45k Star 的 AI 编程神器:Claude Code / Codex / Cursor Token 一律打 2 折
👉 这是一个或许对你有用的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
-
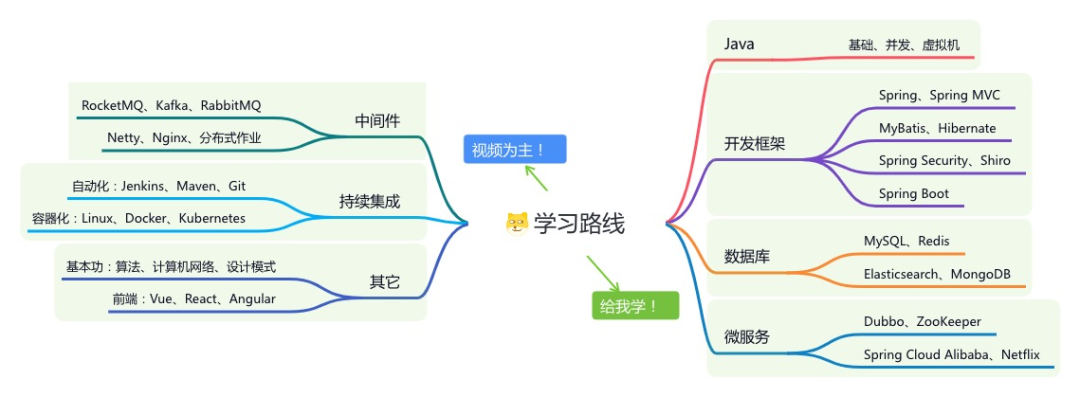
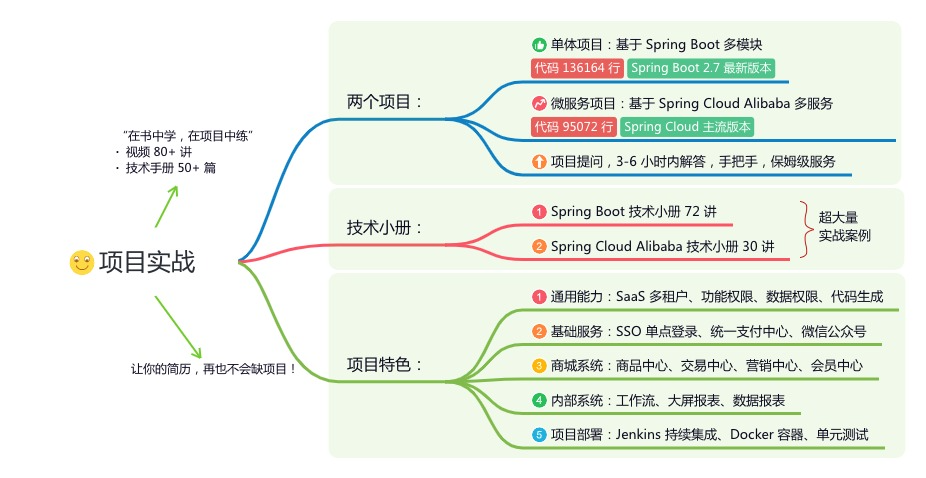
《项目实战(视频)》:从书中学,往事中“练”
-
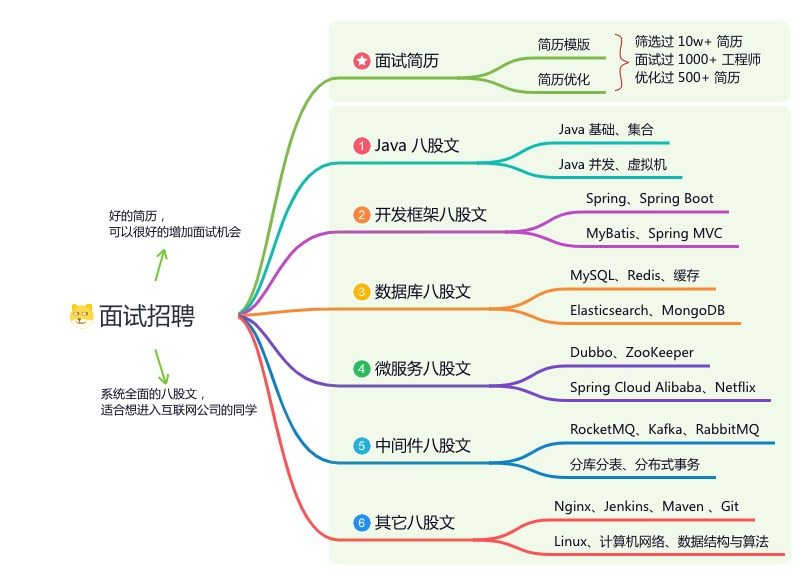
《互联网高频面试题》:面朝简历学习,春暖花开
-
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
-
《精进 Java 学习指南》:系统学习,互联网主流技术栈
-
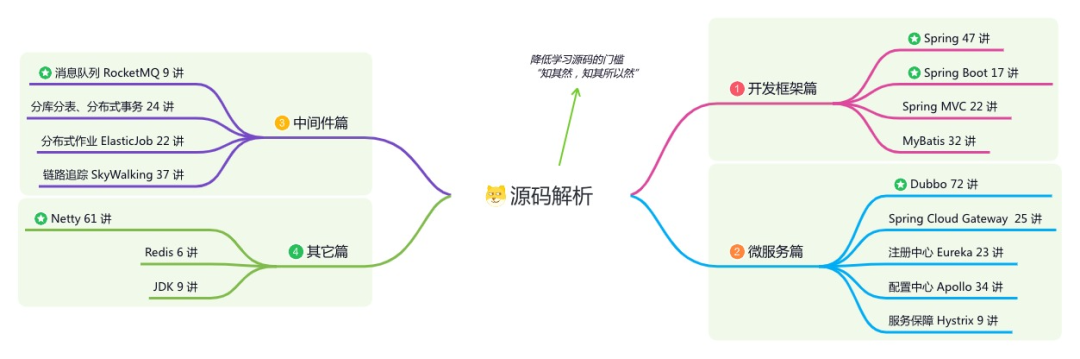
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
国产Star破10w的开源项目,前端包括管理后台、微信小程序,后端支持单体、微服务架构
RBAC权限、数据权限、SaaS多租户、商城、支付、工作流、大屏报表、ERP、CRM、AI大模型、IoT物联网等功能:
多模块:https://gitee.com/zhijiantianya/ruoyi-vue-pro
微服务:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK17/21+SpringBoot3、JDK8/11+Spring Boot2双版本

