KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation
KAG框架提出了一种知识增强生成方法,通过在RAG技术中集成知识图谱的语义推理能力,显著提升了专业领域问答的准确性。该框架采用语义图索引(结合稀疏符号与稠密向量)、语义解析与推理(将问题转化为逻辑形式)、语义检索三大模块,解决了传统RAG方法依赖相似度检索和共现生成的局限性。实验表明,KAG在多跳QA任务中优于现有RAG方法,并在电子政务场景中验证了其专业性能提升。该项目已开源,支持OpenSPG
KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation
基本信息
博客贡献人
燕青
会议
WWW '25: Companion Proceedings of the ACM on Web Conference 2025
作者
Lei Liang, Zhongpu Bo, Zhengke Gui, et al. (antgroup)
标签
RAG, KBQA, Knowledge Graph, Knowledge Reasoning, Information Retrieval
开源
框架:KAG
应用项目:OpenSPG
摘要
近年来,检索增强生成( Retrieval-Augmented Generation,RAG )技术实现了特定领域应用的高效构建。RAG的关键技术是基于相似度的检索和基于下一令牌预测的推理。然而,这种方法与人类解决问题的方式有很大的不同。人类通常遵循一定的分析逻辑,在检索相关信息的同时进行推理,然后将线索联系起来作为参考,最终产生答案。在这个过程中,关注的是关键词之间的语义类型和明确关系,而不是相似度和共现关系。这种方法论上的差异导致RAG技术产生的答案不够准确或有价值。
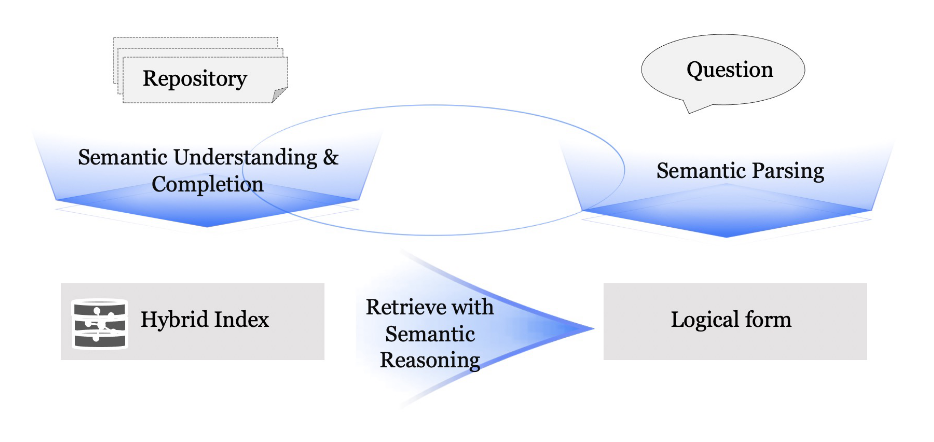
本文的工作专注于建立关键词之间的语义关系,以实现更精确的知识表达,并提出了知识增强生成( KAG )框架。 KAG对文档和问句都进行语义解析和推理,涉及到三种具体的策略:在索引阶段,本文通过信息提取和语义推理来完成关键词的语义信息以及它们之间的语义关系;在问答的推理阶段,本文利用语义解析将问题转化为具有明确语义类型和关系的逻辑形式;在检索阶段,本文预测逻辑形式元素和结构化索引之间的语义关系,从而获得所需的参考文献。
本文在三个多跳QA数据集上将KAG与现有的RAG方法进行了比较,结果表明KAG明显优于现有的方法,达到了新的先进水平。本文还将KAG应用到真实的电子政务问答业务场景中,与传统的RAG方法相比,在专业性方面取得了显著的提升。同时,为了帮助开发者轻松构建准确高效的领域知识问答服务,本文的KAG原生支持开源的KG引擎OpenSPG。
问题定义
现有的RAG方法缺乏逻辑连贯性,如图1中的例子所示。在目前的RAG方法中,检索是基于相似性的,而生成是基于共现(co-occurrence)的。相比之下,人类首先理解问题的语义,即主体、条件和行动是什么。在搜索过程中,人们关注与问题有同义、从属或因果关系的对象,如"养老保险→是→五险一金的一部分"或"视障人士→需要→拐杖",而不是类似的"养老金"或"残疾人"。 这些差异使得现有的RAG无法在法律、医学和科学等专业领域产生正确的答案,而分析推理在这些领域至关重要。
