用 DeepSeek 写代码,成本降到 1/5 ——这个开源工具把 prefix cache 玩明白了。
摘要:DeepSeek-Reasonix 是一个专为 DeepSeek 深度工程化的终端编程代理,通过 Cache-First Loop 架构让长会话 cache hit 率稳定在 94% 以上。真实用户单日 4.35 亿 token,只花了 $12。MIT 开源,13.9K+ Stars,值得每个用 DeepSeek 写代码的人试试。

你有没有遇到过这种情况
用 AI 编程工具做一个稍微复杂的项目,上下文越来越长,token 账单越来越贵,但工具的响应却越来越"失忆"——前面说好的架构,后面忘得一干二净。
我之前就是这个状态。用着各种 coding agent,要么贵、要么慢、要么上下文一长就开始胡说。
直到我发现了 Reasonix。
Reasonix 是什么
全名 DeepSeek-Reasonix,一句话:专门为 DeepSeek 深度工程化的终端 AI 编程代理。
重点在"专门"两个字。
市面上大多数 coding agent 是"通用"的——支持 OpenAI、Claude、DeepSeek,哪个模型都能接。听起来灵活,实际上是什么都能用、什么都没用好。
Reasonix 反其道而行之,只支持 DeepSeek,但把 DeepSeek 的 prefix cache 机制发挥到了极致。
结果就是:长会话成本低得离谱。
先看一个真实数据
2026 年 5 月 1 日,一位真实用户的单日使用记录:
-
输入 token:4.35 亿
-
Cache hit 率:99.82%
-
实际花费:~$12
-
同等无缓存负载(DeepSeek v4-flash):~$61
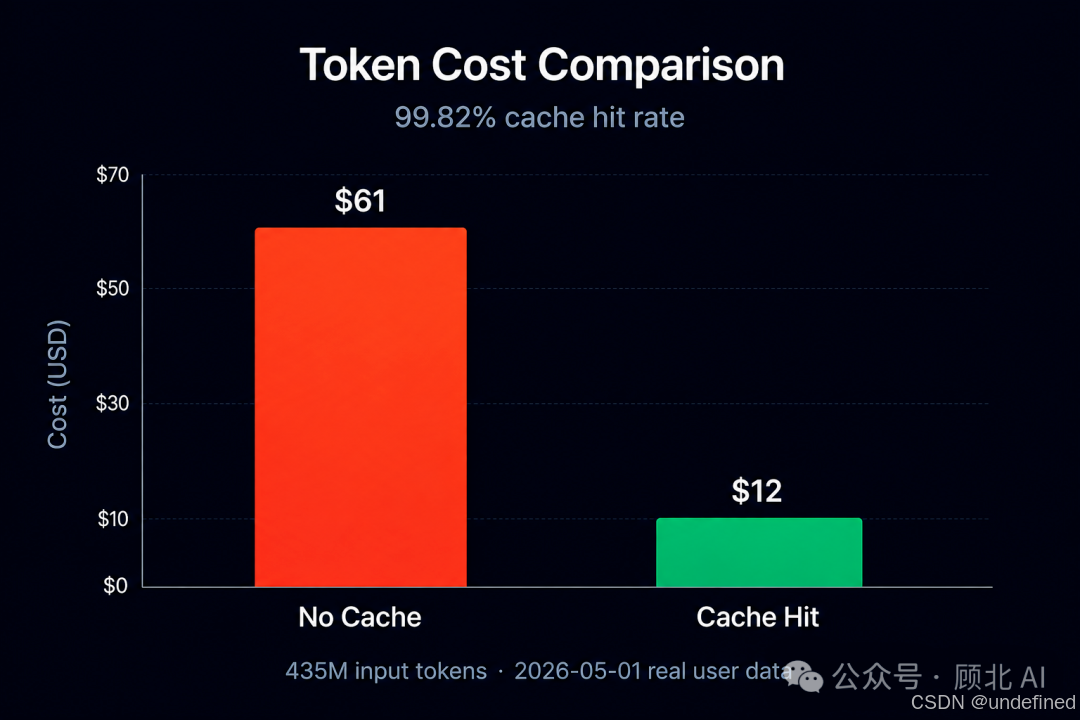
省了将近 5 倍的钱。不是优化了几个百分点,是数量级的差距。
这不是广告文案里的"最高可达",是实测数据,项目里有完整的 benchmark 和计算方法,可以自己去验证。
为什么能做到这一点?三个核心机制
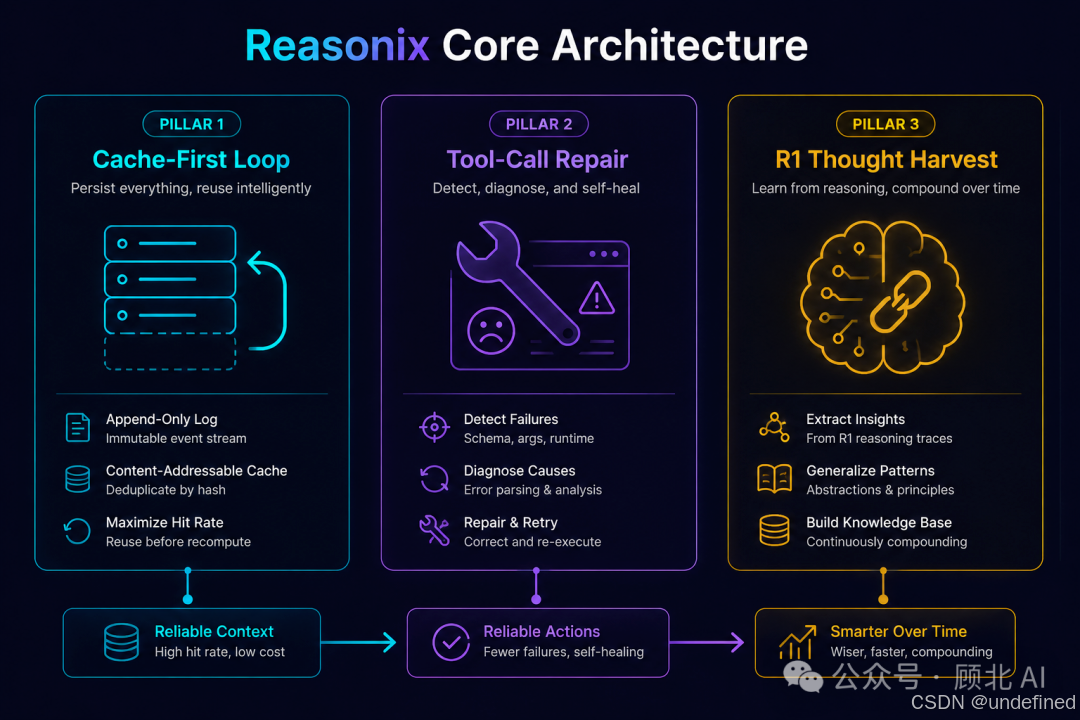
1. Cache-First Loop:追加式循环,不动历史
DeepSeek 的 prefix cache 原理是:从第 0 个字节开始对 prompt 做指纹。只要历史消息一字不改,后续请求就能命中缓存,费率直接降到 1/5。
问题来了:大多数 agent 框架为了控制上下文长度,会定期压缩、重排、截断历史消息。这一动,字节就变了,缓存就废了。
Reasonix 的解法很直接——历史消息只追加,绝不修改:
-
消息和工具结果全部 append,从不 mutate
-
不依赖
cache_control之类的触发标记 -
工具调用顺序和时间戳全部确定性处理
-
结果:就算跑了几十轮工具调用,prefix 依然命中
这是整个项目的核心设计哲学,README 里原话是:"Cache stability isn't a feature you turn on; it's an invariant the loop is designed around."