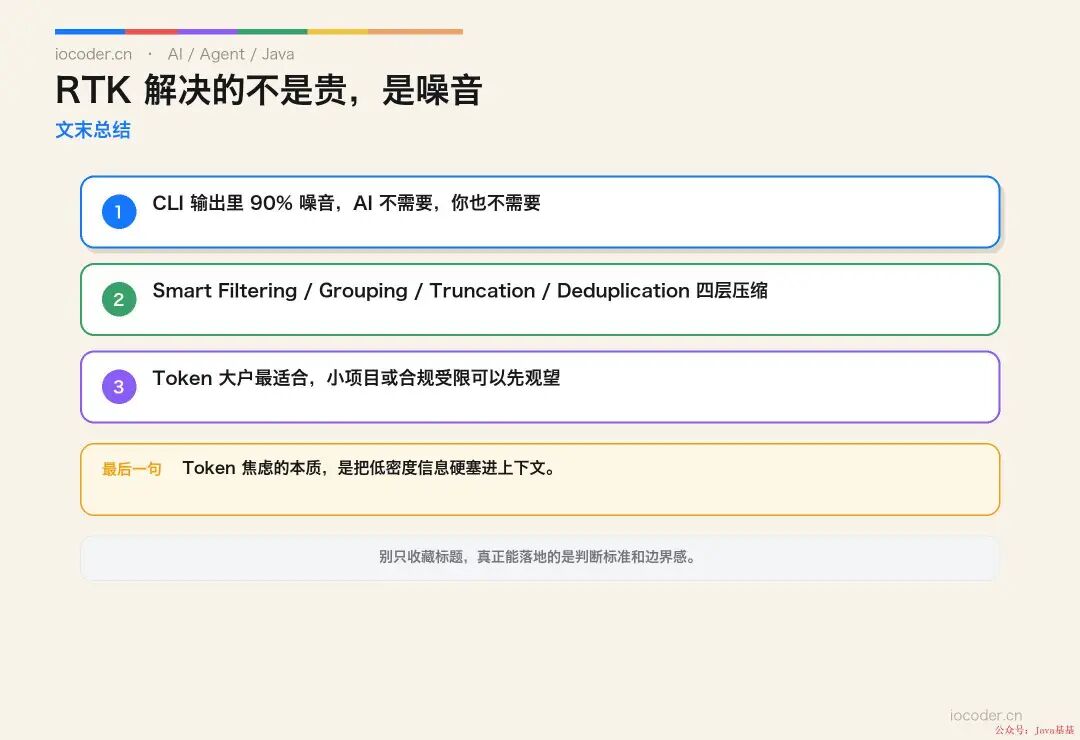
Token 烧不动了:让人崩溃的 4 类典型噪音
你用 Claude Code 重构 yudao-cloud 的某个核心模块,跑了一个 mvn deploy:
[INFO] Building yudao-module-system 2.0.0-SNAPSHOT
[INFO] ...(200+ 行依赖下载日志)
[INFO] [WARNING] /xxx 是不推荐的 API(第 17 次出现)
[INFO] [INFO] Compiling 1532 source files
[WARNING] Used native-image with --no-fallback...(10 次)
[INFO] BUILD SUCCESS整段 200 多行被原样塞进 Claude Code 上下文,有效信息可能就两行 :BUILD SUCCESS、还有最后那个 WARNING。
类似的灾难现场每天上演 4 类:
-
📦 Maven / Gradle 构建日志 — 同一条 WARNING 重复 17 次、依赖下载占了 80% 篇幅;
-
🧪 测试报告 — 几百个测试 case 全绿,给 AI 看就一行 "all passed" 足够;
-
📂
tree/ls -R— 列了几千个文件,其实 AI 只关心前 30 个; -
🐳 Kubernetes Pod 日志 — 启动初始化的 50 行噪音、应用真正异常的 3 行藏在第 47 行。
把这些未压缩的原文 全塞进 AI 上下文——每月 token 账单就是这么吃掉的 。