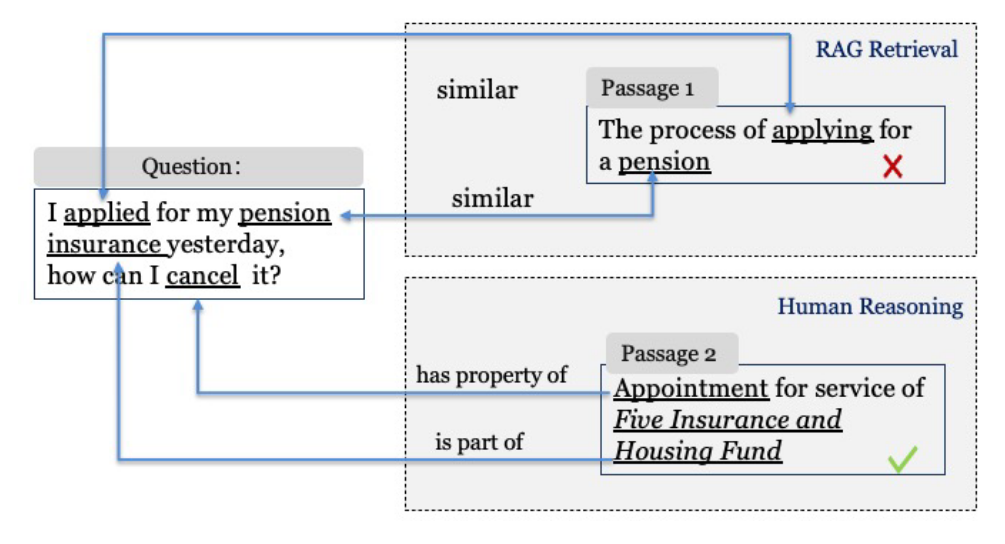
本文提出了知识增强生成( Knowledge Augmented Generation,KAG ),该框架将KG的语义推理能力集成到RAG技术中。本文设计了多种方法将更丰富的语义符号引入到KGs中,从而减少冗余并增强图内知识的互联性。与基于相似度的检索不同,本文的基于语义符号的检索方法提供了更高的准确性,并提高了LLMs的推理和规划能力。本文的KAG与现有的图RAG方法一样,也包括三个步骤:索引、检索和生成。然而,在索引和检索阶段,它利用语义理解和推理来增强逻辑连贯性,而不是依靠关键词和模糊的相似度。
首先,在离线索引阶段,通过预测实体类型、上位概念、同义词、常识关系(commonsence relationship)等关键词之外的潜在语义信息,如常识KG(如Concept Net ),对提取的关键词形成的图进行增广,使提取内容与语义推理内容共同构成知识库的索引。这使得每个关键词具有更明确的语义信息,增加了关键词之间的连接性。其次,本文利用语义解析将自然语言问句转换为一种名为 逻辑形式(Logical Form, LF) 的检索语法,以捕获问句中的语义类型和关系。对于一个给定的问题,可以解析多个逻辑形式子句,每个逻辑形式子句都指向一组SPO(主谓宾)。 变量可以在不同子句之间共享,以实现多跳查询。第三,在检索阶段,预测逻辑形式的关键词与索引中的词之间的语义关系。这种预测充当了用户提问和索引之间的桥梁,取代了模糊的文本相似度作为检索的依据。
本文贡献:
- 提出了一个新的框架KAG,它无缝地集成了LLMs和KGQA的互补技术。该框架将语义理解和推理融入到索引和检索过程中,以提高复杂问答任务的性能。
- 在3个复杂问答任务中的实验结果表明,KAG显著优于其他广泛采用的RAG方法,具有更高的检索和答案准确率。
- 引入了一个基于KAG的工业应用程序,并发布了便于开发本地化应用程序的代码。
相关工作
GraphRAG
GraphRAG利用图结构组织知识库,可以实现更精确和全面的检索,捕获关系型知识,并促进更准确、上下文感知的响应。这类方法通常涉及两个关键步骤:第一是构建一个包含所有文档全局信息的图结构知识库索引,第二是从该知识库中检索以获得所需的参考信息。
GraphRAG在构建离线索引时生成元素级和社区级的摘要,并为每个图社区生成摘要,然后根据摘要生成最终响应。这些方法虽然建立了跨文档的图结构知识库索引,但局限于捕获显式内容,忽略了文章和问题本身所蕴含的语义信息,使得在参考信息查找过程中难以进行基于语义信息的推理和检索。KAG通过利用知识库中的语义知识补全和对问题进行语义解析来提高该场景下的性能。

KBQA
知识库问答( Knowledge Base Question Answering,KBQA )是自然语言处理中的一项重要任务,旨在基于外部知识库响应用户查询。现有的KBQA方法可以分为两类:基于信息检索( Information Retrieval,IR )的方法和基于语义解析( Semantic Parsing,SP )的方法。基于IR的方法从知识库中检索与查询相关的信息,并将其用于增强生成过程。大多数RAG方法都属于这种方法。基于SP的方法生成可执行的数据库查询(如SQL、SparQL 等)或逻辑形式(如S-表达式),并针对知识库执行以获取答案。 虽然这种方法表现出更好的逻辑性和可解释性,但它通常需要一个结构良好的知识库和伴随语言,而大多数现实场景缺乏这种语言,从而导致更高的使用成本。本文的工作结合了IR和SP的方法,使其能够使用逻辑形式,这些逻辑形式具有清晰的逻辑结构,即使在没有预先构造的结构化KB的情况下。这种结合的方法通过利用这些逻辑形式来增强检索和推理的有效性,从而不会增加成本。
