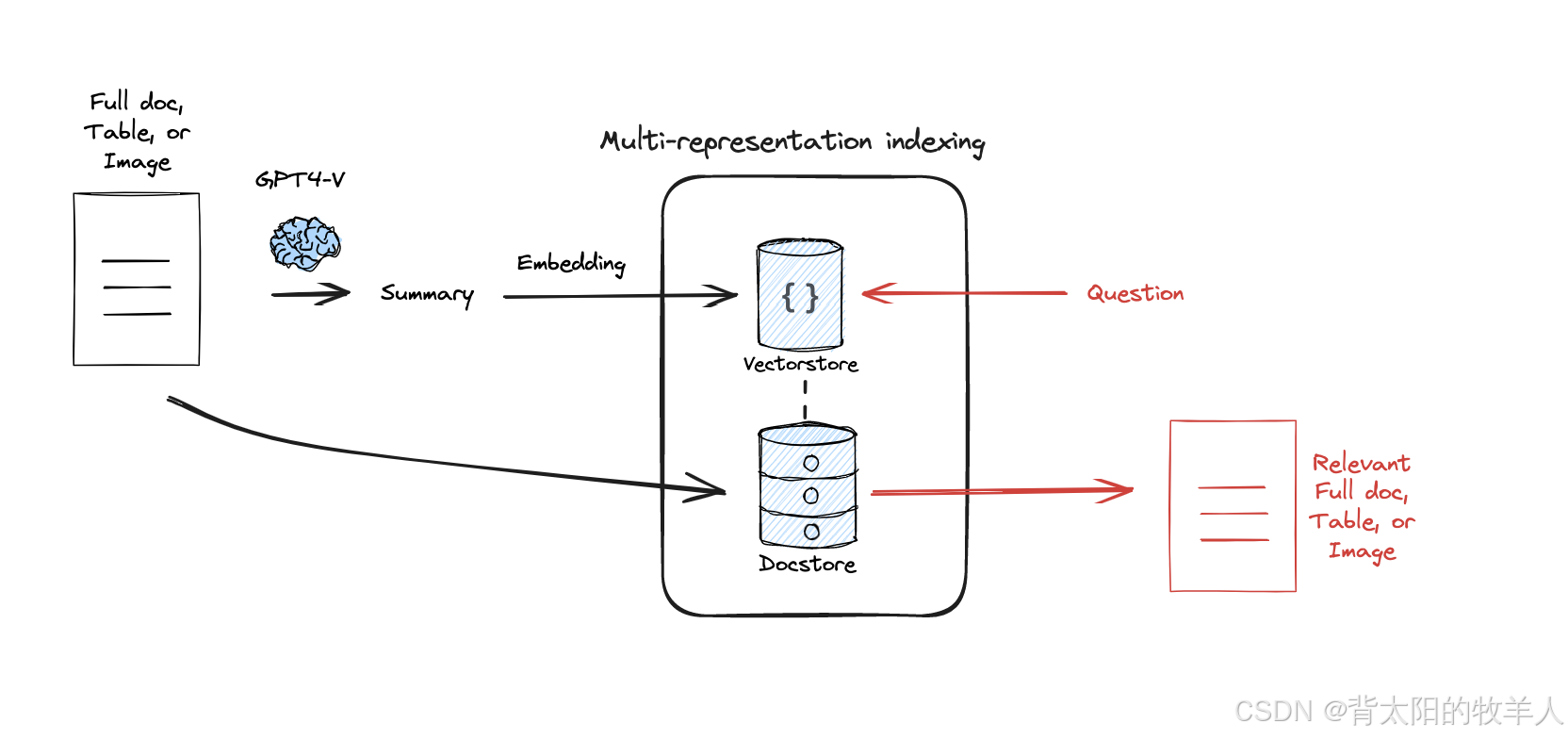
利用 LangChain 进行多向量索引(Multi-representation Indexing)
**利用 LangChain 进行多向量索引(Multi-representation Indexing)**,通过从网页爬取文章,生成摘要,并使用向量数据库(Chroma)存储摘要,同时维护原始文档的存储,以便实现高效检索。
利用 LangChain 进行多向量索引(Multi-representation Indexing),通过从网页爬取文章,生成摘要,并使用向量数据库(Chroma)存储摘要,同时维护原始文档的存储,以便实现高效检索。
完整示例代码如下:
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_PROJECT'] = 'advanced-rag'
os.environ['LANGCHAIN_API_KEY'] = os.getenv("LANGCHAIN_API_KEY")
os.environ['GROQ_API_KEY'] = os.getenv("GROQQ_API_KEY")
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
import os
# 设置一个常见的浏览器 User-Agent 字符串
os.environ["USER_AGENT"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
loader = WebBaseLoader("https://www.36kr.com/p/3175118078316933")
docs = loader.load()
loader = WebBaseLoader("https://www.36kr.com/p/3174699772215686")
docs.extend(loader.load())
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_groq import ChatGroq
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("总结以下文档:\n\n{doc}")
| ChatGroq()
| StrOutputParser()
)
summaries = chain.batch(docs, {"max_concurrency": 1})
from langchain.storage import InMemoryByteStore
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-small-zh-v1.5"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
hf_embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="summaries",
embedding_function=hf_embeddings)
# The storage layer for the parent documents
store = InMemoryByteStore()
id_key = "doc_id"
# The retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
doc_ids = [str(uuid.uuid4()) for _ in docs]
# Docs linked to summaries
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)