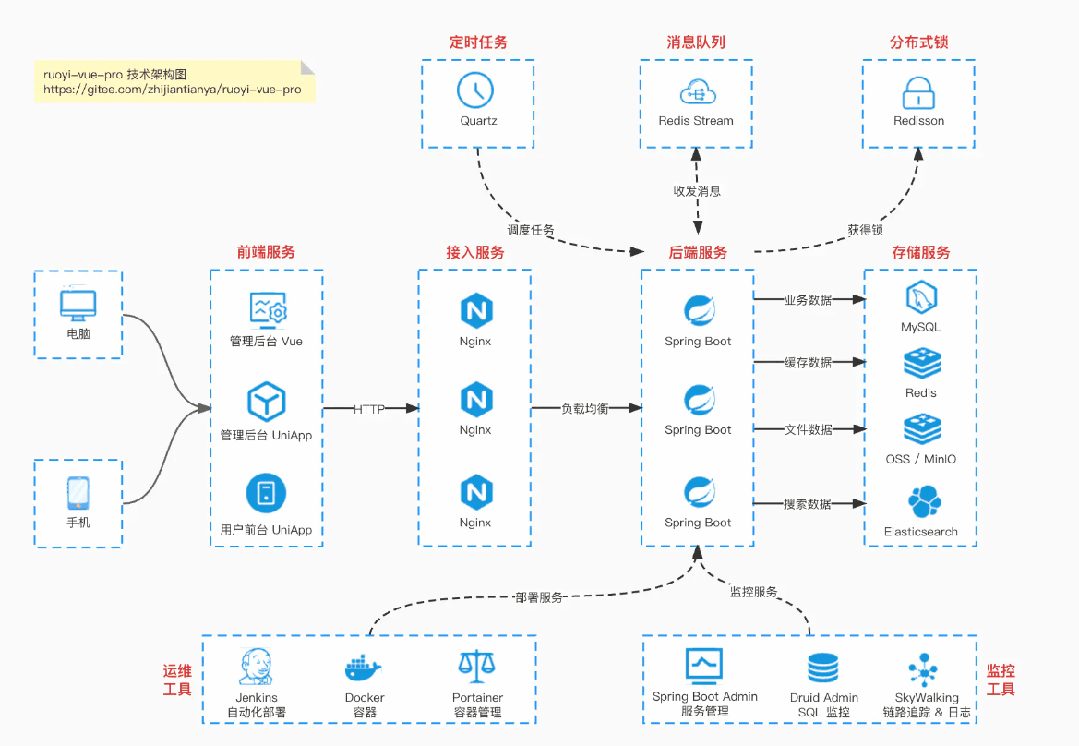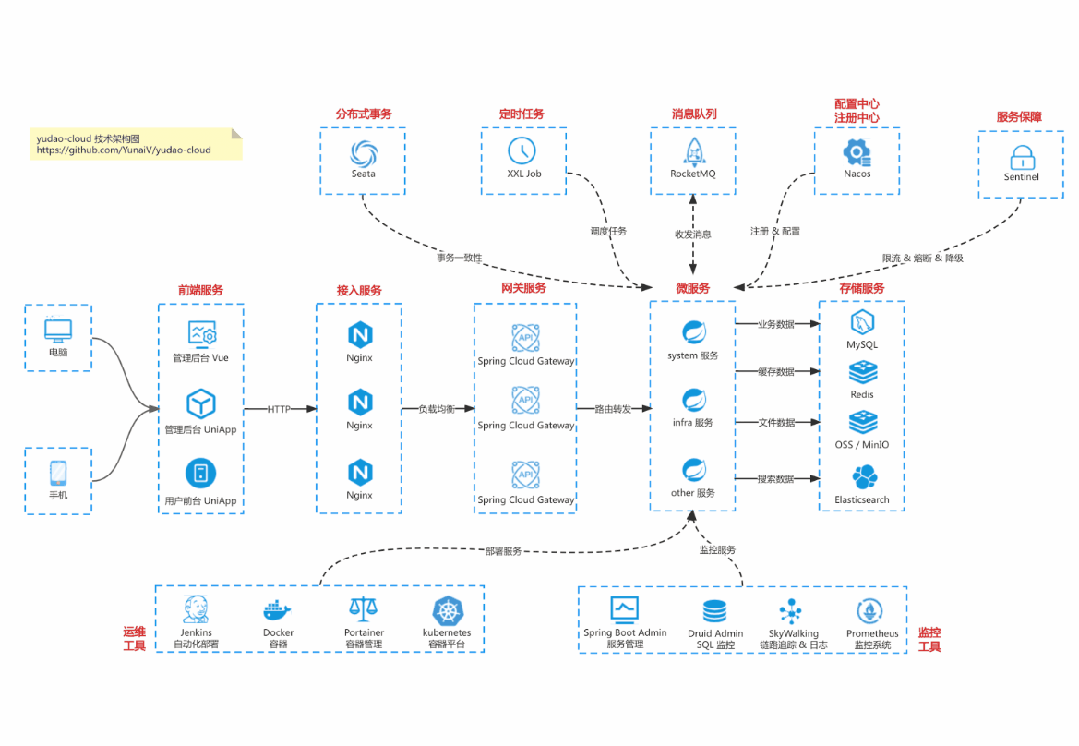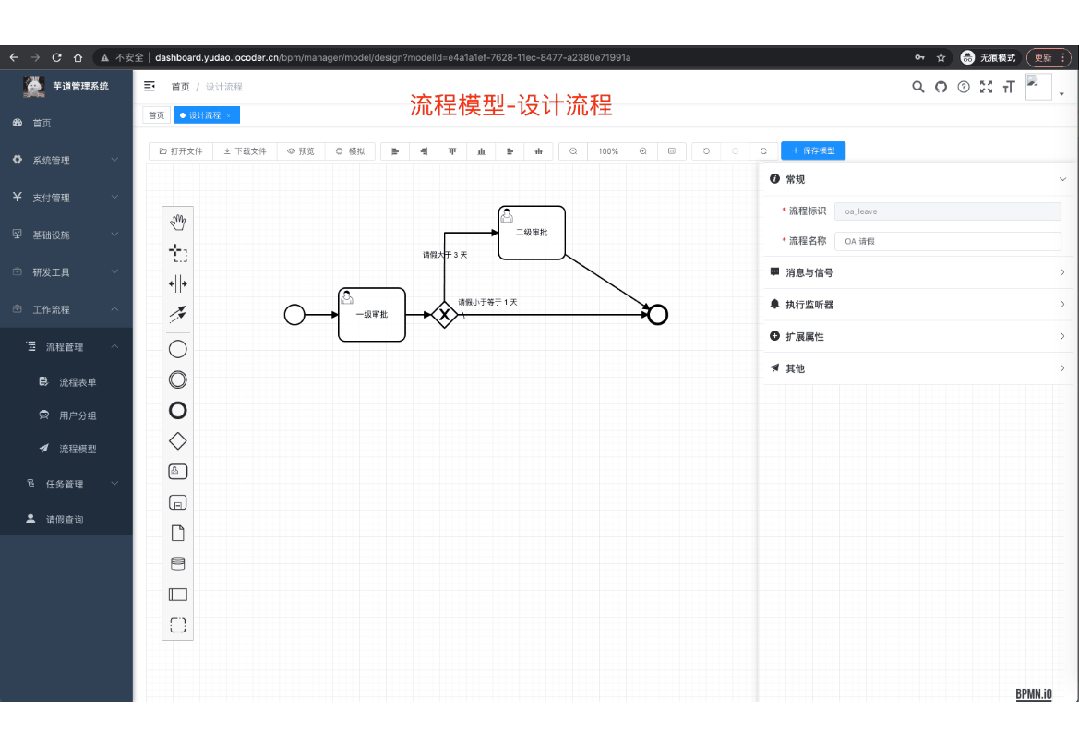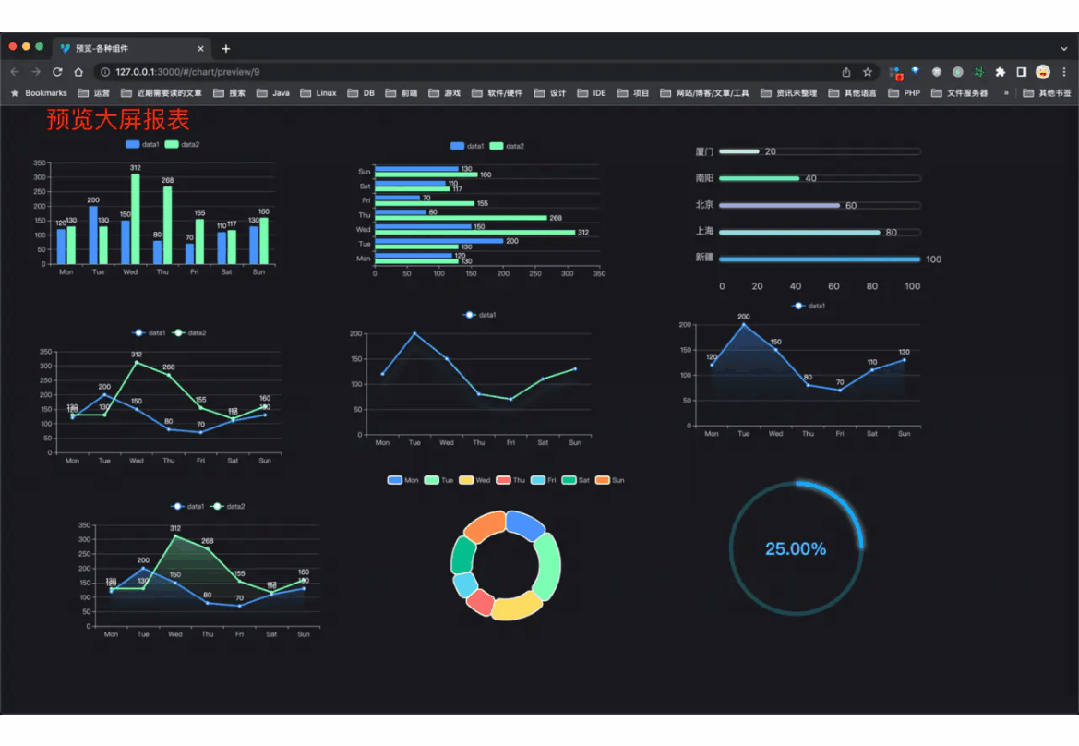
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
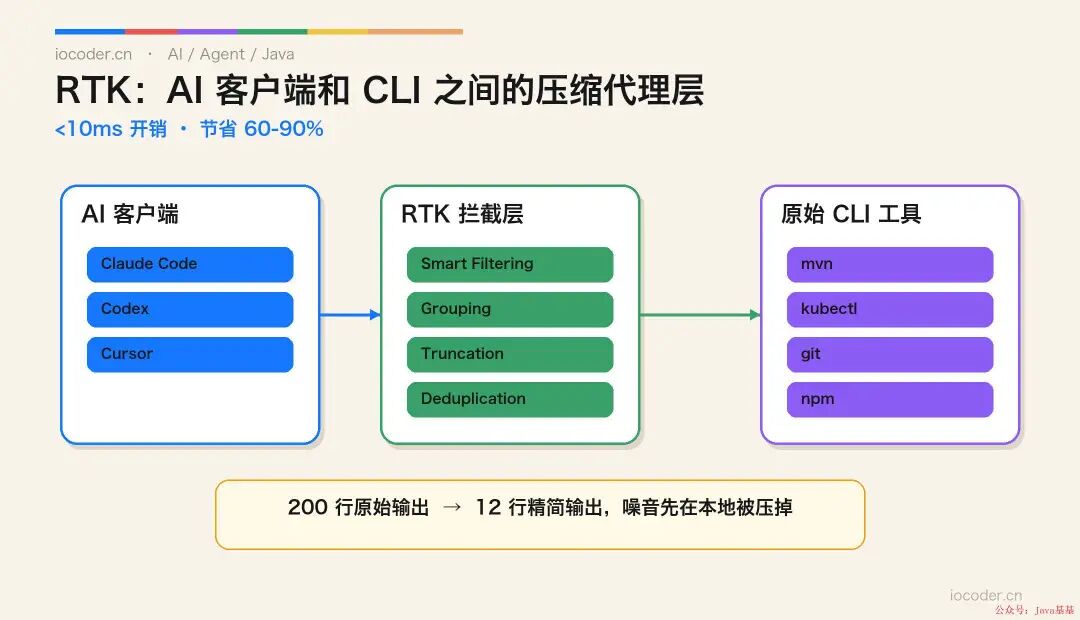
RTK 是什么:Star 半年从 16k 飙到 45k 的 Rust CLI 代理
RTK(Rust Token Killer) 是一个跑在你机器上的 CLI 代理 :拦截你 Claude Code / Codex / Cursor 调用的命令输出,用 4 层策略压缩成精简版 再返给 AI。官方 README 标的节省比例是 60-90% ——一次 30 分钟 Claude Code 会话,11.8 万 tokens 压缩到 2.39 万 。

仓库地址:https://github.com/rtk-ai/rtk
它最让我惊讶的是 Star 涨速 ——半年前文章里写的还是 16.3k,截至本文发稿已经 45.3k Star ——3 倍的涨速,社区在用脚投票。
它的设计哲学一句话 :*"Single Rust binary, 100+ supported commands, <10ms overhead"* —— 单一 Rust 二进制、100+ 命令支持、单次开销 <10ms。用 Rust 写就是为了快,每一次拦截不能拖慢你的工作流 。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