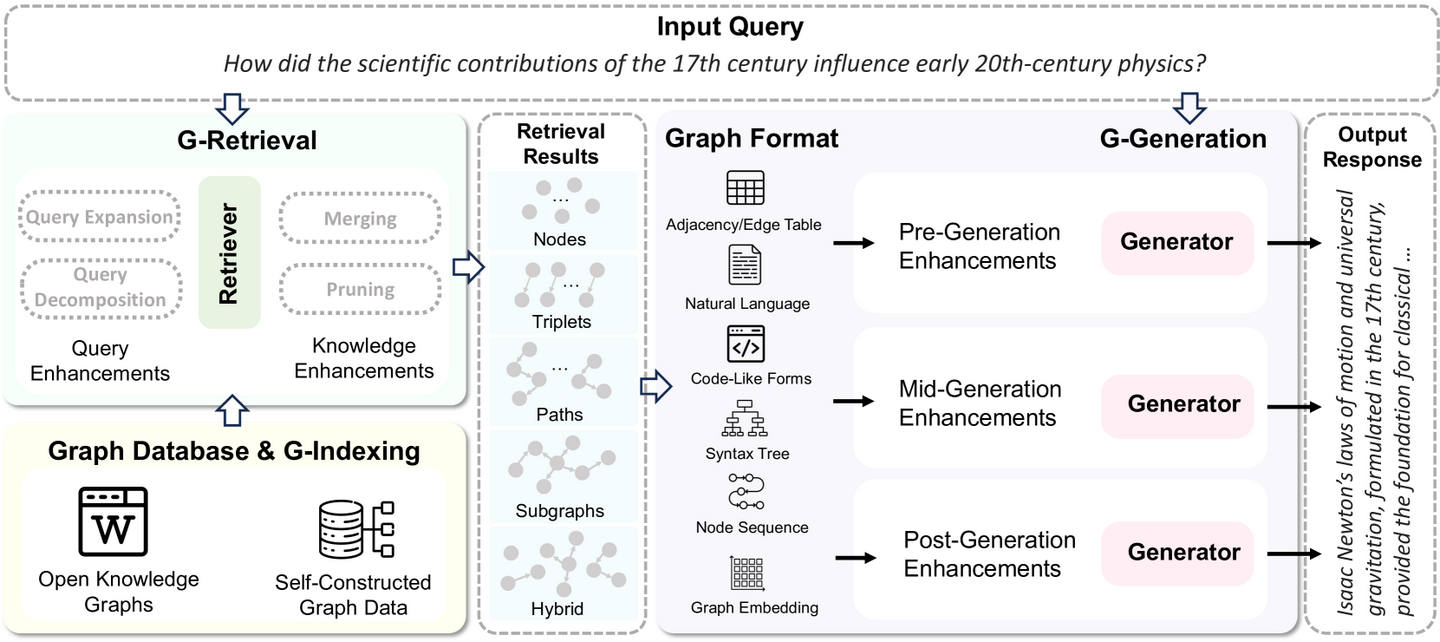
方法
本文架构
- 语义图索引:从文档中提取实体和关系,然后进行各种语义增强,形成语义图。该语义图融合了新生成的概念节点和语义关系边,有效地桥接了多个文档,可作为知识库的混合索引。该混合索引既支持复杂的逻辑推理,又支持模糊的相似性搜索,同时保持了清晰的语义结构。
- 语义解析与推理:将复杂的用户问题分解为一系列较为简单的子问题,并将这些子问题转化为逻辑形式,这些逻辑形式是具有明确语义的结构化查询语句。与自然语言问句相比,逻辑形式问句具有更清晰的语义,更适合与语义图索引配合进行逻辑推理和语义检索。
- 语义检索:从语义图索引的知识库中检索回答问题或子问题所需要的信息。本文设计了两种针对逻辑表单的语义检索方法:一种方法检索语义图数据,另一种方法从知识库中检索文档数据来回答问题。
除了上述主要模块外,KAG还包括一个任务控制模块,用于管理整个问答过程。它的功能包括:问题和子问题状态管理,历史子问题和答案的摘要和记忆,以及多步推理中的执行和终止判断。虽然语义解析推理模块已经支持用户查询的分解,便于多跳推理,但是本文仍然保留了KAG迭代地、反思性地解决复杂问题(即多步回答)的能力。
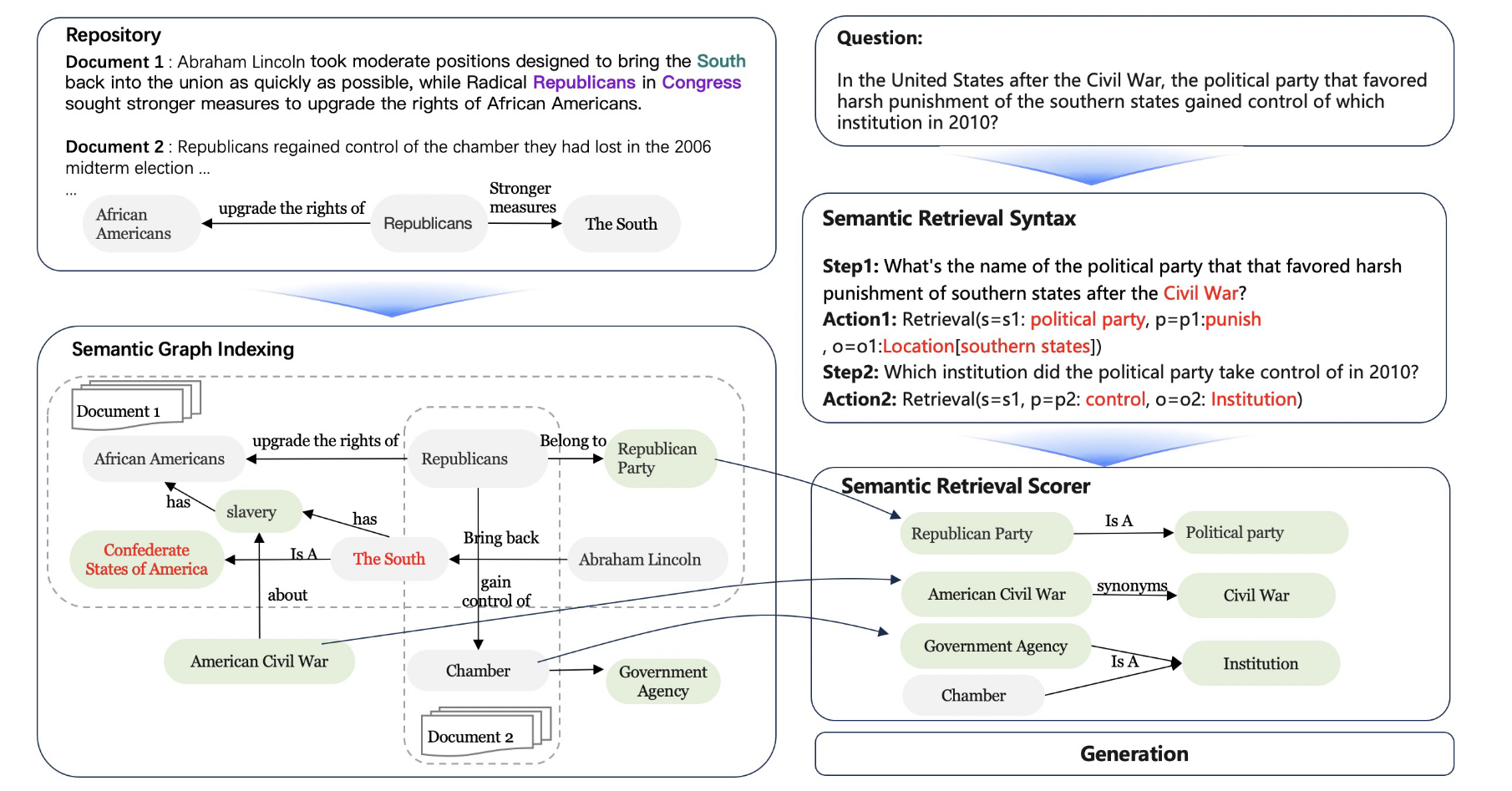
语义图索引
语义图索引是一种稀疏-密集的混合索引。本文为给定的文档语料库构建了一个语义图,它作为一个稀疏的符号索引,支持基于逻辑符号的检索和推理。同时,本文根据语义图中每个节点的名称和上下文计算其嵌入,以创建密集的向量索引,以缓解符号索引的稀疏性问题。一个语义图主要由两部分组成,事实子图和概念子图:
T s e m a n t i c = T f a c t ⊕ T c o n c e p t (1) \mathcal{T}_{semantic}=\mathcal{T}_{fact}\oplus \mathcal{T}_{concept} \tag{1} Tsemantic=Tfact⊕Tconcept(1)
其中 ⊕ \oplus ⊕ 表示两个图的连接,它需要一组从 T f a c t \mathcal{T}_{fact} Tfact 中的节点到 T c o n c e p t \mathcal{T}_{concept} Tconcept 中的节点的边集 E l i n k \mathcal{E}_{link} Elink。
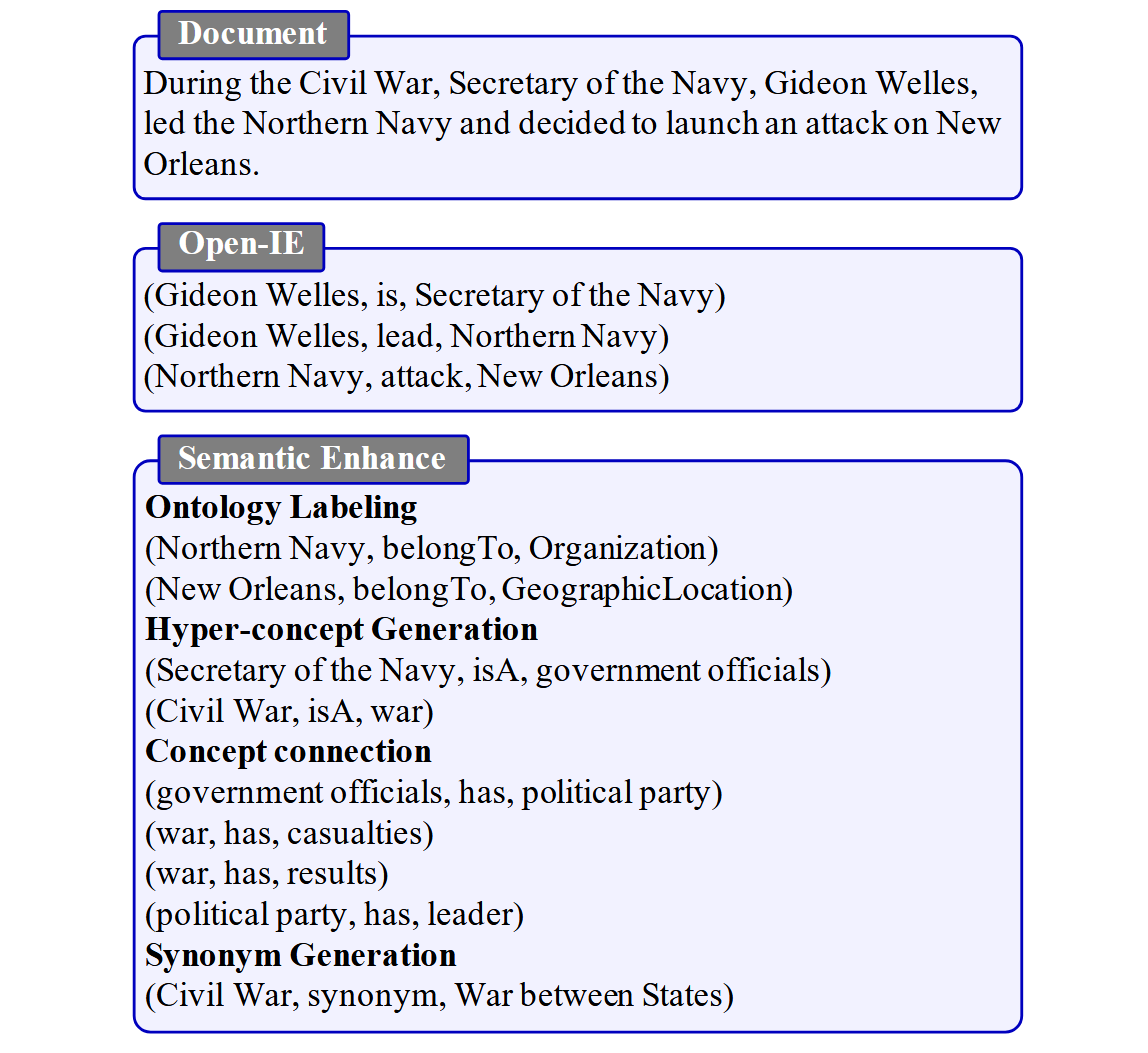
