Embeddings类对一段文本进行嵌入后,再有同样的文本进行嵌入,如果每次都重新调用嵌入模型,不仅会显著增加处理时间,也会带来额外的调用成本。
因此,LangChain提供了CacheBackedEmbeddings可以对嵌入结果进行缓存,下次同样的文本进行嵌入,直接从缓存中读取,无需重复调用嵌入模型。
创建CacheBackedEmbeddings对象,需要通过
from_bytes_store方法,该方法需要指定如下参数:
| 参数 | 含义 |
|---|---|
| underlying_embedder | 真正用于文本嵌入Embeddings类 |
| document_embedding_cache | 用于缓存文档嵌入向量数据的 ByteStore(字节存储接口) ,ByteStore 是 LangChain 提供的通用“字节存储接口”,用于以二进制形式读写向量数据。常见实现包括本地文件系统(如 LocalFileStore)、Redis(RedisStore) 等 |
| batch_size | 可选参数,默认为None,在嵌入缓存未命中时,多少个文档为一批,去调用底层文本嵌入组件去文本嵌入并写入缓存。 |
| namespace | 可选参数,默认为 “” ,文档缓存的命名空间。使用命名空间来避免和其他嵌入模型的缓存数据发生冲突。因此,可以将命名空间设置为所使用的嵌入模型的名称 |
| query_embedding_cache | 可选参数,默认为 None,传入False则不进行缓存,传入True使用与文档缓存相同的ByteStore,也可以传入单独的 ByteStore用于查询文本的缓存 |
from langchain_classic.storage import LocalFileStore
from langchain_classic.embeddings import CacheBackedEmbeddings
import time
import dotenv
from langchain_openai import OpenAIEmbeddings
# 1.加载环境变量
dotenv.load_dotenv()
# 2.创建进行文本嵌入的embeddings对象
underlying_embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 3.创建CacheBackedEmbeddings对象
cache_embeddings = CacheBackedEmbeddings.from_bytes_store(underlying_embeddings=underlying_embeddings,
document_embedding_cache=LocalFileStore("./document_cache/"),
namespace=underlying_embeddings.model,
query_embedding_cache=LocalFileStore("./query_cache/")
)
texts = [
"宋代杰出女词人,号易安居士,婉约词派代表,有“千古第一才女”之称。李清照工诗善文,更擅长词,其词前期多写悠闲生活,后期多悲叹身世,情调感伤。",
"李清照,(1084年3月13日-约1155年)号易安居士,汉族,齐州济南(今山东省济南市章丘区)人。出身书香门第,早期生活优裕,婚后与夫赵明诚共同致力于书画金石的搜集整理。",
"其词语言清丽,强调协律,崇尚典雅,提出词“别是一家”之说,反对以作诗文之法作词。能诗,留存不多,部分篇章感时咏史,情辞慷慨。代表作有《声声慢·寻寻觅觅》《一剪梅·红藕香残玉簟秋》《夏日绝句》等,后人有《漱玉词》辑本。",
]
# 4.将文本转换为向量
start_time = time.time()
vectors = cache_embeddings.embed_documents(texts)
print(f"文档嵌入执行时间:{time.time() - start_time:.4f} 秒")
# 5.将查询转换为向量(句子向量化,即把查询语句向量化)
start_time = time.time()
query = "谁是李清照?"
query_vector = cache_embeddings.embed_query(query)
# 6.输出查询文本向量
print(f"查询文本嵌入执行时间:{time.time() - start_time:.4f} 秒")
五、向量数据库组件
5.1 什么是项链数据库?
向量数据库(Vector database)是一种能够存储多维向量数据的新型数据库,向量数据库实现了一种或者多种近似相邻算法,来支持用户使用查询文本或图像进行相似性检索,来检索到最匹配的向量数据
5.2 为什么要转成向量?