4 层压缩策略,每层针对一类噪音(来自官方 README)
下文 4 个策略名沿用 官方 README 的英文原话——是事实陈述,不二次发明。
策略 1:Smart Filtering(智能过滤)
"Removes extraneous content like comments and whitespace." — 官方 README
专杀注释、空白行、模板化样板代码 。Maven 输出里的 [INFO] Downloaded from central:... 一行没有信息量,全部干掉;测试输出里大段 OKOKOK 收敛成一行。
策略 2:Grouping(分组)
"Consolidates similar items (files by directory, errors by type)." — 官方 README
按维度归类相似项 。mvn test 报错时,10 个文件里出现同一个 NullPointerException——RTK 把它们按异常类型聚成一条,Claude Code 看到的是「在 10 个 service 里同一个 NPE」 ,而不是 10 段重复的 stack trace。
策略 3:Truncation(截断)
"Preserves relevant context while eliminating redundancy." — 官方 README
保留与当前任务相关的部分,砍掉冗余 。tree -L 3 列 5000 个文件,但 AI 这次只关心 yudao-module-system 子目录——RTK 智能保留这部分 + 砍掉无关分支。
策略 4:Deduplication(去重)
"Collapses repeated log entries with occurrence counts." — 官方 README
重复的日志合成一条 + 出现次数 。Pod 启动里的 Connection to Nacos established、Registering as health endpoint、Listening on 8080 这种每个 Pod 都打的样板日志 ——合并成一条带计数的,token 直接省 90%。
yudao-cloud 实测:4 个真实场景节省了多少 Token
我直接拿 https://github.com/YunaiV/yudao-cloud 跑了 4 个高频场景,前后对比是数量级差距 :
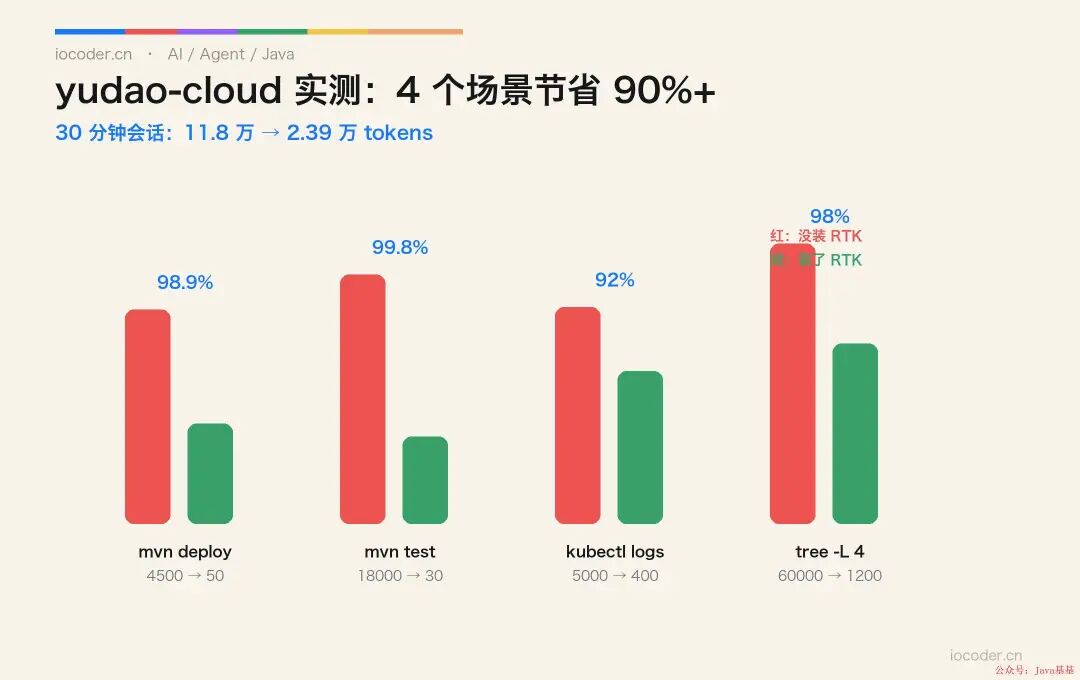
场景 1:Maven 多模块构建
mvn deploy -pl yudao-module-system -am-
没装 RTK :220 行输出 → 约 4500 tokens
-
装了 RTK :1 行 "BUILD SUCCESS" + 关键 WARNING 摘要 → 约 50 tokens
-
节省 98.9%
场景 2:Maven 测试套件
mvn test -pl yudao-module-system-
没装 RTK :800+ 行测试输出 → 约 18000 tokens
-
装了 RTK :1 行 "Tests: 412 passed, 0 failed" → 约 30 tokens
