初学者入门大模型之大模型知识增强:数据层注入(Prompt)、模型层注入(Finetune)、推理层注入(RAG)
通用大模型(如DeepSeek、Qwen)虽具备广泛的知识覆盖和基础推理能力,但仍存在以下局限性:(1)知识短板:难以覆盖细粒度、动态更新的事实(如罕见病治疗方案、最新指南);(2)逻辑薄弱:在复杂推理链、反常识逻辑或伦理判断中表现不足;(3)领域偏科:在医疗、金融等专业领域,需垂直模型辅助才能满足高精度需求。
通用大模型(如DeepSeek、Qwen)虽具备广泛的知识覆盖和基础推理能力,但仍存在以下局限性:
(1)知识短板:难以覆盖细粒度、动态更新的事实(如罕见病治疗方案、最新指南);
(2)逻辑薄弱:在复杂推理链、反常识逻辑或伦理判断中表现不足;
(3)领域偏科:在医疗、金融等专业领域,需垂直模型辅助才能满足高精度需求。
通过大模型的知识注入——数据层注入(Prompt)、模型层注入(Finetune)、推理层注入(RAG),可显著提升模型在特定场景下的表现。
一、数据层注入(Prompt)
数据层注入——知识“拌饭法”
通过将领域知识或任务指令“拌入”输入提示中,使模型在无需修改结构的情况下吸收新知识,以极简方式引导模型生成精准响应。
(1)核心目标
以数据为载体,让模型在训练或推理时‘吃’到知识”,类似将调味料拌入米饭(数据)中。