- 电脑只懂数字,不懂文字
- 相似的意思转成的向量也相似
- 可以用数学方法计算相似度
5.3 常见向量数据库
Milvus 、 Pinecone 、 Qdrant、 Weaviate 、 Chroma
5.4 Weaviate数据库
Weaviate数据库是一个基于GO语言开发的开源的向量数据库
安装:docker run -d --name weaviate -p 8088:8080 -p 50051:50051 semitechnologies/weaviate
注意:这里的端口我映射成了 8088
安装依赖包:pip install -U weaviate-client
5.5 Weaviate数据库的常见操作
5.5.1 校验是否连接成功
连接数据库: weaviate.connect_to_local
# 1.客户端连接是否成功
from typing import List, Dict
import weaviate
import uuid
# 1.创建weaviate 客户端
client = weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
)
# 输出 True 标识连接成功
print("是否连接成功:",client.is_ready())
5.5.2 创建集合
语法:client.collections.create
import weaviate
# 1.创建weaviate 客户端
client = weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
)
print("是否连接成功:",client.is_ready())
# 2.创建集合
resp = client.collections.create("product")
print(resp)
5.5.3 插入一条数据
在集合Database中创建一个带向量和属性的对象,并且insert方法会返回一个uuid,这个uuid就是这个对象的唯一标识
语法: databases.data.insert
import weaviate
# 1.创建weaviate 客户端
client = weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
)
print("是否连接成功:",client.is_ready())
# 2.创建集合
resp = client.collections.create("yunFanDb1")
print(resp)
# 3.创建带向量和元数据的对象
databases = client.collections.get("yunFanDb1")
print( databases)
uuid1 = databases.data.insert(
properties={
"name": "张三",
"age": 18,
"vector": [0.1, 0.2, 0.3, 0.4, 0.5]
}
)
print(uuid1)
5.5.4 批量添加数据
语法:collection.data.insert_many
import weaviate
from weaviate.classes.config import Property, DataType
from weaviate.collections.classes.data import DataObject
import uuid
# ✅ 整个逻辑包裹在 with 块内
with weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
) as client:
print("是否连接成功:", client.is_ready())
# 2. 删除旧集合(可选)
try:
client.collections.delete("yunFanDb2")
except:
pass
# 3. 创建集合
client.collections.create(
name="yunFanDb2",
properties=[
Property(name="title", data_type=DataType.TEXT)
]
)
# 4. 准备数据
data_rows = [{"title": f"标题{i + 1}"} for i in range(5)]
vectors = [[0.1] * 1536 for _ in range(5)]
# 5. 插入带向量的对象
objects_to_insert = [
DataObject(
properties=data_rows[i],
vector=vectors[i],
uuid = uuid.uuid4()
)
for i in range(len(data_rows))
]
print("准备插入的对象:", objects_to_insert)
collection = client.collections.get("yunFanDb2")
response = collection.data.insert_many(objects_to_insert)
if response.has_errors:
print("批量插入失败:")
for err in response.errors:
print(f" UUID {err.uuid}: {err.message}")
else:
print(f"成功插入 {len(response.uuids)} 条记录")
5.5.5 根据id查询一条向量
Weaviate支持通过uuid 检索对象。如果uuid不存在,将会返回 404错误,这里还指定了include_vector属性为True表示除了返回对象元数据信息之外,同时返回向量信息,在打印向量时,读取vector的default属性是因为,在Weaviate对象可以保存多个向量信息,默认的向量名就是default
语法: database.query.fetch_object_by_id
import weaviate
# ✅ 整个逻辑包裹在 with 块内
with weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
) as client:
database = client.collections.get("yunFanDb2")
data_object = database.query.fetch_object_by_id("03ab347d-6f41-4d8b-a513-9ebc09778bc9",include_vector=True)
# 打印向量信息
print(data_object.properties)
print(data_object.vector["default"])
5.5.6 查询所有对象
语法: client.collections.get
import weaviate