-
节省 99.8%
如果有失败的 case :RTK 不会粗暴砍掉——它保留所有失败的完整 stack trace ,但把成功的 412 个收敛成一条。
场景 3:Kubernetes Pod 启动日志
kubectl logs yudao-system-deployment-xxx-
没装 RTK :250 行启动日志(连 Nacos / 注册 / 端口监听 + 业务初始化) → 约 5000 tokens
-
装了 RTK :去重 + 分组后 → 约 400 tokens
-
节省 92%
场景 4:项目目录扫描
tree -L 4 ~/Java/yudao-cloud-
没装 RTK :4500 行目录树 → 约 60000 tokens
-
装了 RTK :智能截取目标子模块 → 约 1200 tokens
-
节省 98%
月度对比 :日常每天用 Claude Code 4 小时——月度 token 账单从 40 左右 。开 yudao-cloud 这种多模块大项目越省越多。
横向对比:和裸 Claude Code、其他省 Token 方案差在哪
|
方案 |
节省比例 |
配置成本 |
适用工具 |
致命短板 |
|---|---|---|---|---|
| RTK | 60-90% |
⭐ 一行命令 |
11+ 主流 AI 工具 |
必须装本地代理 |
| 手动复制粘贴 |
100%(懒得粘的话) |
⭐⭐⭐⭐⭐ 累 |
全部 |
放弃自动化 |
| 更小的 prompt(写更短) |
10-20% |
⭐⭐ |
全部 |
信息丢失风险 |
| 换便宜模型(Haiku) |