]
# Add
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
retriever.docstore.mget(doc_ids)
query = "恒宇医疗近年来在IVUS和OCT产品的商业化驱动"
sub_docs = vectorstore.similarity_search(query,k=1)
sub_docs[0]
retrieved_docs = retriever.get_relevant_documents(query,n_results=1)
retrieved_docs[0].page_content[0:500]
代码详细解析(按模块拆解)
1. 加载环境变量
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
作用:
find_dotenv()用于找到.env文件的路径(如果存在)。load_dotenv()读取.env文件中的环境变量,比如 API Key。
举例:
假设 .env 文件里有:
LANGCHAIN_API_KEY=my-secret-key
GROQQ_API_KEY=my-groq-key
那么,执行 load_dotenv() 后,代码可以通过 os.getenv("LANGCHAIN_API_KEY") 访问这个 Key,而不用直接在代码里写死(提高安全性)。
2. 设置环境变量
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_PROJECT'] = 'advanced-rag'
os.environ['LANGCHAIN_API_KEY'] = os.getenv("LANGCHAIN_API_KEY")
os.environ['GROQ_API_KEY'] = os.getenv("GROQQ_API_KEY")
作用:
- 这些
os.environ变量主要是给 LangChain 设定 API 相关的配置:LANGCHAIN_TRACING_V2 = 'true':开启 LangChain 运行跟踪(方便调试)。LANGCHAIN_PROJECT = 'advanced-rag':指定项目名称。LANGCHAIN_API_KEY和GROQ_API_KEY:分别设置 LangChain 和 Groq 的 API Key(用于大模型调用)。
举例:
print(os.environ["LANGCHAIN_PROJECT"]) # 输出 "advanced-rag"
这说明你已经成功设置了项目名称。
3. 爬取网页数据
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 设置一个常见的浏览器 User-Agent 字符串
os.environ["USER_AGENT"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
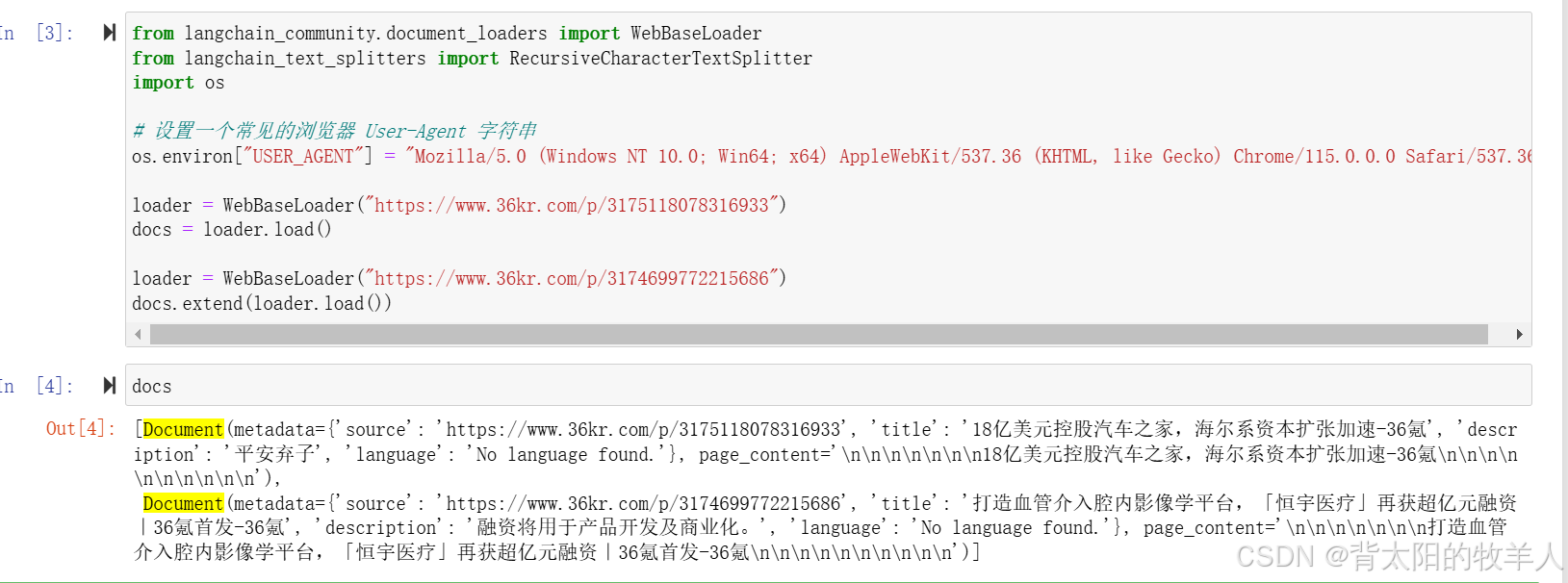
loader = WebBaseLoader("https://www.36kr.com/p/3175118078316933")
docs = loader.load()
loader = WebBaseLoader("https://www.36kr.com/p/3174699772215686")
docs.extend(loader.load())
print(docs)
作用:
WebBaseLoader用于从网页爬取文章。docs = loader.load()抓取第一篇文章(存成 LangChain 文档对象)。docs.extend(loader.load())追加第二篇文章到docs里。
为什么要设定 User-Agent?