(2)实现思路
数据层注入(知识“拌饭法”)就是我们常提到的提示词工程,使模型在无需结构修改的情况下吸收新知识。
就像你请朋友帮忙时需要说清楚“要做什么、怎么做、要什么结果”,提示词工程就是教大语言模型(LLM)如何理解你的需求,就****是你给LLM的“任务说明书”。
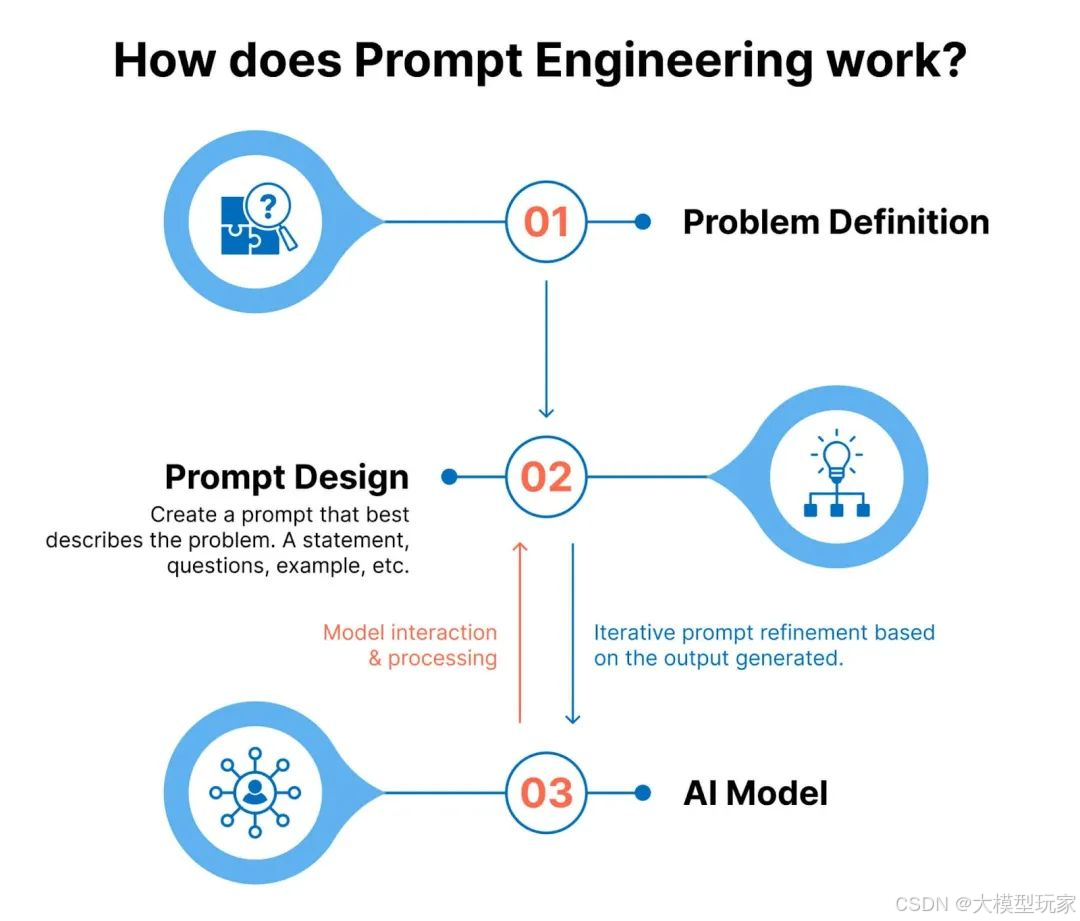
(3)提示词工程(Prompt Engineering)
提示词工程大家再熟悉不过,每天都在使用。通过设计输入提示(Prompt),引导模型利用外部知识回答问题。
它就像“用对话技巧提升效率”——日常工作中,无论是让AI查资料时加限定条件,还是写报告时调整提问方式,本质上都是通过“优化输入”(数据层注入)来引导输出。
例如:设计包含领域知识的提示模板(如“根据《民法典》第XX条,该合同条款应______”)。

二、模型层注入(Finetune)
模型层注入——知识“硬件升级”
通过直接修改模型底层的知识库或参数结构,让模型从“出厂设置”进化为“领域专家”,实现更高效、更精准的知识调用。
(1)核心目标
修改模型参数或结构,将知识固化到神经网络中,相当于给模型进行“硬件升级”。
(2)实现思路
模型层注入(知识“硬件升级”)就是我们常提到的模型微调(Fine-tuning),本质上是给预训练模型“定制化升级”——通过在特定领域数据上进一步训练,让模型从“通才”变成“专家”。