50% |
⭐⭐ |
部分支持 |
能力下降一档 |
| 裸用 Claude Code |
0% |
⭐ |
全部 |
token 烧得最快 |
RTK 的真正定位 :不是让你换模型 / 换工具,是在你现有工作流前面加一道压缩层 ——AI 客户端不变、模型不变、工作方式不变,只是输出在送到 AI 前先精简一遍 。
一行命令装好:3 种安装方式
按推荐度排:
# 方式 1(推荐):Homebrew
brew install rtk
# 方式 2:Shell 脚本一键安装(macOS / Linux / WSL)
curl -fsSL https://raw.githubusercontent.com/rtk-ai/rtk/refs/heads/master/install.sh | sh
# 方式 3:cargo install(Rust 开发者)
cargo install --git https://github.com/rtk-ai/rtk装完后自动在 Bash 里挂 hook ——不用改任何 Claude Code / Cursor 配置,命令执行时会自动经过 RTK 这一层。透明无感 。
想验证装好了 :跑
rtk doctor会列出当前已经接管的命令、压缩比例统计、性能开销。
支持的 11 款 AI 工具
按 README 完整清单:
|
工具 |
是否官方支持 |
|---|---|
| Claude Code |
✅ |
| Codex
(OpenAI) |
✅ |
| Cursor |
✅ |
| GitHub Copilot CLI |
✅ |
| GitHub Copilot for VS Code |