事实子图 T f a c t \mathcal{T}_{fact} Tfact 是通过开放信息提取( Open Information Extraction,Open-IE )模型从文档语料库 D \mathcal{D} D 中提取的事实三元组构成的图。一般来说, T f a c t \mathcal{T}_{fact} Tfact中的三元组可以分为两类:实例知识和常识知识。实例知识三元组通常由两个实体词或一个实体词和一个概念词组成,常识知识三元组通常由两个概念词及其关系组成。在文献中,实例知识被频繁提及,而常识知识往往没有被明确表述。然而,常识在逻辑推理中起着至关重要的作用,它提供了必要的背景信息,并充当了连接图内推理所需逻辑路径的中间节点。因此,本文在 T f a c t \mathcal{T}_{fact} Tfact 的基础上生成了一个概念图 T c o n c e p t \mathcal{T}_{concept} Tconcept 对隐含的常识性知识进行补充。
概念子图是在事实子图的基础上生成的,其中 N c \mathcal{N}_c Nc 和 E c \mathcal{E}_c Ec 是 T c o n c e p t \mathcal{T}_{concept} Tconcept 中的节点和边, N f \mathcal{N}_f Nf 是 T f a c t \mathcal{T}_{fact} Tfact 中的节点:
T c o n c e p t = ( N c , E c ) E c = E e x p ∪ E c o n n e c t N c , E l i n k , E e x p = S e m a n t i c E x p a n i s i o n ( N f , D ) E c o n n e c t = S e m a n t i c C o n n e c t i o n ( N c ) \mathcal{T}_{concept}=(\mathcal{N}_c,\mathcal{E}_c) \\ \mathcal{E}_{c}=\mathcal{E}_{exp}\cup \mathcal{E}_{connect} \\ \mathcal{N}_{c},\mathcal{E}_{link},\mathcal{E}_{exp}=SemanticExpanision(\mathcal{N}_{f},\mathcal{D}) \\ \mathcal{E}_{connect}=SemanticConnection(\mathcal{N}_{c}) Tconcept=(Nc,Ec)Ec=Eexp∪EconnectNc,Elink,Eexp=SemanticExpanision(Nf,D)Econnect=SemanticConnection(Nc)
本文首先通过三种语义扩展方法从 T f a c t \mathcal{T}_{fact} Tfact 动作中生成新的概念节点 N c \mathcal{N}_c Nc 和 E l i n k \mathcal{E}_{link} Elink, E e x p \mathcal{E}_{exp} Eexp:
- 本体标注 (Ontology Labeling):对于每个节点 n i ∈ N f n_i \in \mathcal{N}_f ni∈Nf,本文用16个预定义的本体标签 c c c 对其进行标注,这些标签指的是实体所属的抽象类型。该操作将 c c c 加入 N c \mathcal{N}_c Nc,将三元组 ( n i , b e l o n g T o , c i ) (n_i, belongTo,c_i) (ni,belongTo,ci) 加入 E l i n k \mathcal{E}_{link} Elink,其中 c i ∈ c c_i \in c ci∈c