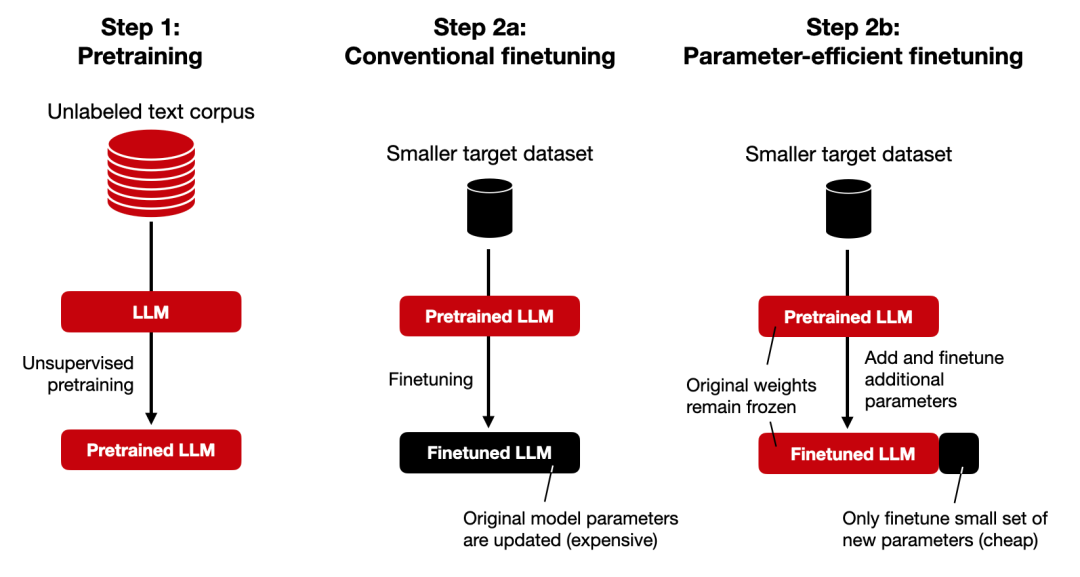
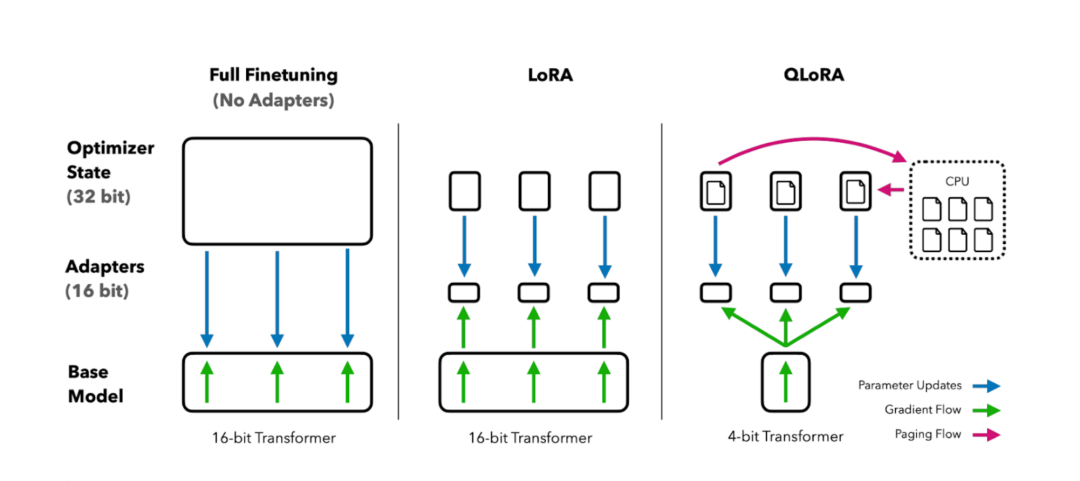
(3)PEFT(参数高效微调)
模型微调常用的方法是PEFT(参数高效微调),通过仅优化模型的部分参数(如低秩矩阵、适配器)而非全量参数,以极低成本实现模型在特定任务上的高效适配。
方法一:LoRA(Low-Rank Adaptation)
在预训练模型的权重矩阵中引入低秩矩阵(参数减少90%以上),通过优化这些低秩矩阵来实现微调,而无需对整个模型进行大幅度修改。
方法二:QLoRA(Quantized Low-Rank Adaptation)
结合LoRA与量化技术,将预训练模型量化为低精度(如4位),同时保持模型精度的最小损失。
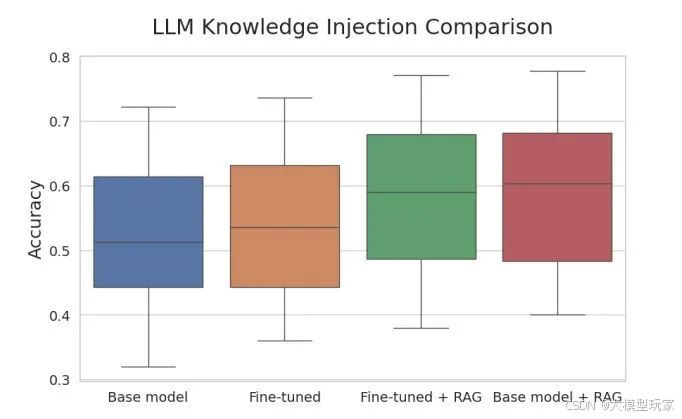
三、推理层注入(RAG)
推理层注入——知识“实时外挂”
通过动态检索外部知识库,实时将最新信息拼接到输入提示中,大语言模型就从“死记硬背答案”进化成“边查资料边写作文”。输出内容既专业精准,又自然流畅,彻底告别“一本正经胡说八道”(已读乱回)。
(1)核心目标