✅ |
| Gemini CLI |
✅ |
| Windsurf |
✅ |
| Cline / Roo Code |
✅ |
| OpenCode |
✅ |
| OpenClaw |
✅ |
| Kilo Code |
✅ |
| Google Antigravity |
✅ |
11 款里的主流 CLI Agent 基本全覆盖 ——不论你团队选了哪一款,RTK 都能进来当压缩层。
我的判断
省 Token 这件事这两年方案有一堆——但 RTK 走的路最聪明:它不让你改习惯 。
适合用的几种情况 :
-
每天用 Claude Code / Codex / Cursor 4 小时以上 ——一个月 ROI 超明显;
-
在 yudao-cloud / Spring Cloud 这类多模块大项目 里——压缩效果最猛;
-
团队有人在烧 Token 套餐配额——一行命令能让套餐 1 个月用 3 个月 。
不太建议入坑的几种情况 :
-
一个月 Token 用量 < $20——节省的钱不够你折腾;
-
项目极小、命令输出本来就短——压缩空间不大;
-
公司禁止本地装第三方代理工具——合规优先。
说到底 :Token 焦虑的本质是信息密度问题 ——你每发一个请求里夹了 90% 的噪音、AI 不需要、你也不需要看,白白烧掉的钱 。RTK 这种"在工作流前加压缩层"的思路,未来一年应该会成为 Agent 标配组件 ——这条路对了。

仓库:https://github.com/rtk-ai/rtk
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)