ChatGPT原理揭密!背后的黑科技Transformer模型
·
ChatGPT原理揭密!背后的黑科技Transformer模型 — 通俗解释
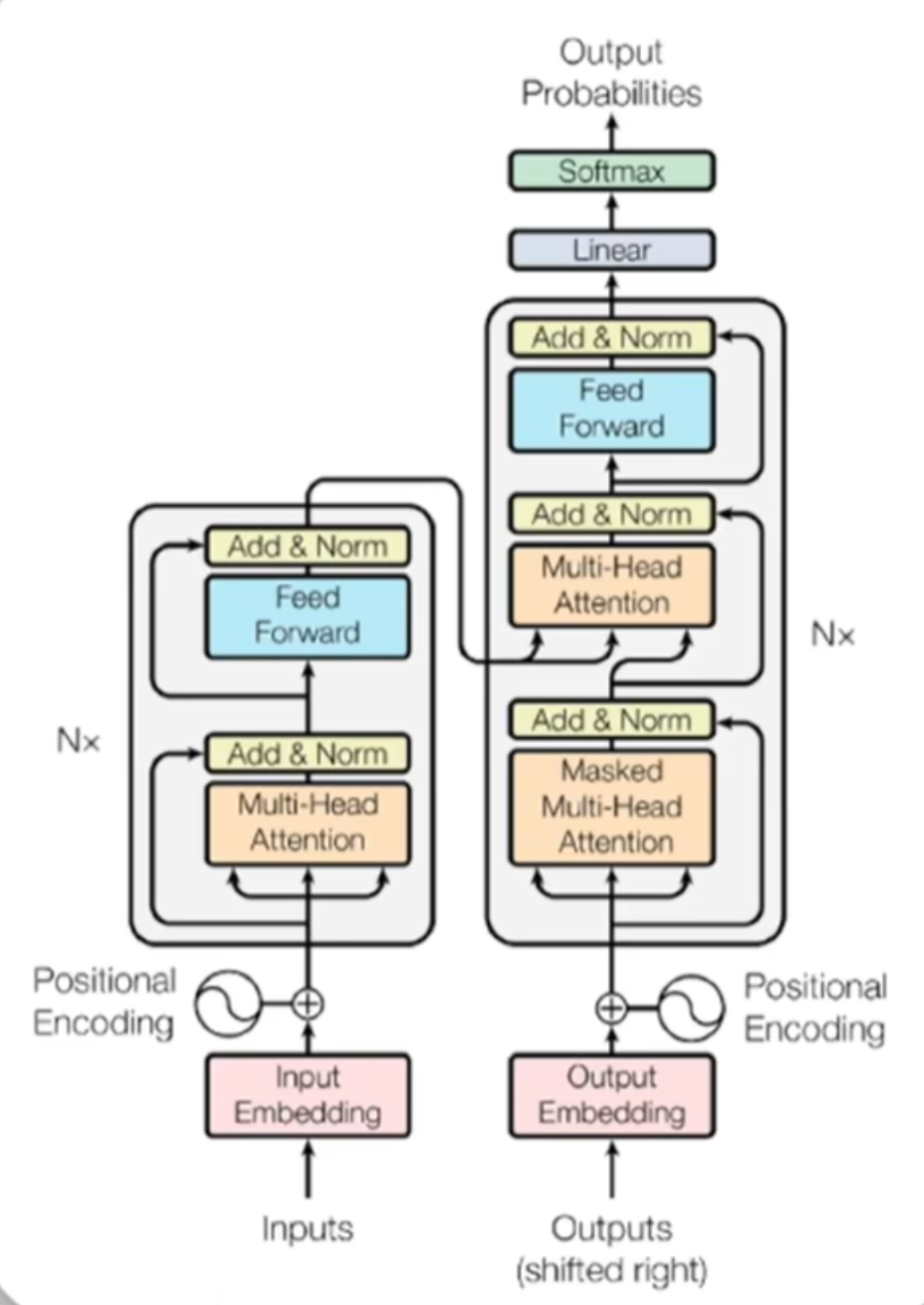
🏷️ Transformer 的整体架构
- GPT 等生成式大语言模型的核心原理是预测出现概率最高的下一个词来实现文本生成
- 效果类似手机输入法的自动补全——输入一个字/词后,系统预测后续文本,概率高的排在前面
- 2017 年论文《Attention is All You Need》提出 Transformer 架构,此后文本领域大模型几乎被它一统江湖
- OpenAI 的 GPT 系列
- 清华的 GLM
- 百度的文心等