# ✅ 整个逻辑包裹在 with 块内
with weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
) as client:
database = client.collections.get("yunFanDb2")
for item in database.iterator(include_vector=True):
#print(item.properties)
#print(item.vector)
print(item)
5.5.7 根据id更新一条信息
语法: database.data.replace
import weaviate
# ✅ 整个逻辑包裹在 with 块内
with weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
) as client:
database = client.collections.get("yunFanDb2")
database.data.replace(
uuid="03ab347d-6f41-4d8b-a513-9ebc09778bc9",
# 更新属性
properties={
"title": "2000",
},
# 更新向量信息
vector=[1.0] * 1536
)
5.5.8 根据id删除一条数据
语法: database.data.delete_by_id
import weaviate
# ✅ 整个逻辑包裹在 with 块内
with weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
) as client:
database = client.collections.get("yunFanDb2")
database.data.delete_by_id("03ab347d-6f41-4d8b-a513-9ebc09778bc9")
5.5.9 条件删除
语法:database.data.delete_many(条件)
import weaviate
from weaviate.classes.query import Filter # ✅ 关键导入
# ✅ 整个逻辑包裹在 with 块内
with weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
) as client:
database = client.collections.get("yunFanDb2")
database.data.delete_many(
where=Filter.by_property("title").like("标题*")
)
5.5.10 删除集合
语法:client.collections.delete(集合名)
import weaviate
# ✅ 整个逻辑包裹在 with 块内
with weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
) as client:
client.collections.delete("yunFanDb2")
5.5.11 向量存储组件VectorStore
使用VectorStore组件将向量数据存储到向量数据库中 VectorStore 接口提供了多个常用方法
| 方法 | 作用 |
|---|---|
| add_texts | 将文本列表转换为向量,并存储到向量数据库 |
| add_documents | 将文档列表转换为向量,并存储到向量数据库 |
| as_retriever | 返回向量数据库初始化的检索器 |
| similarity_search_with_relevance_scores | 进行相似性检索,返回文档及其相关性得分(范围在[0,1]之间) |
| delete | 根据向量id删除向量数据 |
| from_texts | 传入文本列表、元数据信息、文本嵌入模型,返回创建好的VectorStore |
安装依赖
依赖包
pip install langchain-weaviate
生成依赖版本快照pip freeze > requirements.txt
5.5.11.1 使用VectorStore存储
代码示例:
import dotenv
import weaviate
from pathlib import Path
from langchain_openai import OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# ======================
# 读取 .env
# ======================
dotenv.load_dotenv()
# ======================
# 1. 创建 Weaviate 客户端
# ======================
# ✅ 整个逻辑包裹在 with 块内
with weaviate.connect_to_local(
host="192.168.10.181",
port=8088,
grpc_port=50051,
) as client:
# ======================
# 2. Embedding 模型
# ======================
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
# ======================
# 3. 创建 VectorStore
# ======================
vector_store = WeaviateVectorStore(
client=client,
# text_key 表示存储原文的 key 名
text_key="text_key",
embedding=embeddings,
# 数据库表名
index_name="Database",
)
# ======================
# 4. 从文件加载 Document
# ======================
def load_documents(folder: str):
documents = []
# 读取文件夹下的文件
for file in Path(folder).rglob("*.txt"):
loader = TextLoader(str(file),encoding="utf-8")
documents.extend(loader.load())
return documents
# 在当前目录的文件夹名为 data
docs = load_documents("./data")
# ======================
# 5. 文本切分(企业必须)
# ======================
splitter = RecursiveCharacterTextSplitter(
chunk_size=120,
chunk_overlap=20,
)
