【LangChain】Chapter8 - Document Splitting
《LangChain Chat with Your Data》-Document Splitting
说在前面
本节将介绍 Document Splitting 文档分割。上一节我们学习了如何将文档加载为标准格式,这一节将讨论如何对其进行分割(Splitting)。
Main Content
文档分割是相当重要的内容,数据被加载为标准格式之后(Document Loading 的工作),被分割为更小的块(chunk)才能保存在向量数据库中。LangChain文本分割器按照 chunk_size(块大小)和 chunk_overlap(块间重叠大小)进行分割。尽管听上去很简单,但是这里有很多的细微处需要注意。
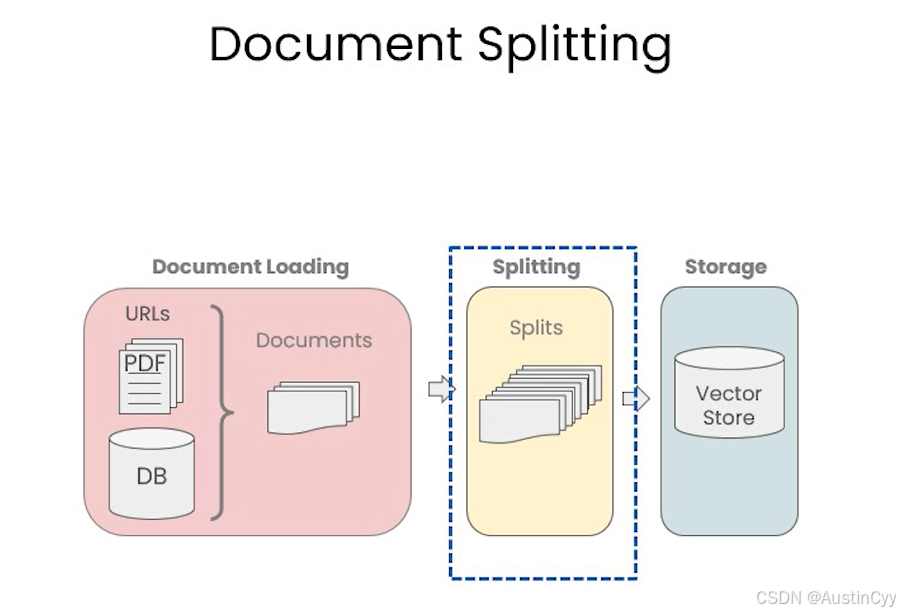
chunk_size(块大小)指的就是我们分割的字符块的大小;chunk_overlap(块间重叠大小)就是下图中加深的部分,上一个字符块和下一个字符块重叠的部分,即上一个字符块的末尾是下一个字符块的开始。

LangChain 中的文档分割器都包含两个方法
create_documents()- Create documents from a list of texts.split_documents()- Split documents
它们其实涉及相同的底层逻辑,只是开放的接口不一样。一个接受文本列表;一个接受文档列表。
LangChain 中包含很多的文档分割器,这里只介绍部分。
前置工作
1.加载环境变量载入 OpenAI API。
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
2.导入我们最常用的两个文档分割器。RecursiveCharacterTextSplitter 递归字符文本分割器 和 CharacterTextSplitter 字符文本分割器。
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
3.设定 chunk_size 和 chunk_overlap 的大小。
chunk_size =26
chunk_overlap = 4
4.初始化两个分割器。r_splitter 和 c_splitter。
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
RecursiveCharacterTextSplitter
1.初始化一个字符串,长度为26。
text1 = 'abcdefghijklmnopqrstuvwxyz'
2.使用 r_splitter 对其进行分割。可以看到分割后得到原本的字符串,这是因为,我们设置的 chunk_size 为26,此时字符串长度也为26,故不会分割成多个部分。
r_splitter.split_text(text1)

3.设置一个长度长于26的字符串 text2。
text2 = 'abcdefghijklmnopqrstuvwxyzabcdefg'
print(len(text2))