- Transformer 由两个核心部分组成:编码器(Encoder) 和 解码器(Decoder)
- 以英语翻译法语为例:编码器接收英语输入,解码器返回对应的法语输出
💡 Token化与词嵌入(Embedding)
- 输入文本首先被 Token 化——拆分成基本单位(Token),短单词每个词是一个 Token,长单词可能被拆成多个
- 每个 Token 用一个整数(Token ID)表示,因为计算机只能处理数字
- 然后经过 嵌入层(Embedding Layer),将每个 Token 用一个向量(一串数字)表示
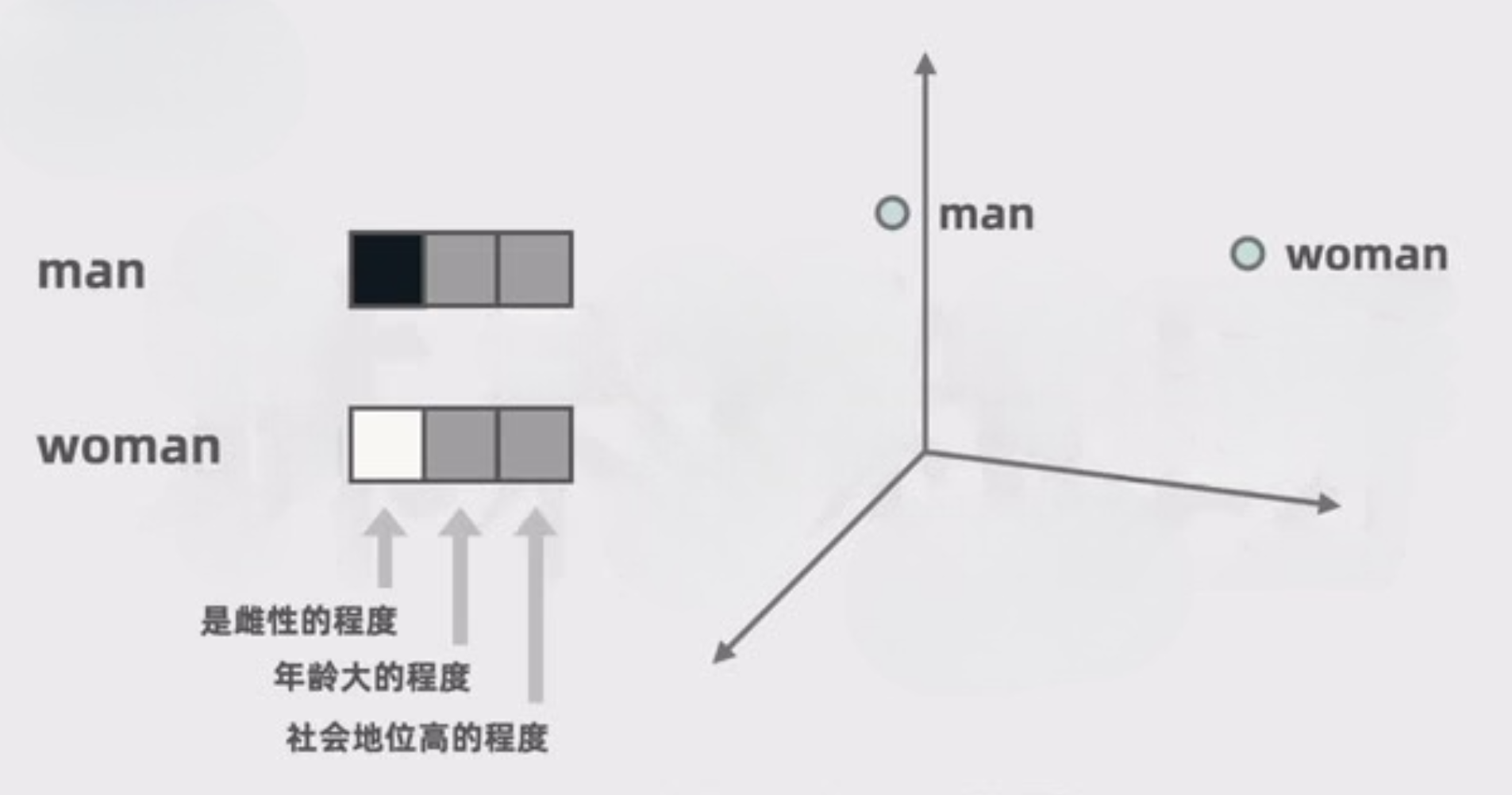
- 为什么要用向量而不是单个数字?