split_docs = splitter.split_documents(docs)
# ======================
# 6. 自动生成 texts + metadatas
# ======================
texts = []
metadatas = []
for i, doc in enumerate(split_docs):
texts.append(doc.page_content)
metadata = doc.metadata.copy()
metadata["segment_id"] = str(i + 1)
metadatas.append(metadata)
# ======================
# 7. 写入 Weaviate
# ======================
uuids = vector_store.add_texts(
texts=texts,
metadatas=metadatas
)
# 6.打印返回的uuid列表
print(f"存储到Weaviate向量数据库的对象的uuid列表:{uuids}")
5.5.11.2 使用VectorStore检索
import dotenv
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
# 读取env配置
dotenv.load_dotenv()
# 1.创建Weaviate客户端
client = weaviate.connect_to_local(
host="192.168.10.181",
port=8088,
grpc_port=50051,
)
# 2.创建文本嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 3.创建Weaviate向量数据库
vector_store = WeaviateVectorStore(
client=client,
text_key="text_key",
embedding=embeddings,
index_name="Database"
)
#方法一 4、进行数据检索
search_result = vector_store.similarity_search_with_relevance_scores(query="公司的董事长是谁?", k=3)
# 5、打印检索结果
for document, score in search_result:
print(f"文档内容:{document.page_content}")
print(f"文档元数据信息:{document.metadata}")
print(f"相关度得分:{score}")
print("=================================")
# 方法二 替换上面的第4/5步
retriever = vector_store.as_retriever()
documents = retriever.invoke("介绍一下公司副总经理的情况。")
for document in documents:
print(document.page_content)
print(document.metadata)
print("=================================")
六、文本检索器
6.1 什么是文本检索器?
Retrievers(检索器)是一种用于从大量文档中检索与给定查询相关的文档或信息片段的工具。
向量数据库本身已经包含了实现召回功能的函数方法 ( similarity_search)。该函数通过计算原始查询向量与数据库中存储向量之间的相似度来实现召回。 LangChain还提供了 更加复杂的召回策略,这些策略被集成在Retrievers(检索器或召回器)组件中。
Retrievers 的执行步骤:步骤1:将输入查询转换为向量表示。步骤2:在向量存储中搜索与查询向量最相似的文档向量(通常使用余弦相似度或欧几里得距离等度量方法)。步骤3:返回与查询最相关的文档或文本片段,以及它们的相似度得分。
6.2 检索器分类
6.2.1 as_retriever
6.2.1.1 默认检索器使用相似性搜索
# 获取检索器 这里设置返回的文档数
retriever = db.as_retriever(search_kwargs={"k": 4})
docs = retriever.invoke("经济政策")
for i, doc in enumerate(docs):
print(f"\n结果 {i+1}:\n{doc.page_content}\n")
6.2.1.2 分数阈值查询 只有相似度超过这个值才会召回
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.1}
)
docs = retriever.invoke("经济政策")
for doc in docs:
print(f"📌 内容: {doc.page_content}")
6.2.1.3 MMR搜索
mmr代表 Maximum Marginal Relevance(最大边际相关性)。这是一种 优化搜索结果的策略,用于平衡结果的相关性与多样性。 在向量检索中,"mmr"会选择与查询最相关的结果,同时避免返回重复的内容。因此,它不仅仅基于相似度排序,还考虑了结果间的多样性,减少冗余,提高检索的质量fetch_k:这将指定 从检索库中返回的文档数量。k 通常表示检索的结果数,在这里 fetch_k=2 意味着只返回 最相关的 2 个文档。
retriever = db.as_retriever(
search_type="mmr",
search_kwargs={"fetch_k":2}
)
docs = retriever.invoke("经济政策")
print(len(docs))
for doc in docs:
print(f"📌 内容: {doc.page_content}")
6.2.2 MultiQueryRetriever
为了提升查询结果的准确性,可以将查询文本传递给大语言模型,由其生成多个不同表达方式的查询文本变体。随后,使用这些不同的查询文本分别进行文档检索,并将所有检索结果汇总、排序,返回最相关的文档。
MultiQueryRetriever(多查询检索器)正是实现上述 RAG 检索优化逻辑的工具。可以使用
MultiQueryRetriever.from_llm() 方法创建一个多查询检索器
使用实例:
import logging
import dotenv
import weaviate
from langchain_classic.retrievers import MultiQueryRetriever
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_weaviate import WeaviateVectorStore
# 读取env配置
dotenv.load_dotenv()