2. Tool-Call Repair:LLM 输出错了,自动修
LLM 有时候会输出格式不对的工具调用——JSON schema 错误、字段缺失、类型不匹配。普通 agent 遇到这种情况要么直接报错,要么触发新一轮重试(成本翻倍)。
Reasonix 内置了一个 schema 感知的自愈机制:检测到格式错误,自动修复,不走重试流程,不打断当前会话,也不破坏已缓存的 prefix。
3. R1 Thought Harvest:捡起推理链里的工具调用
DeepSeek R1 系列模型有个特点:思维链(chain-of-thought)里有时候会"逸出"工具调用——模型在推理过程中想到了要调用某个工具,但没有走正规的 tool_call 路径输出。
Reasonix 会主动扫描推理链,把这些逸出的工具调用捡回来执行。对使用 R1 类模型的场景,这个机制能让模型的实际能力发挥更完整。
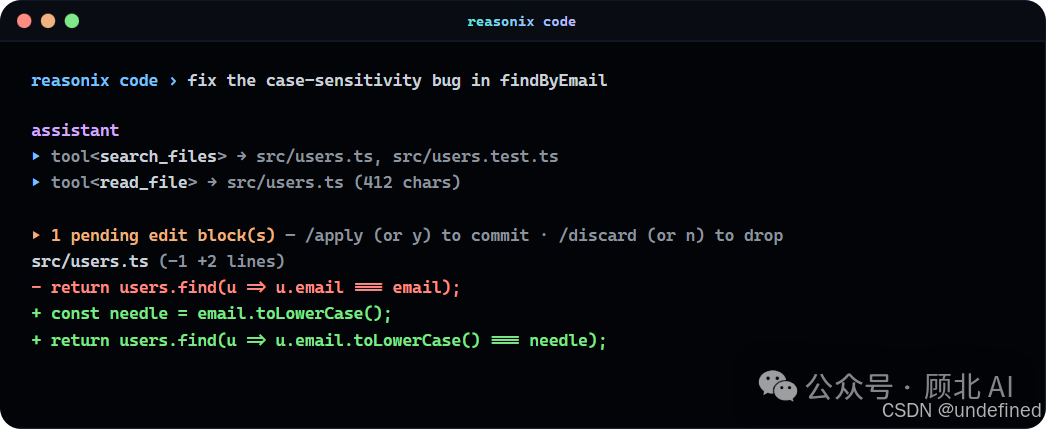
快速上手,5 分钟跑起来
需要 Node ≥ 22,支持 macOS / Linux / Windows。
最简单的方式,不需要全局安装:
cd my-project
npx reasonix code
第一次运行会引导你填入 DeepSeek API Key,填完就存下来了,下次直接用。
如果你每天都用,装全局更省事:
npm install -g reasonix
reasonix code my-project
几个常用命令:
|
命令 |
用途 |
|---|---|
reasonix
/ |
启动编程代理(最常用) |
reasonix chat |
纯对话模式,不带文件系统工具 |
reasonix run "任务描述" |
一次性执行,输出流到 stdout |
reasonix doctor |
检查环境、API key、MCP 配置 |
进入 TUI 之后,几个核心的 slash 命令:
-
/pro:当前这轮切到 V4-Pro(贵但强),其他轮还是 Flash -
/preset max:整个会话都用 Pro -
/plan:进入只读审计模式,所有修改需要你批准才写入 -
/skill new my-skill:新建一个 Skill(Markdown 脚本)
DeepSeek API 费用参考:
-
V4-Flash:0.014/Mtok(缓存命中)**
-
长会话下,实际费率基本锁定在缓存价,成本通常只有通用工具的 1/3
和其他工具比,区别在哪
说实话,现在 coding agent 满天飞,我来直接对比几个常见工具:
|
Reasonix |
Claude Code |
Cursor |
Aider |
|
|---|---|---|---|---|
|
后端模型 |
DeepSeek(专用) |
Anthropic |
OpenAI/Anthropic |
任意 |
|
开源协议 |
MIT |
闭源 |
闭源 |
Apache 2 |
|
运行方式 |
终端 TUI |
终端 |
IDE 插件 |
终端 |
|
成本 |
极低 |
较贵 |
订阅制 |
不一 |
|