- 上位概念生成 (Hyper-concept Generation):对于每个节点 n i ∈ N f n_i\in N_f ni∈Nf,生成一个上位词 (hypernym) 概念序列 h i h_i hi。上位词概念序列是一个有序的词序列,其中下一个词是上一个词的上位词。借助上位词序列,共享同一上位概念的概念将被连接。该操作将新概念 h i h_i hi 添加到 N c N_c Nc 中,将三元组 ( n i , i s A , h i , 1 ) ( n_i , isA , h_{i,1}) (ni,isA,hi,1) 添加到 E l i n k \mathcal{E}_{link} Elink 中,其中 h i , 1 h_{i,1} hi,1 是 h i h_i hi 的第一个元素;将 ( h i , j , i s A , h i , j + 1 ) ( h_{i,j} , isA , h_{i,j+1}) (hi,j,isA,hi,j+1)加入 E e x p \mathcal{E}_{exp} Eexp,其中 j ≥ 2 j \geq2 j≥2。
- 官方命名生成 (Official Name Generation):由于自然语言的多样性,同一对象可以用多种方式表示,导致在一个图索引中存在冗余、二义性和稀疏连接等问题,这些问题在向量嵌入的帮助下仍然严重。因此,本文根据 N f N_f Nf 的上下文为 N f N_f Nf 中的实体生成官方名称,并将三元组 ( n i , o f f i c i a l N a m e , n j ) ( n_i , officialName , n_j) (ni,officialName,nj)引入到 E l i n k \mathcal{E}_{link} Elink中,其中 n j ∈ N c n_j \in N_c nj∈Nc 是生成的官方名称实体。
然后本文用两种语义连接方法在 N c N_c Nc 中的概念节点之间添加语义边 E c o n n e c t \mathcal{E}_{connect} Econnect:
- 概念连接 (Concept Connection):遵循现有的常识知识图谱,如ConceptNet和ATOMIC,本文预测了概念之间的常识关系,因为这些关系以简洁的形式封装了真实世界的逻辑。该操作将三元组 ( n i , r k , n j ) ( n_i , r_k , n_j) (ni,rk,nj) 添加到 E c o n n e c t \mathcal{E}_{connect} Econnect 中,其中 n i ∈ N c n_i \in N_c ni∈Nc, n j ∈ N c n_j \in N_c nj∈Nc 和 r k ∈ r r_k \in r rk∈r 是预定义关系类型的集合。在一般的应用中,本文使用三种常见的关系 r = { i s A , c a u s e s , h a s P r o p e r t y } r = \{ isA,causes,hasProperty \} r={isA,causes,hasProperty},而对于特定领域的应用,可以结合更多的特殊关系。