# 1.创建Weaviate客户端
with weaviate.connect_to_local(
host="192.168.10.181",
port=8088,
grpc_port=50051,
) as client:
# 2.创建文本嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 3.创建Weaviate向量数据库
vector_store = WeaviateVectorStore(
client=client,
text_key="text_key",
embedding=embeddings,
index_name="Database"
)
# 4.创建多查询检索器
retriever = vector_store.as_retriever()
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=retriever, llm=ChatOpenAI(model="gpt-3.5-turbo"),
prompt=PromptTemplate(
input_variables=["question"],
template="""你是一个 AI 语言模型助手。你的任务是:
为给定的用户问题生成 3 个不同的版本,以便从向量数据库中检索相关文档。
通过生成用户问题的多种视角(改写版本),
你的目标是帮助用户克服基于距离的相似性搜索的某些局限性。
请将这些改写后的问题用换行符分隔开。原始问题:{question}""")
)
# 5.进行数据检索
documents = retriever_from_llm.invoke("介绍一下董事长信息")
for document in documents:
print(document.page_content)
print(document.metadata)
print("=================================")
七、案例:智能客服(RAG + LLM)
7.1 RAG 数据的准备和处理
RAG 的准备阶段,主要包含以下 4 个步骤:
(1)
文档加载:使用TextLoader对非结构化的商品信息.md文件进行加载。(2)
文档分割:创建递归文本分割器,并指定块大小为 800,重叠部分为 100,对文本进行分割。(3)
文本嵌入:创建文本嵌入组件,指定模型名称为text-embedding-3-small。(4)
向量存储:创建WeaviateVectorStore,配置 Weaviate 连接,并传入文本嵌入模型,用于将文本片段进行嵌入。最后调用add_documents()方法,将文本片段存储到向量数据库中。
import dotenv
import weaviate
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_weaviate import WeaviateVectorStore
# 读取env配置
dotenv.load_dotenv()
# 1.文档加载
document_load = TextLoader(file_path="商品信息.md",encoding="utf-8")
documents = document_load.load()
# 2.文档分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=800,
chunk_overlap=100,
length_function=len,
)
documents = text_splitter.split_documents(documents)
print(f"文档数量:{len(documents)}")
for document in documents:
print(f"文档片段大小:{len(document.page_content)}")
print("=====================================")
# 3文本嵌入向量数据库
client = weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051
)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 4.向量数据存储
vector_store = WeaviateVectorStore(
client=client,
text_key="text_key",
embedding=embeddings,
index_name="NuoMiProduct")
vector_store.add_documents(documents)
7.2 智能客服系统本身
接下来,开始实现智能客服系统,主要包含以下8 个步骤:
(1)
创建提示词模板:模板包括 系统消息、消息占位符、人类消息。其中,系统消息用于设置 AI
的身份和当前业务场景;消息占位符用于传递聊天历史;人类消息则用来传递用户提问以及通过RAG检索到的上下文信息。(2)
构建模型:使用 gpt-3.5-turbo 模型。(3)
创建输出解析器:创建一个 字符串输出解析器,用于结果输出。(4)
构建检索器:连接 Weaviate 数据库,创建 WeaviateVectorStore 对象,并传入 文本嵌入对象、Weaviate
客户端对象、存储文本信息 key、集合名称。然后调用 WeaviateVectorStore.as_retriever()
方法生成检索器,并指定只返回一条最相关的文档数据。(5)
创建记忆组件:构建记忆组件,并将历史对话信息保存在 customer_service_history.txt 中。(6)
构建链:构建LCEL
链。链的后半部分较为直观,这里重点介绍前半部分。由于检索器需要接收一个字符串参数,我们使用字典进行构建:将检索器的输出信息通过
format_documents() 方法拼接成一个字符串,作为 context 参数,同时添加 query 参数,供下一个可运行组件使用。
这里利用了 RunnableParallel 的参数传递功能。之前介绍过,在LCEL
表达式中,使用字典结构包裹并通过管道符连接时,会自动被包装成 RunnableParallel。(7)
调用链:使用 stream() 方法调用链,传入用户提问。stream() 可以实现流式输出,相比一次性返回结果,用户体验更好。(8)
记忆保存:调用 save_context(),将对话记忆进行持久化。
代码示例
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_core.runnables import RunnableWithMessageHistory, RunnableLambda
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
import dotenv
import weaviate