DeepSeek prefix cache |
深度工程化 |
不适用 |
不适用 |
偶然命中 |
|
嵌入式 Web 仪表板 |
✓ |
— |
IDE 内置 |
— |
|
MCP 支持 |
✓ |
✓ |
✓ |
部分 |
几点补充说明:
Claude Code 的优势:Claude Opus 在某些复杂推理任务(比如解数学题、写高难度算法)上还是比 DeepSeek 强。如果你的工作是"解 PhD 级别的问题",Reasonix 自己的 README 都说了,去用 Claude。
Reasonix 的甜区:日常编程任务——修 bug、重构、加功能、写测试。这些场景 DeepSeek 足够用,成本还低得多。
关于"DeepSeek 专用":这是设计选择,不是妥协。Reasonix 自己的表述是:把 DeepSeek 用到极致,比通用工具勉强支持 DeepSeek 要有用得多。我认为这个判断是对的。

还有些细节值得一提
Desktop 桌面客户端:基于 Tauri 构建,多标签、右侧面板显示当前会话读/写的文件、底部有实时成本/缓存/token 计数。用同一个 ~/.reasonix config,不需要额外配置。目前是 prerelease 状态,Windows 上会有 SmartScreen 警告,点"仍要运行"即可。
QQ 频道支持:可以把 QQ 频道接入当前会话——手机在外面发消息,AI 在你电脑上继续工作,回复直接推回 QQ。这个功能对国内用户挺实用的。
Skills 系统:在 .reasonix/skills/ 下放一个 Markdown 文件,就是一个可调用的 Skill。支持 runAs: subagent 在独立子循环里执行,不污染主会话上下文。Claude Code 格式的 skills 也能直接加载,兼容性不错。
会话隔离:所有文件工具默认沙箱在启动目录,不会乱改你的文件。/plan 模式下更严格,修改全部 pending,你 /apply 才真正写入。
我的判断
对于每天用 DeepSeek 写代码的人,Reasonix 值得花 10 分钟装上试试。
它不是银弹,也明确说了自己的边界:不支持多模型、不做 IDE 插件、需要付费 API key。但在它瞄准的这个场景里——用 DeepSeek 做日常编程——它把成本和稳定性这两件事做得比我见过的任何工具都扎实。
13K+ Stars、80+ 贡献者、32 个 release、还在活跃开发中,社区也在积极讨论下一步方向。MIT 协议,代码全公开,不用担心哪天突然收费或者关门。
项目地址:https://github.com/esengine/DeepSeek-Reasonix
你用过类似的 AI 编程工具吗?有什么用下来觉得特别顺手或者特别坑的,欢迎评论区聊聊。
我是顾北,关注我,获取更多好玩有趣的开源仓库!
谢谢你阅读我的文章~
我们下期再见!
PS:本文部分内容由AI辅助创作

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 10
10 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)