- 实体同义词连接 (Entity Synonym Connection):本文还在事实节点之间添加了同义边,以加强知识库中文档之间的联系。在形式上,本文将三元组 ( n i , s y n o n y m , n j ) ( n_i ,synonym, n_j) (ni,synonym,nj) 添加到图 T f a c t \mathcal{T}_{fact} Tfact 中,其中 n i n_i ni 和 n j n_j nj 是 T f a c t \mathcal{T}_{fact} Tfact 中的节点。
以上所有的概念图构建方法都是使用带有各种说明的LLM来实现的。语义图索引构建过程的完整示例见图5:
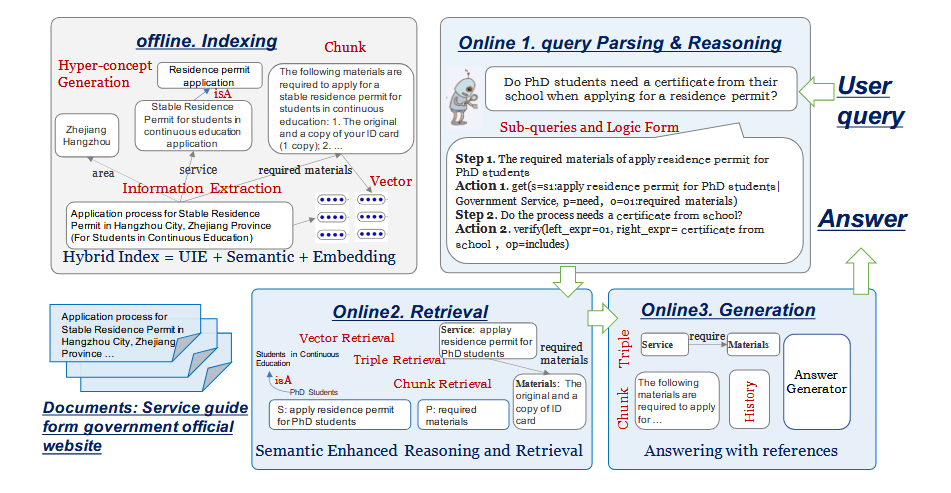
语义解析与推理
如图7所示,该过程首先将用户的原始查询 q q q 分解为一个子查询序列 s = [ s 1 , s 2 , . . . , s n ] s = [ s_1 , s_2 , ... , s_n] s=[s1,s2,...,sn],其中 s i s_i si 为第 i i i 个自然语言子查询。与思维链 (Chain of Thought,CoT) 一样,子查询是对原始查询的逻辑分解。每个子查询比原始查询更简单,通常只涉及到一跳的逻辑推理。随后,每个子查询被翻译成一种称为逻辑形式( Logical Form,LF )的图检索语言。那么原查询可以改写为:
q ~ = [ ( s 1 , L 1 ) , ( s 2 , L 2 ) , . . . , ( s n , L n ) ] (2) \tilde{q}=[(s_1,\mathcal{L_1}),(s_2,\mathcal{L_2}),...,(s_n,\mathcal{L_n})]\tag{2} q~=[(s1,L1),(s2,L2),...,(sn,Ln)](2)
其中, L i \mathcal{L}_i Li 为子查询 s i s_i si 的逻辑形式版本,是一个六元组:
L = ( o p e r a t i o n s , s _ t y p e , s _ m e n t i o n , p , o _ t y p e , o _ m e n t i o n ) (3) \mathcal{L}=(operations,s\_type,s\_mention,p,o\_type,o\_mention)\tag{3} L=(operations,s_type,s_mention,p,o_type,o_mention)(3)
其中 s _ t y p e s\_type s_type 和 o _ t y p e o\_ type o_type 分别表示子查询中主语和宾语的类型; s _ m e n t i o n s\_mention s_mention 和 o _ m e n t i o n o\_mention o_mention 分别表示主语和宾语在子查询中的表达方式; p p p 表示主语和宾语之间的谓语。该操作定义了子查询所表示的数据检索类型。本文根据应用场景预先定义了一组操作类型,常用的操作类型包括 g e t _ s p o 、 s u m 、 m a x get\_spo、sum、max get_spo、sum、max 等。