- 一串数字能表达的含义远大于一个数字,可包含语法、语义等多维信息
- 例如"男人"和"女人":描述的都是人类,但性别相反——单个数字无法同时表达"相似"和"差异"
- 多维向量可以分别表示不同维度:雌性程度、年龄、社会阶层等
- 相似的词在向量空间中距离更近,无关的词距离更远
- 经典示例:"男人"与"国王"的差异 ≈ "女人"与"女王"的差异
- 论文原版向量长度为 512 维,GPT-3 为 12288 维
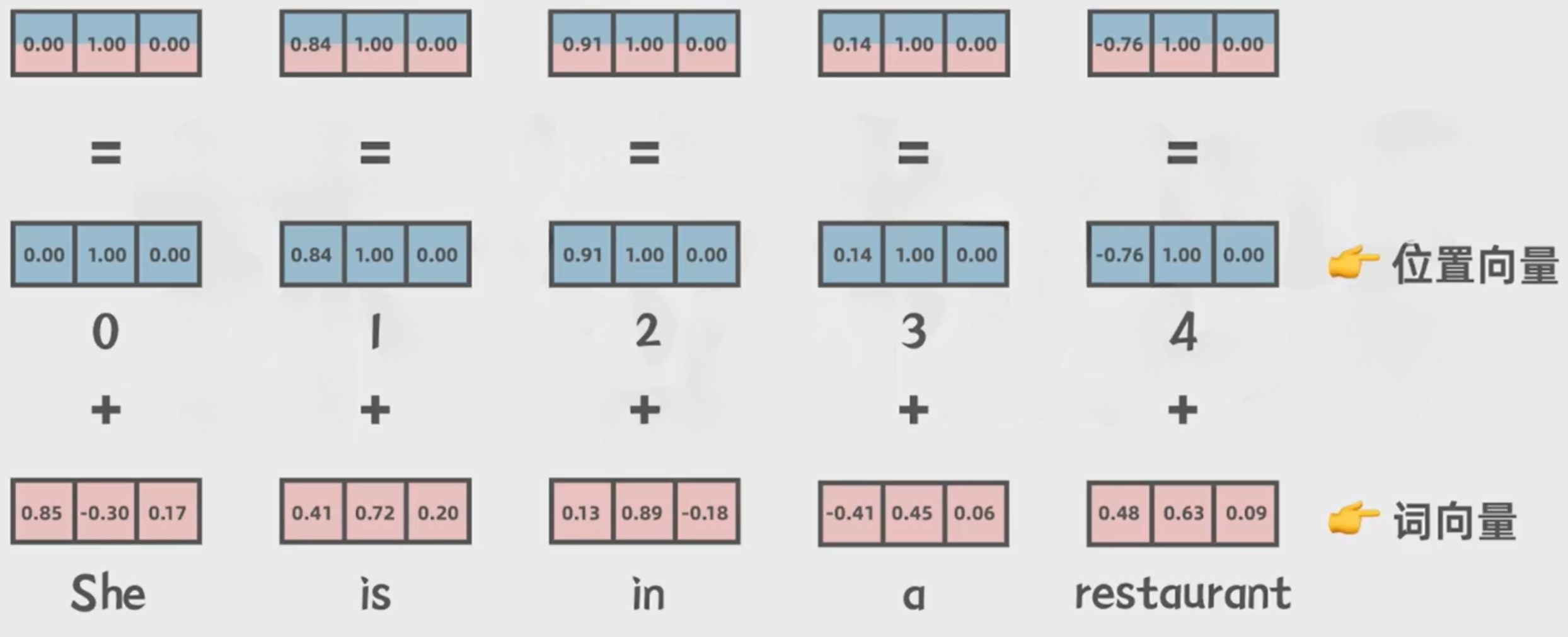
- 得到词向量后加上位置编码(Positional Encoding),让模型既理解语义又能捕捉词序
🧠 编码器核心:自注意力机制(Self-Attention)
- 编码器的核心是 自注意力机制:处理每个词时,不仅关注词本身和相邻词,还关注输入序列中所有其他词
- 正如论文标题所说——“Attention is All You Need”,注意力就是一切
- 通过计算每对词之间的相关性来决定注意力权重
- 例如:“The animal didn’t cross the street because it was too tired”
- “it” 与 “animal” 的关联更强,权重更大
- 输出结果中每个词的表示融合了上下文中的相关信息,同一个词在不同上下文有不同表示
🍎 多头注意力与前馈网络
- Transformer 使用多头自注意力(Multi-Head Attention)——多个并行的注意力"头"
- 每个头关注文本的不同特征:有的关注动词,有的关注修饰词,有的关注情感,有的关注命名实体
- 多个头之间并行运算,互不影响,权重在训练中从大量文本逐渐学习