import os
from langchain_core.documents import Document
# =============================
# 加载环境
# =============================
dotenv.load_dotenv()
# redis配置
redis_password = os.getenv("REDIS_PASSWORD")
redis_url = f"redis://:{redis_password}@192.168.174.198:6379/1"
# 模拟用户id
user_id = "customer_1"
# =============================
# 1. 创建提示词模板
# =============================
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是糯米公司的智能客服,你的名字叫糯米。"
"你只回答商品售卖相关问题,必须礼貌、专业、热情。"
"如果与商品无关,请礼貌拒绝。",
),
MessagesPlaceholder("chat_history"),
(
"human",
"""
用户提问上下文:
<context>
{context}
</context>
用户问题:
{query}
""",
),
]
)
# =============================
# 2. 构建模型
# =============================
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.3,
)
# =============================
# 3. 创建输出解析器
# =============================
parser = StrOutputParser()
# =============================
# Weaviate 向量库连接
# =============================
client = weaviate.connect_to_local(
host="192.168.174.198",
port=8088,
grpc_port=50051,
)
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
vector_store = WeaviateVectorStore(
client=client,
index_name="NuoMiProduct",
text_key="text_key", # ⭐ 必须与 Weaviate schema 一致
embedding=embeddings,
)
# =============================
# 4. 构建检索器
# =============================
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# 获取 collection
collection = client.collections.get("NuoMiProduct")
def safe_retrieve(query: str):
query_vector = embeddings.embed_query(query)
response = collection.query.near_vector(
near_vector=query_vector,
limit=2,
)
docs = []
for obj in response.objects:
text = obj.properties.get("text_key")
if text and isinstance(text, str):
docs.append(Document(page_content=text))
return docs
def format_documents(docs):
if not docs:
return "暂无相关商品信息"
return "\n".join(d.page_content for d in docs)
retrieve_runnable = RunnableLambda(safe_retrieve)
format_runnable = RunnableLambda(format_documents)
# =============================
# 5. 构建链
# =============================
rag_chain = (
{
"context": itemgetter("query")
| retrieve_runnable
| format_runnable,
"query": itemgetter("query"),
"chat_history": itemgetter("chat_history"),
}
| prompt
| llm
| parser
)
# =============================
# 6. 创建记忆组件
# =============================
def get_redis_history(session_id: str):
return RedisChatMessageHistory(
session_id=session_id,
url=redis_url,
)
# =============================
# 7. 带 Memory 的 Chain 记忆保存
# =============================
chain = RunnableWithMessageHistory(
rag_chain,
get_redis_history,
input_messages_key="query",
history_messages_key="chat_history",
)
# =============================
# 8.循环聊天
# =============================
print("===== 大米智能客服启动 =====")
while True:
query = input("用户:")
if query == "退出":
break
print("智能客服:", end="", flush=True)
answer = ""
for chunk in chain.stream(
{"query": query},
config={"configurable": {"session_id": user_id}},
):
answer += chunk
print(chunk, end="", flush=True)
print("\n")

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)