4.对 text2 进行分割。我们可以看到,text2 被分割成了两个 chunk,第一个 chunk 的长度为26,第二个 chunk 的长度为 11。同时我们对两个 chunk 进行观察,可以发现第一个 chunk 的最后四个字符为 wxyz,第二个 chunk 的前四个字符为 wxyz,与我们设置的 chunk_overlap 一致。
r_splitter.split_text(text2)

5.下面设置 text3,其中一共有26个字母,每个字母之间用空格隔开。
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
6.对 text3 进行分割。可以看到分成了 3 个 chunk。我们发现我们设置的 chunk_overlap 为 4,但是实践后看起来 chunk_overlap 像是 3,比如 l m。其实,这里的 chunk_overlap 仍然为 4,第一个 chunk 的重叠部分为 l m,带上空格一共是四个字符,下一个 chunk 会从上一个 chunk 的重叠部分开始继续分割,但是当开头是空格的时候,RecursiveCharacterTextSplitter 会将 chunk 开头的空格去掉,使其分割的块更加紧凑,并且在分割文本时空格经常作为分隔符而不是内容的一部分,将开头的空格去掉符合自然语言处理的习惯。
r_splitter.split_text(text3)

事实上 RecursiveCharacterTextSplitter 适用于大多数的文本内容,下面将会对 RecursiveCharacterTextSplitter 的使用进行进一步的详细说明。
1.定义一段文本 some_text。长度为 496。
some_text = """When writing documents, writers will use document structure to group content. \
This can convey to the reader, which idea's are related. For example, closely related ideas \
are in sentances. Similar ideas are in paragraphs. Paragraphs form a document. \n\n \
Paragraphs are often delimited with a carriage return or two carriage returns. \
Carriage returns are the "backslash n" you see embedded in this string. \
Sentences have a period at the end, but also, have a space.\
and words are separated by space."""
len(some_text)

2.初始化 RecursiveCharacterTextSplitter 分割器 r_splitter。注意此处我们有设置用于分割文本的优先级分隔符列表 separators顺序依次为 双换行 \n\n,换行符 \n, 空格,`` 空字符串(即按字符分割)。
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separators=["\n\n", "\n", " ", ""]
)
3.对文本进行分割。
r_splitter.split_text(some_text)

4.现在我们减少 chunk_size ,从450 调整到 150,并且增加分隔符 \. 句号加空格。
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["\n\n", "\n", "\. ", " ", ""]
)
r_splitter.split_text(some_text)

5.不改变chunk_size ,只调整分隔符的内容,(?<=\. ) 表示使用正则表达式分割:寻找句子结束标点后跟一个空格的位置。。
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["\n\n", "\n", "(?<=\. )", " ", ""]
)
r_splitter.split_text(some_text)

下面是用 pdf 文档来做演示,如何使用 RecursiveCharacterTextSplitter 对 PDF 进行分割。
1.首先使用上一节文档加载中的 PDF 加载器 PyPDFLoader 加载一个 PDF文档。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()
2.初始化一个文档分割器 r_splitter。其中设置 length_function = len 表示使用 len 这个函数来对文本进行计数。
from langchain.text_splitter import RecursiveCharacterTextSplitter
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=150,
length_function=len
)
3.对文档进行分割。
docs = r_splitter.split_documents(pages)
4.我们分别计算 分割后的文档 docs 和 分割前的文档 pages 的长度。可以看到分割后的长度为 77 ,分割前的长度为 22。说明的确有进行分割,文档的长度变长。
len(docs)

len(pages)

5.我们继续对比一下 docs[0] 和 pages[0] 的文本内容。可以看到尽管文本内容被分割了,但是其 metadata 却仍然保留着。
docs[0]

pages[0]