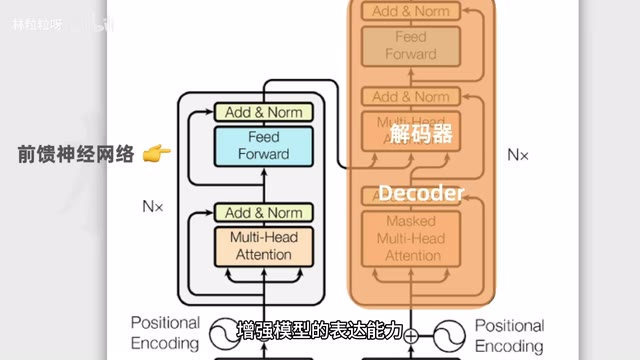
- 多头注意力后面有一个前馈神经网络(FFN),进一步增强模型表达能力
- 编码器实际上是多个堆叠在一起的,结构相同但权重不共享
🔑 解码器:逐词生成输出
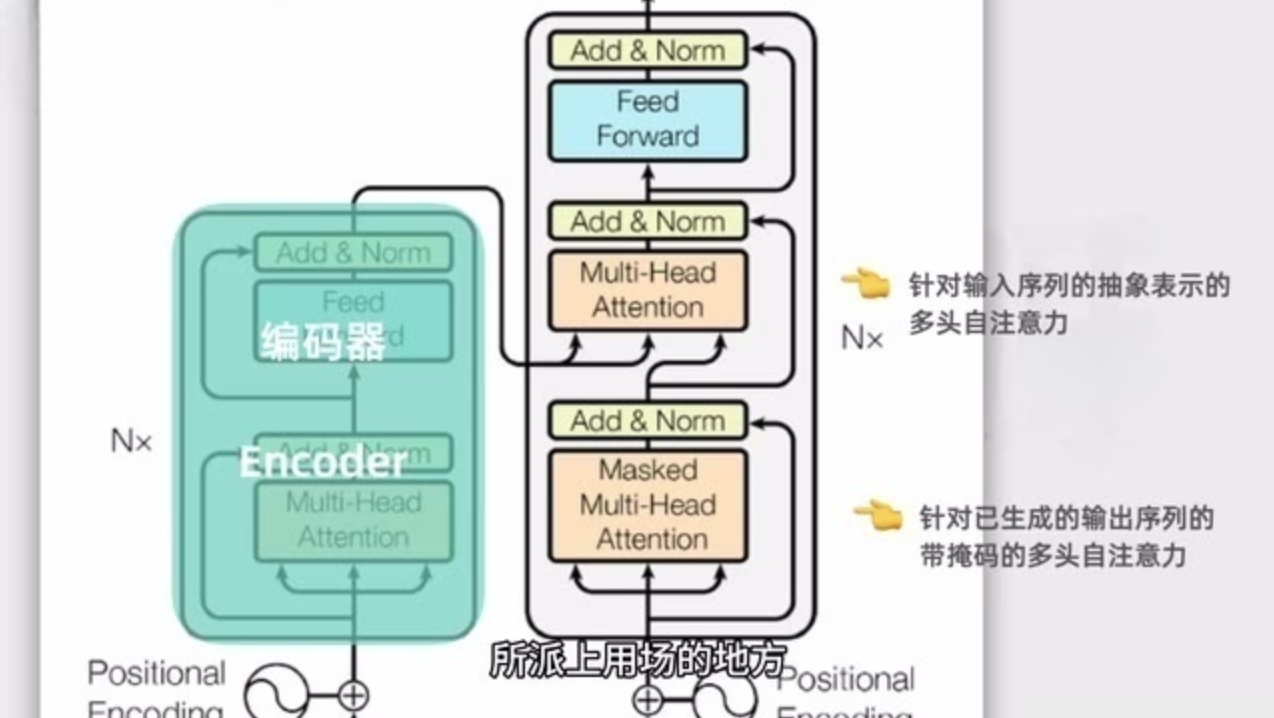
- 解码器是大语言模型生成一个个词的关键
- 接收编码器输出的抽象表示 + 之前已生成的文本作为输入
- 解码器中的自注意力是带掩码的(Masked):只关注当前词和前面的词,后面的词被遮住
- 确保生成时遵循正确的时间顺序,不能"偷看"后续内容
- 解码器还有额外的多头注意力层,捕捉编码器输出与解码器输出之间的对应关系
- 最后经过线性层 + Softmax 层,将输出转换为词汇表的概率分布
- 选择概率最高的 Token 作为下一个输出,重复直到生成结束标记
- 解码器本质上是在"猜"下一个最可能的输出,不保证客观事实——这就是幻觉(Hallucination)
🔢 三种 Transformer 变体

- 原始 Transformer 之后衍生出三种主要变体:
| 变体 | 别名 | 保留部分 | 代表模型 | 擅长任务 |
|---|---|---|---|---|
| 仅编码器 | 自编码器模型 | 编码器 | BERT | 语言理解(掩码语言建模、情感分析等) |
| 仅解码器 | 自回归模型 | 解码器 | GPT 系列 | 文本生成(预测下一个词) |
| 编码器-解码器 | 序列到序列模型 | 两者兼有 | T5、BART | 序列转换(翻译、摘要等) |

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)