图6展示了一个真实问题及其对应的子查询和 L F LF LF,注意到本文给 L L L 中的每个元素一个唯一的别名(例如 s 1 , p 1 s1 , p1 s1,p1),以便重新引用。

语义检索
语义检索的目的是利用逻辑形式从知识库(即文档和语义图索引)中召回与问题相关的信息,最终用于生成问题的答案。本文针对逻辑形式设计了两种不同的语义检索方法。第一种方法是针对每个逻辑形式从语义图中检索三元组,并尝试直接使用这些图三元组来回答原问题,而不依赖于原始文档;第二种方法使用语义图索引来检索相关文档,然后使用这些文档的内容来回答问题。首先,本文尝试使用检索到的三元组来回答这个问题;如果没有检索到三元组或者没有生成有效答案,那么本文使用文档来回答问题。
- 三元组检索
L F LF LF 中的元素由基于用户问题的LLM生成,无法与语义图中的元素进行匹配,从而无法直接执行图数据的查询。为了解决这个问题,本文提出了一种图三元组的召回和匹配方法。具体来说,对于子查询 s s s 及其 L F LF LF L \mathcal{L} L,本文首先基于实体的记载(mention)和类型,利用嵌入余弦相似度从语义图中召回其实体的候选链接节点:
N c a n d L = S i m R e c a l l ( E L , T s e m a n t i c ) (4) \mathcal{N}_{cand}^{\mathcal{L}}=SimRecall(E_{\mathcal{L}},\mathcal{T}_{semantic})\tag{4} NcandL=SimRecall(EL,Tsemantic)(4)
其中, E L E_{\mathcal{L}} EL 表示 L \mathcal{L} L 中的主语和宾语实体的集合。
接下来,在语义图中对召回的候选节点 N c a n d N_{cand} Ncand 进行一跳(one-hop)扩展,得到一个子图作为 L \mathcal{L} L 的候选子图:
T c a n d L = O n e H o p E x p a n s i o n ( N c a n d L , T s e m a n t i c ) (5) \mathcal{T}_{cand}^{\mathcal{L}}=OneHopExpansion(\mathcal{N}_{cand}^{\mathcal{L}},\mathcal{T}_{semantic})\tag{5} TcandL=OneHopExpansion(NcandL,Tsemantic)(5)
最后,将候选子图中适合回答子查询的三元组作为该子查询的查询结果:
T s = M a t c h ( s , T c a n d L ) (6) T_s=Match(s,T_{cand}^{\mathcal{L}})\tag{6} Ts=Match(s,TcandL)(6)
其中 T c a n d L T_{cand}^{\mathcal{L}} TcandL 是 T c a n d L \mathcal{T}_{cand}^{\mathcal{L}} TcandL 中的三元组, T s T_s Ts 是子查询的匹配三元组,它将用于后面的答案生成步骤。 M a t c h ( ⋅ ) Match ( · ) Match(⋅) 是指一个匹配函数,本文在实验中使用LLM来实现这个函数。
- 文档检索