这里对使用 RecursiveCharacterTextSplitter 的规则进行总结:
配置参数:
chunk_size: 决定每个块的最大长度。chunk_overlap: 用于块之间的上下文连接。较大的重叠值适合需要更多上下文的任务(如问答系统),但会增加数据冗余。separators: 定义分割优先级,从段落、句子到逐字符。length_function: 自定义文本长度计算函数。默认使用len,可以根据需求计算字符、字节或特殊符号的长度。
分割顺序: 从优先级最高的分隔符开始,如果能够生成长度符合 chunk_size 的块,则使用该分隔符进行分割。如果无法生成符合要求的块,则退回到下一个优先级的分隔符。
分割块的长度: 每个块的长度尽量不超过 chunk_size。由于分隔符的位置可能无法完全满足 chunk_size,实际块的长度可能会小于 chunk_size。
CharacterTextSplitter
1.同样的对上面中间有空格的字符串 text3 进行测试。结果如下,可以看到 text3 并没有被分割。
c_splitter.split_text(text3)

2.给 CharacterTextSplitter 分割器设置 分割符 (空格),重新分割 text3,看到结果如下。
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator = ' '
)
c_splitter.split_text(text3)

CharacterTextSplitter 默认按照字符进行分割,即默认的 separator = ''。所以在第一处,我们会看到没有分割的现象,因为它是按照字符进行计数的,空格没有被算在内。而第二处,我们设置了分隔符为空格,所以空格被计算在了字符串长度中。所以,可以看出 CharacterTextSplitter 是优先按照 separator 分割,分割后的长度可能超过chunk_size。
Token splitting
上面都是基于字符进行分割,但是在LLM中,我们计数的单位往往是 Token(LLM 的API收费是按照 Token计费的)。所以我们在使用LangChain构建LLM 应用时,相比于 字符往往都是基于 Token 进行分割的。下面介绍基于Token的分割器 TokenTextSplitter 。
1.导入 TokenTextSplitter。
from langchain.text_splitter import TokenTextSplitter
2.初始化分割器,一个Token为一个chunk。
text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0)
3.对文本进行分割,我们可以很直观的看到按照 Token 分割的效果是与基于字符分割的效果的区别的。
text1 = "foo bar bazzyfoo"
text_splitter.split_text(text1)

4.我们此时拿 TokenTextSplitter 对文档进行分割,可以看到分割后,metadata 会被保留,跟 RecursiveCharacterTextSplitter 对文档的分割相似。
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
docs[0]

pages[0].metadata

MarkdownHeaderTextSplitter
MarkdownHeaderTextSplitter 根据指定的标题分割Markdown文档。
1.导入 MarkdownHeaderTextSplitter。
from langchain.text_splitter import MarkdownHeaderTextSplitter
2.定义一个 markdown_document。
markdown_document = """# Title\n\n \
## Chapter 1\n\n \
Hi this is Jim\n\n Hi this is Joe\n\n \
### Section \n\n \
Hi this is Lance \n\n
## Chapter 2\n\n \
Hi this is Molly"""
3.定义标题的分级分割。
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
4.对markdown文本进行分割。我们可以看到 MarkdownHeaderTextSplitter 将同一标题下的文本放在同一个chunk,文本对应的标题信息被存储在 chunk 的metadata中。
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits[0]

md_header_splits[1]

总结一下: MarkdownHeaderTextSplitter基于文档结构感知上下文进行分割,自然的将语义相关的文本划分在同一个chunk。跟Markdown类似,HTML、JSON、Code也有内在的文档结构,可被按照结构分割。
- JSON:RecursiveJsonSplitter,按对象或数组元素分割;
- HTML:HTMLHeaderTextSplitter,使用标签分割;
- Code:CodeSplitter,按函数、类或逻辑块分割;
总结
本节介绍了几种LangChain 中的 Document 分割器。其中最通用的是 RecursiveCharacterTextSplitter,另外在 LLM 中我们常常会基于 Token 进行文档的分割。最后针对不同的文档内容结构,比如 Markdown、Json 等我们也有不同的专用分割器可供选择。此外针对不同的情况我们有独特的分割器,需要根据实际情况进行选择。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)