在模型生成答案时,动态检索外部知识库,并将检索结果实时拼接至输入提示中,相当于给模型安装“实时外挂”。
(2)实现思路
推理层注入(知识“实时外挂”)就是我们常提到的RAG(检索增强生成),通过将用户提问向量化→检索知识库→返回相关片段,然后将“问题+检索结果”输入大模型生成答案。
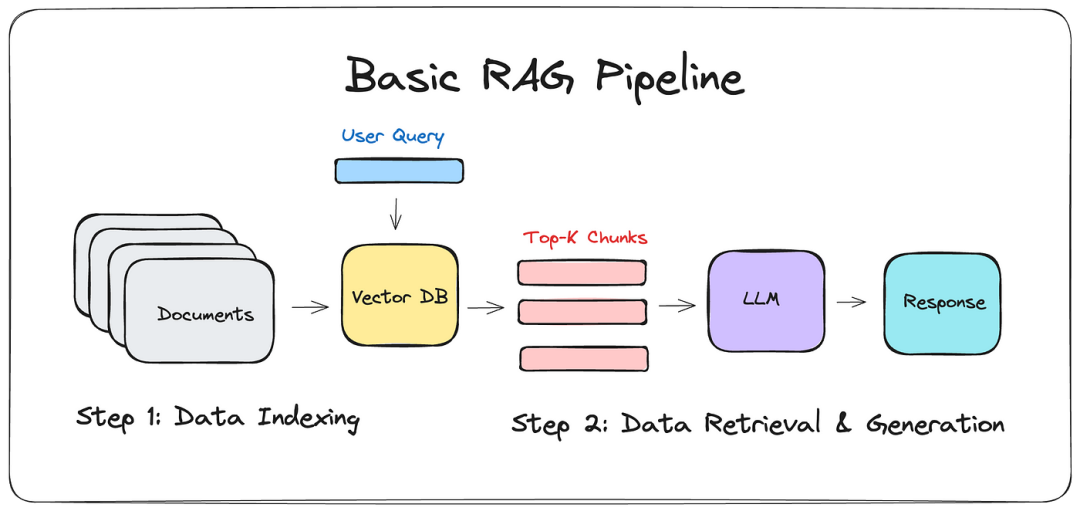
(3)RAG(检索增强生成)
RAG(检索增强生成,Retrieval-Augmented Generation)通过结合信息检索和生成技术,使得大语言模型能够实时从外部知识库中检索相关信息,并将这些信息拼接到输入提示中,从而生成更加准确和有用的回答或文本。
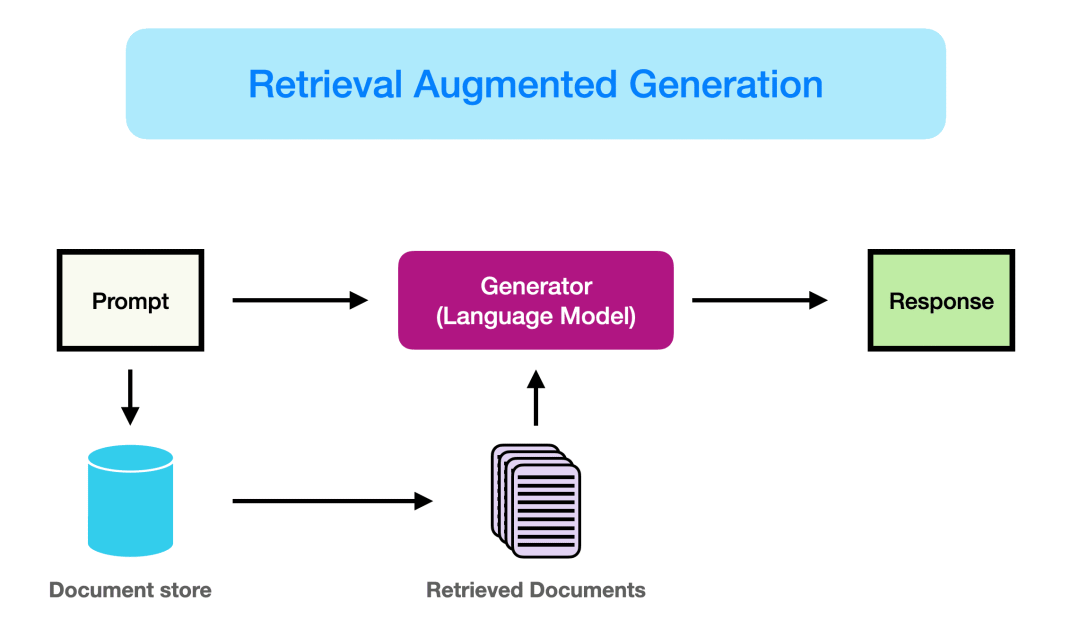
- 检索(Retrieval):从外部知识库中精准抓取与问题高度相关的信息片段,为生成提供实时知识依据。
- 增强(Augmented):将检索到的信息拼接到输入提示中,为生成模型注入外部知识,增强回答的专业性和准确性。
- 生成(Generation):结合检索到的信息和原始问题,通过生成模型输出连贯、自然且准确的回答或文本。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献552条内容
已为社区贡献552条内容

所有评论(0)