根据HippoRAG,本文在语义图上使用PPR算法(Personalized PageRank, 一种基于随机游走的图节点相似度算法)来计算基于种子实体(seed entities, 指与用户查询最相关的实体)集合的文档得分。不同之处在于本文的种子实体集,它由三部分组成:
(1) 从查询中提取的实体。
(2) 公式5描述的三元组检索过程中构建的候选图 T c a n d L \mathcal{T}_{cand}^{\mathcal{L}} TcandL 中的实体。
(3) 通过查询语义增强得到的实体,增强方法包括本体标注、上位概念生成和同义词生成,这与前文语义图构建阶段是一致的。
值得注意的是,与三元组检索不同,文档检索的结果是文档内容而不是图三元组。
流程示例
实验
实验指标
在评估QA性能时,本文使用了两个指标:精确匹配 (Exact Match,EM) 和 F1 分数
在评估检索性能时,本文计算 Top 5/10 检索结果命中率,分别表示为Recall@5和Recall@10
数据集
多跳QA数据集:
- HotpotQA
- 2WikiMultiHopQA
- MuSiQue
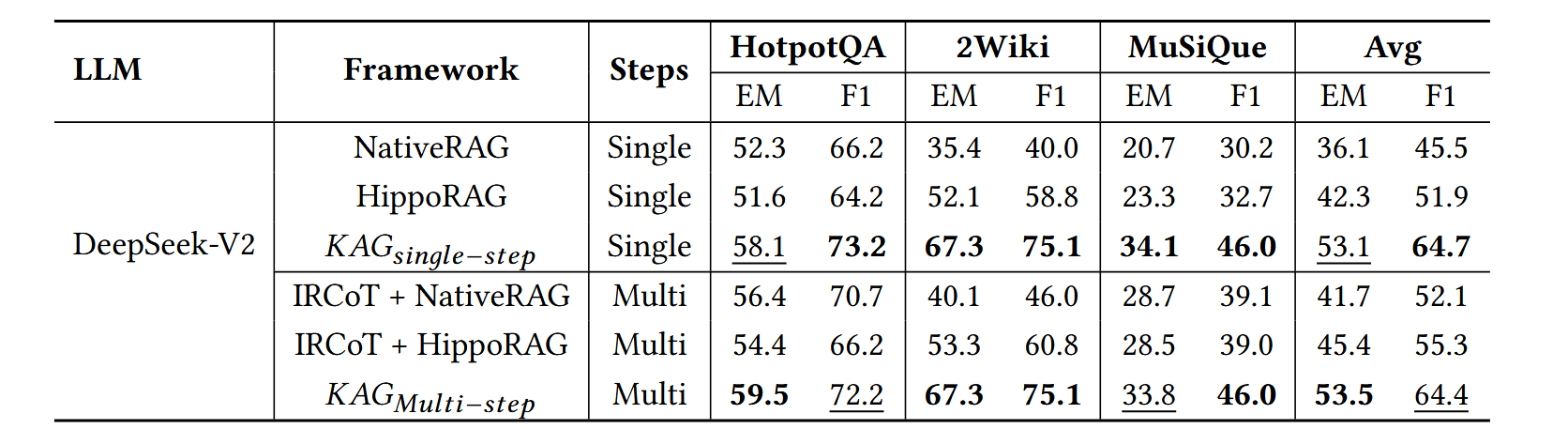
基线模型
单跳模型 K A G s i n g l e − s t e p KAG_{single-step} KAGsingle−step
- NativeRAG
- HippoRAG
多跳模型 K A G m u l t i − s t e p KAG_{multi-step} KAGmulti−step
- NativeRAG+IRCoT
- HippoRAG+IRCoT
实验结果
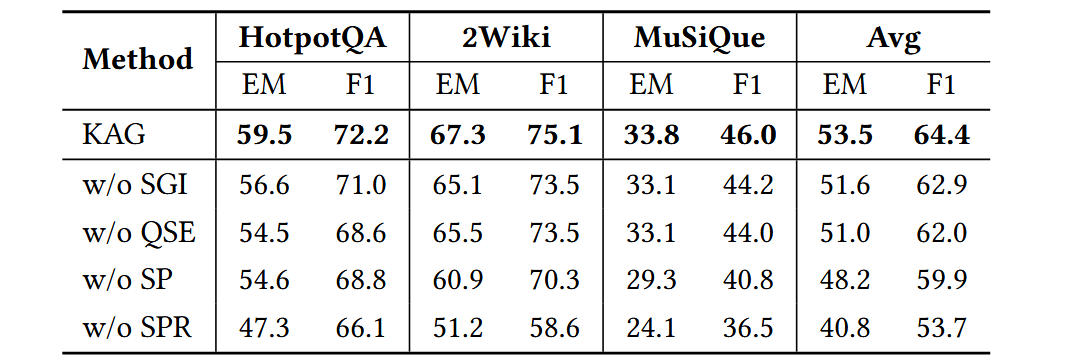
总结
论文原文
KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation
[亮点]
- 提出了一个新的框架KAG,将语义理解和推理融入到索引和检索过程中,以提高复杂问答任务的性能
[启发]
- 知识图谱具有稀疏性导致无法很好地被词向量密集召回,而词向量则无法准确反映知识库中实体间的关系性
- 如何将两者更紧密,巧妙的结合是RAG未来的研究方向
BibTex
@inproceedings{liang2025kag,
title={Kag: Boosting llms in professional domains via knowledge augmented generation},
author={Liang, Lei and Bo, Zhongpu and Gui, Zhengke and Zhu, Zhongshu and Zhong, Ling and Zhao, Peilong and Sun, Mengshu and Zhang, Zhiqiang and Zhou, Jun and Chen, Wenguang and others},
booktitle={Companion Proceedings of the ACM on Web Conference 2025},
pages={334--343},
year={2025}
}

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)