有些网站会禁止爬虫访问,设置 User-Agent 让代码看起来像是正常的用户访问。
举例:
如果你打印 docs,它会是一个包含两篇文章的列表,docs的值是完整的文章:
[Document(page_content="文章1内容...", metadata={"source": "https://www.36kr.com/p/3175118078316933"}),
Document(page_content="文章2内容...", metadata={"source": "https://www.36kr.com/p/3174699772215686"})]
4. 生成摘要
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_groq import ChatGroq
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("总结以下文档:\n\n{doc}")
| ChatGroq()
| StrOutputParser()
)
summaries = chain.batch(docs, {"max_concurrency": 1})
作用:
-
构建 LangChain 处理链(chain):
{"doc": lambda x: x.page_content}:提取docs中的正文内容。ChatPromptTemplate.from_template("总结以下文档:\n\n{doc}"):使用ChatGPT生成摘要的提示词。ChatGroq():调用GroqAPI 让大模型生成摘要。StrOutputParser():解析模型返回的文本输出。
-
并行处理
docs:chain.batch(docs, {"max_concurrency": 1}):逐个处理文档(这里max_concurrency=1限制为单线程处理)。
举例:
假设 docs 中某篇文章的内容是:
"恒宇医疗在IVUS和OCT领域发展迅速,市场份额逐步扩大..."
那么 summaries 可能会返回:
["恒宇医疗近年来在IVUS和OCT产品的商业化驱动方面取得了显著进展..."]
5. 构建多向量索引
from langchain.storage import InMemoryByteStore
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-small-zh-v1.5"
model_kwargs = {"device": "cpu"}
encode_kwargs = {"normalize_embeddings": True}
hf_embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="summaries",
embedding_function=hf_embeddings)
# The storage layer for the parent documents
store = InMemoryByteStore()
id_key = "doc_id"
作用:
- 使用
HuggingFace的bge-small-zh-v1.5模型来生成向量(适用于中文)。 Chroma作为向量数据库,用来存储摘要的向量表示。InMemoryByteStore作为存储层,用于存储原始文档。
6. 存储摘要和原始文档
doc_ids = [str(uuid.uuid4()) for _ in docs]
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)
]
#存储摘要的向量表示
retriever.vectorstore.add_documents(summary_docs)
#存储原始文档
retriever.docstore.mset(list(zip(doc_ids, docs)))
作用:
uuid.uuid4()生成唯一 ID,保证每篇文档都有唯一标识。- 摘要存入
vectorstore(向量数据库)。 - 原文档存入
docstore,用于后续检索时关联原文。
7. 检索
query = "恒宇医疗近年来在IVUS和OCT产品的商业化驱动"
#搜索最相关的摘要
sub_docs = vectorstore.similarity_search(query,k=1)
sub_docs[0]
#完整原文
retrieved_docs = retriever.get_relevant_documents(query,n_results=1)
retrieved_docs[0].page_content[0:500]
作用:
vectorstore.similarity_search(query, k=1):用向量搜索最相关的摘要。retriever.get_relevant_documents(query, n_results=1):找到摘要后,返回完整原文。
retriever.get_relevant_documents(query, n_results=1)的内部执行流程请点击学习
总结
这段代码的完整流程:
- 从网页爬取文章 →
- 用大模型生成摘要 →
- 摘要存入向量数据库(Chroma),原文存入存储层 →
- 基于查询进行向量相似性搜索,最终返回原文档。
这样可以高效检索和关联长文档,特别适用于**RAG(检索增强生成)**场景。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)